

AI in Networks Market
Bloomberg: Meta to sell AI compute in a new cloud services offering
Disclaimer: Perplexity.ai was used for research resulting in this article.
Executive Summary:
According to Bloomberg, Meta Platforms is advancing plans to commercialize its internal AI infrastructure through a new cloud services offering, signaling a strategic expansion beyond its traditional hyperscale consumer platforms into the competitive AI infrastructure market. This initiative would position Meta alongside established cloud providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, while also overlapping with emerging GPU-centric “neocloud” providers. Meta’s move represents a significant evolution in the AI infrastructure landscape, with potential ripple effects across data center architecture, optical transport networks, and the broader telecom ecosystem.
At the core of this strategy is the monetization of Meta’s rapidly expanding AI compute footprint. The company has aggressively invested in large-scale data center infrastructure—reportedly including multi-hundred-billion-dollar campus developments—to support training and inference for its proprietary large language models (LLMs) and recommendation systems. As these deployments scale, Meta appears to be seeking to externalize surplus capacity, transforming a cost center into a revenue-generating platform.
The proposed service portfolio is expected to span two primary layers. First, Meta may expose access to hosted AI models via APIs, analogous to AWS Bedrock or Azure AI Services, enabling enterprises to integrate generative AI and foundation model capabilities without managing underlying infrastructure. Second, Meta is exploring the provision of raw compute capacity—primarily GPU-accelerated workloads—mirroring the infrastructure-as-a-service (IaaS) model offered by neocloud providers such as CoreWeave. This dual-layer approach would allow Meta to compete both in higher-margin AI platform services and in lower-level compute provisioning.
Telecom & Networking Implications:
From a telecom and network infrastructure perspective, this development has several implications. Hyperscale AI workloads are increasingly bandwidth-intensive, requiring high-capacity, low-latency interconnects within and between data centers. Meta’s investments are therefore likely to drive demand for advanced optical networking technologies, including coherent pluggable optics (e.g., 400ZR/800ZR), data center interconnect (DCI) architectures, and AI-optimized fabric designs leveraging Ethernet-based scale-out topologies. In addition, the geographic placement of these data centers—often in power-abundant, rural locations—introduces new requirements for long-haul fiber connectivity and edge aggregation.
The initiative, internally referred to as “Meta Compute,” reflects a broader industry shift toward vertically integrated AI infrastructure stacks, where hyperscalers tightly couple compute, networking, and software frameworks. For telecom operators and infrastructure vendors, this trend underscores the growing convergence between cloud, AI, and network domains, particularly as AI-driven workloads begin to influence traffic patterns, peering strategies, and edge deployment models.
Strategically, Meta’s entry into the AI cloud market raises competitive pressure across multiple fronts. Unlike traditional cloud providers, Meta brings extensive experience in hyperscale distributed systems and open-source AI frameworks (e.g., PyTorch), but lacks a mature enterprise cloud ecosystem. Its success will likely depend on its ability to translate internal infrastructure efficiencies into externally consumable services, while addressing enterprise requirements for reliability, security, and service-level agreements.
Meta’s cloud push is best viewed as a network-and-infrastructure strategy as much as a software business, because monetizing AI capacity depends on how well it can expose compute, move data, and preserve performance at hyperscale. The telecom significance is that Meta is turning internal AI infrastructure into a market-facing platform, which increases the importance of optical transport, data-center interconnect, and low-latency backbone engineering.
From a telecom perspective, the key issue is not simply that Meta may sell AI models or GPU capacity; it is that the company is building a service layer on top of a very large, power- and bandwidth-intensive distributed system. Reuters reported that Meta is considering both hosted model access and raw compute sales, with the former resembling an AI platform service and the latter looking more like neocloud infrastructure.That means the network becomes part of Meta’s product offering. Large AI inference and training environments require high-bisection fabrics inside the data center, plus dense east-west traffic handling, which pushes demand for faster Ethernet switching, advanced optical modules, and carefully engineered rack-to-rack and site-to-site interconnects. Meta’s AI cloud ambitions reinforce a broader shift: hyperscalers are no longer treating networking as a background utility, but as a primary constraint on scale.
Network World’s coverage of Meta Compute notes that Meta has unified data center and network oversight and is planning multi-gigawatt AI buildouts, underscoring how tightly power, fiber, switching, and facility design are now linked.
For network operators and vendors, that translates into stronger demand for long-haul fiber, DCI platforms, low-latency transport, and high-radix switching. It also raises the strategic value of metro and regional interconnect corridors that can support AI clusters, especially when capacity must be spread across multiple sites for power, land, or resiliency reasons.
Meta’s potential move into raw compute sales is especially relevant to telecom because it resembles the economics of infrastructure-heavy cloud and colocation models. In practice, the service quality will depend on how efficiently Meta can provision GPU clusters, maintain deterministic performance, and avoid congestion across the transport layer connecting those clusters. That implies growing importance for:
-
Coherent optical transport and scalable DCI.
-
High-capacity Ethernet fabrics for AI clusters.
-
Open-rack and disaggregated infrastructure designs.
-
Network automation that can track workload placement and traffic hotspots.
These are not just cloud concerns; they are telecom-grade capacity-planning problems. As AI clusters become larger and more distributed, network planning starts to look more like core network engineering than conventional enterprise hosting.

Image Credits: Gabby Jones/Bloomberg / Getty Images
……………………………………………………………………………………………………………………………………………………………………..
Conclusions:
Meta’s entry would not only compete with AWS, Azure, and Google Cloud, but could also pressure specialized neocloud providers more directly. Reuters noted that Meta’s spare capacity could matter more to neo-cloud vendors than to the largest hyperscalers, because those providers rely on access to external GPU supply and managed infrastructure growth. For telecom analysts, that suggests the competitive battleground is shifting from “who has the best model” to “who can deliver the most resilient compute-network-power stack.” The winners will likely be those that can couple AI accelerators with fiber-rich sites, robust interconnect, and energy-secure data center footprints.
Meta’s move reflects the convergence of cloud, AI, and transport networks. The story is less about Meta becoming a generic cloud vendor and more about hyperscale AI infrastructure evolving into a new class of network-dependent utility. Indeed, Meta’s cloud initiative highlights a broader industry reality — in the AI era, compute is valuable, but connectivity, optical scale, and power-aware architecture increasingly determine whether compute can be monetized at all.
……………………………………………………………………………………………………………………………………….
References:
Meta, like SpaceX, looks to turn excess AI compute into cash
https://www.cnbc.com/2026/05/27/mark-zuckerberg-says-meta-starting-cloud-business-on-the-table.html
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
OCP 2025 Meta keynote: Scaling the AI Infrastructure to Data Center Regions
TechCrunch: Meta to build $10 billion Subsea Cable to manage its global data traffic
AI Frenzy Backgrounder; Review of AI Products and Services from Nvidia, Microsoft, Amazon, Google and Meta; Conclusions
Bharti Airtel and Meta extend 2Africa Pearls subsea cable system to India
Is AI the driving force behind the metaverse?
TM Forum’s DTW Ignite 2026: Open Digital Architecture (ODA); Nokia, Ericsson, IBM and Mavenir AI announcements/cloud partnerships
-
- Shift to Action: TM Forum Vice President Aaron Boasman-Patel and CEO Nik Willetts opened the summit emphasizing that the industry must move past abstract C-suite visions.
- The AI Economy: The flagship keynote officially launched the “Race to 2030,” a direct directive tasking operators to secure their market relevance by deploying high-velocity, production-grade architectures.
-
- On-Stage AI Co-Hosts: In an industry event first, agentic AI systems took the stage alongside human moderators to act as live panel co-hosts, digital analysts, and experts.
- Summit Intelligence Layer: Advanced AI systems recorded and indexed every keynote, panel, and breakout session, functioning as a real-time intelligence layer to deliver daily trend summaries to attendees.
-
- Autonomous Networks (AN): Featuring the largest showcase of live autonomous operating systems to date. Major case studies from carriers like China Mobile, China Telecom, TDC NET, and Telefónica showcased functional solutions for self-optimizing networks, RAN energy efficiency, and fast fault resolution.
- Trustworthy AI and Data: Discussions zeroed in on scaling responsible AI, exploring Models-as-a-Service (MODaaS) frameworks, managing tokenomics, and reinforcing cyber resilience.
- Composable IT and Ecosystems: Demonstrations focused on scaling Open Digital Architecture (ODA) from boardroom design into functional, interoperable engineering realities.

Practical Engineering & Showcases:
- Catalyst Showcases: The exhibition floor hosted over 60 collaborative proof-of-concept Catalyst projects and Innovation Engine live demonstrations.
- New Interactive Hubs: The event debuted dedicated “Mission Garages” for hands-on engineering collaboration, along with a specialized Future Skills program to help tech teams adapt to AI-native workflows. [1]
- Major Tech Partnerships: Industry titans—including IBM, Ericsson, Cisco, and Nokia—used the floor to debut subsea infrastructures, physical AI, and cloud-native automation frameworks.
Note 1. DTW Ignite 2026 is TM Forum’s flagship global connectivity event focused on accelerating AI-native telcos, autonomous networks, and composable IT. The event is from June 23 to June 25 at the Bella Center in Copenhagen, Denmark.
……………………………………………………………………………………………………………………………………………………………….
At the show, the TM Forum and its member alliance of over 850 companies across 180 countries, announced a major structural evolution for the Open Digital Architecture (ODA), shifting it from a cloud-native IT modernization blueprint into an AI-native execution environment. The core focus of these updates is to establish standardized, executable reference frameworks that allow operators to move beyond fragmented AI pilots and build an autonomous enterprise. The primary ODA updates and structural expansions announced at the summit include:
-
- Governed Execution Layer: TM Forum members launched AI-native extensions to the ODA specification, adding a governed execution layer. This allows autonomous AI agents and large language models to run natively within the existing ODA component architecture and Open APIs.
- Project Foundation & AI Canvas: Through the Demo ONE Catalyst project, tech leaders debuted an updated AI-Native ODA Canvas. This cloud-native runtime environment orchestrates data, AI models, and autonomous agents across fragmented BSS, OSS, and network domains to replace rigid legacy systems.
- Model-as-a-Service (MODaaS): To solve the challenge of rising token costs and fragmented model selection, an ODA-aligned MODaaS framework was introduced. It establishes a unified control plane to govern, secure, and manage AI model usage across the carrier architecture.
-
- Space-Telco Interoperability: In a major scope expansion, TM Forum officially launched the ODA for Satellite project. Supported by 16 foundational partners—including Airbus, Terrestar, and Vodacom—the initiative targets multi-billion dollar direct-to-device and space-connectivity markets.
- Unified Non-Terrestrial Frameworks: The project extends standard ODA components to satellite technology providers, standardizing how terrestrial mobile networks and non-terrestrial networks (NTNs) handle cross-industry billing, service delivery, and zero-touch roaming integrations.
- Plug-and-Play Validation: TM Forum rolled out its newly expanded ODA Component Certification. This toolkit gives vendors a programmatic way to verify that their commercial software components are truly plug-and-play ready, lowering custom integration costs for telecom buyers.
- “Running on ODA” Milestones: The alliance celebrated that 18 global Communication Service Providers (CSPs), representing over two billion subscribers globally, have officially achieved “Running on ODA” accreditation—confirming that modular, componentized architecture has reached full scale in production environments.
……………………………………………………………………………………………….
Vendor Announcements:
- Amazon Web Services (AWS) Expansion: Nokia and AWS expanded their partnership to run Nokia’s Autonomous Networks Fabric natively on AWS. The integration brings operators closer to Level 4 network autonomy, enabling networks to orchestrate, analyze, and heal themselves at machine speed.
- Google Cloud Integration: Nokia deepened its alliance with Google Cloud to integrate Gemini models into the Nokia Assurance Center. They unveiled six specialized generative AI agents (including a Router Agent and Event Triage Agent) to automatically process data and isolate the root causes of service faults. It launches as a SaaS offering in September 2026.
- Databricks Proof of Concept: Nokia and Databricks announced the completion of a joint project showing a unified, cloud-agnostic data platform. This resolves a legacy pain point by unifying hundreds of fragmented operational silo data architectures so multi-agent AI can run seamlessly across networks.
- GenAI-Native Operations: Instead of relying on traditional rules-based code, Nokia’s new interfaces allow field engineers to query complex multi-vendor topologies, generate diagnostic code, and run natural-language root-cause analyses on real-time traffic faults.
- Autonomous Network Scaling: Nokia presented multi-party Catalyst project solutions targeting network optimization, zero-touch slicing, and automated enterprise edge deployments tailored for the 5G-Advanced landscape.
……………………………………………………………………………………………………………………………………………………….
- EIAP Core Expansion: The headline announcement from the Ericsson Cloud Software and Services division was the expansion of the Ericsson Intelligent Automation Platform (EIAP). Formerly restricted to RAN operations, the platform now fully integrates and unifies Radio Access Network (RAN) and core network automation systems.
- Introduction of cApps: Ericsson claimed a major industry first by rolling out core-specific automation applications (cApps). These decentralized apps allow operators to run automated routines directly on core architectures, streamlining cross-domain workflows to cut operations costs.
- Business Value Pathways: Ericsson debuted a structured strategic blueprint designed to guide Communication Service Providers (CSPs) through the financial steps of scaling from Level 3 to Level 4 autonomous networks.
…………………………………………………………………………………………………………………………………………………….
- Addressing the “AI Trust Gap”: Responding to a TM Forum study revealing that only 14% of operators can prove their AI systems are fully reliable, IBM presented framework tools at DTW Ignite to address security and model bias.
- B2B2X Monetization: IBM focused its platform showcase on orchestrating automated workflows for multi-enterprise B2B2X networks, enabling secure data federation across third-party hyperscalers and edge servers.
……………………………………………………………………………………………………………………………………………………
- Telco-First Cloud Architecture: Stationed at Booth 334, Mavenir debuted its updated AI-by-design, cloud-native software portfolios built natively around TM Forum’s Open Digital Architecture (ODA) frameworks.
- Closed-Loop Automation: Mavenir demonstrated actionable frameworks that handle real-time resource adjustments, shifting power and processing capacity across base stations based on AI-predicted user demand cycles.
……………………………………………………………………………………………………………………………………………………
References:
https://www.tmforum.org/events/dtw/experience-dtw/new-for-2026
Inside TM Forum’s Catalyst project “Living Networks – Phase III”
Deloitte and TM Forum : How AI could revitalize the ailing telecom industry?
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
GSMA, ETSI, IEEE, ITU & TM Forum: AI Telco Troubleshooting Challenge + TelecomGPT: a dedicated LLM for telecom applications
SHIELD-6G with AI-native cyber threat intelligence platform to enhance cybersecurity for Europe’s future 6G networks
Verizon’s 6G Innovation Forum joins a crowded list of 6G efforts that may conflict with 3GPP and ITU-R IMT-2030 work
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
By Shazia Hasnie, PhD
Introduction:
The physical network infrastructure that underpins cloud computing was designed for an era that no longer exists. Distributed training across hundreds of thousands of GPUs, real-time inference at the edge, and autonomous agent coordination impose requirements that traditional cloud network designs were never intended to meet. The networks that served the cloud era were architected for north-south traffic, best-effort delivery, and human-scale applications. None of these assumptions hold for AI.
This article presents a framework for transforming cloud network infrastructure for the AI era. It is organized around two components: a four-pillar reference architecture that defines what must be built, and a five-phase implementation roadmap that defines how to execute the transformation. Together, they provide infrastructure transformation leaders with a complete program for preparing their organizations’ physical network infrastructure for the age of AI.
The Four-Pillar Reference Architecture:
The physical network infrastructure for AI-era cloud computing is organized around four interdependent pillars. Each pillar groups related layers of the infrastructure stack. Each depends on the pillars that precede it and enables the pillars that follow.
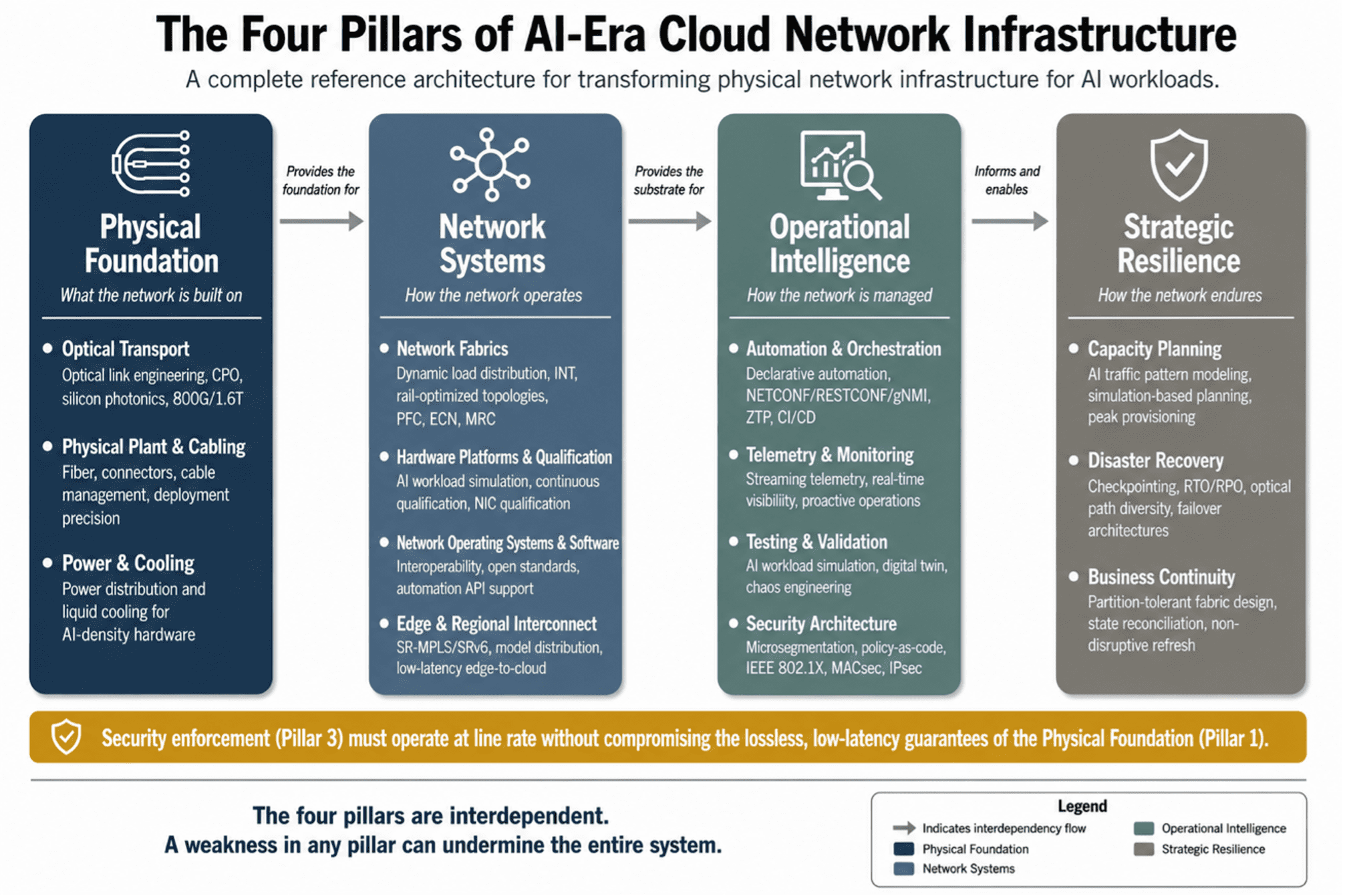
Figure 1: The Four Pillars of AI-Era Cloud Network Infrastructure — a complete reference architecture for physical network transformation.
PILLAR 1: PHYSICAL FOUNDATION
The physical foundation is the literal infrastructure on which all higher-layer network services depend. Optical transport determines the bandwidth, latency, and reliability of every interconnection between data centers, regions, and compute clusters. Physical plant and cabling provide the fiber, connectors, and cable management that make connectivity possible. Power and cooling provide the electrical and thermal infrastructure that keeps everything running.
Optical Transport. Optical link engineering for AI workloads requires a fundamental shift from traditional practice. Traditional optical link engineering treats traffic surges as anomalies and provisions for average utilization. AI workloads generate synchronized, high-bandwidth bursts—checkpointing incast can saturate multiple optical links for minutes at a time—that demand link budgets engineered for peak synchronized demand. The cost of insufficient capacity is not degraded optical performance; it is stalled training runs.
The optical technology roadmap is being reshaped by AI requirements. Co-packaged optics (CPO) integrate the optical engine directly with the switch ASIC, reducing power consumption by 30-50% while increasing port density. Silicon photonics leverage semiconductor manufacturing to produce optical components at scale. 800G and 1.6T per wavelength will be required as GPU bandwidth scales. Linear drive optics remove the digital signal processing from the optical transceiver, reducing power and latency. Breakout optics enable multi-planar topologies where each GPU connects to multiple parallel fabrics. Organizations must ensure that today’s optical investments are forward-compatible with these technologies.
Physical Plant and Cabling. Deployment precision at the physical layer determines whether the architectures designed at higher layers function as intended. Rail-optimized topologies depend on perfect physical cabling—a single miscabled port breaks the single-hop guarantee. Automated cabling verification, where the management interface validates each connection against the reference design, has reduced deployment time by up to 90% for early adopters. Continuous monitoring must detect cabling degradation before it causes performance issues.
Power and Cooling. AI network hardware consumes significantly more power than traditional cloud hardware. A rack of switches populated with 800G pluggable optics can consume over 10 kilowatts. CPO engines may require direct-to-chip liquid cooling. The transition to liquid cooling has implications that extend beyond the network—chilled water systems, heat rejection, building structural load—and retrofitting liquid cooling into a data center designed for air cooling is significantly more expensive than incorporating it into new construction.
PILLAR 2: NETWORK SYSTEMS
Network systems translate the physical foundation into functional network services. Modern data centers operate multiple physical networks—front-end, back-end, storage—each optimized for a specific traffic class. AI training demands a dedicated high-bandwidth, low-latency fabric for GPU-to-GPU communication that must interoperate with existing networks through well-defined interconnection points.
Network Fabrics. AI workloads generate east-west traffic that behaves differently from anything traditional cloud networks were designed to handle. It is dominated by a small number of high-bandwidth elephant flows—sustained, predictable data streams between GPU pairs—that produce synchronized bursts at predictable intervals. Worst-case path latency determines the completion time for collective communication operations, making the performance of the slowest path more important than average performance.
The industry has developed two distinct architectural paths to meet these requirements. For scale-up networks within a single rack or GPU pod, where distances are measured in meters and the cost of a stall is immediate, lossless transport via Priority-Based Flow Control (PFC) and Explicit Congestion Notification (ECN) remains the dominant approach. For scale-out networks connecting GPU clusters across data center halls or buildings, the industry is moving toward efficient utilization with low tail latency through fast recovery rather than absolute loss prevention. The Ultra Ethernet Consortium’s Ultra Ethernet Transport (UET) specification leads this effort, treating packet loss as a recoverable event rather than a failure.
The choice between paths is governed by three criteria: scale of deployment (≤256 GPUs favors lossless; ≥512 GPUs favors low-loss), workload characteristics (tightly coupled training benefits from lossless; loosely coupled inference tolerates low-loss), and organizational maturity (deep PFC expertise extends lossless viability to larger scales).
Four fabric capabilities support both paths. Dynamic load distribution—flowlet switching and packet spray—replaces static Equal Cost Multi-Path (ECMP) with congestion-aware path selection. In-band network telemetry (INT) provides the microsecond-granularity congestion visibility that makes intelligent load distribution possible. Rail-optimized topologies provide single-hop GPU-to-GPU connectivity for the most latency-sensitive collective operations. Advanced transport protocols, add selective retransmission via SACK and NACK that serves both scale-up and scale-out deployments.
Hardware Platforms and Qualification. Hardware must be qualified under AI workload conditions, not standard benchmarks. A switch that performs well under steady-state testing may exhibit unacceptable packet loss under synchronized burst patterns. The qualification process must answer a specific question: will this hardware maintain performance under the traffic patterns that AI workloads generate? Qualification is continuous—a firmware update, a new optics module, or a configuration change can alter behavior and must be validated before reaching production. The endpoint NIC plays a critical role, handling RDMA at line rate, packet-spray reordering, and selective retransmission. NIC qualification must be part of the same AI workload simulation process as switches and optics.
Network Operating Systems. The NOS must support PFC, INT, dynamic load distribution, and automation APIs. Interoperability is an architectural requirement in inherently multi-vendor AI infrastructure. Organizations should prioritize platforms that adhere to open standards—UET specifications, IETF YANG data models, OpenConfig—over proprietary extensions that create long-term supply chain constraints.
Edge and Regional Interconnect. AI inference increasingly occurs at the edge, requiring low-latency connectivity to cloud reasoning agents. Traffic engineering via Segment Routing over MPLS (SR-MPLS) and SR over IPv6 (SRv6) enables explicit path specification for latency-sensitive flows. Model distribution to edge endpoints requires versioned, efficient distribution protocols. Regional interconnect must be treated as a production input, not a shared utility—it is part of the AI supercomputer’s backplane.
PILLAR 3: OPERATIONAL INTELLIGENCE
Operational intelligence provides the control systems that make the network operable at scale. The AI-ready network cannot be managed through manual processes—a single AI cluster may contain thousands of switches requiring consistent configuration, where a single misconfigured buffer can stall thousands of GPUs.
Automation and Orchestration. The architectural response is declarative intent-based automation. The operator declares the desired network state using IETF YANG data models, and the automation framework translates this into device-level configuration via NETCONF, RESTCONF, and gNMI. Zero-touch provisioning enables switches to self-configure from the moment of installation. Configuration-as-code ensures every device conforms to architectural standards, with drift detected and corrected automatically. Network changes move through CI/CD pipelines that validate against policy and test under AI workload conditions before production deployment.
Telemetry and Monitoring. INT captures per-packet, per-path metrics at microsecond granularity. Streaming telemetry replaces polled monitoring with continuous, event-driven data push. The telemetry platform must ingest, store, and analyze millions of data points per second, enabling cross-layer correlation—tracing a GPU-level stall back through the fabric to the specific optical port and wavelength where the loss occurred. Predictive models detect performance degradation before it causes packet loss, shifting operations from reactive to proactive.
Testing and Validation. A dedicated testing environment must replicate production AI workload patterns—synchronized bursts, collective communication operations, checkpointing incast. Fault injection and chaos engineering validate network behavior under failure conditions. A digital twin of the production network, continuously synchronized, within a bounded delay, with real-time telemetry, enables what-if analysis for topology changes, capacity additions, and configuration updates before production deployment.
Security Architecture. Distributed AI dissolves the traditional network perimeter. The architectural response is in-fabric security: microsegmentation at the switch level validates every flow at the point of ingress, policy is bound to workload identity rather than network location, and the enforcement architecture relies on IEEE 802.1X, MACsec, and IPsec. Policy-as-code manages security rules through the same CI/CD pipelines as network configuration. The immutable audit trail serves double duty as both the security record and the compliance record.
PILLAR 4: STRATEGIC RESILIENCE
Strategic resilience ensures the network survives disruptions, scales with demand, and sustains itself over the long term.
Capacity Planning. Traditional capacity planning, based on historical averages and steady-state utilization, systematically underprovisions for AI. AI traffic is bursty, synchronized, and high-volume by design. Capacity must be provisioned for peak synchronized demand. Simulation-based planning models proposed network designs under projected AI workloads, identifying bottlenecks in the design phase before hardware is committed.
Disaster Recovery. AI training runs lasting weeks or months cannot be restarted from scratch. The network must support checkpointing at AI scale, with Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) defined per workload. The optical backbone must provide physically diverse paths with automatic protection switching. Failover architectures—active-active or active-passive—must be designed at the network level for inference workloads requiring high availability.
Business Continuity. The network fabric must tolerate WAN partitions without cascading failures, with local control planes capable of independent operation at each site. State reconciliation architecture—based on the shared event log pattern—must preserve causal ordering across partition boundaries. The network must support non-disruptive infrastructure refresh, with redundant paths and hitless failover enabling component replacement without interrupting workloads that run continuously for weeks or months.
The Five-Phase Implementation Roadmap
The migration from legacy to AI-ready network infrastructure is a multi-phase program that must deliver value at each stage while building toward the target architecture. Each phase has defined activities, deliverables, and success criteria. Each phase delivers measurable value before the next begins. Phase durations are calibrated for a Tier-1 cloud services provider; individual organizational timelines may vary based on scale, complexity, and resource availability. The success criteria stated for each phase are drawn from industry benchmarks and practitioner experience with large-scale network transformation programs. They represent targets that are ambitious but achievable for a Tier-1 cloud services provider with dedicated transformation resources and executive sponsorship.
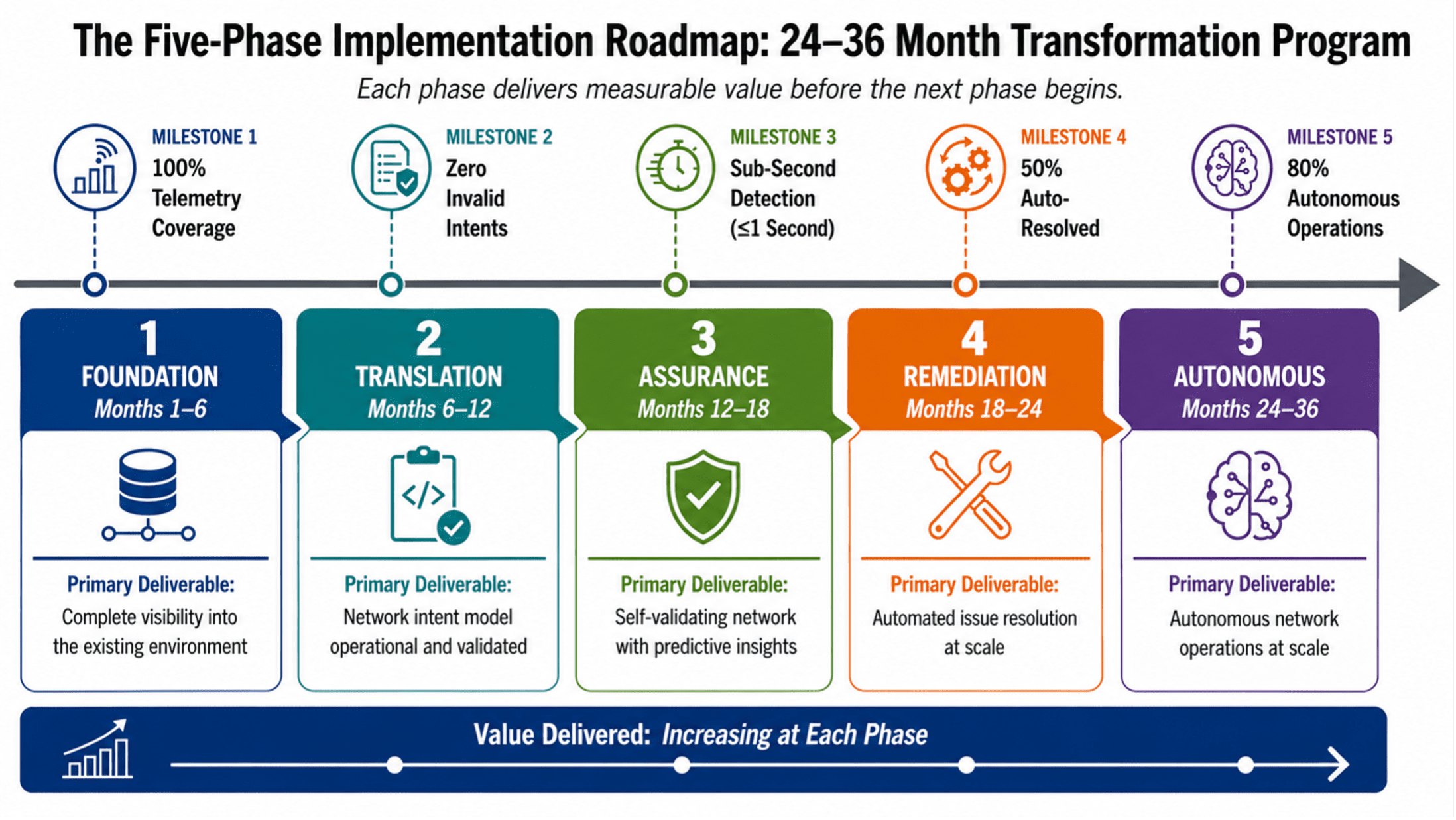
Figure 2: The Five-Phase Implementation Roadmap — A 24–36 Month Transformation Program.
PHASE 1: FOUNDATION (MONTHS 1–6)
The first phase establishes the essential building blocks. Nothing can be automated, optimized, or secured until the network is instrumented and its state is understood.
The starting point is telemetry. Streaming telemetry must be enabled across all network devices in the AI infrastructure path—switches, optics, fabric elements—using gRPC-based protocols and OpenConfig YANG data models. The deliverable is a centralized telemetry platform receiving continuous data streams from every device. The success criterion is 100% telemetry coverage. Without complete visibility, every subsequent phase operates on incomplete information.
With telemetry flowing, a topology knowledge graph must be built—a dynamic map of all devices, links, and interconnections, continuously updated from telemetry data and discovery protocols. The graph must reflect topology changes within seconds, not minutes. Accurate neighbor discovery across all fabric layers is the foundation on which intent-based automation will reason about the network.
Configuration management must be brought under version control. Every device configuration—PFC thresholds, QoS policies, dynamic load distribution parameters—must be stored in version-controlled repositories. Every change must be tracked and attributed. The success criterion is 100% configuration version control with no out-of-band changes permitted. An automation framework that deploys configuration changes cannot operate reliably if changes are also being made through manual processes that bypass the automation pipeline.
Finally, the foundational intent model must be established. This is a structured format for expressing network intent—topology, capacity, QoS policies—in machine-readable YANG-based models. The deliverable is five foundational intents, defined and validated against the existing network state:
- Lossless Transport Intent: “All Remote Direct Memory Access over Converged Ethernet (RoCE) traffic on the AI fabric shall receive PFC priority treatment with zero packet loss under sustained load.”
- Fabric Capacity Intent: “The AI fabric shall maintain a minimum of 30% headroom on all east-west links during peak utilization.”
- Optical Link Diversity Intent: “Every GPU cluster shall have at least two physically diverse optical paths to its checkpoint storage.”
- Configuration Compliance Intent: “All device configurations shall match version-controlled templates. Any deviation shall be detected and flagged within 60 seconds.”
- Telemetry Coverage Intent: “Every device in the AI network path shall stream telemetry data. Any device that stops streaming shall be flagged within 30 seconds.”
These five intents are scoped to be achievable within Phase 1 while covering the most critical dimensions of AI network operations: lossless transport, capacity, resilience, configuration compliance, and observability.
PHASE 2: TRANSLATION (MONTHS 6–12)
The second phase builds the machinery that translates intent into device-level configuration. This is where declarative automation becomes operational.
The centerpiece is the intent compiler—a translation engine that converts YAML or JSON intent specifications into device-level configuration via NETCONF, RESTCONF, and gNMI. The intent compiler is not merely a template engine. It must understand the capabilities and constraints of each target device, select the appropriate protocol for each configuration operation, and handle the transactional semantics that make configuration changes safe. The success criterion is that the five foundational intents from Phase 1 are compiled and deployed without manual intervention.
Before any compiled configuration reaches production, it must be validated in a digital twin—a virtual replica of the AI network, continuously synchronized with production telemetry. The digital twin enables what-if analysis: if this configuration is applied, what happens to fabric utilization, PFC pause events, and flow completion times? The success criterion is 100% of configuration changes validated in the digital twin before production deployment.
Validation checks must be automated. Every intent must pass feasibility validation (can the network support this intent given current capacity?), capability validation (do the target devices support the required features?), and policy validation (does this intent comply with security and operational policies?). The success criterion is zero invalid intents deployed to production.
Multi-domain support must be enabled. The intent compiler must support both data center fabric and optical backbone domains, translating a single intent into coordinated configurations across domains.
PHASE 3: ASSURANCE (MONTHS 12–18)
The third phase closes the loop between intent and reality. The network may be configured correctly at a point in time, but AI workloads cause continuous change—congestion patterns shift, optical performance degrades, buffer utilization fluctuates. Assurance ensures the network remains in its intended state.
Real-time telemetry monitoring must track SLA compliance for all AI network services, updated continuously from streaming telemetry rather than periodically from polled data. Sub-second detection latency for SLA deviations is the success criterion. A RoCE stall that lasts 500 milliseconds must be detected while it is happening, not after the training run has been disrupted.
Drift detection must compare the intended network state against the actual state continuously. Drift can take many forms: a configuration change applied outside the automation pipeline, a performance degradation that violates the intent without changing the configuration, a topology change due to a link failure. The success criterion is 99% detection accuracy for both configuration and performance drift.
The assurance dashboard must provide all stakeholders—network operations, compute operations, capacity planning—with real-time visibility into network state versus intent. Alerting must be integrated with the incident management system so that 100% of SLA breaches generate alerts within one second of detection.
PHASE 4: REMEDIATION (MONTHS 18–24)
The fourth phase enables the network to respond to drift and failures. Detection without response is observation without action. Remediation closes the loop.
Root cause analysis (RCA) must be automated. When drift is detected, the system must correlate telemetry data across layers—optical, fabric, device—to identify the source. A packet loss event at the GPU layer may originate from a congested optical link three hops away. The RCA engine must trace the event across layers. The success criterion is greater than 80% accuracy for common incident types.
At least three remediation types must be implemented and validated in the digital twin before production enablement: rollback to the last known good configuration, traffic rerouting around congested or failed links, and dynamic QoS adjustment.
A policy engine must govern which remediation actions are fully automated, which require human approval, and which are prohibited. The policy framework must be machine-readable, version-controlled, and enforced at the automation layer. The success criterion is 100% of automated remediation actions comply with defined policies.
Supervised remediation must enable a human-in-the-loop approval workflow for actions that exceed the automated threshold. The goal is that 50% of detected issues are resolved automatically without human intervention, with the remainder escalated for approval.
PHASE 5: AUTONOMOUS (MONTHS 24–36)
The final phase extends over 12 months—longer than the preceding phases—because full autonomy is not a single deployment event. It requires progressive expansion of automation scope, validation of continuous optimization across diverse workload patterns, and accumulation of sufficient operational data for the learning system to deliver meaningful accuracy improvements. Each increment of autonomy must be earned through demonstrated reliability.
The automation scope must be expanded to cover all common incident types identified and validated in Phase 4. The success criterion is that 80% of all incidents are resolved automatically. The remaining 20% represent novel failures, complex multi-domain incidents, or situations where policy requires human judgment.
Continuous optimization must become a background process. The network self-tunes PFC thresholds based on observed congestion patterns, adjusts dynamic load distribution policies as workload distributions shift, and reallocates buffer resources as traffic characteristics evolve. The success criterion is a 20% reduction in SLA violations compared to the Phase 3 baseline.
Cross-domain coordination must achieve full automation for standard intents. When a new GPU cluster is provisioned, the orchestration layer coordinates optical link provisioning, fabric configuration, and security policy establishment across domains without manual intervention. Human involvement is reserved for novel or high-risk changes.
The learning system must improve from experience. Machine learning models trained on historical incident and remediation data must increase root cause analysis accuracy over time. The success criterion is a 10% quarterly improvement in RCA accuracy.
COEXISTENCE: RUNNING LEGACY AND AI-READY NETWORKS IN PARALLEL
The transformation cannot be accomplished through a flag-day cutover. The existing cloud network must continue to operate and generate revenue throughout the transition. The AI-ready network is deployed as a separate physical infrastructure—dedicated optical links, dedicated fabric, dedicated switches—wherever possible. Physical separation eliminates the risk that AI workload traffic patterns will disrupt legacy services. Where physical separation is impractical, logical isolation with strict QoS enforcement provides the necessary workload separation. Interconnection points between the two networks must be engineered with the same packet loss, latency and throughput requirements as the AI-ready network. Operational processes must govern both environments simultaneously during a transition measured in years.
ORGANIZATIONAL TRANSFORMATION
The AI-ready network cannot be operated by a team trained only on legacy network operations. Three new skill domains become critical: AI workload literacy (understanding the traffic patterns and failure modes of distributed training and inference), telemetry and data engineering (building and operating streaming telemetry platforms and correlation engines), and automation engineering (designing and operating intent-based automation and CI/CD pipelines). The talent strategy must balance retraining existing engineers—many of the required skills are extensions of existing knowledge—with external hiring for skills that cannot be developed internally in the required timeframe. Retention of critical talent during the transformation is essential: the engineers who understand the legacy infrastructure are essential to the coexistence strategy.
FINANCIAL MODELING
Network investment for AI must be justified on value generation—the network cost per training run completed, per inference served, per GPU-hour utilized—not traditional cost efficiency metrics. This shift from cost-per-bit to value-per-outcome transforms the investment conversation. A network that costs more per gigabit but enables higher GPU utilization generates a return that far exceeds its cost premium. The five-phase roadmap enables investment to be spread over 24 to 36 months, with each phase delivering measurable value before the next begins. The cost of inaction must be quantified and presented alongside the cost of transformation.
CONCLUSIONS:
The physical network is no longer a utility layer that can be taken for granted. It is the foundation on which AI performance depends. The optical backbone determines whether GPU clusters operate at full utilization or sit idle. The network fabric determines whether distributed training completes in days or weeks. The automation and telemetry infrastructure determines whether issues are detected proactively or discovered after customer impact.
The four-pillar reference architecture defines what must be built. The five-phase implementation roadmap defines how to execute the transformation. Together, they form a complete program for infrastructure transformation leaders.
The technologies described here are deployed and operational in production AI networks today. The challenge for infrastructure leaders is not whether these approaches work, but how to adapt them to their organization’s specific constraints, scale, and timeline.
REFERENCES:
[1] TM Forum, “Autonomous Networks: Business Requirements and Framework,” TM Forum IG1251, 2025. [Online].
[2] AMD, “Next Gen Networking Transport for Large Scale AI Training,” May 2026. [Online].
htt
[3] Tolly Group, “Dell Networking Data Center AI Switch Fabric Congestion Mitigation Evaluation,” April 2026. [Online].
[4] Tech Field Day, “Cisco AI Networking Cluster Operations Deep Dive,” November 2025. [Online].
htt
[5] Akamai / WWT, “East-West Is the New North-South: Rethink Security for the AI-Driven Data Center,” February 2026. [Online]. htt
[6] NIST, “Zero Trust Architecture,” NIST Special Publication 800-207, Aug. 2020. [Online].
[7] IETF, “Network Configuration Protocol (NETCONF),” RFC 6241, June 2011. [Online].
[8] IETF, “RESTCONF Protocol,” RFC 8040, January 2017. [Online]. htt
[9] IEEE, “Priority-based Flow Control,” IEEE Standard 802.1Qbb, 2011.
[10] IEEE, “Congestion Notification,” IEEE Standard 802.1Qau, 2010.
[11] OpenConfig, “OpenConfig: Vendor-Neutral Network Configuration and Telemetry,” [Online]. https://www.
[12] Cloud Native Computing Foundation, “gRPC: A High-Performance, Open Source Universal RPC Framework,” [Online]. https://grpc.io/
[13] Ultra Ethernet Consortium, “Ultra Ethernet Specification,” [Online]. https://
………………………………………………………………………………………………………………………………………………………….
References from IEEE Techblog:
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
The enterprise network stack is collapsing; AI’s impact; comparison with “Batch Pipelines Break AI Agents”
ABOUT THE AUTHOR:

Shazia Hasnie, Ph.D., is VP Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale. She brings over 20 years of global experience in communications networks and holds a Ph.D. in Communications Engineering from the Australian National University.
Network X Americas: AT&T and Comcast reveal huge AI impact on network operations
Echoing a recent Cisco report, telecom leaders at the Network X Americas conference (held in Irving, TX last week) noted that AI is fundamentally shifting traffic patterns while having a very positive impact on network operations. With billions of connected sensors and devices (like autonomous vehicles generating 20GB of data per day), operators are forced to prioritize uplink capacity and low latency over traditional consumer downlink traffic.

AT&T’s network CTO, Yigal Elbaz, cited the robo-taxi as a bellwether for how AI is affecting network traffic. Each Waymo vehicle generates about 20 gigabytes of data per day, roughly 30 times the amount a typical mobile user consumes. Most of that traffic flows from the car to the cloud. “Every other week,” Elbaz noted, “a new flavor of a frontier AI model drops on us.”
“We already have about 700,000 changes on a daily basis in our network made by AI,” said Elbaz, noting that AT&T has built a proprietary foundation AI model because standard large language models (LLMs) don’t understand KPIs, network alarms or fiber deployment specifics. He cited a 20-25% cost reduction and 12-15% better results than general-purpose models.
In his keynote speech, Comcast EVP and Chief Network Officer Elad Nafshi described 200 edge compute centers capable of self-healing 77% of network events. He touted AI chipsets close enough to customers’ homes to pinpoint outside plant faults with 99.2% precision, and a partnership with Nvidia to push that edge platform further.
Nafshi highlighted the gap in network provider promises vs delivery with a hypothetical small-business use case example. A pizza shop operator, could materially change workflow and productivity if the service provider delivered an AI-enabled concierge—built on a task-optimized small language model—to manage order intake and customer interaction. In that scenario, the network evolves from a passive access pipe into an application-aware platform that augments business operations. The concept is credible from a technical standpoint, but remains largely theoretical until operators can effectively reach and educate SMB customers who still perceive connectivity as a fixed monthly expense.
Both AT&T and Comcast Israeli executives said this was more than modernization and discussed the changes in what a network does. The network is now a platform, not a pipe. Today’s network learns, adapts and increasingly acts on behalf of its customers. But I can’t help but wonder if the customers know… or if that network value will ever trickle down to the customers who need it most.
In a keynote panel session titled, ” Convergence in action – Competing, scaling and winning in the AI-driven connectivity market,” Josh Goodell, AT&T’s VP of Broadband and Converged Product Development, framed the company’s objective as becoming “the greatest simplifier of our customers’ lives” while instilling “connectivity confidence.” That positioning is notable for a sector that has historically under-communicated its value proposition beyond basic service metrics.
The broader industry narrative appears to be shifting. Historically, go-to-market strategies emphasized throughput benchmarks and promotional pricing. As Omdia’s Ruth Brown (panel session moderator) observed, packaging has been largely defensive, optimized around billing constructs rather than differentiated user experience. The emerging model instead centers on networks that operate contextually and autonomously—delivering value in ways that are largely invisible to the end user.
Derek Peterson, CTO of Boingo Wireless, articulated a parallel issue in venue networks, describing the “stadium problem.” Operators dimension infrastructure for peak ingress and then underutilize that capacity once users are inside the venue. The architectural question is no longer solely about capacity provisioning, but about service-layer innovation on top of that capacity. At Petco Park, Boingo leveraged existing network assets to enable pre-entry commerce, driving incremental revenue before fans pass through the gates. The infrastructure was not the constraint; the limiting factor was identifying and executing on higher-order use cases.
A similar disconnect persists in the industry’s framing of the digital divide. AT&T’s John Stankey and others have suggested the gap is nearing closure, citing expanded fiber footprints and fixed wireless access. While coverage metrics have improved, the divide has never been purely a function of infrastructure availability. Adoption is equally constrained by affordability and, critically, by perceived value. If connectivity continues to be positioned as a commoditized utility, the most economically vulnerable segments—those with the greatest need for digital enablement—remain the least likely to engage.
This is particularly relevant in an AI-driven economy. The users and small enterprises that could benefit most from intelligent, network-delivered services are often those least exposed to the evolving capabilities of the platform. The industry risks over-indexing on measurable deployment milestones while under-communicating the functional value of next-generation networks.
The Network X keynotes underscored that the technical roadmap is largely in place. Network operators are advancing toward networks capable of real-time traffic learning, proactive cybersecurity at the edge, and highly personalized in-home connectivity experiences. These capabilities represent a more compelling value proposition than traditional service tier comparisons.
However, the central challenge remains go-to-market execution. The industry has demonstrated that it can architect and deploy these capabilities at scale. It has yet to establish a clear, effective framework for articulating that value to end users and enterprises in a way that drives adoption.
As a final observation, the broader telecom ecosystem—illustrated by developments such as autonomous vehicle platforms—already depends on AI-enabled, highly distributed network intelligence. While the underlying infrastructure is incrementally aligning with these requirements, the industry dialogue around its broader economic and societal implications remains underdeveloped.
References:
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
Telecom data centers must be redesigned for the AI era with rack scale architectures, enhanced power & cooling requirements
Is the “far edge” a bridge to far to cross for AI inferencing? What about “Distributed AI Grids”?
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Executive Summary:
Consumer-driven AI traffic [1.] currently represents a marginal share of aggregate Internet traffic. However, accelerating adoption of agentic AI is expected to materially reshape traffic composition over the next decade. In its “AI Impact on Wide Area Networks” report, Cisco projects that AI will emerge as the dominant driver of network traffic growth. As consumer AI adoption approaches “near-universal usage,” AI and agentic AI are forecast to increase consumer-driven network traffic by approximately 6.6× by the mid-2030s (see chart below).
Cisco estimates that this AI expansion will account for roughly 63% of incremental traffic growth relative to non-AI scenarios. The study focuses specifically on WAN implications, rather than data center or GPU infrastructure, and provides guidance on network design and capacity planning. Methodologically, the report integrates real-world traffic observations (via Cisco Crosswork Assurance User Experience), third-party industry datasets, and controlled laboratory evaluations of AI agents to characterize how AI-generated traffic diverges from conventional web traffic patterns.
Token-consumption data shows nearly 10x year-over-year growth, while in some service provider measurements Cisco is seeing ~4x growth in just eight months. Sustained growth at these rates means AI traffic will become a meaningful component of overall network traffic by 2035.
Note 1. Consumer AI traffic has a few defining technical traits: it is still dominated by short text-based exchanges, but it is becoming more stateful, more upstream-heavy, and more latency-sensitive as users move from simple prompts to agentic workflows and multimodal interactions. Today’s consumer AI traffic is still overwhelmingly text-oriented, which is one reason the aggregate bandwidth impact remains modest despite rapid adoption. Comcast’s network observation is a useful real-world proxy: 97.1% of AI traffic was text-based, while images accounted for 2.6% and video only 0.3%. The key technical implication is that current traffic volumes are often limited more by conversation frequency and session behavior than by very large payloads, though that changes quickly as users adopt image, audio, and video generation.
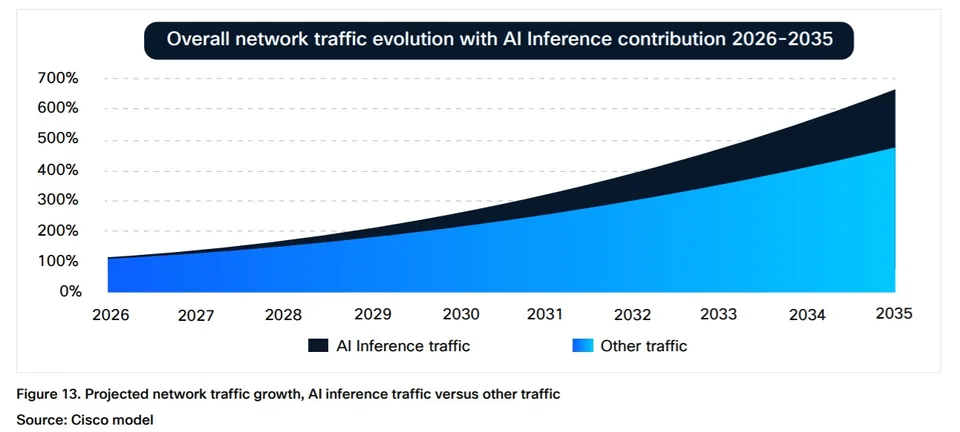
Although AI inference traffic is currently “negligible” relative to dominant categories such as video streaming, Cisco projects it will comprise approximately 25% of total network traffic by 2035 (see chart below). At that point, AI traffic is expected to represent a “meaningful component” of overall network load. Importantly, AI-generated traffic exhibits distinct characteristics: inference flows are approximately twice the duration of typical web transactions, demonstrate higher upstream bandwidth demand, and operate at “software speed” rather than human interaction rates.
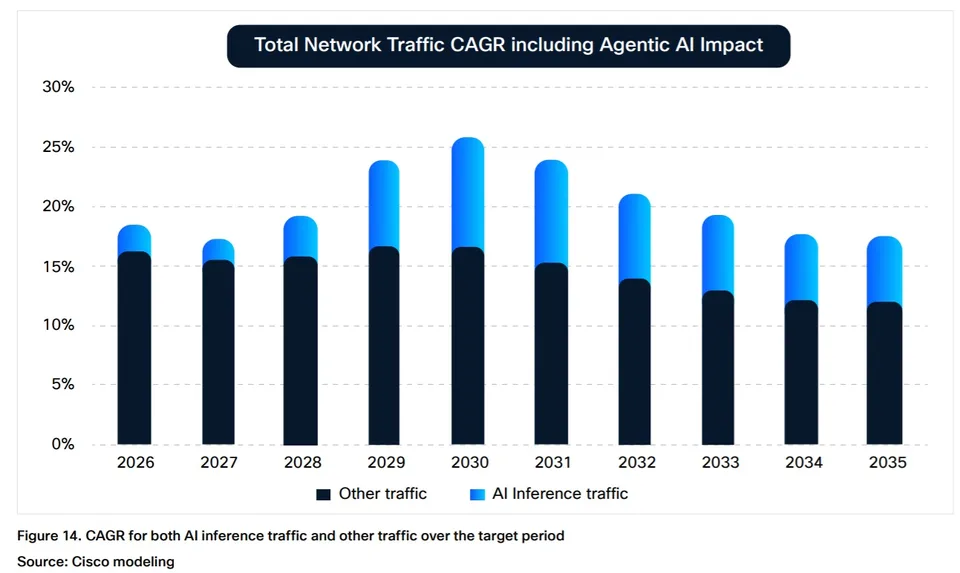
The emergence of AI agents as “power users” further amplifies these dynamics. Cisco notes that agent-executed tasks can generate up to 450% more traffic per task compared to human-driven interactions. This shift is expected to drive operator adoption of “flow-aware network and security systems” as traffic patterns become increasingly machine-driven and less predictable.
Cisco’s broader framing is that AI traffic “isn’t just adding traffic,” but is changing the shape of traffic, with inference flows running about twice as long as typical web transactions and, in some cases, generating up to 450% more traffic per task when an agent executes the workload. AI inference sessions tend to hold resources longer, create more sustained flows, and push operators to think in terms of flow-aware behavior rather than only peak-throughput sizing. Cisco also notes that about 9% of AI inference flows carry more upstream than downstream traffic, versus about 0.5% for typical web traffic, which is a meaningful shift for access and broadband networks. Cisco reports that approximately 9% of AI inference flows are upstream-dominant, compared to roughly 0.5% for traditional web traffic, with this divergence expected to widen alongside increased agentic AI utilization. In parallel, latency sensitivity is anticipated to become a more critical performance parameter for AI-driven applications.
Latency and symmetry:
AI traffic is also more sensitive to latency than many ordinary consumer web transactions because the user experience is often conversational and interactive, with the expectation of near-immediate turn-taking. Cisco describes AI inference as operating at “software speed” rather than human speed, which means small delays can be more noticeable and operationally important. At the same time, upstream demand becomes more significant because prompts, context, attachments, and agent-generated actions can increase return-path traffic, especially as multimodal inputs and agentic tool use expand.
Multimodal growth:
The biggest step-up in technical impact comes when consumer AI shifts from text-only prompting to multimodal generation and agent-driven workflows. In those cases, each task can involve multiple model calls, retrieval steps, tool invocations, and richer media payloads, which expands both flow count and bytes per session. Cisco’s study suggests that this is why AI traffic will increasingly require “flow-aware network and security systems,” because the traffic profile is not just larger, but structurally different from conventional browsing.

Infrastructure Implications:
Telecom infrastructure is becoming “increasingly intertwined with hyperscale infrastructure, not because operators are leading AI investment, but because they are becoming part of the ecosystem that supports it,” analyst firm MTN Consulting said in an April 27th research note. “Demand for optical transport, data-center interconnect, and edge infrastructure is rising as telecom networks carry growing volumes of cloud and AI-driven traffic,” the firm said.
“AI network traffic is already reshaping infrastructure needs. What we are seeing is clear: AI isn’t just adding traffic. It’s changing the shape of traffic,” Javier Antich, principal product management engineer in the CTO office of Cisco’s provider connectivity group, and Gurudatt Shenoy, SVP, product management, provider connectivity, explained in this blog post.
These shifts are beginning to influence access network evolution. Fiber networks already provide relatively symmetric throughput and low latency, while cable operators are advancing similar capabilities through DOCSIS upgrades. Mid-split and high-split architectures increase upstream spectrum allocation, enabling more balanced capacity profiles. Concurrently, Tier 1 operators such as Comcast and Charter Communications are introducing low-latency enhancements within DOCSIS networks.
Operational data reflects early-stage impacts. Comcast Chief Network Officer Elad Nafshi noted at the Cable Next-Gen event in March that approximately 97.1% of AI traffic on Comcast’s network remains text-based, with images accounting for 2.6% and video just 0.3%, indicating that bandwidth-intensive multimodal AI traffic has yet to scale materially.
Network design impact:
For broadband and access networks, the immediate engineering issues are upstream traffic capacity, queue behavior, and latency consistency rather than raw total throughput alone. Symmetry upgrades (such as DOCSIS mid-split and high-split for MSOs), along with low-latency capabilities, are relevant because consumer AI creates more return-path pressure and more time-sensitive sessions. In other words, the challenge is not simply to carry more bytes; it is to carry more interactive sessions with predictable performance, especially as multimodal and agentic usage scales.
………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
Telecom data centers must be redesigned for the AI era with rack scale architectures, enhanced power & cooling requirements
Is the “far edge” a bridge to far to cross for AI inferencing? What about “Distributed AI Grids”?
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Inside Nokia’s new AI Networking Innovation Lab
- Silicon & Compute: Collaborating with AMD to optimize enterprise AI workloads alongside Nokia data center switches.
- Testing & Infrastructure: Partnering with Keysight Technologies to emulate workloads across Ultra Ethernet Consortium (UEC) and RoCEv2 transports.
- Hardware & Servers: Integrating high-performance platforms from Lenovo and Supermicro.
- Data Storage & Cloud: Working with Weka and cloud builders like Nscale to eliminate storage bottlenecks during heavy computational training.

Nokia’s AI Networking Innovation Lab is built upon three fundamental pillars: Technology Innovation, Ecosystem Collaboration, and Validation. Image credit: Nokia
………………………………………………………………………………………………………………….
Technology Innovation: The lab provides a dedicated space for AI partners to experiment with next-gen solutions across the entire networking stack – driving emerging standards forward with pioneering approaches to new protocols, switching silicon, congestion control, real-time telemetry, and automation.
“Partnering with Nokia in the AI Networking Innovation Lab has enabled us to benchmark and optimize AI networks under real-world conditions…Together, we are helping accelerate AI network adoption by giving operators and hyperscalers the validated insights needed for confident, large-scale deployment.”
Ecosystem Collaboration: True progress depends on a strong ecosystem of technology providers – silicon manufacturers, GPU developers, system, storage and test vendors, and cloud platforms – that work together to create highly-compatible AI-ready solutions. This facilitates joint testing for interoperability, improves integration, and ensures roadmaps are aligned across different hardware, software, and orchestration layers.
Travis Karr, Corporate Vice President, HPC and Sovereign AI at AMD believes customer collaboration and an open ecosystem are fundamental to accelerating AI innovation:
“By co-developing solutions with partners, such as Nokia in their AI networking innovation lab, we ensure our AMD enterprise AI solutions are tested with Nokia data center switches on real-world workloads and network demands. An open, standards-driven approach empowers customers to integrate seamlessly across heterogeneous environments, avoiding lock-in and fostering industry-wide advancement in AI.”
Validation: This positions the lab as the testing ground for Nokia Validated Designs, where customers and partners rigorously validate multi-vendor data center architectures under authentic AI training and inference workloads. By testing failure scenarios, congestion behavior, and operational automation, the lab turns NVDs into proven, deployable solutions — enabling predictable performance, faster deployment, and reduced operational complexity and risk for organizations navigating the AI era.
Arno van Huyssteen, Vice President of Global Telecommunications for Nscale:
“Nokia is a strategic networking partner for Nscale as we build towards AI Grid, and the engineering rigour behind their Validated Designs reflects the kind of innovation needed to enable next-generation AI infrastructure. The depth of hardware, software and failure testing behind those blueprints is what will give operators the confidence to deploy complex AI environments faster, with fewer integration risks and less operational disruption. We’re excited to collaborate in the AI Networking Innovation Lab to help push the boundaries of AI-native networking and validate the next generation of solutions before they reach production.”
A primary focal point inside the lab is managing data center congestion. Unlike traditional cloud traffic, back-end AI networks feature high-density data synchronization across massive GPU clusters. The lab uses advanced automation, AIOps, and lossless Ethernet solutions—such as the Nokia 7220 IXR-H6 switches—to handle these intense uplink and synchronization demands safely.
The AI Networking Innovation Lab supports Nokia’s broader strategy to accelerate the next era of AI-driven connectivity. As demand for AI infrastructure continues to grow, data center networking has become one of the most critical foundations of the global AI ecosystem. Through this investment, Nokia is strengthening its capabilities in AI and cloud infrastructure while advancing its vision of AI-native networking.
Rudy Hoebeke, Vice President of Software Product Management at Nokia:
“The launch of Nokia’s AI Networking Innovation Lab marks a major milestone in our commitment to drive the next era of AI-native connectivity. As the industry continues to evolve with solutions like scale-across and AI-Grid, this lab is poised to accelerate AI networking technology that will not only support but optimize these emerging industry offerings. This center gives our customers and partners early access to new technologies, deeper collaboration with the world’s leading AI ecosystem players, and the confidence that their networks are validated under more realistic AI conditions. By accelerating innovation and reducing deployment risks, we’re enabling the industry to deliver faster, more reliable, and more sustainable AI experiences to people and businesses everywhere.”
………………………………………………………………………………………………………………………
References:
Analysis: Nokia’s strong growth in Optical Networks and AI network infrastructure
Orange, Nokia, Nvidia, and Intel debate: ASICs vs. GPUs vs. General-Purpose CPUs for RAN Baseband Processing
Nokia’s AI Applications Study: “Physical AI” may require RAN redesign to support high‑volume, low‑latency uplink traffic
Australia’s NBN and Nokia demonstrate multi-generation optical technologies concurrently over existing FTTP infrastructure
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Tampnet to expand 5G offshore connectivity in the Gulf of Mexico using Nokia AirScale 5G radios
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
By Shazia Hasnie, Ph.D, editorial review by IEEE Techblog team member Sridhar Talari Rajagopal
Abstract:
The adoption of AI agents in network operations has exposed a critical architectural gap. Most enterprise data pipelines were designed for dashboards and reporting, not autonomous decision-making. When AI agents consume data from batch-oriented pipelines, five distinct failure modes emerge: stale data, memory gaps, delete blindness, schema fragility, and coordination failure. This article examines each failure mode, explains the underlying mechanism, and proposes architectural remedies grounded in streaming-first design principles. It also connects each technical failure to measurable business outcomes—extended downtime, recurring incidents, compliance exposure, silent decision degradation, and cascading impact. The result is both a diagnostic framework for I&O leaders and a financial argument for treating streaming data infrastructure as the prerequisite for autonomous operations.
Introduction: The Data Foundation Gap
Artificial intelligence is reshaping network operations. AI agents promise to detect anomalies, diagnose root causes, and execute remediation faster than human engineers. The industry has focused attention on models, GPUs, and orchestration frameworks. The data layer remains largely unexamined.
This is a critical oversight. Most enterprise data pipelines were built for human consumers. They serve dashboards, weekly reports, and historical analysis. Humans tolerate latency. Humans bring context. Humans notice when something looks wrong.
AI agents require something fundamentally different. They need real-time context. They need historical state. They need accurate representations of current reality. When these requirements are not met, agents do not complain. They act—on incomplete information, with incorrect assumptions, producing wrong outcomes.
The gap between what batch pipelines deliver and what agents require creates failure modes that most teams do not see until an agent makes the wrong decision. Recent analysis has identified the economic dimensions of this gap [1], while industry resources have begun documenting the specific failure patterns that arise when batch processing meets autonomous agents [6]. This article extends that work by identifying five distinct failure modes and proposing a streaming-first architectural response.
FIVE FAILURE MODES: ANATOMY OF BATCH-TO-AGENT MISMATCH
The following five failure modes represent the specific ways batch data pipelines undermine autonomous network operations. Each is examined through its mechanism—how the batch pipeline architecture produces the failure—its operational consequence, and the streaming-first architectural remedy that eliminates it. Together, they form a diagnostic taxonomy for any I&O team evaluating whether their data foundation is ready for Agentic AI.
Failure Mode 1: Stale Data
Mechanism: Batch telemetry pipelines poll, collect, and process data in cycles. Data is extracted on a schedule, transformed in bulk, and loaded into a destination—a warehouse, data lake, time-series database, or feature store that holds a static, point-in-time snapshot of the source. Between cycles, the pipeline holds no current state. An AI agent that spins up between cycles receives a snapshot of the past.
Consequence: The agent diagnoses an outage using telemetry from five minutes ago. The network state has changed during that interval. Routes have shifted. Traffic has been redirected. Thus, the agent’s diagnosis is based on a reality that no longer exists. Remediation actions applied to a past state can worsen the current incident. The agent becomes a liability rather than an asset. Industry documentation confirms that AI agents require continuous data freshness to function correctly [5].
Architectural Remedy: Streaming telemetry replaces cyclical polling with continuous event push. Data flows from source to consumer in real time, ingested directly into the streaming platform’s durable event log [2]. The agent consumes from a live stream, not a stale snapshot. Context acquisition takes milliseconds. The cognitive loop remains intact. This is not an add-on to the batch pipeline. It is a structural replacement of the ingestion layer.
Failure Mode 2: Memory Gap
Mechanism: Batch pipelines deliver windows of data—the last hour, the last day, the last processing cycle. They do not preserve the sequence of events that led to the current moment. Historical context is stripped away with each new extract. The pipeline knows what happened. It does not know what happened before.
Consequence: An agent responding to an interface flap cannot answer the most basic diagnostic question: has this happened before? It cannot correlate the current event with the three similar events that occurred in the preceding 24 hours. It cannot detect the pattern that would reveal a degrading optical module. Every incident appears isolated. Pattern recognition—the core value proposition of AI-driven operations—is structurally impossible. The distinction between streaming and batch architectures for these use cases has been well-documented [4].
Architectural Remedy: A durable event log with configurable retention serves as the agent’s memory [2]. Unlike a batch window, which discards history with each new extract, the event log preserves the ordered sequence of all events within the retention period. The agent seeks backward in the log on startup and replays the preceding window of telemetry. Pattern detection across time becomes native to the architecture. This is not a separate cache layered on top. It is the storage layer itself—immutable, ordered, and built for event replay from any offset.
Failure Mode 3: Delete Blindness
Mechanism: Batch pipeline’s Extract, Transform, Load (ETL) processes compare snapshots of source data. They do not watch the database transaction log. They identify what exists at two points in time and process the difference. When a record is deleted from the source system, the pipeline has no way of distinguishing between a row that was deleted and a row that was simply omitted due to extraction error, filtering logic, or schema mismatch. The absence of a row is not an event. It is a gap. Batch pipelines are not designed to interpret gaps as meaningful signals. The record simply vanishes from the next extract. The downstream consumer—an AI agent or any other system—has no way of knowing the record ever existed.
Consequence: The agent queries the downstream data store and finds no record for a deactivated account, a revoked certificate, or a cancelled change order. It cannot distinguish between “never existed” and “was deleted,” so it treats the absence as neutral.
The agent makes decisions on ghosts—data that no longer exists in source systems. In access control scenarios, this is not an operational error. It is a security incident. This specific failure mode has been identified in analyses of batch processing limitations for AI agents [6].
Architectural Remedy: Change data capture (CDC), implemented through Kafka Connect with Debezium connectors, reads the database transaction log directly [2], [8]. Debezium provides CDC source connectors for MySQL, PostgreSQL, MongoDB, SQL Server, and other databases — capturing inserts, updates, and deletes as discrete events with explicit operation types by tailing the database’s native transaction log. Nothing is invisible to the pipeline. The streaming architecture knows not only what exists but what ceased to exist. This is not an ETL workaround with soft-delete flags. It is a structural capability of the integration layer, converting database changes into first-class events the moment they occur.
Failure Mode 4: Schema Fragility
Mechanism: Source database schemas change over time. Columns are renamed, added, deprecated, or re-typed. Batch pipelines are configured for a specific schema at extraction time. When the source schema changes, the pipeline responds in one of two ways. It fails silently and drops the affected field from every subsequent extract. Or it fails loudly and stops processing entirely.
Silent failure is the more dangerous outcome. The pipeline continues delivering data. The consumer has no indication that a critical field is missing.
Consequence: The agent continues operating without a critical data input. It makes decisions with incomplete information. It has no awareness that its reasoning is compromised. The wrong decisions accumulate. By the time the missing field is discovered—often through an operational failure rather than a monitoring alert—the cost of remediation includes auditing and correcting every decision made during the degradation window.
Architectural Remedy: A schema registry with compatibility enforcement validates schema changes before they propagate to downstream consumers [2]. Streaming platforms can enforce backward and forward compatibility rules at the producer level. A breaking schema change is rejected before any data is published. The pipeline fails loudly and immediately. This is not a documentation standard or a code review checklist. It is a structural governance layer embedded in the streaming architecture itself, preventing silent field loss at the point of ingestion.
Failure Mode 5: Coordination Failure
Mechanism: When multiple AI agents operate on batch-derived data, each agent consumes a separate, potentially inconsistent snapshot. Agent A receives data from the 10:00 AM extract. Agent B receives data from the 10:15 AM extract. The extracts differ. Each agent holds a different version of reality. There is no shared, ordered log of events that all agents consume.
Consequence: Two agents respond to the same cascading failure. Agent A identifies a BGP routing issue and begins rerouting traffic. Agent B identifies a DNS resolution failure and begins modifying name server configurations. Neither agent knows the other acted. The redundant changes compete. The conflicting configurations create new instability. The original incident expands rather than resolves. What began as a single point of failure becomes a cascade that erodes trust in autonomous operations.
Architectural Remedy: A shared, ordered event log serves as a single source of truth for all agents in the system. Every agent consumes from the same log. Actions taken by one agent are published back to the log as events, immediately visible to all others [7]. Coordination becomes native to the architecture.
Visibility alone, however, does not prevent conflicting actions. Two agents may observe the same anomaly and both initiate remediation before either’s action becomes visible on the log. In practice, this is addressed through complementary mechanisms layered on the same event-driven model: action intent events that signal an agent is about to act, giving others a window to defer; idempotency keys that prevent duplicate remediation from causing harm; and lightweight leases for resources that should only be modified by one agent at a time. These mechanisms do not require a central coordinator. They are published to the same log, consumed by the same agents, and enforced through the same ordered stream.
This is not a separate orchestration layer or message bus bolted onto the side. It is the core of the streaming platform—a unified, ordered, multi-consumer event stream that provides both the shared state and the coordination primitives that eliminate the inconsistent snapshots batch architectures produce by default.
Batch-to-Streaming Reference Architecture — Five Failure Modes and Their Architectural Remedies
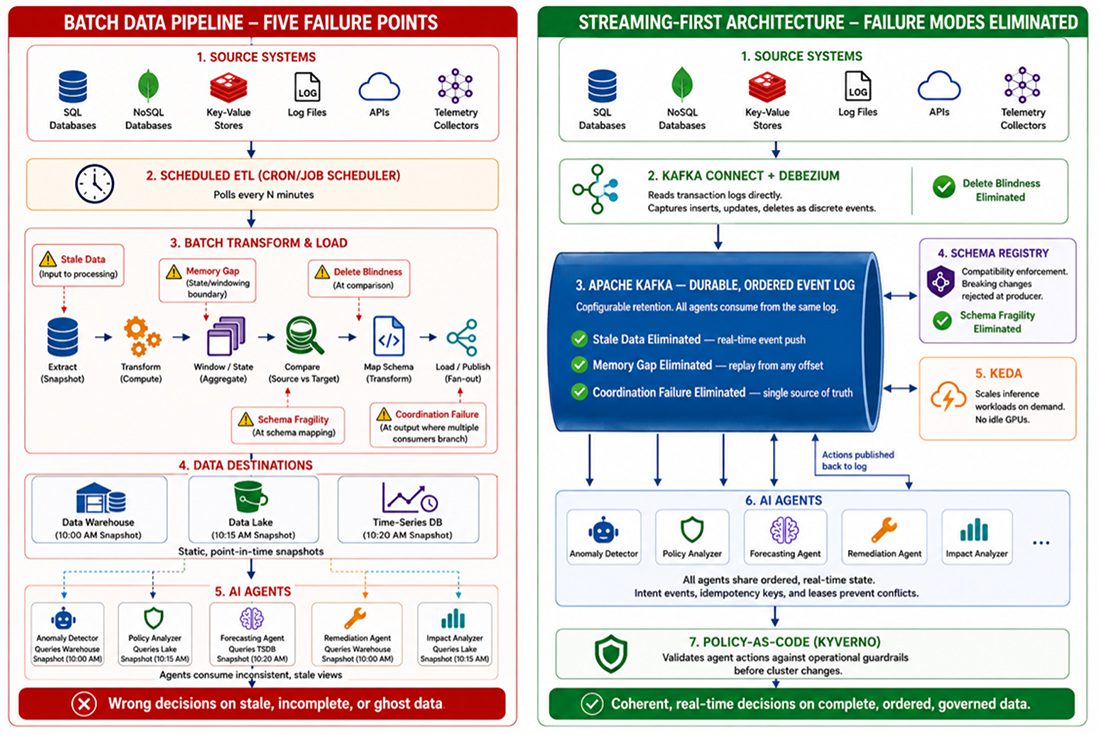
THE UNIFIED DIAGNOSTIC FRAMEWORK
The five failure modes translate into a practical audit that I&O leaders can apply to their own infrastructure. Each question corresponds to a specific architectural requirement.
The Five-Question Audit
- Can the data pipeline deliver real-time context to an agent the moment it wakes up? If not, the system is vulnerable to stale data failures.
- Can the agent access the preceding window of telemetry to detect patterns across events? If not, the system is vulnerable to memory gap failures.
- Does the pipeline capture deletes as explicit events with operation types? If not, the system is vulnerable to delete blindness.
- Does the pipeline detect schema changes before they propagate to downstream consumers? If not, the system is vulnerable to schema fragility.
- Do all agents share a single, ordered view of events with visibility into each other’s actions? If not, the system is vulnerable to coordination failure.
A negative answer to any one of these questions signals a data foundation that is not ready for autonomous operations. The model is not the bottleneck. The GPUs are not the bottleneck. The telemetry pipeline is.
THE MIGRATION PATH: FROM BATCH TO STREAMING-FIRST
Adopting a streaming-first architecture does not require abandoning existing batch investments overnight. For most organizations, the transition follows a coexistence model: streaming pipelines are introduced alongside batch pipelines, not as an immediate replacement.
The practical starting point is to identify the highest-value agent—the one whose decisions carry the greatest operational or financial consequence—and convert its data pipeline first. This agent is typically the one where stale data, memory gaps, or coordination failures have produced measurable incidents. Converting this single pipeline to streaming telemetry with a durable event log delivers a targeted operational improvement while the rest of the batch estate continues to function.
From there, adoption expands incrementally. Each additional agent is migrated as operational experience with the streaming platform grows. Teams develop competence in offset management, schema governance through the registry, and backpressure handling while batch pipelines continue to serve lower-priority consumers. The streaming and batch estates coexist for a transition period measured in months, not days.
This incremental approach also reveals where streaming delivers the greatest marginal benefit. Not every data flow requires real-time treatment. Dashboards fed by hourly batch extracts may serve their purpose indefinitely. The streaming investment should be directed at the pipelines that feed autonomous agents—the flows where the five failure modes carry real operational consequence. The goal is not to stream everything. It is to stream the right things first.
THE BUSINESS IMPACT: FROM TECHNICAL FAILURE TO FINANCIAL CONSEQUENCE
Technical failures in the data pipeline do not remain technical. They cascade into business outcomes that appear on budget reviews, SLA reports, and board presentations. Each failure mode carries a distinct financial consequence.
Stale Data → Extended Downtime
An agent diagnosing from stale telemetry makes incorrect decisions. Remediation applied to a past state can worsen the current incident. Mean Time to Resolution increases. For revenue-generating services, every minute of extended downtime translates to lost revenue and SLA penalty accrual.
Consider an illustrative model: a Tier-1 service provider processing $50M in customer transactions per hour, 5-minute stale-data induced misdiagnosis that extends an outage by 15 minutes represents $12.5M in direct revenue loss—not counting SLA penalties, regulatory scrutiny, or reputational harm. The cost of a single such incident can exceed the annual investment in the streaming infrastructure that would have prevented it. If even a portion of such incidents are eliminated by replacing the batch pipeline feeding the diagnostic agent with a streaming backbone, the infrastructure investment is recovered in a single avoided outage.
Memory Gap → Recurring Incidents
An agent without historical context cannot recognize chronic conditions. A flapping interface, a memory leak, or a degrading optical module triggers the same alert repeatedly. Each occurrence consumes GPU inference cycles. Each occurrence generates a ticket. Each occurrence may require human escalation. The cumulative cost of a single undiagnosed chronic issue, multiplied across an enterprise network over a year, represents operational expenditure that a stateful agent could eliminate.
Delete Blindness → Compliance and Security Exposure
An agent acting on deleted records makes authorization decisions based on invalid state. A deactivated account granted access. A revoked certificate treated as valid. In regulated industries, these errors are compliance violations with defined financial penalties and reporting obligations. The cost of a single access control error caused by ghost data can exceed the annual cost of the streaming infrastructure that would have prevented it.
Schema Fragility → Silent Decision Degradation
When a batch pipeline drops a critical field, the agent does not fail loudly. It continues operating with incomplete inputs. Decisions degrade silently. The cost includes not only the direct operational impact but the effort of auditing and correcting every decision made during the degradation window. Silent failure multiplies eventual remediation cost.
Coordination Failure → Cascading Impact
When multiple agents act on inconsistent views of reality, they create new problems. Redundant changes compete. Conflicting configurations destabilize the environment. The original incident expands. The cost includes extended resolution time, additional engineering effort, and eroded trust in autonomous operations. Organizational credibility is a balance sheet item that coordination failure depletes.
The Aggregated View
Taken together, the five failure modes represent a predictable drain on AI investment returns. An organization that deploys expensive GPU infrastructure, fine-tunes capable models, and implements event-driven orchestration [3]—but feeds all of it with a batch data pipeline—has built an autonomous operations capability on a foundation that guarantees suboptimal outcomes. The streaming backbone is not an incremental cost. It is the insurance policy that protects the returns on every other AI infrastructure investment.
CONCLUSION: STREAMING-FIRST AS THE ARCHITECTURAL PREREQUISITE
The five failure modes share a common root cause. Batch data pipelines were designed for human consumers who tolerate latency, bring context, and notice anomalies. AI agents tolerate nothing. They act on what they receive.
Each failure mode is addressable within a unified streaming data architecture. Streaming telemetry solves stale data by replacing cyclical polling with continuous event push. Durable event logs solve memory gaps by preserving the sequence of events with configurable retention, allowing agents to replay history and detect patterns across time. Change data capture—a structural component of the streaming architecture implemented through Kafka Connect and Debezium—solves delete blindness by reading database transaction logs directly, capturing inserts, updates, and deletes as discrete events with explicit operation types. A schema registry with compatibility enforcement solves schema fragility by validating schema changes before they propagate downstream, catching breaking changes at the source rather than discovering them after agent failure. A shared, ordered event log solves coordination failure by serving as a single source of truth that all agents consume, ensuring every agent operates on the same reality with visibility into every other agent’s actions—complemented by intent events, idempotency keys, and lightweight leases that prevent conflicting actions without a central coordinator.
These are not disparate tools. They are structural elements of a single streaming data architecture. Apache Kafka provides the durable, shared event log at the core. Kafka Connect provides the integration framework for change data capture, ingesting database changes as first-class events. Schema Registry provides the compatibility governance layer. Together, they form a complete data foundation where stale data, memory gaps, delete blindness, schema fragility, and coordination failure are eliminated by design—not patched after the fact.
These architectural components eliminate the data-layer failure modes. But real-time data also enables real-time action—and that speed demands an execution-layer governance framework. Policy-as-code engines ensure that agent decisions, even when based on perfect context and full state, are validated against operational guardrails before they become cluster changes. The streaming backbone delivers the context. The policy layer ensures that context is acted upon safely.
This streaming architecture is not an end in itself. It is the data foundation upon which event-driven network operations can be built. While the streaming backbone eliminates the data-layer failure modes, organizations that pair it with event-driven compute unlock an additional dimension of efficiency. When a telemetry event flows through the event log and an anomaly is detected, that same stream can trigger the Kubernetes Event-driven Autoscaling (KEDA) of inference workloads [3]—spinning up the right-sized model at the right moment, on the right context. The streaming backbone delivers the context. Event-driven orchestration delivers the compute. Together, they close the loop from detection to inference, ensuring the agent has both the data and the compute it needs without the waste of always-on infrastructure.
The barrier is not technology. Each of these architectural components is proven, open-source, and deployed in production environments today. The barrier is architectural awareness. Organizations that invest in a streaming-first data architecture will deploy AI agents that deliver on their promise. Organizations that do not will discover these failure modes in production—after the wrong decision is already made.
The streaming data architecture is not a performance upgrade for Agentic AI. It is the architectural prerequisite.
REFERENCES
[1] P. Madduri and A. L. Thakur, “The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core,” IEEE ComSoc Technology Blog, April 2026. [Online]. Available: https://techblog.comsoc.org/2026/03/30/the-financial-trap-of-autonomous-networks-scaling-agentic-ai-in-the-telecom-core/
[2] Apache Software Foundation, “Apache Kafka Documentation.” [Online].
Available: https://kafka.apache.org/42/getting-started/introduction/
[3] Cloud Native Computing Foundation, “KEDA: Kubernetes Event-driven Autoscaling.” [Online]. Available: https://keda.sh/
[4] Streamkap, “Streaming ETL vs. Batch ETL: A Decision Framework.” [Online].
Available: https://streamkap.com/resources-and-guides/streaming-etl-vs-batch-etl
[5] Streamkap, “Real-Time vs Batch Data for AI Agents: Why Freshness Matters.” [Online]. Available: https://streamkap.com/resources-and-guides/real-time-vs-batch-data-for-agents
[6] Streamkap, “Why AI Agents Can’t Use Batch Data.” [Online]. Available: https://streamkap.com/resources-and-guides/why-agents-cant-use-batch-data
[7] Redpanda, “Building safe, multi-agent AI systems in Redpanda Agentic Data Plane.” [Online]. Available: https://www.redpanda.com/blog/adp-governed-multi-agent-ai-cloud
[8] Debezium Community, “Debezium: Open-Source Change Data Capture,” Debezium Documentation. [Online]. Available: https://debezium.io/
ABOUT THE AUTHOR
Shazia Hasnie, Ph.D., is VP, Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations, AI-driven automation, and streaming data architectures. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale.
Orange, Nokia, Nvidia, and Intel debate: ASICs vs. GPUs vs. General-Purpose CPUs for RAN Baseband Processing
For Orange CTO Laurent Leboucher, the main attraction of AI today lies in its potential to improve the efficiency of 5G radio access networks (RANs). That helps explain Orange’s recent collaboration with Nokia and Nvidia. Orange already deploys Nokia’s purpose-built 5G network equipment and software at mobile sites in France and other markets. Until recently, it had little obvious need for Nvidia, the U.S. chip making king best known for the graphics processing units (GPUs) used to train large language models. But Nokia and Nvidia became closely aligned last October, when Nvidia took a 3% stake in Nokia as part of a $1 billion investment. Nokia is now developing AI RAN software designed to run on GPUs.
Leboucher’s interest is driven in part by concerns over the cost of custom silicon — the application-specific integrated circuits (ASICs) used in purpose-built 5G networks. “It creates an opportunity to bring a general-purpose chipset instead of an ASIC implementation,” he told Light Reading at last week’s FutureNet World event in London. “I think we could, at some point, benefit from the economies of scale of new chipsets. That could be Nvidia.”
The rationale is much easier to understand than arguments about 5G for autonomous vehicles. Chip manufacturing is already expensive, and both Nokia and Ericsson expect component costs to rise further this year amid relentless AI demand. At the same time, the RAN market remains relatively small and has contracted. According to market research firm Omdia, telco spending fell from $45 billion in 2022 to $35 billion last year and is expected to stay at that level. In that context, it is increasingly difficult to justify designing high-cost chips with limited reuse outside telecom.

Image Credit: Orange
Last year, Nvidia spent about $18.5 billion on research and development, generated nearly $216 billion in revenue, and reported a gross margin of more than 70%. Its financial strength is not in question. If telecom operators can use its GPUs for RAN software, they may face less pressure to secure the long-term economics of 5G and 6G development. That alone could be enough to support the case for Nvidia. The counterarguments are cost and power consumption. By design, custom silicon is optimized for a specific workload and will always outperform a more general-purpose processor at that task. An Nvidia GPU in the RAN could therefore be seen as excessive — like using a crop duster to water a hanging basket.
Leboucher, believes that Nokia and Nvidia are developing something far more compact than a typical data-center deployment. “It is not a Blackwell GPU,” he said, referring to Nvidia’s current hyperscaler-class product line. “I have an understanding it’s something which is a little bit smaller.” One of the first GPU-based products is expected to come on a card that Orange can insert into an existing Nokia AirScale chassis.
He is also interested in replacing traditional RAN algorithms with AI to improve spectral efficiency and overall performance. Through trials with Nokia and Nvidia, Orange wants to determine whether a GPU is actually required to capture the full benefit. “We can completely rethink the way we are doing algorithms today, using AI for the radio Layer 1,” he said, referring to the most compute-intensive part of the RAN software stack. Some of the “AI-RAN” narrative still sounds “a little bit like science fiction,” Leboucher admitted. “But I think there are some very interesting ideas behind that. We want to understand where we are.”
This is not the first time the industry has debated a shift from ASICs to general-purpose processors for RAN equipment. Alongside its purpose-built 5G portfolio, Ericsson already offers cloud RAN products based on Intel CPUs. Samsung is now focused on Intel-based virtual RAN and has recently predicted the end of purpose-built 5G. Even so, cloud and virtual RAN still account for only a small share of live 5G deployments. Huawei and Ericsson, the two largest RAN vendors, remain committed to custom silicon development.
Nvidia’s entry into the market has clearly given Leboucher and his team more to evaluate as RAN technology becomes more sophisticated. “We are introducing new requirements for radio networks, typically for beamforming, and we have to consider the need for quite powerful chipsets,” he said. “Whether the best way to keep going is using ASICs or a general-purpose architecture – I think this is a good time to ask the question. Before, it was too early.”
The answer could shape Orange’s next major RAN decisions. The operator is preparing for what Leboucher describes as a “refresh” of RAN equipment across several countries ahead of the expected 6G launch in 2030. For the first time, he said, Orange will include cloud RAN as a “major option” in its request for proposal.
The concern around Intel as an alternative to Nvidia is its still-fragile financial position. Before December, Intel had been trying to spin off its network and edge group (NEX), which develops RAN chips. Those plans were later shelved, but the company’s net loss widened to about $4.3 billion in the most recent first quarter, from $887 million a year earlier, while revenue rose only 7% year over year to $13.6 billion. Cristina Rodriguez, who had led NEX, left this month to join Coherent, and Intel has not yet named a successor. “The shares jumped 28% in after-hours trading, taking Intel firmly into meme-stock territory,” said Radio Free Mobile analyst Richard Windsor in a blog published after results came out on April 23. “I say meme-stock because there is no other way to describe it when the shares are on a 2026 PER [price-to-earnings ratio] of 137x, and its technology looks obsolete.”
Orange places significant value on separating hardware from software, allowing the same RAN software to run across multiple hardware platforms. Ericsson and Samsung both say the virtual RAN software they have built for Intel CPUs could, with relatively modest changes, be ported to AMD silicon using the same x86 architecture or to Arm-based CPUs.
By contrast, Layer 1 code written for Nvidia GPUs and the CUDA software stack would not be portable to other platforms, according to Ericsson. “I think the main challenge we see with that is we are trying very hard to keep our stack portable, to give hardware options,” Michael Begley, Ericsson’s head of RAN compute, told Light Reading at MWC Barcelona this year. “If you go all in on one, it’s great, but you’re all in on one, and you can’t offer those other options to the operators or the ecosystem.”
Leboucher acknowledges that risk. “The risk of lock-in exists, definitely,” he said. “We really want to stay open. At the same time, we know that benefiting from a very, very large-scale general-purpose architecture should improve the TCO [total cost of ownership]. At the end of the day, it will be a trade-off. But we would welcome an architecture where we have the capacity at some point to decide to swap if we need to swap.”
Nokia’s hope is that much of the Layer 1 software written for Nvidia GPUs will eventually be deployable on other GPU platforms. But Nvidia’s near-monopoly in that segment leaves the industry with few alternatives for now. There is also optimism inside Nokia that GPU-based code could later be adapted for capable CPUs, although Ericsson’s comments suggest that would be much harder. For telecom executives, the choices made over the next couple of years may be pivotal as 6G approaches.
………………………………………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/5g/orange-weighs-nvidia-against-intel-for-5g-chips-ahead-of-new-rfp
RAN Silicon Rethink- Part II; vRAN and General-Purpose Compute
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Analysis: Nokia and Marvell partnership to develop 5G RAN silicon technology + other Nokia moves
Analysis: Nvidia’s $2 billion investment in Marvell; NVLink Fusion ecosystem & RAN vendor silicon strategy
Ericsson goes with custom silicon (rather than Nvidia GPUs) for AI RAN
Marvell shrinking share of the RAN custom silicon market & acquisition of XConn Technologies for AI data center connectivity
Custom AI Chips: Powering the next wave of Intelligent Computing
OpenAI and Broadcom in $10B deal to make custom AI chips
Will Google Cloud’s AI and data analytics revenue +TPU IP licensing income offset huge AI CAPEX to produce a decent ROI?
Big Tech AI spending binge results in massive job cuts!
Big Tech AI spending binge results in massive job cuts!
Executive Summary:
The tech industry is undergoing a massive structural realignment. Hyperscalers, Software as a Service (SaaS) vendors, and telecom network and equipment providers are aggressively slashing workforces to reallocate capital toward massive AI infrastructure investments. Alphabet, Meta, Amazon, and Microsoft are projected to spend a collective $674 billion in 2026—over double their 2024 levels. Most of that spending is AI related.
From the referenced WSJ article:
“Tech companies are in effect playing a game of chicken with each other on capital-spending plans. They are shelling out as much as they can—more than their rivals, they hope—on AI chips and data centers that could put them in the lead in a race they feel they can’t afford to lose. That in turn is heightening competition over who can use AI to help do more with a lot less, freeing up money to spend on expensive chips.”
Hyperscalers, such as Microsoft and Meta Platforms (Meta), are the latest to their significantly reduce their workforces to scale AI-driven operations. Meta is reportedly reducing its headcount by approximately 8,000, while Microsoft has initiated a “voluntary retirement program” (aka a buyout) targeting 7% of its U.S. workforce—a strategic move to trim payroll before resorting to involuntary layoffs.
This trend is industry-wide: Oracle and Snap have executed significant reductions, while Block announced plans to cut 40% of its staff (over 4,000 employees). March 2026 represented a two-year peak in tech industry contraction, with Layoffs.fyi reporting 45,800 tech job reductions.
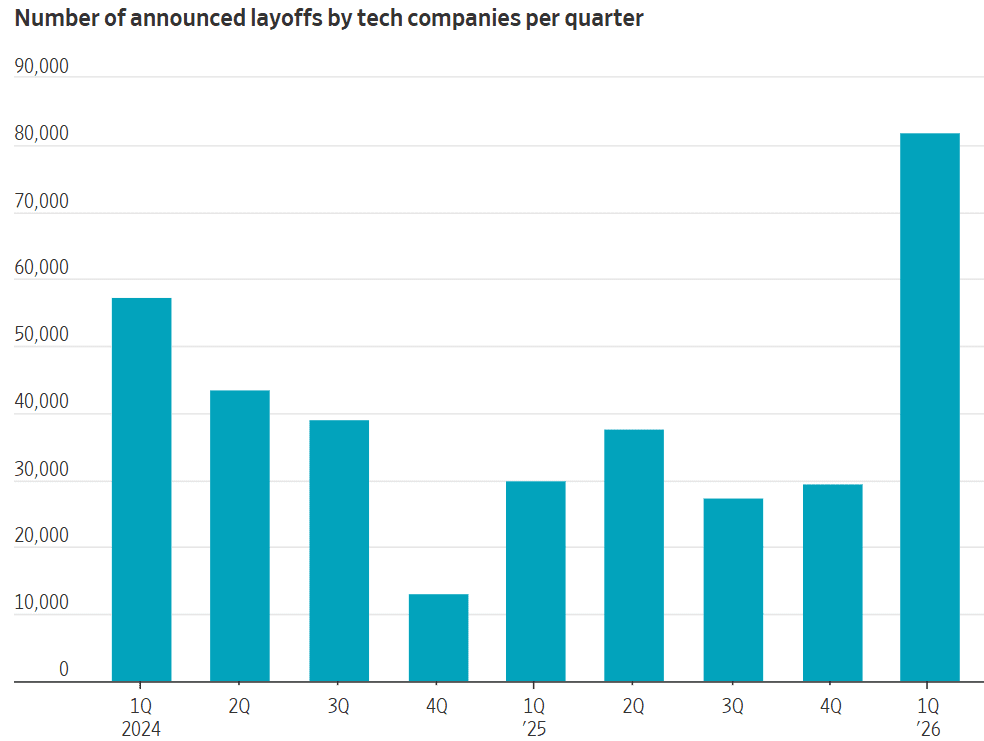
The AI Transformation Narrative vs. Financial Reality:
Executive leadership is framing these cuts as a strategic pivot toward an AI-native future where automated workflows replace legacy human-centric processes. While CEOs like Block’s Jack Dorsey insist these decisions aren’t driven by distress, a “game of chicken” is unfolding in capital planning.
Companies are locked in an escalating race to secure AI silicon (GPUs), High Bandwidth Memory (HBM) and expand Data Center footprints, creating a massive drain on liquidity. This heightens the pressure to achieve “doing more with less”—using AI to automate internal functions and free up the capital necessary for expensive infrastructure. However, in many cases, these cuts are simply corrective measures for pandemic-era overhiring or efforts to normalize efficiency metrics:
- Oracle: Annual revenue per employee remains significantly below industry leaders like Microsoft.
- Snap: Headcount remains 65% above pre-COVID levels despite consistent operating losses.
Strategic Risks and “Off-Balance-Sheet” Engineering:
While slashing headcounts improves Revenue Per Employee (RPE)—a key KPI for Wall Street—it introduces significant long-term risks:
- Talent Attrition & Brain Drain: Aggressive layoffs degrade morale and may drive elite engineering talent toward startups, potentially creating new competitors.
- Governance & Safety: Reducing human oversight during AI deployment could lead to safety and business model integration failures.
- Regulatory & Public Backlash: The “AI as a job killer” narrative is fueling community opposition to massive data center builds, complicating infrastructure rollouts.
The CAPEX Burden:
The financial strain is becoming evident even for “Deep Pocket” firms. Alphabet, Meta, Amazon, and Microsoft are projected to spend $674 billion in CAPEX this year—more than double their 2022 spend.
- Amazon is projected to be cash-flow negative this year.
- Meta’s CAPEX is set to exceed 50% of its annual revenue, with its debt-to-equity ratio climbing to 39% (up from 8% five years ago).
- Some firms are reportedly utilizing “off-balance-sheet financial wizardry” to maintain their AI compute growth without alarming debt markets.
Verdict of the Market?
Markets are sending mixed signals. While analysts are obsessed with efficiency metrics (questions about efficiency on earnings calls have tripled in two years), they are becoming “skittish” regarding unbridled spending. Tesla (TSLA), for instance, saw a 4% stock dip after raising its spending target to $25 billion.
Ultimately, tech giants—who already average $2M in annual revenue per employee—are betting that further workforce reductions will juice efficiency and fund the AI arms race. The trade-off remains whether these “leaner” organizations can maintain the innovation and safety standards required to lead the next technological cycle.
The telecom sector is particularly vulnerable, as AI-native “zero-touch” operations begin to replace legacy roles permanently.
- Network Operators:BT has announced plans to replace up to 10,000 roles with AI by 2030, specifically targeting network management and customer service.
- Network Equipment Vendors: Equipment giants Ericsson and Nokia have collectively shed over 36,000 roles in recent years, pivoting from traditional hardware to AI-optimized software and networking.
- Integrators:Accenture and IBM are utilizing AI to automate junior-level coding and back-office HR tasks, signaling that AI reskilling is now a prerequisite for workforce retention.
Strategic Outlook – Monetization and the “RPE” Battle:
For both MNOs and tech giants, the coming years are about monetization. Investors have shifted from cheering bold AI visions to demanding tangible results, with a heavy focus on Revenue Per Employee (RPE)—a metric that workforce reductions are designed to “juice.”
That “Great Realignment” is a high-stakes gamble, in this author’s opinion. The firms that successfully bridge the gap between massive infrastructure investments and scalable, profitable AI-native services will lead the next generation of global technology. Those that fail to balance efficiency with talent retention may find themselves outpaced by leaner, AI-native startups born from the very talent they have released.
References:
https://www.wsj.com/tech/ai/the-ai-splurge-is-costing-big-tech-its-workforce-34a88e68
AI spending boom accelerates: Big tech to invest an aggregate of $400 billion in 2025; much more in 2026!
AI infrastructure spending boom: a path towards AGI or speculative bubble?
Gartner: AI spending >$2 trillion in 2026 driven by hyperscalers data center investments
AI spending is surging; companies accelerate AI adoption, but job cuts loom large
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Canalys & Gartner: AI investments drive growth in cloud infrastructure spending
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Yesterday, a STL Partners webinar titled “Turning autonomy into margin: Agentic AI and the autonomous RAN,” suggested agentic AI is the missing layer that can turn RAN autonomy from a technical goal into a direct profit margin booster. It argues that operators should prioritize autonomy use cases by business impact, not just by how much automation coverage they add, and that the right roadmap can move autonomy from an engineering KPI to a commercial advantage.
The central message was that autonomy only matters if it improves economics (see poll results below). The webinar revealed that network operators need a dual-axis framework that combines the usual autonomous-network maturity view with a value-creation lens, so they can focus on the capabilities that scale into measurable business outcomes.
Agentic AI is presented as the practical enabler for moving beyond human-in-the-loop operations. In this framing, agents help orchestrate tasks, make decisions, and coordinate network actions in ways that support more closed-loop automation than traditional workflows can deliver.
The results of an “actuality” poll relating to RAN autonomy revealed that controlling costs and reliability were most important, with the enablement of new revenue growth through APIs and sensing only scoring 10.87% of respondents. Similarly, results for an “aspirations” poll for RAN autonomy were also fairly evenly spread between reducing costs and optimizing the customer experience, with just 13.21% citing new revenue growth.
Source: STL Partners
Terje Jensen, SVP, global business security officer and head of network and cloud technology strategy at Telenor, said that he had expected to see network operators’ aspirations shift more clearly towards improving customer experience and even revenue generation, not just efficiency.
Darwin Janz, strategic technology planner at SaskTel, also thought network operators’ ambitions would be higher, but he noted that they still struggle to identify concrete, monetizable use cases. Without that, there’s a real risk of building technical solutions in search of a problem, rather than starting from clear enterprise needs and value, Darwin noted. “We really need to see those use cases and enterprise customer needs,” he added.
……………………………………………………………………………………………………………………….
The webinar was built around four practical questions:
- Which use cases create real commercial impact?
- How to shift from autonomy as an engineering metric to a margin driver?
- Where agentic does AI add value today?
- What data, orchestration, and organizational foundations are needed to scale beyond pilots.
For network operators, the implication is that autonomous RAN strategy should be tied to P&L outcomes such as lower operating cost, better resource utilization, and faster optimization cycles. The webinar’s message is that autonomy becomes strategically important only when it is deployed in a way that compounds across the network and business.
…………………………………………………………………………………………………………………..
References:
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
