

AWS
Amazon and Corning in Multi-Billion-Dollar Fiber Infrastructure Deal in North Carolina
Introduction:
The surge in optical fiber demand is intensifying as hyperscale cloud providers accelerate infrastructure buildouts to support AI-driven workloads and high-density data center interconnect (DCI). Corning [1.] today announced a multi‑billion‑dollar investment from Amazon to expand fiber manufacturing capacity in North Carolina—incremental to its previously announced $10 billion regional cloud infrastructure expansion—reflects a broader structural shift in how optical supply chains are being secured and scaled.
Note 1. Corning’s fiber-optic infrastructure uses highly pure strands of optical glass thinner than a human hair to transmit massive amounts of data as pulses of light. These networks serve as the backbone for modern communications, connecting everything from rural broadband rollouts to hyperscale data centers driving generative AI. In hyperscale cloud and AI data centers, Corning provides high-density optical hardware and cables, such as their GlassWorks AI™ solutions. These large setups feature massive fiber-optic trunk cables containing hundreds to thousands of individual fibers bundled together to link powerful processors and servers. For outdoor networks running underground or on utility poles, you will see ruggedized cables protected by thick jackets and aramid yarn. These cables are designed to withstand weather, crushing, and extreme temperatures.

Corning’s structured cable solutions for internal data center connectivity. Image Credit: Corning
…………………………………………………………………………………………………………………………………………………………………………………….
This trend is not isolated. Hyperscalers including Meta, Microsoft, and wireline network operator Lumen are proactively entering long-term supply and co-investment agreements with fiber and cable manufacturers, effectively reshaping the upstream optical ecosystem.
Recent Fiber Supply Agreements with Corning:
-
May 2026: NVIDIA committed $500 million to Corning to support construction of three new optical manufacturing facilities in North Carolina and Texas. This investment is expected to increase Corning’s U.S.-based optical connectivity manufacturing capacity by approximately 10× and expand domestic fiber production by over 50%, targeting AI cluster interconnect requirements characterized by high fiber count and low-latency links aligned with IEEE 802.3 Ethernet and emerging co-packaged optics ecosystems.
-
January 2026: Meta finalized a $6 billion agreement with Corning to secure fiber supply for large-scale data center fabrics. These fabrics increasingly rely on high-fiber-density architectures consistent with leaf-spine topologies and standards such as IEEE 802.3bs/ck (400G/800G Ethernet), as well as parallel single-mode fiber (PSM) and wavelength-division multiplexing (WDM) approaches defined in ITU-T G.694.x.
-
September 2025: Microsoft entered a manufacturing agreement with Corning and Heraeus focused on hollow-core fiber (HCF), a technology aligned with ITU-T G.650 characterization frameworks. HCF offers lower latency (reduced group index) and improved performance for latency-sensitive AI workloads and inter-data center transport.
-
August 2024: Corning and Lumen established a supply agreement for next-generation fiber optic cable to support AI-driven traffic growth. This aligns with ITU-T G.652.D and G.657 fiber standards for bend-insensitive and high-capacity terrestrial deployments, as well as evolving requirements for high-count ribbon fiber cables in dense metro and campus environments.
Structural Implications for the Optical Supply Chain:
Hyperscalers are transitioning from passive consumers of optical components to active participants in manufacturing scale-up, including:
-
Anchor tenancy models: As seen with Meta’s backing of Corning’s North Carolina facility, hyperscalers are underwriting capacity expansion, effectively securing preferential access to supply.
-
Vertical influence: Direct investments and long-term offtake agreements allow hyperscalers to influence fiber specifications, manufacturing roadmaps, and deployment architectures (e.g., optimized fiber types for short-reach vs. long-haul DCI).
-
Workforce development: Amazon and Corning’s collaboration with Catawba Valley Community College to expand fiber technician training reflects a strategic effort to address labor constraints in optical manufacturing and deployment, reinforcing domestic supply chain resilience.
Implications for Telecom Operators:
These developments introduce non-trivial risks and strategic considerations for telecom operators:
-
Supply prioritization: Hyperscaler-backed agreements may shift allocation dynamics, potentially constraining availability for traditional telecom buyers during periods of tight supply.
-
Pricing pressure: Long-term, high-volume contracts could influence pricing benchmarks, potentially disadvantaging operators without comparable scale or capital flexibility.
-
BEAD timing mismatch: U.S. operators anticipating fiber expansion funded by BEAD (Broadband Equity, Access, and Deployment) may face supply bottlenecks if hyperscaler demand absorbs near-term manufacturing output.
-
Architectural divergence: Hyperscaler-driven requirements—optimized for short-reach, ultra-high-capacity intra-data-center and DCI links—may skew innovation toward their use cases, potentially misaligning with traditional access network needs governed by ITU-T G.984 (GPON), G.9807 (XGS-PON), and emerging 25G/50G PON standards.
A useful analogy is the semiconductor industry, where hyperscaler influence has already reshaped foundry capacity allocation and advanced node prioritization. A similar dynamic is now emerging in optical fiber and connectivity, with hyperscalers effectively acting as quasi-industrial planners for next-generation optical infrastructure.
Quotes:
“Amazon’s investments in North Carolina have created more than 26,000 jobs across the state. This multibillion-dollar agreement with Corning continues that commitment, channeling investment into American manufacturing and creating 1,000 new jobs at their facilities near our data centers,” said Matt Garman, CEO of AWS. “We’re also partnering to train North Carolinians for highly skilled roles in fiber optics and fusion splicing. These long-term investments create long-term careers and real opportunity in the communities where we operate.”
“This agreement with Amazon represents a significant milestone for Corning and for American manufacturing,” said Wendell Weeks, chairman, CEO, and president of Corning. “For 175 years, Corning has pioneered the technologies that connect people and transform industries. Amazon’s investment will help us expand production, create 1,000 new advanced manufacturing jobs at our facilities, and lead the way toward building a resilient U.S. manufacturing base.”
Clearfield CEO Cheri Beranek told Fierce Network at Fiber Connect that supply chain issues are re-emerging, particularly around high-count fiber. “There’s absolutely a shortage of ribbon fiber,” she said, referring to a conversation with Hawaii Telecom, a Clearfield customer. “The high count for the ribbon fiber … everything over 432 is tough to get,” she said. “The fiber companies want to tell you that there’s enough American‑made fiber… but there can’t be.”
“In talking to fiber optic suppliers, they all say one thing, ‘It’s nice to finally be the cool kid on the block.’ Hyperscalers are finally realizing that they not only need compute, storage, chips, power, water and real estate, they also need fiber optic connectivity,” said Fierce Network’s Chief Analyst Linda Hardesty.
The net effect is a tightening coupling between AI infrastructure demand and optical supply chain strategy—one that telecom operators will need to actively manage through procurement strategy, vendor diversification, and potentially deeper participation in supply-side partnerships.
End Note:
Amazon’s long-term commitment to North Carolina goes beyond direct investments and jobs created in the state. Through workforce development, Career Choice, and upskilling programs, Amazon has already provided practical training for nearly 7,000 people in North Carolina, helping to open new pathways for higher-paying jobs and fulfilling careers.
In the last decade, Amazon has contributed more than $72 million to charities and organizations supporting local needs across North Carolina, with $10 million provided in 2025 alone to 26 local community partners. This includes contributions like $1.5 million to enhance public safety services for southeastern Hamlet and surrounding Richmond County communities by funding a new fire substation that is expected to lower emergency response times and homeowner insurance premiums.
References:
https://www.corning.com/data-center/au/en/home/applications/enterprise-private-data-center.html
https://www.aboutamazon.com/news/company-news/amazon-corning-fiber-optics-1000-jobs-north-carolina
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
Corning to Build New Fiber Optic Plant in Phoenix, AZ for AT&T Fiber Network Expansion
Calix and Corning Weigh In: When Will Broadband Wireline Spending Increase?
Verizon-Corning $1.05B fiber deal part of larger build-out or buy program
Inside Amazon’s new data center network architecture: quasi random network topology and passive optical devices
Amazon Web Services (AWS) claims it recently achieved a major breakthrough in Data Center Network (DCN) architecture and has been quietly deploying the new technology in its data centers since late last year. Amazon detailed its new networking design in a paper published May 21st titled “RNG: Flat Data Center Networks at Scale.” RNG, or “resilient network graphs,” is built around a quasi-random topology and new passive optical hardware. It’s a “quasi-random” design that combines elements of traditional, structured data networks with the performance advantages of more random architectures.
The goal is to move off conventional hierarchical “fat-tree” designs toward a flatter, more mesh-like fabric that uses far fewer routers and switches, offers more parallel paths, and therefore delivers higher effective throughput at lower power and capex.
“By essentially flattening the network, we eliminated the bottlenecks that come with traditional networking designs,” Matt Rehder, vice president of AWS Network Engineering, said in an exclusive interview with WIRED. “We think we’re the only ones who have done this at scale. RNG is a great fit for our core demands, but AI training data patterns are far more coordinated and centrally orchestrated, so they don’t approximate a random graph.”
The fact that Amazon is using this in the real world is “remarkable,” said Brighten Godfrey, a computer science professor at the University of Illinois Urbana-Champaign and an expert in networking, who was not involved in Amazon’s research. Godfrey coauthored a seminal 2012 paper on random network graphs, which he says are a “mind-bending problem to solve, in general.”
Classic cloud DCNs use structured topologies (Clos/fat-tree) where paths are highly regular and layered (Top of Rack (ToR)–aggregation–core). By contrast, random-graph theory says the most efficient routing networks are flat random graphs: each node connects to a small random subset of others, creating many short, diverse paths and graceful degradation under failures. The problem has always been practical: random cabling at scale is unmanageable, and routing across a huge random graph is nontrivial.
AWS’s “quasi-random” design essentially mixes determinism with randomness: key structural elements are fixed to keep the cabling and deployment manageable, while enough randomness is retained in the interconnect pattern to get the performance and resilience benefits of random graphs. The physical enabler is a new passive optical device called a ShuffleBox that standardizes how switches connect and internally permutes links so that, when many ShuffleBoxes are wired together, the resulting global topology is quasi-random without having to hand-design every link.

Image Credit: Amazon
………………………………………………………………………………………………………………………….
Key architectural pieces and claimed gains:
AWS reports that RNG-based fabrics now serve as the default network architecture for most new AWS data centers, after initial deployments beginning in 2024. The company claims the design:
-
Uses roughly 69% fewer routers/switches than traditional fat-tree DCNs, because the network is flatter and relies more on passive optical fanout.
-
Delivers up to about 33% higher throughput, due to more independent paths and better load spreading.
-
Cuts network equipment power consumption by on the order of 40%, with associated reductions in cooling and operational overhead.
On the control-plane side, AWS developed a routing scheme called Spraypoint. Instead of always following a strict shortest path from source to destination, Spraypoint first “sprays” traffic randomly to neighbors, then directs it via preselected “waypoints” using more conventional shortest-path routing. This hybrid behavior exploits the quasi-random topology to open many more independent paths than standard ECMP-style shortest-path routing would, which in turn improves utilization and resilience under congestion or failures.
Strategic implications:
For AWS’s cloud and AI build-out, this is positioned as a foundational infrastructure advantage: higher bisection bandwidth and lower network energy per bit directly benefit large-scale AI training clusters, storage backends, and multi-tenant cloud workloads. Fewer active devices and more passive optics also translate into lower capex and opex at hyperscale, so AWS is framing this as both a performance and cost/sustainability play that could save billions of dollars and reduce CO₂ emissions over time.
From a networking-theory standpoint, this is notable as one of the first reported at-scale, production deployments of a flat random-graph-inspired topology in a hyperscale DCN, rather than a purely academic or lab system.
In a quasi-random topology like AWS’s RNG fabric, the impact on latency and jitter comes from three main effects: path length distribution, load spreading, and failure behavior.
Baseline latency: path lengths and device count:
In a traditional Clos/fat-tree, average latency is dominated by a fixed number of stages (ToR → agg → core → agg → ToR), so hop count is tightly controlled but you pay for many active devices. A quasi-random, flat graph replaces that rigid hierarchy with many short, irregular paths; on average, shortest paths between any two switches are similar or slightly shorter in hop count than in a fat-tree, and there are fewer active routers in the path because the architecture offloads fanout to passive optics. That tends to keep or slightly reduce median/mean latency per flow, especially under moderate load, because packets traverse fewer serialized queueing points even if the physical graph looks “messier.”
Jitter: congestion and path diversity:
Jitter is driven much more by variable queueing delay than by fixed propagation or serialization. In a quasi-random fabric with many alternate paths and a load-balancing scheme like Spraypoint (random spray + waypoint-based shortest paths), flows can be spread more evenly across the network, reducing hot spots and thus reducing the variance of queueing delay across packets. That can lower jitter compared with a Clos under the same aggregate load, because the system is less likely to funnel many flows through the same few congested uplinks or spine devices.
However, because the routing intentionally uses many different paths, per-flow packet reordering becomes more likely unless constrained by per-flow hashing or waypointing, which can show up as effective jitter at higher layers. AWS’s description of Spraypoint suggests they mitigate this by using waypoints and policy to preserve some path structure, so you get the diversity benefits without unconstrained per-packet spraying.
Under failure and high load:
Where quasi-random really helps latency/jitter is under failure and partial congestion. In a Clos, link or spine failures can force large sets of flows to converge on a smaller subset of remaining equal-cost paths, driving up queueing delay and jitter nonlinearly. In a resilient random-graph-style fabric, node/edge failures simply remove a few edges from a highly connected graph; there are typically many alternative short paths, so the increase in hop count and queueing pressure is smaller and more diffuse. That tends to keep tail latency and jitter (P99, P99.9) better behaved, even if median latency looks similar to a Clos at low load.
So, qualitatively: median latency is roughly comparable to a well-designed Clos, sometimes better due to fewer active stages; jitter and tail latency should improve under realistic, bursty load and failure scenarios, provided the routing stack is designed to limit packet reordering.
Summary and Conclusions:
Quasi-random data center topologies like AWS’s RNG fabric replace rigid Clos/fat-tree hierarchies with a flatter, graph-like network that preserves short path lengths while dramatically increasing path diversity, which tends to hold median latency roughly steady or slightly better by reducing the number of active, queueing devices per path and offloading fanout to passive optics. They primarily improve jitter and tail latency by spreading flows across many alternative routes so congestion is less concentrated, making queueing delays less bursty and keeping P99/P99.9 behavior more stable under failures and hot spots, provided the routing layer (for example, AWS’s Spraypoint approach) constrains packet reordering through way pointing or per-flow consistency.
In conclusion, quasi-random fabrics are less about shaving a few microseconds off baseline latency and more about delivering more predictable end-to-end performance—especially for east–west, latency-sensitive cloud and AI workloads—by trading rigid structure for statistically robust, highly connected graphs that degrade more gracefully when links, nodes, or traffic patterns become pathological.
…………………………………………………………………………………………………………………………………………………………………….
References:
https://arxiv.org/pdf/2604.15261
https://www.wired.com/story/amazon-aws-ceo-matt-garman-ai-agents/
AWS to deploy AI inference chips from Cerebras in its data centers; Anapurna Labs/Amazon in-house AI silicon products
Amazon’s Jeff Bezos at Italian Tech Week: “AI is a kind of industrial bubble”
Data Center Networking Market to grow at a CAGR of 6.22% during 2022-2027 to reach $35.6 billion by 2027
TMR: Data Center Networking Market sees shift to user-centric & data-oriented business + CoreSite DC Tour
AWS to deploy AI inference chips from Cerebras in its data centers; Anapurna Labs/Amazon in-house AI silicon products
Amazon Web Services (AWS) announced it plans to integrate AI processors from Cerebras Systems [1.] into its data centers, signaling growing confidence in the AI-focused semiconductor startup. Under a new multiyear partnership announced Friday, AWS will deploy Cerebras’s Wafer-Scale Engine (WSE) to accelerate inference workloads—the stage of AI operations where models generate responses to user queries. Financial details of the agreement were not disclosed.
Note 1. Founded in 2015 and headquartered in Sunnyvale, CA, Cerebras claims to have the world’s fastest AI inference and training platform.
The collaboration reflects a significant realignment in compute infrastructure strategies across the AI ecosystem. While initial industry focus centered on model training, the rapid expansion of deployed AI services is driving demand for optimized inference performance. Traditional GPUs, though unmatched for training, can be suboptimal for inference scenarios that require ultra-low latency and high throughput. Cloud and AI platform providers are therefore diversifying their silicon portfolios to better match workload profiles and to scale capacity efficiently.
AWS, the world’s largest cloud infrastructure provider, has traditionally relied on its in-house semiconductor division, Annapurna Labs, for custom chip design. Annapurna’s Trainium processors compete with GPUs from major suppliers such as Nvidia and AMD, offering cost and performance advantages for AI training workloads. The new partnership introduces Cerebras technology into AWS infrastructure, where it will work alongside Trainium to enhance large-scale inference capabilities.
Cerebras, best known for its wafer-scale architecture, markets its WSE processors as a high-speed inference platform capable of executing the decode phase of generative AI processing—where text, images, or other outputs are generated—at up to 25 times the speed of conventional GPU solutions. The company, valued at approximately $23 billion following a $1 billion funding round in February, has attracted backing from Fidelity, Benchmark, Tiger Global, Atreides, and Coatue.

The Cerebras deal underscores a major shift in the market for computing power. Image Credit: rebecca lewington/cerebras syste/Reuters
The AWS collaboration follows Cerebras’s major compute partnership with OpenAI, which reportedly involves deploying up to 750 MW of computing capacity powered by its chips. AWS and Cerebras will position their joint offering as a premium cloud inference solution, targeting enterprise AI developers requiring high-performance and scalable compute.
“The scale of AI demand is shifting from model creation to global deployment,” said Andrew Feldman, CEO of Cerebras. “Working with AWS aligns our technology with the industry’s largest cloud, giving us reach to a broad enterprise and developer base. If you want slow inference, there will be cheaper ways to go,” Feldman said. “But if you want fast tokens, if speed matters to you, if you’re doing coding or agentic work, not only are we the absolute fastest, but we intend to set the bar. We’re in this to win it.”

AWS and Cerebras will support both aggregated and disaggregated configurations. Disaggregated is ideal when you have large, stable workloads. Most customers run a mix of workloads with different prefill/decode ratios, where the traditional aggregated approach is still ideal. The start-up expects most customers will want access to both and the ability to route workloads to whichever configuration serves them best.
The move intensifies competition in the inference silicon segment, where Nvidia faces growing pressure from purpose-built processor architectures such as Cerebras’s WSE and other emerging alternatives. Nvidia, which recently announced a $20 billion licensing deal with Groq and plans to unveil a new inference-optimized platform, remains the dominant supplier but now contends with an accelerating wave of specialization across the AI compute stack.
AWS vice president and Annapurna Labs co-founder Nafea Bshara emphasized the company’s goal of offering flexible performance tiers. “Our job is to push the speed and lower the price,” he said, noting that AWS will continue to offer cost-optimized Trainium-only options alongside high-performance Cerebras-Trainium configurations.
………………………………………………………………………………………………………………………………………………………………………………………………….
Amazon’s Internally Designed AI Silicon:
Amazon has built a fairly broad internal AI-oriented silicon portfolio through Annapurna Labs, primarily for AWS:
-
Inferentia (Inferentia, Inferentia2) – Custom machine learning accelerators designed for high-throughput, low-cost inference at cloud scale. These power many AWS inference instances and are positioned as an alternative to Nvidia GPUs for production model serving.
-
Trainium (Trainium, Trainium2, Trainium3) – AI training accelerators optimized for large-scale model training (including frontier and foundation models), with Trainium2 and Trainium3 as newer generations offering materially higher performance and better $/compute than the first generation. These are central to projects such as the Rainier supercomputer for Anthropic.
-
Graviton (Graviton, Graviton2/3/4) – Arm-based general-purpose CPUs used heavily across EC2, increasingly in AI-adjacent roles (pre/post-processing, orchestration, model-serving microservices) and as part of cost-optimized AI stacks, even though they are not dedicated accelerators.
-
Nitro system – While not an AI accelerator per se, the Nitro family (offload cards and system) is an internally developed data-plane and virtualization offload architecture that underpins EC2 and works in tandem with Graviton, Inferentia, and Trainium to free CPU cycles and improve I/O for AI/ML workloads.
All of these are designed and iterated internally by Annapurna Labs for exclusive use in AWS data centers, then exposed to customers via AWS services rather than as standalone merchant silicon.
Amazon’s Annapurna Labs is an internal chip design group that has become a core strategic asset for AWS, especially for custom data center and AI silicon.
Origins and acquisition:
-
Annapurna Labs is an Israeli chip design startup founded in 2011 by semiconductor veterans of Intel and Broadcom, including Avigdor Willenz and Nafea Bshara.
- “When we talked with market sources and consulted with experts in the fields of data and servers, at that time only Amazon had a holistic vision and the ability to execute on a large scale,” recalls Bshara about the start of the romance with Amazon. “We were prepared to build the technology and at the same time were open to working with startups. From there we began a journey together with many meetings and shared thinking, among others with James Hamilton (Microsoft’s former data-base product architect and to AWS SVP), and from there within six months we found ourselves inside Amazon.”
-
Amazon began working with the company around 2013 and acquired it in 2015 for an estimated $350–$400 million.
-
Before the deal, Annapurna was in stealth, focusing on low‑power networking and server chips to improve data center efficiency.
Role inside Amazon and AWS:
-
Post‑acquisition, Annapurna was folded into AWS as a specialist microelectronics and custom silicon group, designing chips to reduce cost and power per unit of compute.
-
The group underpins several key AWS technologies: the Nitro system for offloading virtualization and I/O, Arm‑based Graviton CPUs for general compute, and Trainium and Inferentia accelerators for AI training and inference.
-
These chips let AWS optimize performance per watt and per dollar versus x86 servers and third‑party accelerators, improving margins and competitive pricing.
Key products and architectures:
-
Nitro: A combination of custom hardware and software that offloads storage, networking, and security functions from the host CPU, increasing tenant isolation and freeing CPU cycles for workloads.
-
Graviton: A family of Arm‑based server CPUs; by 2018 Graviton was widely adopted on AWS and is now used by most AWS customers for general cloud infrastructure workloads due to better price‑performance and energy efficiency.
-
Inferentia and Trainium: Custom accelerators designed by Annapurna for machine learning inference (Inferentia) and training (Trainium), intended to reduce AWS’s dependence on high‑priced Nvidia GPUs for AI workloads.
Strategic importance and AI focus:
-
Annapurna’s work is central to Amazon’s strategy of vertical integration in the cloud: owning the silicon stack as much as the software and services.
-
The group designs chips that power Amazon’s AI infrastructure, including systems used both by internal teams and external customers such as Anthropic, for which AWS is the primary cloud and silicon provider.
-
Amazon and Anthropic are collaborating on “Project Rainier,” a massive supercomputer built around hundreds of thousands of Annapurna‑designed Trainium2 chips, targeting more than five times the compute used to train current frontier models.
Organization, footprint, and industry impact:
-
Annapurna Labs maintains a significant presence in Israel, employing hundreds of engineers focused on advanced AI and networking processors for AWS.
-
It also operates major engineering hubs such as an Austin, Texas lab where advanced semiconductors and AI systems are designed and tested.
-
Analysts often describe the acquisition as one of Amazon’s most successful, arguing that Annapurna’s custom silicon is a “secret sauce” that helps AWS compete with Microsoft, Google, and others on performance, cost, and energy efficiency.
…………………………………………………………………………………………………………………………………………………………..
References:
https://www.cerebras.ai/company
https://www.cerebras.ai/blog/cerebras-is-coming-to-aws
https://www.wsj.com/tech/amazon-announces-inference-chips-deal-with-cerebras-109ecd31
https://en.globes.co.il/en/article-nafea-bshara-the-israeli-behind-amazons-graviton-chip-1001420744
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
Custom AI Chips: Powering the next wave of Intelligent Computing
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Will “AI at the Edge” transform telecom or be yet another telco monetization failure?
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
OpenAI and Broadcom in $10B deal to make custom AI chips
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
2026 Consumer Electronics Show Preview: smartphones, AI in devices/appliances and advanced semiconductor chips
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Google announces Gemini: it’s most powerful AI model, powered by TPU chips
AT&T and AWS to deliver last mile connectivity for AI workloads; AT&T Geo Modeler™ AI simulation tool
AT&T is strategically re-architecting its infrastructure for the AI era through high-capacity network modernization and deep integration with hyperscale cloud providers.
In addition to its almost six year old deal to run its 5G SA core network in Microsoft Azure’s cloud, AT&T announced at MWC 2026 that it’s now woring with Amazon Web Services (AWS) to extend 5G and fiber connectivity from business customers and locations directly into AWS environments, creating secure, resilient and reliable premises‑to‑cloud architectures for AI workloads. The collaboration is designed to reduce network complexity and latency while supporting real‑time analytics, machine learning, and agentic AI use cases.
This collaboration continues a long-standing relationship between AT&T and AWS and follows recent news outlining broader efforts to modernize the nation’s connectivity infrastructure by providing high-capacity fiber to AWS data centers, migrate AT&T workloads to AWS cloud capabilities and explore emerging satellite technologies.
AWS Interconnect – last mile embeds AT&T‑delivered connectivity directly into AWS workflows, designed to enable customers to provision and manage last‑mile connectivity within the AWS environment and lays the foundation for the use of AI agents to monitor and manage the AI experience from the user to the cloud. This streamlined, self‑managed approach helps enterprises reduce network complexity while maintaining control of their extended enterprise network, allowing businesses to move faster as they scale AI.
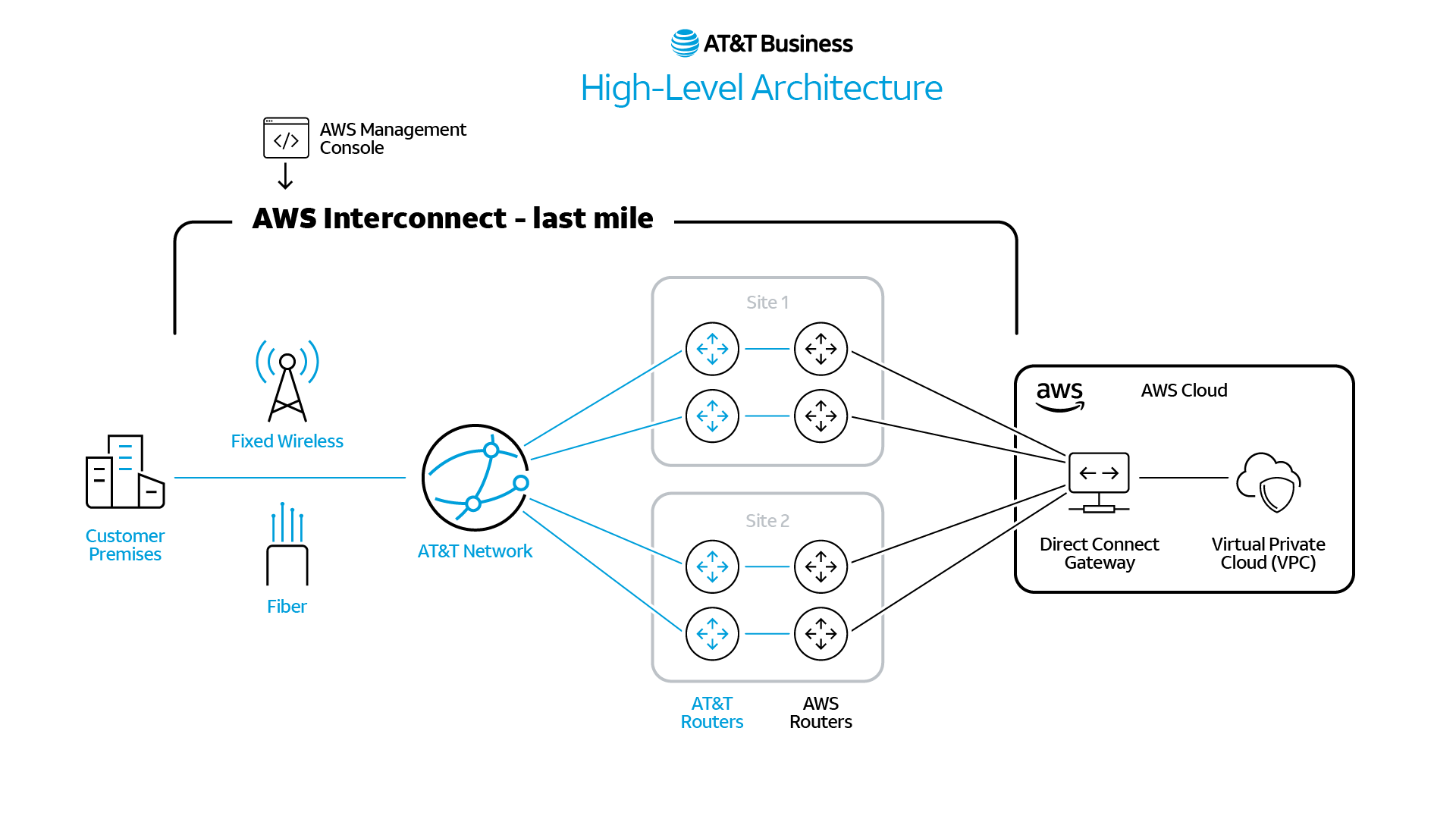
High level illustration of the planned AWS Interconnect – last mile architecture, showing how resilient interconnections and AT&T Fiber and fixed wireless access are intended to simplify private connectivity from customer locations into AWS environments.
Diagram Source: AT&T
………………………………………………………………………………………………………
“AI does not just need more compute; it needs flatter networks and faster connections,” said Shawn Hakl, SVP & Head of Product, AT&T Business. “By bringing high‑capacity connectivity closer to cloud platforms, integrating the management of the networks directly into the cloud provisioning process and engineering for resiliency at the metro level, AT&T is helping enterprises streamline their networks, improve performance, security, and scale AI with confidence.”
AT&T says they are building an AI‑ready network (?) designed to scale performance by continuing ongoing network investment, including the growth of capacities up to 1.6Tbps across key metro and long‑haul routes.
AT&T also announced it would work with Nvidia, Microsoft and MicroAI through its Connected AI platform for “smart manufacturing.”
………………………………………………………………………………………………………………..
Finally, AT&T described AT&T Geo Modeler™ which is able to better predict connectivity for emerging technologies like autonomous vehicles, drones, and robotics.
The Geo Modeler is an AI-powered simulation tool that helps predict, in near real time, how a wireless network will perform in the real world. Inspired by the video games Kounev played with his family growing up, the virtual model and simulation is “essentially like a giant video game of the United States” that, infused with AI tools, gives engineers a clearer picture of where potential weak spots may appear. Then issues can be addressed earlier and fixes can roll out faster. In essence, it creates virtual models, similar to the way video games are designed and developed.
“The Geo Modeler helps us see how the real world will shape coverage before we build, so we can deliver connectivity that’s ready for what’s next,” said AT&T scientist Velin Kounev.
Matt Harden, VP of Connected Solutions at AT&T, agrees. “The Geo Modeler is a foundational capability for the connected mobility era,” he said. “By marrying advanced geospatial simulation with AI-driven network orchestration, we can deliver predictable, high-performance connectivity that adapts with the environment. Whether it’s a hurricane, a packed stadium, or a city corridor full of autonomous vehicles, we will be prepared.”
References:
https://about.att.com/story/2026/aws-collaboration-scalable-business-ai.html
https://about.att.com/blogs/2026/150-years-of-connection.html
https://about.att.com/blogs/2025/geo-modeler.html
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
AT&T deploys nationwide 5G SA while Verizon lags and T-Mobile leads
AT&T to buy spectrum licenses from EchoStar for $23 billion
AT&T’s convergence strategy is working as per its 3Q 2025 earnings report
Progress report: Moving AT&T’s 5G core network to Microsoft Azure Hybrid Cloud platform
AT&T 5G SA Core Network to run on Microsoft Azure cloud platform
Verizon to build new, long-haul, high-capacity fiber pathways to connect AWS data centers
Verizon Business has announced a new Verizon AI Connect deal with Amazon Web Services (AWS) to provide resilient high-capacity, low-latency network infrastructure essential for the next wave of AI innovation. As part of the deal, Verizon will build new, long-haul, high-capacity fiber pathways to connect AWS data center locations. This will enable AWS to continue to deliver and scale its secure, reliable, and high-performance cloud services for customers building and deploying advanced AI applications at scale.
These new fiber segments mark a significant commitment in Verizon’s network buildout, to enable the AI ecosystem to intelligently deliver the exponential data growth driven by generative AI. The Verizon AI Connect solution will provide AWS with resilient network paths that will enhance the performance and reliability of AI workloads underpinned by Verizon’s award-winning network. The Verizon-AWS collaboration also encompasses joint development of private mobile edge computing solutions that provide secure, dedicated connectivity for enterprise customers. These existing collaborations have delivered significant value across multiple industries, from manufacturing and healthcare to retail and entertainment, by combining Verizon’s powerful network infrastructure with AWS’s comprehensive cloud services.

“AI will be essential to the future of business and society, driving innovation that demands a network to match,” said Scott Lawrence, SVP and Chief Product Officer, Verizon Business. “This deal with Amazon demonstrates our continued commitment to meet the growing demands of AI workloads for the businesses and developers building our future.”
“The next wave of innovation will be driven by generative AI, which requires a combination of secure, scalable cloud infrastructure and flexible, high-performance networking,” said Prasad Kalyanaraman, vice president, AWS Infrastructure Services. “By working with Verizon, AWS will enable high-performance network connections that ensure customers across every industry can build and deliver compelling, secure, and reliable AI applications at scale. This collaboration builds on our long-standing commitment to provide customers with the most secure, powerful, and efficient cloud infrastructure available today.”
This initiative strengthens Verizon’s long-standing strategic relationship with AWS. The companies have already established several key engagements, including Verizon’s adoption of AWS as a preferred strategic public cloud provider for its digital transformation initiatives. Previous engagements have targeted use cases across sectors such as manufacturing, healthcare, retail and media, pairing Verizon’s network capabilities with AWS’s cloud stack. It should be noted, however, that AWS also uses other major carriers and dark fiber providers, such as Lumen Technologies, Zayo, AT&T, and others, to ensure a highly redundant and diverse global inter-data center network.
This deal highlights how telecommunications companies are becoming critical enablers of the AI-driven economy by investing in the foundational fiber optic infrastructure required for large-scale AI processing.
References:
https://www.verizon.com/about/news/verizon-business-and-aws-new-fiber-deal
Verizon transports 1.2 terabytes per second of data across a single wavelength
Verizon, AWS and Bloomberg media work on 4K video streaming over 5G with MEC
Amazon AWS and Verizon Business Expand 5G Collaboration with Private MEC Solution
Lumen deploys 400G on a routed optical network to meet AI & cloud bandwidth demands
Big Tech and VCs invest hundreds of billions in AI while salaries of AI experts reach the stratosphere
Introduction:
Two and a half years after OpenAI set off the generative artificial intelligence (AI) race with the release of the ChatGPT, big tech companies are accelerating their A.I. spending, pumping hundreds of billions of dollars into their frantic effort to create systems that can mimic or even exceed the abilities of the human brain. The areas of super huge AI spending are data centers, salaries for experts, and VC investments. Meanwhile, the UAE is building one of the world’s largest AI data centers while Softbank CEO Masayoshi Son believes that Artificial General Intelligence (AGI) will surpass human-level cognitive abilities (Artificial General Intelligence or AGI) within a few years. And that Artificial Super Intelligence (ASI) will surpass human intelligence by a factor of 10,000 within the next 10 years.
AI Data Center Build-out Boom:
Tech industry’s giants are building AI data centers that can cost more than $100 billion and will consume more electricity than a million American homes. Meta, Microsoft, Amazon and Google have told investors that they expect to spend a combined $320 billion on infrastructure costs this year. Much of that will go toward building new data centers — more than twice what they spent two years ago.
As OpenAI and its partners build a roughly $60 billion data center complex for A.I. in Texas and another in the Middle East, Meta is erecting a facility in Louisiana that will be twice as large. Amazon is going even bigger with a new campus in Indiana. Amazon’s partner, the A.I. start-up Anthropic, says it could eventually use all 30 of the data centers on this 1,200-acre campus to train a single A.I system. Even if Anthropic’s progress stops, Amazon says that it will use those 30 data centers to deliver A.I. services to customers.

Amazon is building a data center complex in New Carlisle, Ind., for its work with the A.I. company Anthropic. Photo Credit…AJ Mast for The New York Times
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Stargate UAE:
OpenAI is partnering with United Arab Emirates firm G42 and others to build a huge artificial-intelligence data center in Abu Dhabi, UAE. The project, called Stargate UAE, is part of a broader push by the U.A.E. to become one of the world’s biggest funders of AI companies and infrastructure—and a hub for AI jobs. The Stargate project is led by G42, an AI firm controlled by Sheikh Tahnoon bin Zayed al Nahyan, the U.A.E. national-security adviser and brother of the president. As part of the deal, an enhanced version of ChatGPT would be available for free nationwide, OpenAI said.
The first 200-megawatt chunk of the data center is due to be completed by the end of 2026, while the remainder of the project hasn’t been finalized. The buildings’ construction will be funded by G42, and the data center will be operated by OpenAI and tech company Oracle, G42 said. Other partners include global tech investor, AI/GPU chip maker Nvidia and network-equipment company Cisco.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Softbank and ASI:
Not wanting to be left behind, SoftBank, led by CEO Masayoshi Son, has made massive investments in AI and has a bold vision for the future of AI development. Son has expressed a strong belief that Artificial Super Intelligence (ASI), surpassing human intelligence by a factor of 10,000, will emerge within the next 10 years. For example, Softbank has:
- Significant investments in OpenAI, with planned investments reaching approximately $33.2 billion. Son considers OpenAI a key partner in realizing their ASI vision.
- Acquired Ampere Computing (chip designer) for $6.5 billion to strengthen their AI computing capabilities.
- Invested in the Stargate Project alongside OpenAI, Oracle, and MGX. Stargate aims to build large AI-focused data centers in the U.S., with a planned investment of up to $500 billion.
Son predicts that AI will surpass human-level cognitive abilities (Artificial General Intelligence or AGI) within a few years. He then anticipates a much more advanced form of AI, ASI, to be 10,000 times smarter than humans within a decade. He believes this progress is driven by advancements in models like OpenAI’s o1, which can “think” for longer before responding.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Super High Salaries for AI Researchers:
Salaries for A.I. experts are going through the roof and reaching the stratosphere. OpenAI, Google DeepMind, Anthropic, Meta, and NVIDIA are paying over $300,000 in base salary, plus bonuses and stock options. Other companies like Netflix, Amazon, and Tesla are also heavily invested in AI and offer competitive compensation packages.
Meta has been offering compensation packages worth as much as $100 million per person. The owner of Facebook made more than 45 offers to researchers at OpenAI alone, according to a person familiar with these approaches. Meta’s CTO Andrew Bosworth implied that only a few people for very senior leadership roles may have been offered that kind of money, but clarified “the actual terms of the offer” wasn’t a “sign-on bonus. It’s all these different things.” Tech companies typically offer the biggest chunks of their pay to senior leaders in restricted stock unit (RSU) grants, dependent on either tenure or performance metrics. A four-year total pay package worth about $100 million for a very senior leader is not inconceivable for Meta. Most of Meta’s named officers, including Bosworth, have earned total compensation of between $20 million and nearly $24 million per year for years.
Meta CEO Mark Zuckerberg on Monday announced its new artificial intelligence organization, Meta Superintelligence Labs, to its employees, according to an internal post reviewed by The Information. The organization includes Meta’s existing AI teams, including its Fundamental AI Research lab, as well as “a new lab focused on developing the next generation of our models,” Zuckerberg said in the post. Scale AI CEO Alexandr Wang has joined Meta as its Chief AI Officer and will partner with former GitHub CEO Nat Friedman to lead the organization. Friedman will lead Meta’s work on AI products and applied research.
“I’m excited about the progress we have planned for Llama 4.1 and 4.2,” Zuckerberg said in the post. “In parallel, we’re going to start research on our next generation models to get to the frontier in the next year or so,” he added.
On Thursday, researcher Lucas Beyer confirmed he was leaving OpenAI to join Meta along with the two others who led OpenAI’s Zurich office. He tweeted: “1) yes, we will be joining Meta. 2) no, we did not get 100M sign-on, that’s fake news.” (Beyer politely declined to comment further on his new role to TechCrunch.) Beyer’s expertise is in computer vision AI. That aligns with what Meta is pursuing: entertainment AI, rather than productivity AI, Bosworth reportedly said in that meeting. Meta already has a stake in the ground in that area with its Quest VR headsets and its Ray-Ban and Oakley AI glasses.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
VC investments in AI are off the charts:
Venture capitalists are strongly increasing their AI spending. U.S. investment in A.I. companies rose to $65 billion in the first quarter, up 33% from the previous quarter and up 550% from the quarter before ChatGPT came out in 2022, according to data from PitchBook, which tracks the industry.
This astounding VC spending, critics argue, comes with a huge risk. A.I. is arguably more expensive than anything the tech industry has tried to build, and there is no guarantee it will live up to its potential. But the bigger risk, many executives believe, is not spending enough to keep pace with rivals.
“The thinking from the big C.E.O.s is that they can’t afford to be wrong by doing too little, but they can afford to be wrong by doing too much,” said Jordan Jacobs, a partner with the venture capital firm Radical Ventures. “Everyone is deeply afraid of being left behind,” said Chris V. Nicholson, an investor with the venture capital firm Page One Ventures who focuses on A.I. technologies.
Indeed, a significant driver of investment has been a fear of missing out on the next big thing, leading to VCs pouring billions into AI startups at “nosebleed valuations” without clear business models or immediate paths to profitability.
Conclusions:
Big tech companies and VCs acknowledge that they may be overestimating A.I.’s potential. Developing and implementing AI systems, especially large language models (LLMs), is incredibly expensive due to hardware (GPUs), software, and expertise requirements. One of the chief concerns is that revenue for many AI companies isn’t matching the pace of investment. Even major players like OpenAI reportedly face significant cash burn problems. But even if the technology falls short, many executives and investors believe, the investments they’re making now will be worth it.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
References:
https://www.nytimes.com/2025/06/27/technology/ai-spending-openai-amazon-meta.html
Meta is offering multimillion-dollar pay for AI researchers, but not $100M ‘signing bonuses’
https://www.theinformation.com/briefings/meta-announces-new-superintelligence-lab
OpenAI partners with G42 to build giant data center for Stargate UAE project
AI adoption to accelerate growth in the $215 billion Data Center market
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
Proposed solutions to high energy consumption of Generative AI LLMs: optimized hardware, new algorithms, green data centers
Google Cloud targets telco network functions, while AWS and Azure are in holding patterns
Overview:
Network operators have used public clouds for analytics and IT, including their business and operational support systems, but the vast majority have been reluctant to rely on hyper-scaler public clouds to host their network functions. However, there have been a few exceptions:
1. AWS counts Boost Mobile, Dish Network, Swisscom and Telefónica Germany as network operators running part of their 5G network in its public cloud. In a cloud-native 5G stand alone (SA) core network, the network functions are virtualized and run as software, rather than relying on dedicated hardware.
a] Dish Network is using Nokia’s cloud-native, 5G standalone core software which is deployed on the AWS public cloud. This includes software for subscriber data management, device management, packet core, voice and data core, and integration services. Dish invokes several AWS services, including Regions, Local Zones and Outposts, to host its 5G core network and related components.
b] Swisscom is migrating its core applications, including OSS/BSS and portions of its 5G core, to AWS according to Business Wire. This is part of a broader digital transformation strategy to modernize its infrastructure and services.
c] Telefónica Germany (O2 Telefónica) has moved its 5G core network to Amazon Web Services (AWS). This move, in collaboration with Nokia, makes them the first telecom company to switch an existing 5G core to a public cloud provider, specifically AWS. They launched their 5G cloud core, built entirely in the cloud, in July 2024, initially serving around one million subscribers.
2. Microsoft’s Azure cloud is running AT&T and the Middle East’s Etisalat 5G core network. AT&T is using Microsoft’s Azure Operator Nexus platform to run its 5G core network, including both standalone (SA) and non-standalone (NSA) deployments, according to AT&T and Microsoft. This move is part of a strategic partnership between the two companies where AT&T is shifting its 5G mobile network to the Microsoft cloud. However, AT&T’s 5G core network is not yet commercially available nationwide.
3. Ericsson has partnered with Google Cloud to offer 5G core as a service (5GCaaS) leveraging Google Cloud’s infrastructure. This allows operators to deploy and manage their 5G core network functions on Google’s cloud, rather than relying solely on traditional on-premises infrastructure. This Ericsson on-demand service recently launched with Google seems aimed mainly at smaller telcos, keen to avoid big upfront costs, or specific scenarios. To address much bigger needs, Google has an Outposts competitor it markets under the brand of Google Distributed Cloud (or GDC).
A serious concern with this Ericsson -Google offering is cloud provider lock-in, i.e. that a telco would not be able to move its 5GCaaS provided by Ericsson to an alternative cloud platform. Going “native,” in this case, meant building on top of Google-specific technologies, which rules out any prospect of a “lift and shift” to AWS, Microsoft or someone else, said Eric Parsons, Ericsson’s vice president of emerging segments in core networks, on a recent call with Light Reading.
……………………………………………………………………………………………………………………………………………………………………….
Google Cloud for Network Functions:
Angelo Libertucci, Google’s global head of telecom told Light Reading, the “timing is right” for a Google campaign that targets telco networks after years of sluggish industry progress. “The pressures that telcos are dealing with – the higher capex, lower ARPU [average revenue per user], competitiveness – it’s been a tough two years and there have been a number of layoffs, at least in North America,” he told Light Reading at last week’s Digital Transformation World event in Copenhagen.
“We run the largest private network on the planet,” said Libertucci. “We have over 2 million miles of fiber.” Services for more than a billion users are supported “with a fraction of the people that even the smallest regional telcos have, and that’s because everything we do is automated,” he claimed.
“There haven’t been that many network functions that run in the cloud – you can probably name them on less than four fingers,” he said. “So we don’t think we’ve really missed the boat yet on that one.” Indeed, most network functions are still deployed on telco premises (aka central offices).
Image Credit: Google Cloud Platform
Deutsche Telekom has partnered with Google earlier this year to build an agentic AI called RAN Guardian, which can assess network data, detect performance issues and even take corrective action without manual intervention. Built using Gemini 2.0 in Vertex AI from Google Cloud, the agent can analyze network behavior, detect performance issues, and implement corrective actions to improve network reliability, reduce operational costs, and enhance customer experiences. Deutsche Telekom keeps the network data at its own facilities but relies on interconnection to Google Cloud for the above listed functions.
“Do I then decide to keep it (network functions and data) on-prem and maintain that pre-processing pipeline that I have? Or is there a cost benefit to just run it in cloud, because then you have all the native integration? You don’t have any interconnect, you have all the data for any use case that you ever wanted or could think of. It’s much easier and much more seamless.” Such autonomous networking, in his view, is now the killer use case for the public cloud.
Yet many telco executives believe that public cloud facilities are incapable of handling certain network functions. European telcos including BT, Deutsche Telekom, Orange and Vodafone, have made investments in their own private cloud platforms for their telco workloads. Also, regulators in some countries may block operators from using public clouds. BT this year said local legislation now prevents it from using the public cloud for network functions. European authorities increasingly talk of the need for a “sovereign cloud” under the full control of local players.
Google does claim to have a set of “sovereign cloud” products that ensure data is stored in the country where the telco operates. “We have fully air-gapped sovereign cloud offerings with Google Cloud binaries that we’ve done in partnership with telcos for years now,” said Libertucci. The uncertainty is whether these will always meet the definition. “If sovereign means you can’t use an American-owned organization, then that’s another part of the definition that somehow we will have to find a way to address,” he added. “If you are cloud-native, it’s supposed to be easier to move to any cloud, but with telco it’s not that simple because it’s a very performance-oriented workload,” said Libertucci.
What’s likely, then, is that operators will assign whole regions to specific combinations of public cloud providers and telco vendors, he thinks, as they have done on the network side. “You see telcos awarding a region to Huawei and another to Ericsson with complete separation between them. They might choose to go down that route with network vendors as well and so you may have an Ericsson and Google part of the network.”
“We’re a platform company, we’re a data company and we’re an AI company,” said Libertucci. “I think we’re happy now with being a platform others develop on.”
………………………………………………………………………………………………………………………………………………………………………………….
Cloud RAN Disappoints:
Outside a trial with Ericsson almost two years ago, there is not much sign of Google activity in cloud RAN, the use of general-purpose chips and cloud platforms to support RAN workloads. “So far, no one’s really pushed us down into that area,” said Libertucci. AWS, by contrast, has this year begun to show off an Outposts server built around one of its own Graviton central processing units for cloud RAN. Currently, however, it does not appear to be supporting a cloud RAN deployment for any telco.
………………………………………………………………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/cloud/google-preps-public-cloud-charge-at-telecom-as-microsoft-wobbles
Deutsche Telekom and Google Cloud partner on “RAN Guardian” AI agent
Ericsson revamps its OSS/BSS with AI using Amazon Bedrock as a foundation
At this week’s TM Forum-organized Digital Transformation World (DTW) event in Copenhagen, Ericsson has given its operations support systems (BSS/OSS) portfolio a complete AI makeover. This BSS/OSS revamp aims to improve operational efficiency, boost business growth, and elevate customer experiences. It includes a Gen-AI Lab, where telcos can try out their latest BSS/OSS-related ideas; a Telco Agentic AI Studio, where developers are invited to come and build generative AI products for telcos; and a range of Ericsson’s own Telco IT AI apps. Underpinning all this is the Telco IT AI Engine, which handles various tasks to do with BSS/OSS orchestration.
Ericsson is investing to enable CSPs make a real impact with AI, intent and automation. AI is now embedded throughout the portfolio, and the other updates range across five critical, interlinked transformation areas within a CSP’s operational transformation, with each area of evolution based on a clear rationale and vision for the value it generates. Ericsson sites several benefits for telcos:
- Data – Make your data more useful. Introducing Telco DataOps Platform. An evolution from the existing Ericsson Mediation, the platform enables unified data collection, processing, management, and governance, removing silos and complexity to make data more useful across the whole business, and fuel effective AI to run their business and operations more smoothly.
- Cloud and IT – Stay ahead of the business. Introducing Ericsson Intelligent IT Suite. A holistic end-to-end approach supporting OSS/BSS evolution designed for Telco scale to accelerate delivery, streamline operations, and empower teams with the tools to unlock value from day one and beyond. It enables CSPs to embrace innovative transformative approaches that deliver real-time business agility and impact to stay ahead of business demands in rapidly evolving OSS/BSS landscapes.
- Monetization – Make sure you get paid. Introducing Ericsson Charging and Billing Evolved. A cloud-native monetization platform that enables real-time charging and billing for multi-sided business models. It is powered by cutting-edge AI capabilities that makes it easy to accelerate partner-led growth, launch and monetize enterprise services efficiently, and capture revenue across all business lines at scale.
- Service Orchestration – Deliver as fast as you can sell. Upgraded Ericsson Service Orchestration and Assurance with Agentic AI: Uses AI and intent to automatically set up and manage services based on a CSP’s business goals, providing a robust engine for transforming to autonomous networks. It empowers CSPs to cut out manual steps and provides the infrastructure to launch and scale differentiated connectivity services
- Core Commerce – Be easy to buy from. AI-enabled core commerce. Streamline selling with intelligent offer creation. Key capabilities include efficient offering design through a Gen-AI capable product configuration assistant and guided selling using an intelligent telco-specific CPQ for seamless ‘Quote to Cash’ processes, supported by a CRM-agnostic approach. CSPs can launch tailored enterprise solutions faster and co-create offers with partners all while delivering seamless omni-channel experiences
Grameenphone, a Bangladesh telco with more than 80 million subscribers is an Ericsson BSS/OSS customer. “They can’t do massive investments in areas that aren’t going to give a return,” said Jason Keane, the head of Ericsson’s business and operational support systems portfolio who noted the low average revenue per user (ARPU) in the Bangladeshi telecom market. The technologies developed by Ericsson are helping Grameenphone’s subscribers with top-ups, bill payments and operations issues.
“What they’re saying is we want to enable our customers to have a fast, seamless experience, where AI can help in some of the interaction flows between external systems. “AI itself isn’t free. You’ve got to pay your consumption, and it can add up if you don’t use it correctly.”
To date, very few companies have seen financial benefits in either higher sales or lower costs from AI. The ROI just isn’t there. If organizations end up spending more on AI systems than they would on manual effort to achieve the same results, money would be wasted. Another issue is the poor quality of telco data which can’t be effectively used to train AI agents.

Ericsson’ Booth at DTW Ignite 2025 event in Copenhagen
………………………………………………………………………………………………………………………………………………………..
Ericsson appears to have been heavily reliant on Amazon Web Services (AWS) for the technologies it is advertising at DTW this week. Amazon Bedrock, a managed service for building generative AI models, is the foundation of the Gen-AI Lab and the Telco Agentic AI Studio. “We had to pick one, right?” said Keane. “I picked Amazon. It’s a good provider, and this is the model I do my development against.”
Regarding AI’s threat to jobs of OSS/BSS workers, Light Reading’s Iain Morris, wrote:
“Wider adoption by telcos of Ericsson’s latest technologies, and similar offerings from rivals, might be a big negative for many telco operations employees. At most immediate risk are the junior technicians or programmers dealing with basic code that can be easily handled by AI. But the senior programmers had to start somewhere, and even they don’t look safe. AI enthusiasts dream of what the TM Forum calls the fully autonomous network, when people are out of the loop and the operation is run almost entirely by machines.”
Ericsson has realized its OSS and BSS tools need to address the requirements of network operators that either already, or will in the near future, adopt cloud-native processes, run cloud-based horizontal IT platforms and make extensive use of AI to automate back-office processes and introduce autonomous network operations that reduce manual intervention and the time to address problems while also introducing greater agility (as long as the right foundations are in place).
Mats Karlsson, Head of Solution Area Business and Operations Support Systems, Ericsson says: “What we are unveiling today illustrates a transformative step into industrializing Business and Operations Support Systems for the autonomous age. Using AI and automation, as well as our decades of knowledge and experience in our people, technology, processes – we get results. These changes will ensure we empower CSPs to unlock value precisely when and where it can be captured. We operate in a complex industry, one which is evidently in need of a focus on no nonsense OSS/BSS. These changes, and our commitment to continuous evolution for innovation, will help simplify it where possible, ensuring that CSPs can get on with their key goals of building better, more efficient services for their customers while securing existing revenue and striving for new revenue opportunities.”
Ahmad Latif Ali, Associate Vice President, EMEA Telecommunications Insights at IDC says: “Our recent research, featured in the IDC InfoBrief “Mapping the OSS/BSS Transformation Journey: Accelerate Innovation and Commercial Success,” highlights recurring challenges organizations faced in transformation initiatives, particularly the complex and often simultaneous evolution of systems, processes, and organizational structures. Ericsson’s continuous evolution of OSS/BSS addresses these key, interlinked transformation challenges head-on, paving the way for automation powered by advanced AI capabilities. This approach creates effective pathways to modernize OSS/BSS and supports meaningful progress across the transformation journey.”
References:
McKinsey: AI infrastructure opportunity for telcos? AI developments in the telecom sector
Telecom sessions at Nvidia’s 2025 AI developers GTC: March 17–21 in San Jose, CA
Quartet launches “Open Telecom AI Platform” with multiple AI layers and domains
Goldman Sachs: Big 3 China telecom operators are the biggest beneficiaries of China’s AI boom via DeepSeek models; China Mobile’s ‘AI+NETWORK’ strategy
Generative AI in telecom; ChatGPT as a manager? ChatGPT vs Google Search
Allied Market Research: Global AI in telecom market forecast to reach $38.8 by 2031 with CAGR of 41.4% (from 2022 to 2031)
The case for and against AI in telecommunications; record quarter for AI venture funding and M&A deals
SK Group and AWS to build Korea’s largest AI data center in Ulsan
Amazon Web Services (AWS) is partnering with the SK Group to build South Korea’s largest AI data center. The two companies are expected to launch the project later this month and will hold a groundbreaking ceremony for the 100MW facility in August, according to state news service Yonhap.
Scheduled to begin operations in 2027, the AI Zone will empower organizations in Korea to develop innovative AI applications locally while leveraging world-class AWS services like Amazon SageMaker, Bedrock, and Q. SK Group expects to bolster Korea’s AI competitiveness and establish the region as a key hub for hyperscale infrastructure in Asia-Pacific through AI initiatives.
AWS provides on-demand cloud computing platforms and application programming interfaces (APIs) to individuals, businesses and governments on a pay-per-use basis.The data center will be built on a 36,000-square-meter site in an industrial park in Ulsan, 305 km southeast of Seoul. It will be powered by 60,000 GPUs, making it the country’s first large-scale AI data center.
The facility will be located in the Mipo industrial complex in Ulsan, 305 kilometers southeast of Seoul. It will house 60,000 graphics processing units (GPUs) and have a power capacity of 100 megawatts, making it the country’s first AI infrastructure of such scale, the sources said.
Ryu Young-sang, chief executive officer (CEO) of SK Telecom Co., had announced the company’s plan to build a hyperscale AI data center equipped with 60,000 GPUs in collaboration with a global tech partner, during the Mobile World Congress (MWC) 2025 held in Spain in March.
SK Telecom plans to invest 3.4 trillion won (US$2.49 billion) in AI infrastructure by 2028, with a significant portion expected to be allocated to the data center project. SK Telecom- South Korea’s biggest mobile operator and 31% owned by the SK Group – will manage the project. “They have been working on the project, but the exact timeline and other details have yet to be finalized,” an SK Group spokesperson said.
The AI data center will be developed in two phases, with the initial 40MW phase to be completed by November 2027 and the full 100MW capacity to be operational by February 2029, the Korea Herald reported Monday. Once completed, the facility, powered by 60,000 graphics processing units, will have a power capacity of 103 megawatts, making it the country’s largest AI infrastructure, sources said.
SK Group appears to have chosen Ulsan as the site, considering its proximity to SK Gas’ liquefied natural gas combined heat and power plant, ensuring a stable supply of large-scale electricity essential for data center operations. The facility is also capable of utilizing LNG cold energy for data center cooling.
SKT last month released its revised AI pyramid strategy, targeting AI infrastructure including data centers, GPUaaS and customized data centers. It is also developing personal agents A. and Aster for consumers and AIX services for enterprise customers.
Globally, it has found partners through the Global Telecom Alliance, which it co-founded, and is collaborating with US firms Anthropic and Lambda.
SKT’s AI business unit is still small, however, recording just KRW156 billion ($115 million) in revenue in Q1, two-thirds of it from data center infrastructure. Its parent SK Group, which also includes memory chip giant SK Hynix and energy firm SK Innovation, reported $88 billion in revenue last year.
AWS, the world’s largest cloud services provider, has been expanding its footprint in Korea. It currently runs a data center in Seoul and began constructing its second facility in Incheon’s Seo District in late 2023. The company has pledged to invest 7.85 trillion won in Korea’s cloud computing infrastructure by 2027.
“When SK Group’s exceptional technical capabilities combine with AWS’s comprehensive AI cloud services, we’ll empower customers of all sizes, and across all industries here in Korea to build and innovate with safe, secure AI technologies,” said Prasad Kalyanaraman, VP of Infrastructure Services at AWS. “This partnership represents our commitment to Korea’s AI future, and I couldn’t be more excited about what we’ll achieve together.”
Earlier this month AWS launched its Taiwan cloud region – its 15th in Asia-Pacific – with plans to invest $5 billion on local cloud and AI infrastructure.
References:
https://en.yna.co.kr/view/AEN20250616004500320?section=k-biz/corporate
https://www.koreaherald.com/article/10510141
https://www.lightreading.com/data-centers/aws-sk-group-to-build-korea-s-largest-ai-data-center
Does AI change the business case for cloud networking?
For several years now, the big cloud service providers – Amazon Web Services (AWS), Microsoft Azure, and Google Cloud – have tried to get wireless network operators to run their 5G SA core network, edge computing and various distributed applications on their cloud platforms. For example, Amazon’s AWS public cloud, Microsoft’s Azure for Operators, and Google’s Anthos for Telecom were intended to get network operators to run their core network functions into a hyperscaler cloud.
AWS had early success with Dish Network’s 5G SA core network which has all its functions running in Amazon’s cloud with fully automated network deployment and operations.
Conversely, AT&T has yet to commercially deploy its 5G SA Core network on the Microsoft Azure public cloud. Also, users on AT&T’s network have experienced difficulties accessing Microsoft 365 and Azure services. Those incidents were often traced to changes within the network’s managed environment. As a result, Microsoft has drastically reduced its early telecom ambitions.
Several pundits now say that AI will significantly strengthen the business case for cloud networking by enabling more efficient resource management, advanced predictive analytics, improved security, and automation, ultimately leading to cost savings, better performance, and faster innovation for businesses utilizing cloud infrastructure.
“AI is already a significant traffic driver, and AI traffic growth is accelerating,” wrote analyst Brian Washburn in a market research report for Omdia (owned by Informa). “As AI traffic adds to and substitutes conventional applications, conventional traffic year-over-year growth slows. Omdia forecasts that in 2026–30, global conventional (non-AI) traffic will be about 18% CAGR [compound annual growth rate].”
Omdia forecasts 2031 as “the crossover point where global AI network traffic exceeds conventional traffic.”
Markets & Markets forecasts the global cloud AI market (which includes cloud AI networking) will grow at a CAGR of 32.4% from 2024 to 2029.
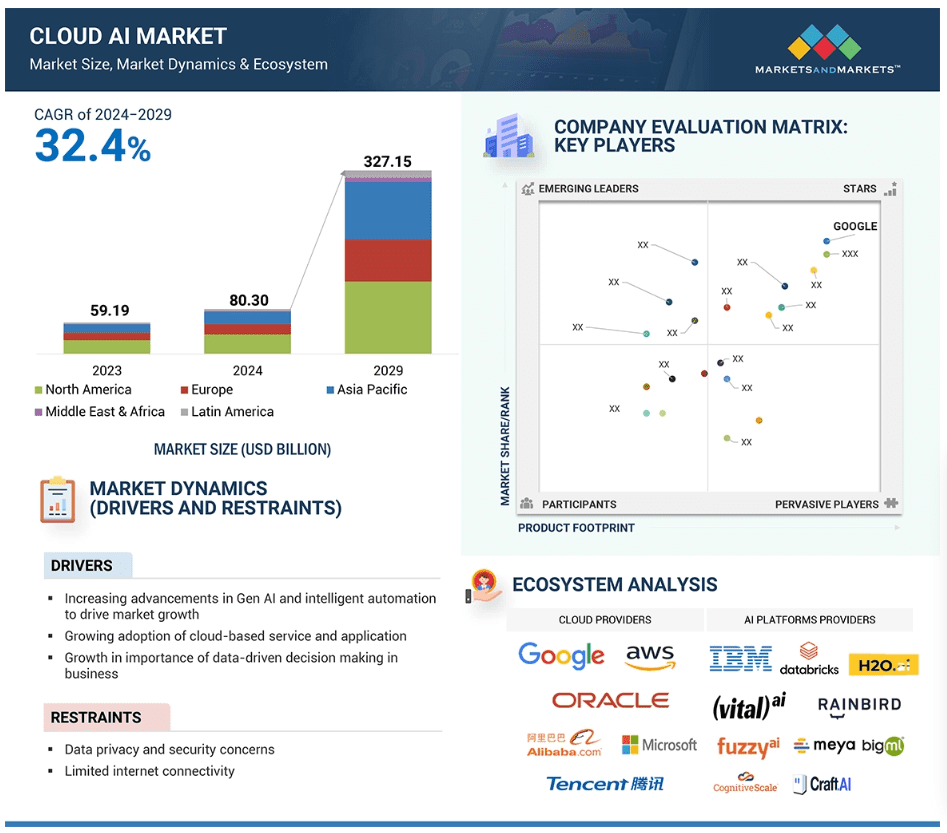
AI is said to enhance cloud networking in these ways:
- Optimized resource allocation:
AI algorithms can analyze real-time data to dynamically adjust cloud resources like compute power and storage based on demand, minimizing unnecessary costs. - Predictive maintenance:
By analyzing network patterns, AI can identify potential issues before they occur, allowing for proactive maintenance and preventing downtime. - Enhanced security:
AI can detect and respond to cyber threats in real-time through anomaly detection and behavioral analysis, improving overall network security. - Intelligent routing:
AI can optimize network traffic flow by dynamically routing data packets to the most efficient paths, improving network performance. - Automated network management:
AI can automate routine network management tasks, freeing up IT staff to focus on more strategic initiatives.
The pitch is that AI will enable businesses to leverage the full potential of cloud networking by providing a more intelligent, adaptable, and cost-effective solution. Well, that remains to be seen. Google’s new global industry lead for telecom, Angelo Libertucci, told Light Reading:
“Now enter AI,” he continued. “With AI … I really have a power to do some amazing things, like enrich customer experiences, automate my network, feed the network data into my customer experience virtual agents. There’s a lot I can do with AI. It changes the business case that we’ve been running.”
“Before AI, the business case was maybe based on certain criteria. With AI, it changes the criteria. And it helps accelerate that move [to the cloud and to the edge],” he explained. “So, I think that work is ongoing, and with AI it’ll actually be accelerated. But we still have work to do with both the carriers and, especially, the network equipment manufacturers.”
Google Cloud last week announced several new AI-focused agreements with companies such as Amdocs, Bell Canada, Deutsche Telekom, Telus and Vodafone Italy.
As IEEE Techblog reported here last week, Deutsche Telekom is using Google Cloud’s Gemini 2.0 in Vertex AI to develop a network AI agent called RAN Guardian. That AI agent can “analyze network behavior, detect performance issues, and implement corrective actions to improve network reliability and customer experience,” according to the companies.
And, of course, there’s all the buzz over AI RAN and we plan to cover expected MWC 2025 announcements in that space next week.
https://www.lightreading.com/cloud/google-cloud-doubles-down-on-mwc
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
The case for and against AI-RAN technology using Nvidia or AMD GPUs
Generative AI in telecom; ChatGPT as a manager? ChatGPT vs Google Search
