

Ookla: AI workloads will force changes in 5G mobile network infrastructure
Introduction:
Ookla’s latest research study examines how AI use cases will stress 5G mobile networks, relative to standard internet traffic. The report, based on Speedtest Intelligence® data across 22 markets, evaluates metrics like upload capacity, latency under load, and cloud infrastructure pathways (see graphs below). Using Speedtest 5G data from 2025 across 22 markets and 86 operators in North America, Europe, Asia Pacific, the Middle East, and Latin America, it measures upload capacity, latency under load, and the quality of the path to the cloud. It also shows where current 5G falls short of what AI actually demands.
Analysis:
Ookla’s report argues that 5G network evaluation is entering a new phase: raw download speed is no longer enough to describe user experience or network capability in an AI-driven era. The more relevant indicators are upload performance, latency, consistency, and resilience, because AI-heavy applications tend to be interactive, symmetric, and sensitive to delay. The report’s timing is important because it reframes 5G from a consumer mobile broadband service into an infrastructure question for AI workloads. That shift matters for network operators, because uplink and latency have historically received less attention than headline download rates in market rankings and public messaging.
Here’s the lead-in (emphasis added):
“AI has changed what a good mobile network looks like, and the metric the industry has marketed for two decades — peak download speed — no longer predicts it. The networks that top the download charts are often not the ones best prepared for AI traffic. Whether an AI application feels instant or breaks depends in large part on how much a network can upload, how it holds up under load, and how consistently it reaches the cloud, and on those measures, different networks come out on top. This report rebuilds the industry’s download-led scorecard around what AI actually asks of a network, and shows where today’s 5G mobile networks are ready and where they fall short. AI traffic is not one thing. Text chat, conversational voice, multimodal and AR vision, generated video, and agentic activity each load the network differently, and most of them lean on parts of the network that download speed never tested. The change AI brings is less about raw capacity, which operators have expanded for years, than about the shape of the traffic — heavier on upload, always on, and bursty, rather than download-led and session-based.”
A few high-level takeaways for the U.S. market include:
- Although the United States ranks among the strongest on overall network performance, it sits at 5.1% for the proportion of network capacity allocated to the uplink, which is the lowest in the dataset.
- The U.S. upload share has contracted, declining from 8.0% to 5.1% between 2023 and 2025.
- The U.S. market top network operators fall short of the 20 Mbps upload target required for AR and multimodal AI.
- For baseline network responsiveness, the U.S. records a multi-server latency of 50.5 ms, missing the target of less than 50 ms for text-based large language models (LLMs).
Technical Implications:
Ookla’s framing implicitly favors 5G SA, 5G Advanced, and edge-assisted architectures, since these are the network generations most likely to improve latency determinism and support more efficient uplink behavior. It also suggests that future benchmarking should include workload-aware tests, not just conventional speed tests, because AI applications stress networks differently from video streaming or web browsing. The report has immediate relevance for markets where 5G download speeds look strong but uplink and latency remain weaker, because those networks may appear healthy under older metrics while still underperforming for AI use cases. That is a useful lens for comparing operators, especially where regulators and carriers are beginning to discuss AI readiness as part of national digital infrastructure strategy.
Conclusions:
With the rise of AI workloads, mobile network measurement is becoming application-specific. The central question is no longer just “How fast is 5G?” but “How well does the network support AI-era traffic patterns, especially interactive and uplink-heavy traffic?” In this new context, metrics such as upload capacity, latency consistency, and service resilience are becoming just as important as peak downlink speed. For operators, this implies that competitive advantage will increasingly depend on how well the network supports real-time, bidirectional, and latency-sensitive applications, rather than how well it performs on legacy consumer benchmarks.
Traditional speed tests still matter, but they are increasingly insufficient as a proxy for user experience in an AI-native environment. In practice, the networks that win will be those that can deliver symmetry, resilience, and predictable latency across real workloads, not merely impressive headline throughput.
…………………………………………………………………………………………………………………………………………………………………………………..
Ookla Charts:




……………………………………………………………………………………………………………………………………………………………………….
References:
https://www.ookla.com/articles/benchmarking-5g-ai-workloads-2026
https://www.ookla.com/s/media/2026/07/Ookla_Research_AI_network_readiness_07262.pdf
Ookla: AI platform reliability decreases as outages surge
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
Ericsson’s June 2026 Mobility Report Highlights + AI impact on network traffic
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Nokia’s AI Applications Study: “Physical AI” may require RAN redesign to support high‑volume, low‑latency uplink traffic
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Ookla on the Global D2D Market
Ookla: Starlink a viable competitor for hybrid 5G/NTN services due to network performance improvements and larger coverage area
Ookla: D2D satellite connectivity surged 24.5% during last 9 months; Starlink’s footprint expansion leads the way
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Dell’Oro: Mobile Core Networks +15% in 2025; Ookla: Global Reality Check on 5G SA and 5G Advanced in 2026
Ookla: FWA Speed Test Results for big 3 U.S. Carriers & Wireless Connectivity Performance at Busy Airports
Huawei’s AI-Centric Network Vision: Six Imperatives for the Next Decade; Critical Questions for IEEE Techblog Community
The Case for AI-Native Networks:
At MWC Shanghai 2026 [1.], David Wang, Deputy Chairman of the Board and Rotating Chairman of Huawei, outlined a strategic roadmap for AI-native mobile networks, positioning artificial intelligence as the cornerstone of industry growth over the next decade.
Note 1. MWC Shanghai 2026 was held June 24–26, 2026 at the Shanghai New International Expo Center (SNIEC), with Huawei showcasing products and solutions in Hall N1.
Over the past 40 years, innovation in mobile technology from each generation to the next has been key to the industry’s success. “With each generation, we have pushed the limits of spectral efficiency and performance,” said Wang. “Network architecture has gradually flattened, with new application scenarios and services emerging left and right. This has consistently expanded the boundaries of communications, helping carriers translate network capabilities into commercial value,” he added.
Huawei argues that traditional telecom infrastructure built around data traffic is no longer sufficient. As the global digital ecosystem transitions toward real-time interactions with AI applications and intelligent agents, mobile and transport networks must be completely redesigned to support both communication and computing. According to Huawei, an AI-native architecture transforms networks from simple communication utilities into revenue-generating engines while helping operators transition to Level-4 and Level-5 network autonomy
Huawei’s Six Strategic Imperatives:
Wang identified six imperatives to guide the industry through the age of intelligence:
-
Developing new services and capabilities for future mobile communications systems
-
Integrating AI with mobile communications to build three distinct layers of intelligence
-
Building network architecture for integrated satellite-ground communications
-
Advocating for sustainable and future-oriented spectrum planning and allocation
-
Clearly defining the specifications of AI-native core networks
-
Exploring new business models and application scenarios for mobile services

Photo Credit: Huawei
Innovations Unveiled: Byte and Token Monetization:
Huawei released a portfolio of innovations targeting both services and infrastructure. On the services side, in collaboration with China’s three major carriers, the company announced advances in 5G-Advanced (5G-A) high-uplink and experience monetization, AI-powered business upgrades, and token monetization.
For infrastructure, Huawei launched the AI-centric target network, designed to enhance carrier competitiveness in byte and token monetization. This architecture comprises three layers:
-
Basic Communications Network: A shift from traffic-centric to real-time interaction networking, offering guaranteed connectivity with high uplink and downlink capabilities alongside advanced QoS mechanisms.
-
Computing Network: A transition from traffic transport to network-wide compute scheduling and supply, where “connecting to the network is equivalent to accessing compute.”
-
AI Computing Infrastructure: High-performance, efficient compute with support for open-source and open ecosystems.
5G-Advanced: 100 Million Users and Beyond:
The global 5G-A (based on 3GPP Release 18) user base has surpassed 100 million. Huawei is now working with network operators worldwide to advance 5G-A experience monetization and integrate it into installed base operations, targeting mid-range and high-end user retention, ARPU growth, and sustainable revenue expansion.
High Uplink Speed: The New Frontier for AI Applications:
High uplink capacity is critical for token monetization. Emerging AI applications—such as multimodal AI glasses for real-time translation and augmented exhibitions—demand uplink speeds of 20 Mbps or higher. In 2026, leading carriers globally are piloting commercial high-uplink services with guaranteed peak speeds, latency, and universal uplink performance.
Upper-6 GHz: The Next Golden Band:
The proliferation of AI agents is expected to drive rapid growth in token services, requiring ultra-broadband networks with high uplink, high reliability, and low latency. Upper-6 GHz (U6 GHz) is positioned as the next-generation golden frequency band for this purpose.
-
More than 20 countries and regions have designated U6 GHz for IMT, covering nearly 80% of the global population.
-
2026 marks the commercial debut of U6 GHz, with the Middle East expected to deploy the world’s first commercial 5G-A network on U6 GHz.
-
Select carriers in Hong Kong and Macao will also initiate commercial U6 GHz deployment.
AI-Native B2C and B2B Services:
Huawei plans to collaborate with carriers in Guangdong, Shanghai, Hebei, and other regions in 2026 to reengineer B2C and B2H services with AI, targeting consumer applications such as smart home assistants, personal communication assistants, and integrated consumer-home services. In the B2B segment, the focus is on AI computing services centered on compute-network integration, unlocking new business growth avenues.
Path to Level-4 Autonomous Networks:
Huawei is advancing AI-native technologies toward Level-4 autonomous networks by developing domain-specific intelligence. In 2026, the company will work with carriers to deploy domain-specific intelligence across wireless and transmission network domains in key regions. This will enable cross-domain synergy in maintenance, optimization, energy efficiency, and user experience, enhancing network quality and enabling differentiated products for high-speed rail, event venues, and campuses.
Critical Questions:
Huawei’s AI-centric network vision positions AI not as an incremental improvement to mobile networks but as a foundational network architecture. That vision raises several critical questions for the IEEE community and IEEE Techblog readers:
-
Interoperability: How does Huawei’s AI-centric target network align—or conflict—with AI-RAN Alliance initiatives and O-RAN specifications?
-
Vendor Comparison: How does Huawei’s AI-centric target network compare with Ericsson’s cloud RAN strategy and Nokia’s Altiplano/Corteca agentic AI platforms in terms of technical architecture and commercial viability?
- Specifications and Standards: What role will 3GPP and ITU-R play in standardizing AI-native core network specifications, particularly for token monetization and compute-network integration?
- Autonomous Networks: How do Huawei’s domain-specific intelligence approaches compare with vendor-neutral SMO/rApp ecosystems, and what are the implications for multi-vendor interoperability?
-
Are carriers adequately prepared for the operational and cultural shifts required to transition from traffic monetization to token monetization?
-
How will U.S./European regulatory frameworks (e.g. spectrum policy, AI governance, data sovereignty) shape the deployment of AI-native networks compared to China’s more centralized approach?
- Spectrum Policy: With Upper 6 GHz emerging as a key enabler for AI-driven token services, what are the regulatory and coexistence challenges, particularly in regions yet to designate Upper 6 GHz for IMT 2030? What will WRC 2027 decide?
Conclusions:
Huawei’s roadmap underscores the ICT industry’s rapid shift towards AI token monetization, positioning 5G-Advanced high-uplink, AI-native networks, and Upper 6 GHz spectrum as the foundational pillars for the next decade of growth. The success of this vision depends not only on technological feasibility but also on standards alignment, regulatory support, and carrier willingness to reinvent business models—a complex challenge that warrants close scrutiny from the IEEE technical community.
……………………………………………………………………………………………………………………………………………………………………………………
References:
https://www.huawei.com/en/news/2026/6/mwcs-ai-byte-token
https://carrier.huawei.com/minisite/mwcs2026/en/
https://www.huawei.com/en/news/2026/6/mwcs-gsma-asac-5g-advanced
Huawei unveils AI Centric Network roadmap, U6 GHz products, 5G Advanced strategy and SuperPoD cluster computing platforms
Huawei FY2025: 2.2% YoY revenue increase; strategic pivot to AI and intelligent automotive solutions
Huawei, Qualcomm, Samsung, and Ericsson Leading Patent Race in $15 Billion 5G Licensing Market
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
Huawei launches CloudMatrix 384 AI System to rival Nvidia’s most advanced AI system
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Huawei Cloud Review and Global Sales Partner Policies for 2026
Huawei’s “FOUR NEW strategy” for carriers to be successful in AI era
Huawei to revolutionize network operations and maintenance
Huawei’s Electric Vehicle Charging Technology & Top 10 Charging Trends
Analysis: Cohere’s $28M U.S. DoD FutureG ISAC contract; OTFS vs OFDM; 6G-NR/IMT 2030 RIT standards outlook
Executive Summary:
Cohere Technologies has won a $28 million U.S. government contract funded by the FutureG Office within the U.S. Department of War (previously called the Defense Department or DoD) to develop a multi-waveform RAN prototype for integrated sensing and communications (ISAC), with Cohere’s Zak-OTFS as a core waveform alongside conventional OFDM [1]. The DoD award expands on a National Science Foundation VINES Phase 2 project. It will fund the development of a sovereign, mission-first ISAC capability that leverages existing and future commercial 5G/6G infrastructure to provide persistent aerial and ground surveillance while remaining indistinguishable from ordinary cellular traffic.
![]()
![]()
Mission: The contract is intended to turn commercial cellular infrastructure into a sensing layer for detection, tracking, and response applications, especially drone defense. Cohere says the prototype will support a multi-waveform software stack, a mobile test platform, and a layered inference sensing system that converts delay-Doppler data into real-time 3D tracks with classification and confidence scoring.
Cohere is positioning OTFS [2.] via its Pulsone/Zak-OTFS technology, as the waveform that better fits high-Doppler sensing and communications than plain OFDM. The company argues that OTFS carries information in the delay-Doppler domain, which is useful when the same signal must communicate and sense moving targets such as drones. If successful, this DoD funded ISAC demo could give OTFS a stronger credibility boost with standards bodies, equipment vendors, and defense customers, even if it does not immediately make OTFS a mainstream 3GPP waveform.
……………………………………………………………………………………………………………………………………………………………………………………………………………………….
Definitions and Comparison: OFDM vs. OTFS:
Note 1. OFDM (orthogonal frequency division multiplexing) is the 1D time-frequency workhorse that dominates WiFi, 4G and 5G because it is simpler, mature, and standardized by IEEE 802.11, ITU-R, and ETSI. OFDM maps data onto orthogonal subcarriers in the frequency domain, with symbols arranged over time and frequency; it is the basis of 4G LTE and is also used in 5G NR. OTFS maps data in the delay-Doppler domain and then spreads each symbol across the time-frequency plane, so the receiver sees a more invariant coupling to the channel under high Doppler and multipath.
Note 2. OTFS (orthogonal time frequency space) modulation is best thought of as a 2D, delay-Doppler-native waveform that Cohere has championed for highly mobile and doubly selective channels. It’s main advantage over OFDM is that it can make the channel look more stable to each symbol in fast-varying, high-Doppler environments, whereas OFDM excels when channels are relatively well-behaved and implementation efficiency matters most.
| Aspect | OTFS | OFDM |
|---|---|---|
| Best channel condition | High mobility, high Doppler, strong time variation | Quasi-stationary or modestly varying channels |
| Channel view | Delay-Doppler domain, more invariant symbol coupling | Time-frequency domain, channel varies per subcarrier/time slot |
| Equalization burden | Potentially easier in challenging channels, especially with mobility | Well understood and efficient in mainstream deployments |
| Standardization | Emerging, not yet the default cellular waveform comsoc+1 | Fully embedded in 4G/5G ecosystems |
| Maturity | Less mature, more research/prototype-driven | Very mature, widely deployed |
………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Quotes and Capabilities:
“ISAC is a mission-first priority for the U.S. Department of War to defend against drone swarms. Due to guidance from leadership to execute rapidly, we required a partner with the right technology ready today,” said Tom Rondeau, Principal Director for FutureG, OUSW(R&E). “As a proven innovator with a demonstrated ability to build multi-waveform platforms, Cohere Technologies offered a clear path that we could move on immediately. Their OTFS modulation carries information directly in the sensing domain, delivering massive communications and sensing performance advantages in high-Doppler environments. This solution rapidly delivers critical ISAC capabilities while building on our ‘innovate-first’ posture, demonstrating the tremendous opportunity for innovation brought by the FutureG Open Centralized Unit Distributed Unit (OCUDU) platform.”
The multi-waveform system prototype is designed to provide detection, classification, tracking, and defeat-cueing of drone threats while operating in commercial spectrum bands, making it difficult for adversaries to distinguish sensing activity from normal cellular communications. In addition to core defense applications-including battlefield awareness, border security, and critical infrastructure protection-the program will identify parallel commercial use cases such as Advanced Air Mobility, smart city traffic management, and public safety. Work under the contract will be executed in close collaboration with government technical authorities and program partners.
“This ISAC contract from DoW represents a major milestone for Cohere and for the future of dual-use wireless technology,” said Ray Dolan, Chairman and CEO of Cohere Technologies. “By combining our Pulsone Technology with conventional Orthogonal Frequency-Division Multiplexing (OFDM) in a flexible, software-defined architecture, we can deliver high-performance sensing that is affordable, scalable, and operationally invisible-exactly what is needed to counter the growing threat of sophisticated drone and Unmanned Aerial Systems (UAS).”
Key Capabilities to Be Developed Under the Program:
- A Multi-Waveform physical layer running on an open, extensible software stack that supports both traditional 4G and 5G OFDM and Pulsone Technology using the Zak-OTFS waveform.
- A Mobile Test Platform enabling bi-static and multi-static sensing configurations.
- A Layered Inference Sensing system that converts raw Delay-Doppler data into real-time 3D tracks with classification and confidence scoring.
- Realistic outdoor test environments supporting mono-static, bi-static, and multi-static sensing.
- Compliance with the FutureG OCUDU platform and Zero Trust security requirements.
“This ISAC project award validates Cohere’s long-term vision of building sovereign, future-proof wireless infrastructure that serves both national security and commercial markets,” Dolan added. “We are proud to work alongside the FutureG Office and partners to deliver technology that strengthens our nation’s ability to sense and respond in contested environments.”
Cohere and the FutureG Office are considering commercial applications like Advanced Air Mobility traffic management, smart-city applications, and public safety are all named as potential adjacent markets, continuing the dual-use framing the Pentagon has increasingly favored for next-gen wireless R&D.
………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Caveats and 6G NR/IMT 2030 RIT Standards Outlook:
The public information so far is largely company-announced, so the contract details, schedule, and technical requirements should be treated as initial disclosures rather than a full program specification. Also, the award appears to fund a prototype and operational demonstration, not a guaranteed path to standards adoption or mass deployment. While it is certainly possible for OTFS to be accepted as an IMT 2030 RIT (Radio Interface Technology), 3GPPs submission (via ATIS) to ITU-R WP5D will almost surely be OFDM based version of 6G NR.
ITU-R WP 5D has published the IMT-2030 roadmap and invited RIT-candidate submissions in the 02/2027 to 02/2029 window, so the process is still open to proposals. WP 5D’s role is to define the overall radio system aspects for IMT, but it does not itself guarantee adoption of any one waveform; candidates must survive technical performance requirements, evaluation criteria, and national/industry consensus. That means OTFS can still be proposed, but it would need to show clear benefits under the evaluation framework and broad support from proponents.
To get adopted, OTFS would need to prove more than attractive simulation results. It would need implementable receiver complexity, backward-compatible deployment pathways, acceptable PAPR and synchronization behavior, and a compelling story for mass-market devices, not just high-mobility or ISAC use cases. The literature and industry commentary generally position OTFS as strongest where Doppler and sensing matter most, which helps its case but may also narrow its scope.
The most realistic 6G/IMT 2030 standards scenario is:
-
3GPP keeps OFDM-family waveforms as the baseline for 6G NR.
-
OTFS remains active in research, patents, and trial implementations.
-
OTFS is considered for targeted IMT-2030 RIT use cases such as high mobility, NTN, or integrated sensing and communications, rather than universal deployment.
Conclusions:
The U.S. government is backing Cohere’s OTFS-centered ISAC concept with real funding, and the strategic aim is to fuse communications and sensing in a way that is harder for drones or other threats to detect. For OTFS, that is a meaningful validation event, but still a prototype-stage win rather than proof of broad cellular standardization.
Cohere’s OTFS is not “better OFDM”; it is a different design point optimized for a harder channel model. OFDM remains the incumbent because it is standardized and efficient, but OTFS has a credible technical case where Doppler and channel variation are the real bottlenecks.
………………………………………………………………………………………………………………………………………………………………………………………………………………………..
About Cohere Technologies:
Cohere is the innovator of Universal Spectrum Multiplier (USM) software for 4G, 5G, and Multi-G. USM significantly improves mobile networks in any FDD and TDD spectrum band – and Pulsone™ Technology which is based on the Zak-OTFS waveform for ISAC and NTN. Pulsone is a trademark of Cohere Technologies. Cohere is headquartered in San Jose, Calif. (USA). www.cohere-tech.com
About the FutureG Office:
The FutureG Office within the Office of the Under Secretary of War for Research and Engineering is responsible for the strategic assessment and research and development of FutureG technologies to confer long-term economic, military and security advantages to the United States of America and its allies. By strengthening and developing relationships with private industry, academia, interagency and international allies and partners, the FutureG Office promotes the use of common, commercial standards for DoW operations, encourages adoption of open and interoperable technologies, and advances critical next-generation wireless network capabilities.
About the OCUDU Ecosystem Foundation:
The OCUDU Ecosystem Foundation, hosted by the Linux Foundation, is a global public-private initiative dedicated to building a commercial and research ecosystem around a production-ready, open source CU/DU stack. By fostering collaboration across the entire RAN lifecycle, from R&D to end-to-end integration, the OCUDU Ecosystem Foundation provides the reference architectures, conformance tooling, and “super blueprints” required to scale Open RAN from pilot projects to global production.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
https://www.lightreading.com/6g/us-defense-dept-backs-6g-rival-to-tech-used-by-ericsson-and-nokia
Cohere Technologies bags $28M DoW deal to turn cell sites into drone-spotting sensors
https://rt.cto.mil/ddre-rt/science-and-technology-futures/futureg-home/
Multi-G Initiative to drive Open RAN Software Interfaces and increase innovation
Bloomberg: Meta to sell AI compute in a new cloud services offering
Disclaimer: Perplexity.ai was used for research resulting in this article.
Executive Summary:
According to Bloomberg, Meta Platforms is advancing plans to commercialize its internal AI infrastructure through a new cloud services offering, signaling a strategic expansion beyond its traditional hyperscale consumer platforms into the competitive AI infrastructure market. This initiative would position Meta alongside established cloud providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, while also overlapping with emerging GPU-centric “neocloud” providers. Meta’s move represents a significant evolution in the AI infrastructure landscape, with potential ripple effects across data center architecture, optical transport networks, and the broader telecom ecosystem.
At the core of this strategy is the monetization of Meta’s rapidly expanding AI compute footprint. The company has aggressively invested in large-scale data center infrastructure—reportedly including multi-hundred-billion-dollar campus developments—to support training and inference for its proprietary large language models (LLMs) and recommendation systems. As these deployments scale, Meta appears to be seeking to externalize surplus capacity, transforming a cost center into a revenue-generating platform.
The proposed service portfolio is expected to span two primary layers. First, Meta may expose access to hosted AI models via APIs, analogous to AWS Bedrock or Azure AI Services, enabling enterprises to integrate generative AI and foundation model capabilities without managing underlying infrastructure. Second, Meta is exploring the provision of raw compute capacity—primarily GPU-accelerated workloads—mirroring the infrastructure-as-a-service (IaaS) model offered by neocloud providers such as CoreWeave. This dual-layer approach would allow Meta to compete both in higher-margin AI platform services and in lower-level compute provisioning.
Telecom & Networking Implications:
From a telecom and network infrastructure perspective, this development has several implications. Hyperscale AI workloads are increasingly bandwidth-intensive, requiring high-capacity, low-latency interconnects within and between data centers. Meta’s investments are therefore likely to drive demand for advanced optical networking technologies, including coherent pluggable optics (e.g., 400ZR/800ZR), data center interconnect (DCI) architectures, and AI-optimized fabric designs leveraging Ethernet-based scale-out topologies. In addition, the geographic placement of these data centers—often in power-abundant, rural locations—introduces new requirements for long-haul fiber connectivity and edge aggregation.
The initiative, internally referred to as “Meta Compute,” reflects a broader industry shift toward vertically integrated AI infrastructure stacks, where hyperscalers tightly couple compute, networking, and software frameworks. For telecom operators and infrastructure vendors, this trend underscores the growing convergence between cloud, AI, and network domains, particularly as AI-driven workloads begin to influence traffic patterns, peering strategies, and edge deployment models.
Strategically, Meta’s entry into the AI cloud market raises competitive pressure across multiple fronts. Unlike traditional cloud providers, Meta brings extensive experience in hyperscale distributed systems and open-source AI frameworks (e.g., PyTorch), but lacks a mature enterprise cloud ecosystem. Its success will likely depend on its ability to translate internal infrastructure efficiencies into externally consumable services, while addressing enterprise requirements for reliability, security, and service-level agreements.
Meta’s cloud push is best viewed as a network-and-infrastructure strategy as much as a software business, because monetizing AI capacity depends on how well it can expose compute, move data, and preserve performance at hyperscale. The telecom significance is that Meta is turning internal AI infrastructure into a market-facing platform, which increases the importance of optical transport, data-center interconnect, and low-latency backbone engineering.
From a telecom perspective, the key issue is not simply that Meta may sell AI models or GPU capacity; it is that the company is building a service layer on top of a very large, power- and bandwidth-intensive distributed system. Reuters reported that Meta is considering both hosted model access and raw compute sales, with the former resembling an AI platform service and the latter looking more like neocloud infrastructure.That means the network becomes part of Meta’s product offering. Large AI inference and training environments require high-bisection fabrics inside the data center, plus dense east-west traffic handling, which pushes demand for faster Ethernet switching, advanced optical modules, and carefully engineered rack-to-rack and site-to-site interconnects. Meta’s AI cloud ambitions reinforce a broader shift: hyperscalers are no longer treating networking as a background utility, but as a primary constraint on scale.
Network World’s coverage of Meta Compute notes that Meta has unified data center and network oversight and is planning multi-gigawatt AI buildouts, underscoring how tightly power, fiber, switching, and facility design are now linked.
For network operators and vendors, that translates into stronger demand for long-haul fiber, DCI platforms, low-latency transport, and high-radix switching. It also raises the strategic value of metro and regional interconnect corridors that can support AI clusters, especially when capacity must be spread across multiple sites for power, land, or resiliency reasons.
Meta’s potential move into raw compute sales is especially relevant to telecom because it resembles the economics of infrastructure-heavy cloud and colocation models. In practice, the service quality will depend on how efficiently Meta can provision GPU clusters, maintain deterministic performance, and avoid congestion across the transport layer connecting those clusters. That implies growing importance for:
-
Coherent optical transport and scalable DCI.
-
High-capacity Ethernet fabrics for AI clusters.
-
Open-rack and disaggregated infrastructure designs.
-
Network automation that can track workload placement and traffic hotspots.
These are not just cloud concerns; they are telecom-grade capacity-planning problems. As AI clusters become larger and more distributed, network planning starts to look more like core network engineering than conventional enterprise hosting.

Image Credits: Gabby Jones/Bloomberg / Getty Images
……………………………………………………………………………………………………………………………………………………………………..
Conclusions:
Meta’s entry would not only compete with AWS, Azure, and Google Cloud, but could also pressure specialized neocloud providers more directly. Reuters noted that Meta’s spare capacity could matter more to neo-cloud vendors than to the largest hyperscalers, because those providers rely on access to external GPU supply and managed infrastructure growth. For telecom analysts, that suggests the competitive battleground is shifting from “who has the best model” to “who can deliver the most resilient compute-network-power stack.” The winners will likely be those that can couple AI accelerators with fiber-rich sites, robust interconnect, and energy-secure data center footprints.
Meta’s move reflects the convergence of cloud, AI, and transport networks. The story is less about Meta becoming a generic cloud vendor and more about hyperscale AI infrastructure evolving into a new class of network-dependent utility. Indeed, Meta’s cloud initiative highlights a broader industry reality — in the AI era, compute is valuable, but connectivity, optical scale, and power-aware architecture increasingly determine whether compute can be monetized at all.
……………………………………………………………………………………………………………………………………….
References:
Meta, like SpaceX, looks to turn excess AI compute into cash
https://www.cnbc.com/2026/05/27/mark-zuckerberg-says-meta-starting-cloud-business-on-the-table.html
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
OCP 2025 Meta keynote: Scaling the AI Infrastructure to Data Center Regions
TechCrunch: Meta to build $10 billion Subsea Cable to manage its global data traffic
AI Frenzy Backgrounder; Review of AI Products and Services from Nvidia, Microsoft, Amazon, Google and Meta; Conclusions
Bharti Airtel and Meta extend 2Africa Pearls subsea cable system to India
Is AI the driving force behind the metaverse?
Dell’Oro: AI RAN revenue forecast: $35B from 2026-to-2030; 3 types of AI RAN explained
According to a new AI RAN Advanced Research Report published by Dell’Oro Group, cumulative AI RAN revenue is projected to reach $35 B over the next five years (2026-2030). However, AI RAN is not expected to expand the overall RAN market.
“Our market assessment and long-term AI RAN position remain unchanged,” said Stefan Pongratz, Vice President at Dell’Oro Group. “AI RAN is already happening and will scale ahead of 6G. At the same time, these tools will enhance the RAN, but they are unlikely to expand the overall RAN market. Even as suppliers introduce new software-based subscription models, we expect AI RAN to generate little, if any, incremental RAN revenue the end of the forecast period,” continued Pongratz.
Additional highlights from the June 2026 AI RAN Advanced Research Report:
- The base-case forecast assumes that AI RAN will not expand the RAN market. Nevertheless, AI RAN is expected to become an important technology enabler as operators incorporate greater virtualization, intelligence, automation, and O-RAN capabilities into their RAN roadmaps.
- GPU RAN projections have been revised upward—GPU RAN is now expected to be a $1 B+ market by the end of the forecast period.
- In the near term, the AI RAN market will remain centered on AI-for-RAN, single-purpose deployments, non-GPU architectures, D-RAN, and 5G.
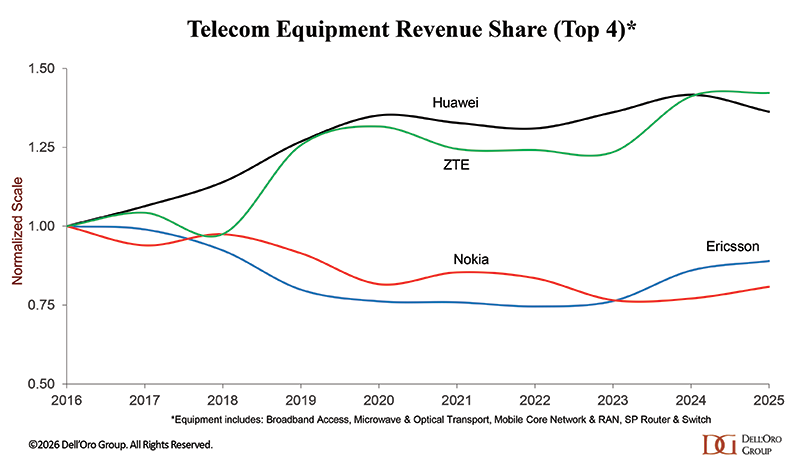
- Incumbent RAN radio and baseband suppliers are well-positioned in the initial AI RAN phase, driven primarily by AI-for-RAN upgrades leveraging existing hardware. Per Dell’Oro Group’s regular RAN coverage, the top five RAN suppliers contributed approximately 96 percent of 2025 RAN revenue. See charts below.
Dell’Oro Group’s AI RAN Advanced Research Report includes a 5-year forecast for AI RAN by location, tenancy, technology, and region. To purchase this report, please contact us at [email protected].
………………………………………………………………………………………………………………………………………………………………………….
Total & Wireless Telecom Equipment Revenue- top 4 and top 3:

………………………………………………………………………………………………………………………………………………………………………………….
Analysis (Source: Perplexity.ai AND Google Gemini):
There are three versions of AI-RAN which are not mutually exclusive:
- AI for RAN: Embeds AI into the base software stack to automatically manage radio waves, optimize spectrum efficiency, enhance beamforming, and reduce energy consumption in real time. Nokia, Ericsson, NVIDIA.
- AI on RAN: Uses cell towers and base stations as decentralized computing nodes. This allows telecom networks to host AI workloads locally rather than sending all data to distant cloud servers, providing ultra-low latency for applications like robotics, AR/VR, and autonomous vehicles. Nokia, NVIDIA, and operator trial partners like T-Mobile, Indosat, and SoftBank.
- AI and RAN: Combines the two to support “Networks for AI,” where distributed telecom networks act as an active, intelligent backbone to serve end-user AI traffic. AI-RAN Alliance plus Nokia and NVIDIA as the most visible industry champions.
References:
AI RAN to Reach $35 B Over Next Five Years, According to Dell’Oro Group
NVIDIA AI RAN video: youtube.com/watch?v=hwLLBfzoSko&t=26
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
Ericsson goes with custom silicon (rather than Nvidia GPUs) for AI RAN
Dell’Oro: RAN Market Stabilized in 2025 with 1% CAG forecast over next 5 years; Opinion on AI RAN, 5G Advanced, 6G RAN/Core risks
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Dell’Oro: AI RAN to account for 1/3 of RAN market by 2029; AI RAN Alliance membership increases but few telcos have joined
Dell’Oro: RAN revenue growth in 1Q2025; AI RAN is a conundrum
Analysis of AWS-3 Spectrum Results: Verizon Wins Big; Urban Capacity vs. Propagation
AWS-3 Auction Results:
Of the $3.57 billion total spent in the recent AWS-3 auction, $3.2 billion of it was accounted for by Verizon alone (bidding as Cellco Partnership). That bought it 82 of the 200 licenses on offer, with the price premium explained by a bias towards high value urban licenses. The remaining AWS-3 spectrum allocation was primarily secured by T-Mobile and, to a lesser extent, AT&T. SpaceX bid conservatively, indicating its recent spectrum acquisitions from Dish Networks will likely serve as supplementary capacity rather than signaling a shift to build a comprehensive, standalone terrestrial mobile network.
T-Mobile took home more raw licenses than Verizon, but spent a fraction of the capital. This architectural split is dictated by existing network layouts. T-Mobile used its capital to snap up cheap, fragmented regional licenses to patch coverage holes in its massive 2.5 GHz (Band 41) rural backbone. Conversely, Verizon spent heavily because its existing grid configuration requires deeper, cleaner mid-band spectrum to keep up with urban data density without triggering catastrophic inter-cell interference.
Here’s a breakdown of winning bids and assigned spectrum:
| Carrier | Licenses Won | Total Spend | Strategic Context |
|---|---|---|---|
| Verizon | 82 | $3.20 billion | Dominant bidder to acquire significant mid-band capacity. |
| T-Mobile | 102 | $278 million | Acquired the largest volume of licenses for rural and edge-market coverage. |
| AT&T | 10 | $121 million | Targeted smaller holdings to bolster localized network capacity. |
| SpaceX | 2 | $8.5 million | Acquired two regional licenses to complement supplemental coverage from space (SCS) initiatives. |
Here are the full results, published by the FCC:

“After years on the sidelines, FCC auctions are finally back,” said Chairman Brendan Carr. “Today’s successful auction generated billions of dollars in competitive bids to put spectrum to effective commercial use, and it bolsters competition in the wireless marketplace. We will carry this momentum forward as we prepare for the Upper C-Band auction in the year ahead.”
“Up to $3.3B of the auction’s proceeds will be used to cover amounts borrowed to support the FCC’s “rip and replace” program and other Commerce Department programs,” said the FCC press release. “The auction made available 200 spectrum licenses in the 1695-1710 MHz, 1755-1780 MHz, and 2155-2180 MHz bands which were subject to bid defaults or bid withdrawals in the 2014 auction and thus have remained unused in the FCC’s inventory since then.”
………………………………………………………………………………………………………………………………………………………………………………..
Let’s examine how cellular network operators are navigating the fundamental physics of RF propagation:
As 5G networks transition from initial deployment to hyper-dense optimization, Auction 113 highlights a widening divergence in network architecture strategies: Verizon’s aggressive pursuit of premium urban capacity versus T-Mobile’s tactical rural densification.
The Physics of the Premium: Why Verizon Paid Up for AWS-3
To the casual observer, Verizon’s multi-billion-dollar bet on AWS-3 (operating in the 1.7 GHz uplink / 2.1 GHz downlink bands) seems redundant given their massive 2021 C-band (3.7 GHz) holdings. However, looking at the link budget reveals that all mid-band spectrum is not created equal.
[1.7 GHz / 2.1 GHz (AWS-3)] ---> Lower Path Loss, Better Indoor Penetration
[3.7 GHz (C-Band)] ---> Higher Path Loss, Requires High Node Density
By securing AWS-3 blocks in high-density markets like New York, Boston, and Chicago, Verizon is solving a specific structural challenge in urban network topology:
- Free-Space Path Loss (FSPL): Operating at 1.7/2.1 GHz provides a significant propagation advantage over 3.7 GHz. According to the Friis transmission equation, signal attenuation increases with the square of the frequency. Moving from 3.7 GHz down to 1.7 GHz yields a theoretical path loss improvement of nearly 6 to 7 dB, drastically extending the effective cell radius.
- Building Penetration Indices: Higher-frequency C-band signals suffer from severe attenuation when interacting with concrete, low-E glass, and brick. AWS-3 signals possess longer wavelengths that penetrate urban building envelopes far more effectively, reducing the reliance on costly indoor small-cell deployments.
- Offloading the Core: Rather than burning valuable C-band capacity on edge-case indoor users with degraded Signal-to-Interference-plus-Noise Ratios (SINR), Verizon can utilize the AWS-3 layer to maintain robust, high-throughput indoor links, preserving the 3.7 GHz layer for line-of-sight macro capacity.
For RF engineers tracking the convergence of terrestrial and non-terrestrial networks (NTN), the most intriguing data point from Auction 113 was SpaceX’s calculated acquisition of two specific licenses—including the Gulf of Mexico footprint—for $8.5 million. This move offers critical clues regarding SpaceX’s Direct-to-Cell (D2C) Starlink framework. Fresh off its multi-billion-dollar spectrum onboarding from EchoStar, SpaceX is systematically hunting for terrestrial frequencies that can act as a safety valve. Winning the Gulf of Mexico AWS-3 block allows SpaceX to establish a seamless, interference-free maritime D2C testing ground. This block can bridge terrestrial terrestrial networks and satellite-to-phone links without violating the strict aggregate interference power-flux-density (PFD) limits imposed near land borders.
Engineering the Transition: Funding “Rip and Replace”:
Beyond network topology, Auction 113 serves a vital national security engineering mandate. Up to $3.3 billion of the auction’s proceeds are legally earmarked to fill the funding shortfall for the FCC’s Secure and Trusted Communications Networks Reimbursement Program.
For hundreds of regional and rural operators, this influx of capital directly funds the complex hardware migration away from legacy, non-compliant Huawei and ZTE cellular access networks. Engineers are replacing proprietary, single-vendor base stations with modern, Open RAN-ready or fully compliant Ericsson, Nokia, and Samsung network infrastructure—effectively rewriting the physical layer of rural American telecom.
Conclusions:
Auction 113 proves that even in an era dominated by software-defined networking and cloud-native cores, physical layer mechanics dictate market value. Verizon’s $3.16 billion investment confirms that superior propagation characteristics and favorable link budgets still command a premium. As carriers race to deliver uniform 5G performance indoors and out, AWS-3 remains an elite tier of wireless real estate where engineering reality justifies the corporate price tag.
References:
https://www.telecoms.com/spectrum/verizon-was-the-big-spender-at-the-aws-3-spectrum-auction
https://www.fierce-network.com/wireless/verizon-emerges-biggest-winner-aws-3-auction
Federal Communications Commission, “Auction of Advanced Wireless Services (AWS-3) Licenses Closes; Winning Bidders Announced for Auction 113,” FCC Public Notice (DA-26-633), Jun. 26, 2026. Available: FCC Official Document Announcement
M. Alleven, “Verizon emerges as biggest winner in AWS-3 auction,” Fierce Network, Jun. 29, 2026. Available: Fierce Network Article
F. Rayal, “Big Carriers Get Selective: Lessons from the $3.57 Billion AWS-3 Auction 113,” Frank Rayal Telecom Insights, Jun. 28, 2026. Available: Frank Rayal Strategic Analysis
G. Winslow, “FCC Raises $3.5 Billion in AWS-3 Wireless Auction,” TV Tech, Jun. 24, 2026. Available: TV Technology Regulatory Report
Reuters, “U.S. spectrum auction raises $3.5 billion, will fund replacing Chinese telecom equipment,” Yahoo Finance, Jun. 23, 2026. Available: Yahoo Finance / Reuters Coverage
SatNews Publishers, “$3.57 Billion Milestone: FCC Advanced Wireless Services (AWS-3) Spectrum Auction Concludes,” SatNews Space & Satellite Media, Jun. 24, 2026. Available: SatNews Auction Summary
Morningstar Equity Research, “US Telecom: Verizon Shells Out $3 Billion for Spectrum as SpaceX Treads Lightly,” Morningstar Investor, Jun. 29, 2026.
FT: SpaceX considering Starlink Direct-to-Consumer mobile service & terrestrial cellular network infrastructure in the U.S.
According to the Financial Times (FT), SpaceX is evaluating a strategic expansion of its Starlink satellite Internet service to include a direct-to-consumer mobile service in the United States, a move that could materially disrupt the established U.S. mobile network market. According to sources familiar with recent IPO roadshow discussions, President and COO Gwynne Shotwell indicated that the company is considering both a retail Starlink mobile offering and the potential development of a terrestrial cellular network infrastructure.
Such a shift would represent a transition from SpaceX’s current wholesale and partnership-driven model—where Starlink satellite capacity is integrated with incumbent MNO networks—to a vertically integrated retail service directly competing with Verizon, AT&T, and T-Mobile. To date, Starlink’s U.S. mobility strategy has primarily relied on enabling partner operators, notably T-Mobile, to extend coverage in underserved and rural areas via satellite augmentation.
Although commercial terms remain undisclosed, industry analysts infer that Starlink currently participates in revenue-sharing arrangements tied to satellite-enabled service tiers. A direct retail model would enable SpaceX to capture a larger share of end-user revenue while reducing dependence on intermediary operators.
……………………………………………………………………………………………………………………………………………………………………………………………….
Here are some details, as reported by Reuters:
-
SpaceX already offers direct-to-cell connectivity with T-Mobile in the U.S., providing supplemental coverage from space to extend internet access to remote areas. [1.]
-
SpaceX is now considering launching a Starlink retail product and could build its own terrestrial U.S. mobile network, President Gwynne Shotwell told investors during a recent IPO roadshow, the FT report said, citing sources.
-
Reuters could not immediately verify the report. SpaceX did not immediately respond to a Reuters request for comment outside regular business hours.
-
In September last year, SpaceX bought wireless spectrum licenses from EchoStar for its Starlink satellite network for about $17 billion and then again for $2.6 billion in November, giving it the ability to quickly create a strong and affordable direct-to-cell service by using EchoStar’s wireless airwaves.
-
SpaceX will disrupt the $1.6 trillion U.S. communications industry as its satellite broadband unit Starlink expands, brokerage firm Oppenheimer said in a note earlier this month.
-
SpaceX’s record valuation is grounded in Starlink, which has over 10 million subscribers, and a launch business that analysts and investors say has transformed access to orbit.
Note 1. T-Mobile US D2D service has lower than expected usage:
During T-Mobile US’s recent earnings call, CEO Srini Gopalan admitted that just under a year after its commercial launch, T-Satellite is experiencing lower-than-predicted usage. However, he put a very positive spin on the situation, insisting that the technology is doing exactly what it was designed for.
“Our partnership with SpaceX is very strong. We’ve worked closely with them to really invent an entire category, and that’s been putting an end to dead zones. We’re pleased with that,” Gopalan said.
“Most of the usage we’re seeing is in national parks and if anything, courtesy of the great network Dr Saw has built, we’re seeing a lot less usage than we were originally thinking,” he admitted, referring to Chief Technology Officer John Saw. “But it’s a great complementary product.”
……………………………………………………………………………………………………………………………………………………………………………………………….

SpaceX Satellite Launch using Falcon 9 Rocket. Image Credit: Space Center Houston
This potential expansion follows SpaceX’s recent IPO, which has intensified investor expectations for accelerated revenue growth and diversification. Starlink already operates in more than 150 countries, delivering broadband services via LEO satellite constellations, with approximately 10.3 million global subscribers as of March. A U.S. mobile retail offering would significantly expand its addressable market beyond fixed satellite broadband.
Importantly, SpaceX has not publicly confirmed plans to launch a retail mobile service. However, speculation has increased following its $17 billion acquisition of wireless spectrum licenses from EchoStar in September, widely interpreted as a foundational step toward mobility services. In its bond prospectus, the company noted that while Starlink Mobile is currently expected “to be most impactful for customers in remote areas uncovered by terrestrial mobile networks,” its long-term positioning is more expansive, stating it would “compete to be the preferred connectivity experience to our customers no matter where they are located, whether in rural, suburban or urban areas.”
Despite the strategic rationale, significant technical and economic barriers remain. U.S. MNOs collectively control approximately 1,020 MHz of spectrum, compared to SpaceX’s estimated 65 MHz, according to New Street Research. This disparity highlights the challenges associated with scaling a competitive terrestrial mobile network, particularly in spectrum-constrained and highly saturated markets.
David Barden of New Street Research emphasized the difficulty of such an undertaking, noting that building a “wireless network in saturated markets around the world would be incredibly hard.” However, he added that “[But,] as a starting point for negotiating the best possible revenue-sharing deal with mobile network operator partners? It makes tremendous sense.”
Conclusions:
While a Starlink retail mobile service offering could redefine the company’s role in the telecom value chain, near-term implementation would likely require a hybrid model leveraging both satellite and terrestrial assets, alongside continued strategic partnerships with incumbent operators.
The most useful follow-on question is whether “terrestrial cellular network infrastructure” means acquiring spectrum, building or buying towers, or simply partnering for access and backhaul. If it means an owned network, the economics look very different from satellite direct-to-device: capital spend rises, time-to-scale slows, and the business starts competing head-on with Verizon, AT&T, and T-Mobile instead of complementing them. If it means a hybrid model, then the more plausible path is a bundled satellite-plus-terrestrial offering targeted at coverage gaps, mobility, and emergency connectivity rather than a nationwide full replacement.
The strategic significance of the FT report is not simply another Starlink service tier, but a possible shift from supplemental coverage provider to vertically integrated U.S. mobile operator, with major implications for spectrum policy, carrier competition, and infrastructure investment.
……………………………………………………………………………………………………………………………………….
References:
https://www.ft.com/content/42af0f15-3aa9-49b7-b429-4a39540af03e?syn-25a6b1a6=1 (paywall)
Ookla: Starlink a viable competitor for hybrid 5G/NTN services due to network performance improvements and larger coverage area
Ookla: D2D satellite connectivity surged 24.5% during last 9 months; Starlink’s footprint expansion leads the way
US Mobile’s new bundle combines its multi-network mobile service with Starlink residential internet
Tutorial: LEO Satellite Internet connectivity, D2D, and major providers
Direct-to-Device (D2D) satellite network comparison: Starlink V2 (Starlink Mobile) vs “Satellite Connect Europe”
Starlink doubles subscriber base; expands to to 42 new countries, territories & markets
Elon Musk: Starlink could become a global mobile carrier; 2 year timeframe for new smartphones
GEO satellite internet from HughesNet and Viasat can’t compete with LEO Starlink in speed or latency
U.S. BEAD overhaul to benefit Starlink/SpaceX at the expense of fiber broadband providers
Telstra selects SpaceX’s Starlink to bring Satellite-to-Mobile text messaging to its customers in Australia
SpaceX launches first set of Starlink satellites with direct-to-cell capabilities
Blue Origin announces TeraWave – satellite internet rival for Starlink and Amazon Leo
Assessing LPWANs for IoT: NB-IoT, 4G LTE versions, 5G Redcap and LoRa WAN
Introduction – LPWANs (Low Power Wide Area Networks):
In April 2011, Cisco soothsayer Dave Evans predicted there would be 50 billion IoT devices in the world by 2020. Yet in 2025, there were only 22.3 billion IoT devices worldwide, according to the Ericsson Mobility Report. Evans forecast was off by 27.7 billion five years after the date for the 50 billion to be realized (2020). The real shocker was just how few of those devices used cellular networks for connectivity – 4.5 billion (again, Ericsson is the source). To add insult to injury, between 600 and 700 million of those cellular IoT connections used much older 2G and 3G systems, according to a chart in Ericsson’s Mobility report. The rest were split between what Ericsson calls “massive” IoT [NB-IoT]-and a separate category of broadband and critical IoT [5G RedCap, LTE Cat-1 and Cat-1 bis standards].
LoRaWAN, which exclusively uses unlicensed sub-gigahertz radio frequency spectrum, was not included in the Ericsson report, but is analyzed in this article (see LoRaWAN subhead below).
Narrow Band IoT (NB-IoT):
NB-IoT was first introduced in 3GPP Release 13 in June 2016. 3GPP Release 18 & 19 (2024–2026) provided physical layer enhancements for NB-IoT NTN, focusing on uplink capacity expansions and time-division duplex (TDD). Also, NB-IoT is included in the ITU-R M.2150 5G RIT/SRIT standard. According to the Ericsson report, NB-IoT accounted for only 1.3 billion IoT connections last year. Most are in China, where the government appears to have mandated rollout of NB-IoT to support Huawei, one of the technology’s original backers. In mid-2024, Omdia analysts, said that China was responsible for 90% of all NB-IoT connections worldwide! Regarding NB-IoT, Japan’s NTT Docomo switched off an NB-IoT network in 2020. AT&T decommissioned its NB-IoT network last year, saying it preferred LTE Cat-M.
NB-IoT still has meaningful deployments in Europe and other regions, especially in utilities and smart-metering, and roaming partnerships have improved its prospects. Omdia also reported that NB-IoT and LoRa together dominated LPWAN connections, with NB-IoT’s growth driven heavily by China but still expanding elsewhere. So the technology itself is alive; the issue is that its non-China commercial traction has been much weaker than its original promise.
The main problem was not radio performance so much as ecosystem economics. Outside of China, carriers often did not price NB-IoT aggressively enough for low-ARPU sensor use cases, and the lack of seamless roaming made global deployments harder than they needed to be. In practice, that left LoRaWAN with a freer runway in many regions, especially for private networks. In conclusion, NB-IoT has been a commercial underperformer outside China, but not a dead LPWAN. Its non-China adoption has been real but fragmented, while China became the scale engine that kept the standard commercially relevant.

Image Credit: Emnify
4G LTE Versions for IoT:
- LTE Cat 1 / Cat 1 bis: For medium-speed IoT (10 Mbps) like telematics, e-bikes, and POS terminals.
- LTE Cat M1 (LTE-M): For low-power, mobile IoT (1 Mbps) supporting voice and firmware updates.
5G RedCap:
As with earlier forms of IoT, one of the big problems with 5G RedCap (5G reduced capability) is module pricing. Any IoT connection generates far less in revenues than any smartphone, and component prices must also be sufficiently low for connecting large volumes of objects to be economical. Even if RedCap is reserved for higher-end devices, such as the Apple Watch, the hardware for it remains too expensive, according to Omdia. In a research note emailed this week, it complains that “adoption has been limited by high module prices.” Omdia says the real constraint is the slow rollout in some countries of 5G SA, without which RedCap won’t work. Numerous mobile network operators (MNOs) have not even launched 5G SA, explaining the displeasure of Ericsson’s CEO. While take-up is especially low in Europe, it is also down at 50% in the U.S., compared with 98% in China, according to Ericsson’s Ekholm.
A new report on 6G by the NGMN Alliance, a club of prominent telcos said, “It should be noted that some MNOs may struggle to identify clear value to migrate to 5G SA, after initially deploying 5G NSA.” Omdia has a much gloomier outlook for IoT than Ericsson. The Swedish vendor currently forecasts the overall number of cellular IoT connections will grow to 7.8 billion by 2031. Omdia does not expect the figure to reach 5.9 billion until 2035, by which stage 6G networks are likely to have been in commercial operation for some five or six years.
……………………………………………………………………………………………………………………………………………..
Proprietary LPWANs Using Unlicensed Spectrum:
1. Sigfox pioneered the concept of LPWANs for IoT. It was founded in 2009 by French entrepreneurs Ludovic Le Moan and Christophe Fourtet in Labège, near Toulouse, France (an area later dubbed “IoT Valley”). While the telecom industry chased high-speed 4G LTE and WiMax, Sigfox did the exact opposite. They built a lightweight protocol optimized for extremely tiny, infrequent messages (just 12 bytes per upload). This allowed endpoints to be extraordinarily cheap and operate on a single battery for over a decade. Sigfox adopted a “top-down” model. It acted as a global network operator, partnering with local companies (Sigfox Operators) to build physical cell towers worldwide. Starting in 2019, Sigfox faced intense competition from LoRaWAN (which offered an open, decentralized model where companies could build private networks) and cellular standards like NB-IoT and LTE-M, which were backed by massive telecom operators. In 2022, the firm filed for bankruptcy protection, before its assets were acquired by Singapore’s UnaBiz.
However imperfect, its business model was at least geared to IoT, which is not the case for nearly every mainstream mobile network operator (MNO). Financial reports from some major telcos have shown IoT contributing as little as 1% or 2% of total service revenues. When the returns are so minuscule, the commercial incentive remains weak.
2. LoRaWAN has been a success in its target markets, though it is not a universal mass-market wireless technology. A February 2026 LoRa Alliance report says LoRaWAN reached 125 million deployed devices globally, grew at a 25% CAGR, and is now used at scale in utilities, smart buildings, agriculture, and critical infrastructure. The evidence points to sustained adoption rather than a one-off technology spike. The LoRa Alliance says the ecosystem reached 360 members, surpassed 625 certified devices, and supports multi-million-device networks from multiple operators and vendors. Its 2024 report also cites more than 350 million end nodes and 6.9 million gateways with LoRa ICs deployed worldwide, plus use by major brands such as Starbucks, Volvo, Chevron, Chick-fil-A, and Logitech.
- LoRaWAN appears strongest in low-power, long-range, intermittent-data use cases. The 2025 report says utilities remain the largest vertical, smart buildings are a leading segment, and NTN/satellite-enabled.
- LoRaWAN is now commercially available from three service providers. That pattern suggests strong product-market fit for massive IoT, not for high-throughput consumer connectivity.
“Success” depends on the benchmark. If the bar is “won the IoT LPWAN market and built a durable ecosystem,” then yes; if the bar is “became a giant mainstream telecom platform,” then no. Independent commentary has also noted that some LoRaWAN companies have had uneven revenue growth and market acceptance even as deployments expanded.
In conclusion, LoRaWAN has been a commercial success in LPWAN/IoT, especially for private and enterprise deployments, but it remains a specialized niche rather than a broad consumer-wireless winner. The biggest adoption difference is that LoRaWAN has tended to win in private, operator-independent deployments, while NB-IoT has tended to win where carrier coverage and cellular integration matter. LoRaWAN adoption is often driven by enterprises, municipalities, and industrial users building their own networks or using community/public LoRa networks, whereas NB-IoT adoption is usually tied to mobile operators and SIM-based service models.tektelic+2
Here is a compact adoption-oriented comparison (Source: Google Gemini):
Here is a ranking for number of connections / scalability across LPWANs, using publicly available vendor/whitepaper comparisons. Because these systems are designed differently, this is best read as a relative ranking, not a single absolute device-count limit (Source: Perplexity.ai)
From Iain Morris, International Editor, Light Reading:
With 6G slowly approaching, the market is still held back by high module prices, inadequate coverage and support, and technological bewilderment, as the options continue to mushroom. Adoption is unsurprisingly not at the level that cellular IoT’s enthusiasts likely hoped for years ago. Yet the 6G story, paradoxically, seems to be all about new device types, from smart glasses to humanoids and other such physical AI.
Hence talk in Ericsson’s latest Mobility Report of a “supercycle, an unusually strong multi-year upgrade wave” that will carry smart glasses and other “connected physical AI device form factors” with it. Chipset vendors, says Ericsson, “are interested in being in the next generation from the start.”
All this, however, sounds a world apart from the humdrum IoT of smart meters and temperature sensors. The connected humanoid or AI drone must look more exciting and potentially lucrative to the average big telco hunting for sales growth in a saturated smartphone market. If telcos can extract service fees from consumers for smart glasses, they will prioritize that over anything in LPWA.
Much of the IoT probably didn’t, doesn’t and won’t ever need 4G, 5G or 6G, explaining the delta between the overall number of connections and the cellular quantity in Ericsson’s report. By 2031, Ericsson thinks we’ll have 47.1 billion total connections, including 38.8 billion that use short-range technologies such as Bluetooth, ZigBee and good old Wi-Fi. The farm of the average AgBot owner might enjoy ubiquitous 6G by then, making the vehicle even more versatile. For the far less dazzling stuff that might benefit from cellular, the risk is of ending up forgotten.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/iot/the-internet-of-things-was-5g-s-big-fail-6g-risks-a-repeat
https://www.emnify.com/developer-blog/evaluating-nb-iot-and-lte-m-part1
LoRaWAN® Enters Its Next Growth Phase as Massive IoT Scales Globally
From LPWAN to Hybrid Networks: Satellite and NTN as Enablers of Enterprise IoT – Part 2
Enterprise IoT and the Transformation of UK Telecom Business Models – Part 1
GSA: 102 Network Operators in 52 Countries have Deployed NB-IoT and LTE-M LPWANs for IoT
5G Americas: LTE & LPWANs leading to ‘Massive Internet of Things’ + IDC’s IoT Forecast
LoRaWAN and Sigfox lead LPWANs; Interoperability via Compression
Semtech LoRa® PHY technology enables Amazon Sidewalk to expand while supporting fixed and mobile IoT endpoints
TM Forum’s DTW Ignite 2026: Open Digital Architecture (ODA); Nokia, Ericsson, IBM and Mavenir AI announcements/cloud partnerships
-
- Shift to Action: TM Forum Vice President Aaron Boasman-Patel and CEO Nik Willetts opened the summit emphasizing that the industry must move past abstract C-suite visions.
- The AI Economy: The flagship keynote officially launched the “Race to 2030,” a direct directive tasking operators to secure their market relevance by deploying high-velocity, production-grade architectures.
-
- On-Stage AI Co-Hosts: In an industry event first, agentic AI systems took the stage alongside human moderators to act as live panel co-hosts, digital analysts, and experts.
- Summit Intelligence Layer: Advanced AI systems recorded and indexed every keynote, panel, and breakout session, functioning as a real-time intelligence layer to deliver daily trend summaries to attendees.
-
- Autonomous Networks (AN): Featuring the largest showcase of live autonomous operating systems to date. Major case studies from carriers like China Mobile, China Telecom, TDC NET, and Telefónica showcased functional solutions for self-optimizing networks, RAN energy efficiency, and fast fault resolution.
- Trustworthy AI and Data: Discussions zeroed in on scaling responsible AI, exploring Models-as-a-Service (MODaaS) frameworks, managing tokenomics, and reinforcing cyber resilience.
- Composable IT and Ecosystems: Demonstrations focused on scaling Open Digital Architecture (ODA) from boardroom design into functional, interoperable engineering realities.

Practical Engineering & Showcases:
- Catalyst Showcases: The exhibition floor hosted over 60 collaborative proof-of-concept Catalyst projects and Innovation Engine live demonstrations.
- New Interactive Hubs: The event debuted dedicated “Mission Garages” for hands-on engineering collaboration, along with a specialized Future Skills program to help tech teams adapt to AI-native workflows. [1]
- Major Tech Partnerships: Industry titans—including IBM, Ericsson, Cisco, and Nokia—used the floor to debut subsea infrastructures, physical AI, and cloud-native automation frameworks.
Note 1. DTW Ignite 2026 is TM Forum’s flagship global connectivity event focused on accelerating AI-native telcos, autonomous networks, and composable IT. The event is from June 23 to June 25 at the Bella Center in Copenhagen, Denmark.
……………………………………………………………………………………………………………………………………………………………….
At the show, the TM Forum and its member alliance of over 850 companies across 180 countries, announced a major structural evolution for the Open Digital Architecture (ODA), shifting it from a cloud-native IT modernization blueprint into an AI-native execution environment. The core focus of these updates is to establish standardized, executable reference frameworks that allow operators to move beyond fragmented AI pilots and build an autonomous enterprise. The primary ODA updates and structural expansions announced at the summit include:
-
- Governed Execution Layer: TM Forum members launched AI-native extensions to the ODA specification, adding a governed execution layer. This allows autonomous AI agents and large language models to run natively within the existing ODA component architecture and Open APIs.
- Project Foundation & AI Canvas: Through the Demo ONE Catalyst project, tech leaders debuted an updated AI-Native ODA Canvas. This cloud-native runtime environment orchestrates data, AI models, and autonomous agents across fragmented BSS, OSS, and network domains to replace rigid legacy systems.
- Model-as-a-Service (MODaaS): To solve the challenge of rising token costs and fragmented model selection, an ODA-aligned MODaaS framework was introduced. It establishes a unified control plane to govern, secure, and manage AI model usage across the carrier architecture.
-
- Space-Telco Interoperability: In a major scope expansion, TM Forum officially launched the ODA for Satellite project. Supported by 16 foundational partners—including Airbus, Terrestar, and Vodacom—the initiative targets multi-billion dollar direct-to-device and space-connectivity markets.
- Unified Non-Terrestrial Frameworks: The project extends standard ODA components to satellite technology providers, standardizing how terrestrial mobile networks and non-terrestrial networks (NTNs) handle cross-industry billing, service delivery, and zero-touch roaming integrations.
- Plug-and-Play Validation: TM Forum rolled out its newly expanded ODA Component Certification. This toolkit gives vendors a programmatic way to verify that their commercial software components are truly plug-and-play ready, lowering custom integration costs for telecom buyers.
- “Running on ODA” Milestones: The alliance celebrated that 18 global Communication Service Providers (CSPs), representing over two billion subscribers globally, have officially achieved “Running on ODA” accreditation—confirming that modular, componentized architecture has reached full scale in production environments.
……………………………………………………………………………………………….
Vendor Announcements:
- Amazon Web Services (AWS) Expansion: Nokia and AWS expanded their partnership to run Nokia’s Autonomous Networks Fabric natively on AWS. The integration brings operators closer to Level 4 network autonomy, enabling networks to orchestrate, analyze, and heal themselves at machine speed.
- Google Cloud Integration: Nokia deepened its alliance with Google Cloud to integrate Gemini models into the Nokia Assurance Center. They unveiled six specialized generative AI agents (including a Router Agent and Event Triage Agent) to automatically process data and isolate the root causes of service faults. It launches as a SaaS offering in September 2026.
- Databricks Proof of Concept: Nokia and Databricks announced the completion of a joint project showing a unified, cloud-agnostic data platform. This resolves a legacy pain point by unifying hundreds of fragmented operational silo data architectures so multi-agent AI can run seamlessly across networks.
- GenAI-Native Operations: Instead of relying on traditional rules-based code, Nokia’s new interfaces allow field engineers to query complex multi-vendor topologies, generate diagnostic code, and run natural-language root-cause analyses on real-time traffic faults.
- Autonomous Network Scaling: Nokia presented multi-party Catalyst project solutions targeting network optimization, zero-touch slicing, and automated enterprise edge deployments tailored for the 5G-Advanced landscape.
……………………………………………………………………………………………………………………………………………………….
- EIAP Core Expansion: The headline announcement from the Ericsson Cloud Software and Services division was the expansion of the Ericsson Intelligent Automation Platform (EIAP). Formerly restricted to RAN operations, the platform now fully integrates and unifies Radio Access Network (RAN) and core network automation systems.
- Introduction of cApps: Ericsson claimed a major industry first by rolling out core-specific automation applications (cApps). These decentralized apps allow operators to run automated routines directly on core architectures, streamlining cross-domain workflows to cut operations costs.
- Business Value Pathways: Ericsson debuted a structured strategic blueprint designed to guide Communication Service Providers (CSPs) through the financial steps of scaling from Level 3 to Level 4 autonomous networks.
…………………………………………………………………………………………………………………………………………………….
- Addressing the “AI Trust Gap”: Responding to a TM Forum study revealing that only 14% of operators can prove their AI systems are fully reliable, IBM presented framework tools at DTW Ignite to address security and model bias.
- B2B2X Monetization: IBM focused its platform showcase on orchestrating automated workflows for multi-enterprise B2B2X networks, enabling secure data federation across third-party hyperscalers and edge servers.
……………………………………………………………………………………………………………………………………………………
- Telco-First Cloud Architecture: Stationed at Booth 334, Mavenir debuted its updated AI-by-design, cloud-native software portfolios built natively around TM Forum’s Open Digital Architecture (ODA) frameworks.
- Closed-Loop Automation: Mavenir demonstrated actionable frameworks that handle real-time resource adjustments, shifting power and processing capacity across base stations based on AI-predicted user demand cycles.
……………………………………………………………………………………………………………………………………………………
References:
https://www.tmforum.org/events/dtw/experience-dtw/new-for-2026
Inside TM Forum’s Catalyst project “Living Networks – Phase III”
Deloitte and TM Forum : How AI could revitalize the ailing telecom industry?
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
GSMA, ETSI, IEEE, ITU & TM Forum: AI Telco Troubleshooting Challenge + TelecomGPT: a dedicated LLM for telecom applications
SHIELD-6G with AI-native cyber threat intelligence platform to enhance cybersecurity for Europe’s future 6G networks
Verizon’s 6G Innovation Forum joins a crowded list of 6G efforts that may conflict with 3GPP and ITU-R IMT-2030 work
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
SNS Telecom & IT: Private 5G Market to Reach $6.6 Billion as Physical AI Takes Hold
Private 5G networks are transitioning from limited-scale deployments to a more material segment of the wireless infrastructure market. SNS Telecom & IT estimates that annual spending on private 5G networks will exceed $6.6 billion by 2029, driven by multi-site and multi-national enterprise rollouts supporting industrial automation, “physical AI” systems, and mission-critical communications across both commercial and public-sector domains.
Historically, private cellular deployments remained a niche market during the 2G/3G era, with notable exceptions such as GSM-R for railway communications. The introduction of private LTE in the early 2010s established a foundation for dedicated enterprise connectivity; however, adoption remained constrained by performance limitations and ecosystem maturity. The evolution to 3GPP-defined 5G NPN architectures—both standalone (SNPN) and public network-integrated (PNI-NPN)—is now enabling broader applicability across industrial verticals, with a trajectory that exceeds prior-generation adoption levels. Concurrently, legacy systems such as GSM-R are expected to transition toward 5G-based FRMCS implementations aligned with 3GPP specifications.
From a technical perspective, 5G introduces capabilities that are better aligned with industrial communication requirements than LTE. Enhanced mobile broadband (eMBB), ultra-reliable low-latency communications (URLLC), and massive machine-type communications (mMTC) collectively support higher throughput, sub-10 ms latency targets, improved reliability, and significantly greater device densities. These characteristics enable 5G NPNs to address use cases traditionally served by wired Ethernet or deterministic industrial networks, particularly in scenarios requiring mobility and flexible topology. Additional attributes—including improved coverage per radio node, network slicing, time-sensitive networking (TSN) integration, and enhanced security mechanisms—position private 5G as a viable alternative to interference-prone unlicensed technologies in dense IIoT environments.
Deployment momentum is increasingly visible across manufacturing, logistics, energy, and transportation sectors. Production-grade implementations have demonstrated measurable operational benefits, including reduced downtime, improved safety, and expanded coverage in previously unconnected areas. A common pattern involves the migration of AGV and AMR connectivity from Wi-Fi to private 5G, enabling more deterministic performance and reduced susceptibility to interference. In parallel, private 5G is extending connectivity to challenging industrial zones where wired infrastructure is cost-prohibitive or operationally restrictive. Emerging use cases also include coordinated robotics and edge-controlled automation systems, often described as “physical AI,” where low-latency and reliable connectivity are critical for closed-loop control.
In the public-sector domain, private 5G is gaining traction for mission-critical communications. Applications span defense, public safety, railways, and utilities, where requirements include high availability, secure communications, and support for MCX services (mission-critical push-to-talk, video, and data). The evolution toward 5G-Advanced, as defined in 3GPP Releases 18 through 20, introduces further enhancements relevant to these deployments, including support for reduced channel bandwidth operation in dedicated spectrum, expanded frequency bands, and specific feature sets aligned with FRMCS and mission-critical service requirements.
Geographically, adoption is concentrated in markets with established industrial bases and supportive regulatory frameworks, including North America, Europe, and parts of Asia-Pacific. As enterprises scale digitalization initiatives—encompassing automation, AI-driven operations, and connected workforce applications—private 5G deployments are increasingly moving beyond pilot phases to multi-site, production-grade networks.
SNS Telecom & IT projects a compound annual growth rate of approximately 34% for private 5G investments between 2026 and 2029. Growth is expected to be led by localized enterprise and campus networks, alongside parallel expansion in mission-critical infrastructure. The combination of maturing 3GPP standards, improving device ecosystems, and demonstrated operational benefits is positioning private 5G as a foundational connectivity layer for next-generation industrial and public-sector systems.
References:
https://www.snstelecom.com/private5g
GSA: Global private mobile networks exceed 2,000 worldwide; Ericsson Private 5G from Verizon Business extends beyond U.S.
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
SNS Telecom & IT: Mission-Critical Networks a $9.2 Billion Market
SNS Telecom & IT: Private 5G Market Nears Mainstream With $5 Billion Surge
SNS Telecom & IT: Private 5G and 4G LTE cellular networks for the global defense sector are a $1.5B opportunity
OneLayer Raises $28M Series A funding to transform private 5G networks with enhanced security
Verizon partners with Nokia to deploy large private 5G network in the UK
