

Author: Vincent Rodriguez
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
By Shazia Hasnie, PhD
Introduction:
The physical network infrastructure that underpins cloud computing was designed for an era that no longer exists. Distributed training across hundreds of thousands of GPUs, real-time inference at the edge, and autonomous agent coordination impose requirements that traditional cloud network designs were never intended to meet. The networks that served the cloud era were architected for north-south traffic, best-effort delivery, and human-scale applications. None of these assumptions hold for AI.
This article presents a framework for transforming cloud network infrastructure for the AI era. It is organized around two components: a four-pillar reference architecture that defines what must be built, and a five-phase implementation roadmap that defines how to execute the transformation. Together, they provide infrastructure transformation leaders with a complete program for preparing their organizations’ physical network infrastructure for the age of AI.
The Four-Pillar Reference Architecture:
The physical network infrastructure for AI-era cloud computing is organized around four interdependent pillars. Each pillar groups related layers of the infrastructure stack. Each depends on the pillars that precede it and enables the pillars that follow.
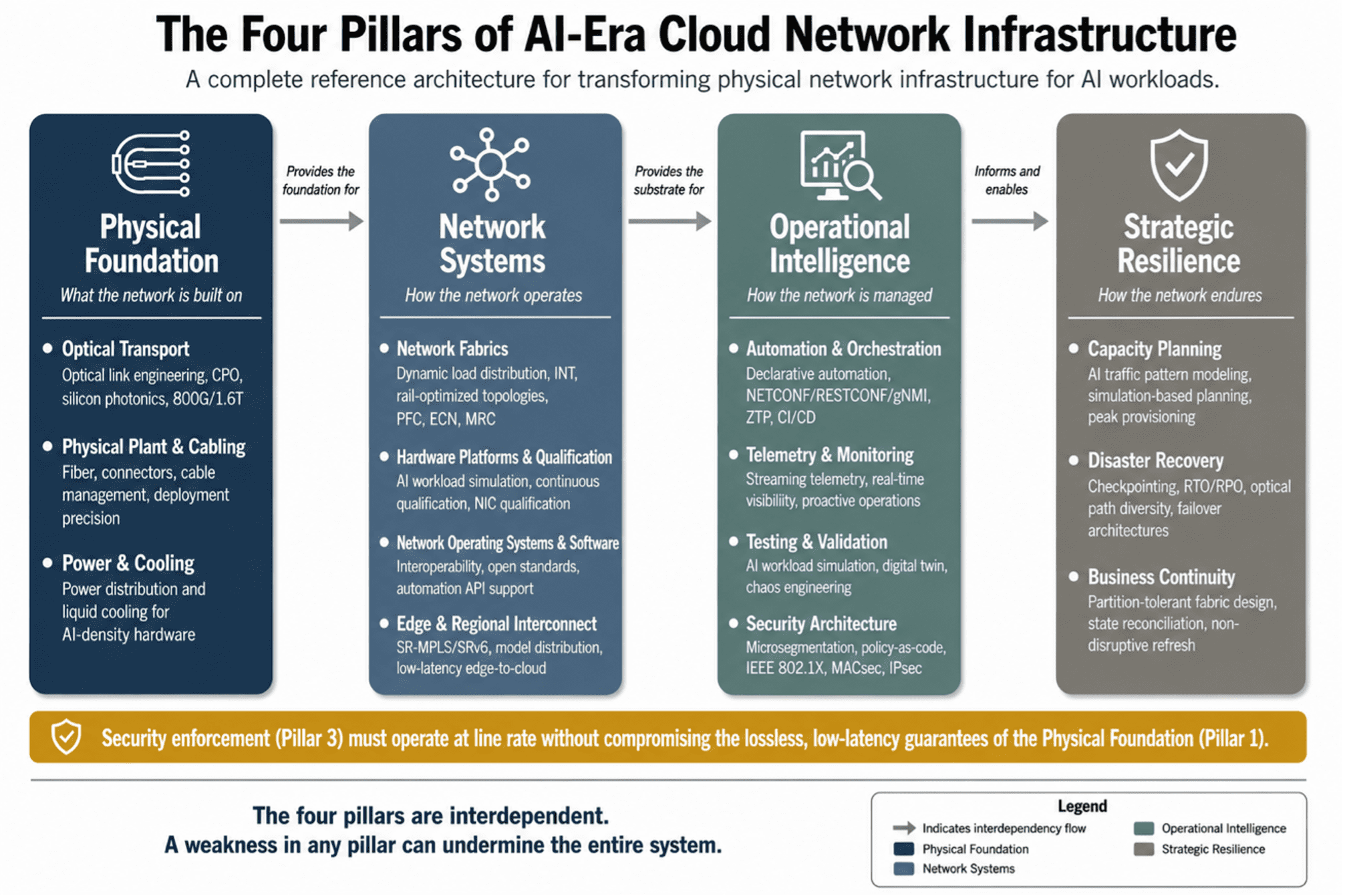
Figure 1: The Four Pillars of AI-Era Cloud Network Infrastructure — a complete reference architecture for physical network transformation.
PILLAR 1: PHYSICAL FOUNDATION
The physical foundation is the literal infrastructure on which all higher-layer network services depend. Optical transport determines the bandwidth, latency, and reliability of every interconnection between data centers, regions, and compute clusters. Physical plant and cabling provide the fiber, connectors, and cable management that make connectivity possible. Power and cooling provide the electrical and thermal infrastructure that keeps everything running.
Optical Transport. Optical link engineering for AI workloads requires a fundamental shift from traditional practice. Traditional optical link engineering treats traffic surges as anomalies and provisions for average utilization. AI workloads generate synchronized, high-bandwidth bursts—checkpointing incast can saturate multiple optical links for minutes at a time—that demand link budgets engineered for peak synchronized demand. The cost of insufficient capacity is not degraded optical performance; it is stalled training runs.
The optical technology roadmap is being reshaped by AI requirements. Co-packaged optics (CPO) integrate the optical engine directly with the switch ASIC, reducing power consumption by 30-50% while increasing port density. Silicon photonics leverage semiconductor manufacturing to produce optical components at scale. 800G and 1.6T per wavelength will be required as GPU bandwidth scales. Linear drive optics remove the digital signal processing from the optical transceiver, reducing power and latency. Breakout optics enable multi-planar topologies where each GPU connects to multiple parallel fabrics. Organizations must ensure that today’s optical investments are forward-compatible with these technologies.
Physical Plant and Cabling. Deployment precision at the physical layer determines whether the architectures designed at higher layers function as intended. Rail-optimized topologies depend on perfect physical cabling—a single miscabled port breaks the single-hop guarantee. Automated cabling verification, where the management interface validates each connection against the reference design, has reduced deployment time by up to 90% for early adopters. Continuous monitoring must detect cabling degradation before it causes performance issues.
Power and Cooling. AI network hardware consumes significantly more power than traditional cloud hardware. A rack of switches populated with 800G pluggable optics can consume over 10 kilowatts. CPO engines may require direct-to-chip liquid cooling. The transition to liquid cooling has implications that extend beyond the network—chilled water systems, heat rejection, building structural load—and retrofitting liquid cooling into a data center designed for air cooling is significantly more expensive than incorporating it into new construction.
PILLAR 2: NETWORK SYSTEMS
Network systems translate the physical foundation into functional network services. Modern data centers operate multiple physical networks—front-end, back-end, storage—each optimized for a specific traffic class. AI training demands a dedicated high-bandwidth, low-latency fabric for GPU-to-GPU communication that must interoperate with existing networks through well-defined interconnection points.
Network Fabrics. AI workloads generate east-west traffic that behaves differently from anything traditional cloud networks were designed to handle. It is dominated by a small number of high-bandwidth elephant flows—sustained, predictable data streams between GPU pairs—that produce synchronized bursts at predictable intervals. Worst-case path latency determines the completion time for collective communication operations, making the performance of the slowest path more important than average performance.
The industry has developed two distinct architectural paths to meet these requirements. For scale-up networks within a single rack or GPU pod, where distances are measured in meters and the cost of a stall is immediate, lossless transport via Priority-Based Flow Control (PFC) and Explicit Congestion Notification (ECN) remains the dominant approach. For scale-out networks connecting GPU clusters across data center halls or buildings, the industry is moving toward efficient utilization with low tail latency through fast recovery rather than absolute loss prevention. The Ultra Ethernet Consortium’s Ultra Ethernet Transport (UET) specification leads this effort, treating packet loss as a recoverable event rather than a failure.
The choice between paths is governed by three criteria: scale of deployment (≤256 GPUs favors lossless; ≥512 GPUs favors low-loss), workload characteristics (tightly coupled training benefits from lossless; loosely coupled inference tolerates low-loss), and organizational maturity (deep PFC expertise extends lossless viability to larger scales).
Four fabric capabilities support both paths. Dynamic load distribution—flowlet switching and packet spray—replaces static Equal Cost Multi-Path (ECMP) with congestion-aware path selection. In-band network telemetry (INT) provides the microsecond-granularity congestion visibility that makes intelligent load distribution possible. Rail-optimized topologies provide single-hop GPU-to-GPU connectivity for the most latency-sensitive collective operations. Advanced transport protocols, add selective retransmission via SACK and NACK that serves both scale-up and scale-out deployments.
Hardware Platforms and Qualification. Hardware must be qualified under AI workload conditions, not standard benchmarks. A switch that performs well under steady-state testing may exhibit unacceptable packet loss under synchronized burst patterns. The qualification process must answer a specific question: will this hardware maintain performance under the traffic patterns that AI workloads generate? Qualification is continuous—a firmware update, a new optics module, or a configuration change can alter behavior and must be validated before reaching production. The endpoint NIC plays a critical role, handling RDMA at line rate, packet-spray reordering, and selective retransmission. NIC qualification must be part of the same AI workload simulation process as switches and optics.
Network Operating Systems. The NOS must support PFC, INT, dynamic load distribution, and automation APIs. Interoperability is an architectural requirement in inherently multi-vendor AI infrastructure. Organizations should prioritize platforms that adhere to open standards—UET specifications, IETF YANG data models, OpenConfig—over proprietary extensions that create long-term supply chain constraints.
Edge and Regional Interconnect. AI inference increasingly occurs at the edge, requiring low-latency connectivity to cloud reasoning agents. Traffic engineering via Segment Routing over MPLS (SR-MPLS) and SR over IPv6 (SRv6) enables explicit path specification for latency-sensitive flows. Model distribution to edge endpoints requires versioned, efficient distribution protocols. Regional interconnect must be treated as a production input, not a shared utility—it is part of the AI supercomputer’s backplane.
PILLAR 3: OPERATIONAL INTELLIGENCE
Operational intelligence provides the control systems that make the network operable at scale. The AI-ready network cannot be managed through manual processes—a single AI cluster may contain thousands of switches requiring consistent configuration, where a single misconfigured buffer can stall thousands of GPUs.
Automation and Orchestration. The architectural response is declarative intent-based automation. The operator declares the desired network state using IETF YANG data models, and the automation framework translates this into device-level configuration via NETCONF, RESTCONF, and gNMI. Zero-touch provisioning enables switches to self-configure from the moment of installation. Configuration-as-code ensures every device conforms to architectural standards, with drift detected and corrected automatically. Network changes move through CI/CD pipelines that validate against policy and test under AI workload conditions before production deployment.
Telemetry and Monitoring. INT captures per-packet, per-path metrics at microsecond granularity. Streaming telemetry replaces polled monitoring with continuous, event-driven data push. The telemetry platform must ingest, store, and analyze millions of data points per second, enabling cross-layer correlation—tracing a GPU-level stall back through the fabric to the specific optical port and wavelength where the loss occurred. Predictive models detect performance degradation before it causes packet loss, shifting operations from reactive to proactive.
Testing and Validation. A dedicated testing environment must replicate production AI workload patterns—synchronized bursts, collective communication operations, checkpointing incast. Fault injection and chaos engineering validate network behavior under failure conditions. A digital twin of the production network, continuously synchronized, within a bounded delay, with real-time telemetry, enables what-if analysis for topology changes, capacity additions, and configuration updates before production deployment.
Security Architecture. Distributed AI dissolves the traditional network perimeter. The architectural response is in-fabric security: microsegmentation at the switch level validates every flow at the point of ingress, policy is bound to workload identity rather than network location, and the enforcement architecture relies on IEEE 802.1X, MACsec, and IPsec. Policy-as-code manages security rules through the same CI/CD pipelines as network configuration. The immutable audit trail serves double duty as both the security record and the compliance record.
PILLAR 4: STRATEGIC RESILIENCE
Strategic resilience ensures the network survives disruptions, scales with demand, and sustains itself over the long term.
Capacity Planning. Traditional capacity planning, based on historical averages and steady-state utilization, systematically underprovisions for AI. AI traffic is bursty, synchronized, and high-volume by design. Capacity must be provisioned for peak synchronized demand. Simulation-based planning models proposed network designs under projected AI workloads, identifying bottlenecks in the design phase before hardware is committed.
Disaster Recovery. AI training runs lasting weeks or months cannot be restarted from scratch. The network must support checkpointing at AI scale, with Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) defined per workload. The optical backbone must provide physically diverse paths with automatic protection switching. Failover architectures—active-active or active-passive—must be designed at the network level for inference workloads requiring high availability.
Business Continuity. The network fabric must tolerate WAN partitions without cascading failures, with local control planes capable of independent operation at each site. State reconciliation architecture—based on the shared event log pattern—must preserve causal ordering across partition boundaries. The network must support non-disruptive infrastructure refresh, with redundant paths and hitless failover enabling component replacement without interrupting workloads that run continuously for weeks or months.
The Five-Phase Implementation Roadmap
The migration from legacy to AI-ready network infrastructure is a multi-phase program that must deliver value at each stage while building toward the target architecture. Each phase has defined activities, deliverables, and success criteria. Each phase delivers measurable value before the next begins. Phase durations are calibrated for a Tier-1 cloud services provider; individual organizational timelines may vary based on scale, complexity, and resource availability. The success criteria stated for each phase are drawn from industry benchmarks and practitioner experience with large-scale network transformation programs. They represent targets that are ambitious but achievable for a Tier-1 cloud services provider with dedicated transformation resources and executive sponsorship.
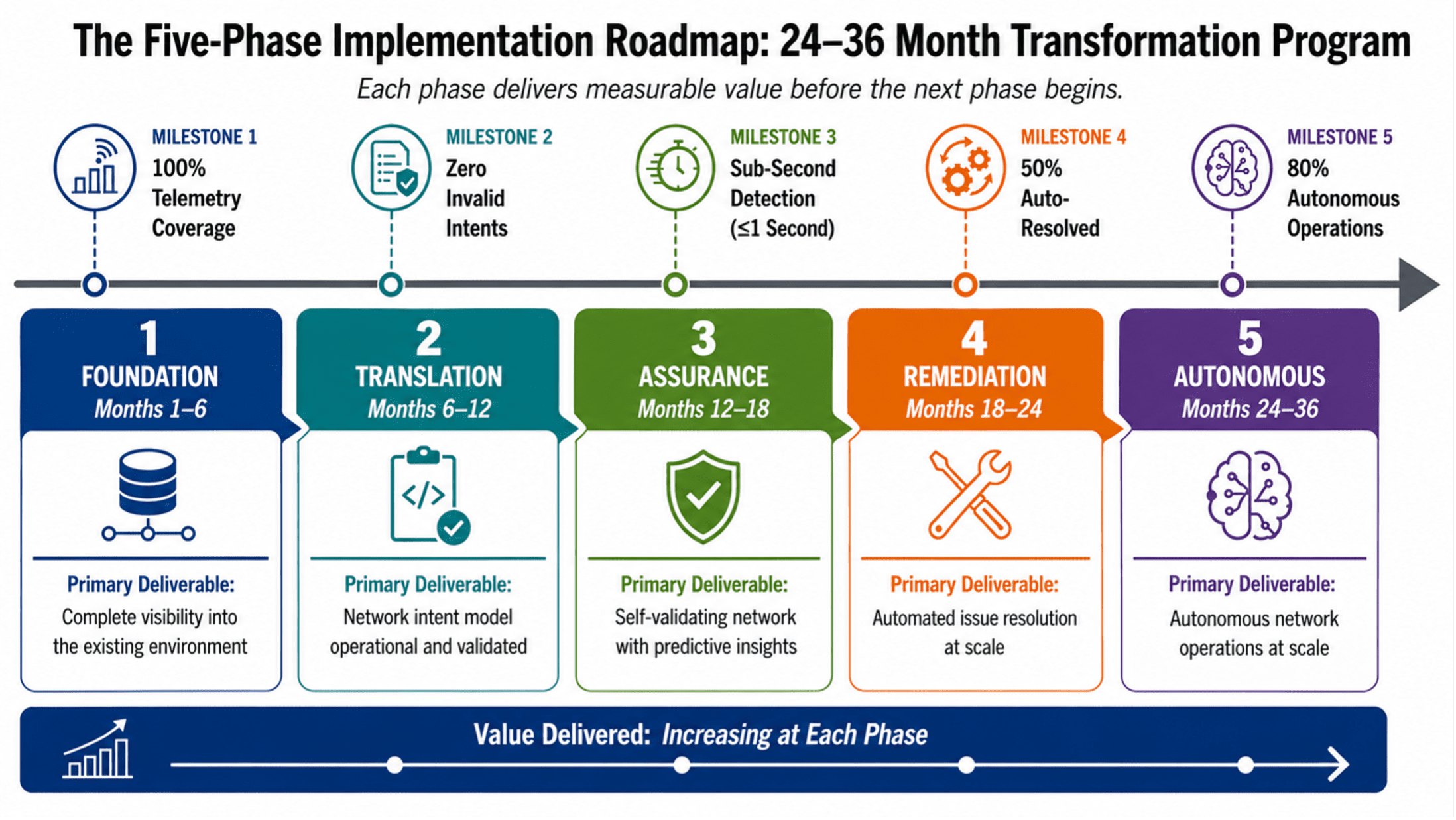
Figure 2: The Five-Phase Implementation Roadmap — A 24–36 Month Transformation Program.
PHASE 1: FOUNDATION (MONTHS 1–6)
The first phase establishes the essential building blocks. Nothing can be automated, optimized, or secured until the network is instrumented and its state is understood.
The starting point is telemetry. Streaming telemetry must be enabled across all network devices in the AI infrastructure path—switches, optics, fabric elements—using gRPC-based protocols and OpenConfig YANG data models. The deliverable is a centralized telemetry platform receiving continuous data streams from every device. The success criterion is 100% telemetry coverage. Without complete visibility, every subsequent phase operates on incomplete information.
With telemetry flowing, a topology knowledge graph must be built—a dynamic map of all devices, links, and interconnections, continuously updated from telemetry data and discovery protocols. The graph must reflect topology changes within seconds, not minutes. Accurate neighbor discovery across all fabric layers is the foundation on which intent-based automation will reason about the network.
Configuration management must be brought under version control. Every device configuration—PFC thresholds, QoS policies, dynamic load distribution parameters—must be stored in version-controlled repositories. Every change must be tracked and attributed. The success criterion is 100% configuration version control with no out-of-band changes permitted. An automation framework that deploys configuration changes cannot operate reliably if changes are also being made through manual processes that bypass the automation pipeline.
Finally, the foundational intent model must be established. This is a structured format for expressing network intent—topology, capacity, QoS policies—in machine-readable YANG-based models. The deliverable is five foundational intents, defined and validated against the existing network state:
- Lossless Transport Intent: “All Remote Direct Memory Access over Converged Ethernet (RoCE) traffic on the AI fabric shall receive PFC priority treatment with zero packet loss under sustained load.”
- Fabric Capacity Intent: “The AI fabric shall maintain a minimum of 30% headroom on all east-west links during peak utilization.”
- Optical Link Diversity Intent: “Every GPU cluster shall have at least two physically diverse optical paths to its checkpoint storage.”
- Configuration Compliance Intent: “All device configurations shall match version-controlled templates. Any deviation shall be detected and flagged within 60 seconds.”
- Telemetry Coverage Intent: “Every device in the AI network path shall stream telemetry data. Any device that stops streaming shall be flagged within 30 seconds.”
These five intents are scoped to be achievable within Phase 1 while covering the most critical dimensions of AI network operations: lossless transport, capacity, resilience, configuration compliance, and observability.
PHASE 2: TRANSLATION (MONTHS 6–12)
The second phase builds the machinery that translates intent into device-level configuration. This is where declarative automation becomes operational.
The centerpiece is the intent compiler—a translation engine that converts YAML or JSON intent specifications into device-level configuration via NETCONF, RESTCONF, and gNMI. The intent compiler is not merely a template engine. It must understand the capabilities and constraints of each target device, select the appropriate protocol for each configuration operation, and handle the transactional semantics that make configuration changes safe. The success criterion is that the five foundational intents from Phase 1 are compiled and deployed without manual intervention.
Before any compiled configuration reaches production, it must be validated in a digital twin—a virtual replica of the AI network, continuously synchronized with production telemetry. The digital twin enables what-if analysis: if this configuration is applied, what happens to fabric utilization, PFC pause events, and flow completion times? The success criterion is 100% of configuration changes validated in the digital twin before production deployment.
Validation checks must be automated. Every intent must pass feasibility validation (can the network support this intent given current capacity?), capability validation (do the target devices support the required features?), and policy validation (does this intent comply with security and operational policies?). The success criterion is zero invalid intents deployed to production.
Multi-domain support must be enabled. The intent compiler must support both data center fabric and optical backbone domains, translating a single intent into coordinated configurations across domains.
PHASE 3: ASSURANCE (MONTHS 12–18)
The third phase closes the loop between intent and reality. The network may be configured correctly at a point in time, but AI workloads cause continuous change—congestion patterns shift, optical performance degrades, buffer utilization fluctuates. Assurance ensures the network remains in its intended state.
Real-time telemetry monitoring must track SLA compliance for all AI network services, updated continuously from streaming telemetry rather than periodically from polled data. Sub-second detection latency for SLA deviations is the success criterion. A RoCE stall that lasts 500 milliseconds must be detected while it is happening, not after the training run has been disrupted.
Drift detection must compare the intended network state against the actual state continuously. Drift can take many forms: a configuration change applied outside the automation pipeline, a performance degradation that violates the intent without changing the configuration, a topology change due to a link failure. The success criterion is 99% detection accuracy for both configuration and performance drift.
The assurance dashboard must provide all stakeholders—network operations, compute operations, capacity planning—with real-time visibility into network state versus intent. Alerting must be integrated with the incident management system so that 100% of SLA breaches generate alerts within one second of detection.
PHASE 4: REMEDIATION (MONTHS 18–24)
The fourth phase enables the network to respond to drift and failures. Detection without response is observation without action. Remediation closes the loop.
Root cause analysis (RCA) must be automated. When drift is detected, the system must correlate telemetry data across layers—optical, fabric, device—to identify the source. A packet loss event at the GPU layer may originate from a congested optical link three hops away. The RCA engine must trace the event across layers. The success criterion is greater than 80% accuracy for common incident types.
At least three remediation types must be implemented and validated in the digital twin before production enablement: rollback to the last known good configuration, traffic rerouting around congested or failed links, and dynamic QoS adjustment.
A policy engine must govern which remediation actions are fully automated, which require human approval, and which are prohibited. The policy framework must be machine-readable, version-controlled, and enforced at the automation layer. The success criterion is 100% of automated remediation actions comply with defined policies.
Supervised remediation must enable a human-in-the-loop approval workflow for actions that exceed the automated threshold. The goal is that 50% of detected issues are resolved automatically without human intervention, with the remainder escalated for approval.
PHASE 5: AUTONOMOUS (MONTHS 24–36)
The final phase extends over 12 months—longer than the preceding phases—because full autonomy is not a single deployment event. It requires progressive expansion of automation scope, validation of continuous optimization across diverse workload patterns, and accumulation of sufficient operational data for the learning system to deliver meaningful accuracy improvements. Each increment of autonomy must be earned through demonstrated reliability.
The automation scope must be expanded to cover all common incident types identified and validated in Phase 4. The success criterion is that 80% of all incidents are resolved automatically. The remaining 20% represent novel failures, complex multi-domain incidents, or situations where policy requires human judgment.
Continuous optimization must become a background process. The network self-tunes PFC thresholds based on observed congestion patterns, adjusts dynamic load distribution policies as workload distributions shift, and reallocates buffer resources as traffic characteristics evolve. The success criterion is a 20% reduction in SLA violations compared to the Phase 3 baseline.
Cross-domain coordination must achieve full automation for standard intents. When a new GPU cluster is provisioned, the orchestration layer coordinates optical link provisioning, fabric configuration, and security policy establishment across domains without manual intervention. Human involvement is reserved for novel or high-risk changes.
The learning system must improve from experience. Machine learning models trained on historical incident and remediation data must increase root cause analysis accuracy over time. The success criterion is a 10% quarterly improvement in RCA accuracy.
COEXISTENCE: RUNNING LEGACY AND AI-READY NETWORKS IN PARALLEL
The transformation cannot be accomplished through a flag-day cutover. The existing cloud network must continue to operate and generate revenue throughout the transition. The AI-ready network is deployed as a separate physical infrastructure—dedicated optical links, dedicated fabric, dedicated switches—wherever possible. Physical separation eliminates the risk that AI workload traffic patterns will disrupt legacy services. Where physical separation is impractical, logical isolation with strict QoS enforcement provides the necessary workload separation. Interconnection points between the two networks must be engineered with the same packet loss, latency and throughput requirements as the AI-ready network. Operational processes must govern both environments simultaneously during a transition measured in years.
ORGANIZATIONAL TRANSFORMATION
The AI-ready network cannot be operated by a team trained only on legacy network operations. Three new skill domains become critical: AI workload literacy (understanding the traffic patterns and failure modes of distributed training and inference), telemetry and data engineering (building and operating streaming telemetry platforms and correlation engines), and automation engineering (designing and operating intent-based automation and CI/CD pipelines). The talent strategy must balance retraining existing engineers—many of the required skills are extensions of existing knowledge—with external hiring for skills that cannot be developed internally in the required timeframe. Retention of critical talent during the transformation is essential: the engineers who understand the legacy infrastructure are essential to the coexistence strategy.
FINANCIAL MODELING
Network investment for AI must be justified on value generation—the network cost per training run completed, per inference served, per GPU-hour utilized—not traditional cost efficiency metrics. This shift from cost-per-bit to value-per-outcome transforms the investment conversation. A network that costs more per gigabit but enables higher GPU utilization generates a return that far exceeds its cost premium. The five-phase roadmap enables investment to be spread over 24 to 36 months, with each phase delivering measurable value before the next begins. The cost of inaction must be quantified and presented alongside the cost of transformation.
CONCLUSIONS:
The physical network is no longer a utility layer that can be taken for granted. It is the foundation on which AI performance depends. The optical backbone determines whether GPU clusters operate at full utilization or sit idle. The network fabric determines whether distributed training completes in days or weeks. The automation and telemetry infrastructure determines whether issues are detected proactively or discovered after customer impact.
The four-pillar reference architecture defines what must be built. The five-phase implementation roadmap defines how to execute the transformation. Together, they form a complete program for infrastructure transformation leaders.
The technologies described here are deployed and operational in production AI networks today. The challenge for infrastructure leaders is not whether these approaches work, but how to adapt them to their organization’s specific constraints, scale, and timeline.
REFERENCES:
[1] TM Forum, “Autonomous Networks: Business Requirements and Framework,” TM Forum IG1251, 2025. [Online].
[2] AMD, “Next Gen Networking Transport for Large Scale AI Training,” May 2026. [Online].
htt
[3] Tolly Group, “Dell Networking Data Center AI Switch Fabric Congestion Mitigation Evaluation,” April 2026. [Online].
[4] Tech Field Day, “Cisco AI Networking Cluster Operations Deep Dive,” November 2025. [Online].
htt
[5] Akamai / WWT, “East-West Is the New North-South: Rethink Security for the AI-Driven Data Center,” February 2026. [Online]. htt
[6] NIST, “Zero Trust Architecture,” NIST Special Publication 800-207, Aug. 2020. [Online].
[7] IETF, “Network Configuration Protocol (NETCONF),” RFC 6241, June 2011. [Online].
[8] IETF, “RESTCONF Protocol,” RFC 8040, January 2017. [Online]. htt
[9] IEEE, “Priority-based Flow Control,” IEEE Standard 802.1Qbb, 2011.
[10] IEEE, “Congestion Notification,” IEEE Standard 802.1Qau, 2010.
[11] OpenConfig, “OpenConfig: Vendor-Neutral Network Configuration and Telemetry,” [Online]. https://www.
[12] Cloud Native Computing Foundation, “gRPC: A High-Performance, Open Source Universal RPC Framework,” [Online]. https://grpc.io/
[13] Ultra Ethernet Consortium, “Ultra Ethernet Specification,” [Online]. https://
………………………………………………………………………………………………………………………………………………………….
References from IEEE Techblog:
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
The enterprise network stack is collapsing; AI’s impact; comparison with “Batch Pipelines Break AI Agents”
ABOUT THE AUTHOR:

Shazia Hasnie, Ph.D., is VP Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale. She brings over 20 years of global experience in communications networks and holds a Ph.D. in Communications Engineering from the Australian National University.
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
By Alan J Weissberger
Executive Summary:
The rapid rise of agentic artificial intelligence (AI) is expected to drive material changes across data centers, service provider networks, and the broader telecom ecosystem. As agentic AI moves from chat-oriented interactions to autonomous digital agents, Cisco says that those workloads will not only increase traffic volumes, but also alter traffic characteristics in ways that place new demands on latency, security, orchestration, and distributed compute placement.
“We are entering into a Network Supercycle,” Jeetu Patel, Cisco’s president and chief product officer, said during his opening keynote at Cisco Live in Las Vegas.
As a result, network operators will need more resilient transport, edge compute, and optical capacity to support new traffic patterns and security demands.
Cisco execs pictured (left to right): Jeetu Patel, president and chief product officer; Chuck Robbins, chairman and CEO; Liz Centoni, EVP and chief customer experience officer; and Steven Clayton, SVP and chief communications officer.
Source: Jeff Baumgartner/Light Reading
AI Traffic Impact on Transport Requirements:
From a transport perspective, agentic AI traffic is likely to be more persistent, more interactive, and more latency-sensitive than conventional application traffic. Cisco has said AI-related network traffic is expected to triple over the next three years, with inference flows emerging as a major driver of load growth. That shift could place pressure on transport architectures that were optimized primarily for human-driven web, video, and enterprise application traffic
The implication for service providers is that traffic engineering will need to evolve toward finer-grained path control, stronger telemetry, and improved handling of asymmetric flows. AI sessions that span multiple exchanges between users, applications, and digital agents may also require more sophisticated policy enforcement and security integration across WAN, metro, and access layers.
Edge Compute Needs Grow:
Cisco’s remarks also point to a growing role for edge compute in telecom and cable networks. Some operators are already repurposing legacy central offices and mini data centers to support AI workloads, reflecting a broader shift toward distributed inference close to the user or device.
That architecture matters because many agentic AI use cases will be latency constrained and will not perform efficiently if all processing is centralized in distant cloud regions. Comcast and Charter have both announced AI edge strategies, underscoring how access networks can become part of the compute fabric rather than acting solely as last-mile connectivity.
For network operators, this suggests a new operational model in which compute, storage, and network functions are increasingly coordinated across regional and edge sites. In practical terms, the network becomes part of the application execution environment, not just the transport layer beneath it.
Optical Network Implications:
Optical infrastructure will likely carry much of the burden created by distributed AI deployments. As inference workloads expand across regional hubs, edge sites, and centralized clouds, operators may need higher-capacity optical transport to sustain east-west traffic between distributed compute nodes.
That points to greater demand for dense 400G and 800G interconnects, more flexible wavelength management, and lower-latency optical paths between metro aggregation points and AI facilities. The challenge is not only to scale throughput, but also to preserve path diversity, minimize jitter, and maintain predictable performance for machine-to-machine workloads that are increasingly sensitive to delay.
As AI traffic becomes more dynamic and more operationally critical, optical networks may need to be engineered with the same level of service awareness traditionally associated with enterprise transport and carrier-grade voice or mobile backhaul.
Security is a Top Priority:
Cisco cited security as a serious concern for agentic AI traffic. CEO Chuck Robbins said AI agents designed to help enterprise customers can run roughshod without a proper defense that can quickly detect, intercept and possibly “kill” them before they get out of control. It becomes an even bigger issue when they are built to be nefarious.
“AI changes the speed of defense,” Robbins said. “It’s empowering adversaries at a pace that we haven’t seen in our careers … These [AI] models are as bad as they are ever going to be …They’re only going to get better.”
Anthropic’s new Claude Mythos model, which can auto-detect and possibly exploit software vulnerabilities at scale, is now a “CEO-level discussion,” he added.
“We’re living in a post-Mythos world where security has to be fused and baked into the network,” Patel said, holding that vulnerabilities can now being attacked as soon as they arise.
“We need to reimagine security” in the AI era, Patel said, noting that AI agents will not only handle tasks locally but will be heading outside to connect to third-party agents, servers and various tools.
“Every agentic action is a routing challenge, a trust decision and a telemetry event,” Patel said. The emergence of agentic AI, he said, is shifting the security and permission focus from “access control” (for us humans) to “action control” for agents that will need to be closely monitored, controlled and, if needed, quickly intercepted.
“People don’t trust these agents right now,” Patel said later during a separate discussion with press and analysts.
These concerns also extend to AI agent identity, which Cisco is addressing with its recent agreement to acquire Astrix Security.
This extends to other types of guardrails and observability metrics, too, including the notion of “tokenomics” – essentially keeping tabs on how many tokens an AI agent could consume. If the agent is found to be overspending on tokens, it could be intercepted and shut down.
Patel suggested that, without guardrails, what a company pays for AI tokens for a year could be consumed by an agent in a week. Assessing such AI agent behavior was a key driver of Cisco’s acquisition of Galileo Technologies.
Cisco’s AI Stack:
Cisco is focused on a vertically integrated platform – starting with its Silicon One platform for data centers and enterprise devices, optics, switches, routers and access points, apps and services, and wrapped by a new Cisco Cloud Control platform announced this week. Though Cisco Cloud Control is able to provide unified access to Cisco’s tools, apps and services, such as Meraki, Catalyst and Splunk, Patel stressed that it will also be able to integrate with third parties and support an open ecosystem. Cisco is starting out with support from 52 partners, including AWS, Google Cloud, NetBrain and ServiceNow.
Telecom Market Transition:
Robbins said Cisco used AI to scan 1.8 billion lines of code in 25 different programming languages over the past eight weeks. Without AI models, that would’ve taken eight years, he said.
Patel described the industry as being at a pivotal moment, moving from chat bots to more advanced agents that function as “digital coworkers.” He noted that “These agents are going to be everywhere.”
That transition suggests telecom networks will increasingly support autonomous machine interactions at scale, with implications that extend beyond bandwidth growth into security, policy control, and distributed systems design. For operators and vendors alike, the strategic question is no longer whether AI will affect the network, but how quickly the network architecture can adapt.
………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/ai-machine-learning/cisco-ai-driving-a-network-supercycle-
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Cisco’s Silicon One G300 as the dominant AI networking fabric, competing with Broadcom’s Tomahawk 6 series
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco to join Stargate UAE consortium as a preferred tech partner
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
By Shazia Hasnie, Ph.D, editorial review by IEEE Techblog team member Sridhar Talari Rajagopal
Abstract:
The adoption of AI agents in network operations has exposed a critical architectural gap. Most enterprise data pipelines were designed for dashboards and reporting, not autonomous decision-making. When AI agents consume data from batch-oriented pipelines, five distinct failure modes emerge: stale data, memory gaps, delete blindness, schema fragility, and coordination failure. This article examines each failure mode, explains the underlying mechanism, and proposes architectural remedies grounded in streaming-first design principles. It also connects each technical failure to measurable business outcomes—extended downtime, recurring incidents, compliance exposure, silent decision degradation, and cascading impact. The result is both a diagnostic framework for I&O leaders and a financial argument for treating streaming data infrastructure as the prerequisite for autonomous operations.
Introduction: The Data Foundation Gap
Artificial intelligence is reshaping network operations. AI agents promise to detect anomalies, diagnose root causes, and execute remediation faster than human engineers. The industry has focused attention on models, GPUs, and orchestration frameworks. The data layer remains largely unexamined.
This is a critical oversight. Most enterprise data pipelines were built for human consumers. They serve dashboards, weekly reports, and historical analysis. Humans tolerate latency. Humans bring context. Humans notice when something looks wrong.
AI agents require something fundamentally different. They need real-time context. They need historical state. They need accurate representations of current reality. When these requirements are not met, agents do not complain. They act—on incomplete information, with incorrect assumptions, producing wrong outcomes.
The gap between what batch pipelines deliver and what agents require creates failure modes that most teams do not see until an agent makes the wrong decision. Recent analysis has identified the economic dimensions of this gap [1], while industry resources have begun documenting the specific failure patterns that arise when batch processing meets autonomous agents [6]. This article extends that work by identifying five distinct failure modes and proposing a streaming-first architectural response.
FIVE FAILURE MODES: ANATOMY OF BATCH-TO-AGENT MISMATCH
The following five failure modes represent the specific ways batch data pipelines undermine autonomous network operations. Each is examined through its mechanism—how the batch pipeline architecture produces the failure—its operational consequence, and the streaming-first architectural remedy that eliminates it. Together, they form a diagnostic taxonomy for any I&O team evaluating whether their data foundation is ready for Agentic AI.
Failure Mode 1: Stale Data
Mechanism: Batch telemetry pipelines poll, collect, and process data in cycles. Data is extracted on a schedule, transformed in bulk, and loaded into a destination—a warehouse, data lake, time-series database, or feature store that holds a static, point-in-time snapshot of the source. Between cycles, the pipeline holds no current state. An AI agent that spins up between cycles receives a snapshot of the past.
Consequence: The agent diagnoses an outage using telemetry from five minutes ago. The network state has changed during that interval. Routes have shifted. Traffic has been redirected. Thus, the agent’s diagnosis is based on a reality that no longer exists. Remediation actions applied to a past state can worsen the current incident. The agent becomes a liability rather than an asset. Industry documentation confirms that AI agents require continuous data freshness to function correctly [5].
Architectural Remedy: Streaming telemetry replaces cyclical polling with continuous event push. Data flows from source to consumer in real time, ingested directly into the streaming platform’s durable event log [2]. The agent consumes from a live stream, not a stale snapshot. Context acquisition takes milliseconds. The cognitive loop remains intact. This is not an add-on to the batch pipeline. It is a structural replacement of the ingestion layer.
Failure Mode 2: Memory Gap
Mechanism: Batch pipelines deliver windows of data—the last hour, the last day, the last processing cycle. They do not preserve the sequence of events that led to the current moment. Historical context is stripped away with each new extract. The pipeline knows what happened. It does not know what happened before.
Consequence: An agent responding to an interface flap cannot answer the most basic diagnostic question: has this happened before? It cannot correlate the current event with the three similar events that occurred in the preceding 24 hours. It cannot detect the pattern that would reveal a degrading optical module. Every incident appears isolated. Pattern recognition—the core value proposition of AI-driven operations—is structurally impossible. The distinction between streaming and batch architectures for these use cases has been well-documented [4].
Architectural Remedy: A durable event log with configurable retention serves as the agent’s memory [2]. Unlike a batch window, which discards history with each new extract, the event log preserves the ordered sequence of all events within the retention period. The agent seeks backward in the log on startup and replays the preceding window of telemetry. Pattern detection across time becomes native to the architecture. This is not a separate cache layered on top. It is the storage layer itself—immutable, ordered, and built for event replay from any offset.
Failure Mode 3: Delete Blindness
Mechanism: Batch pipeline’s Extract, Transform, Load (ETL) processes compare snapshots of source data. They do not watch the database transaction log. They identify what exists at two points in time and process the difference. When a record is deleted from the source system, the pipeline has no way of distinguishing between a row that was deleted and a row that was simply omitted due to extraction error, filtering logic, or schema mismatch. The absence of a row is not an event. It is a gap. Batch pipelines are not designed to interpret gaps as meaningful signals. The record simply vanishes from the next extract. The downstream consumer—an AI agent or any other system—has no way of knowing the record ever existed.
Consequence: The agent queries the downstream data store and finds no record for a deactivated account, a revoked certificate, or a cancelled change order. It cannot distinguish between “never existed” and “was deleted,” so it treats the absence as neutral.
The agent makes decisions on ghosts—data that no longer exists in source systems. In access control scenarios, this is not an operational error. It is a security incident. This specific failure mode has been identified in analyses of batch processing limitations for AI agents [6].
Architectural Remedy: Change data capture (CDC), implemented through Kafka Connect with Debezium connectors, reads the database transaction log directly [2], [8]. Debezium provides CDC source connectors for MySQL, PostgreSQL, MongoDB, SQL Server, and other databases — capturing inserts, updates, and deletes as discrete events with explicit operation types by tailing the database’s native transaction log. Nothing is invisible to the pipeline. The streaming architecture knows not only what exists but what ceased to exist. This is not an ETL workaround with soft-delete flags. It is a structural capability of the integration layer, converting database changes into first-class events the moment they occur.
Failure Mode 4: Schema Fragility
Mechanism: Source database schemas change over time. Columns are renamed, added, deprecated, or re-typed. Batch pipelines are configured for a specific schema at extraction time. When the source schema changes, the pipeline responds in one of two ways. It fails silently and drops the affected field from every subsequent extract. Or it fails loudly and stops processing entirely.
Silent failure is the more dangerous outcome. The pipeline continues delivering data. The consumer has no indication that a critical field is missing.
Consequence: The agent continues operating without a critical data input. It makes decisions with incomplete information. It has no awareness that its reasoning is compromised. The wrong decisions accumulate. By the time the missing field is discovered—often through an operational failure rather than a monitoring alert—the cost of remediation includes auditing and correcting every decision made during the degradation window.
Architectural Remedy: A schema registry with compatibility enforcement validates schema changes before they propagate to downstream consumers [2]. Streaming platforms can enforce backward and forward compatibility rules at the producer level. A breaking schema change is rejected before any data is published. The pipeline fails loudly and immediately. This is not a documentation standard or a code review checklist. It is a structural governance layer embedded in the streaming architecture itself, preventing silent field loss at the point of ingestion.
Failure Mode 5: Coordination Failure
Mechanism: When multiple AI agents operate on batch-derived data, each agent consumes a separate, potentially inconsistent snapshot. Agent A receives data from the 10:00 AM extract. Agent B receives data from the 10:15 AM extract. The extracts differ. Each agent holds a different version of reality. There is no shared, ordered log of events that all agents consume.
Consequence: Two agents respond to the same cascading failure. Agent A identifies a BGP routing issue and begins rerouting traffic. Agent B identifies a DNS resolution failure and begins modifying name server configurations. Neither agent knows the other acted. The redundant changes compete. The conflicting configurations create new instability. The original incident expands rather than resolves. What began as a single point of failure becomes a cascade that erodes trust in autonomous operations.
Architectural Remedy: A shared, ordered event log serves as a single source of truth for all agents in the system. Every agent consumes from the same log. Actions taken by one agent are published back to the log as events, immediately visible to all others [7]. Coordination becomes native to the architecture.
Visibility alone, however, does not prevent conflicting actions. Two agents may observe the same anomaly and both initiate remediation before either’s action becomes visible on the log. In practice, this is addressed through complementary mechanisms layered on the same event-driven model: action intent events that signal an agent is about to act, giving others a window to defer; idempotency keys that prevent duplicate remediation from causing harm; and lightweight leases for resources that should only be modified by one agent at a time. These mechanisms do not require a central coordinator. They are published to the same log, consumed by the same agents, and enforced through the same ordered stream.
This is not a separate orchestration layer or message bus bolted onto the side. It is the core of the streaming platform—a unified, ordered, multi-consumer event stream that provides both the shared state and the coordination primitives that eliminate the inconsistent snapshots batch architectures produce by default.
Batch-to-Streaming Reference Architecture — Five Failure Modes and Their Architectural Remedies
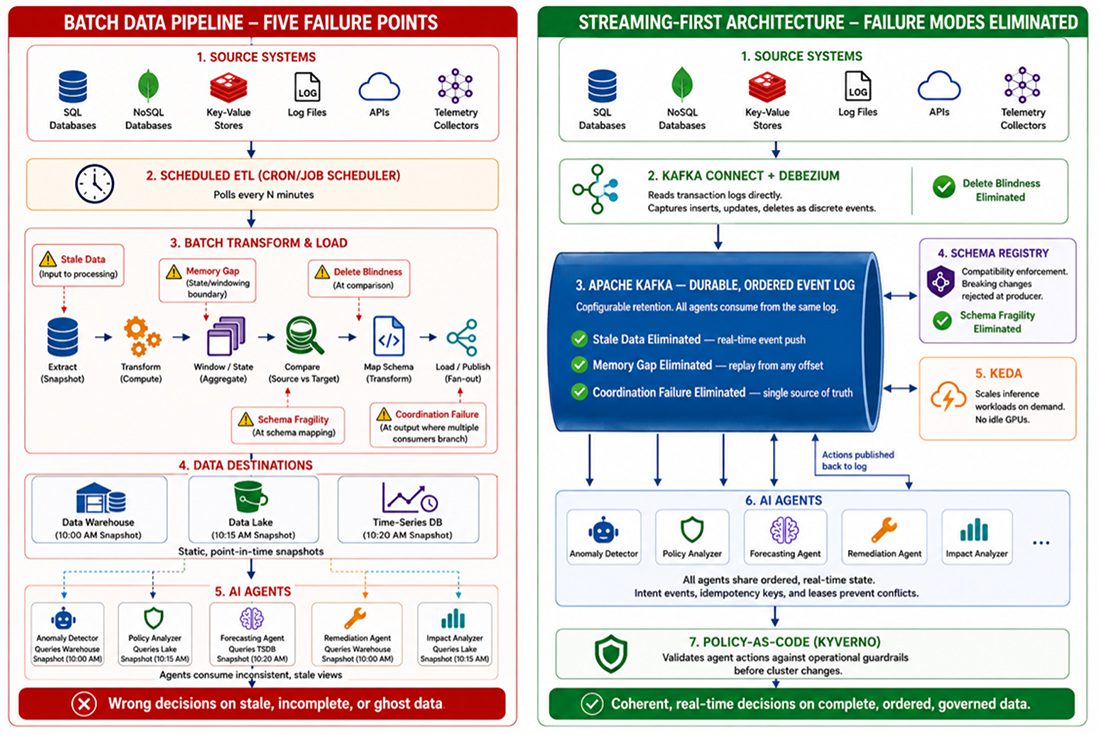
THE UNIFIED DIAGNOSTIC FRAMEWORK
The five failure modes translate into a practical audit that I&O leaders can apply to their own infrastructure. Each question corresponds to a specific architectural requirement.
The Five-Question Audit
- Can the data pipeline deliver real-time context to an agent the moment it wakes up? If not, the system is vulnerable to stale data failures.
- Can the agent access the preceding window of telemetry to detect patterns across events? If not, the system is vulnerable to memory gap failures.
- Does the pipeline capture deletes as explicit events with operation types? If not, the system is vulnerable to delete blindness.
- Does the pipeline detect schema changes before they propagate to downstream consumers? If not, the system is vulnerable to schema fragility.
- Do all agents share a single, ordered view of events with visibility into each other’s actions? If not, the system is vulnerable to coordination failure.
A negative answer to any one of these questions signals a data foundation that is not ready for autonomous operations. The model is not the bottleneck. The GPUs are not the bottleneck. The telemetry pipeline is.
THE MIGRATION PATH: FROM BATCH TO STREAMING-FIRST
Adopting a streaming-first architecture does not require abandoning existing batch investments overnight. For most organizations, the transition follows a coexistence model: streaming pipelines are introduced alongside batch pipelines, not as an immediate replacement.
The practical starting point is to identify the highest-value agent—the one whose decisions carry the greatest operational or financial consequence—and convert its data pipeline first. This agent is typically the one where stale data, memory gaps, or coordination failures have produced measurable incidents. Converting this single pipeline to streaming telemetry with a durable event log delivers a targeted operational improvement while the rest of the batch estate continues to function.
From there, adoption expands incrementally. Each additional agent is migrated as operational experience with the streaming platform grows. Teams develop competence in offset management, schema governance through the registry, and backpressure handling while batch pipelines continue to serve lower-priority consumers. The streaming and batch estates coexist for a transition period measured in months, not days.
This incremental approach also reveals where streaming delivers the greatest marginal benefit. Not every data flow requires real-time treatment. Dashboards fed by hourly batch extracts may serve their purpose indefinitely. The streaming investment should be directed at the pipelines that feed autonomous agents—the flows where the five failure modes carry real operational consequence. The goal is not to stream everything. It is to stream the right things first.
THE BUSINESS IMPACT: FROM TECHNICAL FAILURE TO FINANCIAL CONSEQUENCE
Technical failures in the data pipeline do not remain technical. They cascade into business outcomes that appear on budget reviews, SLA reports, and board presentations. Each failure mode carries a distinct financial consequence.
Stale Data → Extended Downtime
An agent diagnosing from stale telemetry makes incorrect decisions. Remediation applied to a past state can worsen the current incident. Mean Time to Resolution increases. For revenue-generating services, every minute of extended downtime translates to lost revenue and SLA penalty accrual.
Consider an illustrative model: a Tier-1 service provider processing $50M in customer transactions per hour, 5-minute stale-data induced misdiagnosis that extends an outage by 15 minutes represents $12.5M in direct revenue loss—not counting SLA penalties, regulatory scrutiny, or reputational harm. The cost of a single such incident can exceed the annual investment in the streaming infrastructure that would have prevented it. If even a portion of such incidents are eliminated by replacing the batch pipeline feeding the diagnostic agent with a streaming backbone, the infrastructure investment is recovered in a single avoided outage.
Memory Gap → Recurring Incidents
An agent without historical context cannot recognize chronic conditions. A flapping interface, a memory leak, or a degrading optical module triggers the same alert repeatedly. Each occurrence consumes GPU inference cycles. Each occurrence generates a ticket. Each occurrence may require human escalation. The cumulative cost of a single undiagnosed chronic issue, multiplied across an enterprise network over a year, represents operational expenditure that a stateful agent could eliminate.
Delete Blindness → Compliance and Security Exposure
An agent acting on deleted records makes authorization decisions based on invalid state. A deactivated account granted access. A revoked certificate treated as valid. In regulated industries, these errors are compliance violations with defined financial penalties and reporting obligations. The cost of a single access control error caused by ghost data can exceed the annual cost of the streaming infrastructure that would have prevented it.
Schema Fragility → Silent Decision Degradation
When a batch pipeline drops a critical field, the agent does not fail loudly. It continues operating with incomplete inputs. Decisions degrade silently. The cost includes not only the direct operational impact but the effort of auditing and correcting every decision made during the degradation window. Silent failure multiplies eventual remediation cost.
Coordination Failure → Cascading Impact
When multiple agents act on inconsistent views of reality, they create new problems. Redundant changes compete. Conflicting configurations destabilize the environment. The original incident expands. The cost includes extended resolution time, additional engineering effort, and eroded trust in autonomous operations. Organizational credibility is a balance sheet item that coordination failure depletes.
The Aggregated View
Taken together, the five failure modes represent a predictable drain on AI investment returns. An organization that deploys expensive GPU infrastructure, fine-tunes capable models, and implements event-driven orchestration [3]—but feeds all of it with a batch data pipeline—has built an autonomous operations capability on a foundation that guarantees suboptimal outcomes. The streaming backbone is not an incremental cost. It is the insurance policy that protects the returns on every other AI infrastructure investment.
CONCLUSION: STREAMING-FIRST AS THE ARCHITECTURAL PREREQUISITE
The five failure modes share a common root cause. Batch data pipelines were designed for human consumers who tolerate latency, bring context, and notice anomalies. AI agents tolerate nothing. They act on what they receive.
Each failure mode is addressable within a unified streaming data architecture. Streaming telemetry solves stale data by replacing cyclical polling with continuous event push. Durable event logs solve memory gaps by preserving the sequence of events with configurable retention, allowing agents to replay history and detect patterns across time. Change data capture—a structural component of the streaming architecture implemented through Kafka Connect and Debezium—solves delete blindness by reading database transaction logs directly, capturing inserts, updates, and deletes as discrete events with explicit operation types. A schema registry with compatibility enforcement solves schema fragility by validating schema changes before they propagate downstream, catching breaking changes at the source rather than discovering them after agent failure. A shared, ordered event log solves coordination failure by serving as a single source of truth that all agents consume, ensuring every agent operates on the same reality with visibility into every other agent’s actions—complemented by intent events, idempotency keys, and lightweight leases that prevent conflicting actions without a central coordinator.
These are not disparate tools. They are structural elements of a single streaming data architecture. Apache Kafka provides the durable, shared event log at the core. Kafka Connect provides the integration framework for change data capture, ingesting database changes as first-class events. Schema Registry provides the compatibility governance layer. Together, they form a complete data foundation where stale data, memory gaps, delete blindness, schema fragility, and coordination failure are eliminated by design—not patched after the fact.
These architectural components eliminate the data-layer failure modes. But real-time data also enables real-time action—and that speed demands an execution-layer governance framework. Policy-as-code engines ensure that agent decisions, even when based on perfect context and full state, are validated against operational guardrails before they become cluster changes. The streaming backbone delivers the context. The policy layer ensures that context is acted upon safely.
This streaming architecture is not an end in itself. It is the data foundation upon which event-driven network operations can be built. While the streaming backbone eliminates the data-layer failure modes, organizations that pair it with event-driven compute unlock an additional dimension of efficiency. When a telemetry event flows through the event log and an anomaly is detected, that same stream can trigger the Kubernetes Event-driven Autoscaling (KEDA) of inference workloads [3]—spinning up the right-sized model at the right moment, on the right context. The streaming backbone delivers the context. Event-driven orchestration delivers the compute. Together, they close the loop from detection to inference, ensuring the agent has both the data and the compute it needs without the waste of always-on infrastructure.
The barrier is not technology. Each of these architectural components is proven, open-source, and deployed in production environments today. The barrier is architectural awareness. Organizations that invest in a streaming-first data architecture will deploy AI agents that deliver on their promise. Organizations that do not will discover these failure modes in production—after the wrong decision is already made.
The streaming data architecture is not a performance upgrade for Agentic AI. It is the architectural prerequisite.
REFERENCES
[1] P. Madduri and A. L. Thakur, “The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core,” IEEE ComSoc Technology Blog, April 2026. [Online]. Available: https://techblog.comsoc.org/2026/03/30/the-financial-trap-of-autonomous-networks-scaling-agentic-ai-in-the-telecom-core/
[2] Apache Software Foundation, “Apache Kafka Documentation.” [Online].
Available: https://kafka.apache.org/42/getting-started/introduction/
[3] Cloud Native Computing Foundation, “KEDA: Kubernetes Event-driven Autoscaling.” [Online]. Available: https://keda.sh/
[4] Streamkap, “Streaming ETL vs. Batch ETL: A Decision Framework.” [Online].
Available: https://streamkap.com/resources-and-guides/streaming-etl-vs-batch-etl
[5] Streamkap, “Real-Time vs Batch Data for AI Agents: Why Freshness Matters.” [Online]. Available: https://streamkap.com/resources-and-guides/real-time-vs-batch-data-for-agents
[6] Streamkap, “Why AI Agents Can’t Use Batch Data.” [Online]. Available: https://streamkap.com/resources-and-guides/why-agents-cant-use-batch-data
[7] Redpanda, “Building safe, multi-agent AI systems in Redpanda Agentic Data Plane.” [Online]. Available: https://www.redpanda.com/blog/adp-governed-multi-agent-ai-cloud
[8] Debezium Community, “Debezium: Open-Source Change Data Capture,” Debezium Documentation. [Online]. Available: https://debezium.io/
ABOUT THE AUTHOR
Shazia Hasnie, Ph.D., is VP, Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations, AI-driven automation, and streaming data architectures. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale.
Key Differences Between Network Cybersecurity and Control System Cybersecurity & Why It Matters
By Joe Weiss with Alan J Weissberger
Introduction:
The Operational Technology (OT) [1.] cybersecurity [2.] community continues to ignore control system cyber-incidents [3.] – a governance failure masquerading as a vocabulary issue.
IT and OT network data breaches are documented in multiple sources such as the Verizon Data Breach Report, CISA documents, and others. Palo Alto Networks notes that nearly 70% of industrial firms had an OT cyber-attack last year. Those cyber-attacks were from data breaches – not always causing equipment damage.
Industrial organizations need an integrated and cyber resilient IT-OT framework to address this increasingly sophisticated threat landscape, but it appears they’re not well prepared to defend against network or control system cyberattacks.
Note 1. Operational Technology refers to the combination of hardware and software designed to directly monitor, control, and manage physical devices, industrial equipment, and critical processes.
Note 2. Cybersecurity can be defined as the practice of protecting people, systems and data from cyberattacks by using various technologies, processes and policies.
Note 3. Cyber-incidents are defined as electronic communications between systems that effects Confidentiality, Integrity, or Availability. This is an IT-centric definition because Safety is not addressed.

Image Credit: txOne Networks
There are two communities addressing cybersecurity:
- The more prevalent community is the one involved in data security. This includes IT and OT network security and is focused on data breaches.
- The second community is focused on engineering security. It is less well-known, but very critical. This discipline is focused on safety, reliability, and productivity.
Professor Ross Anderson stated in his seminal book, “Security Engineering: A Guide to Building Dependable Distributed Systems,” that security engineering is about building systems to remain dependable in the face of malice, error, or mischance.”
The culture gap between network security and engineering organizations will be addressed in the June 2026 issue of IEEE Computer magazine, “Packets and Process: What Network Security and Engineering Get Wrong About Each Other.”
Discussion:
The OT cybersecurity community’s mission is to focus on OT network cyber-attacks. However, its charter does not extend to malicious and unintentional control system cyber incidents involving process sensors, actuators, motors, turbines, transformers, etc.
Importantly, control system cyber incidents can be physics-related rather than network-related. The 2007 Aurora vulnerability test at the Idaho National Laboratory destroyed a 2 MW commercial diesel generator by remotely restarting the generator out- of-phase with the grid. This is a gap in protection of the electric grid and was addressed in the October 2025 IEEE Computer magazine article, “Physics-Based Cyberattacks Against Electric Power Grids and Alternating Current Equipment.”
Idaho National Laboratory ran the Aurora Generator Test in 2007 to demonstrate how a cyberattack could destroy physical components of the electric grid. The diesel generator used in the experiment beginning to smoke as shown below:

Aurora Generator Test. Image Credit: Wikipedia
Industry and government OT cybersecurity experts continue to downplay the threat of control system cyberattacks and ignore actual control system incidents that do not originate from OT networks by not calling them cyber-related.
There have been more than 20 million control system cyber incidents that have killed more than 30,000 people. Most of these incidents occurred below the IP-Ethernet layers where there is no cyber forensics nor cybersecurity training. As a result, the majority of these incidents were not identified as being cyber-related.
This indicates that control system cyber incidents that are not classified as IP-Ethernet incidents need their own classification as issues to be addressed by cybersecurity policy, especially for critical infrastructure where accidental and/or malicious cyber failures could result in widespread death and destruction.
Given the current geopolitical environment, nation-states are actively reassessing their capabilities to disrupt adversary infrastructure at scale. In this context, dismissing control system cyber incidents solely because they do not originate from traditional IP-based vectors introduces significant risk. Threat actors are increasingly targeting critical infrastructure and associated control systems—spanning both IT and OT domains—leveraging diverse attack surfaces beyond conventional network entry points.
A parallel issue within both the IT and OT security communities is the tendency to classify incidents as “cyber” only when malicious intent is confirmed. This narrow definition is problematic.
For example, the July 2024 CrowdStrike-related outage, which caused global operational disruptions, clearly met the functional criteria of a cyber-incident due to its systemic impact on networked systems. However, its non-malicious origin led some security governance bodies to exclude it from cyber incident classification. Such distinctions can undermine resilience planning, as they fail to account for the full spectrum of cyber-induced operational risk, including software supply chain failures and systemic misconfigurations.
ERPI Focus:
The European Risk Policy Institute (ERPI) was founded by the Australian Risk Policy Institute as part of the Global Risk Policy Network. EPRI Chairman wrote in a blog titled, “Control system cyber incidents and network breaches are apples and oranges”:
“From our ERPI / 3°C World SRP® perspective, Weiss is pointing at a governance failure masquerading as a vocabulary issue: if you define “cyber incident” through an IT breach lens, you will miss (or dismiss) the incidents that actually move risk —those that degrade continuity lifelines by disrupting physical processes. He makes the case that control-system cyber incidents include electronic/automation failures across sensor signals, control logic, firmware and field device communications, and that many are non-malicious yet still produce loss of view, loss of control, equipment damage, and safety/environmental consequences.
What matters strategically is the reporting and response architecture. Breach-centric metrics (and the cultural reflex that “no attack = no incident”) bias organizations toward under-detection, weak root-cause discipline, and false trend comparisons—exactly when coupled infrastructures are most fragile and repair cycles are tight. Weiss’s bridge condition is practical: align engineering and security on a shared incident definition, and train both communities in control-system incident reality so that operational anomalies are treated as cyber-relevant signals, not “maintenance noise.”
If you’re responsible for critical infrastructure, this is a reminder to recalibrate your incident taxonomy and your board narrative: the control-room outcome is the headline, and the network story is only one possible path to it.”
The Crucial Importance of Process Sensors:
Process sensors represent the biggest gap between data security and engineering security. Perplexity.ai explains this gap in detail -see below, but first we distinguish between data security and engineering security:
- Data security focuses on IP-native devices such as firewalls, routers, switches, etc.
- Engineering security should be focused on engineering devices and equipment that could cause equipment damage and deaths but have no cybersecurity, authentication, or cyber forensics. This includes process sensors, actuators, motors, transformers, inverters, etc. However, that focus is often not achieved.
Perplexity.ai on the Data vs. Information Security Gap:
Process sensors sit at the junction of physical process integrity and digital telemetry, so they expose a gap that neither data security teams nor engineering security teams fully own today. In practice, security teams tend to focus on protecting data pipelines, identities, and networks, while engineering teams focus on measurement accuracy, calibration, availability, and safety; the sensor itself often falls between those disciplines.
Process sensors are not just data endpoints; they are safety- and control-relevant instruments whose outputs can drive operators, PLCs, DCS logic, and downstream automation. If a sensor is spoofed, degraded, miscalibrated, or manipulated, the result is not only bad data but potentially unsafe or physically damaging control actions.
Traditional data security assumes the main problem is confidentiality, integrity, and availability of information in transit or at rest. But process sensors often use legacy field protocols, serial links, gateways, or embedded devices that were engineered for function and reliability rather than cryptographic assurance, making them difficult to secure using conventional enterprise controls.
Engineering security is usually optimized for process correctness, alarms, redundancy, and fail-safe behavior, not adversarial manipulation of the measurement layer. That means the sensor may be treated as trustworthy instrumentation, even though compromised or false sensor data can undermine control logic, operator decisions, and safety systems.
The core mismatch: The real issue is that data security protects the pipeline, while engineering security protects the process, but process sensors belong to both domains. Because ownership is split, sensor trust, authentication, anomaly detection, and physical tamper resistance are often addressed inconsistently or not at all, creating a blind spot at the boundary between cyber and physical risk.
Highlights of Sensors Converge Conference Presentation:
To address these important issues and gaps, I will be presenting at the Sensors Converge conference in Santa Clara, CA on May 7, 2026. The title of my talk is, “Process Sensor Monitoring for Cybersecurity, Reliability, and Safety.” The presentation will include the following topics:
- Process sensors (Level 0 devices) are inherently cyber vulnerable yet remain largely unrecognized by cybersecurity organizations.
- Process sensor incidents, both malicious and unintentional, have caused catastrophic and fatal cyber/operational events across multiple sectors, but were not identified as being cyber-related.
- Fatalities have occurred in every decade since the 1980s, including this decade.
- Monitoring process sensors at the physics level can materially improve reliability, safety, and cybersecurity.
- A discussion of what a process sensor cybersecurity program should include and what organizations should be involved.
- The implications of process sensors which are not cyber-secure, because they don’t meet U.S. and/or EU cybersecurity requirements.
Nation-state actors, including Russia, China, and Iran, understand Level 0 cyber deficiencies. In sharp contrast, most cyber defenders do not and won’t identify process sensor incidents as being cyber-related. This gap helps explain why process sensor cybersecurity remains largely absent from OT security forums and RSA Conference discussions. It may also explain why government OT cybersecurity advisories don’t include insecure Level 0 devices, even though process sensors provide the trusted input to controllers and SCADA/DCS systems.
Conclusions:
Network cybersecurity functions across IT and OT domains, and control system engineering organizations, operate with fundamentally different objectives, taxonomies, and thresholds for identifying and classifying cyber incidents. This divergence has led to a persistent disconnect in how incidents affecting control systems are recognized and addressed within broader network security governance frameworks. Dismissing control system cyber events because they fall outside narrow, IT-centric definitions is not merely a semantic issue—it reflects a structural governance gap with direct implications for critical infrastructure resilience.
To address this, industry and government stakeholders must converge on a harmonized definition of cyber incidents that encompasses both network-centric and control system–centric perspectives. This alignment should be supported by cross-domain training, ensuring that both network security practitioners and engineering teams possess sufficient understanding of control system architectures, threat models, and failure modes. Without such integration, efforts to compare incident frequency, severity, and systemic impact across IT networks and control systems will remain inconsistent and misleading. More critically, this fragmentation will continue to obscure systemic risk, leaving essential infrastructure sectors exposed to increasingly sophisticated and multi-domain cyber threats.
About Joe Weiss:

Joe Weiss is an expert on control system cyber security. He authored the 2010 book, “Protecting Industrial Control Systems from Electronic Threats.”
Joe is an ISA Fellow, Emeritus Managing Director of ISA99, an IEEE Senior Member, has patents on instrumentation, control systems, and OT networks. He is a professional engineer with CISM and CRISC certifications and is a member of Control Process Automation Hall of Fame.
References:
https://www.paloaltonetworks.com/resources/research/state-of-ot-security-report
OT Cybersecurity: The Guide to Securing Industrial Systems
Verizon Business sees escalating risks in mobile and IoT security
Anthropic’s Project Glasswing aims to reshape IT cybersecurity
Emerging Cybersecurity Risks in Modern Manufacturing Factory Networks
Cybersecurity threats in telecoms require protection of network infrastructure and availability
StrandConsult Analysis: European Commission second 5G Cybersecurity Toolbox report
IEEE/SCU SoE Virtual Event: May 26, 2022- Critical Cybersecurity Issues for Cellular Networks (3G/4G, 5G), IoT, and Cloud Resident Data Centers
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
By Pavan Madduri with Ajay Lotan Thakur
The telecom industry wants autonomous, self-healing networks, but nobody is looking at the GPU bill. Running Agentic AI 24/7 “just in case” will bankrupt your IT department and ruin your ESG goals. The only way to survive the autonomous era is ruthless, event-driven orchestration that scales cognitive compute to absolute zero.
Introduction – The Compute Crisis:
The Compute Crisis Nobody is Talking About
Everyone in telecom right now is obsessed with “self-healing” autonomous networks. The vendor pitch sounds amazing. Just drop in some Agentic AI, let it watch your data plane, and watch it fix anomalies without a human ever touching a keyboard. But there’s a massive trap hiding underneath all that hype, and enterprise architects are completely ignoring it. It comes down to the raw physics of AI compute.
Unlike your standard microservices, which just run deterministic, compiled code on cheap CPU cycles, Agentic AI needs massive foundation models. To actually reason through a network failure, these models have to load gigabytes of weights into Video RAM and generate tokens. You need dedicated GPUs for this. We aren’t talking about cheap, stateless API calls here. These are the most expensive, power-hungry workloads in your entire datacenter.
If a telco tries to run an autonomous core the old-fashioned way by keeping high-end GPU nodes spinning 24/7 just in case a BGP route flaps, their cloud bill is going to wipe out any operational savings the AI was supposed to deliver.
The reality is that autonomy is no longer just a software problem. It’s a financial one. The telcos that actually win will not be the ones with the smartest AI. They will be the ones who figure out how to build a strict “scale-to-zero” environment. They need to spin up that expensive cognitive compute exactly when it is needed, and kill it the exact second the job is done.
Why Traditional Auto-scaling is Broken for AI:
When platform engineers first see the compute costs of running these AI agents, their first instinct is usually just to slap standard Kubernetes Horizontal Pod Autoscaling (HPA) on the cluster and call it a day. But standard HPA was built for stateless web servers, not massive cognitive engines. If you try to use it for Agentic AI in a telecom core, you’re going to fail for two big reasons.
The Cold-Start Penalty: Traditional autoscaling is entirely reactive. It sits around waiting for a CPU to hit 80% before it decides to scale up. In telecom, SLAs are measured in sub-milliseconds. If you wait for an anomaly to spike your CPU, then provision a new GPU node, pull a massive AI container image, and load the model weights into VRAM, you are talking about minutes of delay. By the time your AI agent actually wakes up to fix the problem, you have already breached your SLA.
CPU Utilization is a Liar: For AI workloads, standard hardware metrics are completely misleading. A GPU could be pegged at 90% utilization just thinking through a minor log warning, while a massive, critical network failure is stuck waiting in the queue. If your scaling logic is tied to hardware metrics instead of the actual severity of the event queue, you are just going to burn budget scaling blindly.
We have to abandon reactive resource metrics entirely and move to event-driven orchestration.
The Fix – Event-Driven Orchestration:
If standard HPA is broken for this, what is the fix? You have to completely decouple the infrastructure from the workload using strict, event-driven orchestration.
Instead of keeping baseline infrastructure running just to maintain a state, you treat cognitive compute as 100% ephemeral. You don’t scale based on how hard the CPU is working. You scale based on the exact depth and severity of the anomaly queue.
To actually build this, architects need purpose-built event-driven scalers like KEDA (Kubernetes Event-driven Autoscaling). KEDA lets your cluster completely bypass those reactive hardware metrics and listen directly to the network’s data plane.
But how do you avoid the cold-start latency of booting a fresh GPU pod? KEDA solves this by reacting to the event queue length itself rather than waiting for an existing pod’s CPU to max out. By the time a traditional HPA notices a CPU spike, the system is already overwhelmed. (To solve this exact issue in production, I open-sourced a custom KEDA scaler specifically designed to scrape and react to native GPU metrics, allowing the orchestrator to scale cognitive workloads preemptively. You can view the architecture on [GitHub])
KEDA intercepts the telemetry trigger at the source. When paired with a warm pool of paused GPU nodes and pre-pulled container images, KEDA can scale a pod from zero to active in milliseconds. The infrastructure is anticipating the load based on the queue, not reacting to the stress of it.
Here is what the workflow actually looks like when you do it right:
- The Trigger: Telemetry picks up a severe anomaly ,like a sudden 5G slice degradation, and pushes an event straight to a message broker like Kafka.
- The Scale-Up: KEDA intercepts that exact metric and instantly provisions a dedicated, GPU-backed AI pod from a warm standby pool.
- The Execution: The Agentic AI loads into VRAM, figures out the blast radius of the anomaly, and executes a fix. This is usually by reconciling the state through a GitOps controller.
- The Kill Switch: The absolute millisecond that the event queue clears and the network is stable, the orchestrator aggressively terminates the pod and gives the GPU back to the node pool.
You only pay the premium GPU tax during moments of active reasoning. The 24/7 idle tax is gone.
Architecting the Scale-to-Zero Core:
To make this scale-to-zero dream a reality, you have to fundamentally change how you handle network observability. The biggest mistake I see architects make is tightly coupling their monitoring tools with their AI execution layer. If your observability stack is running on the same hardware as your AI engine, you are literally wasting premium GPU compute just to watch logs.
You need a strict, physical separation of concerns:
The Watchers (The Lightweight Control Plane):
Your network data plane needs to be monitored by lightweight, CPU-efficient edge collectors like Prometheus or OpenTelemetry. These sit right at the edge, continuously eating millions of telemetry data points and BGP state changes. Because they don’t do any complex reasoning, they run incredibly cheap on standard CPU nodes.
The Thinkers (The Heavyweight Execution Plane):
Your expensive AI models are completely isolated in a separate, GPU-backed node pool that literally defaults to zero instances.
When the Watchers spot an anomaly, they don’t try to fix it. They just fire an alert to KEDA. KEDA then wakes up the Thinkers, spinning up the exact number of GPU pods needed to handle that specific blast radius. By decoupling the watchers from the thinkers, you guarantee that not a single cycle of GPU compute is wasted on baseline monitoring.
The Bottom Line:
Autonomous telecom networks are going to happen. But trying to brute-force the infrastructure provisioning is a fast track to bankrupting your IT department. The smartest Agentic AI in the world is useless if you can’t afford the cloud bill to run it.
Furthermore, this isn’t just about protecting the IT budget. Running idle GPUs 24/7 creates a massive, unnecessary carbon footprint. By enforcing a scale-to-zero architecture, telcos can drastically reduce the energy consumption of their autonomous networks, turning a massive ESG liability into a sustainable operational model.
Autonomy is no longer just a software engineering problem. It is an infrastructure balancing act. If Agentic AI is going to survive in the telecom core, we have to ditch legacy threshold scaling and embrace strict, event-driven orchestration.
Tools like KEDA give us the ability to build networks that are both cognitively brilliant and financially ruthless. We can spin up massive intelligence at the exact millisecond of failure and scale right back to zero the moment the network is healed.
References and Further Reading:
- Unlocking Energy Saving in Telecom Networks: A Path to a Sustainable Future – A deep dive into the operational and ESG mandates driving energy efficiency in modern telecom infrastructure.
- KEDA Documentation: Kubernetes Event-driven Autoscaling – Technical specifications for decoupling workload scaling from standard CPU/Memory metrics.
- keda-gpu-scaler – An open-source custom KEDA scaler I developed to enable event-driven autoscaling specifically tied to native GPU telemetry and queue depth.
Building and Operating a Cloud Native 5G SA Core Network
How Network Repository Function Plays a Critical Role in Cloud Native 5G SA Network
HPE Aruba Launches “Cloud Native” Private 5G Network with 4G/5G Small Cell Radios
…………………………………………………………………………………………….
About the Author:

Pavan Madduri is a Cloud-Native Architect, CNCF Golden Kubestronaut, and active IEEE researcher specializing in enterprise infrastructure automation, Agentic SREs, and Kubernetes networking. He designs scalable, zero-trust cloud environments and frequently writes about the intersection of AI governance and cloud-native infrastructure.
Connect with Pavan Madduri on [LinkedIn] .
Disclaimer: The author acknowledges the use of AI-assisted tools for structural formatting, language refinement, and copyediting during the drafting of this article. The core architectural concepts, technical opinions, and engineering strategies remain entirely original.
Part II: Outcomes from the IEEE–ITU Sustainable Climate Symposium
IEEE–International Telecommunication Union (ITU) Symposium on Achieving a Sustainable Climate – Part II
by Marta Koch, IEEE Europe Member & PhD Researcher & Teaching Facilitator, Imperial College London with Alan J Weissberger, IEEE Techblog Content Manager
Editor’s Note: This is the second of a two-part article summarizing this ITU-IEEE Symposium. Part I is here.
Why AI Matters for Sustainable Telecommunications:
The IEEE–ITU Symposium on underscored that developing AI‑enabled sustainable telecommunications networks represents a fundamentally multidisciplinary challenge situated at the intersection of communications engineering, energy systems, computer science, climate science, and public policy. Delivering meaningful climate outcomes through digital technologies requires not only progress in algorithms, architectures, and network optimization, but also institutional frameworks that enable responsible, interoperable, and scalable deployment across diverse operational contexts.
A systems-level view of telecommunications sustainability os needed—beyond traditional performance metrics—to one where future networks are intelligent, adaptive, and energy‑efficient by design. Building on ITU analyses positioning AI, advanced connectivity, and digital platforms as key enablers of environmental action, participants also highlighted the importance of understanding their environmental trade‑offs.
Machine Learning for Climate‑Aware Network Optimization:
Machine learning (ML) is emerging as a strategic enabler of climate‑aligned energy management across telecom networks. ML techniques now underpin network‑wide energy optimisation, demand and renewable generation forecasting, power–communications coordination, and climate services such as early warning and adaptive planning. In resource‑constrained or climate‑vulnerable contexts, ensuring model robustness, transparency, and alignment with sustainability objectives is essential. Research priorities include energy‑ and carbon‑aware model design, integration of grid and resilience metrics, and standardised evaluation methods for sustainability‑critical ML applications.
Use Cases for Energy‑Efficient Operations via AI:
Important AI applications include traffic prediction, adaptive resource management, energy‑aware RAN optimisation, and predictive network sleep modes. Cross‑layer and multi‑timescale optimisation enables maximum energy efficiency without compromising service quality.
Network Resilience Under Climate Stress:
With climate‑related disruptions increasing globally, AI‑enabled predictive maintenance, self‑healing architectures, and climate‑aware planning have become core to resilient network operations. These approaches align with UN‑led initiatives on climate services and disaster early warning systems.
Power–Communications Interdependencies:
Participants highlighted the coupling between power and communications systems, emphasising cascading‑failure scenarios and the potential of AI‑enabled digital twins for joint optimisation. These perspectives align with ITU frameworks on digital public infrastructure and smart sustainable cities, which stress interoperability across physical and digital systems.
Sustainable AI and Hardware–Software Co‑Design:
Effective climate action depends on co‑optimising physical and digital infrastructure—from data centres and energy systems to ML models and orchestration layers. Sustainable network intelligence requires energy‑efficient algorithms, hardware‑aware deployment, and system‑level governance. The approach aligns with ITU’s Green Digital Action initiative and related efforts by ISO, IEC, UNEP, and WMO to advance standards‑driven, science‑informed digital sustainability.
Digital Public Infrastructure and Climate‑Resilient Digitalization:
Digital Public Infrastructure (DPI)—open and interoperable systems for identity, payments, data exchange, and connectivity—was highlighted as foundational for inclusive, climate‑resilient digital transformation. Effective DPI design requires governance, risk management, and safeguards, as emphasised by UNDP and the UN Office for Digital and Emerging Technologies.
IEEE Technology Assessment Tool:
The symposium introduced an IEEE envisioning proof‑of‑concept tool to support sustainable network planning through systematic assessment of digital and energy technologies, evaluating trade‑offs across performance, sustainability, and resilience.
Importance of International Standards:
A central outcome of the symposium was recognition of the critical role of international standardization in translating technological innovation into practical, climate‑relevant impact. As telecommunications networks become increasingly software‑defined, AI‑driven, and interconnected with energy and physical infrastructure systems, standards provide the technical and governance foundations essential for interoperability, data integrity, trustworthiness, and long‑term sustainability. Presentations from global standards organizations highlighted the importance of harmonized frameworks that can minimize market fragmentation, facilitate cross‑border interoperability, and incorporate environmental and resilience criteria directly into network design, operation, and lifecycle management.
Standards were identified as key to scalable, trustworthy AI deployment, with interoperability and data governance central to ITU‑T Study Group 5’s agenda.
Sessions also reinforced the importance of equitable access—advancing AI‑assisted network planning and cost‑efficient deployment in climate‑vulnerable regions to balance sustainability, affordability, and inclusion.The symposium further emphasized the need for a system‑level approach, recognizing that telecommunications networks operate as integral components within broader energy, transport, and urban infrastructure ecosystems. In this context, AI and machine learning increasingly serve as coordinating layers across hardware, software, and physical assets, enabling cross‑domain optimization. Standardization plays a crucial enabling role by aligning interfaces, performance metrics, and assessment methodologies across sectors, thereby supporting coherent operation of digital and physical systems under conditions of resource constraint, geopolitical uncertainty, and climate stress.
Implications for IEEE Communications Society:
For IEEE Communications Society (ComSoc) members, discussions highlighted a dual responsibility and opportunity. There is a responsibility to ensure future communications networks are designed to minimize environmental impact, maintain resilience under climate extremes, and promote equitable access to essential connectivity and data sharing.
Simultaneously, there is an opportunity for researchers and practitioners to contribute technical evidence, performance models, and quantitative metrics that inform and advance international standardization.
By maintaining sustained collaboration among research institutions, industry stakeholders, standards bodies, and policy entities—and engaging with the broader frameworks of global climate and sustainable‑development governance—the telecom community can play a defining role in enabling energy‑efficient, climate‑aware, and resilient digital infrastructure worldwide.
…………………………………………………………………………………………………………………………………………………………………………
References:
[1] M. Koch and UN Climate Technology Centre and Network (UN CTCN), “Maximizing Emerging Trends in Locally-Led AI Solutions for Climate Action,” SDG Knowledge Hub, International Institute for Sustainable Development, 2025.
https://sdg.iisd.org/commentary/guest-articles/maximizing-emerging-trends-in-locally-led-ai-solutions-for-climate-action/
[2] M. Koch, “Stakeholder asset-mapping of climate technology infrastructures,” Nature Reviews Earth & Environment, 2025.
DOI: 10.1038/s43017-025-00737-z
[3] World Meteorological Organization, Early Warnings for All: Executive Action Plan 2023–2027, WMO, Geneva, 2023.
https://wmo.int/media/magazine-article/overview-of-early-warnings-all-executive-action-plan-2023-2027
[4] United Nations Environment Programme, Global Climate Risk Assessment Framework, UNEP, Nairobi, 2023.
https://www.unepfi.org/themes/climate-change/2023-climate-risk-landscape/
[5] ITU, WMO, UNEP, and UNFCCC, Global Initiative on Resilience to Natural Hazards through AI Solutions, United Nations, Geneva. https://www.itu.int/en/ITU-T/extcoop/ai4resilience/Pages/default.aspx
[6] ITU-T Study Group 5, Work Programme on Environment, Climate Action, Circular Economy and Electromagnetic Fields, International Telecommunication Union, Geneva.
https://www.itu.int/en/ITU-T/studygroups/2022-2024/05/
[7] International Telecommunication Union – Telecommunication Standardization Sector, Building Digital Public Infrastructure for Cities and Communities, ITU, Geneva, 2025.
https://www.itu.int/dms_pub/itu-t/opb/tut/T-TUT-SMARTCITY-2025-9-PDF-E.pdf
[8] International Telecommunication Union – Telecommunication Standardization Sector, Frontier Technologies to Protect the Environment and Tackle Climate Change (T-TUT-ICT-2020-02), ITU, Geneva, 2020.
https://www.itu.int/dms_pub/itu-t/opb/tut/T-TUT-ICT-2020-02-PDF-E.pdf
[9] International Telecommunication Union – Telecommunication Standardization Sector, Smart Sustainable Cities and Digital Infrastructure Frameworks, ITU, Geneva, 2025.
https://www.itu.int/dms_pub/itu-t/opb/tut/T-TUT-SMARTCITY-2025-6-PDF-E.pdf
[10] International Telecommunication Union, Green Digital Action, ITU, Geneva.
https://www.itu.int/initiatives/green-digital-action/
[11] World Bank Group, Digital Public Infrastructure and Development: A World Bank Group Approach, Washington, DC, 2025.
https://openknowledge.worldbank.org/entities/publication/cca2963e-27bf-4dbb-aa5a-24a0ffc92ed9
[12] United Nations Office for Digital and Emerging Technologies and United Nations Development Programme, DPI Safeguards Initiative. https://www.dpi-safeguards.org
……………………………………………………………………………………..
About Marta Koch:

Marta Koch is an IEEE member, PhD Researcher and Teaching Facilitator at Imperial College London, Research Associate at the Oxford Computational Political Science Group at the University of Oxford and Research Consultant at UNOPS. She has been nominated as research delegate to UN Climate Change (UNFCCC), UNEP, UNDESA, UNIDO and ITU meetings.
Part I: Outcomes from the IEEE–ITU Sustainable Climate Symposium
IEEE–International Telecommunication Union (ITU) Symposium: Achieving a Sustainable Climate 2025 Outcomes: Capitalizing on AI for Energy-Efficient and Climate Resilient Telecommunications Networks
By Marta Koch, IEEE Europe Member & PhD Researcher & Teaching Facilitator, Imperial College London with Alan J Weissberger, IEEE Techblog Content Manager
Editor’s Note: This is the first of a two part article summarizing this ITU-IEEE Symposium. The second article is here.
Introduction:
Telecommunications networks are increasingly recognized as critical infrastructure for both economic development and societal resilience. As climate change accelerates and energy systems undergo rapid transformation, the telecoms sector faces a dual challenge: 1.] Reducing its own environmental footprint while ensuring reliable connectivity under growing physical, climatic, and 2.] Systemic stress.
These two themes were the focus of the IEEE–International Telecommunication Union (ITU) Symposium on Achieving a Sustainable Climate, which was held in December 2025 at the ITU headquarters in Geneva.
The symposium convened researchers, industry leaders, standards bodies, and United Nations agencies to examine how digital transformation, artificial intelligence (AI), and emerging ICT solutions can support the energy transition and climate mitigation and adaptation, and the governance and standardisation developments needed to effectively and sustainably leverage this technology globally.
As an Imperial College London researcher and IEEE member, I attended the symposium as part of ongoing work at the intersection of telecommunications, artificial intelligence, and climate action, with a focus on the governance, design, and deployment of AI-enabled systems for climate mitigation and adaptation, as well as the environmental and systems-level sustainability of AI-driven digital infrastructure.
Organization and Collaboration:
The symposium was co-organized by the ITU Telecom Standardization Bureau (ITU-T) and ITU T Study Group 5, which focuses on environment, climate action, circular economy, and electromagnetic fields. This collaboration underscored the central role of international standardization in shaping sustainable, climate-resilient ICT systems and provided a strong standards-oriented framework for discussions on AI deployment, energy efficiency, and network resilience [6].

Symposium photo courtesy of the ITU
……………………………………………………………………………………………………………………………………….
Key Discussion Themes:
Across plenary sessions, thematic panels and case studies, several cross-cutting issues emerged:
- Expanding role of AI and machine learning (ML) in enabling more energy-efficient, resilient, and inclusive telecommunications networks.
- The role of the ICT sector in accelerating decarbonisation and strengthening climate adaptation, particularly in support of the global energy transition
- Interactions between physical and digital infrastructure systems, including electrification and communications, as enablers of circular economy models
- Digital and AI standardisation as foundations for sustainable, climate-resilient development and place- and people-based outcomes
- Intersections between decarbonisation, electrification, circularity, digital access, and equity
- Public–private collaboration models supporting climate finance, eco-design, and scalable deployment in climate-vulnerable and developing regions.
International Policy Governance Perspectives at the Symposium:
The symposium featured strong representation from international organisations, grounding technical discussions in policy, standards, finance, and real-world deployment realities across the ICT, energy, and climate domains.
ITU delegates Tomas Lamanauskas, Seizo Onoe, Bilel Jamoussi, and Dominique Würges emphasized the importance of aligning global mandates with local needs in sustainable ICT ecosystems.
The following are essential to both decarbonization and resilient digital infrastructure: robust standards, interoperability, and AI governance frameworks (particularly those addressing environmental sustainability, circular economy principles, and responsible management of electromagnetic fields). That message was consistent with the opening plenary’s framing of international policy, eco-design, and circularity as foundational for practical deployment.
Energy and electrification perspectives were discussed by Dario Liguti of the United Nations Economic Commission for Europe and Norela Constantinescu of the International Renewable Energy Agency. They highlighted the global energy transition focus on both progress and persistent gaps in decarbonization and electrification. Coordinated planning between energy systems and telecommunications can significantly improve resilience, system efficiency, and equity for climate-adaptive services.
Industrial deployment and logistics viewpoints were provided by Luca Longo of the United Nations Industrial Development Organization and Yaxuan Chen of the Universal Postal Union. They described how integrated ICT and energy solutions could enhance operational outcomes, sustainability, and service delivery across industrial and sectoral contexts. Cross-sector collaboration was identified as a critical enabler of scalable impact.
Standards alignment was discussed by Matthew Doherty of the International Electrotechnical Commission and Noelia García Nebra of the International Organization for Standardization. They reinforced the essential need for international standards frameworks for translating research and innovation into deployable, interoperable solutions. This theme resonated strongly with the standards session’s emphasis on practical tools to support sustainable, climate-resilient outcomes across markets and regions.
Financing and digital innovation perspectives were contributed by Seth Ayers of the World Bank, who highlighted how digital and AI-enabled approaches can help unlock finance, de-risk investment, and expand access to sustainable energy and connectivity solutions in underserved and marginalised contexts, supporting climate resilience and inclusive growth.
Disaster risk reduction and emergency management perspectives were contributed by Yuji Maeda of NTT, Inc., Maeda-son highlighted how advanced aerial technologies and environmental sensing can be used to mitigate the impacts of extreme natural events. He shared ground-breaking research at NTT in Japan demonstrating the world’s first drone designed to act as a “flying lightning rod”, an invention selected by TIME Magazine as one of the Best Inventions of 2025. They are using a protective Faraday cage and a conductive tether to deliberately trigger and safely redirect lightning strikes away from critical infrastructure, illustrating the potential for drone-enabled systems to improve emergency response, infrastructure protection, and climate resilience.
Innovation diffusion was addressed by Heather Jacobs of WIPO GREEN, who underscored the importance of technology transfer, matchmaking platforms, and collaboration mechanisms in scaling affordable and climate-relevant digital and energy technologies. Her remarks highlighted the symposium’s focus on public–private partnerships and global deployment pathways.
A European Green Digital Coalition case study was presented by Ilias Iakovidis of the European Commission Directorate-General for Communications Networks, Content and Technology. He highlighted the development and deployment of a scientific methodology to assess the Net Carbon Impact of ICT solutions. His contribution demonstrated how digitalisation’s sustainability benefits can be quantified and scaled through coordinated industry engagement, financial sector alignment, and evidence-based deployment guidelines.
The growing Global Initiative on Resilience to Natural Hazards through AI Solutions was presented by Elena Xoplaki, Vice-Chair of the UN ITU, WMO, and UNEP Global Initiative on Resilience to Natural Hazards. She explained how AI, data integration, and resilient telecommunications networks underpin multi-hazard early warning systems and climate risk reduction efforts worldwide [5].
……………………………………………………………………………………………………………………………………….
Part II. of this report, listing all references, is here.
About Marta Koch:
Marta Koch is an IEEE member, PhD Researcher and Teaching Facilitator at Imperial College London, Research Associate at the Oxford Computational Political Science Group at the University of Oxford and Research Consultant at UNOPS. She has been nominated as research delegate to UN Climate Change (UNFCCC), UNEP, UNDESA, UNIDO and ITU meetings.
Her research and consultancy work focuses on digital and AI governance, development and deployment for climate action and sustainable development, with particular emphasis on climate technology digital and physical infrastructures and the sustainability of AI and digitalisation. Her research has been funded by the United Nations, Natural Environment Research Council (NERC) and the UK Science & Technology Network (STN) under the Foreign, Commonwealth & Development Office and the Department for Science, Innovation & Technology, and endorsed by the UNESCO International Decade of Sciences for Sustainable Development.
From LPWAN to Hybrid Networks: Satellite and NTN as Enablers of Enterprise IoT – Part 2
By Afnan Khan (ML Engineer) and Mehsam Bin Tahir (Data Engineer)
Introduction:
This is the second of two articles on the impact of the Internet of Things (IoT) on the UK Telecom industry. The first is at
Enterprise IoT and the Transformation of UK Telecom Business Models – Part 1
Executive Summary:
Early Internet of Things (IoT) deployments relied heavily on low power wide area networks (LPWANs) to deliver low-cost connectivity for distributed devices. While these technologies enabled initial IoT adoption, they struggled to deliver sustainable commercial returns for telecom operators. In response, attention has shifted towards hybrid terrestrial–satellite connectivity models that integrate Non-Terrestrial Networks (NTN) directly into mobile network architectures. In 2026, satellite connectivity is increasingly positioned not as a universal coverage solution but as a resilience and continuity layer for enterprise IoT services (Ofcom, 2025).
The Commercial Limits of LPWAN-Based IoT:
LPWAN technologies enabled low-cost connectivity for specific IoT use cases but were typically deployed outside mobile core architectures. This limited their ability to support quality of service guarantees, enterprise-grade security and integrated billing models. As a result, LPWAN deployments often remained fragmented and failed to scale into durable enterprise business models, restricting their long-term commercial value for telecom operators (Ofcom, 2025).
Satellite and NTN as Integrated Mobile Extensions:
In contrast, satellite and NTN connectivity extends existing mobile networks rather than operating as a parallel IoT layer. When non-terrestrial connectivity is integrated into 5G core infrastructure, telecom operators are able to deliver managed IoT services with consistent security, performance and billing models across both terrestrial and remote environments. This architectural shift allows satellite connectivity to be packaged as part of a unified enterprise service rather than sold as a standalone or niche connectivity product (3GPP, 2023). Figure 1 illustrates this hybrid terrestrial–satellite model, showing how satellite connectivity functions as an extension of mobile networks to support continuous IoT services across urban, rural and remote environments.
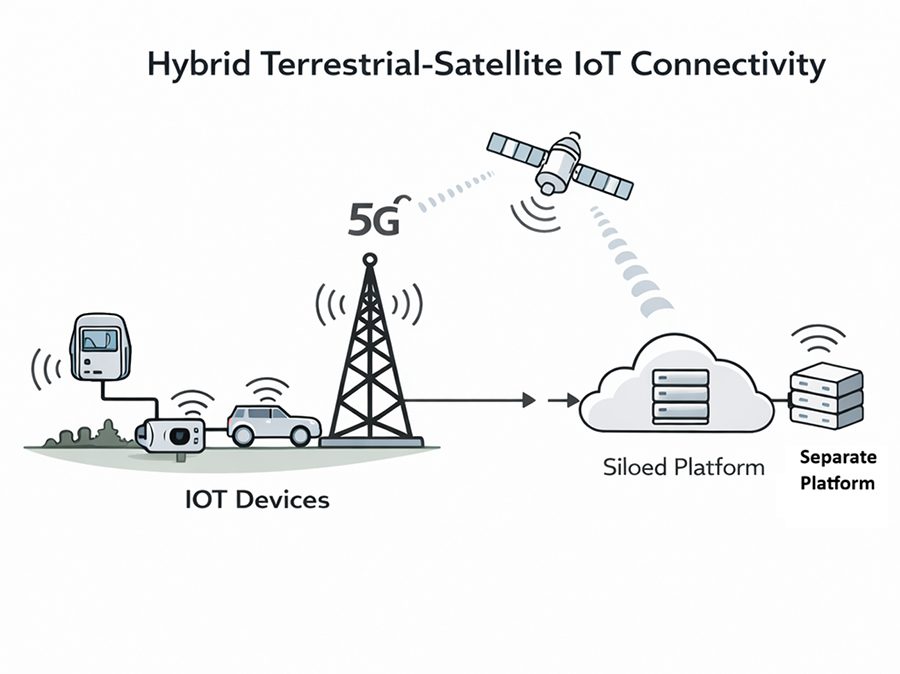
Figure 1: Hybrid terrestrial–satellite connectivity supporting continuous IoT services across urban, rural and remote environments.
Industrial Use Cases and Hybrid Connectivity
In sectors such as offshore energy, agriculture, logistics and remote infrastructure monitoring, IoT deployments prioritise coverage continuity and service resilience over peak data throughput. Hybrid terrestrial–satellite connectivity enables operators to offer coverage guarantees and service level agreements that LPWAN-based models could not reliably support. In 2026, Virgin Media O2 launched satellite-enabled services aimed at supporting rural connectivity and improving resilience for IoT-dependent applications, reflecting a broader operator strategy to monetise non-terrestrial coverage where reliability is a core requirement (Real Wireless, 2025).
The commercial implications of this transition are further illustrated in Figure 2, which contrasts siloed LPWAN deployments with integrated mobile and satellite IoT services delivered through a unified network core.
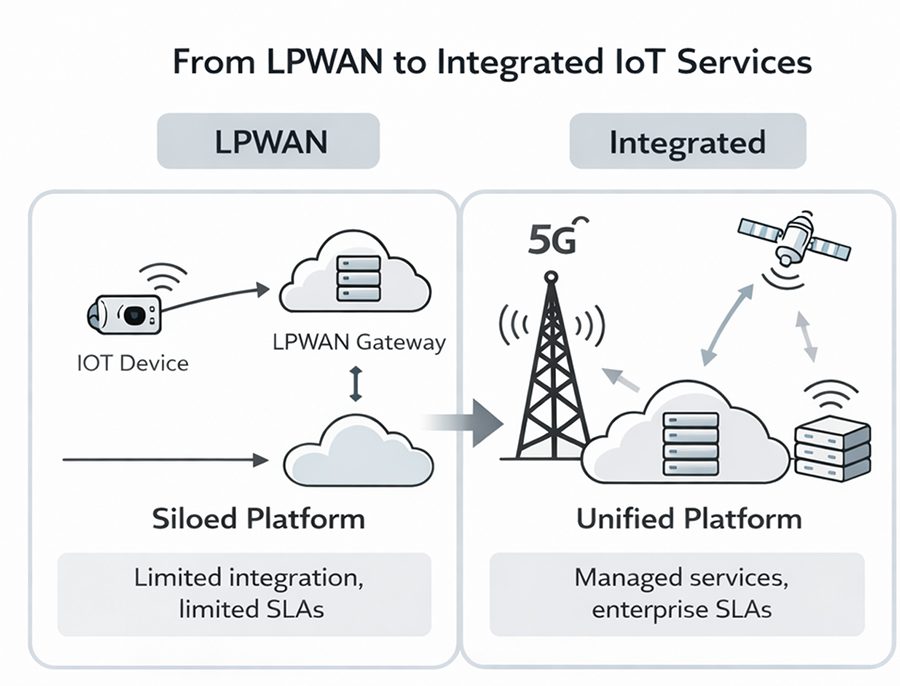
Figure 2: Transition from siloed LPWAN deployments to integrated mobile and satellite IoT services delivered through a unified network core.
Satellite Connectivity and Enterprise IoT at Scale:
The UK Space Agency has identified hybrid terrestrial–satellite connectivity as an enabling layer for remote industrial operations, environmental monitoring and agricultural IoT systems. UK-based firms such as Open Cosmos are contributing to this model by integrating Low Earth Orbit satellite connectivity with existing mobile core networks. This approach allows telecom operators to deliver end-to-end managed connectivity for enterprise customers without deploying separate IoT network stacks, converting coverage limitations from a cost burden into chargeable, service-based revenue opportunities (Open Cosmos, 2024; UK Space Agency, 2025).
Conclusion
In 2026, IoT is reshaping the UK telecom sector primarily by enabling new revenue models rather than by driving incremental network expansion. Following the limited commercial success of LPWAN-based IoT strategies, satellite and Non-Terrestrial Network integration is increasingly deployed as an extension of mobile networks to provide coverage continuity and service guarantees for industrial and remote use cases. When integrated into 5G core architectures, satellite connectivity enables telecom operators to monetise resilience and reliability as part of managed enterprise services rather than offering standalone connectivity. Taken together, these developments show that satellite and NTN integration has become a critical enabler of scalable, enterprise-led IoT business models in the UK (Ofcom-2025; 3GPP-2023).
…………………………………………………………………………………………………………………………………………………………………………
References:
Ofcom. (2025). Connected Nations UK report.
https://www.ofcom.org.uk
Real Wireless. (2025). Satellite to mobile connectivity and the UK market.
https://real-wireless.com
UK Space Agency. (2025). Connectivity and space infrastructure briefing
https://www.gov.uk/government/organisations/uk-space-agency
Open Cosmos. (2024). Satellite solutions for IoT and Earth observation.
https://open-cosmos.com
3GPP. (2023). Non-Terrestrial Networks (NTN) support in 5G systems.
https://www.3gpp.org/news-events/ntn
Non-Terrestrial Networks (NTNs): market, specifications & standards in 3GPP and ITU-R
Keysight Technologies Demonstrates 3GPP Rel-19 NR-NTN Connectivity in Band n252 (using Samsung modem chip set)
Telecoms.com’s survey: 5G NTNs to highlight service reliability and network redundancy
ITU-R recommendation IMT-2020-SAT.SPECS from ITU-R WP 5B to be based on 3GPP 5G NR-NTN and IoT-NTN (from Release 17 & 18)
China ITU filing to put ~200K satellites in low earth orbit while FCC authorizes 7.5K additional Starlink LEO satellites
Samsung announces 5G NTN modem technology for Exynos chip set; Omnispace and Ligado Networks MoU
Enterprise IoT and the Transformation of UK Telecom Business Models – Part 1
By Afnan Khan (ML Engineer) and Raabia Riaz (Data Scientist)
Introduction:
This is the first of two articles on the impact of the Internet of Things (IoT) on the UK Telecom industry. The second is at
From LPWAN to Hybrid Networks: Satellite and NTN as Enablers of Enterprise IoT – Part 2
Executive Summary:
In 2026, the Internet of Things (IoT) is fundamentally changing the UK telecom sector by enabling new business models rather than simply driving incremental network upgrades.
As consumer mobile markets show limited YoY growth between 2025 and 2026, telecom operators have prioritised IoT-led enterprise services as a source of new revenue (as per Ofcom-2025; GSMA-2024). Investment has shifted away from consumer facing upgrades towards private networks, managed connectivity and long-term service contracts for industry and infrastructure. This change reflects a broader move from usage-based connectivity towards service-based delivery.
IoT and Enterprise Connectivity through Private 5G:
Figure 1: Transition from consumer mobile connectivity to enterprise IoT services in the UK telecom sector, highlighting the shift towards managed connectivity and long-term service contracts.
The growth of private 5G and managed enterprise networks represents one of the clearest IoT driven business shifts. Industrial customers increasingly require predictable performance, low latency and enhanced security, which are not consistently available through public mobile networks. 5G Standalone architecture enables features such as network slicing and low latency communication, allowing operators to sell connectivity as a managed service rather than a commodity product (Mobile UK, 2024).
In the UK, this model is visible in projects such as the Port of Felixstowe private 5G trials supporting automated port operations and asset tracking (BT Group, 2023), the Liverpool City Region 5G programme focused on connected logistics (DCMS, 2022), the West Midlands 5G transport and connected vehicle projects (WM5G, 2023) and Network Rail 5G rail monitoring trials supporting safety and asset management (Network Rail, 2024). These deployments are typically delivered through long term enterprise contracts.
Together, these projects illustrate how connectivity is increasingly sold as a managed operational capability embedded within enterprise workflows rather than them being priced through consumer-style data usage as illustrated in figure 1.
IoT and Long-Term Infrastructure Revenue:
IoT enables telecom operators to participate in long-term infrastructure-based revenue models. The UK national smart meter programme illustrates this shift. By the third quarter of 2025, more than 40 million smart and advanced meters had been installed across Great Britain, with around 70% operating in smart mode (Department for Energy Security and Net Zero, 2025).
These systems rely on continuous, secure connectivity over long lifecycles. The Data Communications Company network processes billions of encrypted messages each month, creating sustained demand for resilient connectivity (DCC, 2024). Ofcom has linked the growth of such systems to increased regulatory focus on network resilience where connectivity underpins critical national infrastructure, while the National Cyber Security Centre has highlighted security risks associated with large IoT deployments (Ofcom, 2025; NCSC, 2024).
For telecom operators, these deployments favour long-term service contracts and regulated infrastructure partnerships over short-term retail revenue models.
Conclusions:
In 2026, IoT is transforming the UK telecom sector primarily by reshaping how connectivity is monetised rather than by driving incremental network upgrades. As consumer mobile markets show limited growth, telecom operators have increasingly aligned investment with enterprise IoT demand through private 5G deployments and long-term infrastructure connectivity. These models prioritise predictable performance, security and service continuity over mass-market scale. Private 5G projects across ports, transport networks and logistics hubs demonstrate how IoT demand has accelerated the commercial adoption of 5G Standalone capabilities, allowing operators to sell connectivity as a managed operational service embedded within enterprise workflows (Mobile UK, 2024). At the same time, national smart infrastructure programmes such as smart metering illustrate how IoT supports long-duration connectivity contracts that favour regulated partnerships and resilient network design over short-term retail revenue (Department for Energy Security and Net Zero, 2025; DCC, 2024). Taken together, these developments indicate that IoT is no longer an adjunct to UK telecom networks. Instead, it has become a central driver of enterprise-led, service-based business models that align network investment with stable, long-term revenue streams and critical infrastructure requirements.
…………………………………………………………………………………………………………………………………………………………..
References:
BT Group. (2023). BT and Hutchison Ports trial private 5G at the Port of Felixstowe.
https://www.bt.com/about/news/2023/bt-hutchison-ports-5g-felixstowe
Data Communications Company. (2024). Annual report and accounts 2023–24.
https://www.smartdcc.co.uk/our-company/our-performance/annual-reports/
Department for Digital, Culture, Media and Sport. (2022). Liverpool City Region 5G Testbeds and Trials Programme.
https://www.gov.uk/government/publications/5g-testbeds-and-trials-programme
Department for Energy Security and Net Zero. (2025). Smart meter statistics in Great Britain Q3 2025.
https://www.gov.uk/government/collections/smart-meters-statistics
GSMA. (2024). The Mobile Economy Europe.
https://www.gsma.com/mobileeconomy/europe/
Mobile UK. (2024). Unleashing the power of 5G Standalone.
https://www.mobileuk.org
National Cyber Security Centre. (2024). Cyber security principles for connected places.
https://www.ncsc.gov.uk
Network Rail. (2024). 5G on the railway connectivity trials.
https://www.networkrail.co.uk
Ofcom. (2025). Connected Nations UK report.
https://www.ofcom.org.uk
MTN Consulting: Satellite network operators to focus on Direct-to-device (D2D), Internet of Things (IoT), and cloud-based services
IoT Market Research: Internet Of Things Eclipses The Internet Of People
Artificial Intelligence (AI) and Internet of Things (IoT): Huge Impact on Tech Industry
ITU-R M.2150-1 (5G RAN standard) will include 3GPP Release 17 enhancements; future revisions by 2025
5G Americas: LTE & LPWANs leading to ‘Massive Internet of Things’ + IDC’s IoT Forecast
GSA: 102 Network Operators in 52 Countries have Deployed NB-IoT and LTE-M LPWANs for IoT
LoRaWAN and Sigfox lead LPWANs; Interoperability via Compression
IEEE/SCU SoE Virtual Event: May 26, 2022- Critical Cybersecurity Issues for Cellular Networks (3G/4G, 5G), IoT, and Cloud Resident Data Centers
Automating Fiber Testing in the Last Mile: An Experiment from the Field
By Said Yakhyoev with Sridhar Talari & Ajay Thakur
The December 23, 2025 IEEE ComSoc Tech Blog post on AI-driven data center buildouts [1.] highlights the urgent need to scale optical fiber and related equipment[1]. While much of the industry focus is on manufacturing capacity and high-density components inside data centers, a different bottleneck is emerging downstream— a sprawling last-mile network that demands testing, activation, and long-term maintenance. The AI-driven fiber demand coincided with the historic federal broadband programs to bring fiber to the premises for millions of customers[2]. This not only adds near-term pressure on fiber supply chains, but also creates a longer-term operational challenge: efficiently servicing hundreds of thousands of new fiber endpoints in the field.
As standard-setting bodies and vendors are introducing optimized products and automation inside data centers, similar future-proofing is needed in the last-mile outside plant. This post presents an example of such innovation from a field perspective, based on hands-on experimentation with a robotic tool designed to automate fiber testing inside existing Fiber Distribution Hubs (FDHs).
While central office copper terminating DSLAMs—and Optical Line Terminals (OLTs) in Passive Optical Networks (PONs)—aggregate subscribers and automate testing and provisioning, FDHs function as passive patch panels[3] that deliberately omit electronics to reduce cost. Between an OLT and the subscriber, the passive distribution network remains fixed. As a result, accessing individual ports at a local FDH—and anything downstream of it—remains a manual process. In active networks, DSLAMs and OLTs can electronically manage thousands of subscribers efficiently, but during construction this manual access is a bottleneck. There are likely tens of thousands of FDHs deployed nationwide.
Consider this problem from a technician’s perspective: suburban and urban Fiber to the Home (FTTH) networks are often deployed using a hub-and-spoke architecture centered around FDHs. These cabinets carry between 144 and 432 ports serving customers in a neighborhood, and each line must be tested bidirectionally[4]. In practice, this typically requires two technicians: one stationed at the FDH to move the test equipment between ports, and another at the customer location or terminal.
Testing becomes difficult during inclement weather. Counterintuitively, the technician stationed at the hub—often standing still for long periods—is more exposed than technicians moving between poles in vehicles. In addition to discomfort, there is a real economic penalty: either a skilled technician is tied up performing repetitive port switching, or an additional helper must be assigned. Above all, dependence on both favorable weather and helper availability makes testing schedules unpredictable and slows network completion.
To mitigate this bottleneck, we developed and tested Machine2 (M2)—a compact, gantry-style robotic tool that remotely connects an optical test probe inside an FDH, allowing a single technician to perform bidirectional testing independently.
M2 was designed to retrofit into a commonly deployed 288-port Clearfield FDH used in rural and small-town networks. The available space in front of the patch panel—approximately 9.5 × 28 × 4 inches—constrained the design to a flat Cartesian mechanism capable of navigating between ports and inserting a standard SC connector. Despite the simple design, integrating M2 into an unmodified FDH in the field proved more challenging than expected. Several real-world constraints shaped the redesign.
 |
 |
| FDH cabinet. Space to fit an automated switch | M2 installed for dry-run testing |
Space and geometry constraints: The patch panel occupies roughly 80% of the available volume, leaving only a narrow strip for motors, electronics, and cable routing. This forced compromises in pulley placement, leadscrew length, and motor orientation, limiting motion and requiring multiple iterations. The same constraints also limited battery size, making energy efficiency a primary design concern.
Port aiming: The patch panel is composed of cassettes with loosely constrained SC connectors. Small variations in connector position led to unreliable insertions. After repeated attempts, small misalignments accumulated, rendering the system ineffective without corrective feedback.
Communications reliability: A specialized cellular modem intended for IoT applications performed poorly for command-and-control. Message latency ranged from 1.5 seconds to over 12 seconds – and in some cases minutes – making real-time control impractical. In rural areas of Connecticut and Vermont, cellular coverage was also inconsistent or absent. Thus, the effort was abandoned between 2022 and 2024.
When the project resumed, an unexpected solution emerged. A low-cost consumer mobile hotspot proved more reliable than the specialized modem when cellular signal was available, providing predictable latency and stable Wi-Fi connectivity inside the FDH—even with the all-metal cabinet door closed and locked.
To further reduce latency, we explored using the fiber under test itself as a communication channel, a kind of temporary orderwire. When a two-piece Optical Loss Test Set (OLTS) is connected across an intact fiber, the devices indicate link readiness via an LED. By tapping this status signal, M2 can infer when a technician at the far end disconnects the meter and automatically connects to the next port. While this cue-based mode is limited, it enables near-zero-latency coordination and rapid testing of multiple ports without spoken or typed commands, which proved effective for common field workflows.
A second breakthrough came from addressing port aiming with vision. Standard computer-vision techniques such as edge detection were sufficient to micro-adjust the probe position at individual ports. To detect and avoid dust caps, M2 also uses a lightweight edge-ML[5] model trained to recognize caps under varying illumination. Using only 30 positive and 30 negative training images, the model correctly detected caps in over 80% of cases.
In our experience, lightweight vision models proved sufficient for practical field tasks, suggesting that accessibility—not sophistication—may drive adoption of automation in outside-plant environments.
| M2’s simplified vision sequence to account for nonuniformity of connectors | ||
 |
 |
 |
| Camera view: clipped to region of interest. Rough position | Processed view adjust -12px left, -16px up | Processed view after micro-adjusting |
What building M2 revealed:
- Overcoming communications issues led to an intriguing idea: optical background communication, where modulated laser light subtly changes ambient illumination inside the FDH that a camera can detect and extract instructions.
- M2 also proved useful beyond testing. For example, in a verify-as-you-splice workflow, M2 can lase a specific fiber as confirmation before splicing. Interactive port illumination and detection allow a single technician to troubleshoot complex situations.
The comparison below is illustrative and reflects observed workflows rather than controlled benchmarking.
Illustrative comparison of testing workflows in our experience
| Human helper (remote) | M2 | |
| Connect next port | 1–1.5 s | 2.5–4 s |
| Connect random / distant port | 8–24 s | ~11–30 s |
| Ease of deployment | Requires flat ground, fair weather, ground-level FDH | ~15 min setup; requires software familiarity |
| Functionality | Highly adaptable | Limited to 2–3 functions |
| Economics | Inefficient for small networks | Well-suited for small and medium networks |
| Independence factor | Low; requires two people | High; largely weather-independent |
| Best use | Variable builds, high adaptability | Repetitive builds, independent workflows |
Early insights for OSP vendors and standards
Building M2 revealed two broader lessons relevant to operators and vendors. First, there are now practical opportunities for automation to enter outside-plant workflows following developments in the power industry and datacenters[6]. Second, infrastructure design choices can facilitate this transition.
More spacious or reconfigurable FDH cabinets would simplify retrofitting active devices. Standardized attachment points on cabinets, terminals and pluggable components would allow mechanized or automated fiber management, reducing the risk of damage in dense installations.
Fiducial marks are among the lowest-cost adaptations. QR marks conveying dimensions and part architecture would help machines determine part orientation and position easily. Although these are common in the industry, it may be time to adopt them more broadly in telecom infrastructure maintenance.
Aerial terminals may benefit the most from machine-friendly design. Standardized port spacing and swing-out or hinged caps would significantly simplify autonomous or remotely assisted connections. Such cooperative interfaces could enable standoff connections without requiring a technician to climb a pole, improving safety and reducing access costs. Retrofitting aerial infrastructure to make it robot-friendly has been recommended[7] by the power industry and is also needed in the broadband utilities.
Conclusion
A growing gap is emerging between rapidly evolving data-center infrastructure and the more traditional telecom networks downstream. As fiber density increases, testing, activation, and maintenance of last-mile networks are likely to become bottlenecks. One way ISPs and vendors can future-proof outside-plant infrastructure is by proactively incorporating automation- and robot-friendly design features. M2 is one practical example that helps inform how such transitions might begin.
Short video clip from our early field trial in Massachusetts:
https://youtube.com/shorts/MiDoQd_S6Kw
References:
[1] IEEE ComSoc Technology blog post, Dec 23 2025, How will fiber and equipment vendors meet the increased demand for fiber optics in 2026 due to AI data center buildouts? ↩
[2] U.S. Dept. of Commerce Office of Inspector General, “NTIA Broadband Programs: Semiannual Status Report,” Washington, DC, USA, Rep. no. OIG-25-031-I, Sept. 24, 2025. ↩
[3] for an overview of an FTTH architecture see: Fiber Optic Association (FOA), FTTH Network Design Considerations and Fiber Optic Association (FOA), FTTH and PON Applications ↩
[4] Corning Optical Communications, “Corning Recommended Fiber Optic Test Guidelines,” Hickory, NC, USA, Application Engineering Note LAN-1561-AEN, Feb. 2020. ↩
[5] Refer to tools available for easy to use edge computing by Edge Impulse. ↩
[6] See state of the art indoor optical switches like ROME from NTT-AT and G5 from Telescent. ↩
[7] Andrew Phillips, “Autonomous overhead transmission line inspection robot (TI) development and demonstration,” IEEE PES General Meeting, 2014. ↩
About the Author:
Said Yakhyoev is a fiber optic technician with LightStep LLC in Colorado and a developer of the experimental Machine2 (M2) platform for automating fiber testing in outside-plant networks.
The author acknowledges the use of AI-assisted tools for language refinement and formatting.
