

AI Clusters
Will AI clusters be interconnected via Infiniband or Ethernet: NVIDIA doesn’t care, but Broadcom sure does!
InfiniBand, which has been used extensively for HPC interconnect, currently dominates AI networking accounting for about 90% of deployments. That is largely due to its very low latency and architecture that reduces packet loss, which is beneficial for AI training workloads. Packet loss slows AI training workloads, and they’re already expensive and time-consuming. This is probably why Microsoft chose to run InfiniBand when building out its data centers to support machine learning workloads. However, InfiniBand tends to lag Ethernet in terms of top speeds. Nvidia’s very latest Quantum InfiniBand switch tops out at 51.2 Tb/s with 400 Gb/s ports. By comparison, Ethernet switching hit 51.2 Tb/s nearly two years ago and can support 800 Gb/s port speeds.

While InfiniBand currently has the edge, several factors point to increased Ethernet adoption for AI clusters in the future. Recent innovations are addressing Ethernet’s shortcomings compared to InfiniBand:
- Lossless Ethernet technologies
- RDMA over Converged Ethernet (RoCE)
- Ultra Ethernet Consortium’s AI-focused specifications
Some real-world tests have shown Ethernet offering up to 10% improvement in job completion performance across all packet sizes compared to InfiniBand in complex AI training tasks. By 2028, it’s estimated that: 1] 45% of generative AI workloads will run on Ethernet (up from <20% now) and 2] 30% will run on InfiniBand (up from <20% now).
In a lively session at VM Ware-Broadcom’s Explore event, panelists were asked how to best network together the GPUs, and other data center infrastructure, needed to deliver AI. Broadcom’s Ram Velaga, SVP and GM of the Core Switching Group, was unequivocal: “Ethernet will be the technology to make this happen.” Velaga opening remarks asked the audience, “Think about…what is machine learning and how is that different from cloud computing?” Cloud computing, he said, is about driving utilization of CPUs; with ML, it’s the opposite.
“No one…machine learning workload can run on a single GPU…No single GPU can run an entire machine learning workload. You have to connect many GPUs together…so machine learning is a distributed computing problem. It’s actually the opposite of a cloud computing problem,” Velaga added.
Nvidia (which acquired Israel interconnect fabless chip maker Mellanox [1.] in 2019) says, “Infiniband provides dramatic leaps in performance to achieve faster time to discovery with less cost and complexity.” Velaga disagrees saying “InfiniBand is expensive, fragile and predicated on the faulty assumption that the physical infrastructure is lossless.”
Note 1. Mellanox specialized in switched fabrics for enterprise data centers and high performance computing, when high data rates and low latency are required such as in a computer cluster.
…………………………………………………………………………………………………………………………………………..
Ethernet, on the other hand, has been the subject of ongoing innovation and advancement since, he cited the following selling points:
- Pervasive deployment
- Open and standards-based
- Highest Remote Direct Access Memory (RDMA) performance for AI fabrics
- Lowest cost compared to proprietary tech
- Consistent across front-end, back-end, storage and management networks
- High availability, reliability and ease of use
- Broad silicon, hardware, software, automation, monitoring and debugging solutions from a large ecosystem
To that last point, Velaga said, “We steadfastly have been innovating in this world of Ethernet. When there’s so much competition, you have no choice but to innovate.” InfiniBand, he said, is “a road to nowhere.” It should be noted that Broadcom (which now owns VMWare) is the largest supplier of Ethernet switching chips for every part of a service provider network (see diagram below). Broadcom’s Jericho3-AI silicon, which can connect up to 32,000 GPU chips together, competes head-on with InfiniBand!
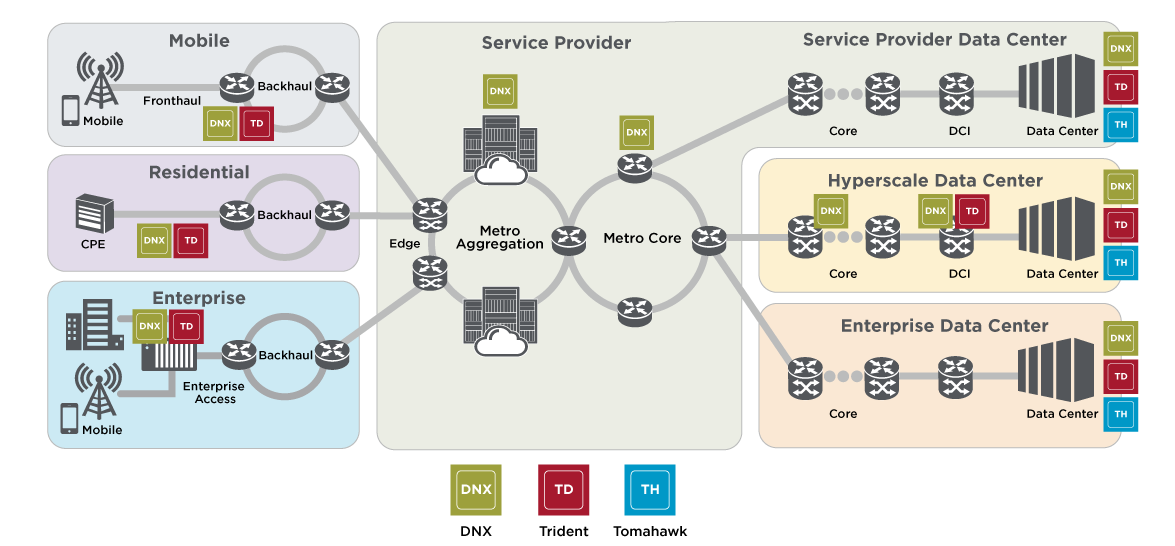
Image Courtesy of Broadcom
………………………………………………………………………………………………………………………………………………………..
Conclusions:
While InfiniBand currently dominates AI networking, Ethernet is rapidly evolving to meet AI workload demands. The future will likely see a mix of both technologies, with Ethernet gaining significant ground due to its improvements, cost-effectiveness, and widespread compatibility. Organizations will need to evaluate their specific needs, considering factors like performance requirements, existing infrastructure, and long-term scalability when choosing between InfiniBand and Ethernet for AI clusters.
–>Well, it turns out that Nvidia’s Mellanox division in Israel makes BOTH Infiniband AND Ethernet chips so they win either way!
…………………………………………………………………………………………………………………………………………………………………………..
References:
https://www.perplexity.ai/search/will-ai-clusters-run-on-infini-uCYEbRjeR9iKAYH75gz8ZA
{kind=link}
https://www.theregister.com/2024/01/24/ai_networks_infiniband_vs_ethernet/
Broadcom on AI infrastructure networking—’Ethernet will be the technology to make this happen’
https://www.nvidia.com/en-us/networking/products/infiniband/h
ttps://www.nvidia.com/en-us/networking/products/ethernet/
Part1: Unleashing Network Potentials: Current State and Future Possibilities with AI/ML
Using a distributed synchronized fabric for parallel computing workloads- Part II
Part-2: Unleashing Network Potentials: Current State and Future Possibilities with AI/ML
