

Stratospheric Platforms demos HAPS based 5G; will it succeed where Google & Facebook failed?
UK-based Stratospheric Platforms (SPL) claims it’s demonstrated the world’s first successful High Altitude Platform Satellite (HAPS) based 5G base station. The 5G coverage from the stratosphere demonstration took place in Saudi Arabia.
–> That’s quite a claim since there are no ITU-R standards or 3GPP implementation specs for HAPS or satellite 5G. Current 5G standards and 3GPP specs are for terrestrial wireless coverage.
A SPL stratospheric mast – which for the purposes of the demonstration had been installed on a civilian aircraft – delivered high-speed coverage to a 5G mobile device from an altitude of 14 kilometres to a geographical area of 450 square kilometres.
SPL says their The High Altitude Platform (HAP) will be certified from the outset for safe operations in civil airspace. Some attributes are the following:
- The HAP will have endurance of over a week on station due its lightweight structure and huge power source.
- Designed to be strong enough to fly through the turbulent lower altitudes to reach the more benign environment of the stratosphere, where it will hold-station.
- A wingspan of 60 metres and a large, reliable power source enables a 140kg communications payload.
- Design life of over 10 years with minimal maintenance, repair and overhaul costs
- Extensive use of automation in manufacturing processes will result in a low cost platform.

Source: Stratospheric Platforms
The joint team established three-way video calls between the land-based test site, a mobile device operated from a boat and a control site located 950 km away. Further land and heliborne tests demonstrated a user could stream 4K video to a mobile phone with an average latency of 1 millisecond above network speed. Signal strength trials, using a 5G enabled device moving at 100 km/h, proved full interoperability with ground-based masts and a consistent ‘five bars’ in known white spots.
Richard Deakin, CEO Stratospheric Platforms said, “Stratospheric Platforms has achieved a world-first. This is a momentous event for the global telecoms industry proving that a 5G telecoms mast flying near the top of the earth’s atmosphere can deliver stable broadband 5G internet to serve mobile users with ubiquitous, high-speed internet, over vast areas.”
Deakin added, “The trial has proved that 5G can be reliably beamed down from an airborne antenna and is indistinguishable from ground-based mobile networks. Our hydrogen-powered ‘Stratomast’ High Altitude Platform currently under development, will be able to fly for a week without refuelling and cover an area of 15,000 km2 using one antenna.”
The successful demonstration that a High Altitude Platform can deliver 5G Internet from the stratosphere means that mobile users can look forward to the capability of 5G mobile internet, even in the remotest areas of the world.
CITC Governor, H.E. Dr Mohammed Altamimi commented “the Kingdom of Saudi Arabia is at the cutting edge of technological innovation and our partnership with Stratospheric Platforms’ with the support of the Red Sea Project and General Authority of Civil Aviation (GACA) has demonstrated how we can deliver ‘always on’, ultra-fast broadband to areas without ground based 5G masts.”
……………………………………………………………………………………………………………………………………………………………
Background and Analysis:
SPL was founded in Cambridge in 2014. In 2016, Deutsche Telekom became its biggest single shareholder and launch customer. It came out of hiding in 2020 with a demonstration in Germany of an aerial LTE base station.
Should SPL turn its HAPS vision into a sustainable, commercial reality, it will have succeeded where some much bigger names have failed. Google had a grand vision to offer long range WiFi connectivity from a fleet of balloons. Project Loon launched its first – and what turned out to be only – commercial service in Kenya in 2018. After nine years, Google gave up on Project Loon in 2021. In 2015 Google also dabbled with a drone-based HAPS service called Project Titan, but that came to an end in 2016.
Similarly Facebook attempted to roll out drone-based connectivity under the Aquila brand in 2016, but threw in the towel two years later. Facebook then posted what they believe will be “the next chapter in high altitude connectivity.”
These inauspicious examples don’t seem to have deterred SPL from pursuing HAPS connectivity, and it isn’t the only one trying. This past January, Japan’s NTT announced it is working with its mobile arm DoCoMo, aircraft maker Airbus, and Japanese satcoms provider Sky Perfect JSAT to look into the feasibility of HAPS-based connectivity.
So the momentum is building for HAPS based wireless connectivity but it won’t go mass market till standards emerge.
References:
https://www.stratosphericplatforms.com/
https://www.stratosphericplatforms.com/news/world-first-5g-transmission/
https://www.stratosphericplatforms.com/category/news/
https://telecoms.com/513882/5g-haps-inches-forward-with-saudi-trial/
New partnership targets future global wireless-connectivity services combining satellites and HAPS
Facebook & AT&T to Test Drones for Wireless Communications Capabilities
After 9 years Alphabet pulls the plug on Loon; Another Google X “moonshot” bites the dust!
2Africa subsea cable system adds 4 new branches

2Africa, which will be the largest subsea cable project in the world, will deliver faster, more reliable internet service to each country where it lands. Communities that rely on the internet for services from education to healthcare, and business will experience the economic and social benefits that come from this increased connectivity.

Alcatel Submarine Networks (ASN) has been selected to deploy the new branches, which will increase the number of 2Africa landings to 35 in 26 countries, further improving connectivity into and around Africa. As with other 2Africa cable landings, capacity will be available to service providers at carrier-neutral data centers or open-access cable landing stations on a fair and equitable basis, encouraging and supporting the development of a healthy internet ecosystem.
Marine surveys completed for most of the cable and cable manufacturing is underway. Since launching the 2Africa cable in May 2020, the 2Africa consortium has made considerable progress in planning and preparing for the deployment of the cable, which is expected to ‘go live’ late 2023. Most of the subsea route survey activity is now complete. ASN has started manufacturing the cable and building repeater units in its factories in Calais and Greenwich to deploy the first segments in 2022.
Egypt terrestrial crossing already completed
One of 2Africa’s key segments, the Egypt terrestrial crossing that interconnects landing sites on the Red and the Mediterranean Seas via two completely diverse terrestrial routes, has been completed ahead of schedule. A third diverse marine path will complement this segment via the Red Sea.
About MTN GlobalConnect
GlobalConnect is a Pan-African digital wholesale and infrastructure services company, and an operating company in the MTN Group. GlobalConnect manages MTN’s international and national major wholesale activities, in addition to offering reliable wholesale and infrastructure solutions for fixed connectivity and wholesale mobility solutions that include international mobile services, Voice, SMS, signalling, roaming and interconnect. The MTN Group launched in 1994 is a leading emerging market operator with a clear vision to lead the delivery of a bold new digital world and is inspired by the belief that everyone deserves the benefits of a modern connected life. Embracing the Ambition 2025 strategy, MTN is anchored on building the largest and most valuable platform business, with a clear focus on Africa. The MTN Group is listed on the JSE Securities Exchange in South Africa under the share code “MTN”.
For more information, please visit www.globalconnect.solutions – https://www.mtn.com
About stc
With its headquarter in Riyadh, stc group is the largest in the Middle East and North Africa based on market cap. stc’s revenue for 2020 amounted to 58,953million SAR (15,721 million US dollars) and the net profit amounted to 10,995 million SAR (2,932 million US dollars). stc was established in 1998 and currently has customers around the globe. It is ranking among the world’s top 50 digital companies and the first in the Middle East and North Africa according to Forbes. It focuses on providing services to enterprise and consumer customers through a fiber-optic network that spans 217,000 kilometers. stc group was among the first in MENA region to launch 5G networks and was considered one of the fastest globally in deploying 5G network as stc already deployed around 4,000 5G towers as end of 2020. stc group has 14 subsidiaries in the Kingdom, gulf and around the world, and its own 100% of stc Bahrain, 51.8% stake in stc Kuwait and 25% stake in Binariang GSM Holding in Malaysia which owns 62% of Maxis in Malaysia.
In Saudi Arabia (the group’s main operation site) stc operates the largest modern mobile network in the Middle East as it covers more than 99% of the country’s populated areas in addition to providing 4G mobile broadband to about 90% of the population across the Kingdom of Saudi Arabia. In addition to the above-mentioned, stc is a strong regional player in IoT, managed services, system integration, cloud computing, information security, big data Analytics fintech and artificial intelligence.
For more information, please visit https://www.stc.com.sa; or to follow us on Twitter: @stc , @stc_ksa
About Telecom Egypt
Telecom Egypt is the first total telecom operator in Egypt providing all telecom services to its customers including fixed and mobile voice and data services. Telecom Egypt has a long history serving Egyptian customers for over 160 years maintaining a leadership position in the Egyptian telecom market by offering its enterprise and consumer customers the most advanced technology, reliable infrastructure solutions and the widest network of submarine cables. Aside from its mobile operation “WE”, the company owns a 45% stake in Vodafone Egypt. Telecom Egypt’s shares and GDRs (Ticker: ETEL.CA; TEEG.LN) are traded on The Egyptian Exchange and the London Stock Exchange. Please refer to Telecom Egypt’s full financial disclosure on ir.te.eg
For more information, email: [email protected]
…………………………………………………………………………………………
References:
https://www.orange.com/en/newsroom/press-releases/2021/new-branches-2africa-subsea-cable-system
Broadcom, Cisco and Facebook Launch TIP Group for open source software on 6 GHz Wi-Fi
The purpose of this new TIP project group is to develop a common reference open source software for an AFC system. The AFC will be used by unlicensed devices in the newly available 6 GHz band to operate outdoor and increased range indoor while ensuring incumbent services are protected.
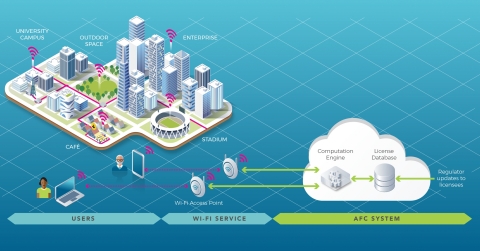
The US, EU, Canada, and Brazil, among others, have approved or are finalizing the approval of 6 GHz unlicensed spectrum use, opening up a huge bandwidth for Wi-Fi services.
By 2025, the Wi-Fi Alliance estimates that the 6 GHz Wi-Fi will deliver USD 527.5 billion in incremental economic benefits to the global economy [1]. Standard outdoor power operations will be a key part of the value proposition of 6 GHz Wi-Fi and is critical for enabling more affordable wireless broadband for consumer access.
The FCC is the first regulator to enable its use under an AFC, ISED Canada authorized standard power with AFC in May 2021, with others expected to follow. The AFC will enhance Wi-Fi to provide a consistent wireless broadband user experience in stadiums, homes, enterprises, schools, and hospitals.
“The 6 GHz Wi-Fi momentum is unmistakable. In the year following the historic FCC ruling to open up the band for unlicensed access, we already have an entire ecosystem of Wi-Fi 6E devices delivering gigabit speeds indoors. As we work towards closing the digital divide and further realizing the value of the 6 GHz band, AFC-enabled standard power Wi-Fi operation becomes critical. As Wi-Fi 7 comes along, AFC will turbocharge the user experience by enabling over 60 times more power for reliable, low latency, and multi-gigabit wireless broadband both indoors and outdoors. With this vision in mind, Broadcom is excited to join hands with Cisco and Facebook to create the TIP Open AFC Software Group aimed at enabling a cost effective and scalable AFC system,” said Vijay Nagarajan, Vice President of Marketing, Wireless Communications & Connectivity Division, Broadcom.
“The creation of the TIP Open AFC Software Group represents the immense momentum behind unlicensed spectrum and the potential it holds to deliver innovation,” said Rakesh Thaker, VP of Wireless Engineering, Cisco. “Many of the applications and use cases we’re just beginning to dream up with the introduction of Wi-Fi 6 and the 6 GHz spectrum will rely on standard power, greater range and reliability. This software group will play an important role in ensuring those applications can become reality, while also protecting important incumbent services. We’re thrilled to join Broadcom and Facebook on this effort, and to share a vision with TIP of providing high-quality, reliable connectivity for all.”
Facebook developed a proof of concept Open AFC system, which will protect 6 GHz incumbent operations and enable faster adoption of standard power operations in the 6 GHz band. This prototype system will be contributed to the TIP community through today’s launch of the Open AFC Software Group, with the goal of enabling the proliferation of standard power devices in the United States to start, with other markets to follow.
Broadcom and Cisco have committed to driving the industry forward in developing Open AFC to ensure that the code continues to be developed to meet the needs of the industry and regulators, such that an AFC operator could take the code and build upon it for rapid certification.
The vast majority of Wi-Fi use is indoors, but there are situations where people will want to use Wi-Fi outdoors. The use of AFC provides the flexibility for outdoor deployments in open air stadiums and similar venues.
“Bringing AFC technology to the TIP Open AFC Software Group is a huge milestone for the unlicensed spectrum community,” said Dan Rabinovitsj, vice president for Facebook Connectivity. “We are excited to see the contributions and innovations by Open AFC and we look forward to celebrating the widespread adoption of the 6 GHz band, which will rapidly accelerate the performance and bandwidth of Wi-Fi networks around the world”.
David Hutton, Chief Engineer of TIP, said: “The industry is coming together to support 6 GHz for unlicensed use for Wi-Fi and TIP will be providing the forum to contribute to make this happen, supporting regulatory efforts by ensuring that AFC systems are developed under a common code base that is available to all industry stakeholders.”
Closing Comment:
We wonder why this new WiFi 6GHz group is in TIP rather than the WiFi Alliance. From the WiFi Alliance Certified 6:
“Wi-Fi Alliance is leading the development of specifications and test plans that can help ensure that standard power Wi-Fi devices operate in 6 GHz spectrum under favorable conditions, avoiding interference with incumbent devices.”
In this author’s opinion, there are way too many alliances/ fora/ consortiums that produce specifications that are to be used with existing standards. In this case (IEEE 802.11ax) there is potential overlap amongst amongst groups, which leads to inconsistent implementations that inhibit interoperability.
References:
Echo and Bifrost: Facebook’s new subsea cables between Asia-Pacific and North America
Facebook has revealed plans to build two new subsea cables between the Asia-Pacific region and North America, called Echo and Bifrost. The social media giant also revealed partnerships with Google as well as Asian telecoms operators for the project.
Although these projects are still subject to regulatory approvals, when completed, these cables will deliver much-needed internet capacity, redundancy, and reliability. The transpacific cables will follow a “new diverse route crossing the Java Sea, connecting Singapore, Indonesia, and North America,” and are expected to increase overall transpacific capacity by 70%.
Facebook says Echo and Bifrost will support further growth for hundreds of millions of people and millions of businesses. Facebook said that economies flourish when there is widely accessible internet for people and businesses.
Echo and Bifrost be the first transpacific cables through a new diverse route crossing the Java Sea. Connecting Singapore, Indonesia, and North America, these cable investments reflect Facebook’s commitment to openness and our innovative partnership model. The social media company works with a variety of leading Indonesian and global partners to ensure that everyone benefits from developing scale infrastructure and shared technology expertise.
Facebook will work with partners such as Indonesian companies Telin and XL Axiata and Singapore-based Keppel on these projects.
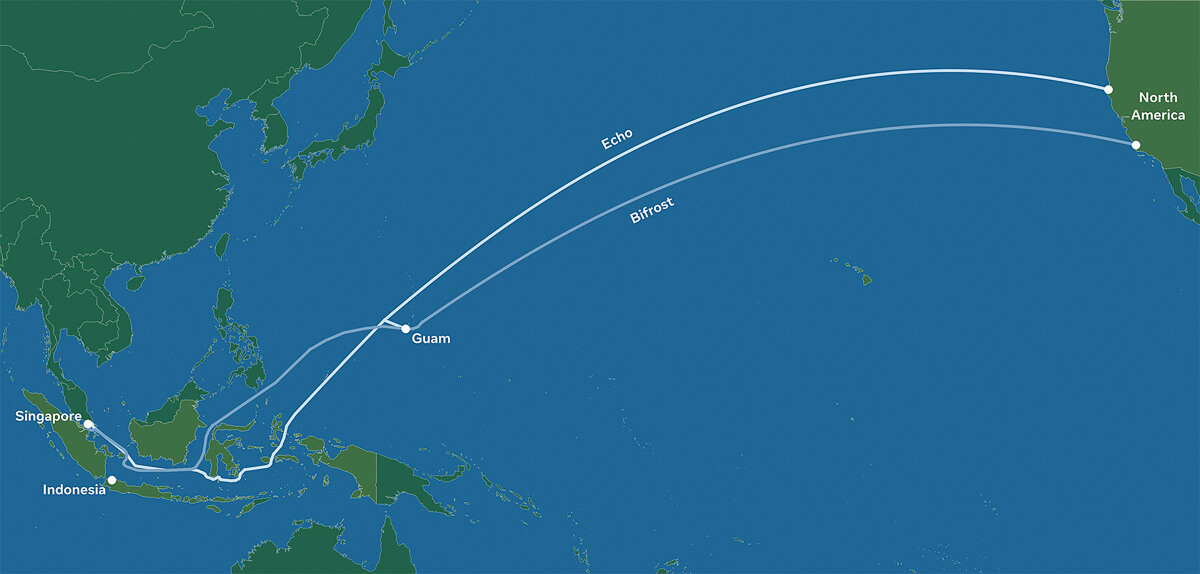
Image Credit: Facebook
………………………………………………………………………………………………..
Kevin Salvadori, VP of network investments at Facebook, provided further details in an interview with Reuters. He said Echo is being built in partnership with Alphabet’s Google and XL Axiata. It should be completed by 2023. Bifrost partners include Telin, a subsidiary of Indonesia’s Telkom, and Keppel. It is due to be completed by 2024.
Aside from the Southeast Asian cables, Facebook was continuing with its broader subsea plans in Asia and globally, including with the Pacific Light Cable Network (PLCN), Salvadori said.
“We are working with partners and regulators to meet all of the concerns that people have, and we look forward to that cable being a valuable, productive transpacific cable going forward in the near future,” he said.
Indonesia
Facebook noted that Echo and Bifrost will complement the subsea cables serving Indonesia today. These investments present an opportunity to enhance connectivity in the Central and Eastern Indonesian provinces, providing greater capacity and improved reliability for Indonesia’s international data information infrastructure. Echo and Bifrost complement the subsea cables serving Indonesia today, increasing service quality and supporting the country’s connectivity demands.
This is all part of Facebook’s continued effort to collaborate with partners in Indonesia to expand access to broadband internet and lower the cost of connectivity. Facebook has partnered with Alita, an Indonesian telecom network provider, to deploy 3,000 kilometers (1,8641 miles) of metro fiber in 20 cities in Bali, Java, Kalimantan, and Sulawesi. In addition, we are improving connectivity by expanding Wi-Fi with Express Wi-Fi.
While 73% of Indonesia’s population of 270 million are online, the majority access the web through mobile data, with less than 10 percent using a broadband connection, according to a 2020 survey by the Indonesian Internet Providers Association. Swathes of the country, remain without any internet access.
Singapore
In Singapore, Echo and Bifrost are expected to provide extra subsea capacity to complement the APG and SJC-2 subsea cables. Building on Facebook’s previously announced Singapore data center investments, Echo and Bifrost will provide important diverse subsea capacity to power Singapore’s digital growth and connectivity hub. Singapore is also home to many of Facebook’s regional teams.
The Asia-Pacific region is very important to Facebook. In order to bring more people online to a faster internet, these new projects add to Facebook’s foundational regional investments in infrastructure and partnerships to improve connectivity to help close the digital divide and strengthen economies.
……………………………………………………………………………………………………………………………………
References:
Advancing connectivity between the Asia-Pacific region and North America
https://www.reuters.com/article/us-facebook-internet-southeastasia-idUSKBN2BL0CH
DoJ: Google to operate undersea cable connecting U.S. and Asia
The U.S. Department of Justice announced Wednesday that it has approved Google’s request to use part of an undersea cable connecting the US and Asia via Taiwan. Google agreed to operate a portion of the 8,000-mile Pacific Light Cable Network System between the US and Taiwan, while avoiding the leg of the system extending to Hong Kong.
Google and Facebook helped pay for construction of the now completed undersea cable, along with a Chinese real estate investor. U.S. regulators had previously expressed national security concerns about the Chinese investor, Beijing-based Dr. Peng Telecom & Media Group Co.

Google, Facebook and telecom and undersea infrastructure developer TE SubCom and PLDC (Pacific Light Data Communication Co. Ltd.) are teaming up to build a 120 Terabits per second (Tbps), 12,800 km subsea cable that will connect Los Angeles with Taiwan, but exclude Hong Kong.
…………………………………………………………………………………………………..
The DoJ granted a six-month authorization for using the cable after Google emphasized “an immediate need to meet internal demand for capacity between the US and Taiwan” and that without the requested temporary authority, it would likely have to seek alternative capacity at “significantly higher prices.”
After discussions with Google representatives, the DoJ concluded that the obligations undertaken by Google would be sufficient to preserve their abilities to enforce the law and protect national security. Under the terms of the security agreement, Google has agreed to a range of operational requirements, notice obligations, access and security guarantees, as well as auditing and reporting duties, among others.
Google also committed to pursuing “diversification of interconnection points in Asia,” as well as to establish network facilities that deliver traffic as close as practicable to its ultimate destination. This reflects the views of the US government that a direct cable connection between the US and Hong Kong “would pose an unacceptable risk to the national security and law enforcement interests of the United States”, the DoJ said.
More information concerning the license application and the US Justice Departments’ response is available here.
……………………………………………………………………………………………………………………………………………………….
The U.S. government decision to exclude Hong Kong (see Update below) from a trans-Pacific cable was “severe blow” to the city as a telecom hub, a key industry figure said Thursday.
The DOJ said “a direct connection between the U.S. and Hong Kong would pose an unacceptable risk” to national security and law enforcement interests.
Charles Mok, the IT industry representative in the Hong Kong Legislative Council, said the decision was “not a surprise.”
It had been public knowledge for at least six months that the FCC held such views about Hong Kong and was delaying approval of the cable.
More than a month ago, Facebook and Google had amended their applications, excluding Hong Kong and terminating the cable in Taiwan, Mok pointed out.
“It is a severe blow to Hong Kong’s status as a hub for telecommunications and underseas cable in the region,” he said.
“The obvious reasons – behind what the US claims to be concerns over their national interest – must be the widely perceived deterioration of Hong Kong’s One Country Two Systems, rule of law, freedom of information and the media, and the increasing interference from China.
June 18, 2020 Update:
In a press release Wednesday, “Team Telecom” recommended the FCC deny an application to connect the Pacific Light Cable Network (PLCN) subsea cable system between the US and Hong Kong.
FCC commissioners appear poised to accept the recommendation. “I’ll reserve judgment for now, but the detailed filing raises major questions about state influence over Chinese telecoms. In this interconnected world, network security must be paramount,” tweeted Democratic FCC Commissioner Geoffrey Starks.
Team Telecom – officially the Committee for the Assessment of Foreign Participation in the United States Telecommunications Services Sector – is an organization created by President Trump in April. It’s chaired by Trump’s attorney general and includes his secretaries of Homeland Security and Defense. As the Department of Justice explained, Team Telecom formalizes a process that has existed for years, but which will “benefit from a transparent and empowered structure.”
References:
https://www.wsj.com/articles/u-s-allows-google-internet-project-to-advance-only-if-hong-kong-is-cut-out-11586377674 (on-line subscription required)
Will Hyperscale Cloud Companies (e.g. Google) Control the Internet’s Backbone?
Rob Powell reports that Google’s submarine cable empire now hooks up another corner of the world. The company’s 10,000km Curie submarine cable has officially come ashore in Valparaiso, Chile.
The Curie cable system now connects Chile with southern California. it’s a four-fiber-pair system that will add big bandwidth along the western coast of the Americas to Google’s inventory. Also part of the plans is a branching unit with potential connectivity to Panama at about the halfway point where they can potentially hook up to systems in the Caribbean.
Subcom’s CS Durable brought the cable ashore on the beach of Las Torpederas, about 100 km from Santiago. In Los Angeles the cable terminates at Equinix’s LA4 facility, while in Chile the company is using its own recently built data center in Quilicura, just outside of Santiago.
Google has a variety of other projects going on around the world as well, as the company continues to invest in its infrastructure. Google’s projects tend to happen quickly, as they don’t need to spend time finding investors to back their plans.

Curie is one of three submarine cable network projects Google unveiled in January 2018. (Source: Google)
……………………………………………………………………………………………………………………………………………………………………………………..
Powell also wrote that SoftBank’s HAPSMobile is investing $125M in Google’s Loon as the two partner for a common platform, and Loon gains an option to invest a similar sum in HAPSMobile later on.
Both companies envision automatic, unmanned, solar-powered devices in the sky above the range of commercial aircraft but not way up in orbit. From there they can reach places that fiber and towers don’t or can’t. HAPSMobile uses drones, and Loon uses balloons. The idea is to develop a ‘common gateway or ground station’ and the necessary automation to support both technologies.
It’s a natural partnership in some ways, and the two are putting real money behind it. But despite the high profile we haven’t really seen mobile operators chomping at the bit, since after all it’s more fun to cherry pick those tower-covered urban centers for 5G first and there’s plenty of work to do. And when they do get around to it, there’s the multiple near-earth-orbit satellite projects going on to compete with.
But the benefit both HAPSMobile and Loon have to their model is that they can, you know, reach it without rockets.
…………………………………………………………………………………………………………
AWS’s Backbone (explained by Sapphire):
An AWS Region is a particular geographic area where Amazon decided to deploy several data centers, just like that. The reason behind a chosen area is to be close to the users and also to have no restrictions. At the same time, every Region is also connected through private links with other Regions which means they have a dedicated link for their communications because for them is cheaper and they also have full capacity planing with lower latency.
What is inside a Region?
- Minimum 2 Availability Zones
- Separate transit centers (peering the connections out of the World)
How transit centers work?
AWS has private links to other AWS regions, but they also have private links for the feature AWS Direct Connect – a dedicated and private & encrypted (IPSEC tunnel) connection from the “xyz” company’s datacenters to their infrastructures in the Cloud, which works with the VLANs inside (IEEE 802.1Q) for accessing public and private resources with a lower latency like Glacier or S3 buckets and their VPC at the same time between <2ms and usually <1ms latency. Between Availability Zones (inter AZ zone) the data transit there’s a 25TB/sec average.
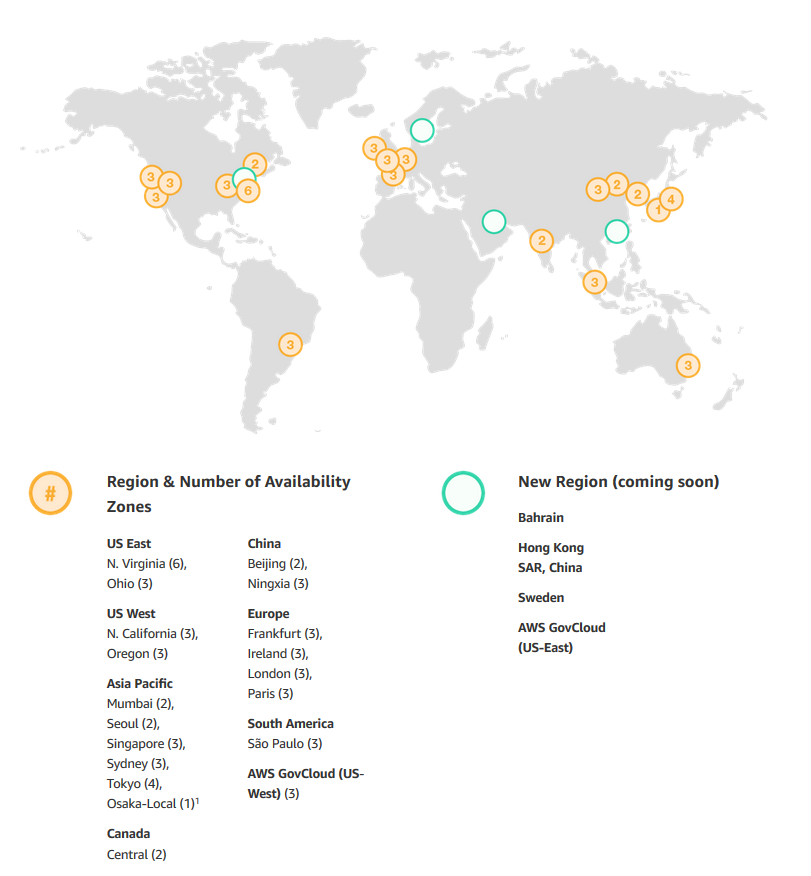
From AWS Multiple Region Multi-VPC Connectivity:
AWS Regions are connected to multiple Internet Service Providers (ISPs) as well as to Amazon’s private global network backbone, which provides lower cost and more consistent cross-region network latency when compared with the public internet. Here is one illustrative example:

,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
From Facebook Building backbone network infrastructure:
We have strengthened the long-haul fiber networks that connect our data centers to one another and to the rest of the world.
As we bring more data centers online, we will continue to partner and invest in core backbone network infrastructure. We take a pragmatic approach to investing in network infrastructure and utilize whatever method is most efficient for the task at hand. Those options include leveraging long-established partnerships to access existing fiber-optic cable infrastructure; partnering on mutually beneficial investments in new infrastructure; or, in situations where we have a specific need, leading the investment in new fiber-optic cable routes.
In particular, we invest in new fiber routes that provide much-needed resiliency and scale. As a continuation of our previous investments, we are building two new routes that exemplify this approach. We will be investing in new long-haul fiber to allow direct connectivity between our data centers in Ohio, Virginia, and North Carolina.
As with our previous builds, these new long-haul fiber routes will help us continue to provide fast, efficient access to the people using our products and services. We intend to allow third parties — including local and regional providers — to purchase excess capacity on our fiber. This capacity could provide additional network infrastructure to existing and emerging providers, helping them extend service to many parts of the country, and particularly in underserved rural areas near our long-haul fiber builds.
………………………………………………………………………………………………….
Venture Beat Assessment of what it all means:
Google’s increasing investment in submarine cables fits into a broader trend of major technology companies investing in the infrastructure their services rely on.
Besides all the datacenters Amazon, Microsoft, and Google are investing in as part of their respective cloud services, we’ve seen Google plow cash into countless side projects, such as broadband infrastrucure in Africa and public Wi-Fi hotspots across Asia.
Elsewhere, Facebook — while not in the cloud services business itself — requires omnipresent internet connectivity to ensure access for its billions of users. The social network behemoth is also investing in numerous satellite internet projectsand had worked on an autonomous solar-powered drone project that was later canned. Earlier this year, Facebook revealed it was working with Viasat to deploy high-speed satellite-powered internet in rural areas of Mexico.
While satellites will likely play a pivotal role in powering internet in the future — particularly in hard-to-reach places — physical cables laid across ocean floors are capable of far more capacity and lower latency. This is vital for Facebook, as it continues to embrace live video and virtual reality. In addition to its subsea investments with Google, Facebook has also partnered with Microsoft for a 4,000-mile transatlantic internet cable, with Amazon and SoftBank for a 14,000 km transpacific cable connecting Asia with North America, and on myriad othercable investments around the world.
Needless to say, Google’s services — ranging from cloud computing and video-streaming to email and countless enterprise offerings — also depend on reliable infrastructure, for which subsea cables are key.
Curie’s completion this week represents not only a landmark moment for Google, but for the internet as a whole. There are currently more than 400 undersea cables in service around the world, constituting 1.1 million kilometers (700,000 miles). Google is now directly invested in around 100,000 kilometers of these cables (62,000 miles), which equates to nearly 10% of all subsea cables globally.
The full implications of “big tech” owning the internet’s backbone have yet to be realized, but as evidenced by their investments over the past few years, these companies’ grasp will only tighten going forward.
Facebook’s F16 achieves 400G effective intra DC speeds using 100GE fabric switches and 100G optics, Other Hyperscalers?
On March 14th at the 2019 OCP Summit, Omar Baldonado of Facebook (FB) announced a next-generation intra -data center (DC) fabric/topology called the F16. It has 4x the capacity of their previous DC fabric design using the same Ethernet switch ASIC and 100GE optics. FB engineers developed the F16 using mature, readily available 100G 100G CWDM4-OCP optics (contributed by FB to OCP in early 2017), which in essence gives their data centers the same desired 4x aggregate capacity increase as 400G optical link speeds, but using 100G optics and 100GE switching.
F16 is based on the same Broadcom ASIC that was the candidate for a 4x-faster 400G fabric design – Tomahawk 3 (TH3). But FB uses it differently: Instead of four multichip-based planes with 400G link speeds (radix-32 building blocks), FB uses the Broadcom TH3 ASIC to create 16 single-chip-based planes with 100G link speeds (optimal radix-128 blocks). Note that 400G optical components are not easy to buy inexpensively at Facebook’s large volumes. 400G ASICs and optics would also consume a lot more power, and power is a precious resource within any data center building. Therefore, FB built the F16 fabric out of 16 128-port 100G switches, achieving the same bandwidth as four 128-port 400G switches would.
Below are some of the primary features of the F16 (also see two illustrations below):
-Each rack is connected to 16 separate planes. With FB Wedge 100S as the top-of-rack (TOR) switch, there is 1.6T uplink bandwidth capacity and 1.6T down to the servers.
-The planes above the rack comprise sixteen 128-port 100G fabric switches (as opposed to four 128-port 400G fabric switches).
-As a new uniform building block for all infrastructure tiers of fabric, FB created a 128-port 100G fabric switch, called Minipack – a flexible, single ASIC design that uses half the power and half the space of Backpack.
-Furthermore, a single-chip system allows for easier management and operations.
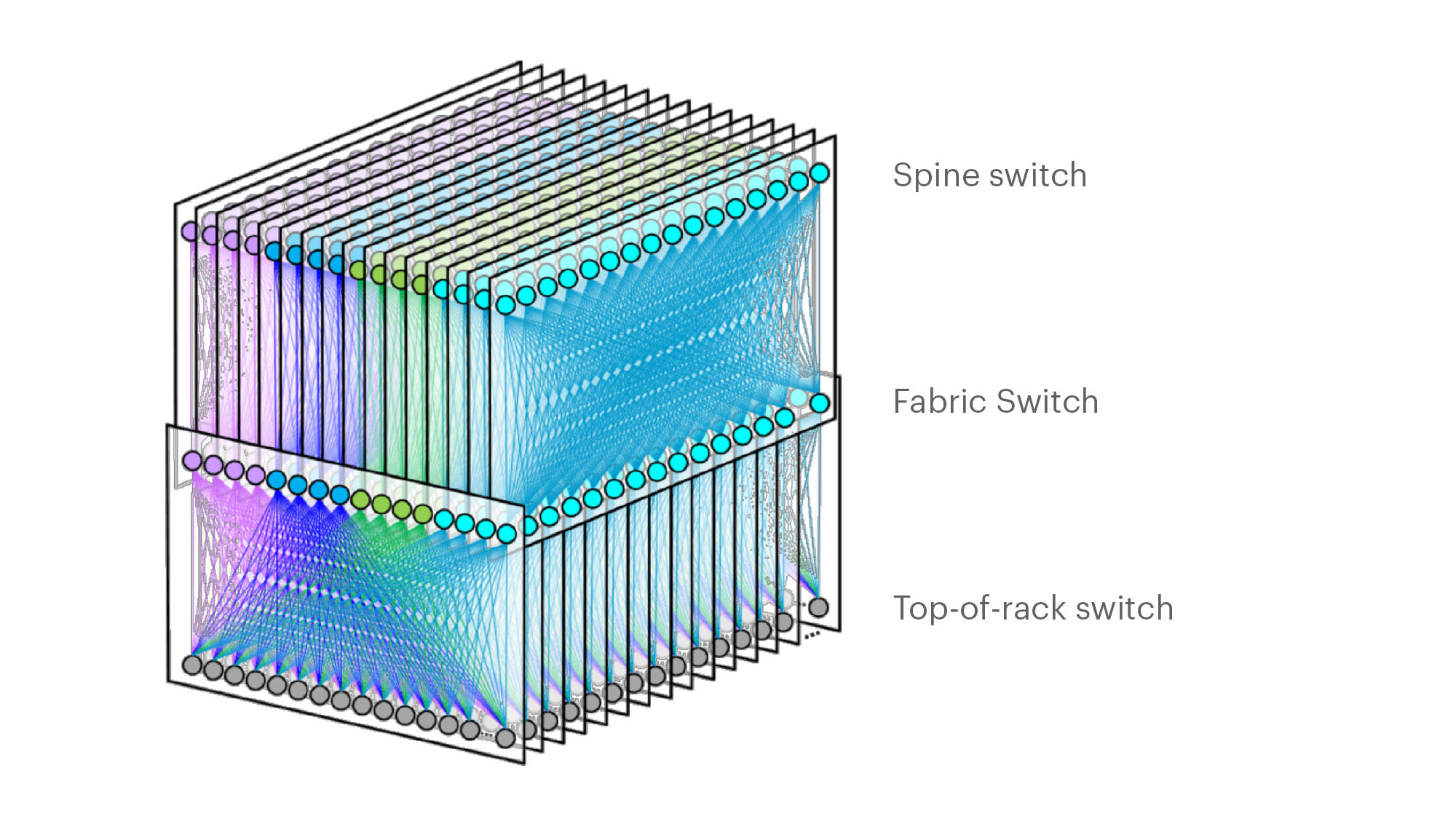 Facebook F16 data center network topology
Facebook F16 data center network topology
………………………………………………………………………………………………………………………………………………………………………………………………..
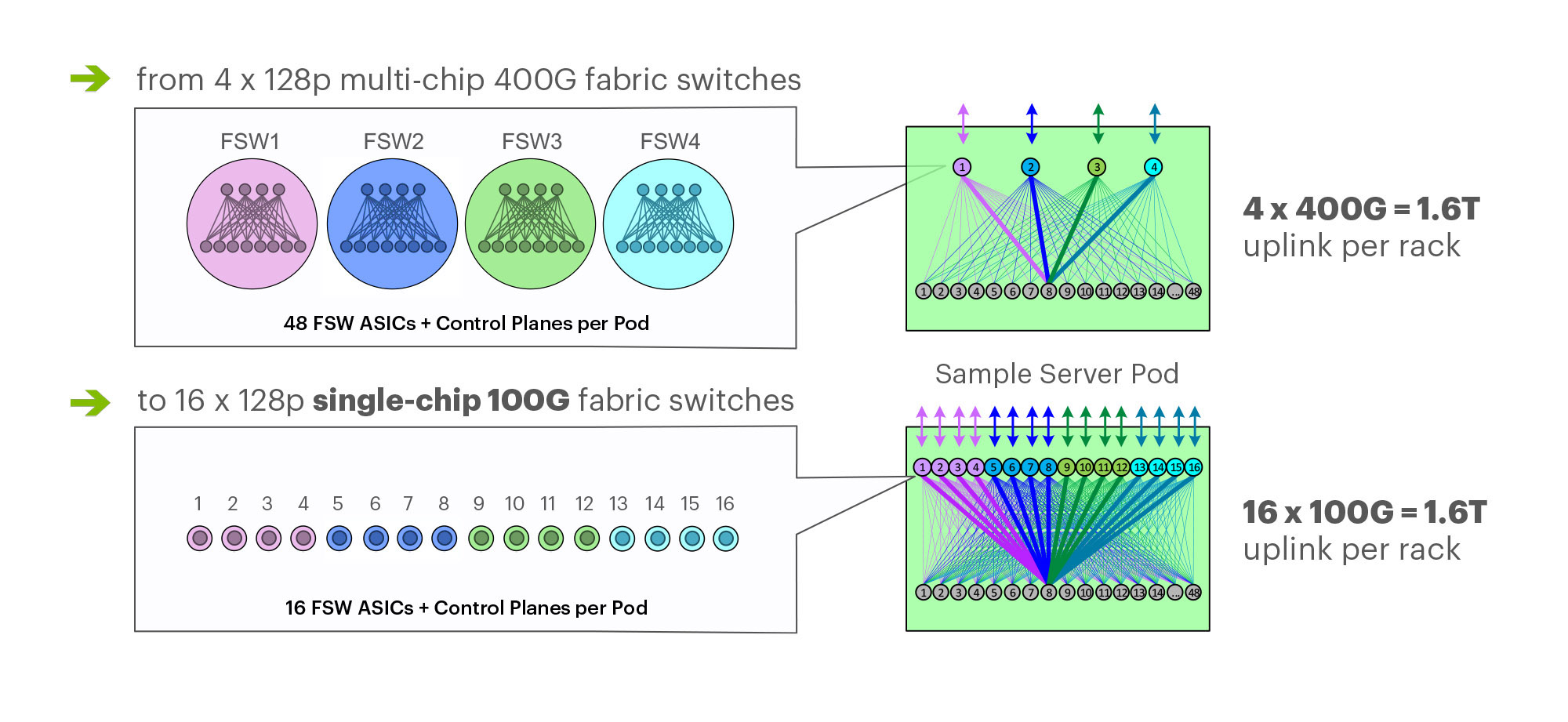
Multichip 400G b/sec pod fabric switch topology vs. FBs single chip (Broadcom ASIC) F16 at 100G b/sec
…………………………………………………………………………………………………………………………………………………………………………………………………..
In addition to Minipack (built by Edgecore Networks), FB also jointly developed Arista Networks’ 7368X4 switch. FB is contributing both Minipack and the Arista 7368X4 to OCP. Both switches run FBOSS – the software that binds together all FB data centers. Of course the Arista 7368X4 will also run that company’s EOS network operating system.
F16 was said to be more scalable and simpler to operate and evolve, so FB says their DCs are better equipped to handle increased intra-DC throughput for the next few years, the company said in a blog post. “We deploy early and often,” Baldonado said during his OCP 2019 session (video below). “The FB teams came together to rethink the DC network, hardware and software. The components of the new DC are F16 and HGRID as the network topology, Minipak as the new modular switch, and FBOSS software which unifies them.”
This author was very impressed with Baldonado’s presentation- excellent content and flawless delivery of the information with insights and motivation for FBs DC design methodology and testing!
References:
https://code.fb.com/data-center-engineering/f16-minipack/
………………………………………………………………………………………………………………………………….
Other Hyperscale Cloud Providers move to 400GE in their DCs?
Large hyperscale cloud providers initially championed 400 Gigabit Ethernet because of their endless thirst for networking bandwidth. Like so many other technologies that start at the highest end with the most demanding customers, the technology will eventually find its way into regular enterprise data centers. However, we’ve not seen any public announcement that it’s been deployed yet, despite its potential and promise!
Some large changes in IT and OT are driving the need to consider 400 GbE infrastructure:
- Servers are more packed in than ever. Whether it is hyper-converged, blade, modular or even just dense rack servers, the density is increasing. And every server features dual 10 Gb network interface cards or even 25 Gb.
- Network storage is moving away from Fibre Channel and toward Ethernet, increasing the demand for high-bandwidth Ethernet capabilities.
- The increase in private cloud applications and virtual desktop infrastructure puts additional demands on networks as more compute is happening at the server level instead of at the distributed endpoints.
- IoT and massive data accumulation at the edge are increasing bandwidth requirements for the network.
400 GbE can be split via a multiplexer into smaller increments with the most popular options being 2 x 200 Gb, 4 x 100 Gb or 8 x 50 Gb. At the aggregation layer, these new higher-speed connections begin to increase in bandwidth per port, we will see a reduction in port density and more simplified cabling requirements.
Yet despite these advantages, none of the U.S. based hyperscalers have announced they have deployed 400GE within their DC networks as a backbone or to connect leaf-spine fabrics. We suspect they all are using 400G for Data Center Interconnect, but don’t know what optics are used or if it’s Ethernet or OTN framing and OAM.
…………………………………………………………………………………………………………………………………………………………………….
In February, Google said it plans to spend $13 billion in 2019 to expand its data center and office footprint in the U.S. The investments include expanding the company’s presence in 14 states. The dollar figure surpasses the $9 billion the company spent on such facilities in the U.S. last year.
In the blog post, CEO Sundar Pichai wrote that Google will build new data centers or expand existing facilities in Nebraska, Nevada, Ohio, Oklahoma, South Carolina, Tennessee, Texas, and Virginia. The company will establish or expand offices in California (the Westside Pavillion and the Spruce Goose Hangar), Chicago, Massachusetts, New York (the Google Hudson Square campus), Texas, Virginia, Washington, and Wisconsin. Pichai predicts the activity will create more than 10,000 new construction jobs in Nebraska, Nevada, Ohio, Texas, Oklahoma, South Carolina, and Virginia. The expansion plans will put Google facilities in 24 states, including data centers in 13 communities. Yet there is no mention of what data networking technology or speed the company will use in its expanded DCs.
I believe Google is still designing all their own IT hardware (compute servers, storage equipment, switch/routers, Data Center Interconnect gear other than the PHY layer transponders). They announced design of many AI processor chips that presumably go into their IT equipment which they use internally but don’t sell to anyone else. So they don’t appear to be using any OCP specified open source hardware. That’s in harmony with Amazon AWS, but in contrast to Microsoft Azure which actively participates in OCP with its open sourced SONIC now running on over 68 different hardware platforms.
It’s no secret that Google has built its own Internet infrastructure since 2004 from commodity components, resulting in nimble, software-defined data centers. The resulting hierarchical mesh design is standard across all its data centers. The hardware is dominated by Google-designed custom servers and Jupiter, the switch Google introduced in 2012. With its economies of scale, Google contracts directly with manufactures to get the best deals.Google’s servers and networking software run a hardened version of the Linux open source operating system. Individual programs have been written in-house.
