

Facebook’s F16 achieves 400G effective intra DC speeds using 100GE fabric switches and 100G optics, Other Hyperscalers?
On March 14th at the 2019 OCP Summit, Omar Baldonado of Facebook (FB) announced a next-generation intra -data center (DC) fabric/topology called the F16. It has 4x the capacity of their previous DC fabric design using the same Ethernet switch ASIC and 100GE optics. FB engineers developed the F16 using mature, readily available 100G 100G CWDM4-OCP optics (contributed by FB to OCP in early 2017), which in essence gives their data centers the same desired 4x aggregate capacity increase as 400G optical link speeds, but using 100G optics and 100GE switching.
F16 is based on the same Broadcom ASIC that was the candidate for a 4x-faster 400G fabric design – Tomahawk 3 (TH3). But FB uses it differently: Instead of four multichip-based planes with 400G link speeds (radix-32 building blocks), FB uses the Broadcom TH3 ASIC to create 16 single-chip-based planes with 100G link speeds (optimal radix-128 blocks). Note that 400G optical components are not easy to buy inexpensively at Facebook’s large volumes. 400G ASICs and optics would also consume a lot more power, and power is a precious resource within any data center building. Therefore, FB built the F16 fabric out of 16 128-port 100G switches, achieving the same bandwidth as four 128-port 400G switches would.
Below are some of the primary features of the F16 (also see two illustrations below):
-Each rack is connected to 16 separate planes. With FB Wedge 100S as the top-of-rack (TOR) switch, there is 1.6T uplink bandwidth capacity and 1.6T down to the servers.
-The planes above the rack comprise sixteen 128-port 100G fabric switches (as opposed to four 128-port 400G fabric switches).
-As a new uniform building block for all infrastructure tiers of fabric, FB created a 128-port 100G fabric switch, called Minipack – a flexible, single ASIC design that uses half the power and half the space of Backpack.
-Furthermore, a single-chip system allows for easier management and operations.
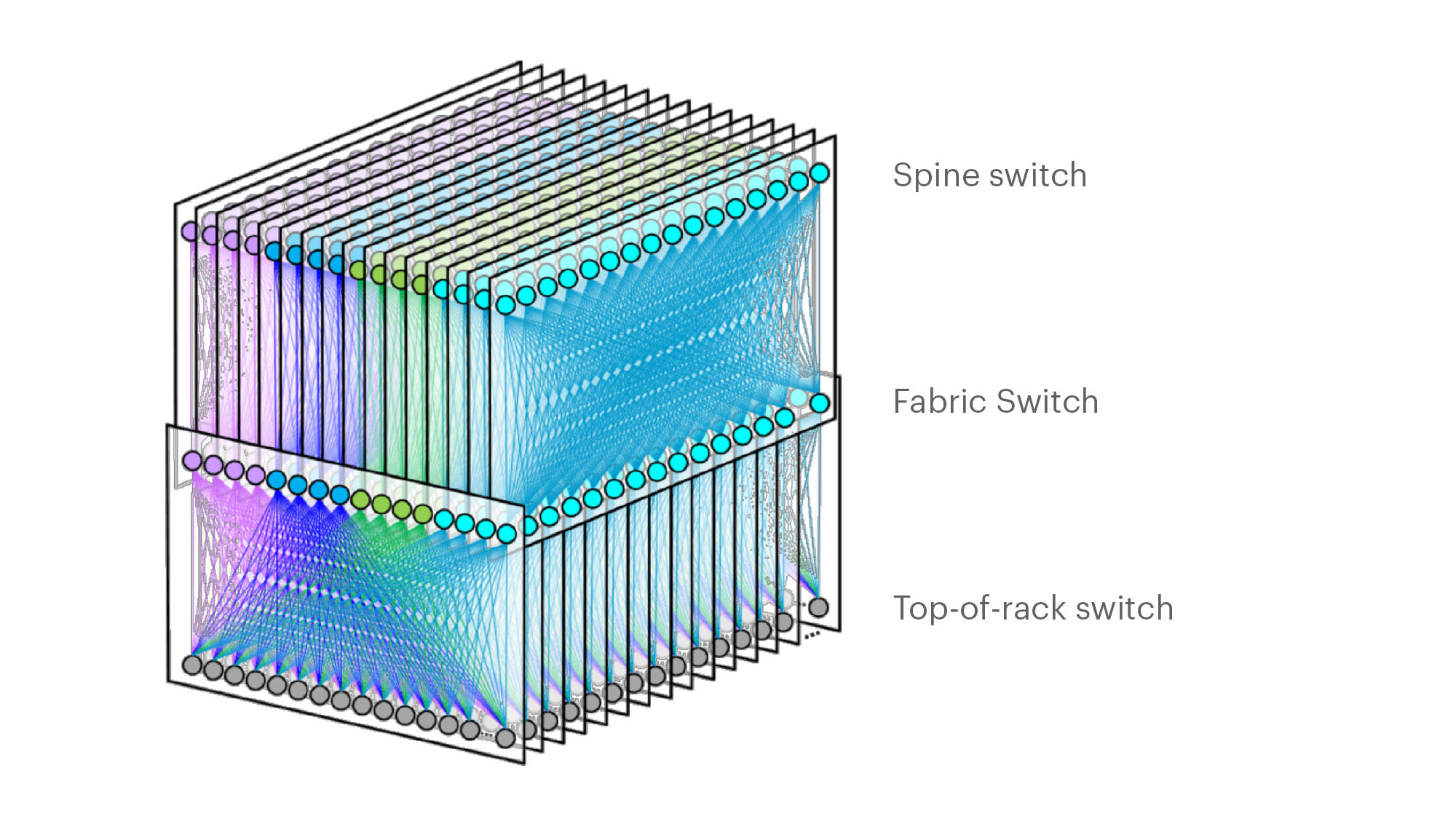 Facebook F16 data center network topology
Facebook F16 data center network topology
………………………………………………………………………………………………………………………………………………………………………………………………..
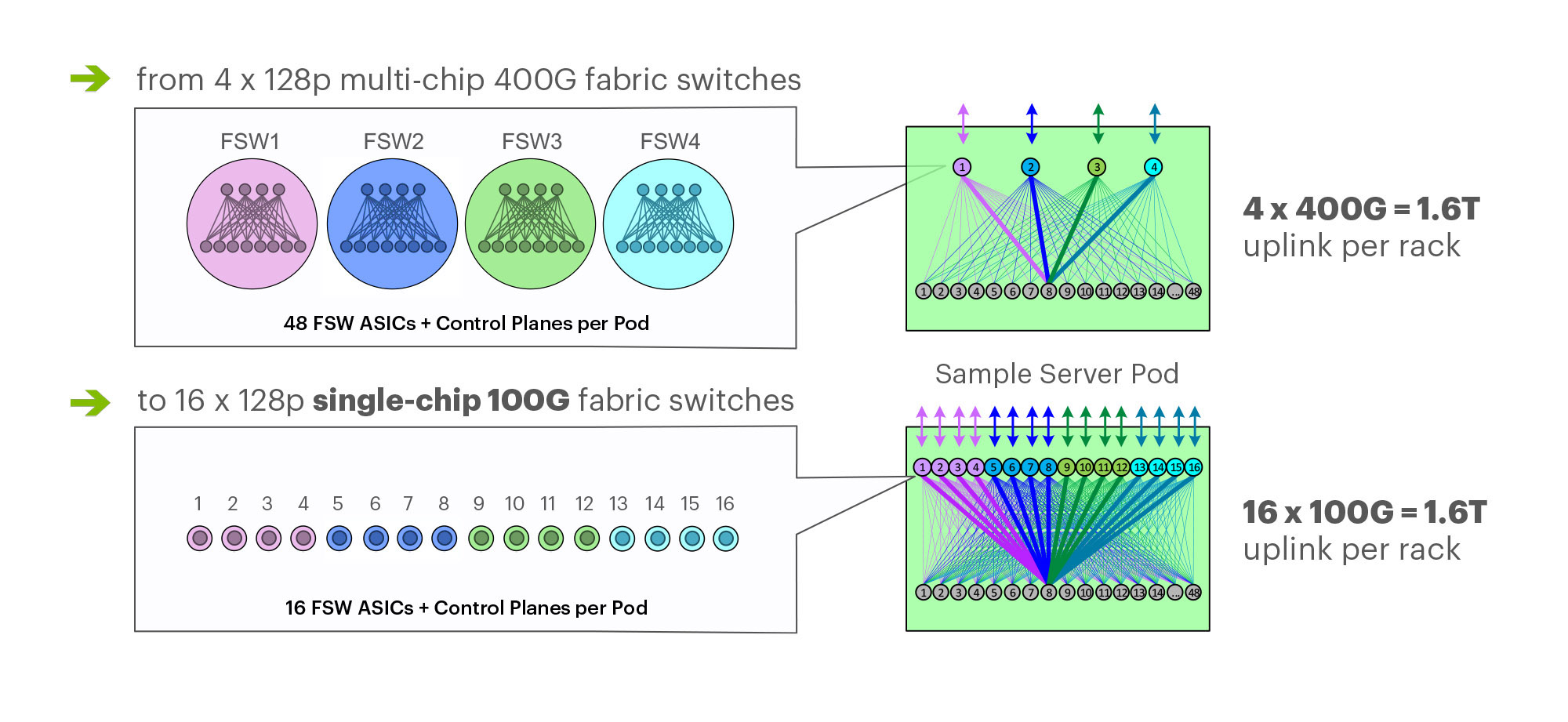
Multichip 400G b/sec pod fabric switch topology vs. FBs single chip (Broadcom ASIC) F16 at 100G b/sec
…………………………………………………………………………………………………………………………………………………………………………………………………..
In addition to Minipack (built by Edgecore Networks), FB also jointly developed Arista Networks’ 7368X4 switch. FB is contributing both Minipack and the Arista 7368X4 to OCP. Both switches run FBOSS – the software that binds together all FB data centers. Of course the Arista 7368X4 will also run that company’s EOS network operating system.
F16 was said to be more scalable and simpler to operate and evolve, so FB says their DCs are better equipped to handle increased intra-DC throughput for the next few years, the company said in a blog post. “We deploy early and often,” Baldonado said during his OCP 2019 session (video below). “The FB teams came together to rethink the DC network, hardware and software. The components of the new DC are F16 and HGRID as the network topology, Minipak as the new modular switch, and FBOSS software which unifies them.”
This author was very impressed with Baldonado’s presentation- excellent content and flawless delivery of the information with insights and motivation for FBs DC design methodology and testing!
References:
https://code.fb.com/data-center-engineering/f16-minipack/
………………………………………………………………………………………………………………………………….
Other Hyperscale Cloud Providers move to 400GE in their DCs?
Large hyperscale cloud providers initially championed 400 Gigabit Ethernet because of their endless thirst for networking bandwidth. Like so many other technologies that start at the highest end with the most demanding customers, the technology will eventually find its way into regular enterprise data centers. However, we’ve not seen any public announcement that it’s been deployed yet, despite its potential and promise!
Some large changes in IT and OT are driving the need to consider 400 GbE infrastructure:
- Servers are more packed in than ever. Whether it is hyper-converged, blade, modular or even just dense rack servers, the density is increasing. And every server features dual 10 Gb network interface cards or even 25 Gb.
- Network storage is moving away from Fibre Channel and toward Ethernet, increasing the demand for high-bandwidth Ethernet capabilities.
- The increase in private cloud applications and virtual desktop infrastructure puts additional demands on networks as more compute is happening at the server level instead of at the distributed endpoints.
- IoT and massive data accumulation at the edge are increasing bandwidth requirements for the network.
400 GbE can be split via a multiplexer into smaller increments with the most popular options being 2 x 200 Gb, 4 x 100 Gb or 8 x 50 Gb. At the aggregation layer, these new higher-speed connections begin to increase in bandwidth per port, we will see a reduction in port density and more simplified cabling requirements.
Yet despite these advantages, none of the U.S. based hyperscalers have announced they have deployed 400GE within their DC networks as a backbone or to connect leaf-spine fabrics. We suspect they all are using 400G for Data Center Interconnect, but don’t know what optics are used or if it’s Ethernet or OTN framing and OAM.
…………………………………………………………………………………………………………………………………………………………………….
In February, Google said it plans to spend $13 billion in 2019 to expand its data center and office footprint in the U.S. The investments include expanding the company’s presence in 14 states. The dollar figure surpasses the $9 billion the company spent on such facilities in the U.S. last year.
In the blog post, CEO Sundar Pichai wrote that Google will build new data centers or expand existing facilities in Nebraska, Nevada, Ohio, Oklahoma, South Carolina, Tennessee, Texas, and Virginia. The company will establish or expand offices in California (the Westside Pavillion and the Spruce Goose Hangar), Chicago, Massachusetts, New York (the Google Hudson Square campus), Texas, Virginia, Washington, and Wisconsin. Pichai predicts the activity will create more than 10,000 new construction jobs in Nebraska, Nevada, Ohio, Texas, Oklahoma, South Carolina, and Virginia. The expansion plans will put Google facilities in 24 states, including data centers in 13 communities. Yet there is no mention of what data networking technology or speed the company will use in its expanded DCs.
I believe Google is still designing all their own IT hardware (compute servers, storage equipment, switch/routers, Data Center Interconnect gear other than the PHY layer transponders). They announced design of many AI processor chips that presumably go into their IT equipment which they use internally but don’t sell to anyone else. So they don’t appear to be using any OCP specified open source hardware. That’s in harmony with Amazon AWS, but in contrast to Microsoft Azure which actively participates in OCP with its open sourced SONIC now running on over 68 different hardware platforms.
It’s no secret that Google has built its own Internet infrastructure since 2004 from commodity components, resulting in nimble, software-defined data centers. The resulting hierarchical mesh design is standard across all its data centers. The hardware is dominated by Google-designed custom servers and Jupiter, the switch Google introduced in 2012. With its economies of scale, Google contracts directly with manufactures to get the best deals.Google’s servers and networking software run a hardened version of the Linux open source operating system. Individual programs have been written in-house.
One thought on “Facebook’s F16 achieves 400G effective intra DC speeds using 100GE fabric switches and 100G optics, Other Hyperscalers?”
Comments are closed.

This week at OCP, Arista Networks announced its new 7360X series of switches that doubles system density and reduces power requirements, all of which leads to a more cost-effective network. The switch is built using Broadcom’s Tomahawk3 silicon, which has a whopping 12.8TB of capacity. This equates to 32 x 400 Gig ports, 64 x 200 Gig, 128 x 100 Gig or some combination of the different speeds.
The new 7360X series has an interesting design in that it’s the first “fixed-modular” switch. This may sound like an oxymoron, but the product is designed around a single chip (Tomahawk3). It’s fixed, but it does have removable cards, therefore it’s modular. The switch is a 4RU form factor but was designed for flexibility. Instead of using the typical horizontal line cards, the 7360X has half height, vertical cards increasing the flexibility.
For example, the switch could initially be configured with eight 16-port 100 Gig line cards. When the need came to test 400 Gig, one of the 16-port 100 Gig line cards could be removed and replace with a single four-port 400 Gig card.
Given the falling prices of 100 Gig optics combined with the lack of availability of 400 Gig connectors, I believe most customers will initially use the product for high-density 100 Gig environments. Businesses can then migrate to 400 Gig as they require while keeping an eye on pricing. The increased flexibility that the half-height cards brings makes this easy to do without breaking the bank on connectors.
Another interesting aspect of this switch is the removable switching card. Other products in this class typically have a fixed switch card, meaning upgrading to the next family of silicon would require a forklift upgrade. The removable switch card can be swapped out, preserving the investment in existing line cards.
Since its inception, Arista’s products have been designed to be open. One proof point of this is that the 7360X series can run Arista’s own EOS operating system or FBOSS (Facebook Open Switch Software). This FBOSS version isn’t available as a commercial product, but it does highlight that the underlying hardware can run more than EOS.
The promise of white box has been out there for a long time, but it’s largely been a flop. One of the reasons is that white box vendors do not offer the same kind of support as a more traditional vendor. Arista’s model lets customers leverage white box but has the reliability and support needed to use them in production environments.
https://www.eweek.com/networking/arista-brings-some-beef-to-hyperscale-environments?