

Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
By Shazia Hasnie, Ph.D, editorial review by IEEE Techblog team member Sridhar Talari Rajagopal
Abstract:
The adoption of AI agents in network operations has exposed a critical architectural gap. Most enterprise data pipelines were designed for dashboards and reporting, not autonomous decision-making. When AI agents consume data from batch-oriented pipelines, five distinct failure modes emerge: stale data, memory gaps, delete blindness, schema fragility, and coordination failure. This article examines each failure mode, explains the underlying mechanism, and proposes architectural remedies grounded in streaming-first design principles. It also connects each technical failure to measurable business outcomes—extended downtime, recurring incidents, compliance exposure, silent decision degradation, and cascading impact. The result is both a diagnostic framework for I&O leaders and a financial argument for treating streaming data infrastructure as the prerequisite for autonomous operations.
Introduction: The Data Foundation Gap
Artificial intelligence is reshaping network operations. AI agents promise to detect anomalies, diagnose root causes, and execute remediation faster than human engineers. The industry has focused attention on models, GPUs, and orchestration frameworks. The data layer remains largely unexamined.
This is a critical oversight. Most enterprise data pipelines were built for human consumers. They serve dashboards, weekly reports, and historical analysis. Humans tolerate latency. Humans bring context. Humans notice when something looks wrong.
AI agents require something fundamentally different. They need real-time context. They need historical state. They need accurate representations of current reality. When these requirements are not met, agents do not complain. They act—on incomplete information, with incorrect assumptions, producing wrong outcomes.
The gap between what batch pipelines deliver and what agents require creates failure modes that most teams do not see until an agent makes the wrong decision. Recent analysis has identified the economic dimensions of this gap [1], while industry resources have begun documenting the specific failure patterns that arise when batch processing meets autonomous agents [6]. This article extends that work by identifying five distinct failure modes and proposing a streaming-first architectural response.
FIVE FAILURE MODES: ANATOMY OF BATCH-TO-AGENT MISMATCH
The following five failure modes represent the specific ways batch data pipelines undermine autonomous network operations. Each is examined through its mechanism—how the batch pipeline architecture produces the failure—its operational consequence, and the streaming-first architectural remedy that eliminates it. Together, they form a diagnostic taxonomy for any I&O team evaluating whether their data foundation is ready for Agentic AI.
Failure Mode 1: Stale Data
Mechanism: Batch telemetry pipelines poll, collect, and process data in cycles. Data is extracted on a schedule, transformed in bulk, and loaded into a destination—a warehouse, data lake, time-series database, or feature store that holds a static, point-in-time snapshot of the source. Between cycles, the pipeline holds no current state. An AI agent that spins up between cycles receives a snapshot of the past.
Consequence: The agent diagnoses an outage using telemetry from five minutes ago. The network state has changed during that interval. Routes have shifted. Traffic has been redirected. Thus, the agent’s diagnosis is based on a reality that no longer exists. Remediation actions applied to a past state can worsen the current incident. The agent becomes a liability rather than an asset. Industry documentation confirms that AI agents require continuous data freshness to function correctly [5].
Architectural Remedy: Streaming telemetry replaces cyclical polling with continuous event push. Data flows from source to consumer in real time, ingested directly into the streaming platform’s durable event log [2]. The agent consumes from a live stream, not a stale snapshot. Context acquisition takes milliseconds. The cognitive loop remains intact. This is not an add-on to the batch pipeline. It is a structural replacement of the ingestion layer.
Failure Mode 2: Memory Gap
Mechanism: Batch pipelines deliver windows of data—the last hour, the last day, the last processing cycle. They do not preserve the sequence of events that led to the current moment. Historical context is stripped away with each new extract. The pipeline knows what happened. It does not know what happened before.
Consequence: An agent responding to an interface flap cannot answer the most basic diagnostic question: has this happened before? It cannot correlate the current event with the three similar events that occurred in the preceding 24 hours. It cannot detect the pattern that would reveal a degrading optical module. Every incident appears isolated. Pattern recognition—the core value proposition of AI-driven operations—is structurally impossible. The distinction between streaming and batch architectures for these use cases has been well-documented [4].
Architectural Remedy: A durable event log with configurable retention serves as the agent’s memory [2]. Unlike a batch window, which discards history with each new extract, the event log preserves the ordered sequence of all events within the retention period. The agent seeks backward in the log on startup and replays the preceding window of telemetry. Pattern detection across time becomes native to the architecture. This is not a separate cache layered on top. It is the storage layer itself—immutable, ordered, and built for event replay from any offset.
Failure Mode 3: Delete Blindness
Mechanism: Batch pipeline’s Extract, Transform, Load (ETL) processes compare snapshots of source data. They do not watch the database transaction log. They identify what exists at two points in time and process the difference. When a record is deleted from the source system, the pipeline has no way of distinguishing between a row that was deleted and a row that was simply omitted due to extraction error, filtering logic, or schema mismatch. The absence of a row is not an event. It is a gap. Batch pipelines are not designed to interpret gaps as meaningful signals. The record simply vanishes from the next extract. The downstream consumer—an AI agent or any other system—has no way of knowing the record ever existed.
Consequence: The agent queries the downstream data store and finds no record for a deactivated account, a revoked certificate, or a cancelled change order. It cannot distinguish between “never existed” and “was deleted,” so it treats the absence as neutral.
The agent makes decisions on ghosts—data that no longer exists in source systems. In access control scenarios, this is not an operational error. It is a security incident. This specific failure mode has been identified in analyses of batch processing limitations for AI agents [6].
Architectural Remedy: Change data capture (CDC), implemented through Kafka Connect with Debezium connectors, reads the database transaction log directly [2], [8]. Debezium provides CDC source connectors for MySQL, PostgreSQL, MongoDB, SQL Server, and other databases — capturing inserts, updates, and deletes as discrete events with explicit operation types by tailing the database’s native transaction log. Nothing is invisible to the pipeline. The streaming architecture knows not only what exists but what ceased to exist. This is not an ETL workaround with soft-delete flags. It is a structural capability of the integration layer, converting database changes into first-class events the moment they occur.
Failure Mode 4: Schema Fragility
Mechanism: Source database schemas change over time. Columns are renamed, added, deprecated, or re-typed. Batch pipelines are configured for a specific schema at extraction time. When the source schema changes, the pipeline responds in one of two ways. It fails silently and drops the affected field from every subsequent extract. Or it fails loudly and stops processing entirely.
Silent failure is the more dangerous outcome. The pipeline continues delivering data. The consumer has no indication that a critical field is missing.
Consequence: The agent continues operating without a critical data input. It makes decisions with incomplete information. It has no awareness that its reasoning is compromised. The wrong decisions accumulate. By the time the missing field is discovered—often through an operational failure rather than a monitoring alert—the cost of remediation includes auditing and correcting every decision made during the degradation window.
Architectural Remedy: A schema registry with compatibility enforcement validates schema changes before they propagate to downstream consumers [2]. Streaming platforms can enforce backward and forward compatibility rules at the producer level. A breaking schema change is rejected before any data is published. The pipeline fails loudly and immediately. This is not a documentation standard or a code review checklist. It is a structural governance layer embedded in the streaming architecture itself, preventing silent field loss at the point of ingestion.
Failure Mode 5: Coordination Failure
Mechanism: When multiple AI agents operate on batch-derived data, each agent consumes a separate, potentially inconsistent snapshot. Agent A receives data from the 10:00 AM extract. Agent B receives data from the 10:15 AM extract. The extracts differ. Each agent holds a different version of reality. There is no shared, ordered log of events that all agents consume.
Consequence: Two agents respond to the same cascading failure. Agent A identifies a BGP routing issue and begins rerouting traffic. Agent B identifies a DNS resolution failure and begins modifying name server configurations. Neither agent knows the other acted. The redundant changes compete. The conflicting configurations create new instability. The original incident expands rather than resolves. What began as a single point of failure becomes a cascade that erodes trust in autonomous operations.
Architectural Remedy: A shared, ordered event log serves as a single source of truth for all agents in the system. Every agent consumes from the same log. Actions taken by one agent are published back to the log as events, immediately visible to all others [7]. Coordination becomes native to the architecture.
Visibility alone, however, does not prevent conflicting actions. Two agents may observe the same anomaly and both initiate remediation before either’s action becomes visible on the log. In practice, this is addressed through complementary mechanisms layered on the same event-driven model: action intent events that signal an agent is about to act, giving others a window to defer; idempotency keys that prevent duplicate remediation from causing harm; and lightweight leases for resources that should only be modified by one agent at a time. These mechanisms do not require a central coordinator. They are published to the same log, consumed by the same agents, and enforced through the same ordered stream.
This is not a separate orchestration layer or message bus bolted onto the side. It is the core of the streaming platform—a unified, ordered, multi-consumer event stream that provides both the shared state and the coordination primitives that eliminate the inconsistent snapshots batch architectures produce by default.
Batch-to-Streaming Reference Architecture — Five Failure Modes and Their Architectural Remedies
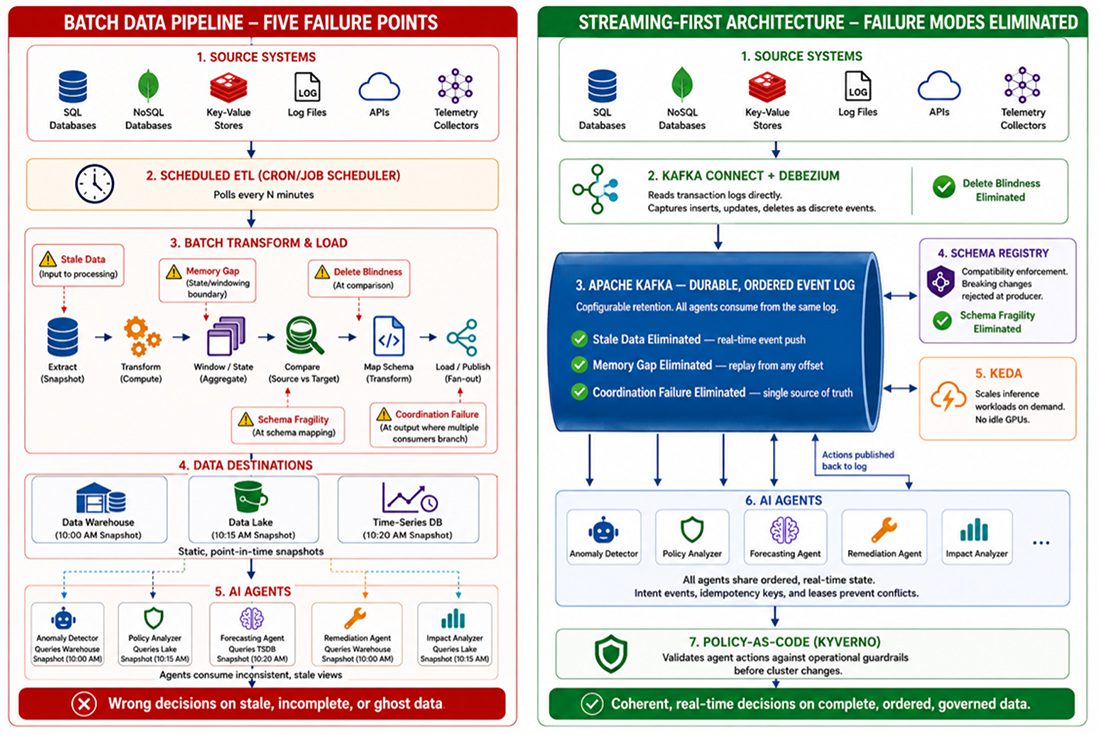
THE UNIFIED DIAGNOSTIC FRAMEWORK
The five failure modes translate into a practical audit that I&O leaders can apply to their own infrastructure. Each question corresponds to a specific architectural requirement.
The Five-Question Audit
- Can the data pipeline deliver real-time context to an agent the moment it wakes up? If not, the system is vulnerable to stale data failures.
- Can the agent access the preceding window of telemetry to detect patterns across events? If not, the system is vulnerable to memory gap failures.
- Does the pipeline capture deletes as explicit events with operation types? If not, the system is vulnerable to delete blindness.
- Does the pipeline detect schema changes before they propagate to downstream consumers? If not, the system is vulnerable to schema fragility.
- Do all agents share a single, ordered view of events with visibility into each other’s actions? If not, the system is vulnerable to coordination failure.
A negative answer to any one of these questions signals a data foundation that is not ready for autonomous operations. The model is not the bottleneck. The GPUs are not the bottleneck. The telemetry pipeline is.
THE MIGRATION PATH: FROM BATCH TO STREAMING-FIRST
Adopting a streaming-first architecture does not require abandoning existing batch investments overnight. For most organizations, the transition follows a coexistence model: streaming pipelines are introduced alongside batch pipelines, not as an immediate replacement.
The practical starting point is to identify the highest-value agent—the one whose decisions carry the greatest operational or financial consequence—and convert its data pipeline first. This agent is typically the one where stale data, memory gaps, or coordination failures have produced measurable incidents. Converting this single pipeline to streaming telemetry with a durable event log delivers a targeted operational improvement while the rest of the batch estate continues to function.
From there, adoption expands incrementally. Each additional agent is migrated as operational experience with the streaming platform grows. Teams develop competence in offset management, schema governance through the registry, and backpressure handling while batch pipelines continue to serve lower-priority consumers. The streaming and batch estates coexist for a transition period measured in months, not days.
This incremental approach also reveals where streaming delivers the greatest marginal benefit. Not every data flow requires real-time treatment. Dashboards fed by hourly batch extracts may serve their purpose indefinitely. The streaming investment should be directed at the pipelines that feed autonomous agents—the flows where the five failure modes carry real operational consequence. The goal is not to stream everything. It is to stream the right things first.
THE BUSINESS IMPACT: FROM TECHNICAL FAILURE TO FINANCIAL CONSEQUENCE
Technical failures in the data pipeline do not remain technical. They cascade into business outcomes that appear on budget reviews, SLA reports, and board presentations. Each failure mode carries a distinct financial consequence.
Stale Data → Extended Downtime
An agent diagnosing from stale telemetry makes incorrect decisions. Remediation applied to a past state can worsen the current incident. Mean Time to Resolution increases. For revenue-generating services, every minute of extended downtime translates to lost revenue and SLA penalty accrual.
Consider an illustrative model: a Tier-1 service provider processing $50M in customer transactions per hour, 5-minute stale-data induced misdiagnosis that extends an outage by 15 minutes represents $12.5M in direct revenue loss—not counting SLA penalties, regulatory scrutiny, or reputational harm. The cost of a single such incident can exceed the annual investment in the streaming infrastructure that would have prevented it. If even a portion of such incidents are eliminated by replacing the batch pipeline feeding the diagnostic agent with a streaming backbone, the infrastructure investment is recovered in a single avoided outage.
Memory Gap → Recurring Incidents
An agent without historical context cannot recognize chronic conditions. A flapping interface, a memory leak, or a degrading optical module triggers the same alert repeatedly. Each occurrence consumes GPU inference cycles. Each occurrence generates a ticket. Each occurrence may require human escalation. The cumulative cost of a single undiagnosed chronic issue, multiplied across an enterprise network over a year, represents operational expenditure that a stateful agent could eliminate.
Delete Blindness → Compliance and Security Exposure
An agent acting on deleted records makes authorization decisions based on invalid state. A deactivated account granted access. A revoked certificate treated as valid. In regulated industries, these errors are compliance violations with defined financial penalties and reporting obligations. The cost of a single access control error caused by ghost data can exceed the annual cost of the streaming infrastructure that would have prevented it.
Schema Fragility → Silent Decision Degradation
When a batch pipeline drops a critical field, the agent does not fail loudly. It continues operating with incomplete inputs. Decisions degrade silently. The cost includes not only the direct operational impact but the effort of auditing and correcting every decision made during the degradation window. Silent failure multiplies eventual remediation cost.
Coordination Failure → Cascading Impact
When multiple agents act on inconsistent views of reality, they create new problems. Redundant changes compete. Conflicting configurations destabilize the environment. The original incident expands. The cost includes extended resolution time, additional engineering effort, and eroded trust in autonomous operations. Organizational credibility is a balance sheet item that coordination failure depletes.
The Aggregated View
Taken together, the five failure modes represent a predictable drain on AI investment returns. An organization that deploys expensive GPU infrastructure, fine-tunes capable models, and implements event-driven orchestration [3]—but feeds all of it with a batch data pipeline—has built an autonomous operations capability on a foundation that guarantees suboptimal outcomes. The streaming backbone is not an incremental cost. It is the insurance policy that protects the returns on every other AI infrastructure investment.
CONCLUSION: STREAMING-FIRST AS THE ARCHITECTURAL PREREQUISITE
The five failure modes share a common root cause. Batch data pipelines were designed for human consumers who tolerate latency, bring context, and notice anomalies. AI agents tolerate nothing. They act on what they receive.
Each failure mode is addressable within a unified streaming data architecture. Streaming telemetry solves stale data by replacing cyclical polling with continuous event push. Durable event logs solve memory gaps by preserving the sequence of events with configurable retention, allowing agents to replay history and detect patterns across time. Change data capture—a structural component of the streaming architecture implemented through Kafka Connect and Debezium—solves delete blindness by reading database transaction logs directly, capturing inserts, updates, and deletes as discrete events with explicit operation types. A schema registry with compatibility enforcement solves schema fragility by validating schema changes before they propagate downstream, catching breaking changes at the source rather than discovering them after agent failure. A shared, ordered event log solves coordination failure by serving as a single source of truth that all agents consume, ensuring every agent operates on the same reality with visibility into every other agent’s actions—complemented by intent events, idempotency keys, and lightweight leases that prevent conflicting actions without a central coordinator.
These are not disparate tools. They are structural elements of a single streaming data architecture. Apache Kafka provides the durable, shared event log at the core. Kafka Connect provides the integration framework for change data capture, ingesting database changes as first-class events. Schema Registry provides the compatibility governance layer. Together, they form a complete data foundation where stale data, memory gaps, delete blindness, schema fragility, and coordination failure are eliminated by design—not patched after the fact.
These architectural components eliminate the data-layer failure modes. But real-time data also enables real-time action—and that speed demands an execution-layer governance framework. Policy-as-code engines ensure that agent decisions, even when based on perfect context and full state, are validated against operational guardrails before they become cluster changes. The streaming backbone delivers the context. The policy layer ensures that context is acted upon safely.
This streaming architecture is not an end in itself. It is the data foundation upon which event-driven network operations can be built. While the streaming backbone eliminates the data-layer failure modes, organizations that pair it with event-driven compute unlock an additional dimension of efficiency. When a telemetry event flows through the event log and an anomaly is detected, that same stream can trigger the Kubernetes Event-driven Autoscaling (KEDA) of inference workloads [3]—spinning up the right-sized model at the right moment, on the right context. The streaming backbone delivers the context. Event-driven orchestration delivers the compute. Together, they close the loop from detection to inference, ensuring the agent has both the data and the compute it needs without the waste of always-on infrastructure.
The barrier is not technology. Each of these architectural components is proven, open-source, and deployed in production environments today. The barrier is architectural awareness. Organizations that invest in a streaming-first data architecture will deploy AI agents that deliver on their promise. Organizations that do not will discover these failure modes in production—after the wrong decision is already made.
The streaming data architecture is not a performance upgrade for Agentic AI. It is the architectural prerequisite.
REFERENCES
[1] P. Madduri and A. L. Thakur, “The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core,” IEEE ComSoc Technology Blog, April 2026. [Online]. Available: https://techblog.comsoc.org/2026/03/30/the-financial-trap-of-autonomous-networks-scaling-agentic-ai-in-the-telecom-core/
[2] Apache Software Foundation, “Apache Kafka Documentation.” [Online].
Available: https://kafka.apache.org/42/getting-started/introduction/
[3] Cloud Native Computing Foundation, “KEDA: Kubernetes Event-driven Autoscaling.” [Online]. Available: https://keda.sh/
[4] Streamkap, “Streaming ETL vs. Batch ETL: A Decision Framework.” [Online].
Available: https://streamkap.com/resources-and-guides/streaming-etl-vs-batch-etl
[5] Streamkap, “Real-Time vs Batch Data for AI Agents: Why Freshness Matters.” [Online]. Available: https://streamkap.com/resources-and-guides/real-time-vs-batch-data-for-agents
[6] Streamkap, “Why AI Agents Can’t Use Batch Data.” [Online]. Available: https://streamkap.com/resources-and-guides/why-agents-cant-use-batch-data
[7] Redpanda, “Building safe, multi-agent AI systems in Redpanda Agentic Data Plane.” [Online]. Available: https://www.redpanda.com/blog/adp-governed-multi-agent-ai-cloud
[8] Debezium Community, “Debezium: Open-Source Change Data Capture,” Debezium Documentation. [Online]. Available: https://debezium.io/
ABOUT THE AUTHOR

Shazia Hasnie, Ph.D., is VP, Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations, AI-driven automation, and streaming data architectures. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale.
One thought on “Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations”
Leave a Reply

From Sebastian Barros: Does Latency Kill AI Agents? June 28, 2026
Why Telecom is Confusing the Latency of Chatbots with the Compounding Demands of Agentic Loops
There is massive confusion in the Telecom sector regarding what an AI agent actually is, how it functions, and the type of network infrastructure it requires. The industry has lazily reduced the entire debate to a binary choice: either put an expensive GPU at the network edge, or keep it in the cloud?
The reality is far more complex and dangerous. The shift from human-triggered chatbots to autonomous, machine-speed agents is triggering a structural latency crisis that completely rewrites network economics. For Telcos and cloud providers alike, solving this architectural challenge will determine who captures the premium token value of the Inference Economy and who gets relegated to selling low-margin data pipes.
Forwarded this email? Subscribe here for more
Does Latency Kill AI Agents?
Why Telecom is Confusing the Latency of Chatbots with the Compounding Demands of Agentic Loops
Sebastian Barros
Jun 28
∙
Preview
READ IN APP
There is massive confusion in the Telecom sector regarding what an AI agent actually is, how it functions, and the type of network infrastructure it requires. The industry has lazily reduced the entire debate to a binary choice: either put an expensive GPU at the network edge, or keep it in the cloud?
The reality is far more complex and dangerous.
The shift from human-triggered chatbots to autonomous, machine-speed agents is triggering a structural latency crisis that completely rewrites network economics. For Telcos and cloud providers alike, solving this architectural challenge will determine who captures the premium token value of the Inference Economy and who gets relegated to selling low-margin data pipes.
The Chat Clock vs. The Agent Clock:
Most generative AI applications operate on a human timescale. When a user enters a prompt into a chatbot, the data packet travels to a centralized cloud server and back. This single cross-country trip takes about 100 milliseconds. Because human users cannot perceive a delay that small, the physical distance to the cloud server is not a problem.
AI agents function differently. Instead of waiting for a single human prompt, they execute automated, continuous loops: perceiving data, reasoning, making decisions, and taking action across multiple systems.
AI agents are distinct from other AI workloads due to their autonomous nature, goal-oriented behavior, and often, their ability to learn and adapt. They are engineered to operate within dynamic environments, responding to changes and pursuing objectives without constant human intervention.
This continuous loop changes the math of network latency. A single enterprise task, such as an automated fraud check or a dynamic supply chain adjustment, can require up to 50 sequential machine-to-machine calls to complete the workflow. If an agent relies on a centralized cloud, each of those 50 calls incurs a transit delay. If each trip takes 100 milliseconds, the agent spends 5 seconds simply waiting for data to travel over the internet.