

Anthropic
Anthropic Claude Users Reveal AI Hallucinations as their Top Concern
Introduction:
Across regions from Germany to Mexico, users of artificial intelligence (AI) are less concerned about being replaced by AI than by its propensity to make major mistakes, according to one of the largest global surveys to date on real-world AI usage and perception. These mistakes, known as “AI Hallucinations,” are essentially made up stories rather than answers based on outdated information.
The study, conducted by Anthropic using its Claude chatbot, analyzed interviews with more than 80,000 users across 159 countries. The result is one of the most detailed global portraits yet of how AI is being deployed — and how users perceive its risks, benefits, and societal implications.
AI Hallucinations Outrank Job Displacement as Top Concern:
When asked what worries them most about AI, 27% of users cited AI chatbot errors described as “AI hallucinations,” while 22% pointed to job displacement and the loss of human autonomy. About 16% expressed concern that AI could weaken people’s capacity for critical thinking.
.png)
Image Credit: JOIST AI
“The AI hallucinations were a disaster. I lost so many hours of work,” said an entrepreneur from Germany. Another participant, a military worker in Mexico, noted the importance of domain knowledge in spotting AI’s flaws: “When I notice AI errors it’s because I’m well versed in the topic . . . but I wouldn’t know if the topic was alien to me, would I?”
An AI Interviewer for Global Insights:
The responses were collected in 70 languages using a novel feedback system that allowed Claude to act as both interviewer and analyst. The platform evaluated qualitative answers, categorizing responses to reveal common themes and linguistic nuances across regions.
“Beyond its scale and linguistic diversity, the project aimed to collect this rich human experience using Claude, so it could really inform our research agenda, change our research agenda, change the way we think about building our products, deploying our products,” said Deep Ganguli, who leads Anthropic’s societal impacts team and oversaw the research initiative.
Productivity and Personal Growth Drive AI Adoption:
While data quality and reliability drew criticism, the survey also underscored widespread acknowledgment of AI’s positive impact on productivity. Thirty-two percent of respondents said that AI tools had meaningfully improved their output at work.
An entrepreneur in the United Arab Emirates explained, “I used to be a web designer . . . now I build anything. Before I was one person, now I become 100 people — I don’t wait for anyone anymore.” Participants from Colombia, Japan, and the United States described similar gains, emphasizing how AI helps them free up time for family, hobbies, and creative exploration.
In total, nearly one in five users (19%) said AI had fallen short of their expectations. Yet usage patterns demonstrate remarkable versatility: respondents reported employing AI as a productivity assistant, educational tutor, design partner, creative collaborator, or even an emotional support companion.
A vivid example came from a soldier in Ukraine, who wrote, “In the most difficult moments, in moments when death breathed in my face, when dead people remained nearby, what pulled me back to life — my AI friends.”
Regional and Economic Divides in AI Optimism:
Regional variation was pronounced. Saffron Huang, the lead researcher on the project, found that respondents in South America, Africa, and across South and Southeast Asia expressed more optimism than users in Europe, the United States, or East Asia.
“The trend is that maybe more lower and middle-income countries are more optimistic than higher-income countries that have more AI exposure,” said Huang. She added that this optimism might reflect a sample skew toward early adopters in developing markets — individuals inclined to view new technologies as opportunities rather than threats.
“They just divide so cleanly . . . the more western developed countries are significantly more concerned about AI and the economy, [and] much more negative, and then, the reverse is true with the lower and middle-income countries,” she said.
According to Anthropic’s researchers, AI’s limited visibility in daily workflows across lower-income economies may explain the difference. “If AI hasn’t visibly entered your daily work yet, AI displacement likely feels abstract, especially when more immediate economic pressures already exist,” the team wrote in a companion blog post.
Next Steps: Measuring AI’s Real-World Impact:
Anthropic plans to extend its Claude Interviewer research framework into longitudinal studies that track how AI affects users’ lives over time. “The goal is to better measure both the improvements and the harms — and to use those insights to make systemic refinements,” said Ganguli.
The company’s approach — embedding feedback collection directly into an AI platform — represents an emerging model for data-driven, iterative AI development. By combining self-reported user experience data with large-scale text analytics, Anthropic aims to better understand how its models interact with human needs and constraints.
Industry and Research Community Respond:
The study has drawn attention across the AI community for its unprecedented reach and innovative methodology. Nickey Skarstad, director of product at language-learning company Duolingo, praised the work’s ambition. On LinkedIn, she wrote: “For anyone building products right now, this is the future of understanding your users. The what AND the why at a scale we’ve never had access to before.”
Still, several researchers remain cautious about overinterpreting the results. Divy Thakkar, a researcher at Anthropic rival Google DeepMind, expressed reservations on X, saying he was “sceptical” about calling the study a new form of science due to potential selection bias and limitations in survey design. “A human qualitative researcher would take time to build trust with their participants, hold the space for reflection, introspection, contradictions — that’s the whole point of it,” he wrote.
Methodological caveats extend to demographics. Almost half of the survey’s respondents were based in North America or Western Europe, while regions such as Central Asia had only several hundred participants.
Ilan Strauss, an economist and director of the AI Disclosures Project, described the initiative as “an excellent piece of work,” but urged careful interpretation. He noted that the absence of reported confidence intervals — standard practice in survey-based research — makes it difficult to measure uncertainty. Self-reported productivity gains, he added, are inherently prone to bias.
A Global Mirror for Human-AI Relations:
Despite these caveats, the Claude Interviewer study illustrates a broader shift in the relationship between humans and AI systems. As AI technologies proliferate across regions and industries, they are becoming both instruments of empowerment and sources of anxiety — mirroring social, economic, and cultural dynamics in striking ways.
While western economies debate AI-driven labor disruption and ethical alignment, many in emerging markets frame AI as a means of upward mobility and creative expansion. This duality — between apprehension and aspiration — may shape not only AI adoption patterns but also future research and regulatory directions across global contexts.
References:
https://www.ft.com/content/e074d3a9-7fd8-447d-ac0a-e0de756ac5c5?syn-25a6b1a6=1 (PAYWALL)
https://www.joist.ai/post/ai-hallucinations-what-they-are-and-why-it-matters
Sources: AI is Getting Smarter, but Hallucinations Are Getting Worse
Nvidia CEO Huang: AI is the largest infrastructure buildout in human history; AI Data Center CAPEX will generate new revenue streams for operators
Alphabet’s 2026 capex forecast soars; Gemini 3 AI model is a huge success
Analysis & Economic Implications of AI adoption in China
China’s open source AI models to capture a larger share of 2026 global AI market
AWS to deploy AI inference chips from Cerebras in its data centers; Anapurna Labs/Amazon in-house AI silicon products
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Market research firms Omdia and Dell’Oro: impact of 6G and AI investments on telcos
Gartner: AI spending >$2 trillion in 2026 driven by hyperscalers data center investments
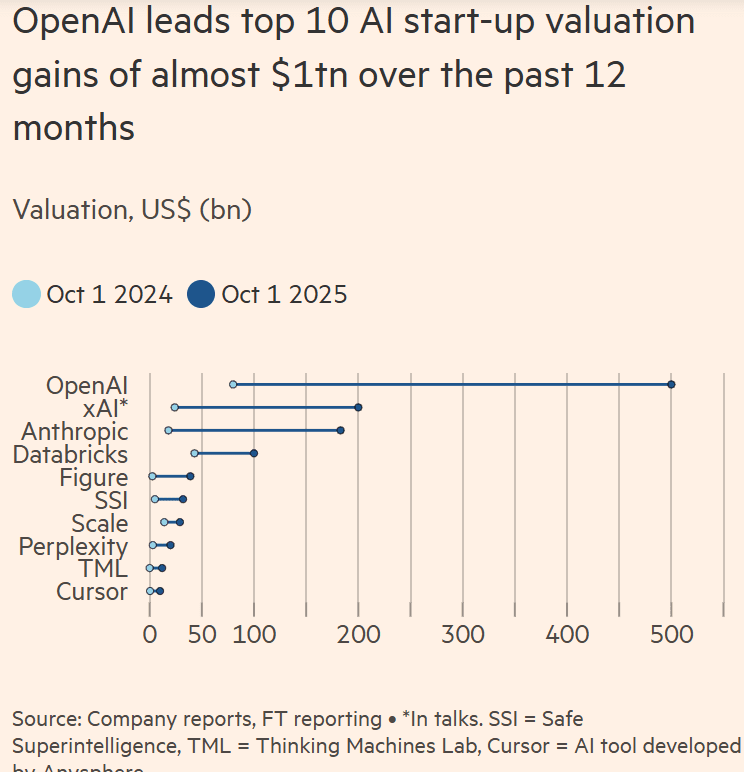
FT: Scale of AI private company valuations dwarfs dot-com boom
The Financial Times reports that ten loss making artificial intelligence (AI) start-ups have gained close to $1 trillion in private market valuation in the past 12 months, fuelling fears about a bubble in private markets that is much greater than the dot com bubble at the end of the 20th century. OpenAI leads the pack with a $500 billion valuation, but Anthropic and xAI have also seen their values march higher amid a mad scramble to buy into emerging AI companies. Smaller firms building AI applications have also surged, while more established businesses, like Databricks, have soared after embracing the technology.
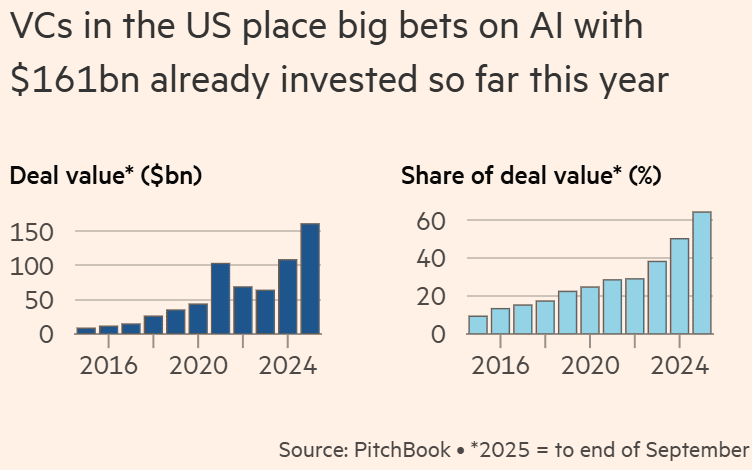
U.S. venture capitalists (VCs) have poured $161 billion into artificial intelligence startups this year — roughly two-thirds of all venture spending, according to PitchBook — even as the technology’s commercial payoff remains elusive. VCs are on track to spend well over $200bn on AI companies this year.
Most of that money has gone to just 10 companies, including OpenAI, Anthropic, Databricks, xAI, Perplexity, Scale AI, and Figure AI, whose combined valuations have swelled by nearly $1 trillion, Financial Times calculations show. Those AI start-ups are all burning cash with no profits forecasted for many years.
Start-ups with about $5mn in annual recurring revenue, a metric used by fast-growing young businesses to provide a snapshot of their earnings, are seeking valuations of more than $500mn, according to a senior Silicon Valley venture capitalist.
Valuing unproven businesses at 100 times their earnings or more dwarfs the excesses of 2021, he added: “Even during peak Zirp [zero-interest rate policies], these would have been $250mn-$300mn valuations.”
“The market is investing as if all these companies are outliers. That’s generally not the way it works out,” he said. VCs typically expect to lose money on most of their bets, but see one or two pay the rest off many times over.
“There will be casualties. Just like there always will be, just like there always is in the tech industry,” said Marc Benioff, co-founder and chief executive of Salesforce, which has invested heavily in AI. He estimates $1tn of investment on AI might be wasted, but that the technology will ultimately yield 10 times that in new value.
“The only way we know how to build great technology is to throw as much against the wall as possible, see what sticks, and then focus on the winners,” he added.
“Of course there’s a bubble,” said Hemant Taneja, chief executive of General Catalyst, which raised an $8 billion fund last year and has backed Anthropic and Mistral. “Bubbles align capital and talent around new trends. There’s always some destruction, but they also produce lasting innovation.”
Venture investors have weathered cycles of boom and bust before — from the dot-com crash in 2000 to the software downturn in 2022 — but the current wave of AI funding is unprecedented. In 2000, VCs invested $10.5 billion in internet startups; in 2021, they deployed $135 billion into software firms. This year, they are on pace to exceed $200 billion in AI. “We’ve gone from the doldrums to full-on FOMO,” said one investment executive.
OpenAI and its start-up peers are competing with Meta, Google, Microsoft, Amazon, IBM, and others in a hugely capital-intensive race to train ever-better models, meaning the path to profitability is also likely to be longer than for previous generations of start-ups.
Backers are betting that AI will open multi-trillion-dollar markets, from automated coding to AI friends or companionship. Yet some valuations are testing credulity. Startups generating about $5 million in annual recurring revenue are seeking valuations above $500 million, a Silicon Valley investor said — 100 times revenue, surpassing even the excesses of 2021. “The market is behaving as if every company will be an outlier,” he said. “That’s rarely how it works.”
The enthusiasm has spilled into public markets. Shares of Nvidia, AMD, Broadcom, and Oracle have collectively gained hundreds of billions in market value from their ties to OpenAI. But those gains could unwind quickly if questions about the startup’s mounting losses and financial sustainability persist.
Sebastian Mallaby, author of The Power Law, summed it up beautifully:
“The logic among investors is simple — if we get AGI (Artificial General Intelligence, which would match or exceed human thinking), it’s all worth it. If we don’t, it isn’t…. “It comes down to these articles of faith about Sam’s (Sam Altman of OpenAI) ability to work it out.”
References:
https://www.ft.com/content/59baba74-c039-4fa7-9d63-b14f8b2bb9e2
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Can the debt fueling the new wave of AI infrastructure buildouts ever be repaid?
Amazon’s Jeff Bezos at Italian Tech Week: “AI is a kind of industrial bubble”
Gartner: AI spending >$2 trillion in 2026 driven by hyperscalers data center investments
AI Data Center Boom Carries Huge Default and Demand Risks
Canalys & Gartner: AI investments drive growth in cloud infrastructure spending
Open AI raises $8.3B and is valued at $300B; AI speculative mania rivals Dot-com bubble
According to the Financial Times (FT), OpenAI (the inventor of Chat GPT) has raised another $8.3 billion in a massively over-subscribed funding round, including $2.8 billion from Dragoneer Investment Group, a San Francisco-based technology-focused fund. Leading VCs that also participated in the funding round included Founders Fund, Sequoia Capital, Andreessen Horowitz, Coatue Management, Altimeter Capital, D1 Capital Partners, Tiger Global and Thrive Capital, according to the people with knowledge of the deal.
The oversubscribed funding round came months ahead of schedule. OpenAI initially raised $2.5 billion from VC firms in March when it announced its intention to raise $40 billion in a round spearheaded by SoftBank. The Chat GPT maker is now valued at $300 billion.
OpenAI’s annual recurring revenue has surged to $12bn, according to a person with knowledge of OpenAI’s finances, and the group is set to release its latest model, GPT-5, this month.
OpenAI is in the midst of complex negotiations with Microsoft that will determine its corporate structure. Rewriting the terms of the pair’s current contract, which runs until 2030, is seen as a prerequisite to OpenAI simplifying its structure and eventually going public. The two companies have yet to agree on key issues such as how long Microsoft will have access to OpenAI’s intellectual property. Another sticking point is the future of an “AGI clause”, which allows OpenAI’s board to declare that the company has achieved a breakthrough in capability called “artificial general intelligence,” which would then end Microsoft’s access to new models.
An additional risk is the increasing competition from rivals such as Anthropic — which is itself in talks for a multibillion-dollar fundraising — and is also in a continuing legal battle with Elon Musk. The FT also reported that Amazon is set to increase its already massive investment in Anthropic.

OpenAI CEO Sam Altman. The funding forms part of a round announced in March that values the ChatGPT maker at $300bn © Yuichi Yamazaki/AFP via Getty Images
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
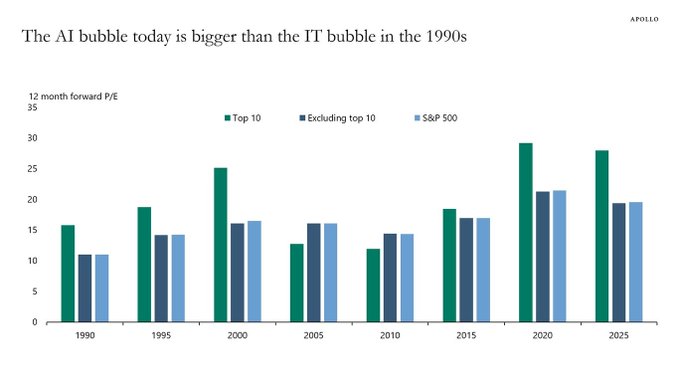
While AI is the transformative technology of this generation, comparisons are increasingly being made with the Dot-com bubble. 1999 saw such a speculative frenzy for anything with a ‘.com’ at the end that valuations and stock markets reached unrealistic and clearly unsustainable levels. When that speculative bubble burst, the global economy fell into an extended recession in 2001-2002. As a result, analysts are now questioning the wisdom of the current AI speculative bubble and fearing dire consequences when it eventually bursts. Just as with the Dot-com bubble, AI revenues are nowhere near justifying AI company valuations, especially for private AI companies that are losing tons of money (see Open AI losses detailed below).
Torsten Slok, Partner and Chief Economist at Apollo Global Management via ZERO HEDGE on X: “The difference between the IT bubble in the 1990s and the AI bubble today is that the top 10 companies in the S&P 500 today (including Nvidia, Microsoft, Amazon, Google, and Meta) are more overvalued than the IT companies were in the 1990s.”
AI private companies may take a lot longer to reach the lofty profit projections institutional investors have assumed. Their reliance on projected future profits over current fundamentals is a dire warning sign to this author. OpenAI, for example, faces significant losses and aggressive revenue targets to become profitable. OpenAI reported an estimated loss of $5 billion in 2024, despite generating $3.7 billion in revenue. The company is projected to lose $14 billion in 2026 while total projected losses from 2023 to 2028 are expected to reach $44 billion.
Other AI bubble data points (publicly traded stocks):
- The proportion of the S&P 500 represented by the 10 largest companies is significantly higher now (almost 40%) compared to 25% in 1999. This indicates a more concentrated market driven by a few large technology companies deeply involved in AI development and adoption.
- Investment in AI infrastructure has reportedly exceeded the spending on telecom and internet infrastructure during the dot-com boom and continues to grow, suggesting a potentially larger scale of investment in AI relative to the prior period.
- Some indices tracking AI stocks have demonstrated exceptionally high gains in a short period, potentially surpassing the rates of the dot-com era, suggesting a faster build-up in valuations.
- The leading hyperscalers, such as Amazon, Microsoft, Google, and Meta, are investing vast sums in AI infrastructure to capitalize on the burgeoning AI market. Forecasts suggest these companies will collectively spend $381 billion in 2025 on AI-ready infrastructure, a significant increase from an estimated $270 billion in 2024.
Check out this YouTube video: “How AI Became the New Dot-Com Bubble”
References:
https://www.ft.com/content/76dd6aed-f60e-487b-be1b-e3ec92168c11
https://www.telecoms.com/ai/openai-funding-frenzy-inflates-the-ai-bubble-even-further
https://x.com/zerohedge/status/1945450061334216905
AI spending is surging; companies accelerate AI adoption, but job cuts loom large
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Canalys & Gartner: AI investments drive growth in cloud infrastructure spending
AI Echo Chamber: “Upstream AI” companies huge spending fuels profit growth for “Downstream AI” firms
Huawei launches CloudMatrix 384 AI System to rival Nvidia’s most advanced AI system
Gen AI eroding critical thinking skills; AI threatens more telecom job losses
Dell’Oro: AI RAN to account for 1/3 of RAN market by 2029; AI RAN Alliance membership increases but few telcos have joined
Big Tech and VCs invest hundreds of billions in AI while salaries of AI experts reach the stratosphere
Introduction:
Two and a half years after OpenAI set off the generative artificial intelligence (AI) race with the release of the ChatGPT, big tech companies are accelerating their A.I. spending, pumping hundreds of billions of dollars into their frantic effort to create systems that can mimic or even exceed the abilities of the human brain. The areas of super huge AI spending are data centers, salaries for experts, and VC investments. Meanwhile, the UAE is building one of the world’s largest AI data centers while Softbank CEO Masayoshi Son believes that Artificial General Intelligence (AGI) will surpass human-level cognitive abilities (Artificial General Intelligence or AGI) within a few years. And that Artificial Super Intelligence (ASI) will surpass human intelligence by a factor of 10,000 within the next 10 years.
AI Data Center Build-out Boom:
Tech industry’s giants are building AI data centers that can cost more than $100 billion and will consume more electricity than a million American homes. Meta, Microsoft, Amazon and Google have told investors that they expect to spend a combined $320 billion on infrastructure costs this year. Much of that will go toward building new data centers — more than twice what they spent two years ago.
As OpenAI and its partners build a roughly $60 billion data center complex for A.I. in Texas and another in the Middle East, Meta is erecting a facility in Louisiana that will be twice as large. Amazon is going even bigger with a new campus in Indiana. Amazon’s partner, the A.I. start-up Anthropic, says it could eventually use all 30 of the data centers on this 1,200-acre campus to train a single A.I system. Even if Anthropic’s progress stops, Amazon says that it will use those 30 data centers to deliver A.I. services to customers.

Amazon is building a data center complex in New Carlisle, Ind., for its work with the A.I. company Anthropic. Photo Credit…AJ Mast for The New York Times
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Stargate UAE:
OpenAI is partnering with United Arab Emirates firm G42 and others to build a huge artificial-intelligence data center in Abu Dhabi, UAE. The project, called Stargate UAE, is part of a broader push by the U.A.E. to become one of the world’s biggest funders of AI companies and infrastructure—and a hub for AI jobs. The Stargate project is led by G42, an AI firm controlled by Sheikh Tahnoon bin Zayed al Nahyan, the U.A.E. national-security adviser and brother of the president. As part of the deal, an enhanced version of ChatGPT would be available for free nationwide, OpenAI said.
The first 200-megawatt chunk of the data center is due to be completed by the end of 2026, while the remainder of the project hasn’t been finalized. The buildings’ construction will be funded by G42, and the data center will be operated by OpenAI and tech company Oracle, G42 said. Other partners include global tech investor, AI/GPU chip maker Nvidia and network-equipment company Cisco.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Softbank and ASI:
Not wanting to be left behind, SoftBank, led by CEO Masayoshi Son, has made massive investments in AI and has a bold vision for the future of AI development. Son has expressed a strong belief that Artificial Super Intelligence (ASI), surpassing human intelligence by a factor of 10,000, will emerge within the next 10 years. For example, Softbank has:
- Significant investments in OpenAI, with planned investments reaching approximately $33.2 billion. Son considers OpenAI a key partner in realizing their ASI vision.
- Acquired Ampere Computing (chip designer) for $6.5 billion to strengthen their AI computing capabilities.
- Invested in the Stargate Project alongside OpenAI, Oracle, and MGX. Stargate aims to build large AI-focused data centers in the U.S., with a planned investment of up to $500 billion.
Son predicts that AI will surpass human-level cognitive abilities (Artificial General Intelligence or AGI) within a few years. He then anticipates a much more advanced form of AI, ASI, to be 10,000 times smarter than humans within a decade. He believes this progress is driven by advancements in models like OpenAI’s o1, which can “think” for longer before responding.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Super High Salaries for AI Researchers:
Salaries for A.I. experts are going through the roof and reaching the stratosphere. OpenAI, Google DeepMind, Anthropic, Meta, and NVIDIA are paying over $300,000 in base salary, plus bonuses and stock options. Other companies like Netflix, Amazon, and Tesla are also heavily invested in AI and offer competitive compensation packages.
Meta has been offering compensation packages worth as much as $100 million per person. The owner of Facebook made more than 45 offers to researchers at OpenAI alone, according to a person familiar with these approaches. Meta’s CTO Andrew Bosworth implied that only a few people for very senior leadership roles may have been offered that kind of money, but clarified “the actual terms of the offer” wasn’t a “sign-on bonus. It’s all these different things.” Tech companies typically offer the biggest chunks of their pay to senior leaders in restricted stock unit (RSU) grants, dependent on either tenure or performance metrics. A four-year total pay package worth about $100 million for a very senior leader is not inconceivable for Meta. Most of Meta’s named officers, including Bosworth, have earned total compensation of between $20 million and nearly $24 million per year for years.
Meta CEO Mark Zuckerberg on Monday announced its new artificial intelligence organization, Meta Superintelligence Labs, to its employees, according to an internal post reviewed by The Information. The organization includes Meta’s existing AI teams, including its Fundamental AI Research lab, as well as “a new lab focused on developing the next generation of our models,” Zuckerberg said in the post. Scale AI CEO Alexandr Wang has joined Meta as its Chief AI Officer and will partner with former GitHub CEO Nat Friedman to lead the organization. Friedman will lead Meta’s work on AI products and applied research.
“I’m excited about the progress we have planned for Llama 4.1 and 4.2,” Zuckerberg said in the post. “In parallel, we’re going to start research on our next generation models to get to the frontier in the next year or so,” he added.
On Thursday, researcher Lucas Beyer confirmed he was leaving OpenAI to join Meta along with the two others who led OpenAI’s Zurich office. He tweeted: “1) yes, we will be joining Meta. 2) no, we did not get 100M sign-on, that’s fake news.” (Beyer politely declined to comment further on his new role to TechCrunch.) Beyer’s expertise is in computer vision AI. That aligns with what Meta is pursuing: entertainment AI, rather than productivity AI, Bosworth reportedly said in that meeting. Meta already has a stake in the ground in that area with its Quest VR headsets and its Ray-Ban and Oakley AI glasses.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
VC investments in AI are off the charts:
Venture capitalists are strongly increasing their AI spending. U.S. investment in A.I. companies rose to $65 billion in the first quarter, up 33% from the previous quarter and up 550% from the quarter before ChatGPT came out in 2022, according to data from PitchBook, which tracks the industry.
This astounding VC spending, critics argue, comes with a huge risk. A.I. is arguably more expensive than anything the tech industry has tried to build, and there is no guarantee it will live up to its potential. But the bigger risk, many executives believe, is not spending enough to keep pace with rivals.
“The thinking from the big C.E.O.s is that they can’t afford to be wrong by doing too little, but they can afford to be wrong by doing too much,” said Jordan Jacobs, a partner with the venture capital firm Radical Ventures. “Everyone is deeply afraid of being left behind,” said Chris V. Nicholson, an investor with the venture capital firm Page One Ventures who focuses on A.I. technologies.
Indeed, a significant driver of investment has been a fear of missing out on the next big thing, leading to VCs pouring billions into AI startups at “nosebleed valuations” without clear business models or immediate paths to profitability.
Conclusions:
Big tech companies and VCs acknowledge that they may be overestimating A.I.’s potential. Developing and implementing AI systems, especially large language models (LLMs), is incredibly expensive due to hardware (GPUs), software, and expertise requirements. One of the chief concerns is that revenue for many AI companies isn’t matching the pace of investment. Even major players like OpenAI reportedly face significant cash burn problems. But even if the technology falls short, many executives and investors believe, the investments they’re making now will be worth it.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
References:
https://www.nytimes.com/2025/06/27/technology/ai-spending-openai-amazon-meta.html
Meta is offering multimillion-dollar pay for AI researchers, but not $100M ‘signing bonuses’
https://www.theinformation.com/briefings/meta-announces-new-superintelligence-lab
OpenAI partners with G42 to build giant data center for Stargate UAE project
AI adoption to accelerate growth in the $215 billion Data Center market
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
Proposed solutions to high energy consumption of Generative AI LLMs: optimized hardware, new algorithms, green data centers
Sources: AI is Getting Smarter, but Hallucinations Are Getting Worse
Recent reports suggest that AI hallucinations—instances where AI generates false or misleading information—are becoming more frequent and present growing challenges for businesses and consumers alike who rely on these technologies. More than two years after the arrival of ChatGPT, tech companies, office workers and everyday consumers are using A.I. bots for an increasingly wide array of tasks. But there is still no way of ensuring that these systems produce accurate information.
A groundbreaking study featured in the PHARE (Pervasive Hallucination Assessment in Robust Evaluation) dataset has revealed that AI hallucinations are not only persistent but potentially increasing in frequency across leading language models. The research, published on Hugging Face, evaluated multiple large language models (LLMs) including GPT-4, Claude, and Llama models across various knowledge domains.
“We’re seeing a concerning trend where even as these models advance in capability, their propensity to hallucinate remains stubbornly present,” notes the PHARE analysis. The comprehensive benchmark tested models across 37 knowledge categories, revealing that hallucination rates varied significantly by domain, with some models demonstrating hallucination rates exceeding 30% in specialized fields.

Hallucinations are when AI bots produce fabricated information and present it as fact. Photo Credit: More SOPA Images/LightRocket via Getty Images
Today’s A.I. bots are based on complex mathematical systems that learn their skills by analyzing enormous amounts of digital data. These systems use mathematical probabilities to guess the best response, not a strict set of rules defined by human engineers. So they make a certain number of mistakes. “Despite our best efforts, they will always hallucinate,” said Amr Awadallah, the chief executive of Vectara, a start-up that builds A.I. tools for businesses, and a former Google executive.
“That will never go away,” he said. These AI bots do not — and cannot — decide what is true and what is false. Sometimes, they just make stuff up, a phenomenon some A.I. researchers call hallucinations. On one test, the hallucination rates of newer A.I. systems were as high as 79%.

Amr Awadallah, the chief executive of Vectara, which builds A.I. tools for businesses, believes A.I. “hallucinations” will persist.Credit…Photo credit: Cayce Clifford for The New York Times
AI companies like OpenAI, Google, and DeepSeek have introduced reasoning models designed to improve logical thinking, but these models have shown higher hallucination rates compared to previous versions. For more than two years, those companies steadily improved their A.I. systems and reduced the frequency of these errors. But with the use of new reasoning systems, errors are rising. The latest OpenAI systems hallucinate at a higher rate than the company’s previous system, according to the company’s own tests.
For example, OpenAI’s latest models (o3 and o4-mini) have hallucination rates ranging from 33% to 79%, depending on the type of question asked. This is significantly higher than earlier models, which had lower error rates. Experts are still investigating why this is happening. Some believe that the complex reasoning processes in newer AI models may introduce more opportunities for errors.
Others suggest that the way these models are trained might be amplifying inaccuracies. For several years, this phenomenon has raised concerns about the reliability of these systems. Though they are useful in some situations — like writing term papers, summarizing office documents and generating computer code — their mistakes can cause problems. Despite efforts to reduce hallucinations, AI researchers acknowledge that hallucinations may never fully disappear. This raises concerns for applications where accuracy is critical, such as legal, medical, and customer service AI systems.
The A.I. bots tied to search engines like Google and Bing sometimes generate search results that are laughably wrong. If you ask them for a good marathon on the West Coast, they might suggest a race in Philadelphia. If they tell you the number of households in Illinois, they might cite a source that does not include that information. Those hallucinations may not be a big problem for many people, but it is a serious issue for anyone using the technology with court documents, medical information or sensitive business data.
“You spend a lot of time trying to figure out which responses are factual and which aren’t,” said Pratik Verma, co-founder and chief executive of Okahu, a company that helps businesses navigate the hallucination problem. “Not dealing with these errors properly basically eliminates the value of A.I. systems, which are supposed to automate tasks for you.”
For more than two years, companies like OpenAI and Google steadily improved their A.I. systems and reduced the frequency of these errors. But with the use of new reasoning systems, errors are rising. The latest OpenAI systems hallucinate at a higher rate than the company’s previous system, according to the company’s own tests.
The company found that o3 — its most powerful system — hallucinated 33% of the time when running its PersonQA benchmark test, which involves answering questions about public figures. That is more than twice the hallucination rate of OpenAI’s previous reasoning system, called o1. The new o4-mini hallucinated at an even higher rate: 48 percent.
When running another test called SimpleQA, which asks more general questions, the hallucination rates for o3 and o4-mini were 51% and 79%. The previous system, o1, hallucinated 44% of the time.
In a paper detailing the tests, OpenAI said more research was needed to understand the cause of these results. Because A.I. systems learn from more data than people can wrap their heads around, technologists struggle to determine why they behave in the ways they do.
“Hallucinations are not inherently more prevalent in reasoning models, though we are actively working to reduce the higher rates of hallucination we saw in o3 and o4-mini,” a company spokeswoman, Gaby Raila, said. “We’ll continue our research on hallucinations across all models to improve accuracy and reliability.”
Tests by independent companies and researchers indicate that hallucination rates are also rising for reasoning models from companies such as Google and DeepSeek.
Since late 2023, Mr. Awadallah’s company, Vectara, has tracked how often chatbots veer from the truth. The company asks these systems to perform a straightforward task that is readily verified: Summarize specific news articles. Even then, chatbots persistently invent information. Vectara’s original research estimated that in this situation chatbots made up information at least 3% of the time and sometimes as much as 27%.
In the year and a half since, companies such as OpenAI and Google pushed those numbers down into the 1 or 2% range. Others, such as the San Francisco start-up Anthropic, hovered around 4%. But hallucination rates on this test have risen with reasoning systems. DeepSeek’s reasoning system, R1, hallucinated 14.3% of the time. OpenAI’s o3 climbed to 6.8%.
Sarah Schwettmann, co-founder of Transluce, said that o3’s hallucination rate may make it less useful than it otherwise would be. Kian Katanforoosh, a Stanford adjunct professor and CEO of the upskilling startup Workera, told TechCrunch that his team is already testing o3 in their coding workflows, and that they’ve found it to be a step above the competition. However, Katanforoosh says that o3 tends to hallucinate broken website links. The model will supply a link that, when clicked, doesn’t work.
AI companies are now leaning more heavily on a technique that scientists call reinforcement learning. With this process, a system can learn behavior through trial and error. It is working well in certain areas, like math and computer programming. But it is falling short in other areas.
“The way these systems are trained, they will start focusing on one task — and start forgetting about others,” said Laura Perez-Beltrachini, a researcher at the University of Edinburgh who is among a team closely examining the hallucination problem.
Another issue is that reasoning models are designed to spend time “thinking” through complex problems before settling on an answer. As they try to tackle a problem step by step, they run the risk of hallucinating at each step. The errors can compound as they spend more time thinking.
“What the system says it is thinking is not necessarily what it is thinking,” said Aryo Pradipta Gema, an A.I. researcher at the University of Edinburgh and a fellow at Anthropic.
New research highlighted by TechCrunch indicates that user behavior may exacerbate the problem. When users request shorter answers from AI chatbots, hallucination rates actually increase rather than decrease. “The pressure to be concise seems to force these models to cut corners on accuracy,” the TechCrunch article explains, challenging the common assumption that brevity leads to greater precision.
References:
https://www.nytimes.com/2025/05/05/technology/ai-hallucinations-chatgpt-google.html
The Confidence Paradox: Why AI Hallucinations Are Getting Worse, Not Better
https://www.forbes.com/sites/conormurray/2025/05/06/why-ai-hallucinations-are-worse-than-ever/
https://techcrunch.com/2025/04/18/openais-new-reasoning-ai-models-hallucinate-more/
Goldman Sachs: Big 3 China telecom operators are the biggest beneficiaries of China’s AI boom via DeepSeek models; China Mobile’s ‘AI+NETWORK’ strategy
Telecom sessions at Nvidia’s 2025 AI developers GTC: March 17–21 in San Jose, CA
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
Does AI change the business case for cloud networking?
Deutsche Telekom and Google Cloud partner on “RAN Guardian” AI agent
Ericsson’s sales rose for the first time in 8 quarters; mobile networks need an AI boost
FT: New benchmarks for Gen AI models; Neocloud groups leverage Nvidia chips to borrow >$11B
The Financial Times reports that technology companies are rushing to redesign how they test and evaluate their Gen AI models, as current AI benchmarks appear to be inadequate. AI benchmarks are used to assess how well an AI model can generate content that is coherent, relevant, and creative. This can include generating text, images, music, or any other form of content.
OpenAI, Microsoft, Meta and Anthropic have all recently announced plans to build AI agents that can execute tasks for humans autonomously on their behalf. To do this effectively, the AI systems must be able to perform increasingly complex actions, using reasoning and planning.
Current public AI benchmarks — Hellaswag and MMLU — use multiple-choice questions to assess common sense and knowledge across various topics. However, researchers argue this method is now becoming redundant and models need more complex problems.
“We are getting to the era where a lot of the human-written tests are no longer sufficient as a good barometer for how capable the models are,” said Mark Chen, senior vice-president of research at OpenAI. “That creates a new challenge for us as a research world.”
The SWE Verified benchmark was updated in August to better evaluate autonomous systems based on feedback from companies, including OpenAI. It uses real-world software problems sourced from the developer platform GitHub and involves supplying the AI agent with a code repository and an engineering issue, asking them to fix it. The tasks require reasoning to complete.
“It is a lot more challenging [with agentic systems] because you need to connect those systems to lots of extra tools,” said Jared Kaplan, chief science officer at Anthropic.
“You have to basically create a whole sandbox environment for them to play in. It is not as simple as just providing a prompt, seeing what the completion is and then evaluating that.”
Another important factor when conducting more advanced tests is to make sure the benchmark questions are kept out of the public domain, in order to ensure the models do not effectively “cheat” by generating the answers from training data, rather than solving the problem.
The need for new benchmarks has also led to efforts by external organizations. In September, the start-up Scale AI announced a project called “Humanity’s Last Exam”, which crowdsourced complex questions from experts across different disciplines that required abstract reasoning to complete.
Meanwhile, the Financial Times recently reported that Wall Street’s largest financial institutions had loaned more than $11bn to “neocloud” groups, backed by their possession of Nvidia’s AI GPU chips. These companies include names such as CoreWeave, Crusoe and Lambda, and provide cloud computing services to tech businesses building AI products. They have acquired tens of thousands of Nvidia’s graphics processing units (GPUs) through partnerships with the chipmaker. With capital expenditure on data centres surging, in the rush to develop AI models, the Nvidia’s AI GPU chips have become a precious commodity.

Nvidia’s chips have become a precious commodity in the ongoing race to develop AI models © Marlena Sloss/Bloomberg
…………………………………………………………………………………………………………………………………
The $3tn tech group’s allocation of chips to neocloud groups has given confidence to Wall Street lenders to lend billions of dollars to the companies that are then used to buy more Nvidia chips. Nvidia is itself an investor in neocloud companies that in turn are among its largest customers. Critics have questioned the ongoing value of the collateralised chips as new advanced versions come to market — or if the current high spending on AI begins to retract. “The lenders all coming in push the story that you can borrow against these chips and add to the frenzy that you need to get in now,” said Nate Koppikar, a short seller at hedge fund Orso Partners. “But chips are a depreciating, not appreciating, asset.”
References:
https://www.ft.com/content/866ad6e9-f8fe-451f-9b00-cb9f638c7c59
https://www.ft.com/content/fb996508-c4df-4fc8-b3c0-2a638bb96c19
https://www.ft.com/content/41bfacb8-4d1e-4f25-bc60-75bf557f1f21
Tata Consultancy Services: Critical role of Gen AI in 5G; 5G private networks and enterprise use cases
Reuters & Bloomberg: OpenAI to design “inference AI” chip with Broadcom and TSMC
AI adoption to accelerate growth in the $215 billion Data Center market
AI Echo Chamber: “Upstream AI” companies huge spending fuels profit growth for “Downstream AI” firms
AI winner Nvidia faces competition with new super chip delayed
