

AI Interencing
Autonomous customer experience required for AI-Native 6G and distributed intelligence at the network edge
Executive Sumary:
Communications service providers (CSPs) have historically competed on network-centric KPIs—coverage, capacity, reliability, and price—anchored in 3GPP performance and management frameworks (e.g., TS 28-series, TS 23.501 QoS models). However, these metrics alone are no longer sufficient to sustain differentiation in increasingly saturated and capital-intensive markets, according to Chantel Cary, Product Marketing Senior Manager at Oracle Communications [1],
“The battleground has shifted,” Cary told Capacity Global. “Today, customer experience is becoming the clearest point of differentiation, and in many cases, the most important driver of growth.”
This shift is unfolding alongside structural constraints: flat ARPU, rising capex associated with 5G standalone, fiber access (FTTx), and edge cloud expansion, and increasing customer acquisition and retention costs. At the same time, customer expectations—benchmarked against hyperscaler-grade digital platforms—are becoming uniformly high across mobile and fixed broadband services.
“They do not compare a telecom provider only to other providers,” she said. “They compare every experience to the best experience they have anywhere.”
…………………………………………………………………………………………………………………………………………………………………………………………………………………..
Note 1. Oracle Communications is a dedicated global business unit and product portfolio fully owned and operated by Oracle. It provides enterprise software and infrastructure designed specifically for telecommunications service providers (like AT&T or Verizon) and large enterprises. Their solutions manage everything from network routing, security, and signaling (including 5G) to back-office billing, revenue management, and customer experience operations,
…………………………………………………………………………………………………………………………………………………………………………………………………………………..
Analysys Mason reports that 97% of operators view AI-powered automation as essential for survival and growth, reinforcing alignment with TM Forum’s Autonomous Networks framework and the broader industry transition toward AI-native system design.
AI-Native Customer Experience Architecture:
Cary’s concept of “autonomous customer experience” maps directly to the emerging paradigm of AI-native networks, where intelligence is embedded across both network and service layers rather than applied as an overlay. “It is not about removing the human element from engagement,” she explained. “It is about using AI to continuously orchestrate the customer lifecycle in ways that humans alone cannot manage at scale.”
In wireless networks, this evolution is reflected in 3GPP-defined enablers such as the Network Data Analytics Function (NWDAF, TS 23.288), which provides real-time analytics to optimize policy control, mobility, and QoS. In parallel, O-RAN Alliance architectures introduce the near-real-time and non-real-time RAN Intelligent Controllers (near-RT RIC, non-RT RIC), enabling AI-driven control loops for radio resource management and service optimization.

Image Credit: Aisera
In wireline and converged networks, similar principles are emerging through SDN-based control planes, broadband network gateways (BNG) with telemetry streaming, and ITU-T frameworks (e.g., Y.3172 for machine learning in future networks), enabling closed-loop optimization across access, aggregation, and core domains.
However, Cary notes that most OSS/BSS environments remain fragmented, limiting the ability to operationalize these capabilities at the customer experience layer. Data silos, batch-oriented processing, and loosely coupled workflows constrain real-time, cross-domain orchestration.
AI Across Commercial and Network Domains:
Cary identifies three primary domains of impact, increasingly converging with network intelligence:
-
Marketing: AI-driven personalization is evolving toward real-time, context-aware engagement informed by both customer behavior and network conditions (e.g., location, QoS state, congestion). This aligns with event-driven architectures and customer data platforms integrated with network analytics (e.g., NWDAF exposure via APIs). “Personalisation shifts from broad audiences to the individual,” she said, adding that relevance is now “a prerequisite for attention.”
-
Sales: AI enables next-best-action and dynamic offer generation, incorporating network-aware insights such as service availability, slice characteristics (in 5G SA), and fiber capacity constraints. Integration with policy control (3GPP TS 23.203) and service orchestration frameworks supports closed-loop order capture and fulfillment. “That combination of higher conversion and lower friction is valuable,” she said.
-
Service: AI-driven assurance is transitioning from reactive fault management to predictive and intent-based service assurance across both wireless and wireline domains. Telemetry from RAN, transport, and fixed access networks feeds AI models that anticipate degradation and trigger remediation before customer impact. “Human agents still play a central role,” Cary said, “but they can be augmented with real-time recommendations, contextual history and autonomous processes that improve both speed and consistency.”
Scaling Challenges in AI-Native Transformation:
Despite progress in AI models and domain-specific analytics, Cary highlights a systemic gap in operationalization.
“What it lacks, in many cases, is the ability to turn fragmented customer data into real-time decisions that can actually be executed across marketing, sales and service,” she said.
Analysys Mason data indicates that only 6% of operators achieve ROI above 25% from AI initiatives, while 60% advance just 20% of proofs of concept into production. This reflects challenges in integrating heterogeneous data sources across OSS, BSS, and network domains, as well as limitations in MLOps and real-time orchestration frameworks.
Fragmentation is compounded in converged networks, where wireless (3GPP-based) and wireline (e.g., Broadband Forum TR-369/USP, TR-383 for disaggregated BNG) ecosystems often evolve independently. Additionally, 93% of operators cite multi-vendor complexity as increasing total cost of ownership, underscoring the need for interoperable, standards-based integration across AI, network, and IT domains.
“That creates an unfortunate pattern across the industry,” she said, “promising AI initiatives that demonstrate value in isolation but fail to scale because they are not connected to the data, systems and processes where real work happens.”
Toward Fully AI-Native Operations:
Cary emphasizes that the target state is not incremental automation but fully AI-native operations, where intelligence is embedded into both network control loops and customer engagement workflows.
“This is why the future of customer experience in communications is not about layering AI onto the edge of the enterprise,” Cary said. “It is about making AI operational at the core of engagement.”
This vision aligns with emerging 6G research directions, where AI is treated as a native design primitive across RAN, core, and service layers, as well as with TM Forum’s Open Digital Architecture (ODA), which promotes composable, API-driven integration between OSS, BSS, and AI components.
Oracle’s approach reflects this convergence by unifying customer data, embedding AI into engagement and orchestration layers, and integrating these capabilities with telecom operational systems across both wireless and wireline domains.
Implementation Suggestions:
Cary said that network providers do not need to transform everything at once. She recommends starting by unifying customer data across touchpoints to establish a trusted, real-time view, before activating high-value AI use cases across marketing, sales and service. From there, providers can embed AI into workflows so insight translates into action rather than sitting in dashboards, eventually connecting those capabilities into end-to-end orchestration.
Indeed, Cary advocates a phased approach consistent with AI-native transformation:
-
Establish a unified, real-time data fabric spanning customer, service, and network domains.
-
Deploy high-value AI use cases (e.g., next-best-action, churn prediction, predictive assurance) leveraging both IT and network telemetry.
-
Embed AI into execution workflows to enable closed-loop, intent-driven orchestration across the customer lifecycle.
This progression reflects the broader industry trajectory toward converged, AI-native networks, where customer experience is no longer an overlay on connectivity, but a direct outcome of tightly coupled intelligence across wireless and wireline infrastructures.
“The communications providers that lead in the years ahead will not be the ones that simply adopt more AI tools. They will be the ones that use AI to rethink how customer engagement works across the enterprise. AI is not just enhancing customer experience,” she added. “It is redefining how customer experience is delivered, and in communications, that shift is likely to separate the providers that keep pace from the ones that set the pace.”
………………………………………………………………………………………………………………………………
Editorial Analysis:
Cary’s vision aligns with IMT 2030/6G’s shift from AI as an overlay to AI as an architectural primitive, spanning the air interface, semantic service handling, and distributed edge intelligence across wireless and wireline domains. The cleanest way to map her suggestions into 6G is to treat “autonomous customer experience” as the service-layer expression of an AI-native network stack: AI decisions would no longer sit only in OSS/BSS, but would be distributed across RAN, transport, core, and edge applications, with closed-loop control spanning wireless and wireline domains. That maps well to current AI-native 6G proposals that emphasize model interdependencies, distributed intelligence, and AI embedded directly in the architecture rather than layered on top.
For the AI native air interface, the link is to AI-assisted radio control, where the network uses learned models to optimize scheduling, mobility, beam management, and QoS-aware policy decisions in real time. In a 6G framing, that extends beyond today’s AI for RAN optimization and toward an AI-native air interface in which the radio stack itself is designed for machine-driven adaptation, including distributed control loops between UE, RAN, and core. For your article, this supports language that customer experience is increasingly shaped by network intelligence at the point of access, not just by back-office engagement systems.ieeexplore.ieee+2
Semantic communications maps to the idea that the network should optimize for meaning or task relevance, not simply bit delivery. In practice, that means a 6G service layer could prioritize the semantic value of an interaction—such as whether a customer is trying to resolve an outage, confirm a move order, or change a plan—and allocate resources accordingly across wireless and wireline paths. The relevance to Cary’s argument is that customer experience becomes more contextual and intent-aware when the network itself can distinguish between low-value traffic and high-importance service interactions.
Distributed intelligence at the network edge is the most direct bridge between CSP operations and 6G design. In a converged wireless-wireline environment, edge AI can fuse RAN telemetry, fixed access metrics, subscriber context, and service history to trigger local decisions such as proactive care, dynamic QoS adjustment, or preemptive fault mitigation. That makes the experience layer more autonomous because the decision point moves closer to where the event occurs, reducing dependence on centralized, slower, batch-oriented processing.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
References:
https://www.nokia.com/6g/unlocking-the-full-potential-of-ai-native-6g-through-standards/
Comparing AI Native mode in 6G (IMT 2030) vs AI Overlay/Add-On status in 5G (IMT 2020)
SHIELD-6G with AI-native cyber threat intelligence platform to enhance cybersecurity for Europe’s future 6G networks
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
Ericsson and Intel collaborate to accelerate AI-Native 6G; other AI-Native 6G advancements at MWC 2026
NVIDIA and global telecom leaders to build 6G on open and secure AI-native platforms + Linux Foundation launches OCUDU
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
Meta’s “Iris” AI Chip for MTIA: Implications for Telecom-Grade Optical Networking, DCI and High Capacity Ethernet Fabrics
Executive Summary:
According to Reuters, Meta Platforms (previously known as Facebook) plans to start manufacturing an artificial intelligence (AI) chip in September as part of its plan to boost overall computing power to 14 gigawatts in 2027. The social media firm’s data center chip, code-named “Iris,” is part of a four-generation project for Meta Training and Inference Accelerators (MTIA) that it will design in-house. The plan is to use custom-built silicon to improve the AI that powers its Facebook and Instagram social media platforms.
This move by Meta marks a pivotal moment in hyperscaler AI infrastructure strategy. This vertical integration play, executed through a multi-vendor supply chain (Broadcom design, TSMC manufacturing, Samsung RAM, SanDisk storage, Sumitomo fiber-optic equipment), has profound implications for telecom-grade optical networking, data center interconnect (DCI), and high-capacity Ethernet fabrics.
For IEEE Techblog readers focused on network architecture, standards, and infrastructure economics, the Meta MTIA story illuminates three critical trends:
- Hyperscaler silicon sovereignty as a cost and performance lever.
- Scaling challenge of 14 GW AI compute for optical transport and DCI.
- The emerging “Network Supercycle” driven by agentic AI workloads as per Cisco.

Image Credit: Meta Platforms
…………………………………………………………………………………………………………………………………………………………………………………………………………………………..
The MTIA “Iris” Roadmap: Accelerating AI Silicon Cadence:
Meta’s Meta Training and Inference Accelerator (MTIA) program—now in its third generation with “Iris”—is pursuing an aggressive development cadence: a new chip every six months through 2027. This contrasts sharply with the industry-standard 12–18 month cadence for AI accelerators from NVIDIA, AMD, and even hyperscaler custom silicon programs (Google TPU, AWS Trainium)
Key MTIA milestones:
-
MTIA v1 (2024): First-generation training/inference chip, proof-of-concept for Meta’s internal AI workloads
-
MTIA v2 (early 2026): Performance and efficiency improvements, scaled deployment for Llama model training
-
MTIA v3 “Iris” (September 2026): Production ramp, targeting higher throughput and lower power per inference
-
MTIA v4 (2027): Next-generation architecture, expected to integrate advanced packaging, higher-bandwidth memory, and improved interconnect topologies
This cadence is not merely a technical achievement—it’s a strategic signal. Meta is betting that in-house silicon, even if initially less performant than NVIDIA’s H100/B100 or AMD’s MI300X, can deliver better total cost of ownership (TCO) when optimized for Meta’s specific workloads (Llama LLMs, recommendation systems, ad targeting).
Broadcom + TSMC: A Multi-Vendor Supply Chain Play:
Meta’s MTIA program is not a pure in-house design effort. The company is partnering with Broadcom for chip design and TSMC for advanced-node manufacturing (likely 5nm or 3nm process). This hybrid approach—hyperscaler architectural control with foundry and design partner execution—is becoming the dominant model for AI silicon:techcrunch
Why this matters: The multi-vendor AI chip supply chain is becoming a critical dependency for telecom-grade infrastructure. Broadcom’s involvement in both Meta’s MTIA and Apple’s $30B RF/FBAR deal (announced July 7–8, 2026) positions the company as a central player in both AI compute and 5G/6G RF ecosystems. For network architects, this means tracking Broadcom’s packaging, interconnect, and I/O roadmaps—not just NVIDIA’s.
14 GW Computing Target: The Optical and DCI Challenge:
Meta’s internal memo, reported by Reuters on July 9, 2026, outlines a target of 14 GW of computing capacity by 2027. To put this in perspective:
-
14 GW ≈ 14 large nuclear power plants (each ~1 GW)
-
Current hyperscaler data center power draw: ~50–100 GW total across all hyperscalers (2025 estimate)
-
Meta’s 2025 data center power: ~10–12 GW (estimated)
-
Growth rate: ~15–20% CAGR in hyperscaler power draw, but Meta is targeting a step-function increase
This is not just a compute scaling story—it’s an optical transport and DCI scaling story. Each GW of AI compute requires:
-
High-bandwidth optical interconnect within data centers (400G/800G/1.6T Ethernet, optical circuit switching)
-
Long-haul DCI between data center campuses (coherent 800G/1.6T, subsea cable systems)
-
Power and cooling infrastructure (liquid cooling, direct-to-chip, immersion)
-
Fiber-optic cabling and fiber-optic equipment (Sumitomo, Corning, Prysmian)
Optical Transport Implications:
Meta’s 14 GW target implies a massive buildout of optical infrastructure. Key considerations for IEEE ComSoc readers:
-
Intra-DC Optical Fabrics: AI clusters (e.g., 10K–100K GPU/TPU/MTIA nodes) require non-blocking, low-latency optical fabrics. Meta’s 2025–2026 data center designs likely use:
-
800G/1.6T optical transceivers (OSFP, QSFP-DD)
-
Optical circuit switching (OCS) for dynamic bandwidth allocation (e.g., Oriole Networks PRISM, Google Apollo)
-
Co-packaged optics (CPO) and near-packaged optics (NPO) for power efficiency
-
-
Inter-DC DCI: Meta operates multiple data center campuses globally (U.S., Europe, Asia). Connecting these for AI workload distribution requires:
-
Coherent 800G/1.6T DCI (400ZR/ZR+, OpenROADM)
-
Subsea cable systems (e.g., Meta’s 2024–2026 investments in transatlantic and transpacific cables)
-
Terragraph-inspired metro fiber for regional campus interconnects
-
-
Fiber-Optic Equipment: Meta’s supply chain includes Sumitomo Electric for fiber-optic equipment, per the July 2026 memo. Sumitomo is a key supplier of:reuters
-
Optical amplifiers (EDFA)
-
Optical switches and ROADMs
-
Fiber-optic cables and connectors
-
Standards relevance: IEEE 802.3 (Ethernet), IEEE 802.1 (Time-Sensitive Networking), and ITU-T G.709 (OTN) are all directly impacted by Meta’s custom AI chip development program.
Cost Reduction vs. NVIDIA/AMD: The Vertical Integration Calculus & Why Hyperscalers Are Building Their Own AI Chips:
Meta’s MTIA program is part of a broader hyperscaler trend: vertical integration in AI silicon. The economic rationale is straightforward:
-
NVIDIA H100/B100 pricing: $30K–$40K per GPU (2025–2026 list prices)
-
AMD MI300X pricing: $20K–$30K per accelerator (2025–2026)
-
Hyperscaler custom silicon TCO: 30–50% lower than NVIDIA/AMD at scale, despite lower peak performance
Meta’s internal analysis (per their July 2026 internal memo) likely shows that MTIA v3 “Iris” can deliver comparable inference throughput per dollar to NVIDIA H100 for Llama workloads, even if peak FLOPS are lower. This is because:
-
Workload-specific optimization: MTIA is tuned for Meta’s LLM architectures (Llama 2/3/4), recommendation systems, and ad targeting—not general-purpose AI training.
-
Supply chain control: Meta can negotiate better TSMC wafer pricing, avoid NVIDIA’s 20–30% gross margin, and reduce dependency on a single vendor.
-
Software stack integration: Meta can optimize PyTorch, Llama inference libraries, and Meta’s internal AI frameworks for MTIA, reducing software overhead.
NVIDIA’s AI Chip “tax” vs. Hyperscaler Pushback:
NVIDIA’s dominance in AI accelerators (80–90% market share in 2025) has created what hyperscalers call the “NVIDIA tax”: premium pricing, limited supply, and software lock-in (CUDA ecosystem). Meta’s MTIA, Google’s TPU, Amazon’s Trainium, and Microsoft’s Maia are all attempts to reduce this dependency.
This is analogous to the telecom industry’s historical pushback against Cisco/Juniper proprietary switching ASICs. Open networking (Barefoot Tofino, Broadcom StrataXGS, P4 programmability) and disaggregated hardware (white-box switches, SONiC NOS) emerged as responses. AI silicon is following a similar path: disaggregation, open software stacks, and multi-vendor supply chains.
Full AI Infrastructure Stack Diversification: Samsung, SanDisk, Sumitomo:
Meta’s July 2026 memo outlines a fully diversified AI infrastructure stack:
-
AI accelerators: Meta MTIA (Broadcom design, TSMC fab)
-
DRAM: Samsung (HBM3/HBM3e for high-bandwidth memory)
-
Storage: SanDisk (NVMe SSDs, QLC/TLC NAND for model checkpoints and data lakes)
-
Fiber-optic equipment: Sumitomo (optical amplifiers, switches, cables)
-
Networking: Broadcom (Ethernet switches, NICs), potentially NVIDIA (Spectrum-X, Quantum InfiniBand for some clusters)
This diversification is not just about cost—it’s about supply chain resilience. The 2020–2023 chip shortage, U.S.-China trade tensions, and Taiwan geopolitics have made hyperscalers acutely aware of single-vendor risk.
Telecom relevance: This mirrors the telecom industry’s shift from Cisco/Juniper monolithic routers to disaggregated white-box switches, open optical line systems, and multi-vendor RAN (O-RAN, vRAN). The AI infrastructure stack is undergoing a similar transformation.
The “Network Supercycle” Narrative: AI Compute as a WAN Traffic Driver:
Cisco executives have framed agentic AI workloads as driving a new infrastructure investment wave, with AI inference projected to account for ~25% of total WAN traffic by 2035. Meta’s 14 GW target is a concrete manifestation of this thesis.
Key implications for WAN and DCI:
-
Bursty, Low-Latency Uplink Traffic: Agentic AI (e.g., autonomous coding agents, multi-agent collaboration) requires high uplink capacity, low latency, and guaranteed connectivity—exactly the traffic patterns Ookla’s July 2026 report highlighted as stressors for 5G networks.
-
East-West DCI Traffic: AI training and inference workloads require massive data movement between storage, compute, and memory across data center campuses. This drives demand for:
-
Coherent 800G/1.6T DCI
-
Optical circuit switching for dynamic bandwidth allocation
-
Subsea cable systems for intercontinental AI workload distribution
-
-
Token/Byte Monetization: Huawei’s July 2026 AI-centric network vision includes “token/byte” monetization strategies for AI-driven services in the upper-6 GHz band. Meta’s AI infrastructure buildout is the supply-side enabler for this demand-side monetization.techblog.comsoc+1
Nokia’s “Physical AI” Warning:
Nokia’s “Physical AI” study (covered in earlier Techblog posts) warns that high-volume, low-latency uplink traffic from physical AI applications (e.g., robotics, autonomous systems) may require a fundamental RAN redesign. Meta’s 14 GW target is a parallel data center-side manifestation of this trend: AI workloads are reshaping both RAN and DCI/optical architectures.techblog.comsoc+1
Standards and Interoperability:
Meta’s MTIA “Iris” and 14 GW target have direct implications for several IEEE and standards activities:
IEEE 802.3 (Ethernet):
-
800G/1.6T Ethernet: IEEE 802.3df (800G/1.6T) and IEEE 802.3dj (1.6T/3.2T) are critical for AI cluster fabrics.
-
Power over Ethernet (PoE) for AI racks: Higher-power PoE standards may be needed for AI accelerator racks and liquid-cooled systems.
IEEE 802.1 (Time-Sensitive Networking):
-
Deterministic Ethernet for AI: Low-latency, jitter-free traffic for AI inference may require TSN profiles or new deterministic Ethernet extensions.
IEEE 802.15 (Wireless Personal Area Networks):
-
AI-native wireless for edge inference: Meta’s MTIA may eventually extend to edge inference (e.g., AR/VR, metaverse), requiring low-power, high-bandwidth wireless standards.
ITU-T and OIF:
-
Coherent DCI: ITU-T G.709 (OTN), G.709.x (coherent OTN), and OIF 400ZR/ZR+ are critical for inter-DCI.
-
Open optical line systems: OpenROADM, OpenCable, and disaggregated optical line systems are relevant for hyperscaler DCI builds.
O-RAN and AI-RAN Alliance:
-
AI-for-RAN vs. AI-on-RAN: Meta’s AI infrastructure could eventually support AI-on-RAN workloads (running AI inference on RAN/edge infrastructure), aligning with the AI-RAN Alliance’s vision.
Competitive Landscape – How Meta’s MTIA Compares:
Key takeaway: Meta’s MTIA is not the most performant AI accelerator, but it’s part of a broader hyperscaler strategy to reduce NVIDIA dependency, control TCO, and optimize for specific workloads.
Conclusions – The AI Infrastructure Stack as a Telecom-Grade Opportunity:
Meta’s MTIA “Iris” chip and 14 GW computing target are not just hyperscaler news—they are telecom-grade infrastructure news. For IEEE ComSoc readers, the implications are clear:
-
Optical transport and DCI will scale dramatically to support 14 GW of AI compute, creating demand for 800G/1.6T coherent optics, optical circuit switching, and subsea cable systems.
-
Hyperscaler silicon sovereignty is reshaping the AI accelerator market, with direct implications for Broadcom, TSMC, and the broader semiconductor supply chain.
-
The “Network Supercycle” is real, driven by agentic AI workloads that require high uplink capacity, low latency, and guaranteed connectivity.
-
Standards bodies (IEEE, ITU-T, OIF, O-RAN) must track AI infrastructure trends to ensure interoperability, performance, and cost efficiency.
For telecom network architects, optical engineers, and standards professionals, the Meta MTIA story is a call to action: AI infrastructure is the next frontier for telecom-grade networking. The question is not whether telecom and AI will converge—it’s how quickly and effectively the industry can adapt.
References:
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
Ookla: AI workloads will force changes in 5G mobile network infrastructure
Nokia’s AI Applications Study: “Physical AI” may require RAN redesign to support high‑volume, low‑latency uplink traffic
Ookla: AI platform reliability decreases as outages surge
Huawei’s AI-Centric Network Vision: Six Imperatives for the Next Decade; Critical Questions for IEEE Techblog Community
Dell’Oro: AI RAN revenue forecast: $35B from 2026-to-2030; 3 types of AI RAN explained
AI-RAN and Agentic AI get real: Ericsson, Nokia, Verizon & other operators enter into a new network automation era
AI-RAN Reality Check: hype vs hesitation, shaky business case, no specific definition, no standards?
Analysis: Nvidia’s rumored new 6G AI-RAN – likely features/functions and industry impact
Dell’Oro: 2H2026 Data Center Capex to Accelerate due to massive AI Deployments
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Ookla: AI workloads will force changes in 5G mobile network infrastructure
Introduction:
Ookla’s latest research study examines how AI use cases will stress 5G mobile networks, relative to standard internet traffic. The report, based on Speedtest Intelligence® data across 22 markets, evaluates metrics like upload capacity, latency under load, and cloud infrastructure pathways (see graphs below). Using Speedtest 5G data from 2025 across 22 markets and 86 operators in North America, Europe, Asia Pacific, the Middle East, and Latin America, it measures upload capacity, latency under load, and the quality of the path to the cloud. It also shows where current 5G falls short of what AI actually demands.
Analysis:
Ookla’s report argues that 5G network evaluation is entering a new phase: raw download speed is no longer enough to describe user experience or network capability in an AI-driven era. The more relevant indicators are upload performance, latency, consistency, and resilience, because AI-heavy applications tend to be interactive, symmetric, and sensitive to delay. The report’s timing is important because it reframes 5G from a consumer mobile broadband service into an infrastructure question for AI workloads. That shift matters for network operators, because uplink and latency have historically received less attention than headline download rates in market rankings and public messaging.
Here’s the lead-in (emphasis added):
“AI has changed what a good mobile network looks like, and the metric the industry has marketed for two decades — peak download speed — no longer predicts it. The networks that top the download charts are often not the ones best prepared for AI traffic. Whether an AI application feels instant or breaks depends in large part on how much a network can upload, how it holds up under load, and how consistently it reaches the cloud, and on those measures, different networks come out on top. This report rebuilds the industry’s download-led scorecard around what AI actually asks of a network, and shows where today’s 5G mobile networks are ready and where they fall short. AI traffic is not one thing. Text chat, conversational voice, multimodal and AR vision, generated video, and agentic activity each load the network differently, and most of them lean on parts of the network that download speed never tested. The change AI brings is less about raw capacity, which operators have expanded for years, than about the shape of the traffic — heavier on upload, always on, and bursty, rather than download-led and session-based.”
A few high-level takeaways for the U.S. market include:
- Although the United States ranks among the strongest on overall network performance, it sits at 5.1% for the proportion of network capacity allocated to the uplink, which is the lowest in the dataset.
- The U.S. upload share has contracted, declining from 8.0% to 5.1% between 2023 and 2025.
- The U.S. market top network operators fall short of the 20 Mbps upload target required for AR and multimodal AI.
- For baseline network responsiveness, the U.S. records a multi-server latency of 50.5 ms, missing the target of less than 50 ms for text-based large language models (LLMs).
Technical Implications:
Ookla’s framing implicitly favors 5G SA, 5G Advanced, and edge-assisted architectures, since these are the network generations most likely to improve latency determinism and support more efficient uplink behavior. It also suggests that future benchmarking should include workload-aware tests, not just conventional speed tests, because AI applications stress networks differently from video streaming or web browsing. The report has immediate relevance for markets where 5G download speeds look strong but uplink and latency remain weaker, because those networks may appear healthy under older metrics while still underperforming for AI use cases. That is a useful lens for comparing operators, especially where regulators and carriers are beginning to discuss AI readiness as part of national digital infrastructure strategy.
Conclusions:
With the rise of AI workloads, mobile network measurement is becoming application-specific. The central question is no longer just “How fast is 5G?” but “How well does the network support AI-era traffic patterns, especially interactive and uplink-heavy traffic?” In this new context, metrics such as upload capacity, latency consistency, and service resilience are becoming just as important as peak downlink speed. For operators, this implies that competitive advantage will increasingly depend on how well the network supports real-time, bidirectional, and latency-sensitive applications, rather than how well it performs on legacy consumer benchmarks.
Traditional speed tests still matter, but they are increasingly insufficient as a proxy for user experience in an AI-native environment. In practice, the networks that win will be those that can deliver symmetry, resilience, and predictable latency across real workloads, not merely impressive headline throughput.
…………………………………………………………………………………………………………………………………………………………………………………..
Ookla Charts:




……………………………………………………………………………………………………………………………………………………………………….
References:
https://www.ookla.com/articles/benchmarking-5g-ai-workloads-2026
https://www.ookla.com/s/media/2026/07/Ookla_Research_AI_network_readiness_07262.pdf
Ookla: AI platform reliability decreases as outages surge
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
Ericsson’s June 2026 Mobility Report Highlights + AI impact on network traffic
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Nokia’s AI Applications Study: “Physical AI” may require RAN redesign to support high‑volume, low‑latency uplink traffic
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Ookla on the Global D2D Market
Ookla: Starlink a viable competitor for hybrid 5G/NTN services due to network performance improvements and larger coverage area
Ookla: D2D satellite connectivity surged 24.5% during last 9 months; Starlink’s footprint expansion leads the way
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Dell’Oro: Mobile Core Networks +15% in 2025; Ookla: Global Reality Check on 5G SA and 5G Advanced in 2026
Ookla: FWA Speed Test Results for big 3 U.S. Carriers & Wireless Connectivity Performance at Busy Airports
TM Forum’s DTW Ignite 2026: Open Digital Architecture (ODA); Nokia, Ericsson, IBM and Mavenir AI announcements/cloud partnerships
-
- Shift to Action: TM Forum Vice President Aaron Boasman-Patel and CEO Nik Willetts opened the summit emphasizing that the industry must move past abstract C-suite visions.
- The AI Economy: The flagship keynote officially launched the “Race to 2030,” a direct directive tasking operators to secure their market relevance by deploying high-velocity, production-grade architectures.
-
- On-Stage AI Co-Hosts: In an industry event first, agentic AI systems took the stage alongside human moderators to act as live panel co-hosts, digital analysts, and experts.
- Summit Intelligence Layer: Advanced AI systems recorded and indexed every keynote, panel, and breakout session, functioning as a real-time intelligence layer to deliver daily trend summaries to attendees.
-
- Autonomous Networks (AN): Featuring the largest showcase of live autonomous operating systems to date. Major case studies from carriers like China Mobile, China Telecom, TDC NET, and Telefónica showcased functional solutions for self-optimizing networks, RAN energy efficiency, and fast fault resolution.
- Trustworthy AI and Data: Discussions zeroed in on scaling responsible AI, exploring Models-as-a-Service (MODaaS) frameworks, managing tokenomics, and reinforcing cyber resilience.
- Composable IT and Ecosystems: Demonstrations focused on scaling Open Digital Architecture (ODA) from boardroom design into functional, interoperable engineering realities.

Practical Engineering & Showcases:
- Catalyst Showcases: The exhibition floor hosted over 60 collaborative proof-of-concept Catalyst projects and Innovation Engine live demonstrations.
- New Interactive Hubs: The event debuted dedicated “Mission Garages” for hands-on engineering collaboration, along with a specialized Future Skills program to help tech teams adapt to AI-native workflows. [1]
- Major Tech Partnerships: Industry titans—including IBM, Ericsson, Cisco, and Nokia—used the floor to debut subsea infrastructures, physical AI, and cloud-native automation frameworks.
Note 1. DTW Ignite 2026 is TM Forum’s flagship global connectivity event focused on accelerating AI-native telcos, autonomous networks, and composable IT. The event is from June 23 to June 25 at the Bella Center in Copenhagen, Denmark.
……………………………………………………………………………………………………………………………………………………………….
At the show, the TM Forum and its member alliance of over 850 companies across 180 countries, announced a major structural evolution for the Open Digital Architecture (ODA), shifting it from a cloud-native IT modernization blueprint into an AI-native execution environment. The core focus of these updates is to establish standardized, executable reference frameworks that allow operators to move beyond fragmented AI pilots and build an autonomous enterprise. The primary ODA updates and structural expansions announced at the summit include:
-
- Governed Execution Layer: TM Forum members launched AI-native extensions to the ODA specification, adding a governed execution layer. This allows autonomous AI agents and large language models to run natively within the existing ODA component architecture and Open APIs.
- Project Foundation & AI Canvas: Through the Demo ONE Catalyst project, tech leaders debuted an updated AI-Native ODA Canvas. This cloud-native runtime environment orchestrates data, AI models, and autonomous agents across fragmented BSS, OSS, and network domains to replace rigid legacy systems.
- Model-as-a-Service (MODaaS): To solve the challenge of rising token costs and fragmented model selection, an ODA-aligned MODaaS framework was introduced. It establishes a unified control plane to govern, secure, and manage AI model usage across the carrier architecture.
-
- Space-Telco Interoperability: In a major scope expansion, TM Forum officially launched the ODA for Satellite project. Supported by 16 foundational partners—including Airbus, Terrestar, and Vodacom—the initiative targets multi-billion dollar direct-to-device and space-connectivity markets.
- Unified Non-Terrestrial Frameworks: The project extends standard ODA components to satellite technology providers, standardizing how terrestrial mobile networks and non-terrestrial networks (NTNs) handle cross-industry billing, service delivery, and zero-touch roaming integrations.
- Plug-and-Play Validation: TM Forum rolled out its newly expanded ODA Component Certification. This toolkit gives vendors a programmatic way to verify that their commercial software components are truly plug-and-play ready, lowering custom integration costs for telecom buyers.
- “Running on ODA” Milestones: The alliance celebrated that 18 global Communication Service Providers (CSPs), representing over two billion subscribers globally, have officially achieved “Running on ODA” accreditation—confirming that modular, componentized architecture has reached full scale in production environments.
……………………………………………………………………………………………….
Vendor Announcements:
- Amazon Web Services (AWS) Expansion: Nokia and AWS expanded their partnership to run Nokia’s Autonomous Networks Fabric natively on AWS. The integration brings operators closer to Level 4 network autonomy, enabling networks to orchestrate, analyze, and heal themselves at machine speed.
- Google Cloud Integration: Nokia deepened its alliance with Google Cloud to integrate Gemini models into the Nokia Assurance Center. They unveiled six specialized generative AI agents (including a Router Agent and Event Triage Agent) to automatically process data and isolate the root causes of service faults. It launches as a SaaS offering in September 2026.
- Databricks Proof of Concept: Nokia and Databricks announced the completion of a joint project showing a unified, cloud-agnostic data platform. This resolves a legacy pain point by unifying hundreds of fragmented operational silo data architectures so multi-agent AI can run seamlessly across networks.
- GenAI-Native Operations: Instead of relying on traditional rules-based code, Nokia’s new interfaces allow field engineers to query complex multi-vendor topologies, generate diagnostic code, and run natural-language root-cause analyses on real-time traffic faults.
- Autonomous Network Scaling: Nokia presented multi-party Catalyst project solutions targeting network optimization, zero-touch slicing, and automated enterprise edge deployments tailored for the 5G-Advanced landscape.
……………………………………………………………………………………………………………………………………………………….
- EIAP Core Expansion: The headline announcement from the Ericsson Cloud Software and Services division was the expansion of the Ericsson Intelligent Automation Platform (EIAP). Formerly restricted to RAN operations, the platform now fully integrates and unifies Radio Access Network (RAN) and core network automation systems.
- Introduction of cApps: Ericsson claimed a major industry first by rolling out core-specific automation applications (cApps). These decentralized apps allow operators to run automated routines directly on core architectures, streamlining cross-domain workflows to cut operations costs.
- Business Value Pathways: Ericsson debuted a structured strategic blueprint designed to guide Communication Service Providers (CSPs) through the financial steps of scaling from Level 3 to Level 4 autonomous networks.
…………………………………………………………………………………………………………………………………………………….
- Addressing the “AI Trust Gap”: Responding to a TM Forum study revealing that only 14% of operators can prove their AI systems are fully reliable, IBM presented framework tools at DTW Ignite to address security and model bias.
- B2B2X Monetization: IBM focused its platform showcase on orchestrating automated workflows for multi-enterprise B2B2X networks, enabling secure data federation across third-party hyperscalers and edge servers.
……………………………………………………………………………………………………………………………………………………
- Telco-First Cloud Architecture: Stationed at Booth 334, Mavenir debuted its updated AI-by-design, cloud-native software portfolios built natively around TM Forum’s Open Digital Architecture (ODA) frameworks.
- Closed-Loop Automation: Mavenir demonstrated actionable frameworks that handle real-time resource adjustments, shifting power and processing capacity across base stations based on AI-predicted user demand cycles.
……………………………………………………………………………………………………………………………………………………
References:
https://www.tmforum.org/events/dtw/experience-dtw/new-for-2026
Inside TM Forum’s Catalyst project “Living Networks – Phase III”
Deloitte and TM Forum : How AI could revitalize the ailing telecom industry?
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
GSMA, ETSI, IEEE, ITU & TM Forum: AI Telco Troubleshooting Challenge + TelecomGPT: a dedicated LLM for telecom applications
SHIELD-6G with AI-native cyber threat intelligence platform to enhance cybersecurity for Europe’s future 6G networks
Verizon’s 6G Innovation Forum joins a crowded list of 6G efforts that may conflict with 3GPP and ITU-R IMT-2030 work
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
By Shazia Hasnie, PhD
Introduction:
The physical network infrastructure that underpins cloud computing was designed for an era that no longer exists. Distributed training across hundreds of thousands of GPUs, real-time inference at the edge, and autonomous agent coordination impose requirements that traditional cloud network designs were never intended to meet. The networks that served the cloud era were architected for north-south traffic, best-effort delivery, and human-scale applications. None of these assumptions hold for AI.
This article presents a framework for transforming cloud network infrastructure for the AI era. It is organized around two components: a four-pillar reference architecture that defines what must be built, and a five-phase implementation roadmap that defines how to execute the transformation. Together, they provide infrastructure transformation leaders with a complete program for preparing their organizations’ physical network infrastructure for the age of AI.
The Four-Pillar Reference Architecture:
The physical network infrastructure for AI-era cloud computing is organized around four interdependent pillars. Each pillar groups related layers of the infrastructure stack. Each depends on the pillars that precede it and enables the pillars that follow.
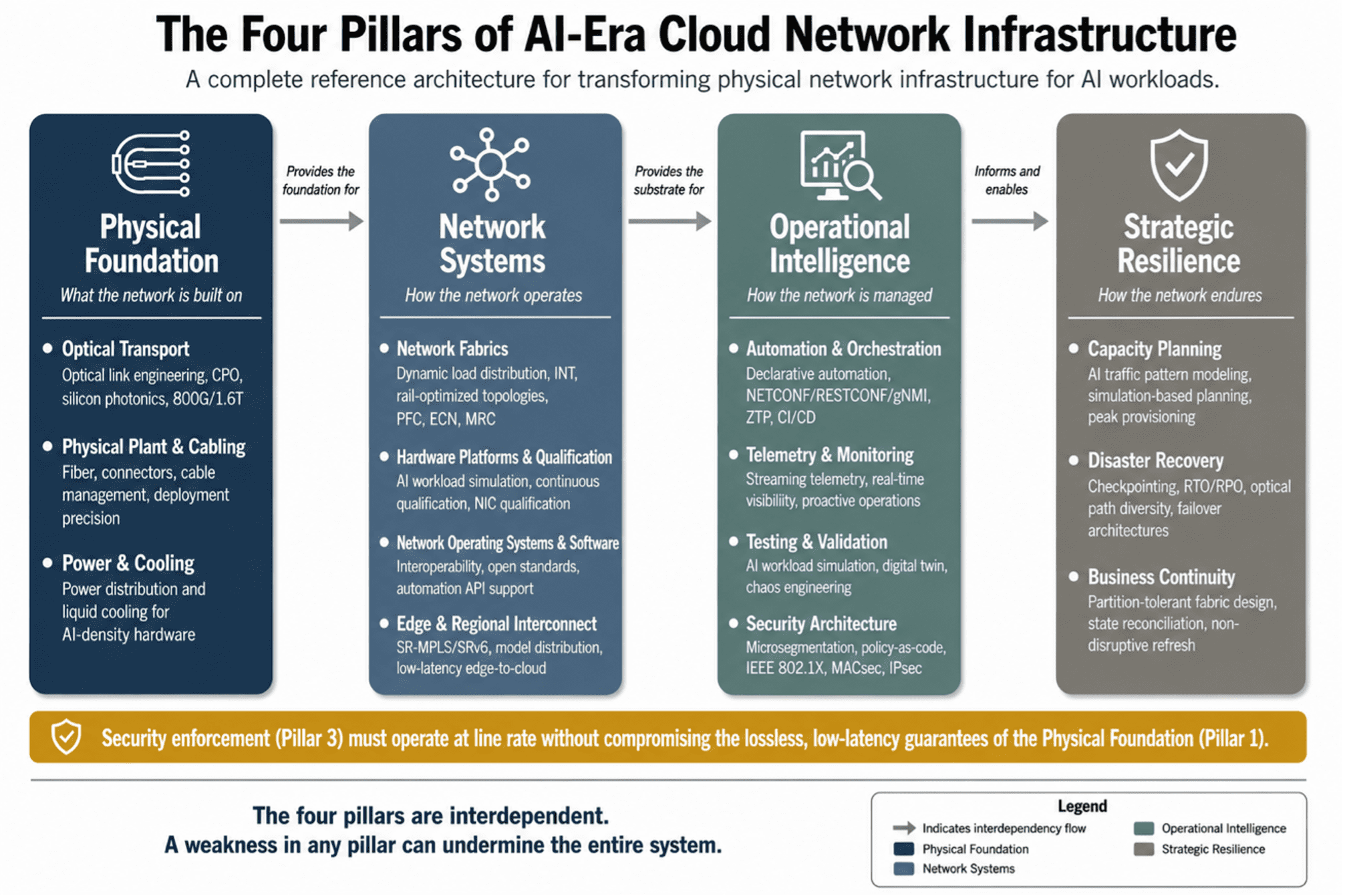
Figure 1: The Four Pillars of AI-Era Cloud Network Infrastructure — a complete reference architecture for physical network transformation.
PILLAR 1: PHYSICAL FOUNDATION
The physical foundation is the literal infrastructure on which all higher-layer network services depend. Optical transport determines the bandwidth, latency, and reliability of every interconnection between data centers, regions, and compute clusters. Physical plant and cabling provide the fiber, connectors, and cable management that make connectivity possible. Power and cooling provide the electrical and thermal infrastructure that keeps everything running.
Optical Transport. Optical link engineering for AI workloads requires a fundamental shift from traditional practice. Traditional optical link engineering treats traffic surges as anomalies and provisions for average utilization. AI workloads generate synchronized, high-bandwidth bursts—checkpointing incast can saturate multiple optical links for minutes at a time—that demand link budgets engineered for peak synchronized demand. The cost of insufficient capacity is not degraded optical performance; it is stalled training runs.
The optical technology roadmap is being reshaped by AI requirements. Co-packaged optics (CPO) integrate the optical engine directly with the switch ASIC, reducing power consumption by 30-50% while increasing port density. Silicon photonics leverage semiconductor manufacturing to produce optical components at scale. 800G and 1.6T per wavelength will be required as GPU bandwidth scales. Linear drive optics remove the digital signal processing from the optical transceiver, reducing power and latency. Breakout optics enable multi-planar topologies where each GPU connects to multiple parallel fabrics. Organizations must ensure that today’s optical investments are forward-compatible with these technologies.
Physical Plant and Cabling. Deployment precision at the physical layer determines whether the architectures designed at higher layers function as intended. Rail-optimized topologies depend on perfect physical cabling—a single miscabled port breaks the single-hop guarantee. Automated cabling verification, where the management interface validates each connection against the reference design, has reduced deployment time by up to 90% for early adopters. Continuous monitoring must detect cabling degradation before it causes performance issues.
Power and Cooling. AI network hardware consumes significantly more power than traditional cloud hardware. A rack of switches populated with 800G pluggable optics can consume over 10 kilowatts. CPO engines may require direct-to-chip liquid cooling. The transition to liquid cooling has implications that extend beyond the network—chilled water systems, heat rejection, building structural load—and retrofitting liquid cooling into a data center designed for air cooling is significantly more expensive than incorporating it into new construction.
PILLAR 2: NETWORK SYSTEMS
Network systems translate the physical foundation into functional network services. Modern data centers operate multiple physical networks—front-end, back-end, storage—each optimized for a specific traffic class. AI training demands a dedicated high-bandwidth, low-latency fabric for GPU-to-GPU communication that must interoperate with existing networks through well-defined interconnection points.
Network Fabrics. AI workloads generate east-west traffic that behaves differently from anything traditional cloud networks were designed to handle. It is dominated by a small number of high-bandwidth elephant flows—sustained, predictable data streams between GPU pairs—that produce synchronized bursts at predictable intervals. Worst-case path latency determines the completion time for collective communication operations, making the performance of the slowest path more important than average performance.
The industry has developed two distinct architectural paths to meet these requirements. For scale-up networks within a single rack or GPU pod, where distances are measured in meters and the cost of a stall is immediate, lossless transport via Priority-Based Flow Control (PFC) and Explicit Congestion Notification (ECN) remains the dominant approach. For scale-out networks connecting GPU clusters across data center halls or buildings, the industry is moving toward efficient utilization with low tail latency through fast recovery rather than absolute loss prevention. The Ultra Ethernet Consortium’s Ultra Ethernet Transport (UET) specification leads this effort, treating packet loss as a recoverable event rather than a failure.
The choice between paths is governed by three criteria: scale of deployment (≤256 GPUs favors lossless; ≥512 GPUs favors low-loss), workload characteristics (tightly coupled training benefits from lossless; loosely coupled inference tolerates low-loss), and organizational maturity (deep PFC expertise extends lossless viability to larger scales).
Four fabric capabilities support both paths. Dynamic load distribution—flowlet switching and packet spray—replaces static Equal Cost Multi-Path (ECMP) with congestion-aware path selection. In-band network telemetry (INT) provides the microsecond-granularity congestion visibility that makes intelligent load distribution possible. Rail-optimized topologies provide single-hop GPU-to-GPU connectivity for the most latency-sensitive collective operations. Advanced transport protocols, add selective retransmission via SACK and NACK that serves both scale-up and scale-out deployments.
Hardware Platforms and Qualification. Hardware must be qualified under AI workload conditions, not standard benchmarks. A switch that performs well under steady-state testing may exhibit unacceptable packet loss under synchronized burst patterns. The qualification process must answer a specific question: will this hardware maintain performance under the traffic patterns that AI workloads generate? Qualification is continuous—a firmware update, a new optics module, or a configuration change can alter behavior and must be validated before reaching production. The endpoint NIC plays a critical role, handling RDMA at line rate, packet-spray reordering, and selective retransmission. NIC qualification must be part of the same AI workload simulation process as switches and optics.
Network Operating Systems. The NOS must support PFC, INT, dynamic load distribution, and automation APIs. Interoperability is an architectural requirement in inherently multi-vendor AI infrastructure. Organizations should prioritize platforms that adhere to open standards—UET specifications, IETF YANG data models, OpenConfig—over proprietary extensions that create long-term supply chain constraints.
Edge and Regional Interconnect. AI inference increasingly occurs at the edge, requiring low-latency connectivity to cloud reasoning agents. Traffic engineering via Segment Routing over MPLS (SR-MPLS) and SR over IPv6 (SRv6) enables explicit path specification for latency-sensitive flows. Model distribution to edge endpoints requires versioned, efficient distribution protocols. Regional interconnect must be treated as a production input, not a shared utility—it is part of the AI supercomputer’s backplane.
PILLAR 3: OPERATIONAL INTELLIGENCE
Operational intelligence provides the control systems that make the network operable at scale. The AI-ready network cannot be managed through manual processes—a single AI cluster may contain thousands of switches requiring consistent configuration, where a single misconfigured buffer can stall thousands of GPUs.
Automation and Orchestration. The architectural response is declarative intent-based automation. The operator declares the desired network state using IETF YANG data models, and the automation framework translates this into device-level configuration via NETCONF, RESTCONF, and gNMI. Zero-touch provisioning enables switches to self-configure from the moment of installation. Configuration-as-code ensures every device conforms to architectural standards, with drift detected and corrected automatically. Network changes move through CI/CD pipelines that validate against policy and test under AI workload conditions before production deployment.
Telemetry and Monitoring. INT captures per-packet, per-path metrics at microsecond granularity. Streaming telemetry replaces polled monitoring with continuous, event-driven data push. The telemetry platform must ingest, store, and analyze millions of data points per second, enabling cross-layer correlation—tracing a GPU-level stall back through the fabric to the specific optical port and wavelength where the loss occurred. Predictive models detect performance degradation before it causes packet loss, shifting operations from reactive to proactive.
Testing and Validation. A dedicated testing environment must replicate production AI workload patterns—synchronized bursts, collective communication operations, checkpointing incast. Fault injection and chaos engineering validate network behavior under failure conditions. A digital twin of the production network, continuously synchronized, within a bounded delay, with real-time telemetry, enables what-if analysis for topology changes, capacity additions, and configuration updates before production deployment.
Security Architecture. Distributed AI dissolves the traditional network perimeter. The architectural response is in-fabric security: microsegmentation at the switch level validates every flow at the point of ingress, policy is bound to workload identity rather than network location, and the enforcement architecture relies on IEEE 802.1X, MACsec, and IPsec. Policy-as-code manages security rules through the same CI/CD pipelines as network configuration. The immutable audit trail serves double duty as both the security record and the compliance record.
PILLAR 4: STRATEGIC RESILIENCE
Strategic resilience ensures the network survives disruptions, scales with demand, and sustains itself over the long term.
Capacity Planning. Traditional capacity planning, based on historical averages and steady-state utilization, systematically underprovisions for AI. AI traffic is bursty, synchronized, and high-volume by design. Capacity must be provisioned for peak synchronized demand. Simulation-based planning models proposed network designs under projected AI workloads, identifying bottlenecks in the design phase before hardware is committed.
Disaster Recovery. AI training runs lasting weeks or months cannot be restarted from scratch. The network must support checkpointing at AI scale, with Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) defined per workload. The optical backbone must provide physically diverse paths with automatic protection switching. Failover architectures—active-active or active-passive—must be designed at the network level for inference workloads requiring high availability.
Business Continuity. The network fabric must tolerate WAN partitions without cascading failures, with local control planes capable of independent operation at each site. State reconciliation architecture—based on the shared event log pattern—must preserve causal ordering across partition boundaries. The network must support non-disruptive infrastructure refresh, with redundant paths and hitless failover enabling component replacement without interrupting workloads that run continuously for weeks or months.
The Five-Phase Implementation Roadmap
The migration from legacy to AI-ready network infrastructure is a multi-phase program that must deliver value at each stage while building toward the target architecture. Each phase has defined activities, deliverables, and success criteria. Each phase delivers measurable value before the next begins. Phase durations are calibrated for a Tier-1 cloud services provider; individual organizational timelines may vary based on scale, complexity, and resource availability. The success criteria stated for each phase are drawn from industry benchmarks and practitioner experience with large-scale network transformation programs. They represent targets that are ambitious but achievable for a Tier-1 cloud services provider with dedicated transformation resources and executive sponsorship.
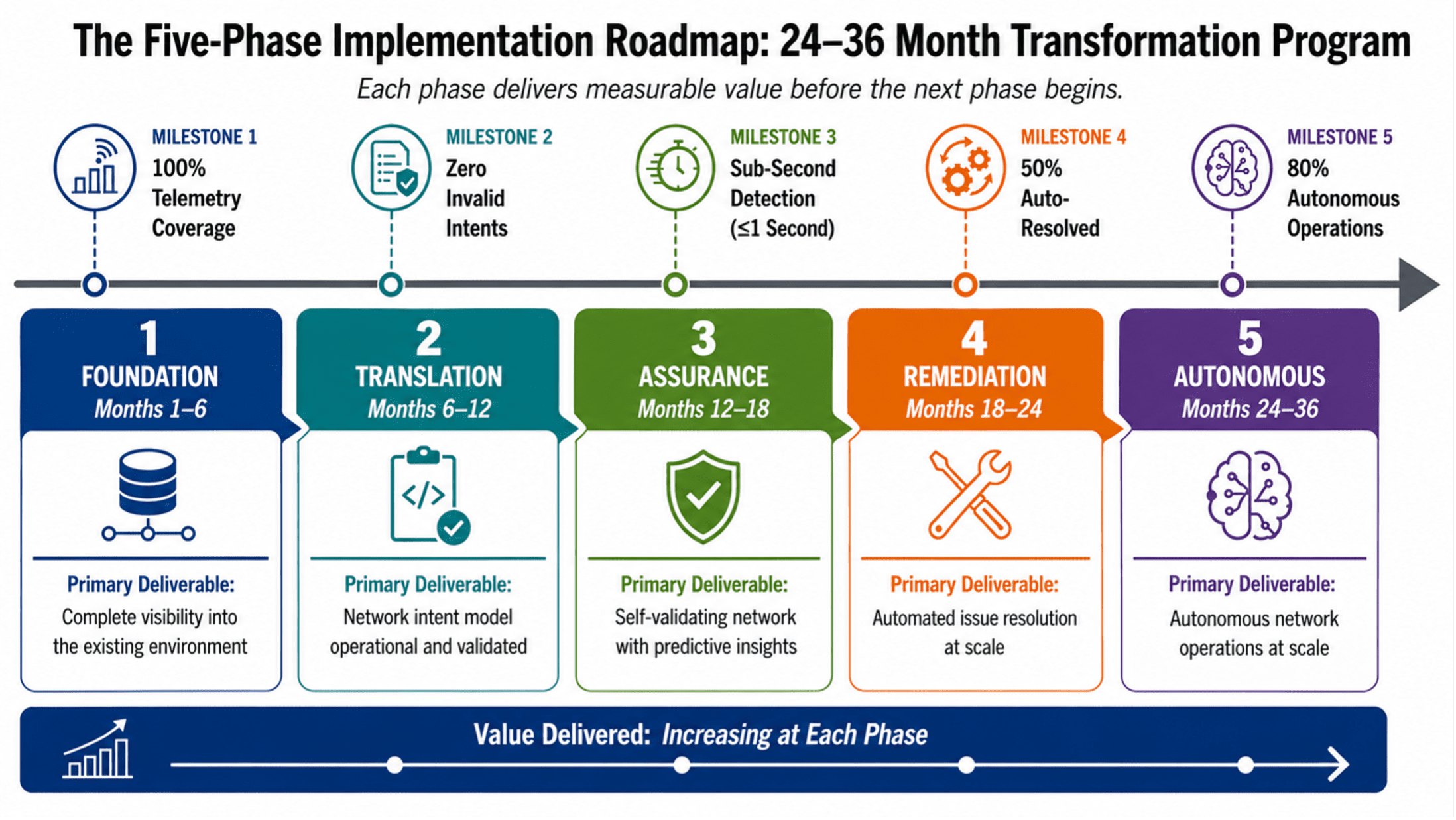
Figure 2: The Five-Phase Implementation Roadmap — A 24–36 Month Transformation Program.
PHASE 1: FOUNDATION (MONTHS 1–6)
The first phase establishes the essential building blocks. Nothing can be automated, optimized, or secured until the network is instrumented and its state is understood.
The starting point is telemetry. Streaming telemetry must be enabled across all network devices in the AI infrastructure path—switches, optics, fabric elements—using gRPC-based protocols and OpenConfig YANG data models. The deliverable is a centralized telemetry platform receiving continuous data streams from every device. The success criterion is 100% telemetry coverage. Without complete visibility, every subsequent phase operates on incomplete information.
With telemetry flowing, a topology knowledge graph must be built—a dynamic map of all devices, links, and interconnections, continuously updated from telemetry data and discovery protocols. The graph must reflect topology changes within seconds, not minutes. Accurate neighbor discovery across all fabric layers is the foundation on which intent-based automation will reason about the network.
Configuration management must be brought under version control. Every device configuration—PFC thresholds, QoS policies, dynamic load distribution parameters—must be stored in version-controlled repositories. Every change must be tracked and attributed. The success criterion is 100% configuration version control with no out-of-band changes permitted. An automation framework that deploys configuration changes cannot operate reliably if changes are also being made through manual processes that bypass the automation pipeline.
Finally, the foundational intent model must be established. This is a structured format for expressing network intent—topology, capacity, QoS policies—in machine-readable YANG-based models. The deliverable is five foundational intents, defined and validated against the existing network state:
- Lossless Transport Intent: “All Remote Direct Memory Access over Converged Ethernet (RoCE) traffic on the AI fabric shall receive PFC priority treatment with zero packet loss under sustained load.”
- Fabric Capacity Intent: “The AI fabric shall maintain a minimum of 30% headroom on all east-west links during peak utilization.”
- Optical Link Diversity Intent: “Every GPU cluster shall have at least two physically diverse optical paths to its checkpoint storage.”
- Configuration Compliance Intent: “All device configurations shall match version-controlled templates. Any deviation shall be detected and flagged within 60 seconds.”
- Telemetry Coverage Intent: “Every device in the AI network path shall stream telemetry data. Any device that stops streaming shall be flagged within 30 seconds.”
These five intents are scoped to be achievable within Phase 1 while covering the most critical dimensions of AI network operations: lossless transport, capacity, resilience, configuration compliance, and observability.
PHASE 2: TRANSLATION (MONTHS 6–12)
The second phase builds the machinery that translates intent into device-level configuration. This is where declarative automation becomes operational.
The centerpiece is the intent compiler—a translation engine that converts YAML or JSON intent specifications into device-level configuration via NETCONF, RESTCONF, and gNMI. The intent compiler is not merely a template engine. It must understand the capabilities and constraints of each target device, select the appropriate protocol for each configuration operation, and handle the transactional semantics that make configuration changes safe. The success criterion is that the five foundational intents from Phase 1 are compiled and deployed without manual intervention.
Before any compiled configuration reaches production, it must be validated in a digital twin—a virtual replica of the AI network, continuously synchronized with production telemetry. The digital twin enables what-if analysis: if this configuration is applied, what happens to fabric utilization, PFC pause events, and flow completion times? The success criterion is 100% of configuration changes validated in the digital twin before production deployment.
Validation checks must be automated. Every intent must pass feasibility validation (can the network support this intent given current capacity?), capability validation (do the target devices support the required features?), and policy validation (does this intent comply with security and operational policies?). The success criterion is zero invalid intents deployed to production.
Multi-domain support must be enabled. The intent compiler must support both data center fabric and optical backbone domains, translating a single intent into coordinated configurations across domains.
PHASE 3: ASSURANCE (MONTHS 12–18)
The third phase closes the loop between intent and reality. The network may be configured correctly at a point in time, but AI workloads cause continuous change—congestion patterns shift, optical performance degrades, buffer utilization fluctuates. Assurance ensures the network remains in its intended state.
Real-time telemetry monitoring must track SLA compliance for all AI network services, updated continuously from streaming telemetry rather than periodically from polled data. Sub-second detection latency for SLA deviations is the success criterion. A RoCE stall that lasts 500 milliseconds must be detected while it is happening, not after the training run has been disrupted.
Drift detection must compare the intended network state against the actual state continuously. Drift can take many forms: a configuration change applied outside the automation pipeline, a performance degradation that violates the intent without changing the configuration, a topology change due to a link failure. The success criterion is 99% detection accuracy for both configuration and performance drift.
The assurance dashboard must provide all stakeholders—network operations, compute operations, capacity planning—with real-time visibility into network state versus intent. Alerting must be integrated with the incident management system so that 100% of SLA breaches generate alerts within one second of detection.
PHASE 4: REMEDIATION (MONTHS 18–24)
The fourth phase enables the network to respond to drift and failures. Detection without response is observation without action. Remediation closes the loop.
Root cause analysis (RCA) must be automated. When drift is detected, the system must correlate telemetry data across layers—optical, fabric, device—to identify the source. A packet loss event at the GPU layer may originate from a congested optical link three hops away. The RCA engine must trace the event across layers. The success criterion is greater than 80% accuracy for common incident types.
At least three remediation types must be implemented and validated in the digital twin before production enablement: rollback to the last known good configuration, traffic rerouting around congested or failed links, and dynamic QoS adjustment.
A policy engine must govern which remediation actions are fully automated, which require human approval, and which are prohibited. The policy framework must be machine-readable, version-controlled, and enforced at the automation layer. The success criterion is 100% of automated remediation actions comply with defined policies.
Supervised remediation must enable a human-in-the-loop approval workflow for actions that exceed the automated threshold. The goal is that 50% of detected issues are resolved automatically without human intervention, with the remainder escalated for approval.
PHASE 5: AUTONOMOUS (MONTHS 24–36)
The final phase extends over 12 months—longer than the preceding phases—because full autonomy is not a single deployment event. It requires progressive expansion of automation scope, validation of continuous optimization across diverse workload patterns, and accumulation of sufficient operational data for the learning system to deliver meaningful accuracy improvements. Each increment of autonomy must be earned through demonstrated reliability.
The automation scope must be expanded to cover all common incident types identified and validated in Phase 4. The success criterion is that 80% of all incidents are resolved automatically. The remaining 20% represent novel failures, complex multi-domain incidents, or situations where policy requires human judgment.
Continuous optimization must become a background process. The network self-tunes PFC thresholds based on observed congestion patterns, adjusts dynamic load distribution policies as workload distributions shift, and reallocates buffer resources as traffic characteristics evolve. The success criterion is a 20% reduction in SLA violations compared to the Phase 3 baseline.
Cross-domain coordination must achieve full automation for standard intents. When a new GPU cluster is provisioned, the orchestration layer coordinates optical link provisioning, fabric configuration, and security policy establishment across domains without manual intervention. Human involvement is reserved for novel or high-risk changes.
The learning system must improve from experience. Machine learning models trained on historical incident and remediation data must increase root cause analysis accuracy over time. The success criterion is a 10% quarterly improvement in RCA accuracy.
COEXISTENCE: RUNNING LEGACY AND AI-READY NETWORKS IN PARALLEL
The transformation cannot be accomplished through a flag-day cutover. The existing cloud network must continue to operate and generate revenue throughout the transition. The AI-ready network is deployed as a separate physical infrastructure—dedicated optical links, dedicated fabric, dedicated switches—wherever possible. Physical separation eliminates the risk that AI workload traffic patterns will disrupt legacy services. Where physical separation is impractical, logical isolation with strict QoS enforcement provides the necessary workload separation. Interconnection points between the two networks must be engineered with the same packet loss, latency and throughput requirements as the AI-ready network. Operational processes must govern both environments simultaneously during a transition measured in years.
ORGANIZATIONAL TRANSFORMATION
The AI-ready network cannot be operated by a team trained only on legacy network operations. Three new skill domains become critical: AI workload literacy (understanding the traffic patterns and failure modes of distributed training and inference), telemetry and data engineering (building and operating streaming telemetry platforms and correlation engines), and automation engineering (designing and operating intent-based automation and CI/CD pipelines). The talent strategy must balance retraining existing engineers—many of the required skills are extensions of existing knowledge—with external hiring for skills that cannot be developed internally in the required timeframe. Retention of critical talent during the transformation is essential: the engineers who understand the legacy infrastructure are essential to the coexistence strategy.
FINANCIAL MODELING
Network investment for AI must be justified on value generation—the network cost per training run completed, per inference served, per GPU-hour utilized—not traditional cost efficiency metrics. This shift from cost-per-bit to value-per-outcome transforms the investment conversation. A network that costs more per gigabit but enables higher GPU utilization generates a return that far exceeds its cost premium. The five-phase roadmap enables investment to be spread over 24 to 36 months, with each phase delivering measurable value before the next begins. The cost of inaction must be quantified and presented alongside the cost of transformation.
CONCLUSIONS:
The physical network is no longer a utility layer that can be taken for granted. It is the foundation on which AI performance depends. The optical backbone determines whether GPU clusters operate at full utilization or sit idle. The network fabric determines whether distributed training completes in days or weeks. The automation and telemetry infrastructure determines whether issues are detected proactively or discovered after customer impact.
The four-pillar reference architecture defines what must be built. The five-phase implementation roadmap defines how to execute the transformation. Together, they form a complete program for infrastructure transformation leaders.
The technologies described here are deployed and operational in production AI networks today. The challenge for infrastructure leaders is not whether these approaches work, but how to adapt them to their organization’s specific constraints, scale, and timeline.
REFERENCES:
[1] TM Forum, “Autonomous Networks: Business Requirements and Framework,” TM Forum IG1251, 2025. [Online].
[2] AMD, “Next Gen Networking Transport for Large Scale AI Training,” May 2026. [Online].
htt
[3] Tolly Group, “Dell Networking Data Center AI Switch Fabric Congestion Mitigation Evaluation,” April 2026. [Online].
[4] Tech Field Day, “Cisco AI Networking Cluster Operations Deep Dive,” November 2025. [Online].
htt
[5] Akamai / WWT, “East-West Is the New North-South: Rethink Security for the AI-Driven Data Center,” February 2026. [Online]. htt
[6] NIST, “Zero Trust Architecture,” NIST Special Publication 800-207, Aug. 2020. [Online].
[7] IETF, “Network Configuration Protocol (NETCONF),” RFC 6241, June 2011. [Online].
[8] IETF, “RESTCONF Protocol,” RFC 8040, January 2017. [Online]. htt
[9] IEEE, “Priority-based Flow Control,” IEEE Standard 802.1Qbb, 2011.
[10] IEEE, “Congestion Notification,” IEEE Standard 802.1Qau, 2010.
[11] OpenConfig, “OpenConfig: Vendor-Neutral Network Configuration and Telemetry,” [Online]. https://www.
[12] Cloud Native Computing Foundation, “gRPC: A High-Performance, Open Source Universal RPC Framework,” [Online]. https://grpc.io/
[13] Ultra Ethernet Consortium, “Ultra Ethernet Specification,” [Online]. https://
………………………………………………………………………………………………………………………………………………………….
References from IEEE Techblog:
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
The enterprise network stack is collapsing; AI’s impact; comparison with “Batch Pipelines Break AI Agents”
ABOUT THE AUTHOR:

Shazia Hasnie, Ph.D., is VP Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale. She brings over 20 years of global experience in communications networks and holds a Ph.D. in Communications Engineering from the Australian National University.
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Executive Summary:
Consumer-driven AI traffic [1.] currently represents a marginal share of aggregate Internet traffic. However, accelerating adoption of agentic AI is expected to materially reshape traffic composition over the next decade. In its “AI Impact on Wide Area Networks” report, Cisco projects that AI will emerge as the dominant driver of network traffic growth. As consumer AI adoption approaches “near-universal usage,” AI and agentic AI are forecast to increase consumer-driven network traffic by approximately 6.6× by the mid-2030s (see chart below).
Cisco estimates that this AI expansion will account for roughly 63% of incremental traffic growth relative to non-AI scenarios. The study focuses specifically on WAN implications, rather than data center or GPU infrastructure, and provides guidance on network design and capacity planning. Methodologically, the report integrates real-world traffic observations (via Cisco Crosswork Assurance User Experience), third-party industry datasets, and controlled laboratory evaluations of AI agents to characterize how AI-generated traffic diverges from conventional web traffic patterns.
Token-consumption data shows nearly 10x year-over-year growth, while in some service provider measurements Cisco is seeing ~4x growth in just eight months. Sustained growth at these rates means AI traffic will become a meaningful component of overall network traffic by 2035.
Note 1. Consumer AI traffic has a few defining technical traits: it is still dominated by short text-based exchanges, but it is becoming more stateful, more upstream-heavy, and more latency-sensitive as users move from simple prompts to agentic workflows and multimodal interactions. Today’s consumer AI traffic is still overwhelmingly text-oriented, which is one reason the aggregate bandwidth impact remains modest despite rapid adoption. Comcast’s network observation is a useful real-world proxy: 97.1% of AI traffic was text-based, while images accounted for 2.6% and video only 0.3%. The key technical implication is that current traffic volumes are often limited more by conversation frequency and session behavior than by very large payloads, though that changes quickly as users adopt image, audio, and video generation.
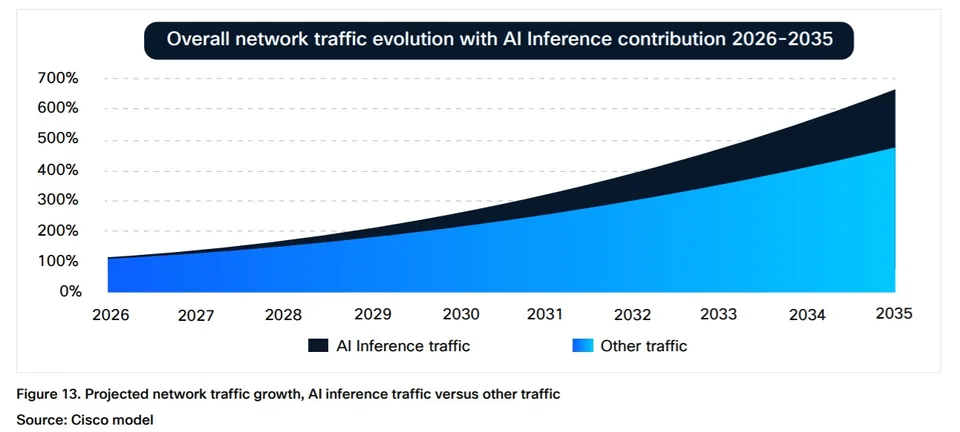
Although AI inference traffic is currently “negligible” relative to dominant categories such as video streaming, Cisco projects it will comprise approximately 25% of total network traffic by 2035 (see chart below). At that point, AI traffic is expected to represent a “meaningful component” of overall network load. Importantly, AI-generated traffic exhibits distinct characteristics: inference flows are approximately twice the duration of typical web transactions, demonstrate higher upstream bandwidth demand, and operate at “software speed” rather than human interaction rates.
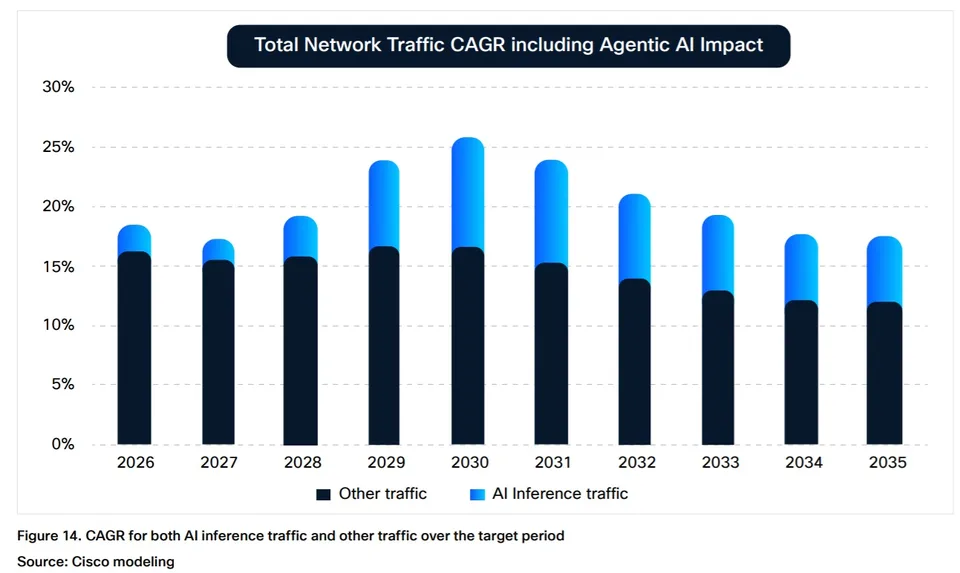
The emergence of AI agents as “power users” further amplifies these dynamics. Cisco notes that agent-executed tasks can generate up to 450% more traffic per task compared to human-driven interactions. This shift is expected to drive operator adoption of “flow-aware network and security systems” as traffic patterns become increasingly machine-driven and less predictable.
Cisco’s broader framing is that AI traffic “isn’t just adding traffic,” but is changing the shape of traffic, with inference flows running about twice as long as typical web transactions and, in some cases, generating up to 450% more traffic per task when an agent executes the workload. AI inference sessions tend to hold resources longer, create more sustained flows, and push operators to think in terms of flow-aware behavior rather than only peak-throughput sizing. Cisco also notes that about 9% of AI inference flows carry more upstream than downstream traffic, versus about 0.5% for typical web traffic, which is a meaningful shift for access and broadband networks. Cisco reports that approximately 9% of AI inference flows are upstream-dominant, compared to roughly 0.5% for traditional web traffic, with this divergence expected to widen alongside increased agentic AI utilization. In parallel, latency sensitivity is anticipated to become a more critical performance parameter for AI-driven applications.
Latency and symmetry:
AI traffic is also more sensitive to latency than many ordinary consumer web transactions because the user experience is often conversational and interactive, with the expectation of near-immediate turn-taking. Cisco describes AI inference as operating at “software speed” rather than human speed, which means small delays can be more noticeable and operationally important. At the same time, upstream demand becomes more significant because prompts, context, attachments, and agent-generated actions can increase return-path traffic, especially as multimodal inputs and agentic tool use expand.
Multimodal growth:
The biggest step-up in technical impact comes when consumer AI shifts from text-only prompting to multimodal generation and agent-driven workflows. In those cases, each task can involve multiple model calls, retrieval steps, tool invocations, and richer media payloads, which expands both flow count and bytes per session. Cisco’s study suggests that this is why AI traffic will increasingly require “flow-aware network and security systems,” because the traffic profile is not just larger, but structurally different from conventional browsing.

Infrastructure Implications:
Telecom infrastructure is becoming “increasingly intertwined with hyperscale infrastructure, not because operators are leading AI investment, but because they are becoming part of the ecosystem that supports it,” analyst firm MTN Consulting said in an April 27th research note. “Demand for optical transport, data-center interconnect, and edge infrastructure is rising as telecom networks carry growing volumes of cloud and AI-driven traffic,” the firm said.
“AI network traffic is already reshaping infrastructure needs. What we are seeing is clear: AI isn’t just adding traffic. It’s changing the shape of traffic,” Javier Antich, principal product management engineer in the CTO office of Cisco’s provider connectivity group, and Gurudatt Shenoy, SVP, product management, provider connectivity, explained in this blog post.
These shifts are beginning to influence access network evolution. Fiber networks already provide relatively symmetric throughput and low latency, while cable operators are advancing similar capabilities through DOCSIS upgrades. Mid-split and high-split architectures increase upstream spectrum allocation, enabling more balanced capacity profiles. Concurrently, Tier 1 operators such as Comcast and Charter Communications are introducing low-latency enhancements within DOCSIS networks.
Operational data reflects early-stage impacts. Comcast Chief Network Officer Elad Nafshi noted at the Cable Next-Gen event in March that approximately 97.1% of AI traffic on Comcast’s network remains text-based, with images accounting for 2.6% and video just 0.3%, indicating that bandwidth-intensive multimodal AI traffic has yet to scale materially.
Network design impact:
For broadband and access networks, the immediate engineering issues are upstream traffic capacity, queue behavior, and latency consistency rather than raw total throughput alone. Symmetry upgrades (such as DOCSIS mid-split and high-split for MSOs), along with low-latency capabilities, are relevant because consumer AI creates more return-path pressure and more time-sensitive sessions. In other words, the challenge is not simply to carry more bytes; it is to carry more interactive sessions with predictable performance, especially as multimodal and agentic usage scales.
………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
Telecom data centers must be redesigned for the AI era with rack scale architectures, enhanced power & cooling requirements
Is the “far edge” a bridge to far to cross for AI inferencing? What about “Distributed AI Grids”?
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Inside Nokia’s new AI Networking Innovation Lab
- Silicon & Compute: Collaborating with AMD to optimize enterprise AI workloads alongside Nokia data center switches.
- Testing & Infrastructure: Partnering with Keysight Technologies to emulate workloads across Ultra Ethernet Consortium (UEC) and RoCEv2 transports.
- Hardware & Servers: Integrating high-performance platforms from Lenovo and Supermicro.
- Data Storage & Cloud: Working with Weka and cloud builders like Nscale to eliminate storage bottlenecks during heavy computational training.

Nokia’s AI Networking Innovation Lab is built upon three fundamental pillars: Technology Innovation, Ecosystem Collaboration, and Validation. Image credit: Nokia
………………………………………………………………………………………………………………….
Technology Innovation: The lab provides a dedicated space for AI partners to experiment with next-gen solutions across the entire networking stack – driving emerging standards forward with pioneering approaches to new protocols, switching silicon, congestion control, real-time telemetry, and automation.
“Partnering with Nokia in the AI Networking Innovation Lab has enabled us to benchmark and optimize AI networks under real-world conditions…Together, we are helping accelerate AI network adoption by giving operators and hyperscalers the validated insights needed for confident, large-scale deployment.”
Ecosystem Collaboration: True progress depends on a strong ecosystem of technology providers – silicon manufacturers, GPU developers, system, storage and test vendors, and cloud platforms – that work together to create highly-compatible AI-ready solutions. This facilitates joint testing for interoperability, improves integration, and ensures roadmaps are aligned across different hardware, software, and orchestration layers.
Travis Karr, Corporate Vice President, HPC and Sovereign AI at AMD believes customer collaboration and an open ecosystem are fundamental to accelerating AI innovation:
“By co-developing solutions with partners, such as Nokia in their AI networking innovation lab, we ensure our AMD enterprise AI solutions are tested with Nokia data center switches on real-world workloads and network demands. An open, standards-driven approach empowers customers to integrate seamlessly across heterogeneous environments, avoiding lock-in and fostering industry-wide advancement in AI.”
Validation: This positions the lab as the testing ground for Nokia Validated Designs, where customers and partners rigorously validate multi-vendor data center architectures under authentic AI training and inference workloads. By testing failure scenarios, congestion behavior, and operational automation, the lab turns NVDs into proven, deployable solutions — enabling predictable performance, faster deployment, and reduced operational complexity and risk for organizations navigating the AI era.
Arno van Huyssteen, Vice President of Global Telecommunications for Nscale:
“Nokia is a strategic networking partner for Nscale as we build towards AI Grid, and the engineering rigour behind their Validated Designs reflects the kind of innovation needed to enable next-generation AI infrastructure. The depth of hardware, software and failure testing behind those blueprints is what will give operators the confidence to deploy complex AI environments faster, with fewer integration risks and less operational disruption. We’re excited to collaborate in the AI Networking Innovation Lab to help push the boundaries of AI-native networking and validate the next generation of solutions before they reach production.”
A primary focal point inside the lab is managing data center congestion. Unlike traditional cloud traffic, back-end AI networks feature high-density data synchronization across massive GPU clusters. The lab uses advanced automation, AIOps, and lossless Ethernet solutions—such as the Nokia 7220 IXR-H6 switches—to handle these intense uplink and synchronization demands safely.
The AI Networking Innovation Lab supports Nokia’s broader strategy to accelerate the next era of AI-driven connectivity. As demand for AI infrastructure continues to grow, data center networking has become one of the most critical foundations of the global AI ecosystem. Through this investment, Nokia is strengthening its capabilities in AI and cloud infrastructure while advancing its vision of AI-native networking.
Rudy Hoebeke, Vice President of Software Product Management at Nokia:
“The launch of Nokia’s AI Networking Innovation Lab marks a major milestone in our commitment to drive the next era of AI-native connectivity. As the industry continues to evolve with solutions like scale-across and AI-Grid, this lab is poised to accelerate AI networking technology that will not only support but optimize these emerging industry offerings. This center gives our customers and partners early access to new technologies, deeper collaboration with the world’s leading AI ecosystem players, and the confidence that their networks are validated under more realistic AI conditions. By accelerating innovation and reducing deployment risks, we’re enabling the industry to deliver faster, more reliable, and more sustainable AI experiences to people and businesses everywhere.”
………………………………………………………………………………………………………………………
References:
Analysis: Nokia’s strong growth in Optical Networks and AI network infrastructure
Orange, Nokia, Nvidia, and Intel debate: ASICs vs. GPUs vs. General-Purpose CPUs for RAN Baseband Processing
Nokia’s AI Applications Study: “Physical AI” may require RAN redesign to support high‑volume, low‑latency uplink traffic
Australia’s NBN and Nokia demonstrate multi-generation optical technologies concurrently over existing FTTP infrastructure
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Tampnet to expand 5G offshore connectivity in the Gulf of Mexico using Nokia AirScale 5G radios
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Is the “far edge” a bridge to far to cross for AI inferencing? What about “Distributed AI Grids”?
How Far is the Far Edge?
As major telcos size up distributed edge sites for a possible AI inferencing model, they’re trying to determine how far out the right place is in their networks to invest in AI computing capacity. According to Light Reading, the “far edge” is a divisive option for inferencing. According to Omdia, owned by Informa, the Far edge includes: radio access network (RAN) cell sites, aggregation hubs, exchange offices, optical line terminal (OLT) nodes, and Tier 2 metro hubs.
Many telcos are struggling to define how far is the edge from customer premises and how to serve various use cases with compute and intelligence? It seems that 5G SA core with network slicing would be mandatory to support multiple unique use cases, each with different QoS requirements.
According to Omdia’s Telco Edge Computing Survey last year, just 15% of telcos ranked network far edge as the top location for where most AI inferencing will take place, while even less (11%) said the network near edge would be the main spot (which includes central offices, headend sites and large telco data centers). The results showed AI inferencing is expected to be handled mostly on the end devices themselves and at the enterprise edge (e.g., offices, campus or manufacturing sites).
Kerem Arsal, Omdia senior principal analyst for telco enterprise and whoIe sale, predicted in a research note that this year will see telcos split into camps of “believers” and “doubters” of the far edge.

Image Credit: Sphere
…………………………………………………………………………………………………………………………………………………………………………………………………………………..
AT&T VP Yigal Elbaz, speaking at the recent New Street Research and BCG Global Connectivity Leaders Conference, expressed a cautious view on AI compute at the “far edge,” questioning how far the edge truly needs to extend to serve specific use cases effectively. He said the following (Source: Light Reading)
“The proliferation of compute and high-performing compute across the nation, in all metros is just happening, with a software layer on top of this [and] with the tools that developers need. So, I am not sure that there’s much value in extending that compute all the way to the far edge just to save another millisecond or two milliseconds of latency.”
“AT&T’s fiber and wireless networks can provide the “deterministic experience” needed between any new use cases and help them to “intelligently connect to the right model that they use, the context or the infrastructure that they need because that’s going to be heavily distributed across the US.”
“There’s no doubt that that AI is going to be embedded into wireless networks, and we’re going to call it AI-native and combine the physical space with the intelligence of the network. This is all true,” said Elbaz.
………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Distributed AI Grids:
- Ethernet with RDMA (RoCE): The foundation is built on Nvidia Spectrum-X Ethernet, which utilizes RDMA over Converged Ethernet (RoCE). This allows for direct memory access between edge GPUs (e.g., Nvidia RTX PRO 6000 Blackwell Server Edition) and the network core, bypassing CPU overhead to achieve near-line-rate performance.
- Scale-Across Networking: Using Nvidia Spectrum-XGS, the architecture extends standard RoCE to scale across geographically distributed sites. This creates a unified “AI Factory Grid” where remote edge nodes function as a single, programmable compute substrate.
- Silicon One Routing: Cisco’s Silicon One-based routing is utilized for AI-optimized traffic management, providing the high-speed, high-density throughput required for token-intensive inference workloads.
- Zero Trust & Secure Pathways: The interconnect includes a Zero Trust security layer embedded directly into the fabric. It utilizes localized traffic breakout and policy-enforced pathways to ensure that sensitive IoT and video data (such as public safety feeds) remain within the customer’s secure domain at the network edge.
- Orchestration Control Plane: A workload-aware control plane manages these protocols to intelligently route tasks based on real-time KPIs (latency, cost-per-token, and data sovereignty), ensuring that “mission-critical” inference happens at the optimal node.
- Proprietary Software Lock-in: Integrating network functions into a proprietary ecosystem (like Nvidia’s CUDA or AI Aerial) can create a “subscription trap,” where software is inseparable from specific hardware, making it nearly impossible to swap vendors without a total architectural overhaul.
- Data Fragmentation: Deploying AI across a distributed grid often leads to fragmented data sets across legacy and new multi-vendor platforms, which can result in inaccurate AI models and increased operational complexity.
- Standardization Lag: While industry bodies like the GSMA are pushing for Open Telco AI standards, the rapid deployment of proprietary AI systems often outpaces these frameworks, leading to entrenched, incompatible systems that require significantly more resources to reconcile later.
- Integration with Legacy Systems: Modern “agentic AI” and AI-native stacks often struggle to orchestrate processes across siloed legacy infrastructure, creating rigid operational environments that prevent the seamless flow of data needed for automated network troubleshooting.
Bottom Line: While the AI Grid may offer a more viable roadmap than AI-RAN, there is insufficient industry discourse regarding the strategic risks of a global, geographically distributed computing platform—as Nvidia defines it—reliant on a single-vendor hardware stack. Although Nvidia currently maintains undisputed market dominance, historical precedents such as Intel serve as a cautionary tale; long-term dominance is never guaranteed, and even market leaders face potential obsolescence. Furthermore, Nvidia’s practice of providing capital injections to entities that subsequently re-invest those funds back into Nvidia’s own ecosystem raises significant concerns regarding market sustainability and long-term financial health.
References:
https://www.lightreading.com/ai-machine-learning/at-t-cto-casts-doubt-on-ai-compute-at-the-far-edge
https://www.lightreading.com/5g/nvidia-lines-up-ai-grid-as-orange-cto-echoes-the-ai-ran-doubts
Edge AI Computing Explained: Key Concepts and Industry Use Cases
Will “AI at the Edge” transform telecom or be yet another telco monetization failure?
Analysis: Edge AI and Qualcomm’s AI Program for Innovators 2026 – APAC for startups to lead in AI innovation
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
Nvidia’s networking solutions give it an edge over competitive AI chip makers
AWS to deploy AI inference chips from Cerebras in its data centers; Anapurna Labs/Amazon in-house AI silicon products
Amazon Web Services (AWS) announced it plans to integrate AI processors from Cerebras Systems [1.] into its data centers, signaling growing confidence in the AI-focused semiconductor startup. Under a new multiyear partnership announced Friday, AWS will deploy Cerebras’s Wafer-Scale Engine (WSE) to accelerate inference workloads—the stage of AI operations where models generate responses to user queries. Financial details of the agreement were not disclosed.
Note 1. Founded in 2015 and headquartered in Sunnyvale, CA, Cerebras claims to have the world’s fastest AI inference and training platform.
The collaboration reflects a significant realignment in compute infrastructure strategies across the AI ecosystem. While initial industry focus centered on model training, the rapid expansion of deployed AI services is driving demand for optimized inference performance. Traditional GPUs, though unmatched for training, can be suboptimal for inference scenarios that require ultra-low latency and high throughput. Cloud and AI platform providers are therefore diversifying their silicon portfolios to better match workload profiles and to scale capacity efficiently.
AWS, the world’s largest cloud infrastructure provider, has traditionally relied on its in-house semiconductor division, Annapurna Labs, for custom chip design. Annapurna’s Trainium processors compete with GPUs from major suppliers such as Nvidia and AMD, offering cost and performance advantages for AI training workloads. The new partnership introduces Cerebras technology into AWS infrastructure, where it will work alongside Trainium to enhance large-scale inference capabilities.
Cerebras, best known for its wafer-scale architecture, markets its WSE processors as a high-speed inference platform capable of executing the decode phase of generative AI processing—where text, images, or other outputs are generated—at up to 25 times the speed of conventional GPU solutions. The company, valued at approximately $23 billion following a $1 billion funding round in February, has attracted backing from Fidelity, Benchmark, Tiger Global, Atreides, and Coatue.

The Cerebras deal underscores a major shift in the market for computing power. Image Credit: rebecca lewington/cerebras syste/Reuters
The AWS collaboration follows Cerebras’s major compute partnership with OpenAI, which reportedly involves deploying up to 750 MW of computing capacity powered by its chips. AWS and Cerebras will position their joint offering as a premium cloud inference solution, targeting enterprise AI developers requiring high-performance and scalable compute.
“The scale of AI demand is shifting from model creation to global deployment,” said Andrew Feldman, CEO of Cerebras. “Working with AWS aligns our technology with the industry’s largest cloud, giving us reach to a broad enterprise and developer base. If you want slow inference, there will be cheaper ways to go,” Feldman said. “But if you want fast tokens, if speed matters to you, if you’re doing coding or agentic work, not only are we the absolute fastest, but we intend to set the bar. We’re in this to win it.”

AWS and Cerebras will support both aggregated and disaggregated configurations. Disaggregated is ideal when you have large, stable workloads. Most customers run a mix of workloads with different prefill/decode ratios, where the traditional aggregated approach is still ideal. The start-up expects most customers will want access to both and the ability to route workloads to whichever configuration serves them best.
The move intensifies competition in the inference silicon segment, where Nvidia faces growing pressure from purpose-built processor architectures such as Cerebras’s WSE and other emerging alternatives. Nvidia, which recently announced a $20 billion licensing deal with Groq and plans to unveil a new inference-optimized platform, remains the dominant supplier but now contends with an accelerating wave of specialization across the AI compute stack.
AWS vice president and Annapurna Labs co-founder Nafea Bshara emphasized the company’s goal of offering flexible performance tiers. “Our job is to push the speed and lower the price,” he said, noting that AWS will continue to offer cost-optimized Trainium-only options alongside high-performance Cerebras-Trainium configurations.
………………………………………………………………………………………………………………………………………………………………………………………………….
Amazon’s Internally Designed AI Silicon:
Amazon has built a fairly broad internal AI-oriented silicon portfolio through Annapurna Labs, primarily for AWS:
-
Inferentia (Inferentia, Inferentia2) – Custom machine learning accelerators designed for high-throughput, low-cost inference at cloud scale. These power many AWS inference instances and are positioned as an alternative to Nvidia GPUs for production model serving.
-
Trainium (Trainium, Trainium2, Trainium3) – AI training accelerators optimized for large-scale model training (including frontier and foundation models), with Trainium2 and Trainium3 as newer generations offering materially higher performance and better $/compute than the first generation. These are central to projects such as the Rainier supercomputer for Anthropic.
-
Graviton (Graviton, Graviton2/3/4) – Arm-based general-purpose CPUs used heavily across EC2, increasingly in AI-adjacent roles (pre/post-processing, orchestration, model-serving microservices) and as part of cost-optimized AI stacks, even though they are not dedicated accelerators.
-
Nitro system – While not an AI accelerator per se, the Nitro family (offload cards and system) is an internally developed data-plane and virtualization offload architecture that underpins EC2 and works in tandem with Graviton, Inferentia, and Trainium to free CPU cycles and improve I/O for AI/ML workloads.
All of these are designed and iterated internally by Annapurna Labs for exclusive use in AWS data centers, then exposed to customers via AWS services rather than as standalone merchant silicon.
Amazon’s Annapurna Labs is an internal chip design group that has become a core strategic asset for AWS, especially for custom data center and AI silicon.
Origins and acquisition:
-
Annapurna Labs is an Israeli chip design startup founded in 2011 by semiconductor veterans of Intel and Broadcom, including Avigdor Willenz and Nafea Bshara.
- “When we talked with market sources and consulted with experts in the fields of data and servers, at that time only Amazon had a holistic vision and the ability to execute on a large scale,” recalls Bshara about the start of the romance with Amazon. “We were prepared to build the technology and at the same time were open to working with startups. From there we began a journey together with many meetings and shared thinking, among others with James Hamilton (Microsoft’s former data-base product architect and to AWS SVP), and from there within six months we found ourselves inside Amazon.”
-
Amazon began working with the company around 2013 and acquired it in 2015 for an estimated $350–$400 million.
-
Before the deal, Annapurna was in stealth, focusing on low‑power networking and server chips to improve data center efficiency.
Role inside Amazon and AWS:
-
Post‑acquisition, Annapurna was folded into AWS as a specialist microelectronics and custom silicon group, designing chips to reduce cost and power per unit of compute.
-
The group underpins several key AWS technologies: the Nitro system for offloading virtualization and I/O, Arm‑based Graviton CPUs for general compute, and Trainium and Inferentia accelerators for AI training and inference.
-
These chips let AWS optimize performance per watt and per dollar versus x86 servers and third‑party accelerators, improving margins and competitive pricing.
Key products and architectures:
-
Nitro: A combination of custom hardware and software that offloads storage, networking, and security functions from the host CPU, increasing tenant isolation and freeing CPU cycles for workloads.
-
Graviton: A family of Arm‑based server CPUs; by 2018 Graviton was widely adopted on AWS and is now used by most AWS customers for general cloud infrastructure workloads due to better price‑performance and energy efficiency.
-
Inferentia and Trainium: Custom accelerators designed by Annapurna for machine learning inference (Inferentia) and training (Trainium), intended to reduce AWS’s dependence on high‑priced Nvidia GPUs for AI workloads.
Strategic importance and AI focus:
-
Annapurna’s work is central to Amazon’s strategy of vertical integration in the cloud: owning the silicon stack as much as the software and services.
-
The group designs chips that power Amazon’s AI infrastructure, including systems used both by internal teams and external customers such as Anthropic, for which AWS is the primary cloud and silicon provider.
-
Amazon and Anthropic are collaborating on “Project Rainier,” a massive supercomputer built around hundreds of thousands of Annapurna‑designed Trainium2 chips, targeting more than five times the compute used to train current frontier models.
Organization, footprint, and industry impact:
-
Annapurna Labs maintains a significant presence in Israel, employing hundreds of engineers focused on advanced AI and networking processors for AWS.
-
It also operates major engineering hubs such as an Austin, Texas lab where advanced semiconductors and AI systems are designed and tested.
-
Analysts often describe the acquisition as one of Amazon’s most successful, arguing that Annapurna’s custom silicon is a “secret sauce” that helps AWS compete with Microsoft, Google, and others on performance, cost, and energy efficiency.
…………………………………………………………………………………………………………………………………………………………..
References:
https://www.cerebras.ai/company
https://www.cerebras.ai/blog/cerebras-is-coming-to-aws
https://www.wsj.com/tech/amazon-announces-inference-chips-deal-with-cerebras-109ecd31
https://en.globes.co.il/en/article-nafea-bshara-the-israeli-behind-amazons-graviton-chip-1001420744
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
Custom AI Chips: Powering the next wave of Intelligent Computing
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Will “AI at the Edge” transform telecom or be yet another telco monetization failure?
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
OpenAI and Broadcom in $10B deal to make custom AI chips
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
2026 Consumer Electronics Show Preview: smartphones, AI in devices/appliances and advanced semiconductor chips
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Google announces Gemini: it’s most powerful AI model, powered by TPU chips
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
Intel and AI chip startup SambaNova have entered into a multi-year strategic collaboration to deploy high-performance, cost-efficient AI inference solutions [1.] tailored for AI-native firms, enterprises, and government sectors. This global initiative leverages Intel® Xeon® infrastructure, with Intel Capital further signaling commitment through participation in SambaNova’s $350M Series E financing round. The collaboration will give customers a powerful alternative to GPU‑centric solutions, offering optimized performance for leading open‑source models with predictable throughput and total cost of ownership. Founded in 2017, the Palo Alto, CA company specializes in AI chips and software. SambaNova’s Chairman is Lip-Bu Tan, who is also the CEO of Intel!
Note 1. AI inferencing is the process of using a trained AI model to make real-time predictions, decisions, or generate content from new, previously unseen data. It transforms inputs (a query, image, sensor reading) into useful results (a sentence, classification, alert). Unlike training and language models, inference is about prompt execution, often requiring low-latency (speed) and high efficiency. AI Inference chips have attracted intense investor interest following a wave of deal making around rivals to Nvidia, as AI companies seek faster and more efficient hardware. See References below for more information.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
For high-scale AI workloads, the integration of Intel CPUs with SambaNova’s specialized AI platform was said to offer a high-efficiency rack-level inference alternative. This partnership serves as a strategic bridge as Intel scales its independent GPU-based offerings. Intel remains fully committed to its internal GPU roadmap, continuing aggressive investment across architecture, software, and systems. This collaboration enhances Intel’s edge-to-cloud strategy without altering its competitive trajectory in the GPU market. By combining Xeon processors, Intel networking, and SambaNova systems, the two companies are positioned to capture a significant share of the multi-billion-dollar inference market through heterogeneous data center architectures.
As part of the collaboration, Intel plans to make a strategic investment in SambaNova to accelerate the rollout of an Intel‑powered AI cloud. The collaboration is expected to span three key areas:
- AI Cloud Expansion – Scaling SambaNova’s vertically integrated AI cloud, built on Intel Xeon‑based infrastructure and optimized for large language and multimodal models. The platform will deliver low‑latency, high‑throughput AI services, supported by reference architectures, deployment blueprints, and partnerships with system integrators and software vendors.
- Integrated AI Infrastructure – Combining SambaNova’s systems with Intel’s CPUs, accelerators, and networking technologies to power scalable, production‑ready inference for reasoning, code generation, multimodal applications, and agentic workflows.
- Go‑to‑Market Execution – Joint co‑selling and co‑marketing through Intel’s global enterprise, cloud, and partner channels to accelerate adoption across the AI ecosystem.
Together, SambaNova and Intel aim to shape the next generation of heterogeneous AI data centers — integrating Intel Xeon processors, Intel GPUs, Intel networking and storage, and SambaNova systems — to unlock a multi‑billion‑dollar inference market opportunity.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………
SambaNova also announced its SN50 AI chip, which boasts a max speed that’s 5X faster than competitive chips, according to the company.

Image Credit: SambaNova
Positioned as the most efficient chip for agentic AI, the SN50 chip offers enterprises a 3X lower total cost of ownership – a powerful foundation to scale fast inference and bring autonomous AI agents into full production. The SN50 will be shipping to customers later this year. To quickly scale and distribute SN50, SambaNova is collaborating with Intel, and has obtained $350 million in strategic Series E financing to expand manufacturing and cloud capacity.
“AI is no longer a contest to build the biggest model,” said Rodrigo Liang, co‑founder and CEO of SambaNova. “With the SN50 and our deep collaboration with Intel, the real race is about who can light up entire data centers with AI agents that answer instantly, never stall, and do it at a cost that turns AI from an experiment into the most profitable engine in the cloud.”
“Customers are asking for more choice and more efficient ways to scale AI,” said Kevork Kechichian, EVP, General Manager, Data Center Group, Intel. “By combining Intel’s leadership in compute, networking, and memory with SambaNova’s full-stack AI systems and inference cloud platform, we are delivering a compelling option for organizations looking for GPU alternatives to deploy advanced AI at scale.”
The SN50 delivers five times more compute per accelerator and four times more network bandwidth than the previous generation. It links up to 256 accelerators over a multi‑terabyte‑per‑second interconnect, cutting time‑to‑first‑token and supporting larger batch sizes. The result: Enterprises can deploy bigger, longer‑context AI models with higher throughput and responsiveness — while keeping performance high and costs and latency under control.
“AI is moving from a software story to an infrastructure story,” said Landon Downs, co-founder and managing partner at Cambium Capital. “SN50 is engineered for the real-world latency and economic requirements that will determine who successfully deploys agentic AI at scale.”
Built on SambaNova’s Reconfigurable Data Unit (RDU) architecture, SN50 delivers:
- Instant AI Experiences – Ultra‑low latency delivers real‑time responsiveness for next‑gen enterprise apps like voice assistants.
- Unmatched Scale and Concurrency – Power thousands of simultaneous AI sessions with consistent high performance.
- Breakthrough Model Capacity – Three‑tier memory architecture unlocks 10T+ parameter models and 10M+ context lengths for deeper reasoning and richer outputs.
- Maximum Efficiency at Scale – Higher hardware utilization lowers cost‑per‑token, driving greater performance and ROI.
- Smarter Memory, Smarter Efficiency – Resident multi‑model memory and agentic caching optimize the three‑tier architecture, cutting infrastructure costs for enterprise‑scale AI deployments.
“The new SambaNova SN50 RDU changes the tokenomics of AI inference at scale. By delivering both high performance and high throughput with a chip that uses existing power and is air cooled, SambaNova is changing the game,” said Peter Rutten, Research Vice-President Performance Intensive Computing at analyst firm IDC.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………
SoftBank Corp. will be the first customer to deploy SN50 within its next‑generation AI data centers in Japan. The deployment will power low‑latency inference services for sovereign and enterprise customers across Asia‑Pacific, supporting both open‑source and proprietary frontier models with aggressive latency and throughput requirements.
“With SN50, we are building an AI inference fabric for Japan that can serve our customers and partners with the speed, resiliency and sovereignty they expect from SoftBank,” said Hironobu Tamba, Vice President and Head of the Data Platform Strategy Division of the Technology Unit at SoftBank Corp. “By standardizing on SN50, we gain the ability to deliver world‑class AI services on our own terms — with the performance of the best GPU clusters, but with far better economics and control.”
The SN50 deployment deepens SambaNova’s existing relationship with SoftBank Corp., which already hosts SambaCloud to provide ultra‑fast inference for developers in the region. By anchoring its newest clusters on SN50, SoftBank positions SambaNova as the inference backbone for its sovereign AI initiatives and future large‑scale agentic services.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………
References:
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Groq and Nvidia in non-exclusive AI Inference technology licensing agreement; top Groq execs joining Nvidia
Analysis: Edge AI and Qualcomm’s AI Program for Innovators 2026 – APAC for startups to lead in AI innovation
Custom AI Chips: Powering the next wave of Intelligent Computing
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
OpenAI and Broadcom in $10B deal to make custom AI chips
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
