

DriveNets
DriveNets and Ciena Complete Joint Testing of 400G ZR/ZR+ optics for Network Cloud Platform
DriveNets and Ciena have
The successful tests demonstrate how the integrated solution optimizes service provider networks and builds more efficient converged infrastructures. The solution also includes enhanced network configuration and management software capabilities and ensures the Ciena WaveLogic 5 Nano (WL5n) pluggables can be tuned, configured, and managed by DriveNets Network Cloud software.
This solution will be on display at OFC Conference, March 26-28 in San Diego, CA, as part of the University of Texas in Dallas (UTC) – OpenLab OFCnet demonstration.
![]()
Last year, DriveNets announced that Network Cloud was the first Disaggregated Distributed Chassis/Backbone Router (DDC/DDBR) to support ZR/ZR+ optics as native transceivers for Network Cloud-supported white boxes. Today’s announcement demonstrates that two market leaders and innovators are working together to offer a fully tested and validated solution that advances and expands the adoption of open, disaggregated networking solutions.
Efficient Converged Infrastructure:
“Today’s announcement is another step in the growing adoption of disaggregated networking solutions, supporting operators’ desire to lower their operational costs by simplifying the network architecture and building networks like cloud,” said Dudy Cohen, Vice President of Product Marketing at DriveNets. “Operators are looking for open solutions that allow them to mix and match elements from multiple vendors as well as reduce the number of networks they need to support. The converged IP/Optical solution enabled by this announcement delivers on both goals.”
“As a leading provider of both optical networks and coherent optical modules, Ciena continues to innovate and give our customers greater choice in how they create open and robust networks, without compromise,” said Joe Shapiro, Vice President, Product Line Management, Ciena. “The combined solution – a converged IP/Optical white box – can achieve longer unregenerated reaches while also being simple to manage, resulting in improved cost and operational efficiencies.”
Simplifying the network by collapsing network layers:
The integrated solution delivers significant cost savings by collapsing Layer-1 to Layer-3 communications into a single platform. The use of ZR/ZR+ also eliminates the need for standalone optical transponders, lowering the number of boxes in the solution and reducing operational overhead, floorspace, and power requirements.
This collaboration ensures that the DriveNets NOS (DNOS) supports the WL5n coherent pluggable transceivers beyond simply plugging them into the box. It will support multiple modes of operation, including 400ZR, ZR+, as well as higher performance modes to extend 400G connectivity across more links in the network. The combined solution was tested across a Ciena open line system, representing a real networking environment.
This integration goes beyond interoperability validation. DriveNets Network Cloud will offer software support for Ciena’s optical solution, including configuration (channel and power), monitoring and troubleshooting for Ciena transceivers.
Future planned enhancements involve standards-based integration with Ciena’s end-to-end intelligent network control system – the Ciena Navigator Network Control Suite (NCS) – for better visibility and optimization of the optical infrastructure.
About DriveNets:
DriveNets is a leader in high-scale disaggregated networking solutions. Founded in 2015, DriveNets modernizes the way service providers, cloud providers and hyperscalers build networks, streamlining network operations, increasing network performance at scale, and improving their economic model. DriveNets’ solutions – Network Cloud and Network Cloud-AI – adapt the architectural model of hyperscale cloud to telco-grade networking and support any network use case – from core-to-edge to AI networking – over a shared physical infrastructure of standard white-boxes, radically simplifying the network’s operations and offering telco-scale performance and reliability with hyperscale elasticity. DriveNets’ solutions are currently deployed in the world’s largest networks. Learn more at www.drivenets.com
References:
KDDI Deploys DriveNets Network Cloud: The 1st Disaggregated, Cloud-Native IP Infrastructure Deployed in Japan
IEEE/SCU SoE May 1st Virtual Panel Session: Open Source vs Proprietary Software Running on Disaggregated Hardware
DriveNets raises $262M to expand its cloud-based alternative to core network routers
AT&T Deploys Dis-Aggregated Core Router White Box with DriveNets Network Cloud software
DriveNets Network Cloud: Fully disaggregated software solution that runs on white boxes
KDDI Deploys DriveNets Network Cloud: The 1st Disaggregated, Cloud-Native IP Infrastructure Deployed in Japan
Israel based DriveNets announced today that Japanese telecommunications provider KDDI Corporation has successfully deployed DriveNets Network Cloud as its internet gateway peering router. DriveNets Network Cloud provides carrier-grade peering router connectivity across the KDDI network, enabling KDDI to scale its network and services quickly, while significantly reducing hardware requirements, lowering costs, and accelerating innovation. Additional applications will be deployed on DriveNets Network Cloud in the future.
“KDDI prides itself on deploying the most advanced and innovative technology solutions that allow us to anticipate and respond to the ever-changing usage trends, while providing considerable value to our customers,” said Kenji Kumaki, Ph.D. General Manager and Chief Architect, Technology Strategy & Planning, KDDI Corporation. “DriveNets Network Cloud enables us to quickly scale our network as needed, while controlling our costs effectively.”
“While many of Japan’s service providers have been aggressively pursuing the virtualization of network functions on their 4G and 5G networks, disaggregation of software and hardware in service providers’ routing infrastructure is just getting started,” said Ido Susan, DriveNets’ co-founder and CEO. “I am extremely proud that our Network Cloud solution was selected by KDDI, a leading innovative service provider, and is already deployed in their network, supporting the needs of KDDI‘s customers.”
![]()
The deployment of DriveNets Network Cloud on the KDDI network is the culmination of several years of testing and verification in KDDI‘s labs. It also reflects the growing adoption of disaggregated network architectures in service provider networks around the world.
“The move to disaggregated networking solutions will continue to be a prevailing trend in 2023 and beyond as savvy service providers try new technologies that can enable them to innovate faster and reduce costs. We are now seeing this technology also adopted in other high-scale networking environments, such as AI infrastructures,” said Susan.
DriveNets Run Almog wrote in an email, “KDDI is using white box devices from Delta. These are the “same” OCP compliant NCP devices which are deployed at AT&T (UFISpace in the AT&T case). they are using it as a peering router (vs. AT&T’s core use case). so this announcement is public indicative to several things: a 2nd Tier #1, another use case, and another ODM vendor, all in commercial deployments with our network cloud.”
DriveNets Inbar Lasser-Raab wrote in an email, “Getting a tier-1 SP to announce is very hard. They are cautious and our solution needs to be working and validated for some time before they are willing to talk about it. We are working on our next PR, but you never know when we’ll get the OK to release” ![]()
Compared to traditional routers that are comprised of software, hardware and chips from a single vendor, a DDBR solution combines software and equipment from multiple vendors, allowing service providers to break vendor lock and move to a new model that enables greater vendor choice and faster scale and introduction of new services through modern cloud design.
In addition to KDDI, DriveNets is already working with other service providers in Asia Pacific to meet the growing interest in its disaggregated networking solutions in the region. In mid-2021, the company established a Tokyo-based subsidiary to enhance its presence in the region.
DriveNets offers an architectural model similar to that of cloud hyperscalers, leading to better network economics and faster innovation. DriveNets Network Cloud includes an open ecosystem with elements from leading silicon vendors and original design manufacturers (ODMs), certified by DriveNets and empowered by our partners, which ensure the seamless integration of the solutions into providers’ networks.
About DriveNets:
DriveNets is a leader in cloud-native networking software and network disaggregation solutions. Founded at the end of 2015 and based in Israel, DriveNets transforms the way service and cloud providers build networks. DriveNets’ solution – Network Cloud – adapts the architectural and economic models of cloud to telco-grade networking. Network Cloud is a cloud-native software that runs over a shared physical infrastructure of white-boxes, radically simplifying the network’s operations, increasing network scale and elasticity and accelerating service innovation. DriveNets continues to deploy its Network Cloud with Tier 1 operators worldwide (like AT&T) and has raised more than $587 million in three funding rounds.
About KDDI:
KDDI is telecommunication service provider in Japan, offering 5G and IoT services to a multitude of individual and corporate customers within and outside Japan through its “au”, “UQ mobile” and “povo” brands. In the Mid-Term Management Strategy (FY23.3–FY25.3), KDDI is promoting the Satellite Growth Strategy to strengthen the 5G-driven evolution of its telecommunications business and the expansion of focus areas centered around telecommunications.
Specifically, KDDI is especially focusing on following five areas: DX (digital transformation), Finance, Energy, LX (life transformation) and Regional Co-Creation. In particular, to promote DX, KDDI is assisting corporate customers in bringing telecommunication into everything through IoT to organize an environment in which customers can enjoy using 5G without being aware of its presence, and in providing business platforms that meet industry-specific needs to support customers in creating businesses.
In addition, KDDI places “sustainability management” that aims to achieve the sustainable growth of society and the enhancement of corporate value together with our partners at the core of the Mid-Term Management Strategy. By harnessing the characteristics of 5G in order to bring about an evolution of the power to connect, KDDI is working toward an era of the creation of new value.
References:
https://drivenets.com/products/
IEEE/SCU SoE May 1st Virtual Panel Session: Open Source vs Proprietary Software Running on Disaggregated Hardware
DriveNets raises $262M to expand its cloud-based alternative to core network routers
AT&T Deploys Dis-Aggregated Core Router White Box with DriveNets Network Cloud software
DriveNets Network Cloud: Fully disaggregated software solution that runs on white boxes
KDDI claims world’s first 5G Standalone (SA) Open RAN site using Samsung vRAN and Fujitsu radio units
IEEE/SCU SoE May 1st Virtual Panel Session: Open Source vs Proprietary Software Running on Disaggregated Hardware
Complete Event Description at:
https://scv.chapters.comsoc.org/event/open-source-vs-proprietary-software-running-on-disaggregated-hardware/
The video recording is now publicly available:
https://www.youtube.com/watch?v=RWS39lyvCPI
……………………………………………………………………………………………………………………………………………….
Backgrounder – Open Networking vs. Open Source Network Software
Open Networking was promised to be a new paradigm for the telecom, cloud and enterprise networking industries when it was introduced in 2011 by the Open Networking Foundation (ONF). This “new epoch” in networking was based on Software Defined Networking (SDN), which dictated a strict separation of the Control and Data planes with OpenFlow as the API/protocol between them. A SDN controller running on a compute server was responsible for hierarchical routing within a given physical network domain, with “packet forwarding engines” replacing hop by hop IP routers in the wide area network. Virtual networks via an overlay model were not permitted and were referred to as “SDN Washing” by Guru Parulkar, who ran the Open Networking Summit’s for many years.
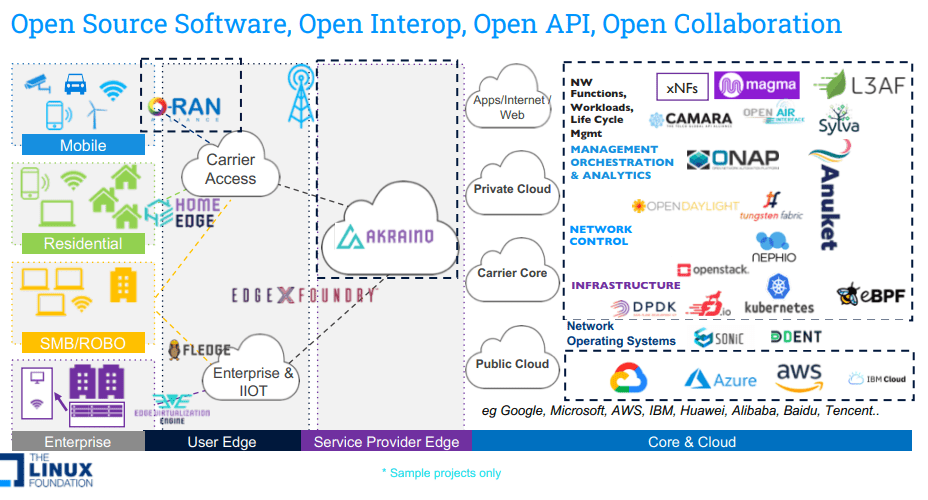
Today, the term Open Networking encompasses three important vectors:
A) Beyond the disaggregation of hardware and software, it also includes: Open Source Software, Open API, Open Interoperability, Open Governance and Open collaboration across global organizations that focus on standards, specification and Open Source software.
B) Beyond the original Data/Control plane definition, today Open Networking covers entire software stack (Data plane, control plane, management, orchestration and applications).
C) Beyond just the Data Center use case, it currently covers all networking markets (Service Provider, Enterprise and Cloud) and also includes all aspects of architecture (from Core to Edge to Access – residential and enterprise).
Open Source Networking Software refers to any network related program whose source code is made available for use or modification by users or other developers. Unlike proprietary software, open source software is computer software that is developed as a public, open collaboration and made freely available to the public. There are several organizations that develop open source networking software, such as the Linux Foundation, ONF, OCP, and TIP.
Currently, it seems the most important open networking and open source network software projects are being developed in the Linux Foundation (LF) Networking activity. Now in its fifth year as an umbrella organization, LF Networking software and projects provide the foundations for network infrastructure and services across service providers, cloud providers, enterprises, vendors, and system integrators that enable rapid interoperability, deployment and adoption.
Event Description:
In this virtual panel session, our distinguished panelists will discuss the current state and future directions of open networking and open source network software. Most importantly, we will compare open source vs. proprietary software running on disaggregated hardware (white box compute servers and/or bare metal switches).
With so many consortiums producing so much open source code, the open source networking community is considered by many to be a trailblazer in terms of creating new features, architectures and functions. Others disagree, maintaining that only the large cloud service providers/hyperscalers (Amazon, Microsoft, Google, Facebook) are using open source software, but it’s their own versions (e.g. Microsoft SONIC which they contributed to the OCP).
We will compare and contrast open source vs proprietary networking software running on disaggregated hardware and debate whether open networking has lived up to its potential.
Panelists:
- Roy Chua, AvidThink
- Arpit Joshipura, LF Networking
- Run Almog, DriveNets
Moderator: Alan J Weissberger, IEEE Techblog, SCU SoE
Host: Prof. Ahmed Amer, SCU SoE

Co-Sponsor: Ashutosh Dutta, IEEE Future Networks
Co-Sponsor: IEEE Communications Society-SCV
Agenda:
- Opening remarks by Moderator and IEEE Future Networks – 8 to 10 minutes
- Panelist’s Position Presentations – 55 minutes
- Pre-determined issues/questions for the 3 panelists to discuss and debate -30 minutes
- Issues/questions that arise from the presentations/discussion-from Moderator & Host -8 to 10 minutes
- Audience Q &A via ZOOM Chat box or Question box (TBD) -15 minutes
- Wrap-up and Thanks (Moderator) – 2 minutes
Panelist Position Statements:
1. Roy will examine the open networking landscape, tracing its roots back to the emergence of Software Defined Networking (SDN) in 2011. He will offer some historical context while discussing the main achievements and challenges faced by open networking over the years, as well as the factors that contributed to these outcomes. Also covered will be the development of open networking and open-source networking, touching on essential topics such as white box switching, disaggregation, OpenFlow, P4, and the related Network Function Virtualization (NFV) movement.
Roy will also provide insight into the ongoing importance of open networking and open-source networking in a dynamic market shaped by 5G, distributed clouds and edge computing, private wireless, fiber build-outs, satellite launches, and subsea-cable installations. Finally, Roy will explore how open networking aims to address the rising demand for greater bandwidth, improved control, and strengthened security across various environments, including data centers, transport networks, mobile networks, campuses, branches, and homes.
2. Arpit will cover the state of open source networking software, specifications, and related standards. He will describe how far we have come in the last few years exemplified by a few success stories. While the emphasis will be on the Linux Foundation projects, relevant networking activity from other open source consortiums (e.g. ONS, OCP, TIP, and O-RAN) will also be noted. Key challenges for 2023 will be identified, including all the markets of telecom, cloud computing, and enterprise networking.
3. Run will provide an overview of Israel based DriveNets “network cloud” software and cover the path DriveNets took before deciding on a Distributed Disaggregated Chassis (DDC) architecture for its proprietary software. He will describe the reasoning behind the major turns DriveNets took during this long and winding road. It will be a real life example with an emphasis on what didn’t work as well as what did.
……………………………………………………………………………………………………………….
References:
https://lfnetworking.org/
https://lfnetworking.org/how-
https://lfnetworking.org/
https://lfnetworking.org/open-
Using a distributed synchronized fabric for parallel computing workloads- Part II
by Run Almog Head of Product Strategy, Drivenets (edited by Alan J Weissberger)
Introduction:
In the previous part I article, we covered the different attributes of AI/HPC workloads and the impact this has on requirements from the network that serves these applications. This concluding part II article will focus on an open standard solution that addresses these needs and enables these mega sized applications to run larger workloads without compromising on network attributes. Various solutions are described and contrasted along with a perspective from silicon vendors.
Networking for HPC/AI:
A networking solution serving HPC/AI workloads will need to carry certain attributes. Starting with scale of the network which can reach thousands of high speed endpoints and having all these endpoints run the same application in a synchronized manner. This requires the network to run like a scheduled fabric that offers full bandwidth between any group of endpoints at any given time.
Distributed Disaggregated Chassis (DDC):
DDC is an architecture that was originally defined by AT&T and contributed to the Open Compute Project (OCP) as an open architecture in September 2019. DDC defines the components and internal connectivity of a network element that is purposed to serve as a carrier grade network router. As opposed to the monolithic chassis-based router, the DDC defines every component of the router as a standalone device.
- The line card of the chassis is defined as a distributed chassis packet-forwarder (DCP)
- The fabric card of the chassis is defined as a distributed chassis fabric (DCF)
- The routing stack of the chassis is defined as a distributed chassis controller (DCC)
- The management card of the chassis is defined as a distributed chassis manager (DCM)
- All devices are physically connected to the DCM via standard 10GbE interfaces to establish a control and a management plane.
- All DCP are connected to all DCF via 400G fabric interfaces in a Clos-3 topology to establish a scheduled and non-blocking data plane between all network ports in the DDC.
- DCP hosts both fabric ports for connecting to DCF and network ports for connecting to other network devices using standard Ethernet/IP protocols while DCF does not host any network ports.
- The DCC is in fact a server and is used to run the main base operating system (BaseOS) that defines the functionality of the DDC
Advantages of the DDC are the following:
- It’s capacity since there is no metal chassis enclosure that needs to hold all these components into a single machine. This allows building a wider Clos-3 topology that expands beyond the boundaries of a single rack making it possible for thousands of interfaces to coexist on the same network element (router).
- It is an open standard definition which makes it possible for multiple vendors to implement the components and as a result, making it easier for the operator (Telco) to establish a multi-source procurement methodology and stay in control of price and supply chain within his network as it evolves.
- It is a distributed array of components that each has an ability to exist as a standalone as well as act as part of the DDC. This gives a very high level of resiliency to services running over a DDC based router vs. services running over a chassis-based router.
AT&T announced they use DDC clusters to run their core MPLS in a DriveNets based implementation and as standalone edge and peering IP networks while other operators worldwide are also using DDC for such functionality.
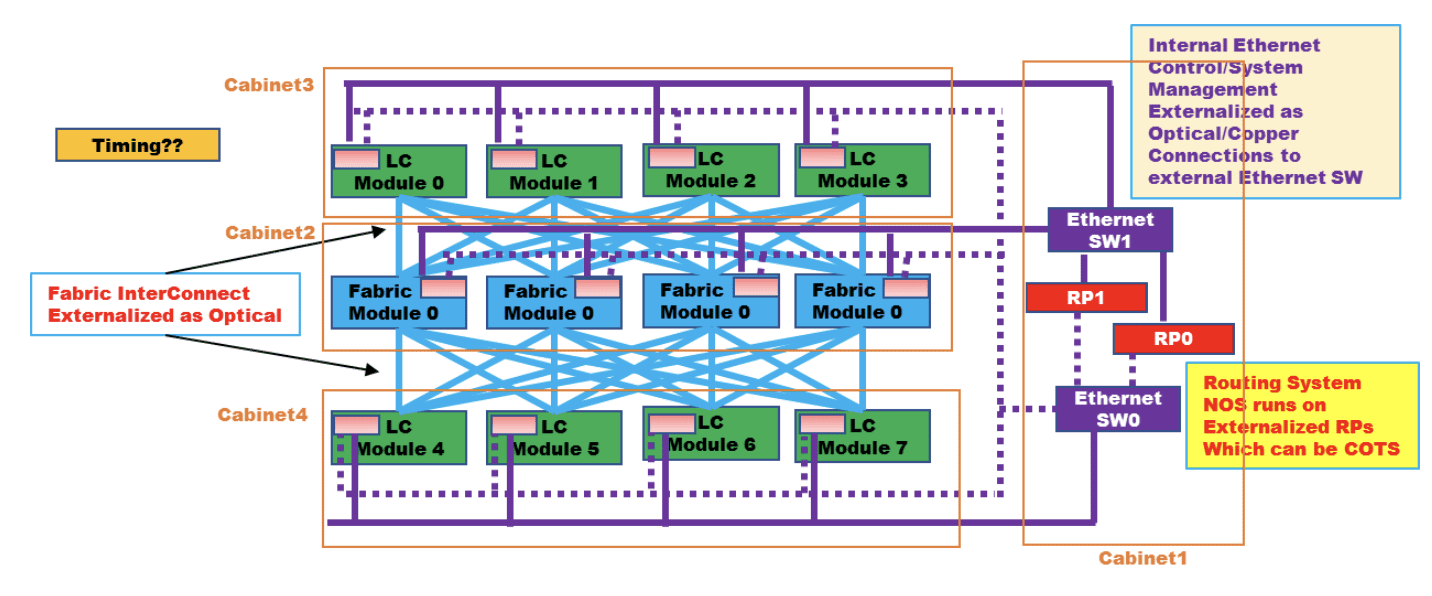
Figure 1: High level connectivity structure of a DDC
……………………………………………………………………………………………………………………………………………………..
LC is defined as DCP above, Fabric module is defined as DCF above, RP is defined as DCC above, Ethernet SW is defined as DCM above
Source: OCP DDC specification
DDC is implementing a concept of disaggregation. The decoupling of the control plane from data plane enables the sourcing of the software and hardware from different vendors and assembling them back into a unified network element when deployed. This concept is rather new but still has had a lot of successful deployments prior to it being used as part of DDC.
Disaggregation in Data Centers:
The implementation of a detached data plane from the control plane had major adoption in data center networks in recent years. Sourcing the software (control plane) from one vendor while the hardware (data plane) is sourced from a different vendor mandate that the interfaces between the software and hardware be very precise and well defined. This has brought up a few components which were developed by certain vendors and contributed to the community to allow for the concept of disaggregation to go beyond the boundaries of implementation in specific customers networks.
Such components include open network install environment (ONIE) which enables mounting of the software image onto a platform (typically a single chip 1RU/2RU device) as well as the switch abstraction interface (SAI) which enable the software to directly access the application specific integrated circuit (ASIC) and operate directly onto the data plane at line rate speeds.
Two examples of implementing disaggregation networking in data centers are:
- Microsoft which developed their network operating system (NOS) software Sonic as one that runs on SAI and later contributed its source code to the networking community via OCP and he Linux foundation.
- Meta has defined devices called “wedge” who are purpose built to assume various NOS versions via standard interfaces.
These two examples of hyperscale companies are indicative to the required engineering effort to develop such interfaces and functions. The fact that such components have been made open is what enabled other smaller consumers to enjoy the benefits of disaggregation without the need to cater for large engineering groups.
The data center networking world today has a healthy ecosystem with hardware (ASIC and system) vendors as well as software (NOS and tools) which make a valid and widely used alternative to the traditional monolithic model of vertically integrated systems.
Reasons for deploying a disaggregated networking solution are a combination of two. First, is a clear financial advantage of buying white box equipment vs. the branded devices which carry a premium price. Second, is the flexibility which such solution enables, and this enables the customer to get better control over his network and how it’s run, as well as enable the network administrators a lot of room to innovate and adapt their network to their unique and changing needs.
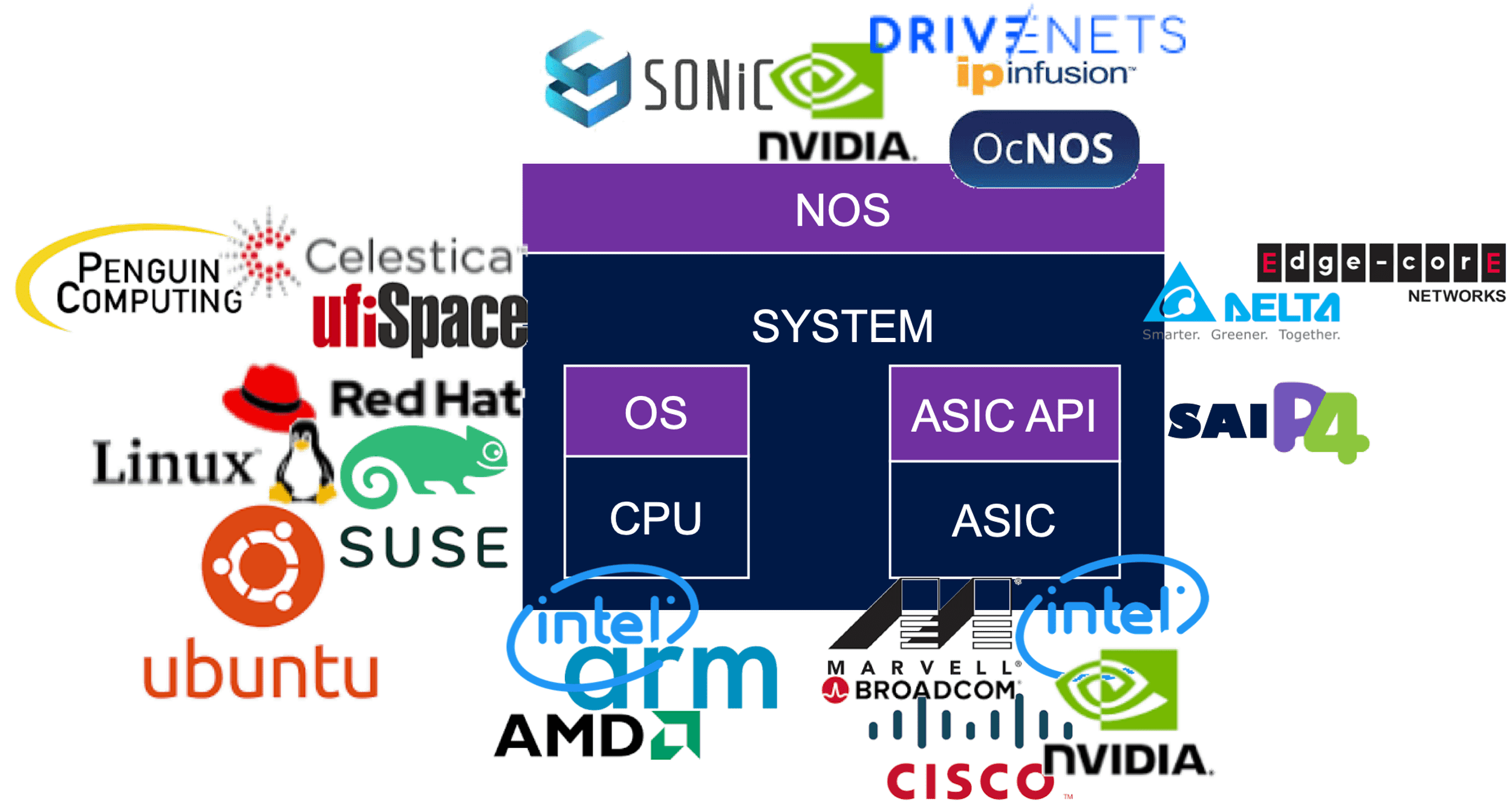
The image below reflects a partial list of the potential vendors supplying components within the OCP networking community. The full OCP Membership directory is available at the OCP website.
Between DC and Telco Networking:
Data center networks are built to serve connectivity towards multiple servers which contain data or answer user queries. The size of data as well as number of queries towards it is a constantly growing function as humanity grows its consumption model of communication services. Traffic in and out of these servers is divided to north/south that indicates traffic coming in and goes out of the data center, and east/west that indicates traffic that runs inside the data center between different servers.
As a general pattern, the north/south traffic represent most of the traffic flows within the network while the east/west traffic represent the most bandwidth being consumed. This is not an accurate description of data center traffic, but it is accurate enough to explain the way data center networks are built and operated.
A data center switch connects to servers with a high-capacity link. This tier#1 switch is commonly known as a top of rack (ToR) switch and is a high capacity, non-blocking, low latency switch with some minimal routing capabilities.
- The ToR is then connected to a Tier#2 switch that enables it to connect to other ToR in the data center.
- The Tier#2 switches are connected to Tier#3 to further grow the connectivity.
- Traffic volumes are mainly east/west and best kept within the same Tier of the network to avoid scaling the routing tables.
- In theory, a Tier#4/5/6 of this network can exist, but this is not common.
- The higher Tier of the data center network is also connected to routers which interface the data center to the outside world (primarily the Internet) and these routers are a different design of a router than the tiers of switching devices mentioned earlier.
- These externally facing routers are commonly connected in a dual homed logic to create a level of redundancy for traffic to come in and out of the datacenter. Further functions on the ingress and egress of traffic towards data centers are also firewalled, load-balanced, address translated, etc. which are functions that are sometimes carried by the router and can also be carried by dedicated appliances.
As data centers density grew to allow better service level to consumers, the amount of traffic running between data center instances also grew and data center interconnect (DCI) traffic became predominant. A DCI router on the ingress/egress point of a data center instance is now a common practice and these devices typically connect over larger distance of fiber connectivity (tens to hundreds of Km) either towards other DCI routers or to Telco routers that is the infrastructure of the world wide web (AKA the Internet).
While data center network devices shine is their high capacity and low latency and are built from the ASIC level via the NOS they run to optimize on these attributes, they lack in their capacity for routing scale and distance between their neighboring routers. Telco routers however are built to host enough routes that “host” the Internet (a ballpark figure used in the industry is 1M routes according to CIDR) and a different structure of buffer (both size and allocation) to enable long haul connectivity. A telco router has a superset of capabilities vs. a data center switch and is priced differently due to the hardware it uses as well as the higher software complexity it requires which acts as a filter that narrows down the number of vendors that provide such solutions.
Attributes of an AI Cluster:
As described in a previous article HPC/AI workloads demand certain attributes from the network. Size, latency, lossless, high bandwidth and scale are all mandatory requirements and some solutions that are available are described in the next paragraphs.
Chassis Based Solutions:
This solution derives from Telco networking.
Chassis based routers are built as a black box with all its internal connectivity concealed from the user. It is often the case that the architecture used to implement the chassis is using line cards and fabric cards in a Clos-3 topology as described earlier to depict the structure of the DDC. As a result of this, the chassis behavior is predictable and reliable. It is in fact a lossless fabric wrapped in sheet metal with only its network interfaces facing the user. The caveat of a chassis in this case is its size. While a well-orchestrated fabric is a great fit for the network needs of AI workloads, it’s limited capacity of few hundred ports to connect to servers make this solution only fitting very small deployments.
In case chassis is used at a scale larger than the sum number of ports per single chassis, a Clos (this is in fact a non-balanced Clos-8 topology) of chassis is required and this breaks the fabric behavior of this model.
Standalone Ethernet Solutions:
This solution derives from data center networking.
As described previously in this paper, data center solutions are fast and can carry high bandwidth of traffic. They are however based on standalone single chip devices connected in a multi-tiered topology, typically a Clos-5 or Clos-7. as long as traffic is only running within the same device in this topology, behavior of traffic flows will be close to uniform. With the average number of interfaces per such device limited to the number of servers physically located in one rack, this single ToR device cannot satisfy the requirements of a large infrastructure. Expanding the network to higher tiers of the network also means that traffic patterns begin to alter, and application run-to-completion time is impacted. Furthermore, add-on mechanisms are mounted onto the network to turn the lossy network into a lossless one. Another attribute of the traffic pattern of AI workloads is the uniformity of the traffic flows from the perspective of the packet header. This means that the different packets of the same flow, will be identified by the data plane as the same traffic and be carried in the exact same path regardless of the network’s congestion situation, leaving parts of the Clos topology poorly utilized while other parts can be overloaded to a level of traffic loss.
Proprietary Locked Solutions:
Additional solutions in this field are implemented as a dedicated interconnect for a specific array of servers. This is more common in the scientific domain of heavy compute workloads, such as research labs, national institutes, and universities. As proprietary solutions, they force
the customer into one interconnect provider that serves the entire server array starting from the server itself and ending on all other servers in the array.
The nature of this industry is such where a one-time budget is allocated to build a “super-computer” which means that the resulting compute array is not expected to further grow but only be replaced or surmounted by a newer model. This makes the vendor-lock of choosing a proprietary interconnect solution more tolerable.
On the plus side of such solutions, they perform very well, and you can find examples on the top of the world’s strongest supercomputers list which use solutions from HPE (Slingshot), Intel (Omni-Path), Nvidia (InfiniBand) and more.
Perspective from Silicon Vendors:
DSF like solutions have been presented in the last OCP global summit back in October-2022 as part of the networking project discussions. Both Broadcom and Cisco (separately) have made claims of superior silicon implementation with improved power consumption or a superior implementation of a Virtual Output Queueing (VOQ) mechanism.
Conclusions:
There are differences between AI and HPC workloads and the required network for each.
While the HPC market finds proprietary implementations of interconnect solutions acceptable for building secluded supercomputers for specific uses, the AI market requires solutions that allow more flexibility in their deployment and vendor selection. This boils down to Ethernet based solutions of various types.
Chassis and standalone Ethernet based solutions provide reasonable solutions up to the scale of a single machine but fail to efficiently scale beyond a single interconnect machine and keep the required performance to satisfy the running workloads.
A distributed fabric solution presents a standard solution that matches the forecasted industry need both in terms of scale and in terms of performance. Different silicon implementations that can construct a DSF are available. They differ slightly but all show substantial benefits vs. chassis or standard ethernet solutions.
This paper does not cover the different silicon types implementing the DSF architecture but only the alignment of DSF attributes to the requirements from interconnect solutions built to run AI workloads and the advantages of DSF vs. other solutions which are predominant in this space.
–>Please post a comment in the box below this article if you have any questions or requests for clarification for what we’ve presented here and in part I.
References:
Using a distributed synchronized fabric for parallel computing workloads- Part I
Using a distributed synchronized fabric for parallel computing workloads- Part I
by Run Almog Head of Product Strategy, Drivenets (edited by Alan J Weissberger)
Introduction:
Different networking attributes are needed for different use cases. Endpoints can be the source of a service provided via the internet or can also be a handheld device streaming a live video from anywhere on the planet. In between endpoints we have network vertices that handle this continuous and ever-growing traffic flow onto its destination as well as handle the knowhow of the network’s whereabouts, apply service level assurance, handle interruptions and failures and a wide range of additional attributes that eventually enable network service to operate.
This two part article will focus on a use case of running artificial intelligence (AI) and/or high-performance computing (HPC) applications with the resulting networking aspects described. The HPC industry is now integrating AI and HPC, improving support for AI use cases. HPC has been successfully used to run large-scale AI models in fields like cosmic theory, astrophysics, high-energy physics, and data management for unstructured data sets.
In this Part I article, we examine: HPC/AI workloads, disaggregation in data centers, role of the Open Compute Project, telco data center networking, AI clusters and AI networking.
HPC/AI Workloads, High Performance Compute Servers, Networking:
HPC/AI workloads are applications that run over an array of high performance compute servers. Those servers typically host a dedicated computation engine like GPU/FPGA/accelerator in addition to a high performance CPU, which by itself can act as a compute engine, and some storage capacity, typically a high-speed SSD. The HPC/AI application running on such servers is not running on a specific server but on multiple servers simultaneously. This can range from a few servers or even a single machine to thousands of machines all operating in synch and running the same application which is distributed amongst them.
The interconnect (networking) between these computation machines need to allow any to any connectivity between all machines running the same application as well as cater for different traffic patterns which are associated with the type of application running as well as stages of the application’s run. An interconnect solution for HPC/AI would resultingly be different than a network built to serve connectivity to residential households or a mobile network as well as be different than a network built to serve an array of servers purposed to answers queries from multiple users as a typical data center structure would be used for.
Disaggregation in Data Centers (DCs):
Disaggregation has been successfully used as a solution for solving challenges in cloud resident data centers. The Open Compute Project (OCP) has generated open source hardware and software for this purpose. The OCP community includes hyperscale data center operators and industry players, telcos, colocation providers and enterprise IT users, working with vendors to develop and commercialize open innovations that, when embedded in product are deployed from the cloud to the edge.
High-performance computing (HPC) is a term used to describe computer systems capable of performing complex calculations at exceptionally high speeds. HPC systems are often used for scientific research, engineering simulations and modeling, and data analytics. The term high performance refers to both speed and efficiency. HPC systems are designed for tasks that require large amounts of computational power so that they can perform these tasks more quickly than other types of computers. They also consume less energy than traditional computers, making them better suited for use in remote locations or environments with limited access to electricity.
HPC clusters commonly run batch calculations. At the heart of an HPC cluster is a scheduler used to keep track of available resources. This allows for efficient allocation of job requests across different compute resources (CPUs and GPUs) over high-speed networks. Several HPC clusters have integrated Artificial Intelligence (AI).
While hyperscale, cloud resident data centers and HPC/AI clusters have a lot of similarities between them, the solution used in hyperscale data centers is falling short when trying to address the additional complexity imposed by the HPC/AI workloads.
Large data center implementations may scale to thousands of connected compute servers. Those servers are used for an array of different application and traffic patterns shift between east/west (inside the data center) and north/south (in and out of the data center). This variety boils down to the fact that every such application handles itself so the network does not need to cover guarantee delivery of packets to and from application endpoints, these issues are solved with standard based retransmission or buffering of traffic to prevent traffic loss.
An HPC/AI workload on the other hand, is measured by how fast a job is completed and is interfacing to machines so latency and accuracy are becoming more of a critical factor. A delayed packet or a packet being lost, with or without the resulting retransmission of that packet, drags a huge impact on the application’s measured performance. In HPC/AI world, this is the responsibility of the interconnect to make sure this mishaps do not happen while the application simply “assumes” that it is getting all the information “on-time” and “in-synch” with all the other endpoints it shares the workload with.
–>More about how Data centers use disaggregation and how it benefits HPC/AI in the second part of this article (Part II).
Telco Data Center Networking:
Telco data centers/central offices are traditionally less supportive of deploying disaggregated solutions than hyper scale, cloud resident data centers. They are characterized by large monolithic, chassis based and vertically integrated routers. Every such router is well-structured and in fact a scheduled machine built to carry packets between every group of ports is a constant latency and without losing any packet. A chassis based router would potentially pose a valid solution for HPC/AI workloads if it could be built with scale of thousands of ports and be distributed throughout a warehouse with ~100 racks filled with servers.
However, some tier 1 telcos, like AT&T, use disaggregated core routing via white box switch/routers and DriveNets Network Cloud (DNOS) software. AT&T’s open disaggregated core routing platform was carrying 52% of the network operators traffic at the end of 2022, according to Mike Satterlee, VP of AT&T’s Network Core Infrastructure Services. The company says it is now exploring a path to scale the system to 500Tbps and then expand to 900Tbps.
“Being entrusted with AT&T’s core network traffic – and delivering on our performance, reliability and service availability commitments to AT&T– demonstrates our solution’s strengths in meeting the needs of the most demanding service providers in the world,” said Ido Susan, DriveNets founder and CEO. “We look forward to continuing our work with AT&T as they continue to scale their next-gen networks.”
Satterlee said AT&T is running a nearly identical architecture in its core and edge environments, though the edge system runs Cisco’s disaggregates software. Cisco and DriveNets have been active parts of AT&T’s disaggregation process, though DriveNets’ earlier push provided it with more maturity compared to Cisco.
“DriveNets really came in as a disruptor in the space,” Satterlee said. “They don’t sell hardware platforms. They are a software-based company and they were really the first to do this right.”
AT&T began running some of its network backbone on DriveNets core routing software beginning in September 2020. The vendor at that time said it expected to be supporting all of AT&T’s traffic through its system by the end of 2022.
Attributes of an AI Cluster:
Artificial intelligence is a general term that indicates the ability of computers to run logic which assimilates the thinking patterns of a biological brain. The fact is that humanity has yet to understand “how” a biological brain behaves, how are memories stored and accessed, how come different people have different capacities and/or memory malfunction, how are conclusions being deduced and how come they are different between individuals and how are actions decided in split second decisions. All this and more are being observed by science but not really understood to a level where it can be related to an explicit cause.
With evolution of compute capacity, the ability to create a computing function that can factor in large data sets was created and the field of AI focuses on identifying such data sets and their resulting outcome to educate the compute function with as many conclusion points as possible. The compute function is then required to identify patterns within these data sets to predict the outcome of new data sets which it did not encounter before. Not the most accurate description of what AI is (it is a lot more than this) but it is sufficient to explain why are networks built to run AI workloads different than regular data center networks as mentioned earlier.
Some example attributes of AI networking are listed here:
- Parallel computing – AI workloads are a unified infrastructure of multiple machines running the same application and same computation task
- Size – size of such task can reach thousands of compute engines (e.g., GPU, CPU, FPGA, Etc.)
- Job types – different tasks vary in their size, duration of the run, the size and number of data sets it needs to consider, type of answer it needs to generate, etc. this as well as the different language used to code the application and the type of hardware it runs on contributes to a growing variance of traffic patterns within a network built for running AI workloads
- Latency & Jitter – some AI workloads are resulting a response which is anticipated by a user. The job completion time is a key factor for user experience in such cases which makes latency an important factor. However, since such parallel workloads run over multiple machines, the latency is dictated by the slowest machine to respond. This means that while latency is important, jitter (or latency variation) is in fact as much a contributor to achieve the required job completion time
- Lossless – following on the previous point, a response arriving late is delaying the entire application. Whereas in a traditional data center, a message dropped will result in retransmission (which is often not even noticed), in an AI workload, a dropped message means that the entire computation is either wrong or stuck. It is for this reason that AI running networks requires lossless behavior of the network. IP networks are lossy by nature so for an IP network to behave as lossless, certain additions need to be applied. This will be discussed in. follow up to this paper.
- Bandwidth – large data sets are large. High bandwidth of traffic needs to run in and out of servers for the application to feed on. AI or other high performance computing functions are reaching interface speeds of 400Gbps per every compute engine in modern deployments.
The narrowed down conclusion from these attributes is that a network purposed to run AI workloads differs from a traditional data center network in that it needs to operate “in-synch.
There are several such “in-synch” solutions available. The main options are: Chassis based solutions, Standalone Ethernet solutions, and proprietary locked solutions.–>These will be briefly described to their key advantages and deficiencies in our part II article.
Conclusions:
There are a few differences between AI and HPC workloads and how this translates to the interconnect used to build such massive computation machines.
While the HPC market finds proprietary implementations of interconnect solutions acceptable for building secluded supercomputers for specific uses, the AI market requires solutions that allow more flexibility in their deployment and vendor selection.
AI workloads have greater variance of consumers of outputs from the compute cluster which puts job completion time as the primary metric for measuring the efficiency of the interconnect. However, unlike HPC where faster is always better, some AI consumers will only detect improvements up to a certain level which gives interconnect jitter a higher impact than latency.
Traditional solutions provide reasonable solutions up to the scale of a single machine (either standalone or chassis) but fail to scale beyond a single interconnect machine and keep the required performance to satisfy the running workloads. Further conclusions and merits of the possible solutions will be discussed in a follow up article.
………………………………………………………………………………………………………………………………………………………………………………..
About DriveNets:
DriveNets is a fast-growing software company that builds networks like clouds. It offers communications service providers and cloud providers a radical new way to build networks, detaching network growth from network cost and increasing network profitability.
DriveNets Network Cloud uniquely supports the complete virtualization of network and compute resources, enabling communication service providers and cloud providers to meet increasing service demands much more efficiently than with today’s monolithic routers. DriveNets’ software runs over standard white-box hardware and can easily scale network capacity by adding additional white boxes into physical network clusters. This unique disaggregated network model enables the physical infrastructure to operate as a shared resource that supports multiple networks and services. This network design also allows faster service innovation at the network edge, supporting multiple service payloads, including latency-sensitive ones, over a single physical network edge.
References:
https://drivenets.com/resources/events/nfdsp1-drivenets-network-cloud-and-serviceagility/
https://www.run.ai/guides/hpc-clusters/hpc-and-ai
https://drivenets.com/news-and-events/press-release/drivenets-network-cloud-now-carries-more-than-52-of-atts-core-production-traffic/
https://techblog.comsoc.org/2023/01/27/att-highlights-5g-mid-band-spectrum-att-fiber-gigapower-joint-venture-with-blackrock-disaggregation-traffic-milestone/
AT&T Deploys Dis-Aggregated Core Router White Box with DriveNets Network Cloud software
DriveNets Network Cloud: Fully disaggregated software solution that runs on white boxes
DriveNets raises $262M to expand its cloud-based alternative to core network routers
Israel based DriveNets provides software-based internet routing solutions to service providers to run them as virtualized services over a “network cloud” based architecture using “white box” hardware. Founded in 2016 by serial entrepreneur Ido Susan, with the objective of developing a cloud-based virtual router platform as an alternative to the chassis-based IP routers from companies like Cisco, Juniper Networks, Nokia and Huawei.
Today, the company announced it has secured $262 million in a Series C venture capital funding round, considerably increasing the company’s valuation over its January 2021 Series B round. The funding from this latest round of investment will be used to develop future technology solutions, pursue new business opportunities, and expand the company’s global operations and support teams to support growing customer demand.
The round was led by D2 Investments with the participation of DriveNets’ current investors, including Bessemer Venture Partners, Pitango, D1 Capital, Atreides Management, and Harel Insurance Investments & Financial Services. With this round, DriveNets has now raised just over $580 million.
“DriveNets’ approach of building networks like cloud allows telecom providers to take advantage of technological efficiencies available to cloud hyperscalers, such as cloud-native software design and optimal utilization of shared resources across multiple services,” said Ido Susan, DriveNets founder and CEO. “This latest round of investment demonstrates our investors and customers’ confidence in us and will enable us to expand the value and global operational support we offer them.”
“Most of our customers are tier 1 and 2 service providers and we found that Asian operators are early adopters and open to new technologies that can accelerate growth and lower their cost,” said Susan this week. A lot of initial engagement is around cost-cutting.
DriveNets first big announced sale was to AT&T in 2020 as we noted in this IEEE Techblog post. DriveNets disaggregated core routing solution has been deployed over AT&T’s IP-MPLS backbone network. AT&T recently said that it plans to have 50 per cent of its core backbone traffic running on white box switches and open hardware by the end of 2022.
“DriveNets has demonstrated its ability to move the networking industry forward and has gained the trust of tier-1 operators,” said Adam Fisher, Partner at Bessemer Venture Partners. “While other solution providers are facing challenging headwinds, DriveNets continues to innovate and execute on its vision to change the future of the networking market.”
“DriveNets has already made a big impact in the high-scale networking industry and its routing solutions are adopted by tier-1 operators for their quality and the innovation they enable,” said Aaron Mankovski, Managing Partner at Pitango. “This investment will allow DriveNets to expand its footprint in the market and develop additional offerings.”
DriveNet’s claim to fame is that it can replace costly core router hardware with its proprietary sophisticated operating system which runs on cheaper “white box” equipment that resides in the service provider’s own cloud resident data center. That works out to a cost savings on average of 40%, Susan previously told Tech Crunch.
The operating system has a lot of different functionality, covering core, aggregation, peering, cable, data center interconnection, edge computing and cloud services, and this means, Susan said, that while customers come for the discounts, they stay for the services, “since our model is software-based we enable faster innovation and service rollout.”
Since its last funding round in 2021, DriveNets has gained significant market traction:
- Growing network traffic running on the DriveNets’ Network Cloud solution by 1,000 percent
- Engaging with nearly 100 customers and doubled bookings year over year
- Establishing key strategic partnerships to speed up the deployment of next-generation networks worldwide, including agreements with Itochu Techno-Solutions Corporation (CTC), EPS Global, Wipro Limited, and KGPCo.
- Growing its overall employee base by 30 percent, significantly expanding its operations and deployment teams, and its global reach.
“During the COVID-19 pandemic they grew their existing networks based by simply buying more of the same to minimize the operational burden,” said Susan. That’s now changing, though, in the current economic climate.
“Now, post pandemic they are starting to refresh these networks and with the growing interest of Cloud Hyperscalers in networking service, operators are looking at more innovative ways to stay competitive and accelerate innovation, by building networks in more like cloud. These are the big customers that we are seeing now — transformative large operators who are expanding the capacity of their networks and are looking to rollout newer services at a wide scale,” he said.
“We have seen in the past couple of years some of the incumbent networking vendors starting to adopt our model,” said Susan. He credits the company’s “huge success” at AT&T as a proof that “the model works. You can build networks like cloud at a very high scale and reliability and both lower network cost and accelerate service rollout.”
“Now it is not a matter of ‘if’ but of ‘when’ since incumbent vendors have more to lose over that transition,” he added. He believes that DriveNets will emerge a leader in the networking vendor space nonetheless, not least due to being able to invest in further development on the back of funding rounds like this one.
“We are investing in our current solution to ensure that we keep ahead of the market but also continue to add expected capabilities,” said Susan. He notes that the company was the first to support Broadcom’s latest chipset and more than triple the network capacity but also lead the transition to 400Gig. “In parallel, we are already investing in additional solution offerings that will provide additional value to our customers and expand our TAM,” he said.
“DriveNets has already made a big impact in the high-scale networking industry and its routing solutions are adopted by tier-1 operators for their quality and the innovation they enable,” said Aaron Mankovski, managing partner at Pitango, in a statement. “This investment will allow DriveNets to expand its footprint in the market and develop additional offerings.”
The biggest challenge is not technological, per se, but one of talent, “recruiting quality people to support our engineering efforts and our global expansion. At the end of the day, it is all about the people,” Susan explained. The company has been recruiting software engineers to fuel its growth. DriveNets also recently announced the addition of three cloud and networking industry veterans to its leadership team.
However, there are still a lot of skeptics as LightCounting pointed out in this IEEE Techblog post. LightCounting’s research indicates that “the overall Disaggregated Open Router (DOR) market remains incipient and unless proof of concept (PoC), testing and validation accelerate, volumes will take some time to materialize.”
About DriveNets:
DriveNets is a leader in cloud-native networking software and network disaggregation solutions. Founded in 2015 and based in Israel, DriveNets offers communications service providers (CSPs) and cloud providers a radical new way to build networks, substantially growing their profitability by changing their technological and economic models. DriveNets’ solution – Network Cloud – adapts the architectural model of cloud to telco-grade networking. Network Cloud is a cloud-native software that runs over a shared physical infrastructure of standard white-boxes, radically simplifying the network’s operations, offering telco-scale performance and elasticity at a much lower cost.
Learn more at www.drivenets.com
References:
https://drivenets.com/news-and-events/press-release/drivenets-secures-262-million/
DriveNets connects with $262M as demand booms for its cloud-based alternative to network routers
AT&T Deploys Dis-Aggregated Core Router White Box with DriveNets Network Cloud software
Light Counting: Large majority of CSPs remain skeptical about Disaggregated Open Routers
Light Counting: Large majority of CSPs remain skeptical about Disaggregated Open Routers
LightCounting’s second annual report provides an update on the emergence of the Disaggregated Open Routers (DOR) market in wireless infrastructure. DOR are white-box cell site, aggregation and core routers based on an open and disaggregated architecture for existing 2G/3G/4G and future 5G network architectures.
The DOR architecture was hailed as a new paradigm as early as 2012, using open source software for a centralized SDN Controller from the Open Network Foundation and Linux Foundation. The “open networking architecture” was envisioned to be used by tier 1 telcos and hyperscale cloud service providers and later extend to enterprise/campus networks. Well, that never happened!
Instead, hyperscalers developed their own proprietary versions of SDN, sometimes using a bit of open sourced software (e.g. Microsoft Azure). A few start-ups (e.g. Pica 8 and Cumulus Networks) developed their own software to run on white boxes and bare metal switches, including network operating systems, routing and network management.
One company that’s succeeded at customized software running over white boxes is
Israel based DriveNets. Indeed, the DriveNets software (see References below) is custom built- not open source! It’s an “unbundled” networking software solution, which runs over a cluster of low-cost white box routers and white box x86 based compute servers. DriveNets has developed its own Network Operating System (NOS), rather than use open source or Cumulus’ NOS as several other open networking software companies have done.
LightCounting’s research indicates that the overall DOR market remains incipient and unless proof of concept (PoC), testing and validation accelerate, volumes will take some time to materialize.
“Despite TIP’s (Facebook’s Telecom Infra Project) relentless efforts to push network disaggregation to all network elements and domains, and a flurry of communication service providers (CSPs) taking the lead with commercial DOR deployments like AT&T with DriveNets (NOS), UfiSpace (hardware) and Broadcom (networking silicon), a large majority of CSPs (Communications Service Providers) remain skeptical about the potential opex reduction, the maturity of transport disaggregation, and the impact on operations, administration, maintenance, procurement and support.” said Stéphane Téral, Chief Analyst at LightCounting Market Research.
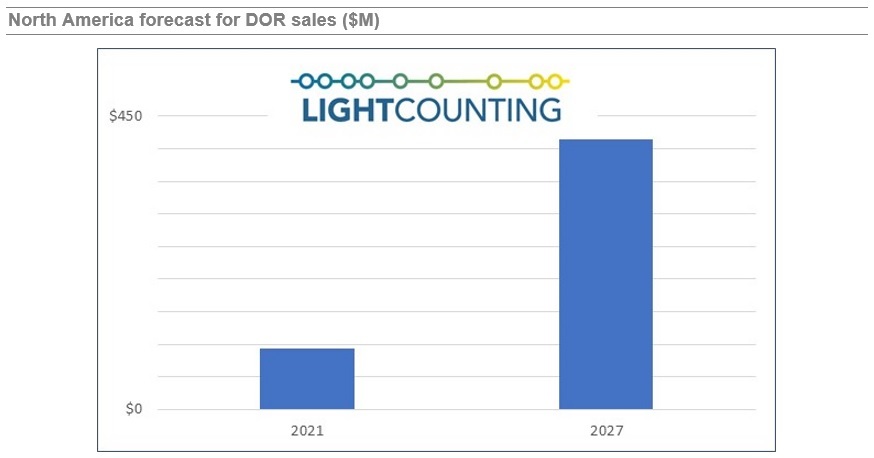
Source: Light Counting
That quote is quite different from Stephane’s comment one year ago that the DOR market was poised for imminent growth:
“Still incipient, the DOR market is just about to take off and is here to stay but requires more CSPs (Communications Service Providers) to take the plunge and drive volumes. And with China’s lack of appetite for DOR, North America is taking the lead.”
Major findings in the report are the following:
- The open RAN ascension brought router disaggregation to the spotlight and paved the way to four fundamental routes. This phenomenon would have never happened without TIP’s initiative.
- Although NOS software vendors are mushrooming and by far outnumbering the white box hardware suppliers dominated by UfiSpace, there have been some casualties down the DOR road. In the networking silicon domain, Broadcom remains predominant.
- CSPs remain cautiously optimistic about router disaggregation but have yet to see more maturity and the full benefits. As AT&T is showing the DOR way, KDDI and LG U+ could be DriveNets’ next major customers.
- With all inputs from all vendors and CSPs with DOR rollout plans taken into consideration, our cell site-based model produced a forecast showing a slow start that reflects the early stage of this market and an uptick at the end of the 2021-2026 forecast period marked by a double digit CAGR.
About the report:
LightCounting’s Disaggregated Open Routers report explores the emergence of the Disaggregated Open Routers (DOR) market. Disaggregated open routers are white-box routers based on separated white box hardware and software with cloud enabled software functions for existing 2G/3G/4G and future 5G network architectures. The report analyzes the disaggregated open routers’ (aggregation and core) architectures and implementations in wireless infrastructure, including the emerging vendor ecosystem, and tracks white box hardware units and sales, and software sales, all broken down by region including North America, Europe Middle East Africa, Asia Pacific, and Caribbean Latin America. It includes the total number of cell sites worldwide and a 5-year market forecast.
Historical data accounts for sales of the following vendors:
| Vendor | Software | Hardware/White Box | Source of Information | |
| Adva | Ensemble Activator | Survey data and estimates | ||
| Altran | Intelligent Switching Solution (ISS) | |||
| Alpha Networks | Hardware platform | |||
| Arrcus | ArcOS | |||
| Aviat Networks & Metaswitch (Microsoft) | AOS | |||
| Cisco | IOS XR7 | |||
| Datacom | DmOS | |||
| Dell Technologies | NOS | Hardware platform | ||
| Delta Electronics | AGCXD40V1, AGCV208S/AGCV208SV1, AGC7008S | Estimates | ||
| DriveNets | DNOS | |||
| Edgecore Networks | AS7316-26XB, AS7315-27X, AS5915-18X | Survey data and estimates | ||
| Exaware | ExaNOS | |||
| IP Infusion | OcNOS, DANOS | Estimates | ||
| Infinera | CNOS | DRX Series | Survey data and estimates | |
| Niral Networks | NiralOS | |||
| UfiSpace | S9700-53DX, S9700-23D, S9705-48D, S9500-30XS | Survey data and estimates | ||
| Volta Networks (now in IBM) | VEVRE | |||
| Note: Not all vendors provide services |
References:
https://www.lightcounting.com/report/march-2022-disaggregated-open-routers-135
AT&T Deploys Dis-Aggregated Core Router White Box with DriveNets Network Cloud software
AT&T today announced that Israeli start-up DriveNets is providing its software-based, disaggregated core routing solution for the carrier’s IP-MPLS backbone network. AT&T also said it had deployed its “next gen long haul 400G optical transport platform, giving AT&T the network infrastructure needed to transport the tsunami of demand that will be generated by 5G, fiber-based broadband and entertainment content services in the years ahead.” [Long haul is for distances >= 600km. AT&T did not name its 40G optical transport equipment vendor]
DriveNets says their Network Cloud solution perfectly fits the vision of AT&T and other leading service providers and cloud hyper-scalers for the evolution of the network to be open, agile, cost effective and software based. DriveNets Network Cloud is cloud-native software (not open source software). It’s a software solution which runs over a cluster of low-cost white box routers and compute servers. It has its own Network Operating System (NOS) and turns the physical network into a shared resource supporting multiple network services in the most efficient way.
Indeed, Network Cloud runs on standard white boxes built by ODM partners like UfiSpace who provided the white boxes to AT&T, based on the Jericho2 chipset from Broadcom. This approach creates a new economic model for the networking industry, lowering cost per bit and improving network profitability.
“We’re thrilled about this opportunity to work with AT&T on their next gen core network, and proud of our engineers for meeting AT&T’s rigorous certification process that field-prove the quality of our solution,” said Ido Susan, CEO of DriveNets. “This announcement demonstrates to those who questioned the disaggregated network model that our Network Cloud is more scalable and cost-efficient than traditional hardware-centric routers. DriveNets is transforming the network in the same way that VMware transformed the compute and storage industry” he added.
“I’m proud to announce today that we have now deployed a next gen IP/MPLS core routing platform into our production network based on the open hardware designs we submitted to OCP last fall,” said Andre Fuetsch, AT&T’s CTO of Network Services, in his keynote speech at the Open Networking and Edge Summit (ONES). “We chose DriveNets, a disruptive supplier, to provide the Network Operating System (NOS) software for this core use case.”
One year ago, AT&T contributed an open source specification for a distributed disaggregated chassis (DDC)to the Open Compute Project (OCP). The DDC was intended to define a standard set of configurable building blocks to construct service provider-class routers, ranging from single line card systems, a.k.a. “pizza boxes,” to large, disaggregated chassis clusters. It is a a white box design based on Broadcom’s Jericho2 silicon. AT&T said the Jericho2 chip set provide the density, scale and features needed to support the requirements of a service provider.
The white box hardware was designed and manufactured by Taiwan based UfiSpace. It consists of three components: a 40x100G line card system, 10x400G line card system, and a 48x400G fabric system. These building blocks can be deployed in various configurations to build routers with capacity anywhere between 4 Tbps to 192 Tbps.
DriveNets Network Cloud solution and its innovative Network Operating System (NOS) software is NOT open source/open networking. It provides the management and control of the white box hardware. It supports a sophisticated set of traffic engineering features that enable highly reliable and efficient MPLS transport for our global, multi-service core backbone. The software then connects into AT&T’s centralized SDN controller that optimizes the routing of traffic across the core.
DriveNets Network Cloud offers extreme capacity and scale for networking service providers and cloud hyperscalers, supporting small to largest core, aggregation and peering network services. DriveNets Network Cloud runs over scalable physical clusters ranging from 4 Tbps (single box) to 768 Tbps (large cluster of 192 boxes), acting as a single router entity. This model is designed to offer both network scaling flexibility, similar to cloud architectures, as well as the ability to add new service offerings and scale them efficiently across the entire network.
“We are pleased to see the broad adoption of Jericho2 products across the networking industry combined with the innovative DriveNets Network Cloud software,” said Ram Velaga, senior vice president and general manager, Core Switching Group, Broadcom. “AT&T’s submission of the Distributed Disaggregation Chassis white box architecture based on Jericho2 is making a big impact on driving the networking industry forward,” he added.
“UfiSpace has been among the first who committed to opening the networking model, starting with our disaggregated cell site gateway routers which we have already demonstrated with AT&T at the Open Networking Summit (ONS) last April.” said Vincent Ho, CEO UfiSpace. “We are proud that AT&T’s core routing platform will utilize our white box solution where we can take part in the largest live Dis-Aggregated network in the world.”
In an email to Light Reading, Drivenets’ Mr. Susan wrote: “This is the largest backbone network in the U.S. and DriveNets Network Cloud is deployed across the entire network, running over multiple large white box clusters in many core and aggregation locations of the AT&T network. Each one of these large clusters contains 192 white boxes from UfiSpace. The DriveNets Network Cloud Network Operating System (NOS) turn these large clusters of 192 white boxes into a single router entity. These large router entities are deployed in many locations at the AT&T network.”
Performing as the best in class router when it comes to stability, reliability and availability, DriveNets Network Cloud is the largest router in the market today. DriveNets is engaged with 18 service providers and hyperscalers and is already on the path to becoming one of the leading networking vendors in the market. Last week, DriveNets announced lab testing of a 192Tbps distributed router by a European operator.
DriveNets Network Cloud created a new SaaS-based network economic model that detaches network growth from network cost, lowering cost per bit and improving network profitability. This disruptive business model assists service providers and cloud hyperscalers in reducing both network CapEx and OpEx.
“AT&T has a rigorous certification process that challenged my engineers to their limits, and we are delighted to take the project to the next level with deployment into the production network,” said Drivenets’ Susan.
Today’s white box with core routing software announcement is just the first of many from AT&T we may see in the near future. AT&T’s Fuetsch wrote in the press release, “In the coming weeks, we’ll announce additional software suppliers for other use cases operating on the same hardware, demonstrating the maturity of the eco-system and power of openness.”
Expect forthcoming AT&T white box related announcements to be on Provider Edge routers for which the carrier alluded to when releasing its DDC spec to the OCP.
…………………………………………………………………………………………………………………………………………………….
References:
https://about.att.com/story/2020/open_disaggregated_core_router.html
https://about.att.com/story/2019/open_compute_project.html
DriveNets Network Cloud: Fully disaggregated software solution that runs on white boxes
DriveNets Network Cloud: Fully disaggregated software solution that runs on white boxes
by Ofer Weill, Director of Product Marketing at DriveNets; edited and augmented by Alan J Weissberger
Introduction:
Networking software startup DriveNets announced in February that it had raised $110 million in first round (Series A) of venture capital funding. With headquarters in Ra’anana, Israel, DriveNets’ cloud-based service, called Network Cloud, simplifies the deployment of new services for carriers at a time when many telcos are facing declining profit margins. Bessemer Venture Partners and Pitango Growth are the lead VC investors in the round, which also includes money from an undisclosed number of private angel investors.
DriveNets was founded in 2015 by telco experts Ido Susan and Hillel Kobrinsky who are committed to creating the best performing CSP Networks and improving its economics. Network Cloud was designed and built for CSPs (Communications Service Providers), addressing their strict resilience, security and QoS requirements, with zero compromise.
“We believe Network Cloud will become the networking model of the future,” said DriveNets co-founder and CEO Ido Susan, in a statement. “We’ve challenged many of the assumptions behind traditional routing infrastructures and created a technology that will allow service providers to address their biggest challenges like the exponential capacity growth, 5G deployments and low-latency AI applications.”’
The Solution:
Network Cloud does not use open-source code. It’s an “unbundled” networking software solution, which runs over a cluster of low-cost white box routers and white box x86 based compute servers. DriveNets has developed its own Network Operating System (NOS) rather than use open source or Cumulus’ NOS as several other open networking software companies have done.
Fully disaggregated, its shared data plane scales-out linearly with capacity demand. A single Network Cloud can encompass up to 7,600 100Gb ports in its largest configuration. Its control plane scales up separately, consolidating any service and routing protocol.
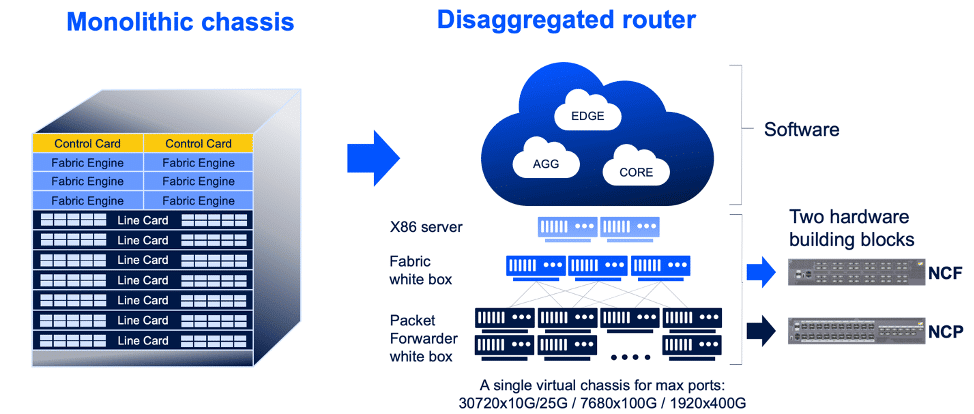
Network Cloud data-plane is created from just two building blocks white boxes – NCP for packet forwarding and NCF for fabric, shrinking operational expenses by reducing the number of hardware devices, software versions and change procedures associated with building and managing the network. The two white-boxes (NCP and NCF) are based on Broadcom’s Jericho2 chipset which has high-speed, high-density port interfaces of 100G and 400G bits/sec. A single virtual chassis for max ports might have this configuration: 30720 x 10G/25G / 7680 x 100G / 1920 x 400G bits/sec.
Last month, DriveNets disaggregated router added 400G-port routing support (via whitebox routers using the aforementioned Broadcom chipset). The latest Network Cloud hardware and software is now being tested and certified by an undisclosed tier-1 Telco customer.
“Just like hyper-scale cloud providers have disaggregated hardware and software for maximum agility, DriveNets is bringing a similar approach to the service provider router market. It is impressive to see it coming to life, taking full advantage of the strength and scale of our Jericho2 device,” said Ram Velaga, Senior Vice President and General Manager of the Switch Products Division at Broadcom.
Network Cloud control-plane runs on a separate compute server and is based on containerized microservices that run different routing services for different network functions (Core, Edge, Aggregation, etc.). Where they are co-located, service-chaining allows sharing of the same infrastructure for all router services.
Multi-layer resiliency, with auto failure recovery, is a key feature of Network Cloud. There is inter-router redundancy and geo-redundancy of control to select a new end to end path by routing around points of failure.
Network Cloud’s orchestration capabilities include Zero Touch Provisioning, full life cycle management and automation, as well as superior diagnostics with unmatched transparency. These are illustrated in the figures below:

Image Courtesy of DriveNets
Future New Services:
Network Cloud is a platform for new revenue generation. For example, adding 3rd party services as separate micro-services, such as DDoS Protection, Managed LAN to WAN, Network Analytics, Core network and Edge network.
“Unlike existing offerings, Network Cloud has built a disaggregated router from scratch. We adapted the data-center switching model behind the world’s largest clouds to routing, at a carrier-grade level, to build the world’s largest Service Providers’ networks. We are proud to show how DriveNets can rapidly and reliably deploy technological innovations at that scale,” said Ido Susan CEO and Co-Founder of DriveNets in a press release.
………………………………………………………………………………………………
References:
https://www.drivenets.com/about-us
https://www.drivenets.com/uploads/Press/201904_dn_400g.pdf
