

Analysis: Nvidia’s rumored new 6G AI-RAN – likely features/functions and industry impact
Executive Summary:
According to Light Reading, Nvidia is working on a GPU combo chip that would sit directly in the 6G radio unit [1.], extending its AI-RAN push from baseband/server into the radio itself. It’s reported to be a more hardware-integrated, sub-100W embedded design rather than just GPU acceleration in centralized RAN compute.
Note 1. 6G/IMT 2030 Radio Interface Technologies (RITs) have yet to be defined, let alone specified by 3GPP or ITU-R WP5D. They won’t be solidified until the end of 2030 so any specific silicon design won’t be completed until then or 2031!
……………………………………………………………………………………………………………………………………………………….
Light Reading’s headline frames it as a “radical new AI-RAN plan and they wrote that “the move was confirmed by knowledgeable sources, with Nvidia saying GPUs in more advanced radios will become “essential” in future. It marks a dramatic new development in the GPU giant’s “AI-RAN” strategy.”
If accurate, this would be a notable shift for Nvidia, because it would let them influence the whole RAN stack, not just centralized compute. That could matter for performance, power efficiency, and AI-native functions such as sensing, spectrum optimization, and real-time signal processing. Nvidia’s broader 6G messaging already emphasizes AI-native wireless, integrated sensing and communications, and spectrum agility as core themes.
The unconfirmed report fits Nvidia’s existing telecom roadmap rather than appearing out of nowhere. Nvidia has already announced an AI-native wireless stack for 6G with partners including Cisco, MITRE, Booz Allen, ODC, and T-Mobile, and it has promoted AI-RAN as a way to combine connectivity, computing, and sensing on one platform. It also aligns with the company’s recent partnership with Nokia, where Nvidia introduced the ARC-Pro 6G-ready accelerated computing platform and described it as a software-upgradable path from 5G-Advanced to 6G. That makes the rumored radio-chip move look like a vertical extension of the same strategy.
For wireless network operators, a radio-unit chip from Nvidia would be significant only if it improves cost, power, or flexibility versus incumbent RU silicon. The practical test will be whether it can deliver enough RF, baseband, and AI function integration to justify another architecture layer at the edge. It would also intensify competition in the radio-access supply chain and reinforce the trend toward AI-native, software-defined RANs. It also suggests Nvidia wants to shape not only the compute layer but the physical radio layer of 6G networks.
Possible AI Silicon Features and Functions:
Nvidia would most likely add AI-for-RAN features into radio silicon first, because those map directly to signal processing and link adaptation rather than to generic “AI at the edge.” Nvidia’s own AI-RAN materials emphasize embedding AI/ML into the radio signal-processing layer to improve spectral efficiency, coverage, capacity, and performance. Here are a few likely AI features/functions for the rumored 6G AI Nvidia super chip:
-
Neural channel estimation and equalization, to infer cleaner channel state from noisy RF observations and improve link reliability. Nvidia’s open-source Aerial release specifically calls out advanced neural models for channel estimation.
-
Real-time beam management, including beam selection, beam tracking, and beam refinement for massive MIMO and mmWave/upper-midband deployments. These are natural AI-RAN use cases because they depend on fast adaptation to changing propagation conditions.
-
Spectrum agility and interference mitigation, such as identifying jammed or congested resource blocks and dynamically avoiding them. NVIDIA and partners have already described spectrum agility applications that freeze only affected frequencies while keeping the rest of the system online.
-
Dynamic resource scheduling, using learned traffic and channel patterns to allocate PRBs, power, and compute more efficiently in real time. Nvidia describes AI-RAN as improving spectral efficiency and dynamic traffic handling through AI.
-
Integrated sensing and communications support, where the radio helps detect objects, motion, or environmental context in parallel with communication. Nvidia has already highlighted ISAC-style applications with camera/RF fusion and object tracking.
-
Edge inference hooks, letting the RU expose real-time PHY data to AI applications or a dApp-style framework. Nvidia’s open-source Aerial stack says third-party apps can access physical-layer data through secure APIs and modify RAN behavior in real time.
-
Self-optimization and closed-loop control, where the radio silicon learns local conditions and continuously retunes thresholds, coding, MCS selection, and precoding policies. That fits Nvidia’s broader framing of AI-native networks as software-defined and continuously adaptable.
The most plausible first wave is not a fully autonomous “AI radio,” but a hybrid RU chip that accelerates selected PHY functions and exposes telemetry/data paths to the rest of the AI-RAN stack. Nvidia’s current messaging emphasizes software-defined infrastructure, deterministic performance, and layered AI-RAN capabilities rather than replacing the entire RAN with a black-box model.
The real differentiator would be whether Nvidia can combine RF signal processing with its GPU/CUDA ecosystem, so the same platform handles channel learning, inference, and orchestration across RU/DU/CU tiers. That would let operators optimize for spectral efficiency and OPEX while still keeping a software-upgrade path to 6G. Radio electronics is constrained by power, latency, determinism, and certification, so Nvidia would need to prove these AI features help without destabilizing PHY timing. That is why the likely starting point is assistive AI inside the signal chain, not a fully learned end-to-end radio.

Image Credit: Nvidia
…………………………………………………………………………………………………………………………………………………………………………………………………………..
Competitive Analysis:
Nvidia’s reported move into a 6G radio-unit chip is most threatening to Marvell and Qualcomm at the silicon layer, while it is more of a strategic architecture challenge to Nokia and Ericsson at the system level. The immediate effect is less about a single chip and more about Nvidia trying to pull compute, connectivity, and AI deeper into the RAN value chain
Qualcomm is the closest direct competitor if Nvidia is trying to put silicon into the radio or near-radio layer. Qualcomm already has a Layer 1 strategy that combines silicon and software in SmartNIC/server-adjacent form factors, so Nvidia would be moving into a space where Qualcomm has both telecom credibility and established IP.
The risk for Qualcomm is that Nvidia can use its AI brand, CUDA ecosystem, and hyperscale relationships to redefine what “performance” means in RAN silicon, especially if AI-native functions become a buying criterion. The counterpoint is that Qualcomm still has a strong edge in wireless-specific silicon integration and standards heritage, which matters if the 6G radio path remains RF- and modem-centric.
Nokia looks less exposed in the short term because it is already partnering with Nvidia rather than treating it as a pure adversary. Nvidia and Nokia have publicly framed their relationship as an AI-native 5G-Advanced/6G platform effort, and Nokia says it will add NVIDIA-powered commercial AI-RAN products to its RAN portfolio.
Nonetheless, a Nvidia radio-chip push could still compress Nokia’s differentiation over time if more of the RAN stack becomes software-defined and GPU-centric. The strategic question is whether Nokia remains the integrator and operator-facing systems vendor, or whether Nvidia gradually becomes the architectural center of gravity.
Ericsson is the most structurally interesting case because it sits at the high end of global RAN share and has been more cautious about Nvidia as a Layer 1 option. Light Reading notes Ericsson is currently dismissive of Nvidia as a Layer 1 choice, even while the broader ecosystem explores AI-RAN collaboration.
For Ericsson, the threat is not immediate revenue loss from a single chip; it is erosion of the traditional assumption that RAN leadership comes from proprietary radio and baseband stacks. If Nvidia can make AI-native RAN a default design paradigm, Ericsson may be forced to defend its software and systems value rather than simply its box-selling model.
Samsung Electronics contacted Light Reading after their story was published to point out that it also works with AMD as a chip partner. “Samsung supports full Layer 1 (L1) processing using Intel’s telco CPUs (e.g., Xeon 6 Granite Rapids) and lookaside accelerator approach and in addition has successfully demonstrated full L1 processing on AMD’s CPUs without relying on dedicated L1 accelerators,” a Samsung spokesperson said via email.
Marvell is the most exposed chip supplier in this story because its telecom position is more concentrated in custom Layer 1 silicon. Light Reading specifically points out that Marvell is a critical supplier to Nokia in Layer 1, which makes a Nvidia radio-chip effort a direct substitution threat in portions of the stack.
If Nvidia succeeds, Marvell faces a two-sided squeeze: loss of design wins in telecom silicon and a narrative shift toward AI-native programmable platforms that favor Nvidia’s broader ecosystem. Marvell’s defense is that telecom operators still care about power, latency, and deterministic functionality, areas where custom silicon can remain more efficient than a generalized AI-compute approach.
…………………………………………………………………………………………………………………………………………………………………………
Summary Table:
| Company | Impact level | Why |
|---|---|---|
| Qualcomm | High | Direct silicon adjacency and overlapping Layer 1 ambitions. |
| Marvell | High | Telecom custom-silicon exposure, especially Layer 1. |
| Ericsson | Medium | Strategic and architectural threat more than immediate chip displacement. |
| Nokia | Medium to low near term | Partnered with Nvidia, so risk is more about future dependence and stack control. |
Source: Perplexity.ai
…………………………………………………………………………………………………………………………………………………………………………
Conclusions:
It’s unknown whether Nvidia’s rumored radio chip becomes a product, a reference design, or just an extension of its AI-RAN platform. If it ships, watch for operator trials, power-envelope disclosures, and whether it targets RU integration, DU acceleration, or a hybrid AI-RAN endpoint. If it stays at the partnership/reference-design level, the market impact will be more narrative than revenue-relevant.
Another unanswered question is whether Nokia and Ericsson keep treating Nvidia as a collaborator while preserving their own Physical layer control, or whether they start to see Nvidia as a platform owner in the making. That boundary will determine whether this is a tactical ecosystem play or the beginning of a deeper industry reset.
…………………………………………………………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/6g/nvidia-has-a-radical-new-ai-ran-plan-a-6g-radio-unit-chip
https://www.lightreading.com/6g/analyst-insight-6g-coming-into-focus
https://www.nvidia.com/en-us/industries/telecommunications/ai-ran/
RAN Silicon Rethink- Part II; vRAN and General-Purpose Compute
Orange, Nokia, Nvidia, and Intel debate: ASICs vs. GPUs vs. General-Purpose CPUs for RAN Baseband Processing
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Nvidia pays $1 billion for a stake in Nokia to collaborate on AI networking solutions
Inside Nokia’s new AI Networking Innovation Lab
Analysis: Nvidia’s $2 billion investment in Marvell; NVLink Fusion ecosystem & RAN vendor silicon strategy
Marvell shrinking share of the RAN custom silicon market & acquisition of XConn Technologies for AI data center connectivity
Oriole Networks photonic networking platform to be integrated with AMD GPUs/CPUs for next-gen AI data center fabrics
London, England based Oriole Networks today announced continued progress in its collaboration with AMD in support of the UK’s Advanced Research & Invention Agency (ARIA) Scaling Inference Lab. The initiative integrates Oriole’s photonic interconnect architecture with AMD Instinct GPUs and AMD EPYC CPUs to evaluate next-generation data center fabrics capable of addressing the performance, latency, and energy constraints inherent in large-scale AI workloads.
The multi-year collaboration is advancing toward deployment of what is positioned as the first production-scale, all-photonic AI network fabric. The system is designed to deliver ultra-low latency and deterministic transport characteristics at the system level, leveraging optical circuit switching to optimize east-west traffic flows across accelerator clusters. The primary objective is to demonstrate how optical interconnect technologies can support large-scale inference and distributed AI processing under stringent performance and energy constraints.
Oriole’s PRISM photonic networking platform [2.] replaces conventional electronic switching in the network core with nanosecond-scale optical circuit switching. In contrast to packet-switched electronic fabrics, this approach is intended to reduce forwarding overhead, lower core power consumption, and improve end-to-end transport efficiency for accelerator-dense workloads. AMD is contributing compute hardware and technical collaboration to support modeling and execution of large-scale network workloads relevant to frontier AI systems. However, PRISM is not built for any single chip vendor. It works across any accelerator platform, giving the wider industry a path to frontier-scale system-wide performance without the need for proprietary stacks.
Note 1. Oriole Networks is a photonic networking company, developing disruptive technologies for AI/ML and HPC networking that will revolutionize data centers. These technologies address AI’s biggest challenges – speed, latency, and sustainability. Our holistic approach replaces energy-hungry electrical switching with photonic switching. By using only light to move data in the network, our solution will increase the efficiency of LLM training and inference to unprecedented levels while dramatically reducing the energy consumption of data centers, currently putting a huge strain on energy grids. We can offer faster, more efficient, and more sustainable AI without sacrificing the planet.
Note 2. Oriole’s PRISM is a fully photonic network system designed to provide port-level, all-to-all connectivity, eliminating the need for electrical switches and dramatically reducing the number of optical transceivers needed in the network. This evolution greatly reduces power consumption and latency, increases bandwidth, and strengthens network resilience by eliminating single points of failure.

Image Credit: Oriole Networks
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
The deployment also represents the first commercial implementation of Oriole’s technology following an R&D-to-production transition completed in approximately three years. The company states that its xPU-agnostic architecture is intended to support heterogeneous accelerator environments and broader industry rollout beginning in 2027.
Photonic networking architecture:
PRISM is designed to route data optically rather than electrically, using photonic circuit paths in place of conventional electronic switching elements. As AI training and inference workloads scale, data center interconnect requirements increasingly exceed the efficiency limits of traditional switch-based architectures, particularly in terms of power dissipation, thermal load, and communication latency.
By eliminating electronic switching in the fabric core, the PRISM architecture seeks to reduce core network power consumption and limit buffering- and queuing-related delay. The use of optical circuit switching is consistent with ongoing industry interest in photonic interconnects, co-packaged optics, and optical disaggregation as potential enablers of high-density AI clusters.
The company reports that the architecture can substantially reduce GPU idle time and improve system-level utilization by shortening data movement paths between compute nodes. It also indicates potential reductions in cooling demand and associated water usage due to lower network power dissipation.
Quotes:
James Regan, CEO of Oriole, said: “A year ago, we were proving the physics; today, we’re proving the business. Our collaboration with AMD has moved from concept to deployment to a system an order of magnitude larger, and the data proves this is already driving performance increases at pace. This is what it looks like when photonic networking stops being a research curiosity and starts being the foundation of how serious AI infrastructure gets built. There’s a big problem now with electrical switches, which are basically bottlenecking AI traffic, and it’s going to get worse. What we do is we replace all the electrical switches.”
“AMD is excited to collaborate with Oriole on the ARIA Scaling Inference Lab cluster,” said Madhu Rangarajan, corporate vice president, Compute and Enterprise AI business, AMD. “Oriole’s AI backend networking with nanosecond optical circuit switching represents a fundamentally different way to connect accelerators at scale. We are helping to validate how photonic fabrics can work alongside AMD compute to deliver the low-latency, high-bandwidth connectivity that AI Inference workloads demand.”
“Meeting the demands for modern AI requires rapidly identifying ways to improve the performance and cost-efficiency of large-scale AI clusters. ARIA is thrilled to collaborate with Oriole and AMD to demonstrate the benefits of this new technology and it’s exactly the type of collaboration, between innovative startups and industry leaders, that the Scaling Inference Lab was designed to foster,” said Suraj Bramhavar, Program Director at ARIA
Standards and interoperability context:
From a standards perspective, photonic AI fabrics remain an active area of industry development rather than a fully mature architectural class. Relevant technical domains include IEEE 802.3 optical Ethernet interfaces, ITU-T optical transport frameworks such as G.694 and G.709, and ecosystem work in optical interconnect and co-packaged optics initiatives.
A vendor-neutral, accelerator-agnostic photonic fabric may be of interest to standards and industry groups evaluating future data center interconnect models for AI and high-performance computing. The Oriole–AMD collaboration therefore provides an early reference point for assessing the operational characteristics, integration constraints, and interoperability implications of optical circuit-switched AI infrastructure.
……………………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
Oriole to Deploy World’s First AI System with Pure Photonic Network to Supercharge Data Centers
https://www.fierce-network.com/cloud/oriole-networks-pushes-pure-photonic-networking-ai-data-centers
NTT’s IOWN is (finally) evolving to an All Photonics Network (APN); Physics based AI for enterprise OT
Goldman Sachs report: Optical Networking is the next mega trend in AI infrastructure
Hyperscaler design of networking equipment with ODM partners
Technavio: Silicon Photonics market estimated to grow at ~25% CAGR from 2024-2028
Amazon and Corning in Multi-Billion-Dollar Fiber Infrastructure Deal in North Carolina
Introduction:
The surge in optical fiber demand is intensifying as hyperscale cloud providers accelerate infrastructure buildouts to support AI-driven workloads and high-density data center interconnect (DCI). Corning [1.] today announced a multi‑billion‑dollar investment from Amazon to expand fiber manufacturing capacity in North Carolina—incremental to its previously announced $10 billion regional cloud infrastructure expansion—reflects a broader structural shift in how optical supply chains are being secured and scaled.
Note 1. Corning’s fiber-optic infrastructure uses highly pure strands of optical glass thinner than a human hair to transmit massive amounts of data as pulses of light. These networks serve as the backbone for modern communications, connecting everything from rural broadband rollouts to hyperscale data centers driving generative AI. In hyperscale cloud and AI data centers, Corning provides high-density optical hardware and cables, such as their GlassWorks AI™ solutions. These large setups feature massive fiber-optic trunk cables containing hundreds to thousands of individual fibers bundled together to link powerful processors and servers. For outdoor networks running underground or on utility poles, you will see ruggedized cables protected by thick jackets and aramid yarn. These cables are designed to withstand weather, crushing, and extreme temperatures.

Corning’s structured cable solutions for internal data center connectivity. Image Credit: Corning
…………………………………………………………………………………………………………………………………………………………………………………….
This trend is not isolated. Hyperscalers including Meta, Microsoft, and wireline network operator Lumen are proactively entering long-term supply and co-investment agreements with fiber and cable manufacturers, effectively reshaping the upstream optical ecosystem.
Recent Fiber Supply Agreements with Corning:
-
May 2026: NVIDIA committed $500 million to Corning to support construction of three new optical manufacturing facilities in North Carolina and Texas. This investment is expected to increase Corning’s U.S.-based optical connectivity manufacturing capacity by approximately 10× and expand domestic fiber production by over 50%, targeting AI cluster interconnect requirements characterized by high fiber count and low-latency links aligned with IEEE 802.3 Ethernet and emerging co-packaged optics ecosystems.
-
January 2026: Meta finalized a $6 billion agreement with Corning to secure fiber supply for large-scale data center fabrics. These fabrics increasingly rely on high-fiber-density architectures consistent with leaf-spine topologies and standards such as IEEE 802.3bs/ck (400G/800G Ethernet), as well as parallel single-mode fiber (PSM) and wavelength-division multiplexing (WDM) approaches defined in ITU-T G.694.x.
-
September 2025: Microsoft entered a manufacturing agreement with Corning and Heraeus focused on hollow-core fiber (HCF), a technology aligned with ITU-T G.650 characterization frameworks. HCF offers lower latency (reduced group index) and improved performance for latency-sensitive AI workloads and inter-data center transport.
-
August 2024: Corning and Lumen established a supply agreement for next-generation fiber optic cable to support AI-driven traffic growth. This aligns with ITU-T G.652.D and G.657 fiber standards for bend-insensitive and high-capacity terrestrial deployments, as well as evolving requirements for high-count ribbon fiber cables in dense metro and campus environments.
Structural Implications for the Optical Supply Chain:
Hyperscalers are transitioning from passive consumers of optical components to active participants in manufacturing scale-up, including:
-
Anchor tenancy models: As seen with Meta’s backing of Corning’s North Carolina facility, hyperscalers are underwriting capacity expansion, effectively securing preferential access to supply.
-
Vertical influence: Direct investments and long-term offtake agreements allow hyperscalers to influence fiber specifications, manufacturing roadmaps, and deployment architectures (e.g., optimized fiber types for short-reach vs. long-haul DCI).
-
Workforce development: Amazon and Corning’s collaboration with Catawba Valley Community College to expand fiber technician training reflects a strategic effort to address labor constraints in optical manufacturing and deployment, reinforcing domestic supply chain resilience.
Implications for Telecom Operators:
These developments introduce non-trivial risks and strategic considerations for telecom operators:
-
Supply prioritization: Hyperscaler-backed agreements may shift allocation dynamics, potentially constraining availability for traditional telecom buyers during periods of tight supply.
-
Pricing pressure: Long-term, high-volume contracts could influence pricing benchmarks, potentially disadvantaging operators without comparable scale or capital flexibility.
-
BEAD timing mismatch: U.S. operators anticipating fiber expansion funded by BEAD (Broadband Equity, Access, and Deployment) may face supply bottlenecks if hyperscaler demand absorbs near-term manufacturing output.
-
Architectural divergence: Hyperscaler-driven requirements—optimized for short-reach, ultra-high-capacity intra-data-center and DCI links—may skew innovation toward their use cases, potentially misaligning with traditional access network needs governed by ITU-T G.984 (GPON), G.9807 (XGS-PON), and emerging 25G/50G PON standards.
A useful analogy is the semiconductor industry, where hyperscaler influence has already reshaped foundry capacity allocation and advanced node prioritization. A similar dynamic is now emerging in optical fiber and connectivity, with hyperscalers effectively acting as quasi-industrial planners for next-generation optical infrastructure.
Quotes:
“Amazon’s investments in North Carolina have created more than 26,000 jobs across the state. This multibillion-dollar agreement with Corning continues that commitment, channeling investment into American manufacturing and creating 1,000 new jobs at their facilities near our data centers,” said Matt Garman, CEO of AWS. “We’re also partnering to train North Carolinians for highly skilled roles in fiber optics and fusion splicing. These long-term investments create long-term careers and real opportunity in the communities where we operate.”
“This agreement with Amazon represents a significant milestone for Corning and for American manufacturing,” said Wendell Weeks, chairman, CEO, and president of Corning. “For 175 years, Corning has pioneered the technologies that connect people and transform industries. Amazon’s investment will help us expand production, create 1,000 new advanced manufacturing jobs at our facilities, and lead the way toward building a resilient U.S. manufacturing base.”
Clearfield CEO Cheri Beranek told Fierce Network at Fiber Connect that supply chain issues are re-emerging, particularly around high-count fiber. “There’s absolutely a shortage of ribbon fiber,” she said, referring to a conversation with Hawaii Telecom, a Clearfield customer. “The high count for the ribbon fiber … everything over 432 is tough to get,” she said. “The fiber companies want to tell you that there’s enough American‑made fiber… but there can’t be.”
“In talking to fiber optic suppliers, they all say one thing, ‘It’s nice to finally be the cool kid on the block.’ Hyperscalers are finally realizing that they not only need compute, storage, chips, power, water and real estate, they also need fiber optic connectivity,” said Fierce Network’s Chief Analyst Linda Hardesty.
The net effect is a tightening coupling between AI infrastructure demand and optical supply chain strategy—one that telecom operators will need to actively manage through procurement strategy, vendor diversification, and potentially deeper participation in supply-side partnerships.
End Note:
Amazon’s long-term commitment to North Carolina goes beyond direct investments and jobs created in the state. Through workforce development, Career Choice, and upskilling programs, Amazon has already provided practical training for nearly 7,000 people in North Carolina, helping to open new pathways for higher-paying jobs and fulfilling careers.
In the last decade, Amazon has contributed more than $72 million to charities and organizations supporting local needs across North Carolina, with $10 million provided in 2025 alone to 26 local community partners. This includes contributions like $1.5 million to enhance public safety services for southeastern Hamlet and surrounding Richmond County communities by funding a new fire substation that is expected to lower emergency response times and homeowner insurance premiums.
References:
https://www.corning.com/data-center/au/en/home/applications/enterprise-private-data-center.html
https://www.aboutamazon.com/news/company-news/amazon-corning-fiber-optics-1000-jobs-north-carolina
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
Corning to Build New Fiber Optic Plant in Phoenix, AZ for AT&T Fiber Network Expansion
Calix and Corning Weigh In: When Will Broadband Wireline Spending Increase?
Verizon-Corning $1.05B fiber deal part of larger build-out or buy program
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
By Alan J Weissberger
Executive Summary:
The rapid rise of agentic artificial intelligence (AI) is expected to drive material changes across data centers, service provider networks, and the broader telecom ecosystem. As agentic AI moves from chat-oriented interactions to autonomous digital agents, Cisco says that those workloads will not only increase traffic volumes, but also alter traffic characteristics in ways that place new demands on latency, security, orchestration, and distributed compute placement.
“We are entering into a Network Supercycle,” Jeetu Patel, Cisco’s president and chief product officer, said during his opening keynote at Cisco Live in Las Vegas.
As a result, network operators will need more resilient transport, edge compute, and optical capacity to support new traffic patterns and security demands.
Cisco execs pictured (left to right): Jeetu Patel, president and chief product officer; Chuck Robbins, chairman and CEO; Liz Centoni, EVP and chief customer experience officer; and Steven Clayton, SVP and chief communications officer.
Source: Jeff Baumgartner/Light Reading
AI Traffic Impact on Transport Requirements:
From a transport perspective, agentic AI traffic is likely to be more persistent, more interactive, and more latency-sensitive than conventional application traffic. Cisco has said AI-related network traffic is expected to triple over the next three years, with inference flows emerging as a major driver of load growth. That shift could place pressure on transport architectures that were optimized primarily for human-driven web, video, and enterprise application traffic
The implication for service providers is that traffic engineering will need to evolve toward finer-grained path control, stronger telemetry, and improved handling of asymmetric flows. AI sessions that span multiple exchanges between users, applications, and digital agents may also require more sophisticated policy enforcement and security integration across WAN, metro, and access layers.
Edge Compute Needs Grow:
Cisco’s remarks also point to a growing role for edge compute in telecom and cable networks. Some operators are already repurposing legacy central offices and mini data centers to support AI workloads, reflecting a broader shift toward distributed inference close to the user or device.
That architecture matters because many agentic AI use cases will be latency constrained and will not perform efficiently if all processing is centralized in distant cloud regions. Comcast and Charter have both announced AI edge strategies, underscoring how access networks can become part of the compute fabric rather than acting solely as last-mile connectivity.
For network operators, this suggests a new operational model in which compute, storage, and network functions are increasingly coordinated across regional and edge sites. In practical terms, the network becomes part of the application execution environment, not just the transport layer beneath it.
Optical Network Implications:
Optical infrastructure will likely carry much of the burden created by distributed AI deployments. As inference workloads expand across regional hubs, edge sites, and centralized clouds, operators may need higher-capacity optical transport to sustain east-west traffic between distributed compute nodes.
That points to greater demand for dense 400G and 800G interconnects, more flexible wavelength management, and lower-latency optical paths between metro aggregation points and AI facilities. The challenge is not only to scale throughput, but also to preserve path diversity, minimize jitter, and maintain predictable performance for machine-to-machine workloads that are increasingly sensitive to delay.
As AI traffic becomes more dynamic and more operationally critical, optical networks may need to be engineered with the same level of service awareness traditionally associated with enterprise transport and carrier-grade voice or mobile backhaul.
Security is a Top Priority:
Cisco cited security as a serious concern for agentic AI traffic. CEO Chuck Robbins said AI agents designed to help enterprise customers can run roughshod without a proper defense that can quickly detect, intercept and possibly “kill” them before they get out of control. It becomes an even bigger issue when they are built to be nefarious.
“AI changes the speed of defense,” Robbins said. “It’s empowering adversaries at a pace that we haven’t seen in our careers … These [AI] models are as bad as they are ever going to be …They’re only going to get better.”
Anthropic’s new Claude Mythos model, which can auto-detect and possibly exploit software vulnerabilities at scale, is now a “CEO-level discussion,” he added.
“We’re living in a post-Mythos world where security has to be fused and baked into the network,” Patel said, holding that vulnerabilities can now being attacked as soon as they arise.
“We need to reimagine security” in the AI era, Patel said, noting that AI agents will not only handle tasks locally but will be heading outside to connect to third-party agents, servers and various tools.
“Every agentic action is a routing challenge, a trust decision and a telemetry event,” Patel said. The emergence of agentic AI, he said, is shifting the security and permission focus from “access control” (for us humans) to “action control” for agents that will need to be closely monitored, controlled and, if needed, quickly intercepted.
“People don’t trust these agents right now,” Patel said later during a separate discussion with press and analysts.
These concerns also extend to AI agent identity, which Cisco is addressing with its recent agreement to acquire Astrix Security.
This extends to other types of guardrails and observability metrics, too, including the notion of “tokenomics” – essentially keeping tabs on how many tokens an AI agent could consume. If the agent is found to be overspending on tokens, it could be intercepted and shut down.
Patel suggested that, without guardrails, what a company pays for AI tokens for a year could be consumed by an agent in a week. Assessing such AI agent behavior was a key driver of Cisco’s acquisition of Galileo Technologies.
Cisco’s AI Stack:
Cisco is focused on a vertically integrated platform – starting with its Silicon One platform for data centers and enterprise devices, optics, switches, routers and access points, apps and services, and wrapped by a new Cisco Cloud Control platform announced this week. Though Cisco Cloud Control is able to provide unified access to Cisco’s tools, apps and services, such as Meraki, Catalyst and Splunk, Patel stressed that it will also be able to integrate with third parties and support an open ecosystem. Cisco is starting out with support from 52 partners, including AWS, Google Cloud, NetBrain and ServiceNow.
Telecom Market Transition:
Robbins said Cisco used AI to scan 1.8 billion lines of code in 25 different programming languages over the past eight weeks. Without AI models, that would’ve taken eight years, he said.
Patel described the industry as being at a pivotal moment, moving from chat bots to more advanced agents that function as “digital coworkers.” He noted that “These agents are going to be everywhere.”
That transition suggests telecom networks will increasingly support autonomous machine interactions at scale, with implications that extend beyond bandwidth growth into security, policy control, and distributed systems design. For operators and vendors alike, the strategic question is no longer whether AI will affect the network, but how quickly the network architecture can adapt.
………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/ai-machine-learning/cisco-ai-driving-a-network-supercycle-
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Cisco’s Silicon One G300 as the dominant AI networking fabric, competing with Broadcom’s Tomahawk 6 series
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco to join Stargate UAE consortium as a preferred tech partner
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
Hyperscalers Dominance of Subsea Cable Capacity to Increase in the AI Era
Hyperscalers (AWS, Google, Microsoft, Meta/FB) now dominate global subsea cable capacity. Their share of total international bandwidth has surged from negligible levels in 2010 to approximately 75% today. According to data from TeleGeography, hyperscalers are participating in over two-thirds of all planned submarine cable deployments, with Google alone anchoring eight new systems in the Asia-Pacific (APAC) region. Despite this shift, traditional telecommunications operators remain critical to the subsea ecosystem.
Tier-1 telecom carriers provide the deep terrestrial reach and last-mile connectivity that both regional service providers and large content providers require to access edge markets. However, those network operators must increasingly architect their Wide Area Network (WAN) and long-haul transport infrastructure to integrate seamlessly with these massive hyperscale topologies.
Brian Washburn, Chief Analyst at Omdia’s Telco B2B Solutions Intelligence Service, notes that carriers face intensifying pressure to align their infrastructure with hyperscaler technical requirements. To achieve complete architectural control and establish fully isolated private networks, hyperscalers frequently seek to deploy proprietary optical transport equipment directly within carrier landing stations and co-location facilities. This shift toward self-contained infrastructure creates visibility challenges for the industry. Washburn noted Google’s extensive transpacific cable network as a primary example. Because this hyperscaler traffic is routed over fully private, dark fiber subsea segments, it remains entirely invisible to carrier networks and traditional traffic-modeling metrics, rendering these massive data volumes completely opaque.
TeleGeography’s interactive submarine cable map shows the majority of active and planned international submarine cable systems and their landing stations. Selecting a cable route on the map provides access to data about the cable, including the cable’s name, ready-for-service (RFS) date, length, owners, website, and landing points. Selecting a landing point provides a list of all submarine cables landing at that station.
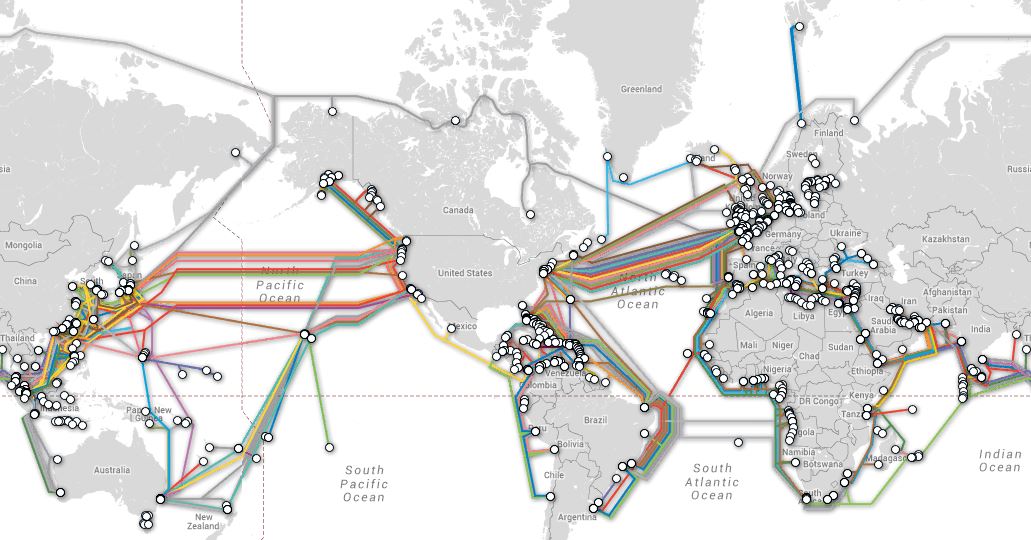
From a macro perspective, the deployment of next-generation physical infrastructure is increasingly tied to the rollout of raw, rack-scale data center capacity to support emerging AI workloads. Matt Walker, Chief Analyst at MTN Consulting, indicates that while Tier-1 US operators anticipate near-term traffic growth from centralized AI training models, they maintain a cautious, wait-and-see outlook regarding long-term network demand and the broader monetization of distributed inference at the edge. “With agentic, the potential for rapid growth in unexpected parts of the network is real, and it’s not clear how to plan for this,” he said. Operators are worried they will be stuck with the network costs to support “these pricey new AI-enabled services,” he also noted. Telco’s lack of visibility becomes a problem here. Walker stated in his research report: “The industry is flying partially blind. No comprehensive public study of AI traffic volumes, patterns, or growth exists. Nokia, Ericsson, and a handful of others have made partial contributions, but hyperscalers don’t share traffic data. For an industry spending over $600 billion in capex this year, this is a significant planning liability.”
MTN also revealed that telco capex remained subdued in 4Q2025, rising just 0.2% YoY to $86.6B as operators prioritized capital discipline, AI-enabled efficiency, and monetization of prior 5G investments. On an annualized basis, capex declined 0.9% to $295.7B, remaining below the $300B threshold for a second consecutive year. The strongest annualized capex growth rates were recorded by Swisscom (40.7%), Etisalat (40.5%), Airtel (24.4%), SoftBank (10.5%), and Deutsche Telekom (10.3%). The steepest capex declines came from China Telecom (-13.6%), Telefonica (-12.3%), China Unicom (-11.5%), Reliance Jio (-10.8%), and China Mobile (-8.1%).
Regionally, the Americas strengthened its lead in 4Q2025, accounting for 36.5% of global telecom revenues and 36.3% of capex, supported by resilient performance from T-Mobile US, AT&T, and Verizon. Asia’s revenue share moderated to 35.6% and capex share fell to 32.4%. This is notable given that Chinese telcos have been ramping AI and data center spending, while overall capex continues to decline as cuts to radio/hardware spending post-5G more than offset these gains.
References:
https://www.lightreading.com/ai-machine-learning/ai-is-going-to-transform-our-networks
https://www.submarinecablemap.com/
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Fiber Optic Networks & Subsea Cable Systems as the foundation for AI and Cloud services
Subsea cable systems: the new high-capacity, high-resilience backbone of the AI-driven global network
FCC updates subsea cable regulations; repeals 98 “outdated” broadcast rules and regulations
India’s Data Transmission Capacity to Quadruple in 2025 via New Submarine Cables
TechCrunch: Meta to build $10 billion Subsea Cable to manage its global data traffic
Google’s Bosun subsea cable to link Darwin, Australia to Christmas Island in the Indian Ocean
China seeks to control Asian subsea cable systems; SJC2 delayed, Apricot and Echo avoid South China Sea
“SMART” undersea cable to connect New Caledonia and Vanuatu in the southwest Pacific Ocean
Telstra International partners with: Trans Pacific Networks to build Echo cable; Google and APTelecom for central Pacific Connect cables
Orange Deploys Infinera’s GX Series to Power AMITIE Subsea Cable
Intentional or Accident: Russian fiber optic cable cut (1 of 3) by Chinese container ship under Baltic Sea
SK Telecom applies digital twins to SK Hynix semiconductor fabs using NVIDIA Omniverse libraries
SK Telecom (SKT) announced today that it has applied digital twins to SK Hynix semiconductor fabs [1.] using NVIDIA Omniverse libraries, optimizing the technology for complex, large-scale manufacturing environments. Digital twins recreate actual factories and equipment in virtual environments, enabling companies to simulate and verify the impact of process changes and equipment layout adjustments in advance. By enabling simulation of a wide range of scenarios in virtual environments, digital twins are gaining attention as a core physical AI technology that reduces trial and error while supporting data-driven decision-making. Last year, SKT completed a proof of concept (PoC) for applying digital twin technology to SK Hynix semiconductor fab. The company plans to proceed with commercialization in phases, aligning with SK Hynix’s roadmap to establish an “Autonomous Fab” by 2030.
Note 1. SK Hynix operates major semiconductor fabrication and packaging sites across South Korea and China, with new multibillion-dollar facilities under development in South Korea and the United States. While its core, multi-billion-dollar fabs are dedicated entirely to semiconductor memory production (DRAM, HBM, and NAND Flash), the company also operates a dedicated, separate pure-play foundry business that manufactures non-memory logic chips for external contract clients. : The main facilities in Icheon, Cheongju, and Yongin are specialized strictly for SK Hynix’s high-volume memory products like High-Bandwidth Memory (HBM), standard DRAM, and NAND flash. These massive facilities do not accept contract manufacturing orders for logic chips from external companies.
The Contract Foundry Business (External Clients): SK Hynix operates a wholly-owned subsidiary called SK Hynix System IC. This arm acts as a dedicated foundry for fabless semiconductor clients.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Using the NVIDIA Agent Toolkit, SKT has also developed “Agentic Digital Twin Modeling” technology, which automates and intelligently processes diverse data—such as equipment and spatial structures at manufacturing sites—for digital twin environments. This technology enhances the efficiency of data conversion, scene optimization, and performance improvement tasks that arise during the development and operation of digital twins in manufacturing environments.

A virtual factory implementation using SK Telecom’s digital twin platform. /Courtesy of SK Telecom
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
SKT is enhancing its platform by integrating NVIDIA Omniverse libraries to improve the loading speed of large-scale Open USD-based 3D scenes, execution performance, and GPU and memory usage efficiency. Through this, the company plans to implement a stable and scalable digital twin environment even in complex manufacturing environments with massive data volumes, such as semiconductor fabs.
“Semiconductor fabs are among the most challenging manufacturing environments, combining massive amounts of 3D data, complex equipment structures, and the need for high-level optimization,” said Mike Geyer, head of industrial digital twins at NVIDIA. “SKT has demonstrated a high level of technical capability in applying and validating NVIDIA Omniverse libraries, as well as the NVIDIA Agent Toolkit in real-world industrial settings within this environment.”
“Through our collaboration with NVIDIA, we have validated that manufacturing digital twins can evolve beyond simple 3D visualization into a physical AI platform capable of understanding and optimizing large-scale 3D manufacturing data,” said Cho Ik-hwan, Head of Physical AI at SKT. “Going forward, SKT will continue to expand its role as a physical AI technology partner with NVIDIA across various industrial sectors, including semiconductors.”
As a network provider equipped with end-to-end AI solutions — from AI infrastructure and models to services — SK Telecom plans to expand and strengthen its business targeting the enterprise and public sectors.
References:
https://www.thelec.net/news/articleView.html?idxno=10930
Inside Amazon’s new data center network architecture: quasi random network topology and passive optical devices
Amazon Web Services (AWS) claims it recently achieved a major breakthrough in Data Center Network (DCN) architecture and has been quietly deploying the new technology in its data centers since late last year. Amazon detailed its new networking design in a paper published May 21st titled “RNG: Flat Data Center Networks at Scale.” RNG, or “resilient network graphs,” is built around a quasi-random topology and new passive optical hardware. It’s a “quasi-random” design that combines elements of traditional, structured data networks with the performance advantages of more random architectures.
The goal is to move off conventional hierarchical “fat-tree” designs toward a flatter, more mesh-like fabric that uses far fewer routers and switches, offers more parallel paths, and therefore delivers higher effective throughput at lower power and capex.
“By essentially flattening the network, we eliminated the bottlenecks that come with traditional networking designs,” Matt Rehder, vice president of AWS Network Engineering, said in an exclusive interview with WIRED. “We think we’re the only ones who have done this at scale. RNG is a great fit for our core demands, but AI training data patterns are far more coordinated and centrally orchestrated, so they don’t approximate a random graph.”
The fact that Amazon is using this in the real world is “remarkable,” said Brighten Godfrey, a computer science professor at the University of Illinois Urbana-Champaign and an expert in networking, who was not involved in Amazon’s research. Godfrey coauthored a seminal 2012 paper on random network graphs, which he says are a “mind-bending problem to solve, in general.”
Classic cloud DCNs use structured topologies (Clos/fat-tree) where paths are highly regular and layered (Top of Rack (ToR)–aggregation–core). By contrast, random-graph theory says the most efficient routing networks are flat random graphs: each node connects to a small random subset of others, creating many short, diverse paths and graceful degradation under failures. The problem has always been practical: random cabling at scale is unmanageable, and routing across a huge random graph is nontrivial.
AWS’s “quasi-random” design essentially mixes determinism with randomness: key structural elements are fixed to keep the cabling and deployment manageable, while enough randomness is retained in the interconnect pattern to get the performance and resilience benefits of random graphs. The physical enabler is a new passive optical device called a ShuffleBox that standardizes how switches connect and internally permutes links so that, when many ShuffleBoxes are wired together, the resulting global topology is quasi-random without having to hand-design every link.

Image Credit: Amazon
………………………………………………………………………………………………………………………….
Key architectural pieces and claimed gains:
AWS reports that RNG-based fabrics now serve as the default network architecture for most new AWS data centers, after initial deployments beginning in 2024. The company claims the design:
-
Uses roughly 69% fewer routers/switches than traditional fat-tree DCNs, because the network is flatter and relies more on passive optical fanout.
-
Delivers up to about 33% higher throughput, due to more independent paths and better load spreading.
-
Cuts network equipment power consumption by on the order of 40%, with associated reductions in cooling and operational overhead.
On the control-plane side, AWS developed a routing scheme called Spraypoint. Instead of always following a strict shortest path from source to destination, Spraypoint first “sprays” traffic randomly to neighbors, then directs it via preselected “waypoints” using more conventional shortest-path routing. This hybrid behavior exploits the quasi-random topology to open many more independent paths than standard ECMP-style shortest-path routing would, which in turn improves utilization and resilience under congestion or failures.
Strategic implications:
For AWS’s cloud and AI build-out, this is positioned as a foundational infrastructure advantage: higher bisection bandwidth and lower network energy per bit directly benefit large-scale AI training clusters, storage backends, and multi-tenant cloud workloads. Fewer active devices and more passive optics also translate into lower capex and opex at hyperscale, so AWS is framing this as both a performance and cost/sustainability play that could save billions of dollars and reduce CO₂ emissions over time.
From a networking-theory standpoint, this is notable as one of the first reported at-scale, production deployments of a flat random-graph-inspired topology in a hyperscale DCN, rather than a purely academic or lab system.
In a quasi-random topology like AWS’s RNG fabric, the impact on latency and jitter comes from three main effects: path length distribution, load spreading, and failure behavior.
Baseline latency: path lengths and device count:
In a traditional Clos/fat-tree, average latency is dominated by a fixed number of stages (ToR → agg → core → agg → ToR), so hop count is tightly controlled but you pay for many active devices. A quasi-random, flat graph replaces that rigid hierarchy with many short, irregular paths; on average, shortest paths between any two switches are similar or slightly shorter in hop count than in a fat-tree, and there are fewer active routers in the path because the architecture offloads fanout to passive optics. That tends to keep or slightly reduce median/mean latency per flow, especially under moderate load, because packets traverse fewer serialized queueing points even if the physical graph looks “messier.”
Jitter: congestion and path diversity:
Jitter is driven much more by variable queueing delay than by fixed propagation or serialization. In a quasi-random fabric with many alternate paths and a load-balancing scheme like Spraypoint (random spray + waypoint-based shortest paths), flows can be spread more evenly across the network, reducing hot spots and thus reducing the variance of queueing delay across packets. That can lower jitter compared with a Clos under the same aggregate load, because the system is less likely to funnel many flows through the same few congested uplinks or spine devices.
However, because the routing intentionally uses many different paths, per-flow packet reordering becomes more likely unless constrained by per-flow hashing or waypointing, which can show up as effective jitter at higher layers. AWS’s description of Spraypoint suggests they mitigate this by using waypoints and policy to preserve some path structure, so you get the diversity benefits without unconstrained per-packet spraying.
Under failure and high load:
Where quasi-random really helps latency/jitter is under failure and partial congestion. In a Clos, link or spine failures can force large sets of flows to converge on a smaller subset of remaining equal-cost paths, driving up queueing delay and jitter nonlinearly. In a resilient random-graph-style fabric, node/edge failures simply remove a few edges from a highly connected graph; there are typically many alternative short paths, so the increase in hop count and queueing pressure is smaller and more diffuse. That tends to keep tail latency and jitter (P99, P99.9) better behaved, even if median latency looks similar to a Clos at low load.
So, qualitatively: median latency is roughly comparable to a well-designed Clos, sometimes better due to fewer active stages; jitter and tail latency should improve under realistic, bursty load and failure scenarios, provided the routing stack is designed to limit packet reordering.
Summary and Conclusions:
Quasi-random data center topologies like AWS’s RNG fabric replace rigid Clos/fat-tree hierarchies with a flatter, graph-like network that preserves short path lengths while dramatically increasing path diversity, which tends to hold median latency roughly steady or slightly better by reducing the number of active, queueing devices per path and offloading fanout to passive optics. They primarily improve jitter and tail latency by spreading flows across many alternative routes so congestion is less concentrated, making queueing delays less bursty and keeping P99/P99.9 behavior more stable under failures and hot spots, provided the routing layer (for example, AWS’s Spraypoint approach) constrains packet reordering through way pointing or per-flow consistency.
In conclusion, quasi-random fabrics are less about shaving a few microseconds off baseline latency and more about delivering more predictable end-to-end performance—especially for east–west, latency-sensitive cloud and AI workloads—by trading rigid structure for statistically robust, highly connected graphs that degrade more gracefully when links, nodes, or traffic patterns become pathological.
…………………………………………………………………………………………………………………………………………………………………….
References:
https://arxiv.org/pdf/2604.15261
https://www.wired.com/story/amazon-aws-ceo-matt-garman-ai-agents/
AWS to deploy AI inference chips from Cerebras in its data centers; Anapurna Labs/Amazon in-house AI silicon products
Amazon’s Jeff Bezos at Italian Tech Week: “AI is a kind of industrial bubble”
Data Center Networking Market to grow at a CAGR of 6.22% during 2022-2027 to reach $35.6 billion by 2027
TMR: Data Center Networking Market sees shift to user-centric & data-oriented business + CoreSite DC Tour
Network X Americas: AT&T and Comcast reveal huge AI impact on network operations
Echoing a recent Cisco report, telecom leaders at the Network X Americas conference (held in Irving, TX last week) noted that AI is fundamentally shifting traffic patterns while having a very positive impact on network operations. With billions of connected sensors and devices (like autonomous vehicles generating 20GB of data per day), operators are forced to prioritize uplink capacity and low latency over traditional consumer downlink traffic.

AT&T’s network CTO, Yigal Elbaz, cited the robo-taxi as a bellwether for how AI is affecting network traffic. Each Waymo vehicle generates about 20 gigabytes of data per day, roughly 30 times the amount a typical mobile user consumes. Most of that traffic flows from the car to the cloud. “Every other week,” Elbaz noted, “a new flavor of a frontier AI model drops on us.”
“We already have about 700,000 changes on a daily basis in our network made by AI,” said Elbaz, noting that AT&T has built a proprietary foundation AI model because standard large language models (LLMs) don’t understand KPIs, network alarms or fiber deployment specifics. He cited a 20-25% cost reduction and 12-15% better results than general-purpose models.
In his keynote speech, Comcast EVP and Chief Network Officer Elad Nafshi described 200 edge compute centers capable of self-healing 77% of network events. He touted AI chipsets close enough to customers’ homes to pinpoint outside plant faults with 99.2% precision, and a partnership with Nvidia to push that edge platform further.
Nafshi highlighted the gap in network provider promises vs delivery with a hypothetical small-business use case example. A pizza shop operator, could materially change workflow and productivity if the service provider delivered an AI-enabled concierge—built on a task-optimized small language model—to manage order intake and customer interaction. In that scenario, the network evolves from a passive access pipe into an application-aware platform that augments business operations. The concept is credible from a technical standpoint, but remains largely theoretical until operators can effectively reach and educate SMB customers who still perceive connectivity as a fixed monthly expense.
Both AT&T and Comcast Israeli executives said this was more than modernization and discussed the changes in what a network does. The network is now a platform, not a pipe. Today’s network learns, adapts and increasingly acts on behalf of its customers. But I can’t help but wonder if the customers know… or if that network value will ever trickle down to the customers who need it most.
In a keynote panel session titled, ” Convergence in action – Competing, scaling and winning in the AI-driven connectivity market,” Josh Goodell, AT&T’s VP of Broadband and Converged Product Development, framed the company’s objective as becoming “the greatest simplifier of our customers’ lives” while instilling “connectivity confidence.” That positioning is notable for a sector that has historically under-communicated its value proposition beyond basic service metrics.
The broader industry narrative appears to be shifting. Historically, go-to-market strategies emphasized throughput benchmarks and promotional pricing. As Omdia’s Ruth Brown (panel session moderator) observed, packaging has been largely defensive, optimized around billing constructs rather than differentiated user experience. The emerging model instead centers on networks that operate contextually and autonomously—delivering value in ways that are largely invisible to the end user.
Derek Peterson, CTO of Boingo Wireless, articulated a parallel issue in venue networks, describing the “stadium problem.” Operators dimension infrastructure for peak ingress and then underutilize that capacity once users are inside the venue. The architectural question is no longer solely about capacity provisioning, but about service-layer innovation on top of that capacity. At Petco Park, Boingo leveraged existing network assets to enable pre-entry commerce, driving incremental revenue before fans pass through the gates. The infrastructure was not the constraint; the limiting factor was identifying and executing on higher-order use cases.
A similar disconnect persists in the industry’s framing of the digital divide. AT&T’s John Stankey and others have suggested the gap is nearing closure, citing expanded fiber footprints and fixed wireless access. While coverage metrics have improved, the divide has never been purely a function of infrastructure availability. Adoption is equally constrained by affordability and, critically, by perceived value. If connectivity continues to be positioned as a commoditized utility, the most economically vulnerable segments—those with the greatest need for digital enablement—remain the least likely to engage.
This is particularly relevant in an AI-driven economy. The users and small enterprises that could benefit most from intelligent, network-delivered services are often those least exposed to the evolving capabilities of the platform. The industry risks over-indexing on measurable deployment milestones while under-communicating the functional value of next-generation networks.
The Network X keynotes underscored that the technical roadmap is largely in place. Network operators are advancing toward networks capable of real-time traffic learning, proactive cybersecurity at the edge, and highly personalized in-home connectivity experiences. These capabilities represent a more compelling value proposition than traditional service tier comparisons.
However, the central challenge remains go-to-market execution. The industry has demonstrated that it can architect and deploy these capabilities at scale. It has yet to establish a clear, effective framework for articulating that value to end users and enterprises in a way that drives adoption.
As a final observation, the broader telecom ecosystem—illustrated by developments such as autonomous vehicle platforms—already depends on AI-enabled, highly distributed network intelligence. While the underlying infrastructure is incrementally aligning with these requirements, the industry dialogue around its broader economic and societal implications remains underdeveloped.
References:
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
Telecom data centers must be redesigned for the AI era with rack scale architectures, enhanced power & cooling requirements
Is the “far edge” a bridge to far to cross for AI inferencing? What about “Distributed AI Grids”?
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Hurricane Electric establishes carrier neutral PoP at Lincoln Data Centers, Nebraska
Fremont, CA headquartered Hurricane Electric is a leading Internet backbone [1.] and colocation provider specializing in colocation, dedicated servers, direct Internet connections and web hosting. Hurricane Electric operates its own global network, running multiple OC192s, OC48s and Gigabit Ethernet. The ISP offer the following services:
- IP Transit [2.]: Wholesale internet connectivity ranging from 100 Mbps to massive network speeds over IPv4 and IPv6.
- Colocation: Physical rack and cabinet space in their carrier-neutral data centers (primarily in Fremont and San Jose, California) for customer-owned servers.
- Dedicated Servers: Single-tenant servers for businesses seeking dedicated safety, hardware, and performance.
- Web Hosting: Virtual hosting accounts for running and maintaining websites.
Note 1. Hurricane Electric claims to have the world’s largest IPv6-native Internet backbone. President Mike Leber founded Hurricane Electric in a garage in 1994. Hurricane Electric now operates an international backbone network and owns several datacenters, including a new 200,000 square-foot Fremont 2 colocation facility.
Note 2. IP transit is a commercial, wholesale service where an upstream Internet Service Provider (ISP) allows network traffic to travel through its backbone infrastructure to reach the rest of the global internet

Image Credit: Hurricane Electric
………………………………………………………………………………………………………………………………………………………………
Today, the company announced that it has established a new Point of Presence (PoP) at Lincoln Data Centers. The new PoP is located at 206 South 13th Street, Lincoln NE.
Lincoln Data Centers provides a carrier-neutral interconnection and colocation environment purpose-built for organizations with expanding connectivity requirements. The facility combines diverse fiber infrastructure, access to regional and long-haul carriers, low-friction interconnection through meet-me-room capabilities, and flexible deployment options that support scalable growth. Positioned in the geographic center of the United States, Lincoln Data Centers serves as an efficient regional hub for enterprises, cloud platforms, content providers, and network operators seeking resilient, low-latency connectivity across the Midwest and beyond.
The central United States continues to play an increasingly important role in digital infrastructure development due to its geographic advantages, expanding fiber ecosystems, growing enterprise technology adoption, and proximity to major population and business centers. Nebraska’s favorable business environment and central location make Lincoln an attractive market for organizations seeking resilient, low-latency connectivity and diversified network routes.
The new PoP improves fault tolerance, load balancing, and congestion management for next-generation IP connectivity services throughout the region. Customers of Lincoln Data Centers can now access Hurricane Electric’s extensive IPv4 and IPv6 backbone through 100GE (100 Gigabit Ethernet), 10GE (10 Gigabit Ethernet), and GigE (1 Gigabit Ethernet) ports.
“We are pleased to expand Hurricane Electric’s presence in the Midwest with this new Point of Presence at Lincoln Data Centers,” said Mike Leber, President of Hurricane Electric. “Lincoln’s central location, strong business climate, and growing digital infrastructure ecosystem make it an ideal site to support customers requiring reliable, high-capacity Internet connectivity across the region.”
With this deployment, organizations in and around Lincoln can exchange IP traffic directly with Hurricane Electric’s vast global network, which supports more than 40,000 BGP sessions with over 10,500 networks across more than 320 major exchange points worldwide.
The addition of this PoP reflects Hurricane Electric’s ongoing investment in expanding connectivity throughout North America and its commitment to delivering low-latency, highly resilient Internet connectivity for enterprises, cloud providers, research institutions, content platforms, and service providers.
About Hurricane Electric:
Fremont, California-based Hurricane Electric operates its own global IPv4 and IPv6 network and is considered the largest IPv6 backbone in the world. Within its global network, Hurricane Electric is connected to more than 320 major exchange points and exchanges traffic directly with more than 10,500 different networks. Employing a resilient fiber-optic topology, Hurricane Electric has five redundant 100G paths crossing North America, four separate 100G paths between the U.S. and Europe, and 100G rings in Europe, Australia and Asia. Hurricane also has a ring around Africa, and a PoP in Auckland, NZ. Hurricane Electric offers IPv4 and IPv6 transit solutions over the same connection. Connection speeds available include 100GE (100 gigabits/second), 10GE, and gigabit ethernet. Additional information can be found at http://he.net.
References:
Broadcom with Samsung Electronics: Integrated 5G and Wi-Fi 8 FWA Platform
Broadcom has announced a collaboration with Samsung Electronics Co., Ltd. to develop a reference platform for fixed wireless access (FWA) deployments, combining Broadcom’s BCM6776 Wi-Fi system-on-chip (SoC) with Samsung’s B1320 5G modem. The platform is designed to integrate 3GPP Release 17 5G connectivity with emerging IEEE 802.11bn (Wi-Fi 8) capabilities, supporting convergence between wide-area and local-area broadband technologies.
The reference design targets global FWA use cases, where operators seek to deliver high-throughput broadband services using 5G radio access in conjunction with advanced in-home wireless distribution. By aligning 5G and Wi-Fi 8 performance characteristics, the platform addresses requirements for sustained throughput, low latency, and reliability under variable radio conditions. The design also emphasizes scalability for high-volume deployments, with integration intended to reduce system complexity and cost.
The Broadcom BCM6776 is a tri-band Wi-Fi 8 SoC designed for residential and small enterprise access points. It integrates a quad-core Arm-based network processor with Wi-Fi 8 radio functionality in a single device. The SoC supports 2-stream operation with 40 MHz channels in the 2.4 GHz band, and 4-stream operation with up to 160 MHz channels in the 5 GHz and 6 GHz bands. This configuration enables multi-gigabit aggregate throughput while maintaining compatibility with evolving IEEE 802.11bn features.
Integration of compute and radio subsystems within a single SoC reduces bill of materials (BOM) requirements and simplifies hardware design. Power efficiency is also improved relative to prior architectures that relied on discrete components, supporting deployment in thermally constrained residential environments.

Image Credit: Broadcom
…………………………………………………………………………………………………………………………………………………
The Samsung B1320 modem is a 5 nm-class integrated 5G chipset compliant with 3GPP Release 17. It supports peak downlink throughput of up to 3.43 Gbps and uplink throughput of up to 1.17 Gbps, depending on deployment configuration. The modem incorporates a quad-core Arm CPU, RF transceiver, power management functions, and a global navigation satellite system (GNSS) receiver.
The platform further supports non-terrestrial network (NTN) operation, including both NR-NTN and NB-NTN modes, enabling compatibility with satellite-based extensions of 5G coverage.
The combined architecture is designed to sustain end-to-end throughput between the 5G access link and the in-home Wi-Fi network, minimizing bottlenecks between the wide-area and local domains. This is particularly relevant for FWA deployments, where performance is constrained by both radio access conditions and in-premises distribution efficiency.
By providing a pre-integrated reference design, the platform enables original equipment manufacturers (OEMs) and operators to accelerate development cycles and standardize system performance across deployments. This approach supports broader adoption of FWA as a complement to fixed broadband infrastructure, particularly in scenarios where fiber deployment is limited or economically constrained.
“At Computex 2026, we are highlighting that the future of home internet can be both accessible and affordable,” said Joonsuk Kim, Executive Vice President and Head of CP Development at Samsung Electronics. “This platform is designed to deliver reliable performance across a wide range of environments, helping operators bring high-quality connectivity experiences to subscribers.”
“Broadcom is proud to lead the Wi-Fi 8 transition alongside Samsung and our valued ODM partners,” said Vijay Nagarajan, Vice President of Marketing, Wireless and Broadband Communications Division at Broadcom. “This partnership is a game-changer for the FWA market. The combination of Wi-Fi 8 and 5G prioritizes coordinated reliability, giving operators a tool that delivers a consistent experience to every corner of the home.”
Product Features:
The Samsung B1320 is a broadband-optimized 5G platform with the following features:
- 3GPP Release 17
- 4Rx/2Tx radio chain support
- Power Class 1.5 support (TDD bands)
- LPDDR4x / LPDDR5x support
- 1.6 GHz quad-core ARM Cortex-A55 CPU
- 5 Gbps USXGMII, PCIe Gen 3, USB 2.0
- GNSS
- NR-NTN and NB-NTN support for n255 and n256 (L- and S-bands)
The Broadcom BCM6776 is a single-chip Wi-Fi SoC and multi-band radio supporting the following:
- High performance quad-core CPU complex
- Dedicated network processing engine freeing the CPU complex for operator-specific applications and utilities
- Integrated 2×2 2.4 GHz and 4×4 5 GHz and 6 GHz Wi-Fi 8 MAC/PHY/Radio functionality, simplifying system design and lowering cost
- On-chip 2.4 GHz power amplifiers (PAs) and support for third-generation digital pre-distortion for reduced external components and improved RF efficiency
- Versatile memory controller supporting DDR4, LPDDR4, DDR5, and LPDDR5
- Dual PCIe Gen3 controllers to enable simultaneous tri-band applications with a single additional chip
- Integrated multi-gig PHY
A Global Ecosystem of Support:
The launch is supported by the world’s leading original equipment manufacturers (OEMs), who are already integrating the B1320 / BCM6776 platform into their next-generation gateway portfolios.
“HUMAX Networks is delighted to pioneer the next-generation 5G CPE market alongside global technology leaders Broadcom and Samsung. At the recent MWC 2026, we successfully showcased the industry’s first Wi-Fi 8 solution, which integrates Samsung’s cutting-edge 5G technology with Broadcom’s next-generation silicon. Through our ongoing partnership, we remain committed to driving market innovation and consistently delivering top-tier experiences and innovative devices to our global customers,” said Jerry Lee, CEO of Humax Networks.
“We are delighted to collaborate with Broadcom and Samsung to develop our next generation Wi-Fi 8 gateway addressing MSO CBU/FWA market. This solution is capable of delivering a smarter, more secure, and future-ready network optimized solution to meet MSO/FWA customers’ increasing demands of cost competitive 5G NR connectivity,” said Johnson Hsu, SVP & GM of WNC’s Connectivity & Solutions BG.
Availability:
Global carrier trials and OEM sampling of the Samsung B1320 / Broadcom BCM6776 FWA platform are underway.
About Broadcom:
Broadcom Inc. (NASDAQ: AVGO) is a technology leader that designs, develops, and supplies semiconductors and infrastructure software for global organizations’ complex, mission-critical needs. Broadcom combines long-term R&D investment with superb execution to deliver the best technology, at scale. Broadcom is a Delaware corporation headquartered in Palo Alto, CA. For more information, visit www.broadcom.com.
Broadcom, the pulse logo, and Connecting everything are among the trademarks of Broadcom. The term “Broadcom” refers to Broadcom Inc., and/or its subsidiaries. Other trademarks are the property of their respective owners.
…………………………………………………………………………………………………………………..
References:
Extreme Networks deploys Wi‑Fi 7 (IEEE 802.11be) at University of Florida’s “Swamp”
Ookla: FWA Speed Test Results for big 3 U.S. Carriers & Wireless Connectivity Performance at Busy Airports
Aviat Networks and Intracom Telecom partner to deliver 5G mmWave FWA in North America
T-Mobile’s growth trajectory increases: 5G FWA, Metronet acquisition and MVNO deals with Charter & Comcast
Analysis: AT&T 1Q-2026 results: increased fiber penetration, FWA momentum, D2D deals, and mobile/home internet bundles
Latest Ericsson Mobility Report talks up 5G SA networks and FWA
