

Ookla: AI platform reliability decreases as outages surge
So you thought “AI Hallucinations” were the only big problem with AI performance? Think again! In a new Ookla reliability report, data from its Downdetector reveals that AI platform outages surged from 6 high-disruption days in Q1 2025 to 51 in Q1 2026 , as AI tools transitioned from novelties to critical business infrastructure. These disruptions stem from rapid scale-up volatility, cloud provider failures, and complex, agentic workflows. Analysing 471 days of US Downdetector data from 1 January 2025 to 16 April 2026 across ChatGPT, Claude, Gemini, Microsoft Copilot, AWS and Microsoft Azure, Ookla recorded 3.7 million user-reported problems.
High-signal disruption days, defined as when a service recorded more than 10 times its own median daily report volume, rose from six across four major AI apps in Q1 2025 to 51 in Q1 2026, according to the report by Ookla analyst Luke Kehoe.

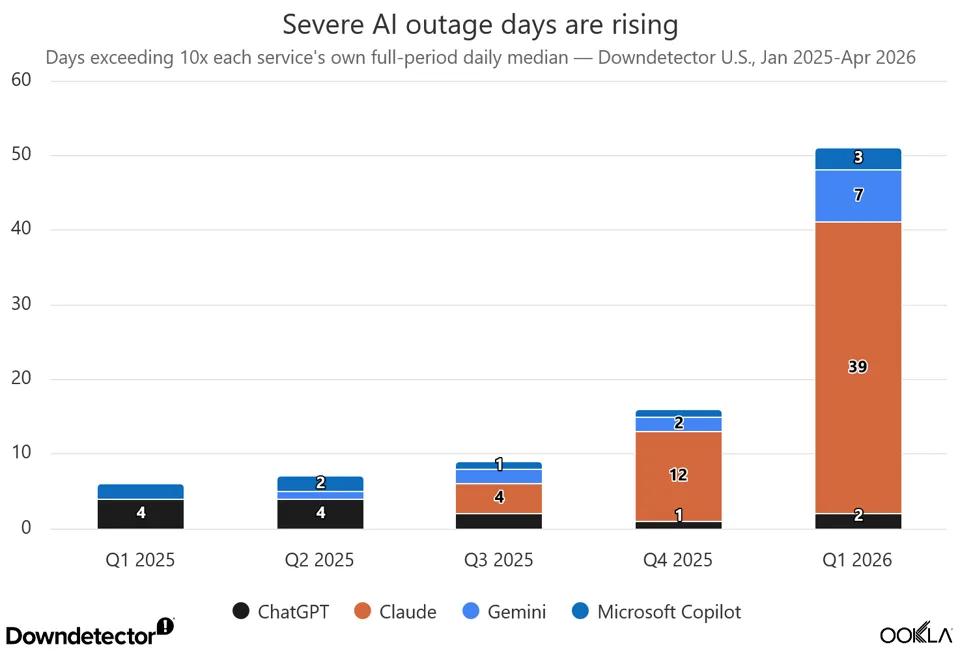
Anthropic’s Claude model accounted for 39 of those 51 disruption days. Gemini accounted for seven, Copilot three and ChatGPT two. Here’s a summary:
- Claude: Anthropic’s platform was the clearest example of scale-up volatility, accounting for 39 of the 51 high-signal disruption days in early 2026 due to rapid adoption and scaling.
- ChatGPT: While it generated some of the largest raw disruption spikes—often linked to model updates or demand surges—its median daily report trend improved compared to the prior year.
- Microsoft Copilot: Outage reports heavily clustered on weekdays, reflecting its core integration into enterprise business workflows rather than consumer use.
- Gemini: Incidents rose to seven alongside expanding user adoption.
- Cloud Infrastructure: A significant portion of AI downtime wasn’t the AI model itself, but outages at the cloud level that caused cascading failures. AWS’s 20 October 2025 DynamoDB DNS event generated more than 315,000 US disruption reports, while Microsoft’s Azure Front Door incident on 29 October produced nearly 96,000, illustrating how failures in cloud control planes can cascade into AI platform disruptions.
Claude’s growth over the past 12 months was accompanied by significant disruption. Ookla describes it as “the clearest example of scale-up volatility,” with disruptions to its offering starting to move the needle in July last year as adoption rose. There’s a hint that the upward trajectory will continue – Ookla notes that at 2,830 daily reports on average, Claude’s report volume in March was three times that it recorded in February.
AI reliability now spans multiple failure layers:
AI platforms are not single systems from the user’s point of view, even when they present a single interface. A ChatGPT, Claude, Gemini, or Copilot failure can sit in the product layer, the provider orchestration layer, the hyperscaler layer, or the edge and access layer. The product layer is what users actually see. The provider orchestration layer includes login, routing, model selection, rate limits, feature flags, inference scheduling, retry behavior, and capacity allocation. The hyperscaler layer includes compute, databases, storage, networking, and regional control planes. The edge and access layer includes DNS, web gateways, bot protection, content delivery, and authentication flows.
Ookla’s Kehoe wrote, “As AI systems move from short chat sessions into longer-running agentic tasks, a failed prompt, login loop, stalled code task, unavailable file, or broken connector can interrupt work that now sits inside real business processes.” This is a very serious concern!

Those layers are not always owned by different companies, and they are not the full physical internet stack. Network operators, subsea cables, data centers, and user access networks still matter. The focus here is narrower: the service and dependency layers that are most visible in Downdetector data and public incident records.
This distinction is important because the same user-facing symptom can have different operational meanings. A failed prompt, login loop, missing chat history, rate-limit error, unavailable file, or stalled agent task may not share the same root cause. For enterprise buyers and risk teams, resilience is about understanding more than whether an AI platform was simply available. They need to know where the issue occurred, which workflows were affected, and whether it reflected a problem with a single provider or a broader dependency across the AI stack.
…………………………………………………………………………………………………………………………………………
References:
https://www.ookla.com/articles/ai-platform-reliability
https://www.mobileworldlive.com/ai-cloud/ookla-finds-ai-platform-outages-surge-as-adoption-grows
https://www.telecoms.com/ai/ai-app-disruption-is-on-the-up
Will 2026 be the “Year of the AI Ontology” for telecoms?
