

Google’s new quantum computer chip Willow infinitely outpaces the world’s fastest supercomputers
Overview:
In a blog post on Monday, Google unveiled a new quantum computer chip called Willow, which demonstrates error correction and performance that paves the way to a useful, large-scale quantum computer. Willow has state-of-the-art performance across a number of metrics, enabling two major achievements.
- The first is that Willow can reduce errors exponentially as we scale up using more qubits. This cracks a key challenge in quantum error correction that the field has pursued for almost 30 years.
- Second, Willow performed a standard benchmark computation in under five minutes that would take one of today’s fastest supercomputers 10 septillion (that is, 1025) years — a number that vastly exceeds the age of the Universe.

Google’s quantum computer chip, Willow. Photo Credit…Google Quantum AI
………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Quantum computing — the result of decades of research into a type of physics called quantum mechanics — is still an experimental technology. But Google’s achievement shows that scientists are steadily improving techniques that could allow quantum computing to live up to the enormous expectations that have surrounded this big idea for decades.
“When quantum computing was originally envisioned, many people — including many leaders in the field — felt that it would never be a practical thing,” said Mikhail Lukin, a professor of physics at Harvard and a co-founder of the quantum computing start-up QuEra. “What has happened over the last year shows that it is no longer science fiction.”
As a measure of Willow’s performance, Google used the random circuit sampling (RCS) benchmark. Pioneered by its team and now widely used as a standard in the field, RCS is the classically hardest benchmark that can be done on a quantum computer today. You can think of this as an entry point for quantum computing — it checks whether a quantum computer is doing something that couldn’t be done on a classical computer.
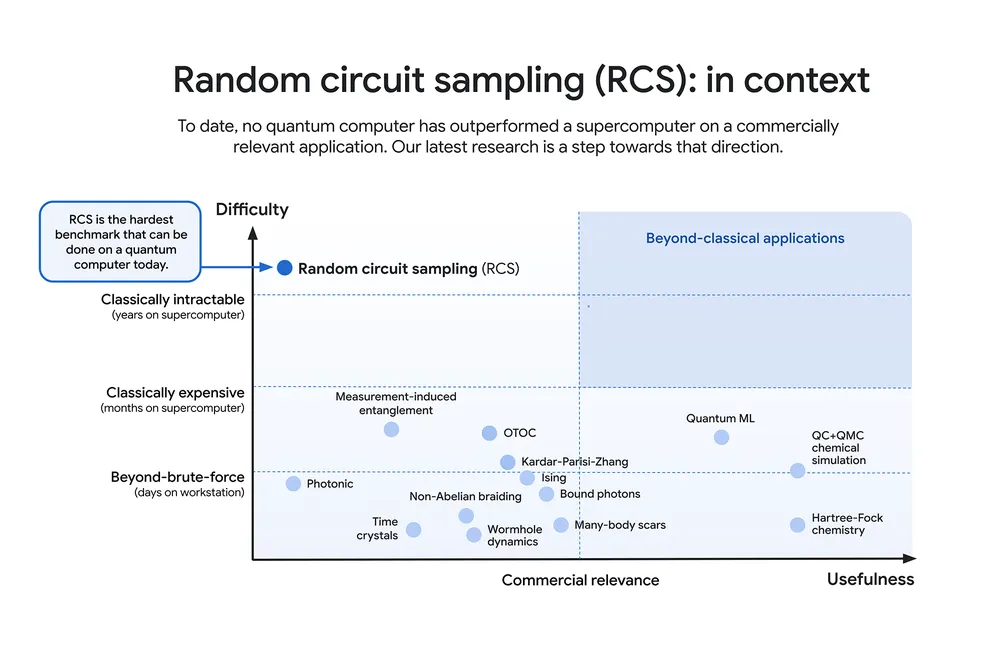
Random circuit sampling (RCS), while extremely challenging for classical computers, has yet to demonstrate practical commercial applications. Image Credit: Google AI.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Willow’s performance on this benchmark is astonishing: It performed a computation in under five minutes that would take one of today’s fastest supercomputers 1025 or 10 septillion years. If you want to write it out, it’s 10,000,000,000,000,000,000,000,000 years. This mind-boggling number exceeds known timescales in physics and vastly exceeds the age of the universe. It lends credence to the notion that quantum computation occurs in many parallel universes, in line with the idea that we live in a multiverse, a prediction first made by David Deutsch.
Google’s assessment of how Willow outpaces one of the world’s most powerful classical supercomputers, Frontier, was based on conservative assumptions. For example, we assumed full access to secondary storage, i.e., hard drives, without any bandwidth overhead — a generous and unrealistic allowance for Frontier. Of course, as happened after we announced the first beyond-classical computation in 2019, we expect classical computers to keep improving on this benchmark, but the rapidly growing gap shows that quantum processors are peeling away at a double exponential rate and will continue to vastly outperform classical computers as we scale up.

In a research paper published on Monday in the science journal Nature, Google said its machine had surpassed the “error correction threshold,” a milestone that scientists have been working toward for decades. That means quantum computers are on a path to a moment, still well into the future, when they can overcome their mistakes and perform calculations that could accelerate the progress of drug discovery. They could also break the encryption that protects computers vital to national security.
“What we really want these machines to do is run applications that people really care about,” said John Preskill, a theoretical physicist at the California Institute of Technology who specializes in quantum computing. “Though it still might be decades away, we will eventually see the impact of quantum computing on our everyday lives.”
Sidebar –Quantum Computing Explained:
A traditional computer like a laptop or a smartphone stores numbers in semiconductor memories or registers and then manipulates those numbers, adding them, multiplying them and so on. It performs these calculations by processing “bits” of information. Each bit holds either a 1 or a 0. But a quantum computer defies common sense. It relies on the mind-bending ways that some objects behave at the subatomic level or when exposed to extreme cold, like the exotic metal that Google chills to nearly 460 degrees below zero inside its quantum computer.
Quantum bits, or “qubits,” behave very differently from normal bits. A single object can behave like two separate objects at the same time when it is either extremely small or extremely cold. By harnessing that behavior, scientists can build a qubit that holds a combination of 1 and 0. This means that two qubits can hold four values at once. And as the number of qubits grows, a quantum computer becomes exponentially more powerful. Google builds “superconducting qubits,” where certain metals are cooled to extremely low temperatures.
Many other tech giants, including Microsoft, Intel and IBM, are building similar quantum technology as the United States jockeys with China for supremacy in this increasingly important field. As the United States has pushed forward, primarily through corporate giants and start-up companies, the Chinese government has said it is pumping more than $15.2 billion into quantum research.
With its latest superconducting computer, Google has claimed “quantum supremacy,” meaning it has built a machine capable of tasks that are beyond what any traditional computer can do. But these tasks are esoteric. They involve generating random numbers that can’t necessarily be applied to practical applications, like drug discovery.
Google and its rivals are still working toward what scientists call “quantum advantage,” when a quantum computer can accelerate the progress of other fields like chemistry and artificial intelligence or perform tasks that businesses or consumers find useful. The problem is that quantum computers still make too many errors.
Scientists have spent nearly three decades developing techniques — which are mind-bending in their own right — for getting around this problem. Now, Google has shown that as it increases the number of qubits, it can exponentially reduce the number of errors through complex analysis.
Experts believe it is only a matter of time before a quantum computer reaches its vast potential. “People no longer doubt it will be done,” Dr. Lukin said. “The question now is: When?”
References:
https://blog.google/technology/research/google-willow-quantum-chip/
https://www.nytimes.com/2024/12/09/technology/google-quantum-computing.html
Quantum Computers and Qubits: IDTechEx report; Alice & Bob whitepaper & roadmap
Bloomberg on Quantum Computing: appeal, who’s building them, how does it work?
China Mobile verifies optimized 5G algorithm based on universal quantum computer
SK Telecom and Thales Trial Post-quantum Cryptography to Enhance Users’ Protection on 5G SA Network
Quantum Technologies Update: U.S. vs China now and in the future
Can Quantum Technologies Crack RSA Encryption as China Researchers Claim?
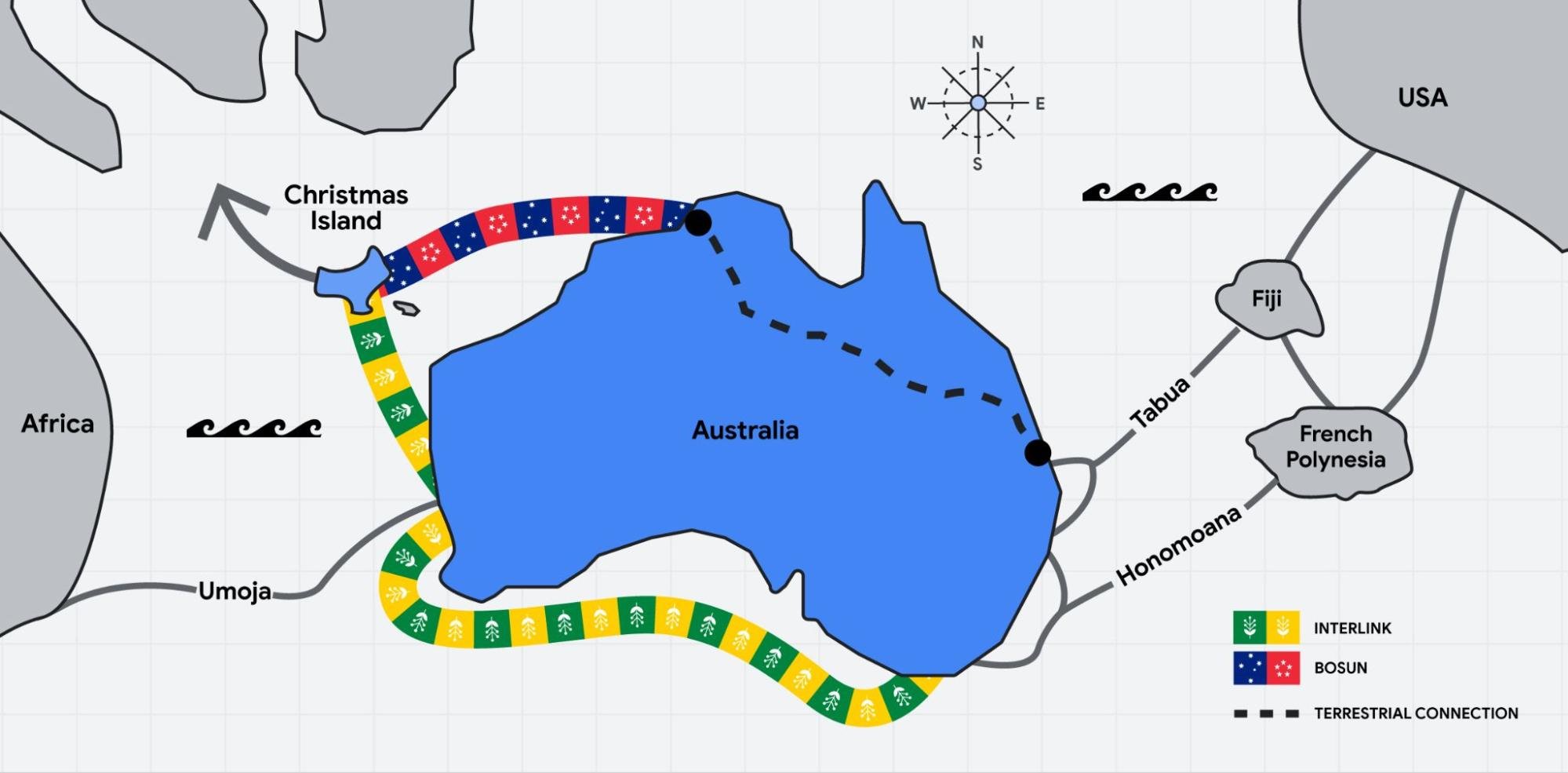
Google’s Bosun subsea cable to link Darwin, Australia to Christmas Island in the Indian Ocean

“Vocus is thrilled to have the opportunity to deepen our strategic network partnership with Google, and to play a part in establishing critical digital infrastructure for our region. Australia Connect will bolster our nation’s strategic position as a vital gateway between Asia and the United States by connecting key nodes located in Australia’s East, West, and North to global digital markets,” said Jarrod Nink, Interim Chief Executive Officer, Vocus.
“The combination of the new Australia Connect subsea cables with Vocus’ existing terrestrial route between Darwin and Brisbane, will create a low latency, secure, and stable network architecture. It will also establish Australia’s largest and most diverse domestic inter-capital network, with unparalleled reach and protection across terrestrial and subsea paths.
“By partnering with Google, we are ensuring that Vocus customers have access to high capacity, trusted and protected digital infrastructure linking Australia to the Asia Pacific and to the USA. “The new subsea paths, combined with Vocus’ existing land-based infrastructure, will provide unprecedented levels of diversity, capacity and reliability for Google, our customers and partners,” Nink said.
“Australia Connect advances Google’s mission to make the world’s information universally accessible and useful. We’re excited to collaborate with Vocus to build out the reach, reliability, and resiliency of internet access in Australia and across the Indo-Pacific region,” said Brian Quigley, VP, Global Network Infrastructure, Google Cloud.
Perth, Darwin, and Brisbane are key beneficiaries of this investment and are now emerging as key nodes on the global internet utilizing the competitive and diverse subsea and terrestrial infrastructure established by the Vocus network. Vocus will be in a position to supply an initial 20-30Tbps of capacity per fiber pair on the announced systems, depending on the length of the segment.
References:
Google’s Equiano subsea cable lands in Namibia en route to Cape Town, South Africa
Google’s Topaz subsea cable to link Canada and Japan
“SMART” undersea cable to connect New Caledonia and Vanuatu in the southwest Pacific Ocean
Telstra International partners with: Trans Pacific Networks to build Echo cable; Google and APTelecom for central Pacific Connect cables
HGC Global Communications, DE-CIX & Intelsat perspectives on damaged Red Sea internet cables
Orange Deploys Infinera’s GX Series to Power AMITIE Subsea Cable
NEC completes Patara-2 subsea cable system in Indonesia
SEACOM telecom services now on Equiano subsea cable surrounding Africa
Bharti Airtel and Meta extend 2Africa Pearls subsea cable system to India
China seeks to control Asian subsea cable systems; SJC2 delayed, Apricot and Echo avoid South China Sea
Intentional or Accident: Russian fiber optic cable cut (1 of 3) by Chinese container ship under Baltic Sea
Altice Portugal MEO signs landing party agreement for Medusa subsea cable in Lisbon
2Africa subsea cable system adds 4 new branches
Echo and Bifrost: Facebook’s new subsea cables between Asia-Pacific and North America
Equinix and Vodafone to Build Digital Subsea Cable Hub in Genoa, Italy
Ericsson and Nokia demonstrate 5G Network Slicing on Google Pixel 6 Pro phones running Android 13 mobile OS
In separate announcements today, Ericsson and Nokia stated they had completed 5G Network Slicing trials with Google on Pixel 6 Pro smart phones running the Android 13 mobile OS [1.].
Network Slicing is perhaps the most highly touted benefits of 5G, but its commercial realization is taking much longer than most of the 5G cheerleaders expected. That is because Network Slicing, like all 5G features, can only be realized on a 5G standalone (SA) network, very few of which have been deployed by wireless network operators. Network slicing software must be resident in the 5G SA Core network and the 5G endpoint device, in this case the Google Pixel 6 Pro smartphone.
Note 1. On August 15, 2022, Google released Android 13 -the latest version of its mobile OS. It comes with a number of new features and improvements, as well as offers better security and performance fixes. However, it’s implementation on smartphones will be fragmented and slow according to this blog post.
For devices running Android 12 or higher, Android provides support for 5G Network Slicing, the use of network virtualization to divide single network connections into multiple distinct virtual connections that provide different amounts of resources to different types of traffic. 5G network slicing allows network operators to dedicate a portion of the network to providing specific features for a particular segment of customers. Android 12 introduces the following 5G enterprise network slicing capabilities, which network operators can provide to their enterprise clients.
Android 12 introduces support for 5G network slicing through additions to the telephony codebase in the Android Open Source Project (AOSP) and the Tethering module to incorporate existing connectivity APIs that are required for network slicing.
Here’s a functional block diagram depicting 5G network slicing architecture in AOSP:
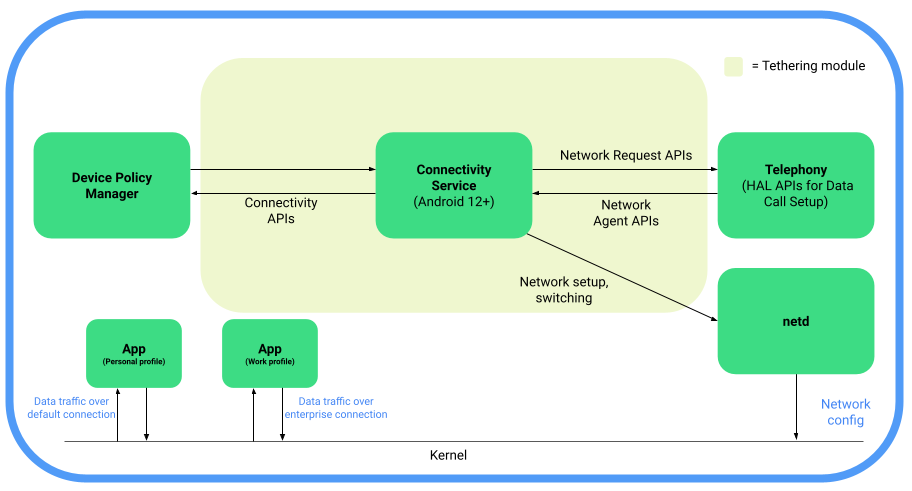
Image Credit: Android Open Source Project
1. Ericsson and Google demonstrated support on Ericsson network infrastructure for multiple slices on a single device running Android 13, supporting both enterprise (work profile) and consumer applications. In addition, for the first time, a slice for carrier branded services will allow communications service providers (CSP) to provide extra flexibility for customized offerings and capabilities. A single device can make use of multiple slices, which are used according to the on-device user profiles and network policies defined at the CSP level.
The results were achieved in an Interoperability Device Testing (IODT) environment on Google Pixel 6 (Pro) devices using Android 13. The new release sees an expansion of the capabilities for enterprises assigning network slicing to applications through User Equipment Route Selection Policy (URSP ) rules, which is the feature that enables one device using Android to connect to multiple network slices simultaneously.
Two different types of slices were made available on a device’s consumer profile, apart from the default mobile broadband (MBB) slice. App developers can now request what connectivity category (latency or bandwidth) their app will need and then an appropriate slice, whose characteristics are defined by the mobile network, will be selected. In this way either latency or bandwidth can be prioritized, according to the app’s requirements. For example, the app could use a low-latency slice that has been pre-defined by the mobile network for online gaming, or a pre-defined high-bandwidth slice to stream or take part in high-definition video calling.
In an expansion of the network slicing support offered by Android 12, Android 13 will also allow for up to five enterprise-defined slices to be used by the device’s work profile. In situations where no USRP rules are available, carriers can configure their network so traffic from work profile apps can revert to a pre-configured enterprise APN (Access Point Name) connection – meaning the device will always keep a separate mobile data connection for enterprise- related traffic even if the network does not support URSP delivery.
Monica Zethzon, Head of Solution Area Packet Core at Ericsson said: “As carriers and enterprises seek a return on their investment in 5G networks, the ability to provide for a wide and varied selection of use cases is of crucial importance. Communications Service Providers and enterprises who can offer customers the flexibility to take advantage of tailored network slices for both work and personal profiles on a single Android device are opening up a vast reserve of different uses of those devices. By confirming that the new network slicing capabilities offered by Android 13 will work fully with Ericsson network technology, we are marking a significant step forward in helping the full mobile ecosystem realize the true value of 5G.”
Ericsson and partners have delivered multiple pioneering network slicing projects using the Android 12 device ecosystem. In July, Telefonica and Ericsson announced a breakthrough in end-to-end, automated network slicing in 5G Standalone mode.
2. Nokia and Google announced that they have successfully trialed innovative network slice selection functionality on 4G/5G networks using UE Route Selection Policy (URSP) [2.] technology and Google Pixel 6 (Pro) phones running Android 13. Once deployed, the solution will enable operators to provide new 5G network slicing services and enhance the customer application experience of devices with Android 13. Specifically, URSP capabilities enable a smartphone to connect to multiple network slices simultaneously via different enterprise and consumer applications depending on a subscriber’s specific requirements. The trial, which took place at Nokia’s network slicing development center in Tampere, Finland, also included LTE-5G New Radio slice interworking functionality. This will enable operators to maximally utilize existing network assets such as spectrum and coverage.
Note 2. User Equipment Route Selection (URSP) is the feature that enables one device using Android to connect to multiple network slices simultaneously. It’s a feature that both Nokia and Google are supporting.
URSP capabilities extend network slicing to new types of applications and use cases, allowing network slices to be tailored based on network performance, traffic routing, latency, and security. For example, an enterprise customer could send business-sensitive information using a secure and high-performing network slice while participating in a video call using another slice at the same time. Additionally, consumers could receive personalized network slicing services for example for cloud gaming or high-quality video streaming. The URSP-based network slicing solution is also compatible with Nokia’s new 5G radio resource allocation mechanisms as well as slice continuity capabilities over 4G and 5G networks.
The trial was conducted using Nokia’s end-to-end 4G/5G network slicing product portfolio across RAN-transport-core as well as related control and management systems. The trial included 5G network slice selection and connectivity based on enterprise and consumer application categories as well as 5G NR-LTE slice interworking functionalities.
Nokia is the industry leader in 4G/5G network slicing and was the first to demonstrate 4G/5G network slicing across RAN-Transport-Core with management and assurance. Nokia’s network slicing solution supports all LTE, 5G NSA, and 5G SA devices, enabling mobile operators to utilize a huge device ecosystem and provide slice continuity over 4G and 5G.
Nokia has carried out several live network deployments and trials with Nokia’s global customer base including deployments of new slicing capabilities such as Edge Slicing in Virtual Private Networks, LTE-NSA-SA end-to-end network slicing, Fixed Wireless Access slicing, Sliced Private Wireless as well as Slice Management Automation and Orchestration.
Ari Kynäslahti, Head of Strategy and Technology at Nokia Mobile Networks, said: “New application-based URSP slicing solutions widen operator’s 5G network business opportunities. We are excited to develop and test new standards-based URSP technologies with Android that will ensure that our customers can provide leading-edge enterprise and consumer services using Android devices and Nokia’s 4G/5G networks.”
Resources:
…………………………………………………………………………………………………………………………………………………………….
Addendum:
- Google’s Pixel 6 and Pixel 6 Pro, which run on Android 12, are the first two devices certified on Rogers 5G SA network in Canada, which was deployed in October 2021. However, 5G network slicing hasn’t been announced yet.
- Telia deployed a commercial 5G standalone network in Finland using gear from Nokia and the operator highlighted its ability to introduce network slicing now that it has a 5G SA core.
- OPPO, a Chinese consumer electronics and mobile communications company headquartered in Dongguan, Guangdong, recently demonstrated the pre-commercial 5G enterprise network slicing product at its 5G Communications Lab in collaboration with Ericsson and Qualcomm. OPPO has been conducting research and development in 5G network slicing together with network operators and other partners for a number of years now.
- Earlier this month, Nokia and Safaricom completed Africa’s first Fixed Wireless Access (FWA) 5G network slicing trial.
References:
https://source.android.com/docs/core/connect/5g-slicing
Nokia and Safaricom complete Africa’s first Fixed Wireless Access (FWA) 5G network slicing trial
Stratospheric Platforms demos HAPS based 5G; will it succeed where Google & Facebook failed?
UK-based Stratospheric Platforms (SPL) claims it’s demonstrated the world’s first successful High Altitude Platform Satellite (HAPS) based 5G base station. The 5G coverage from the stratosphere demonstration took place in Saudi Arabia.
–> That’s quite a claim since there are no ITU-R standards or 3GPP implementation specs for HAPS or satellite 5G. Current 5G standards and 3GPP specs are for terrestrial wireless coverage.
A SPL stratospheric mast – which for the purposes of the demonstration had been installed on a civilian aircraft – delivered high-speed coverage to a 5G mobile device from an altitude of 14 kilometres to a geographical area of 450 square kilometres.
SPL says their The High Altitude Platform (HAP) will be certified from the outset for safe operations in civil airspace. Some attributes are the following:
- The HAP will have endurance of over a week on station due its lightweight structure and huge power source.
- Designed to be strong enough to fly through the turbulent lower altitudes to reach the more benign environment of the stratosphere, where it will hold-station.
- A wingspan of 60 metres and a large, reliable power source enables a 140kg communications payload.
- Design life of over 10 years with minimal maintenance, repair and overhaul costs
- Extensive use of automation in manufacturing processes will result in a low cost platform.

Source: Stratospheric Platforms
The joint team established three-way video calls between the land-based test site, a mobile device operated from a boat and a control site located 950 km away. Further land and heliborne tests demonstrated a user could stream 4K video to a mobile phone with an average latency of 1 millisecond above network speed. Signal strength trials, using a 5G enabled device moving at 100 km/h, proved full interoperability with ground-based masts and a consistent ‘five bars’ in known white spots.
Richard Deakin, CEO Stratospheric Platforms said, “Stratospheric Platforms has achieved a world-first. This is a momentous event for the global telecoms industry proving that a 5G telecoms mast flying near the top of the earth’s atmosphere can deliver stable broadband 5G internet to serve mobile users with ubiquitous, high-speed internet, over vast areas.”
Deakin added, “The trial has proved that 5G can be reliably beamed down from an airborne antenna and is indistinguishable from ground-based mobile networks. Our hydrogen-powered ‘Stratomast’ High Altitude Platform currently under development, will be able to fly for a week without refuelling and cover an area of 15,000 km2 using one antenna.”
The successful demonstration that a High Altitude Platform can deliver 5G Internet from the stratosphere means that mobile users can look forward to the capability of 5G mobile internet, even in the remotest areas of the world.
CITC Governor, H.E. Dr Mohammed Altamimi commented “the Kingdom of Saudi Arabia is at the cutting edge of technological innovation and our partnership with Stratospheric Platforms’ with the support of the Red Sea Project and General Authority of Civil Aviation (GACA) has demonstrated how we can deliver ‘always on’, ultra-fast broadband to areas without ground based 5G masts.”
……………………………………………………………………………………………………………………………………………………………
Background and Analysis:
SPL was founded in Cambridge in 2014. In 2016, Deutsche Telekom became its biggest single shareholder and launch customer. It came out of hiding in 2020 with a demonstration in Germany of an aerial LTE base station.
Should SPL turn its HAPS vision into a sustainable, commercial reality, it will have succeeded where some much bigger names have failed. Google had a grand vision to offer long range WiFi connectivity from a fleet of balloons. Project Loon launched its first – and what turned out to be only – commercial service in Kenya in 2018. After nine years, Google gave up on Project Loon in 2021. In 2015 Google also dabbled with a drone-based HAPS service called Project Titan, but that came to an end in 2016.
Similarly Facebook attempted to roll out drone-based connectivity under the Aquila brand in 2016, but threw in the towel two years later. Facebook then posted what they believe will be “the next chapter in high altitude connectivity.”
These inauspicious examples don’t seem to have deterred SPL from pursuing HAPS connectivity, and it isn’t the only one trying. This past January, Japan’s NTT announced it is working with its mobile arm DoCoMo, aircraft maker Airbus, and Japanese satcoms provider Sky Perfect JSAT to look into the feasibility of HAPS-based connectivity.
So the momentum is building for HAPS based wireless connectivity but it won’t go mass market till standards emerge.
References:
https://www.stratosphericplatforms.com/
https://www.stratosphericplatforms.com/news/world-first-5g-transmission/
https://www.stratosphericplatforms.com/category/news/
https://telecoms.com/513882/5g-haps-inches-forward-with-saudi-trial/
New partnership targets future global wireless-connectivity services combining satellites and HAPS
Facebook & AT&T to Test Drones for Wireless Communications Capabilities
After 9 years Alphabet pulls the plug on Loon; Another Google X “moonshot” bites the dust!
Google & Subcom to build Firmina cable connecting U.S. and South America
Cable maker/installer SubCom said it has teamed up with Google to build and deploy a new undersea cable connecting North and South America. The cable, named ‘Firmina’ after Brazilian abolitionist and author Maria Firmina dos Reis, will run from the East Coast of the United States to Las Toninas in Argentina, with additional landings in Praia Grande, Brazil and Punta del Este, Uruguay. Designed as a twelve-fiber pair trunk, Firmina will be Google’s second proprietary U.S. to South America cable designed to improve access to the company’s services for users in the region.
SubCom said Firmina will be the world’s longest cable capable of maintaining operations with single-end feed power, in the event of a far-end fault. Manufacture of the cable and equipment will take place at SubCom’s recently-expanded manufacturing campus in Newington during 2021 and early 2022, with main lay installation operations scheduled for summer 2022. The system is expected to be ready for service by the end of 2023.
In a blogpost, Google Cloud’s vice-president of global networking, Bikash Koley, said:
“As people and businesses have come to depend on digital services for many aspects of their lives, Firmina will improve access to Google services for users in South America. With 12 fiber pairs, the cable will carry traffic quickly and securely between North and South America, giving users fast, low-latency access to Google products such as Search, Gmail and YouTube, as well as Google Cloud services.
Connecting North to South America, the cable will be the longest ever to feature single-end power feeding capability. Achieving this record-breaking, highly resilient design is accomplished by supplying the cable with a voltage 20pc higher than with previous systems.”
SubCom’s CEO, David Coughlan, said the partnership with Google will “supply a high-speed, high-capacity undersea cable system that will encompass some of the most advanced transmission technologies in the world.”

Source: Google
…………………………………………………………………………………………………………………………………………..
Firmina will join other Google cables in the region, including the 10,500 kilometer Monet system running from Boca Raton in the US to Fortaleza and Praia Grande in Brazil, the Tannat (Brazil-Uruguay) cable and the Junior cable connecting Rio de Janeiro to Santos in Brazil.
Google is also working with fellow tech giant Facebook on two new subsea cables that will connect North America and south-east Asia.
This came after another Google-Facebook subsea cable was blocked. Plans for the Pacific Light Cable Network were cancelled late last year due concerns from the U.S. government about direct communications links between the U.S. and Hong Kong.
………………………………………………………………………………………………………………………………….
About SubCom:
SubCom is the leading global partner for today’s undersea data transport requirements.
SubCom designs, manufactures, deploys, maintains, and operates the industry’s most reliable
fiber optic cable networks. Its flexible solutions include repeaterless to ultra-long-haul, offshore
oil and gas, scientific applications, and marine services. SubCom brings end-to-end network
knowledge and global experience to support on-time delivery and meet the needs of customers
worldwide. To date, the company has deployed over 200 networks – enough undersea cable to
circle Earth more than 17 times at the equator.
Echo and Bifrost: Facebook’s new subsea cables between Asia-Pacific and North America
Facebook has revealed plans to build two new subsea cables between the Asia-Pacific region and North America, called Echo and Bifrost. The social media giant also revealed partnerships with Google as well as Asian telecoms operators for the project.
Although these projects are still subject to regulatory approvals, when completed, these cables will deliver much-needed internet capacity, redundancy, and reliability. The transpacific cables will follow a “new diverse route crossing the Java Sea, connecting Singapore, Indonesia, and North America,” and are expected to increase overall transpacific capacity by 70%.
Facebook says Echo and Bifrost will support further growth for hundreds of millions of people and millions of businesses. Facebook said that economies flourish when there is widely accessible internet for people and businesses.
Echo and Bifrost be the first transpacific cables through a new diverse route crossing the Java Sea. Connecting Singapore, Indonesia, and North America, these cable investments reflect Facebook’s commitment to openness and our innovative partnership model. The social media company works with a variety of leading Indonesian and global partners to ensure that everyone benefits from developing scale infrastructure and shared technology expertise.
Facebook will work with partners such as Indonesian companies Telin and XL Axiata and Singapore-based Keppel on these projects.
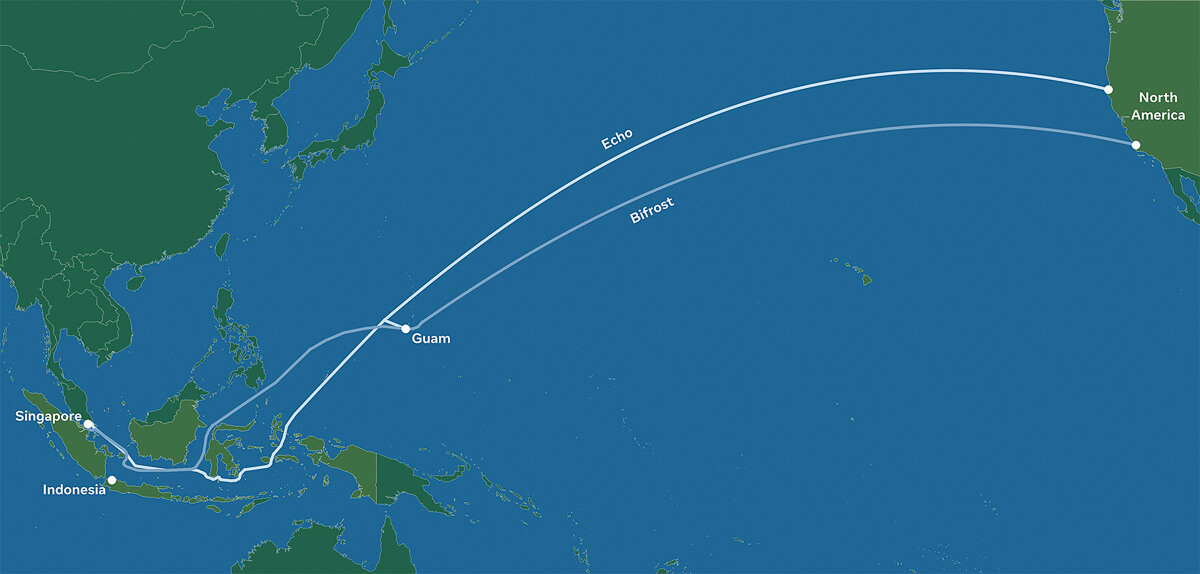
Image Credit: Facebook
………………………………………………………………………………………………..
Kevin Salvadori, VP of network investments at Facebook, provided further details in an interview with Reuters. He said Echo is being built in partnership with Alphabet’s Google and XL Axiata. It should be completed by 2023. Bifrost partners include Telin, a subsidiary of Indonesia’s Telkom, and Keppel. It is due to be completed by 2024.
Aside from the Southeast Asian cables, Facebook was continuing with its broader subsea plans in Asia and globally, including with the Pacific Light Cable Network (PLCN), Salvadori said.
“We are working with partners and regulators to meet all of the concerns that people have, and we look forward to that cable being a valuable, productive transpacific cable going forward in the near future,” he said.
Indonesia
Facebook noted that Echo and Bifrost will complement the subsea cables serving Indonesia today. These investments present an opportunity to enhance connectivity in the Central and Eastern Indonesian provinces, providing greater capacity and improved reliability for Indonesia’s international data information infrastructure. Echo and Bifrost complement the subsea cables serving Indonesia today, increasing service quality and supporting the country’s connectivity demands.
This is all part of Facebook’s continued effort to collaborate with partners in Indonesia to expand access to broadband internet and lower the cost of connectivity. Facebook has partnered with Alita, an Indonesian telecom network provider, to deploy 3,000 kilometers (1,8641 miles) of metro fiber in 20 cities in Bali, Java, Kalimantan, and Sulawesi. In addition, we are improving connectivity by expanding Wi-Fi with Express Wi-Fi.
While 73% of Indonesia’s population of 270 million are online, the majority access the web through mobile data, with less than 10 percent using a broadband connection, according to a 2020 survey by the Indonesian Internet Providers Association. Swathes of the country, remain without any internet access.
Singapore
In Singapore, Echo and Bifrost are expected to provide extra subsea capacity to complement the APG and SJC-2 subsea cables. Building on Facebook’s previously announced Singapore data center investments, Echo and Bifrost will provide important diverse subsea capacity to power Singapore’s digital growth and connectivity hub. Singapore is also home to many of Facebook’s regional teams.
The Asia-Pacific region is very important to Facebook. In order to bring more people online to a faster internet, these new projects add to Facebook’s foundational regional investments in infrastructure and partnerships to improve connectivity to help close the digital divide and strengthen economies.
……………………………………………………………………………………………………………………………………
References:
Advancing connectivity between the Asia-Pacific region and North America
https://www.reuters.com/article/us-facebook-internet-southeastasia-idUSKBN2BL0CH
DoJ: Google to operate undersea cable connecting U.S. and Asia
The U.S. Department of Justice announced Wednesday that it has approved Google’s request to use part of an undersea cable connecting the US and Asia via Taiwan. Google agreed to operate a portion of the 8,000-mile Pacific Light Cable Network System between the US and Taiwan, while avoiding the leg of the system extending to Hong Kong.
Google and Facebook helped pay for construction of the now completed undersea cable, along with a Chinese real estate investor. U.S. regulators had previously expressed national security concerns about the Chinese investor, Beijing-based Dr. Peng Telecom & Media Group Co.

Google, Facebook and telecom and undersea infrastructure developer TE SubCom and PLDC (Pacific Light Data Communication Co. Ltd.) are teaming up to build a 120 Terabits per second (Tbps), 12,800 km subsea cable that will connect Los Angeles with Taiwan, but exclude Hong Kong.
…………………………………………………………………………………………………..
The DoJ granted a six-month authorization for using the cable after Google emphasized “an immediate need to meet internal demand for capacity between the US and Taiwan” and that without the requested temporary authority, it would likely have to seek alternative capacity at “significantly higher prices.”
After discussions with Google representatives, the DoJ concluded that the obligations undertaken by Google would be sufficient to preserve their abilities to enforce the law and protect national security. Under the terms of the security agreement, Google has agreed to a range of operational requirements, notice obligations, access and security guarantees, as well as auditing and reporting duties, among others.
Google also committed to pursuing “diversification of interconnection points in Asia,” as well as to establish network facilities that deliver traffic as close as practicable to its ultimate destination. This reflects the views of the US government that a direct cable connection between the US and Hong Kong “would pose an unacceptable risk to the national security and law enforcement interests of the United States”, the DoJ said.
More information concerning the license application and the US Justice Departments’ response is available here.
……………………………………………………………………………………………………………………………………………………….
The U.S. government decision to exclude Hong Kong (see Update below) from a trans-Pacific cable was “severe blow” to the city as a telecom hub, a key industry figure said Thursday.
The DOJ said “a direct connection between the U.S. and Hong Kong would pose an unacceptable risk” to national security and law enforcement interests.
Charles Mok, the IT industry representative in the Hong Kong Legislative Council, said the decision was “not a surprise.”
It had been public knowledge for at least six months that the FCC held such views about Hong Kong and was delaying approval of the cable.
More than a month ago, Facebook and Google had amended their applications, excluding Hong Kong and terminating the cable in Taiwan, Mok pointed out.
“It is a severe blow to Hong Kong’s status as a hub for telecommunications and underseas cable in the region,” he said.
“The obvious reasons – behind what the US claims to be concerns over their national interest – must be the widely perceived deterioration of Hong Kong’s One Country Two Systems, rule of law, freedom of information and the media, and the increasing interference from China.
June 18, 2020 Update:
In a press release Wednesday, “Team Telecom” recommended the FCC deny an application to connect the Pacific Light Cable Network (PLCN) subsea cable system between the US and Hong Kong.
FCC commissioners appear poised to accept the recommendation. “I’ll reserve judgment for now, but the detailed filing raises major questions about state influence over Chinese telecoms. In this interconnected world, network security must be paramount,” tweeted Democratic FCC Commissioner Geoffrey Starks.
Team Telecom – officially the Committee for the Assessment of Foreign Participation in the United States Telecommunications Services Sector – is an organization created by President Trump in April. It’s chaired by Trump’s attorney general and includes his secretaries of Homeland Security and Defense. As the Department of Justice explained, Team Telecom formalizes a process that has existed for years, but which will “benefit from a transparent and empowered structure.”
References:
https://www.wsj.com/articles/u-s-allows-google-internet-project-to-advance-only-if-hong-kong-is-cut-out-11586377674 (on-line subscription required)
IHS Markit: Microsoft #1 for total cloud services revenue; AWS remains leader for IaaS; Multi-clouds continue to form
Following is information and insight from the IHS Markit Cloud & Colocation Services for IT Infrastructure and Applications Market Tracker.
Highlights:
· The global off-premises cloud service market is forecast to grow at a five-year compound annual growth rate (CAGR) of 16 percent, reaching $410 billion in 2023.
· We expect cloud as a service (CaaS) and platform as a service (PaaS) to be tied for the largest 2018 to 2023 CAGR of 22 percent. Infrastructure as a service (IaaS) and software as a service (SaaS) will have the second and third largest CAGRs of 14 percent and 13 percent, respectively.
IHS Markit analysis:
Microsoft in 2018 became the market share leader for total off-premises cloud service revenue with 13.8 percent share, bumping Amazon to the #2 spot with 13.2 percent; IBM was #3 with 8.8 percent revenue share. Microsoft’s success can be attributed to its comprehensive portfolio and the growth it is experiencing from its more advanced PaaS and CaaS offerings.
Although Amazon relinquished its lead in total off-premises cloud service revenue, it remains the top IaaS provider. In this very segmented market with a small number of large, well-established providers competing for market share:
• Amazon was #1 in IaaS in 2018 with 45 percent of IaaS revenue.
• Microsoft was #1 for CaaS with 22 percent of CaaS revenue and #1 in PaaS with 27 percent of PaaS revenue.
• IBM was #1 for SaaS with 17 percent of SaaS revenue.
…………………………………………………………………………………………………………………………………
“Multi-clouds [1] remain a very popular trend in the market; many enterprises are already using various services from different providers and this is continuing as more cloud service providers (CSPs) offer services that interoperate with services from their partners and their competitors,” said Devan Adams, principal analyst, IHS Markit. Expectations of increased multi-cloud adoption were displayed in our recent Cloud Service Strategies & Leadership North American Enterprise Survey – 2018, where respondents stated that in 2018 they were using 10 different CSPs for SaaS (growing to 14 by 2020) and 10 for IT infrastructure (growing to 13 by 2020).
Note 1. Multi-cloud (also multicloud or multi cloud) is the use of multiple cloud computing and storage services in a single network architecture. This refers to the distribution of cloud assets, software, applications, and more across several cloud environments.
There have recently been numerous multi-cloud related announcements highlighting its increased availability, including:
· Microsoft: Entered into a partnership with Adobe and SAP to create the Open Data Initiative, designed to provide customers with a complete view of their data across different platforms. The initiative allows customers to use several applications and platforms from the three companies including Adobe Experience Cloud and Experience Platform, Microsoft Dynamics 365 and Azure, and SAP C/4HANA and S/4HANA.
· IBM: Launched Multicloud Manager, designed to help companies manage, move, and integrate apps across several cloud environments. Multicloud Manager is run from IBM’s Cloud Private and enables customers to extend workloads from public to private clouds.
· Cisco: Introduced CloudCenter Suite, a set of software modules created to help businesses design and deploy applications on different cloud provider infrastructures. It is a Kubernetes-based multi-cloud management tool that provides workflow automation, application lifecycle management, cost optimization, governance and policy management across cloud provider data centers.
IHS Markit Cloud & Colocation Intelligence Service:
The bi-annual IHS Markit Cloud & Colocation Services Market Tracker covers worldwide and regional market size, share, five-year forecast analysis, and trends for IaaS, CaaS, PaaS, SaaS, and colocation. This tracker is a component of the IHS Markit Cloud & Colocation Intelligence Service which also includes the Cloud & Colocation Data Center Building Tracker and Cloud and Colocation Data Center CapEx Market Tracker. Cloud service providers tracked within this service include Amazon, Alibaba, Baidu, IBM, Microsoft, Salesforce, Google, Oracle, SAP, China Telecom, Deutsche Telekom Tencent, China Unicom and others. Colocation providers tracked include Equinix, Digital Realty, China Telecom, CyrusOne, NTT, Interion, China Unicom, Coresite, QTS, Switch, 21Vianet, Internap and others.
Will Hyperscale Cloud Companies (e.g. Google) Control the Internet’s Backbone?
Rob Powell reports that Google’s submarine cable empire now hooks up another corner of the world. The company’s 10,000km Curie submarine cable has officially come ashore in Valparaiso, Chile.
The Curie cable system now connects Chile with southern California. it’s a four-fiber-pair system that will add big bandwidth along the western coast of the Americas to Google’s inventory. Also part of the plans is a branching unit with potential connectivity to Panama at about the halfway point where they can potentially hook up to systems in the Caribbean.
Subcom’s CS Durable brought the cable ashore on the beach of Las Torpederas, about 100 km from Santiago. In Los Angeles the cable terminates at Equinix’s LA4 facility, while in Chile the company is using its own recently built data center in Quilicura, just outside of Santiago.
Google has a variety of other projects going on around the world as well, as the company continues to invest in its infrastructure. Google’s projects tend to happen quickly, as they don’t need to spend time finding investors to back their plans.

Curie is one of three submarine cable network projects Google unveiled in January 2018. (Source: Google)
……………………………………………………………………………………………………………………………………………………………………………………..
Powell also wrote that SoftBank’s HAPSMobile is investing $125M in Google’s Loon as the two partner for a common platform, and Loon gains an option to invest a similar sum in HAPSMobile later on.
Both companies envision automatic, unmanned, solar-powered devices in the sky above the range of commercial aircraft but not way up in orbit. From there they can reach places that fiber and towers don’t or can’t. HAPSMobile uses drones, and Loon uses balloons. The idea is to develop a ‘common gateway or ground station’ and the necessary automation to support both technologies.
It’s a natural partnership in some ways, and the two are putting real money behind it. But despite the high profile we haven’t really seen mobile operators chomping at the bit, since after all it’s more fun to cherry pick those tower-covered urban centers for 5G first and there’s plenty of work to do. And when they do get around to it, there’s the multiple near-earth-orbit satellite projects going on to compete with.
But the benefit both HAPSMobile and Loon have to their model is that they can, you know, reach it without rockets.
…………………………………………………………………………………………………………
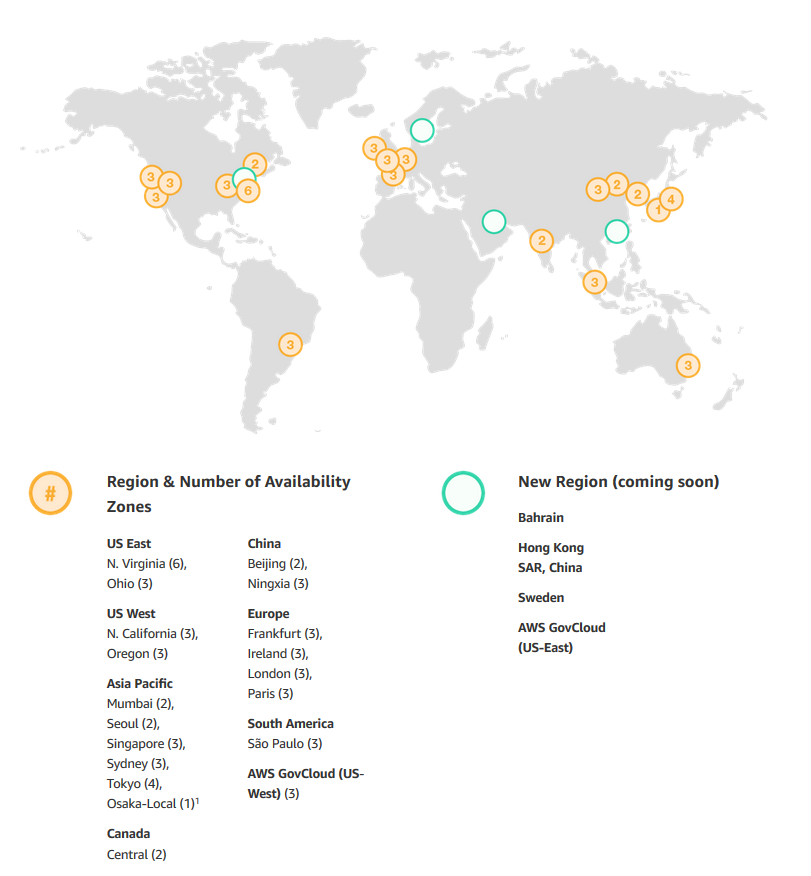
AWS’s Backbone (explained by Sapphire):
An AWS Region is a particular geographic area where Amazon decided to deploy several data centers, just like that. The reason behind a chosen area is to be close to the users and also to have no restrictions. At the same time, every Region is also connected through private links with other Regions which means they have a dedicated link for their communications because for them is cheaper and they also have full capacity planing with lower latency.
What is inside a Region?
- Minimum 2 Availability Zones
- Separate transit centers (peering the connections out of the World)
How transit centers work?
AWS has private links to other AWS regions, but they also have private links for the feature AWS Direct Connect – a dedicated and private & encrypted (IPSEC tunnel) connection from the “xyz” company’s datacenters to their infrastructures in the Cloud, which works with the VLANs inside (IEEE 802.1Q) for accessing public and private resources with a lower latency like Glacier or S3 buckets and their VPC at the same time between <2ms and usually <1ms latency. Between Availability Zones (inter AZ zone) the data transit there’s a 25TB/sec average.
From AWS Multiple Region Multi-VPC Connectivity:
AWS Regions are connected to multiple Internet Service Providers (ISPs) as well as to Amazon’s private global network backbone, which provides lower cost and more consistent cross-region network latency when compared with the public internet. Here is one illustrative example:

,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
From Facebook Building backbone network infrastructure:
We have strengthened the long-haul fiber networks that connect our data centers to one another and to the rest of the world.
As we bring more data centers online, we will continue to partner and invest in core backbone network infrastructure. We take a pragmatic approach to investing in network infrastructure and utilize whatever method is most efficient for the task at hand. Those options include leveraging long-established partnerships to access existing fiber-optic cable infrastructure; partnering on mutually beneficial investments in new infrastructure; or, in situations where we have a specific need, leading the investment in new fiber-optic cable routes.
In particular, we invest in new fiber routes that provide much-needed resiliency and scale. As a continuation of our previous investments, we are building two new routes that exemplify this approach. We will be investing in new long-haul fiber to allow direct connectivity between our data centers in Ohio, Virginia, and North Carolina.
As with our previous builds, these new long-haul fiber routes will help us continue to provide fast, efficient access to the people using our products and services. We intend to allow third parties — including local and regional providers — to purchase excess capacity on our fiber. This capacity could provide additional network infrastructure to existing and emerging providers, helping them extend service to many parts of the country, and particularly in underserved rural areas near our long-haul fiber builds.
………………………………………………………………………………………………….
Venture Beat Assessment of what it all means:
Google’s increasing investment in submarine cables fits into a broader trend of major technology companies investing in the infrastructure their services rely on.
Besides all the datacenters Amazon, Microsoft, and Google are investing in as part of their respective cloud services, we’ve seen Google plow cash into countless side projects, such as broadband infrastrucure in Africa and public Wi-Fi hotspots across Asia.
Elsewhere, Facebook — while not in the cloud services business itself — requires omnipresent internet connectivity to ensure access for its billions of users. The social network behemoth is also investing in numerous satellite internet projectsand had worked on an autonomous solar-powered drone project that was later canned. Earlier this year, Facebook revealed it was working with Viasat to deploy high-speed satellite-powered internet in rural areas of Mexico.
While satellites will likely play a pivotal role in powering internet in the future — particularly in hard-to-reach places — physical cables laid across ocean floors are capable of far more capacity and lower latency. This is vital for Facebook, as it continues to embrace live video and virtual reality. In addition to its subsea investments with Google, Facebook has also partnered with Microsoft for a 4,000-mile transatlantic internet cable, with Amazon and SoftBank for a 14,000 km transpacific cable connecting Asia with North America, and on myriad othercable investments around the world.
Needless to say, Google’s services — ranging from cloud computing and video-streaming to email and countless enterprise offerings — also depend on reliable infrastructure, for which subsea cables are key.
Curie’s completion this week represents not only a landmark moment for Google, but for the internet as a whole. There are currently more than 400 undersea cables in service around the world, constituting 1.1 million kilometers (700,000 miles). Google is now directly invested in around 100,000 kilometers of these cables (62,000 miles), which equates to nearly 10% of all subsea cables globally.
The full implications of “big tech” owning the internet’s backbone have yet to be realized, but as evidenced by their investments over the past few years, these companies’ grasp will only tighten going forward.
Facebook’s F16 achieves 400G effective intra DC speeds using 100GE fabric switches and 100G optics, Other Hyperscalers?
On March 14th at the 2019 OCP Summit, Omar Baldonado of Facebook (FB) announced a next-generation intra -data center (DC) fabric/topology called the F16. It has 4x the capacity of their previous DC fabric design using the same Ethernet switch ASIC and 100GE optics. FB engineers developed the F16 using mature, readily available 100G 100G CWDM4-OCP optics (contributed by FB to OCP in early 2017), which in essence gives their data centers the same desired 4x aggregate capacity increase as 400G optical link speeds, but using 100G optics and 100GE switching.
F16 is based on the same Broadcom ASIC that was the candidate for a 4x-faster 400G fabric design – Tomahawk 3 (TH3). But FB uses it differently: Instead of four multichip-based planes with 400G link speeds (radix-32 building blocks), FB uses the Broadcom TH3 ASIC to create 16 single-chip-based planes with 100G link speeds (optimal radix-128 blocks). Note that 400G optical components are not easy to buy inexpensively at Facebook’s large volumes. 400G ASICs and optics would also consume a lot more power, and power is a precious resource within any data center building. Therefore, FB built the F16 fabric out of 16 128-port 100G switches, achieving the same bandwidth as four 128-port 400G switches would.
Below are some of the primary features of the F16 (also see two illustrations below):
-Each rack is connected to 16 separate planes. With FB Wedge 100S as the top-of-rack (TOR) switch, there is 1.6T uplink bandwidth capacity and 1.6T down to the servers.
-The planes above the rack comprise sixteen 128-port 100G fabric switches (as opposed to four 128-port 400G fabric switches).
-As a new uniform building block for all infrastructure tiers of fabric, FB created a 128-port 100G fabric switch, called Minipack – a flexible, single ASIC design that uses half the power and half the space of Backpack.
-Furthermore, a single-chip system allows for easier management and operations.
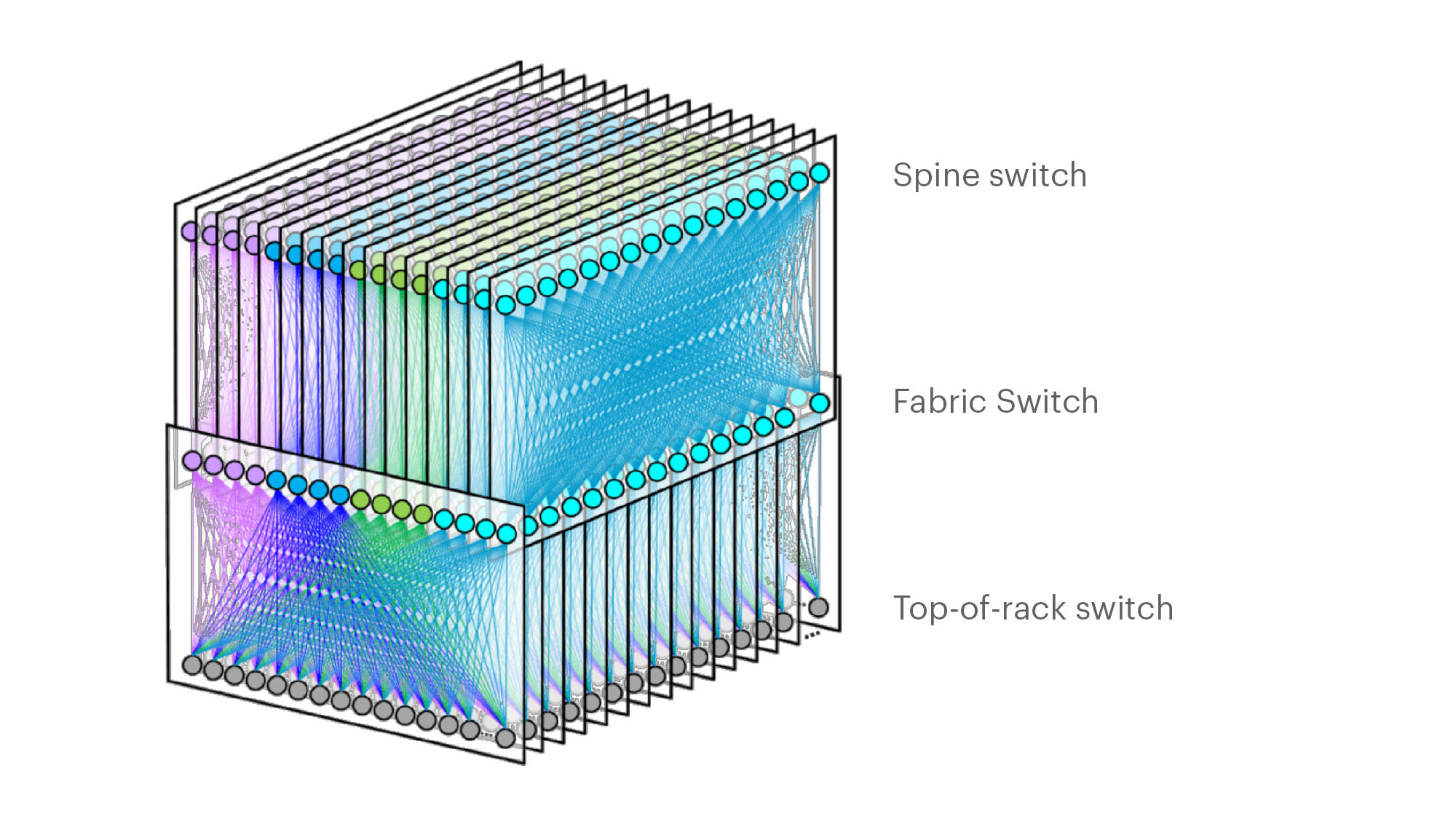 Facebook F16 data center network topology
Facebook F16 data center network topology
………………………………………………………………………………………………………………………………………………………………………………………………..
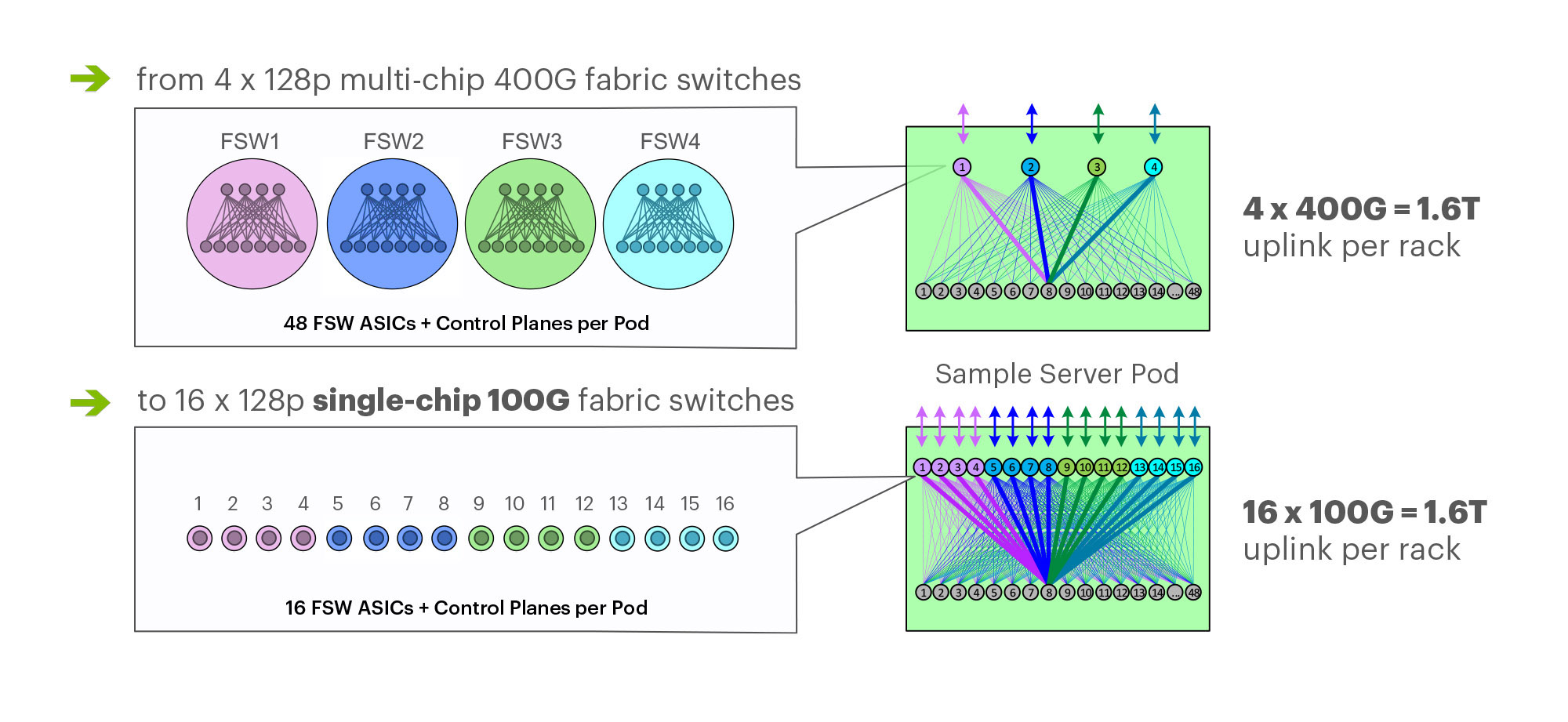
Multichip 400G b/sec pod fabric switch topology vs. FBs single chip (Broadcom ASIC) F16 at 100G b/sec
…………………………………………………………………………………………………………………………………………………………………………………………………..
In addition to Minipack (built by Edgecore Networks), FB also jointly developed Arista Networks’ 7368X4 switch. FB is contributing both Minipack and the Arista 7368X4 to OCP. Both switches run FBOSS – the software that binds together all FB data centers. Of course the Arista 7368X4 will also run that company’s EOS network operating system.
F16 was said to be more scalable and simpler to operate and evolve, so FB says their DCs are better equipped to handle increased intra-DC throughput for the next few years, the company said in a blog post. “We deploy early and often,” Baldonado said during his OCP 2019 session (video below). “The FB teams came together to rethink the DC network, hardware and software. The components of the new DC are F16 and HGRID as the network topology, Minipak as the new modular switch, and FBOSS software which unifies them.”
This author was very impressed with Baldonado’s presentation- excellent content and flawless delivery of the information with insights and motivation for FBs DC design methodology and testing!
References:
https://code.fb.com/data-center-engineering/f16-minipack/
………………………………………………………………………………………………………………………………….
Other Hyperscale Cloud Providers move to 400GE in their DCs?
Large hyperscale cloud providers initially championed 400 Gigabit Ethernet because of their endless thirst for networking bandwidth. Like so many other technologies that start at the highest end with the most demanding customers, the technology will eventually find its way into regular enterprise data centers. However, we’ve not seen any public announcement that it’s been deployed yet, despite its potential and promise!
Some large changes in IT and OT are driving the need to consider 400 GbE infrastructure:
- Servers are more packed in than ever. Whether it is hyper-converged, blade, modular or even just dense rack servers, the density is increasing. And every server features dual 10 Gb network interface cards or even 25 Gb.
- Network storage is moving away from Fibre Channel and toward Ethernet, increasing the demand for high-bandwidth Ethernet capabilities.
- The increase in private cloud applications and virtual desktop infrastructure puts additional demands on networks as more compute is happening at the server level instead of at the distributed endpoints.
- IoT and massive data accumulation at the edge are increasing bandwidth requirements for the network.
400 GbE can be split via a multiplexer into smaller increments with the most popular options being 2 x 200 Gb, 4 x 100 Gb or 8 x 50 Gb. At the aggregation layer, these new higher-speed connections begin to increase in bandwidth per port, we will see a reduction in port density and more simplified cabling requirements.
Yet despite these advantages, none of the U.S. based hyperscalers have announced they have deployed 400GE within their DC networks as a backbone or to connect leaf-spine fabrics. We suspect they all are using 400G for Data Center Interconnect, but don’t know what optics are used or if it’s Ethernet or OTN framing and OAM.
…………………………………………………………………………………………………………………………………………………………………….
In February, Google said it plans to spend $13 billion in 2019 to expand its data center and office footprint in the U.S. The investments include expanding the company’s presence in 14 states. The dollar figure surpasses the $9 billion the company spent on such facilities in the U.S. last year.
In the blog post, CEO Sundar Pichai wrote that Google will build new data centers or expand existing facilities in Nebraska, Nevada, Ohio, Oklahoma, South Carolina, Tennessee, Texas, and Virginia. The company will establish or expand offices in California (the Westside Pavillion and the Spruce Goose Hangar), Chicago, Massachusetts, New York (the Google Hudson Square campus), Texas, Virginia, Washington, and Wisconsin. Pichai predicts the activity will create more than 10,000 new construction jobs in Nebraska, Nevada, Ohio, Texas, Oklahoma, South Carolina, and Virginia. The expansion plans will put Google facilities in 24 states, including data centers in 13 communities. Yet there is no mention of what data networking technology or speed the company will use in its expanded DCs.
I believe Google is still designing all their own IT hardware (compute servers, storage equipment, switch/routers, Data Center Interconnect gear other than the PHY layer transponders). They announced design of many AI processor chips that presumably go into their IT equipment which they use internally but don’t sell to anyone else. So they don’t appear to be using any OCP specified open source hardware. That’s in harmony with Amazon AWS, but in contrast to Microsoft Azure which actively participates in OCP with its open sourced SONIC now running on over 68 different hardware platforms.
It’s no secret that Google has built its own Internet infrastructure since 2004 from commodity components, resulting in nimble, software-defined data centers. The resulting hierarchical mesh design is standard across all its data centers. The hardware is dominated by Google-designed custom servers and Jupiter, the switch Google introduced in 2012. With its economies of scale, Google contracts directly with manufactures to get the best deals.Google’s servers and networking software run a hardened version of the Linux open source operating system. Individual programs have been written in-house.
