

AI data centers
Hyperscaler AI Race: Soaring Capex Wipes Out Free Cash Flow; AGI and Digital Gods
| Company | 2024 (Actual) | 2025 (Actual) | 2026 (Current Guidance / Est) | 2027 (Projected) |
|---|---|---|---|---|
| 📦 Amazon | $53B | $112B | $195B – $210B | $230B – $260B |
| 🔍 Alphabet (Google) | $51B | $104B | $195B – $205B | $240B – $280B |
| 💻 Microsoft | $56B | $108B | $185B – $195B | $220B – $250B |
| ♾️ Meta | $38B | $85B | $125B – $145B | $150B – $180B |
| 🗄️ Oracle | $13B | $25B | $45B – $50B | $55B – $65B |
| 🧮 Combined Aggregate | $211B | $434B | $745B – $805B | $895B – $1,035B |
The huge increase in hyperscaler capex, wipes out their free cash flow (revenues-expenses is now negative for all but Microsoft). The shift in focus by investors from earnings to free cash flow marks a turning point in market perceptions. The correct way to describe free cash flow is the cash flow a company generates during a period of time that is available to be paid to the company’s shareholders and debtholders.Companies with negative free cash flow are only able to cover the interest and principal on their debt by additional borrowing or by issuing new equity. In other words, cash is flowing from investors to the company, not the other way around. In a financial crisis, investors become unwilling to support companies not able to cover interest and principal, with the result being a cascade of defaults and runs on financial institutions.
A major concern with the massive AI-capex which has occurred during the last two years is that much of it is debt financed. As the real cost of generative AI-tokens is becoming clear, lower priced Chinese competitors are emerging, and AI customers are beginning to economize on their use of AI. As a result, investors are becoming increasingly alarmed about whether U.S. AI firms will be able to cover their debt obligations. AI-capex has been the main, and perhaps only driver of U.S. economic growth. If more companies announce negative free cash flows, that increase in magnitude, the financial system and overall economy will move closer to the tipping point.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
But wait, Google/Alphabet co-founder says it’s more about winning AI market share than skyrocketing capex or ROI. On Patrick O’Shaughnessy’s Invest Like the Best podcast, Gavin Baker, Chief Investment Officer for Atreides Management, shared an anecdote about what’s been going on within Google/Alphabet offices. According to Baker, Google co-founder Larry Page has been telling Google employees, “I am willing to go bankrupt rather than lose this race.” That shows how high the person who led Alphabet through its halcyon days thinks the stakes are in AI.
References:
https://www.fool.com/investing/2024/08/31/thinking-of-selling-nvidia-stock-larry-page-quote/
Curmudgeon: Caveat Emptor: Huge Debt and Circular Financing Deals Dominate AI Build-Outs
Merry-go-round of dog chasing its tail: Relationship between U.S. hyperscalers and private Gen AI companies
Ookla: AI platform reliability decreases as outages surge
Nvidia CEO Huang: AI is the largest infrastructure buildout in human history; AI Data Center CAPEX will generate new revenue streams for operators
Hyperscaler capex > $600 bn in 2026 a 36% increase over 2025 while global spending on cloud infrastructure services skyrockets
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Bloomberg: Meta to sell AI compute in a new cloud services offering
Disclaimer: Perplexity.ai was used for research resulting in this article.
Executive Summary:
According to Bloomberg, Meta Platforms is advancing plans to commercialize its internal AI infrastructure through a new cloud services offering, signaling a strategic expansion beyond its traditional hyperscale consumer platforms into the competitive AI infrastructure market. This initiative would position Meta alongside established cloud providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, while also overlapping with emerging GPU-centric “neocloud” providers. Meta’s move represents a significant evolution in the AI infrastructure landscape, with potential ripple effects across data center architecture, optical transport networks, and the broader telecom ecosystem.
At the core of this strategy is the monetization of Meta’s rapidly expanding AI compute footprint. The company has aggressively invested in large-scale data center infrastructure—reportedly including multi-hundred-billion-dollar campus developments—to support training and inference for its proprietary large language models (LLMs) and recommendation systems. As these deployments scale, Meta appears to be seeking to externalize surplus capacity, transforming a cost center into a revenue-generating platform.
The proposed service portfolio is expected to span two primary layers. First, Meta may expose access to hosted AI models via APIs, analogous to AWS Bedrock or Azure AI Services, enabling enterprises to integrate generative AI and foundation model capabilities without managing underlying infrastructure. Second, Meta is exploring the provision of raw compute capacity—primarily GPU-accelerated workloads—mirroring the infrastructure-as-a-service (IaaS) model offered by neocloud providers such as CoreWeave. This dual-layer approach would allow Meta to compete both in higher-margin AI platform services and in lower-level compute provisioning.
Telecom & Networking Implications:
From a telecom and network infrastructure perspective, this development has several implications. Hyperscale AI workloads are increasingly bandwidth-intensive, requiring high-capacity, low-latency interconnects within and between data centers. Meta’s investments are therefore likely to drive demand for advanced optical networking technologies, including coherent pluggable optics (e.g., 400ZR/800ZR), data center interconnect (DCI) architectures, and AI-optimized fabric designs leveraging Ethernet-based scale-out topologies. In addition, the geographic placement of these data centers—often in power-abundant, rural locations—introduces new requirements for long-haul fiber connectivity and edge aggregation.
The initiative, internally referred to as “Meta Compute,” reflects a broader industry shift toward vertically integrated AI infrastructure stacks, where hyperscalers tightly couple compute, networking, and software frameworks. For telecom operators and infrastructure vendors, this trend underscores the growing convergence between cloud, AI, and network domains, particularly as AI-driven workloads begin to influence traffic patterns, peering strategies, and edge deployment models.
Strategically, Meta’s entry into the AI cloud market raises competitive pressure across multiple fronts. Unlike traditional cloud providers, Meta brings extensive experience in hyperscale distributed systems and open-source AI frameworks (e.g., PyTorch), but lacks a mature enterprise cloud ecosystem. Its success will likely depend on its ability to translate internal infrastructure efficiencies into externally consumable services, while addressing enterprise requirements for reliability, security, and service-level agreements.
Meta’s cloud push is best viewed as a network-and-infrastructure strategy as much as a software business, because monetizing AI capacity depends on how well it can expose compute, move data, and preserve performance at hyperscale. The telecom significance is that Meta is turning internal AI infrastructure into a market-facing platform, which increases the importance of optical transport, data-center interconnect, and low-latency backbone engineering.
From a telecom perspective, the key issue is not simply that Meta may sell AI models or GPU capacity; it is that the company is building a service layer on top of a very large, power- and bandwidth-intensive distributed system. Reuters reported that Meta is considering both hosted model access and raw compute sales, with the former resembling an AI platform service and the latter looking more like neocloud infrastructure.That means the network becomes part of Meta’s product offering. Large AI inference and training environments require high-bisection fabrics inside the data center, plus dense east-west traffic handling, which pushes demand for faster Ethernet switching, advanced optical modules, and carefully engineered rack-to-rack and site-to-site interconnects. Meta’s AI cloud ambitions reinforce a broader shift: hyperscalers are no longer treating networking as a background utility, but as a primary constraint on scale.
Network World’s coverage of Meta Compute notes that Meta has unified data center and network oversight and is planning multi-gigawatt AI buildouts, underscoring how tightly power, fiber, switching, and facility design are now linked.
For network operators and vendors, that translates into stronger demand for long-haul fiber, DCI platforms, low-latency transport, and high-radix switching. It also raises the strategic value of metro and regional interconnect corridors that can support AI clusters, especially when capacity must be spread across multiple sites for power, land, or resiliency reasons.
Meta’s potential move into raw compute sales is especially relevant to telecom because it resembles the economics of infrastructure-heavy cloud and colocation models. In practice, the service quality will depend on how efficiently Meta can provision GPU clusters, maintain deterministic performance, and avoid congestion across the transport layer connecting those clusters. That implies growing importance for:
-
Coherent optical transport and scalable DCI.
-
High-capacity Ethernet fabrics for AI clusters.
-
Open-rack and disaggregated infrastructure designs.
-
Network automation that can track workload placement and traffic hotspots.
These are not just cloud concerns; they are telecom-grade capacity-planning problems. As AI clusters become larger and more distributed, network planning starts to look more like core network engineering than conventional enterprise hosting.

Image Credits: Gabby Jones/Bloomberg / Getty Images
……………………………………………………………………………………………………………………………………………………………………..
Conclusions:
Meta’s entry would not only compete with AWS, Azure, and Google Cloud, but could also pressure specialized neocloud providers more directly. Reuters noted that Meta’s spare capacity could matter more to neo-cloud vendors than to the largest hyperscalers, because those providers rely on access to external GPU supply and managed infrastructure growth. For telecom analysts, that suggests the competitive battleground is shifting from “who has the best model” to “who can deliver the most resilient compute-network-power stack.” The winners will likely be those that can couple AI accelerators with fiber-rich sites, robust interconnect, and energy-secure data center footprints.
Meta’s move reflects the convergence of cloud, AI, and transport networks. The story is less about Meta becoming a generic cloud vendor and more about hyperscale AI infrastructure evolving into a new class of network-dependent utility. Indeed, Meta’s cloud initiative highlights a broader industry reality — in the AI era, compute is valuable, but connectivity, optical scale, and power-aware architecture increasingly determine whether compute can be monetized at all.
……………………………………………………………………………………………………………………………………….
References:
Meta, like SpaceX, looks to turn excess AI compute into cash
https://www.cnbc.com/2026/05/27/mark-zuckerberg-says-meta-starting-cloud-business-on-the-table.html
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
OCP 2025 Meta keynote: Scaling the AI Infrastructure to Data Center Regions
TechCrunch: Meta to build $10 billion Subsea Cable to manage its global data traffic
AI Frenzy Backgrounder; Review of AI Products and Services from Nvidia, Microsoft, Amazon, Google and Meta; Conclusions
Bharti Airtel and Meta extend 2Africa Pearls subsea cable system to India
Is AI the driving force behind the metaverse?
Big Fiber’s $250M financing deal to buildout dark fiber routes for AI Data Center expansion
Executive Summary:
Big Fiber [1.] has secured $250 million in financing from Stonepeak and Caisse de dépôt et placement du Québec (CDPQ) to expand its dark fiber footprint and increase network capacity in response to accelerating hyperscaler and large-scale data center investments in AI-driven workloads.
Note 1. Sunnyvale, CA headquartered Big Fiber was previously known as Bandwidth IG, which was originally established in 2019 as a telecom and dark-fiber infrastructure company. The rebrand to BIG Fiber was announced on May 1, 2025 when the company described it as a shift to better reflect its focus on privately owned, newly constructed dark fiber networks. The company has built privately owned metro dark fiber networks from its inception, primarily in the SF Bay Area and the Greater Portland, OR and Atlanta, GA areas.
BIG Fiber structures its dark fiber portfolio around high‑strand‑count, single‑mode, low‑loss fiber deployed in purpose‑built, underground metro and regional routes, rather than a carrier‑specific “technology” stack of its own. The company’s public materials emphasize:
-
Single‑mode fiber (SMF) for metro and long‑haul connectivity, consistent with standard dark‑fiber infrastructure designed for multi‑wavelength and DWDM‑based upgrades.
-
High‑density, high‑fiber‑count cables in metro corridors (often hundreds of strands) to support dense data‑center and interconnect demand, which is typical of “new‑build” dark‑fiber operators entering AI‑and‑cloud‑centric markets.
-
Point‑to‑point and ring‑style topologies engineered for extreme route diversity (tri‑/quad‑versity) and low latency, rather than a legacy long‑haul backbone that relies on older fiber types or managed wavelengths.
To complement Big Fiber’s dark‑fiber infrastructure; the customer provides the optical PHY layer (e.g., coherent DWDM, 400ZR/ZR+, or other high‑speed optics), which is how dark‑fiber providers typically position their offerings.
–>More about Big Fiber at the end of this article from the company itself.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
Proceeds of the facility will be used to refinance existing debt, provide new capital and facilitate the necessary headroom for major fiber optic network expansions already underway. This includes a significant multi-market buildout in Greater Atlanta, adding over 205 route miles and 165,000 fiber miles to BIG Fiber’s existing market-leading footprint.
“Our partnership with Stonepeak Credit and La Caisse marks a pivotal moment in our mission to empower our customers with highly scalable and purpose-built dark fiber solutions,” said Bruce Garrison, CEO of BIG Fiber. “This financing ensures we have the scale to stay ahead of the escalating demand for modernized infrastructure enabling the AI ecosystem and the necessary digital highways for decades to come.”
“BIG Fiber’s infrastructure delivers critical bandwidth to meet the insatiable demand for both data and compute capacity across its key markets,” said Arun Varanasi, Managing Director at Stonepeak Credit. “We are proud to partner with Columbia Capital, SDC Capital Partners, and La Caisse to support the company’s next leg of growth as it positions itself as one of the preeminent dark fiber operators in the country.”
“BIG Fiber is well positioned to meet the growing connectivity needs of enterprises and data centers seeking new, high-quality infrastructure options,” said Jérôme Marquis, Managing Director and Head of Private Credit at La Caisse. “Its resilient business model, underpinned by long-term contracts and strong structural demand, positions the company well for growth. Together with Stonepeak Credit, we’re providing a tailored financing solution that supports the continued buildout of essential digital infrastructure.”
The latest expansion will bring BIG Fiber’s Atlanta and San Francisco Bay Area network capacity to 850 route miles and over 3 million fiber miles. Projects are currently under construction or contract, with phased Ready for Service (RFS) dates expected in early 2027.

………………………………………………………………………………………………………………………………………………………………………………………………………………………………
According to Big Fiber Chief Commercial Officer Patton Lochridge, demand signals are particularly strong in key U.S. metros including the San Francisco Bay Area, Hillsboro, and Atlanta, where new fiber routes are being deployed to support AI-centric data center expansion. “We’re seeing customers require extreme route diversity, often moving toward triversity or quadversity networks to connect metro assets and long-haul routes,” Lochridge said. He added that inference workloads are increasing the demand for dense metro connectivity: “Traditional telecommunications networks are often too congested or lack the latency and loss tolerances required for stringent AI workloads, making purpose-built metro fiber essential.” Lochridge indicated that the majority of the new capital will be directed toward greenfield build-outs and targeted overbuilds of “exhausted legacy telecommunications corridors that need more scale.”
Industry analysts highlight a parallel geographic shift in AI infrastructure deployment. Sterling Perrin, senior principal analyst for optical networks and transport at Omdia, noted that AI campuses are expanding beyond traditional connectivity hubs such as Ashburn, Dallas, and Northern California into power-advantaged regions including West Texas, Ohio, Tennessee, Louisiana, and Georgia. “They all require massive fiber optic connectivity,” Perrin said.
Power availability is emerging as a primary constraint shaping network topology. Ron Westfall, vice president and analyst at HyperFrame Research, emphasized that grid limitations are driving hyperscalers toward distributed AI campus architectures interconnected via metro and long-haul dark fiber. “Power grid constraints have forced a material shift toward metro and long-haul dark fiber infrastructure to stitch together distributed regional data center campuses,” Westfall said. “Because this relentless GPU-to-GPU communication demands near-zero latency and unprecedented bandwidth, infrastructure planners are prioritizing the deployment of ultra-high-strand dark fiber corridors that directly link distributed, power-rich data centers.”
AI Workloads Reshape Optical Demand:
AI-driven traffic growth is now materially impacting the optical supply chain. In its April 2026 post-OFC analysis, CRU Group reported that AI-related data center demand “has overtaken traditional telecom as the primary growth engine for optical [fiber] and cable,” contributing to tightening supply conditions for high-fiber-count cables and upstream preform materials.
Despite this surge, the majority of AI traffic remains intra-data-center. Omdia estimates indicate that up to 90% of AI traffic does not exit the facility during GPU cluster operations. However, the emergence of distributed AI architectures is beginning to increase requirements for high-capacity inter-data-center interconnect (DCI).
At the Optica Executive Forum, Cisco SVP and Fellow Rakesh Chopra highlighted the scale differential between AI and conventional traffic profiles. As cited by Perrin, AI “scale-up” traffic within data centers can generate 504 times more traffic than traditional DCI flows, while “scale-out” traffic can produce 56 times DCI bandwidth requirements. “With AI training models at the limits of what can be processed within a data center, distributed AI clusters are inevitable,” Perrin said.
This architectural transition is reflected in NVIDIA’s AI factory designs, which decouple east-west GPU compute traffic from traditional north-south enterprise flows, leveraging low-latency leaf-spine topologies optimized for continuous GPU synchronization.
Westfall further noted that these evolving traffic patterns are fundamentally altering network design assumptions. Operators are increasingly optimizing for persistent machine-to-machine synchronization rather than burst-oriented enterprise traffic models.
Fiber as a Core AI Infrastructure Asset:
The Big Fiber’s latest financing aligns with broader trends in AI infrastructure investment, where capital is being deployed across integrated stacks including energy, land, connectivity, and compute infrastructure. Utilities are expanding transmission capacity, while developers are co-locating generation resources near emerging AI hubs.
Within this context, fiber infrastructure is being revalued based on its strategic proximity to power-rich data center clusters. “Infrastructure monetization is shifting away from historical metrics such as per-megabit pricing toward asset-level valuations built around proximity to power-rich data centers,” Westfall said.
If current deployment trajectories persist, the resulting topology will consist of a dense, high-capacity mesh of metro and long-haul fiber routes interconnecting geographically distributed, power-optimized AI campuses with hyperscale cloud and interconnection ecosystems.
………………………………………………………………………………………………………………………………
About BIG Fiber:
BIG Fiber is a metro dark fiber provider that offers high capacity, strategically placed, dark fiber networks to mission critical data centers, Hyperscalers and enterprises throughout the San Francisco Bay Area, Greater Portland and Greater Atlanta areas. BIG Fiber’s 100% underground network meets critical data needs for enterprises and data centers that require new, quality infrastructure options. BIG Fiber’s San Francisco Bay Area network offers more than 320 route miles and 65 data centers. The Greater Portland network has more than 20 route miles and 15 data centers, and the Greater Atlanta network has more than 550 route miles and 30 data centers. BIG Fiber was founded in 2019 and is headquartered in Sunnyvale, California. Visit www.bigfiber.com to learn more.
………………………………………………………………………………………………………………………………
References:
BIG Fiber Secures $250 Million Financing Led by Stonepeak Credit and La Caisse
Analysis: Fiber Broadband Association (FBA) whitepaper: Upgrading MSO Networks to Fiber to the Home (FTTH): A Technical Perspective
Fiber Broadband Association Middle Mile WG: how to use “Digital Infrastructure Networks” for coordinated fiber backbone investments
Analysis: AT&T 1Q-2026 results: increased fiber penetration, FWA momentum, D2D deals, and mobile/home internet bundles
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
Fiber Optic Networks & Subsea Cable Systems as the foundation for AI and Cloud services
How will fiber and equipment vendors meet the increased demand for fiber optics in 2026 due to AI data center buildouts?
Automating Fiber Testing in the Last Mile: An Experiment from the Field
AI wireless and fiber optic network technologies; IMT 2030 “native AI” concept
Nvidia strategic partnership with IREN targets 5G Watts AI infrastructure buildout + $2.1B investment option
Nvidia has announced a strategic partnership with cloud AI data center operator IREN [1.] to deploy up to 5G Watts (5GW) of AI infrastructure, driven by a $3.4 billion services contract and a $2.1 billion investment option for Nvidia. This collaboration aims to secure critical, high-density data center capacity for AI workloads while accelerating IREN’s transition into a major AI infrastructure provider. This strategic expansion targets up to 5GW of NVIDIA DSX-aligned AI infrastructure across IREN’s global pipeline. The roadmap centers on the 2GW Sweetwater campus in Texas, positioned to be the flagship deployment of NVIDIA’s DSX factory architecture. This integrated model synergizes NVIDIA’s reference designs with IREN’s core competencies in utility-scale power procurement, site development, and full-stack GPU cloud operations.

“AI factories are becoming foundational infrastructure for the global economy,” said Jensen Huang, founder and CEO of Nvidia. “Deploying these systems at scale requires deep integration across the full stack — compute, networking, software, power and operations. IREN brings the scale and infrastructure expertise to help accelerate the buildout of next-generation AI infrastructure globally. Together, we are building for the age of AI,” he added. Future deployments are expected to focus on IREN’s 2-gigawatt Sweetwater campus in Texas, which the companies expect to serve as a flagship deployment for Nvidia’s DSX architecture.
“This partnership combines NVIDIA’s AI systems and architecture leadership with IREN’s expertise across power, land, data centers, GPU deployment and infrastructure operations,” said Daniel Roberts, cofounder and co-CEO of IREN. “Together, we believe we can accelerate deployment of AI infrastructure and expand access to compute for AI-native and enterprise customers globally.”
References:
China vs U.S.: Race to Generate Power for AI Data Centers as Electricity Demand Soars
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
How will fiber and equipment vendors meet the increased demand for fiber optics in 2026 due to AI data center buildouts?
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Expose: AI is more than a bubble; it’s a data center debt bomb
Can the debt fueling the new wave of AI infrastructure buildouts ever be repaid?
Big Tech AI spending binge results in massive job cuts!
Executive Summary:
The tech industry is undergoing a massive structural realignment. Hyperscalers, Software as a Service (SaaS) vendors, and telecom network and equipment providers are aggressively slashing workforces to reallocate capital toward massive AI infrastructure investments. Alphabet, Meta, Amazon, and Microsoft are projected to spend a collective $674 billion in 2026—over double their 2024 levels. Most of that spending is AI related.
From the referenced WSJ article:
“Tech companies are in effect playing a game of chicken with each other on capital-spending plans. They are shelling out as much as they can—more than their rivals, they hope—on AI chips and data centers that could put them in the lead in a race they feel they can’t afford to lose. That in turn is heightening competition over who can use AI to help do more with a lot less, freeing up money to spend on expensive chips.”
Hyperscalers, such as Microsoft and Meta Platforms (Meta), are the latest to their significantly reduce their workforces to scale AI-driven operations. Meta is reportedly reducing its headcount by approximately 8,000, while Microsoft has initiated a “voluntary retirement program” (aka a buyout) targeting 7% of its U.S. workforce—a strategic move to trim payroll before resorting to involuntary layoffs.
This trend is industry-wide: Oracle and Snap have executed significant reductions, while Block announced plans to cut 40% of its staff (over 4,000 employees). March 2026 represented a two-year peak in tech industry contraction, with Layoffs.fyi reporting 45,800 tech job reductions.
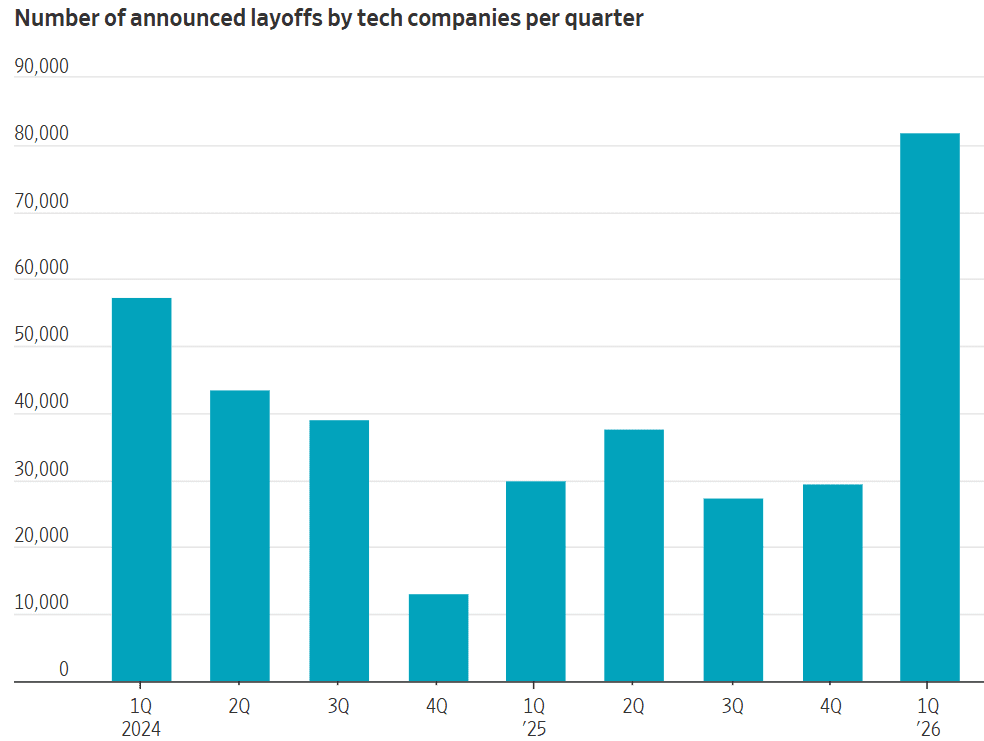
The AI Transformation Narrative vs. Financial Reality:
Executive leadership is framing these cuts as a strategic pivot toward an AI-native future where automated workflows replace legacy human-centric processes. While CEOs like Block’s Jack Dorsey insist these decisions aren’t driven by distress, a “game of chicken” is unfolding in capital planning.
Companies are locked in an escalating race to secure AI silicon (GPUs), High Bandwidth Memory (HBM) and expand Data Center footprints, creating a massive drain on liquidity. This heightens the pressure to achieve “doing more with less”—using AI to automate internal functions and free up the capital necessary for expensive infrastructure. However, in many cases, these cuts are simply corrective measures for pandemic-era overhiring or efforts to normalize efficiency metrics:
- Oracle: Annual revenue per employee remains significantly below industry leaders like Microsoft.
- Snap: Headcount remains 65% above pre-COVID levels despite consistent operating losses.
Strategic Risks and “Off-Balance-Sheet” Engineering:
While slashing headcounts improves Revenue Per Employee (RPE)—a key KPI for Wall Street—it introduces significant long-term risks:
- Talent Attrition & Brain Drain: Aggressive layoffs degrade morale and may drive elite engineering talent toward startups, potentially creating new competitors.
- Governance & Safety: Reducing human oversight during AI deployment could lead to safety and business model integration failures.
- Regulatory & Public Backlash: The “AI as a job killer” narrative is fueling community opposition to massive data center builds, complicating infrastructure rollouts.
The CAPEX Burden:
The financial strain is becoming evident even for “Deep Pocket” firms. Alphabet, Meta, Amazon, and Microsoft are projected to spend $674 billion in CAPEX this year—more than double their 2022 spend.
- Amazon is projected to be cash-flow negative this year.
- Meta’s CAPEX is set to exceed 50% of its annual revenue, with its debt-to-equity ratio climbing to 39% (up from 8% five years ago).
- Some firms are reportedly utilizing “off-balance-sheet financial wizardry” to maintain their AI compute growth without alarming debt markets.
Verdict of the Market?
Markets are sending mixed signals. While analysts are obsessed with efficiency metrics (questions about efficiency on earnings calls have tripled in two years), they are becoming “skittish” regarding unbridled spending. Tesla (TSLA), for instance, saw a 4% stock dip after raising its spending target to $25 billion.
Ultimately, tech giants—who already average $2M in annual revenue per employee—are betting that further workforce reductions will juice efficiency and fund the AI arms race. The trade-off remains whether these “leaner” organizations can maintain the innovation and safety standards required to lead the next technological cycle.
The telecom sector is particularly vulnerable, as AI-native “zero-touch” operations begin to replace legacy roles permanently.
- Network Operators:BT has announced plans to replace up to 10,000 roles with AI by 2030, specifically targeting network management and customer service.
- Network Equipment Vendors: Equipment giants Ericsson and Nokia have collectively shed over 36,000 roles in recent years, pivoting from traditional hardware to AI-optimized software and networking.
- Integrators:Accenture and IBM are utilizing AI to automate junior-level coding and back-office HR tasks, signaling that AI reskilling is now a prerequisite for workforce retention.
Strategic Outlook – Monetization and the “RPE” Battle:
For both MNOs and tech giants, the coming years are about monetization. Investors have shifted from cheering bold AI visions to demanding tangible results, with a heavy focus on Revenue Per Employee (RPE)—a metric that workforce reductions are designed to “juice.”
That “Great Realignment” is a high-stakes gamble, in this author’s opinion. The firms that successfully bridge the gap between massive infrastructure investments and scalable, profitable AI-native services will lead the next generation of global technology. Those that fail to balance efficiency with talent retention may find themselves outpaced by leaner, AI-native startups born from the very talent they have released.
References:
https://www.wsj.com/tech/ai/the-ai-splurge-is-costing-big-tech-its-workforce-34a88e68
AI spending boom accelerates: Big tech to invest an aggregate of $400 billion in 2025; much more in 2026!
AI infrastructure spending boom: a path towards AGI or speculative bubble?
Gartner: AI spending >$2 trillion in 2026 driven by hyperscalers data center investments
AI spending is surging; companies accelerate AI adoption, but job cuts loom large
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Canalys & Gartner: AI investments drive growth in cloud infrastructure spending
Will Google Cloud’s AI and data analytics revenue +TPU IP licensing income offset huge AI CAPEX to produce a decent ROI?
An April 24th Investors Business Daily (IBD) article asserts that Google’s AI position is strong, but the real test will be monetization. Specifically, can Gemini translate technical lead and user scale into durable profits for parent company Alphabet? The company has benefited from AI enthusiasm and Google Cloud momentum, but investors are now focused on whether heavy AI spending will generate sufficient revenues to justify the enormous capex ramp up. The article highlights Gemini’s growing traction, Google Cloud’s rapid expansion, and a very large backlog as signs of demand, but it also stresses that those positives must offset rising infrastructure costs.
With its Gemini family, Google continues to push its AI technology across the “stack,” (see quote below) deploying it to Google Maps, enterprise Workplace productivity tools, and YouTube’s content and ad platforms. AI technology is even making Google’s autonomous vehicle company, Waymo, better and safer amid its large market expansion.
A key theme is that Google has multiple ways to earn revenue from AI, including consumer subscriptions, enterprise software, and cloud services. The article points to Gemini Advanced as an example of paid AI packaging, while also implying that the larger opportunity is converting AI usage into higher-value cloud and platform revenue rather than just user growth. However, Alphabet is planning very large AI infrastructure spending (much more below), and the article questions whether the company can turn that investment into sustainable high-margin revenue fast enough to satisfy investors.
Google has also ventured into AI semiconductors with its AI accelerator Tensor Processing Unit, known as TPU, co-developed with Broadcom and manufactured by TSMC (Taiwan Semiconductor Manufacturing Company). Google is shifting future TPU generation designs to include MediaTek for design support, with TSMC continuing as the primary fabrication partner for advanced 2nm, 3nm, and 5nm nodes.
Google has recently introduced the 7th-gen “Ironwood“ TPU 7x and revealed plans for the 8th-gen TPU 8t and TPU 8i for 2027. Long time colleague Amin Vadat, PhD wrote in a blog post, “We are introducing the eighth generation of Google’s custom Tensor Processor Unit (TPU), coming soon with two distinct, purpose-built architectures for training and inference: TPU 8t and TPU 8i. These two chips are designed to power our custom-built supercomputers, to drive everything from cutting-edge model training and agent development, to massive inference workloads. TPUs have been powering leading foundation models, including Gemini, for years. These 8th generation TPUs together will deliver scale, efficiency and capabilities across training, serving and agentic workloads.”

Image credit: Google.
Indeed, Google’s TPUs have emerged as a threat to Nvidia’s dominance in the AI chip market. Anthropic has licensed Google’s TPU accelerators for use in data centers. Broadcom will modify the TPUs for Anthropic before the customized chips are made by TSMC. Wells Fargo estimates that Google could bring in over $10 billion in high-margin intellectual property (IP) licensing fees from TPUs in 2026 and 2027.
“What stands out about Google is that they’ve been investing up and down the technology stack, from silicon to the AI models,” said Daniel Flax, managing director at investment management firm Neuberger Berman. “While competition is fierce, they’ve been able to innovate. What we’re focused on is (Google’s) ability to execute on their product road map from one generation of AI models to the next.”
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
AI Competition from OpenAI and Anthropic:
Google faces lots of AI competition from other hyperscalers (Amazon, Microsoft, Meta, etc) and especially from two private AI companies:.
- OpenAI remains a major AI player, powered by the rapid advance of ChatGPT, which launched in 2022. In its latest funding round, OpenAI landed $122 billion in capital commitments, which values the company at $852 billion. OpenAI’s GPT-6 is its next-generation AI model, as soon as late 2026. GPT-6 is expected to include new memory features that support the personalization of AI chatbots. It’ll also offer more support for autonomous AI agents that perform tasks over the internet.
- Anthropic’s Claude AI model family has grabbed the spotlight this year. With Claude-based coding and other AI tools, Anthropic shook up the enterprise software market. Anthropic is preparing a next-generation, more powerful AI model called Mythos. Anthropic recently raised $30 billion in a funding round that valued the AI company at $380 billion.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
AI Cloud Competition:
Google’s cloud computing business is one area that should benefit from the company’s AI spending. The unit has excellent momentum. Cloud revenue climbed 47% to over $16 billion in the December quarter, up from 34% growth in the previous quarter. And Google’s cloud computing sales backlog grew 55% to $240 billion from the September quarter. AWS still has the largest cloud market share, with Azure second and Google Cloud third. Google Cloud’s edge is AI and data analytics, especially through Vertex AI, Gemini-related services, and TPU-based infrastructure. The company has developed AI Gemini models targeting specific industries, such as financial services and pharmaceutical companies. With the recent $32 billion purchase of Wiz, Google plans to offer AI-based cybersecurity threat detection tools.
Google Cloud is growing faster than AWS on an AI-driven basis, but it still trails Azure in the most AI-sensitive growth comparisons and remains third in overall cloud share. The broad pattern is: AWS leads in scale, Azure leads in AI momentum and enterprise pull, and Google Cloud is the strongest “AI-first” challenger with faster growth than AWS but a smaller base. Recent comparisons show AWS revenue growth around 18% year over year, while Google Cloud grew about 32%, and Azure’s estimated growth was about 39% in the same period.
Microsoft reported Intelligent Cloud segment growth was also faster than AWS. The rough share split cited in recent coverage is AWS about 30%, Azure about 20%, and Google Cloud about 13%. Azure’s edge is enterprise distribution and the Azure OpenAI ecosystem, while AWS offers the broadest infrastructure catalog and strong AI tooling but is less clearly identified as the AI growth leader. Investor takeaway For investors, Google Cloud looks like the fastest-improving AI cloud franchise relative to its size, but not the biggest one. The real question is whether Google’sAI-led growth can stay above AWS while also narrowing the gap with Azure’s enterprise AI momentum.
Monetization is a Major Issue:
Many analyst say it’s unclear how many consumers will pay for AI. Only about 5% of ChatGPT’s user base is paid. “Consumer AI is becoming a distribution channel and brand builder, while enterprise agents are where the high-margin, sticky revenue is actually getting locked in,” Ben Lorica, editor of the Gradient Flow AI newsletter, told IBD in an interview. “Widespread platform promiscuity across ChatGPT, Gemini and Claude signals low switching costs and thin margins, which is not a great recipe for durable revenue.”
“Cloud, AI revenues have to scale fast enough for people to say, ‘OK, this is actually working,'” said Michael Landsberg, chief executive of Landsberg Bennett Private Wealth Management. “With Google, a lot of things are going very well, but when is it going to translate into money in the pocket? Gemini is doing really well gaining market share from ChatGPT. But there’s no money yet,” Landsberg added. “The big issue around Google search is, ‘Are they going to be able to put advertising in Gemini?'”
“I think most people want free AI because we’ve been trained that free is how we do this computer thing,” said Kimberly Forrest, Bokeh Capital Partners’ chief investment officer. “Facebook, Instagram — it’s all free now. There might be some people willing to spend $20 monthly on AI, but probably not enough to generate the income that these models need to be continually improved.”
Alphabet has historically monetized consumer products through advertising rather than subscriptions. “I think the average consumer doesn’t want to pay for AI, and if they do, they certainly don’t want to pay much for AI,” said Tim Ghriskey, senior portfolio strategist at Ingalls & Snyder.
Author’s Note: I regularly use Gemini for Home on my Google Smart Speaker and a different Gemini on PCs and my Samsung phone. There’s a huge difference in performance with the former making many more mistakes and “AI Hallucinations” than the latter. The reason is the Gemini for Home and regular Gemini run on two totally different AI systems. For reasons neither I or Gemini for Home can explain, the Home version is severely deficient with many wrong answers and hallucinations that you don’t get when you use Gemini on a pc or the Gemini app on a smartphone.
One particularly bothersome Gemini for Home response to a question asked or a complaint is: “These pictures should match” or “Here are your photos” or “check out these pictures” with corresponding pics/photos displayed on the speaker’s screen.
–>THAT HAS ABSOLUTELY NOTHING TO DO WITH ANYTHING yet it happens frequently AFTER the Google speaker promises never to repeat it! Ugggh!!!!
……………………………………………………………………………………………………………………………………….
Google/Alphabet’s Surging CAPEX and ROI:
Alphabet said its 2026 capex will be $175 billion to $185 billion, and management has framed the spending as overwhelmingly AI/infrastructure-related which will support revenue growth in Google Cloud, Gemini, and AI-enhanced Search.
The clearest breakdown disclosed to date is roughly 60% to servers and 40% to data centers and networking equipment. Using the company’s forward guidance ranges:
-
AI Compute Servers: about $105 billion to $111 billion.
-
Data centers and networking equipment: about $70 billion to $74 billion.
That means most of the spend is going into fast-depreciating compute hardware, with the rest funding the physical and network buildout needed to host AI workloads. Google says the investment is meant to expand AI compute, support Google Cloud demand, and scale Gemini and enterprise AI offerings.
The company also pointed to a $240 billion cloud backlog and strong cloud revenue growth as signs that the spending is tied to real demand rather than just speculative buildout. The key issue for investors is whether this capital intensity converts into enough cloud and AI revenue to justify the return profile. Alphabet has not given a specific ROI number for its 2026 AI investments. What it has said, and what analysts infer, is that the return should come from faster cloud growth, higher AI-related search usage, and paid enterprise adoption rather than a near-term accounting yield.
In conclusion, 2026 is an AI scale-up year for Google, but the ROI question is still open.
………………………………………………………………………………………………………………………………………………………..
References:
Google’s AI Reckoning: Can Gemini Turn Dominance Into Dollars?
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
AI infrastructure spending boom: a path towards AGI or speculative bubble?
Expose: AI is more than a bubble; it’s a data center debt bomb
China vs U.S.: Race to Generate Power for AI Data Centers as Electricity Demand Soars
Anthropic’s Project Glasswing aims to reshape IT cybersecurity
IDC Survey of Networking Leaders: Enterprise AI progress stalls despite ambitious goals
Will “AI at the Edge” transform telecom or be yet another telco monetization failure?
Nvidia Survey Reveals How Telcos Plan to Use AI; Quantifying ROI is a Challenge
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
AWS to deploy AI inference chips from Cerebras in its data centers; Anapurna Labs/Amazon in-house AI silicon products
Amazon Web Services (AWS) announced it plans to integrate AI processors from Cerebras Systems [1.] into its data centers, signaling growing confidence in the AI-focused semiconductor startup. Under a new multiyear partnership announced Friday, AWS will deploy Cerebras’s Wafer-Scale Engine (WSE) to accelerate inference workloads—the stage of AI operations where models generate responses to user queries. Financial details of the agreement were not disclosed.
Note 1. Founded in 2015 and headquartered in Sunnyvale, CA, Cerebras claims to have the world’s fastest AI inference and training platform.
The collaboration reflects a significant realignment in compute infrastructure strategies across the AI ecosystem. While initial industry focus centered on model training, the rapid expansion of deployed AI services is driving demand for optimized inference performance. Traditional GPUs, though unmatched for training, can be suboptimal for inference scenarios that require ultra-low latency and high throughput. Cloud and AI platform providers are therefore diversifying their silicon portfolios to better match workload profiles and to scale capacity efficiently.
AWS, the world’s largest cloud infrastructure provider, has traditionally relied on its in-house semiconductor division, Annapurna Labs, for custom chip design. Annapurna’s Trainium processors compete with GPUs from major suppliers such as Nvidia and AMD, offering cost and performance advantages for AI training workloads. The new partnership introduces Cerebras technology into AWS infrastructure, where it will work alongside Trainium to enhance large-scale inference capabilities.
Cerebras, best known for its wafer-scale architecture, markets its WSE processors as a high-speed inference platform capable of executing the decode phase of generative AI processing—where text, images, or other outputs are generated—at up to 25 times the speed of conventional GPU solutions. The company, valued at approximately $23 billion following a $1 billion funding round in February, has attracted backing from Fidelity, Benchmark, Tiger Global, Atreides, and Coatue.

The Cerebras deal underscores a major shift in the market for computing power. Image Credit: rebecca lewington/cerebras syste/Reuters
The AWS collaboration follows Cerebras’s major compute partnership with OpenAI, which reportedly involves deploying up to 750 MW of computing capacity powered by its chips. AWS and Cerebras will position their joint offering as a premium cloud inference solution, targeting enterprise AI developers requiring high-performance and scalable compute.
“The scale of AI demand is shifting from model creation to global deployment,” said Andrew Feldman, CEO of Cerebras. “Working with AWS aligns our technology with the industry’s largest cloud, giving us reach to a broad enterprise and developer base. If you want slow inference, there will be cheaper ways to go,” Feldman said. “But if you want fast tokens, if speed matters to you, if you’re doing coding or agentic work, not only are we the absolute fastest, but we intend to set the bar. We’re in this to win it.”

AWS and Cerebras will support both aggregated and disaggregated configurations. Disaggregated is ideal when you have large, stable workloads. Most customers run a mix of workloads with different prefill/decode ratios, where the traditional aggregated approach is still ideal. The start-up expects most customers will want access to both and the ability to route workloads to whichever configuration serves them best.
The move intensifies competition in the inference silicon segment, where Nvidia faces growing pressure from purpose-built processor architectures such as Cerebras’s WSE and other emerging alternatives. Nvidia, which recently announced a $20 billion licensing deal with Groq and plans to unveil a new inference-optimized platform, remains the dominant supplier but now contends with an accelerating wave of specialization across the AI compute stack.
AWS vice president and Annapurna Labs co-founder Nafea Bshara emphasized the company’s goal of offering flexible performance tiers. “Our job is to push the speed and lower the price,” he said, noting that AWS will continue to offer cost-optimized Trainium-only options alongside high-performance Cerebras-Trainium configurations.
………………………………………………………………………………………………………………………………………………………………………………………………….
Amazon’s Internally Designed AI Silicon:
Amazon has built a fairly broad internal AI-oriented silicon portfolio through Annapurna Labs, primarily for AWS:
-
Inferentia (Inferentia, Inferentia2) – Custom machine learning accelerators designed for high-throughput, low-cost inference at cloud scale. These power many AWS inference instances and are positioned as an alternative to Nvidia GPUs for production model serving.
-
Trainium (Trainium, Trainium2, Trainium3) – AI training accelerators optimized for large-scale model training (including frontier and foundation models), with Trainium2 and Trainium3 as newer generations offering materially higher performance and better $/compute than the first generation. These are central to projects such as the Rainier supercomputer for Anthropic.
-
Graviton (Graviton, Graviton2/3/4) – Arm-based general-purpose CPUs used heavily across EC2, increasingly in AI-adjacent roles (pre/post-processing, orchestration, model-serving microservices) and as part of cost-optimized AI stacks, even though they are not dedicated accelerators.
-
Nitro system – While not an AI accelerator per se, the Nitro family (offload cards and system) is an internally developed data-plane and virtualization offload architecture that underpins EC2 and works in tandem with Graviton, Inferentia, and Trainium to free CPU cycles and improve I/O for AI/ML workloads.
All of these are designed and iterated internally by Annapurna Labs for exclusive use in AWS data centers, then exposed to customers via AWS services rather than as standalone merchant silicon.
Amazon’s Annapurna Labs is an internal chip design group that has become a core strategic asset for AWS, especially for custom data center and AI silicon.
Origins and acquisition:
-
Annapurna Labs is an Israeli chip design startup founded in 2011 by semiconductor veterans of Intel and Broadcom, including Avigdor Willenz and Nafea Bshara.
- “When we talked with market sources and consulted with experts in the fields of data and servers, at that time only Amazon had a holistic vision and the ability to execute on a large scale,” recalls Bshara about the start of the romance with Amazon. “We were prepared to build the technology and at the same time were open to working with startups. From there we began a journey together with many meetings and shared thinking, among others with James Hamilton (Microsoft’s former data-base product architect and to AWS SVP), and from there within six months we found ourselves inside Amazon.”
-
Amazon began working with the company around 2013 and acquired it in 2015 for an estimated $350–$400 million.
-
Before the deal, Annapurna was in stealth, focusing on low‑power networking and server chips to improve data center efficiency.
Role inside Amazon and AWS:
-
Post‑acquisition, Annapurna was folded into AWS as a specialist microelectronics and custom silicon group, designing chips to reduce cost and power per unit of compute.
-
The group underpins several key AWS technologies: the Nitro system for offloading virtualization and I/O, Arm‑based Graviton CPUs for general compute, and Trainium and Inferentia accelerators for AI training and inference.
-
These chips let AWS optimize performance per watt and per dollar versus x86 servers and third‑party accelerators, improving margins and competitive pricing.
Key products and architectures:
-
Nitro: A combination of custom hardware and software that offloads storage, networking, and security functions from the host CPU, increasing tenant isolation and freeing CPU cycles for workloads.
-
Graviton: A family of Arm‑based server CPUs; by 2018 Graviton was widely adopted on AWS and is now used by most AWS customers for general cloud infrastructure workloads due to better price‑performance and energy efficiency.
-
Inferentia and Trainium: Custom accelerators designed by Annapurna for machine learning inference (Inferentia) and training (Trainium), intended to reduce AWS’s dependence on high‑priced Nvidia GPUs for AI workloads.
Strategic importance and AI focus:
-
Annapurna’s work is central to Amazon’s strategy of vertical integration in the cloud: owning the silicon stack as much as the software and services.
-
The group designs chips that power Amazon’s AI infrastructure, including systems used both by internal teams and external customers such as Anthropic, for which AWS is the primary cloud and silicon provider.
-
Amazon and Anthropic are collaborating on “Project Rainier,” a massive supercomputer built around hundreds of thousands of Annapurna‑designed Trainium2 chips, targeting more than five times the compute used to train current frontier models.
Organization, footprint, and industry impact:
-
Annapurna Labs maintains a significant presence in Israel, employing hundreds of engineers focused on advanced AI and networking processors for AWS.
-
It also operates major engineering hubs such as an Austin, Texas lab where advanced semiconductors and AI systems are designed and tested.
-
Analysts often describe the acquisition as one of Amazon’s most successful, arguing that Annapurna’s custom silicon is a “secret sauce” that helps AWS compete with Microsoft, Google, and others on performance, cost, and energy efficiency.
…………………………………………………………………………………………………………………………………………………………..
References:
https://www.cerebras.ai/company
https://www.cerebras.ai/blog/cerebras-is-coming-to-aws
https://www.wsj.com/tech/amazon-announces-inference-chips-deal-with-cerebras-109ecd31
https://en.globes.co.il/en/article-nafea-bshara-the-israeli-behind-amazons-graviton-chip-1001420744
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
Custom AI Chips: Powering the next wave of Intelligent Computing
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Will “AI at the Edge” transform telecom or be yet another telco monetization failure?
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
OpenAI and Broadcom in $10B deal to make custom AI chips
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
2026 Consumer Electronics Show Preview: smartphones, AI in devices/appliances and advanced semiconductor chips
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Google announces Gemini: it’s most powerful AI model, powered by TPU chips
AT&T and AWS to deliver last mile connectivity for AI workloads; AT&T Geo Modeler™ AI simulation tool
AT&T is strategically re-architecting its infrastructure for the AI era through high-capacity network modernization and deep integration with hyperscale cloud providers.
In addition to its almost six year old deal to run its 5G SA core network in Microsoft Azure’s cloud, AT&T announced at MWC 2026 that it’s now woring with Amazon Web Services (AWS) to extend 5G and fiber connectivity from business customers and locations directly into AWS environments, creating secure, resilient and reliable premises‑to‑cloud architectures for AI workloads. The collaboration is designed to reduce network complexity and latency while supporting real‑time analytics, machine learning, and agentic AI use cases.
This collaboration continues a long-standing relationship between AT&T and AWS and follows recent news outlining broader efforts to modernize the nation’s connectivity infrastructure by providing high-capacity fiber to AWS data centers, migrate AT&T workloads to AWS cloud capabilities and explore emerging satellite technologies.
AWS Interconnect – last mile embeds AT&T‑delivered connectivity directly into AWS workflows, designed to enable customers to provision and manage last‑mile connectivity within the AWS environment and lays the foundation for the use of AI agents to monitor and manage the AI experience from the user to the cloud. This streamlined, self‑managed approach helps enterprises reduce network complexity while maintaining control of their extended enterprise network, allowing businesses to move faster as they scale AI.
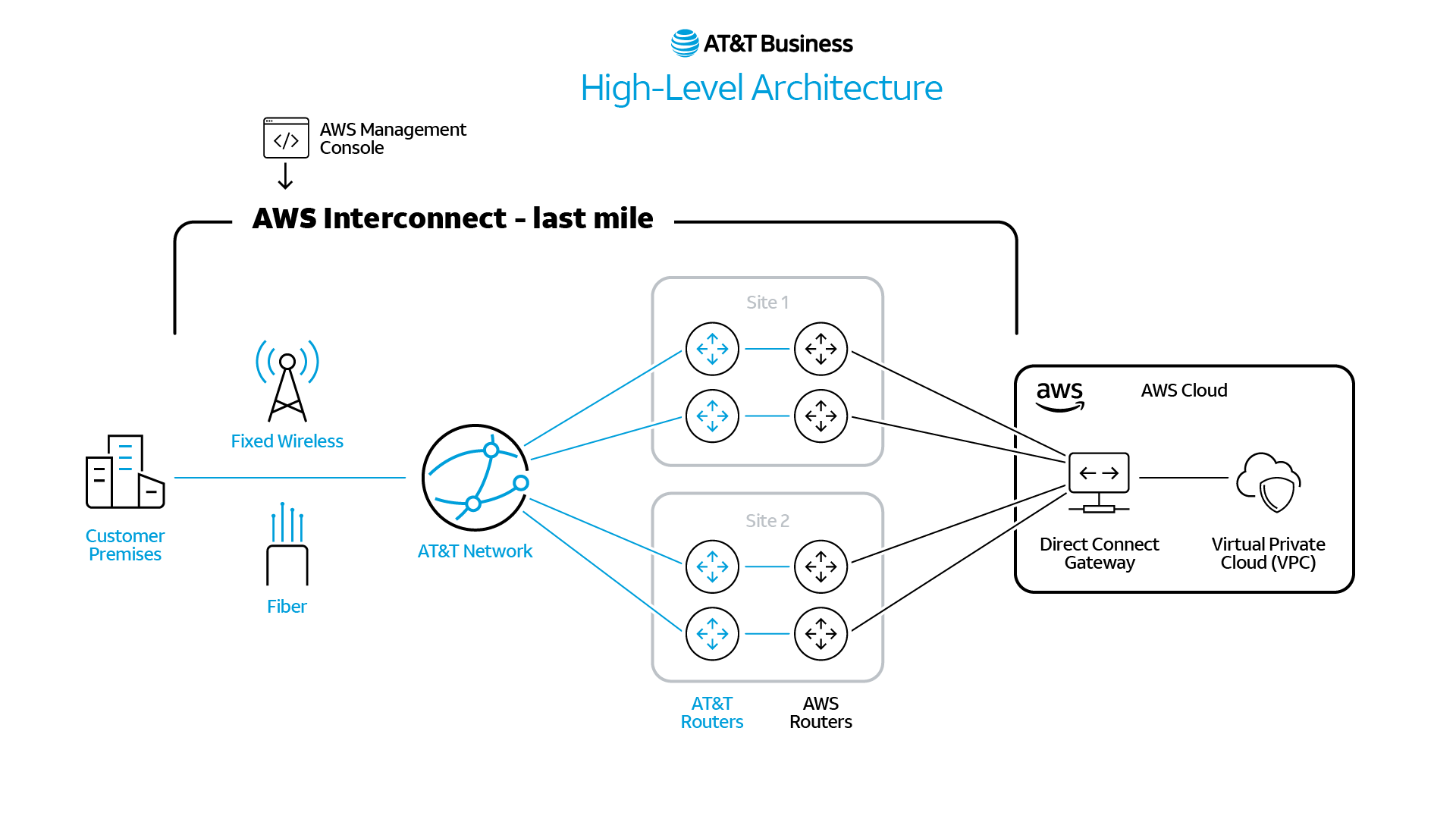
High level illustration of the planned AWS Interconnect – last mile architecture, showing how resilient interconnections and AT&T Fiber and fixed wireless access are intended to simplify private connectivity from customer locations into AWS environments.
Diagram Source: AT&T
………………………………………………………………………………………………………
“AI does not just need more compute; it needs flatter networks and faster connections,” said Shawn Hakl, SVP & Head of Product, AT&T Business. “By bringing high‑capacity connectivity closer to cloud platforms, integrating the management of the networks directly into the cloud provisioning process and engineering for resiliency at the metro level, AT&T is helping enterprises streamline their networks, improve performance, security, and scale AI with confidence.”
AT&T says they are building an AI‑ready network (?) designed to scale performance by continuing ongoing network investment, including the growth of capacities up to 1.6Tbps across key metro and long‑haul routes.
AT&T also announced it would work with Nvidia, Microsoft and MicroAI through its Connected AI platform for “smart manufacturing.”
………………………………………………………………………………………………………………..
Finally, AT&T described AT&T Geo Modeler™ which is able to better predict connectivity for emerging technologies like autonomous vehicles, drones, and robotics.
The Geo Modeler is an AI-powered simulation tool that helps predict, in near real time, how a wireless network will perform in the real world. Inspired by the video games Kounev played with his family growing up, the virtual model and simulation is “essentially like a giant video game of the United States” that, infused with AI tools, gives engineers a clearer picture of where potential weak spots may appear. Then issues can be addressed earlier and fixes can roll out faster. In essence, it creates virtual models, similar to the way video games are designed and developed.
“The Geo Modeler helps us see how the real world will shape coverage before we build, so we can deliver connectivity that’s ready for what’s next,” said AT&T scientist Velin Kounev.
Matt Harden, VP of Connected Solutions at AT&T, agrees. “The Geo Modeler is a foundational capability for the connected mobility era,” he said. “By marrying advanced geospatial simulation with AI-driven network orchestration, we can deliver predictable, high-performance connectivity that adapts with the environment. Whether it’s a hurricane, a packed stadium, or a city corridor full of autonomous vehicles, we will be prepared.”
References:
https://about.att.com/story/2026/aws-collaboration-scalable-business-ai.html
https://about.att.com/blogs/2026/150-years-of-connection.html
https://about.att.com/blogs/2025/geo-modeler.html
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
AT&T deploys nationwide 5G SA while Verizon lags and T-Mobile leads
AT&T to buy spectrum licenses from EchoStar for $23 billion
AT&T’s convergence strategy is working as per its 3Q 2025 earnings report
Progress report: Moving AT&T’s 5G core network to Microsoft Azure Hybrid Cloud platform
AT&T 5G SA Core Network to run on Microsoft Azure cloud platform
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
Intel and AI chip startup SambaNova have entered into a multi-year strategic collaboration to deploy high-performance, cost-efficient AI inference solutions [1.] tailored for AI-native firms, enterprises, and government sectors. This global initiative leverages Intel® Xeon® infrastructure, with Intel Capital further signaling commitment through participation in SambaNova’s $350M Series E financing round. The collaboration will give customers a powerful alternative to GPU‑centric solutions, offering optimized performance for leading open‑source models with predictable throughput and total cost of ownership. Founded in 2017, the Palo Alto, CA company specializes in AI chips and software. SambaNova’s Chairman is Lip-Bu Tan, who is also the CEO of Intel!
Note 1. AI inferencing is the process of using a trained AI model to make real-time predictions, decisions, or generate content from new, previously unseen data. It transforms inputs (a query, image, sensor reading) into useful results (a sentence, classification, alert). Unlike training and language models, inference is about prompt execution, often requiring low-latency (speed) and high efficiency. AI Inference chips have attracted intense investor interest following a wave of deal making around rivals to Nvidia, as AI companies seek faster and more efficient hardware. See References below for more information.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
For high-scale AI workloads, the integration of Intel CPUs with SambaNova’s specialized AI platform was said to offer a high-efficiency rack-level inference alternative. This partnership serves as a strategic bridge as Intel scales its independent GPU-based offerings. Intel remains fully committed to its internal GPU roadmap, continuing aggressive investment across architecture, software, and systems. This collaboration enhances Intel’s edge-to-cloud strategy without altering its competitive trajectory in the GPU market. By combining Xeon processors, Intel networking, and SambaNova systems, the two companies are positioned to capture a significant share of the multi-billion-dollar inference market through heterogeneous data center architectures.
As part of the collaboration, Intel plans to make a strategic investment in SambaNova to accelerate the rollout of an Intel‑powered AI cloud. The collaboration is expected to span three key areas:
- AI Cloud Expansion – Scaling SambaNova’s vertically integrated AI cloud, built on Intel Xeon‑based infrastructure and optimized for large language and multimodal models. The platform will deliver low‑latency, high‑throughput AI services, supported by reference architectures, deployment blueprints, and partnerships with system integrators and software vendors.
- Integrated AI Infrastructure – Combining SambaNova’s systems with Intel’s CPUs, accelerators, and networking technologies to power scalable, production‑ready inference for reasoning, code generation, multimodal applications, and agentic workflows.
- Go‑to‑Market Execution – Joint co‑selling and co‑marketing through Intel’s global enterprise, cloud, and partner channels to accelerate adoption across the AI ecosystem.
Together, SambaNova and Intel aim to shape the next generation of heterogeneous AI data centers — integrating Intel Xeon processors, Intel GPUs, Intel networking and storage, and SambaNova systems — to unlock a multi‑billion‑dollar inference market opportunity.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………
SambaNova also announced its SN50 AI chip, which boasts a max speed that’s 5X faster than competitive chips, according to the company.

Image Credit: SambaNova
Positioned as the most efficient chip for agentic AI, the SN50 chip offers enterprises a 3X lower total cost of ownership – a powerful foundation to scale fast inference and bring autonomous AI agents into full production. The SN50 will be shipping to customers later this year. To quickly scale and distribute SN50, SambaNova is collaborating with Intel, and has obtained $350 million in strategic Series E financing to expand manufacturing and cloud capacity.
“AI is no longer a contest to build the biggest model,” said Rodrigo Liang, co‑founder and CEO of SambaNova. “With the SN50 and our deep collaboration with Intel, the real race is about who can light up entire data centers with AI agents that answer instantly, never stall, and do it at a cost that turns AI from an experiment into the most profitable engine in the cloud.”
“Customers are asking for more choice and more efficient ways to scale AI,” said Kevork Kechichian, EVP, General Manager, Data Center Group, Intel. “By combining Intel’s leadership in compute, networking, and memory with SambaNova’s full-stack AI systems and inference cloud platform, we are delivering a compelling option for organizations looking for GPU alternatives to deploy advanced AI at scale.”
The SN50 delivers five times more compute per accelerator and four times more network bandwidth than the previous generation. It links up to 256 accelerators over a multi‑terabyte‑per‑second interconnect, cutting time‑to‑first‑token and supporting larger batch sizes. The result: Enterprises can deploy bigger, longer‑context AI models with higher throughput and responsiveness — while keeping performance high and costs and latency under control.
“AI is moving from a software story to an infrastructure story,” said Landon Downs, co-founder and managing partner at Cambium Capital. “SN50 is engineered for the real-world latency and economic requirements that will determine who successfully deploys agentic AI at scale.”
Built on SambaNova’s Reconfigurable Data Unit (RDU) architecture, SN50 delivers:
- Instant AI Experiences – Ultra‑low latency delivers real‑time responsiveness for next‑gen enterprise apps like voice assistants.
- Unmatched Scale and Concurrency – Power thousands of simultaneous AI sessions with consistent high performance.
- Breakthrough Model Capacity – Three‑tier memory architecture unlocks 10T+ parameter models and 10M+ context lengths for deeper reasoning and richer outputs.
- Maximum Efficiency at Scale – Higher hardware utilization lowers cost‑per‑token, driving greater performance and ROI.
- Smarter Memory, Smarter Efficiency – Resident multi‑model memory and agentic caching optimize the three‑tier architecture, cutting infrastructure costs for enterprise‑scale AI deployments.
“The new SambaNova SN50 RDU changes the tokenomics of AI inference at scale. By delivering both high performance and high throughput with a chip that uses existing power and is air cooled, SambaNova is changing the game,” said Peter Rutten, Research Vice-President Performance Intensive Computing at analyst firm IDC.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………
SoftBank Corp. will be the first customer to deploy SN50 within its next‑generation AI data centers in Japan. The deployment will power low‑latency inference services for sovereign and enterprise customers across Asia‑Pacific, supporting both open‑source and proprietary frontier models with aggressive latency and throughput requirements.
“With SN50, we are building an AI inference fabric for Japan that can serve our customers and partners with the speed, resiliency and sovereignty they expect from SoftBank,” said Hironobu Tamba, Vice President and Head of the Data Platform Strategy Division of the Technology Unit at SoftBank Corp. “By standardizing on SN50, we gain the ability to deliver world‑class AI services on our own terms — with the performance of the best GPU clusters, but with far better economics and control.”
The SN50 deployment deepens SambaNova’s existing relationship with SoftBank Corp., which already hosts SambaCloud to provide ultra‑fast inference for developers in the region. By anchoring its newest clusters on SN50, SoftBank positions SambaNova as the inference backbone for its sovereign AI initiatives and future large‑scale agentic services.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………
References:
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Groq and Nvidia in non-exclusive AI Inference technology licensing agreement; top Groq execs joining Nvidia
Analysis: Edge AI and Qualcomm’s AI Program for Innovators 2026 – APAC for startups to lead in AI innovation
Custom AI Chips: Powering the next wave of Intelligent Computing
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
OpenAI and Broadcom in $10B deal to make custom AI chips
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
China vs U.S.: Race to Generate Power for AI Data Centers as Electricity Demand Soars
The International Energy Agency (IEA) forecasts that in the next five years, the global demand for power (electricity) is set to grow roughly 50% faster than it did during the previous decade – and more than twice as fast as energy demand overall. That tremendous increase in demand is due to power hungry AI data centers. There’s also electric cars and buses, electric-powered industrial machines, and electric heating of homes.
Global AI growth will be contingent on generating more power for data centers:
- Global data center power demand is now expected to rise to a record 1,596 terawatt-hours by 2035 – +255% increase from 2025 levels.
- The U.S. is set to remain the leader in energy consumption with a +144% surge in demand over this period, to 430 terawatt-hours.
- China’s demand is projected to rise +255%, to 397 terawatt-hours.
- European demand is expected to surge +303%, to 274 terawatt-hours.
- New data centers coming online between now and 2030 will need more than 600 terawatt-hours of electricity. This is enough to power ~60 million homes.


Power for AI Data Centers: China vs U.S.:
China is currently ahead of the United States in generating and building out power infrastructure to support AI data centers, a phenomenon sometimes described by industry observers as an “electron gap.”
China’s rapid, centralized expansion of electricity generation—including both massive renewable projects and traditional, dispatchable power—has created a significant capacity advantage in the race to support AI workloads, which are increasingly limited by energy availability rather than just chip access.
Key factors in China’s power advantage for AI include:
Massive Generation Growth: Between 2010 and 2024, China’s power production increased by more than the rest of the world combined. In 2024 alone, China added 543 gigawatts of power capacity—more than the total capacity added by the U.S. in its entire history.
Significant Surplus Capacity: By 2030, China is projected to have roughly 400 gigawatts of spare power capacity, which is triple the expected power demand of the global data center fleet at that time.
“Eastern Data, Western Computing” Initiative: China is actively shifting energy-intensive data centers to its resource-rich western regions (like Inner Mongolia) while powering them with surplus renewable energy, such as wind and solar.
Lower Costs and Faster Buildouts: Data centers in China can pay less than half the rates for electricity that American data centers do. Furthermore, projects in China can move from planning to operation in months, compared to years in the U.S. due to faster permitting and fewer regulatory hurdles.
Conclusions:
While the U.S. currently leads in advanced AI chips and model development, it is facing a severe “energy bottleneck” for new data centers, with some requiring over a gigawatt of power. U.S. power demand has remained relatively flat for 20 years, resulting in a lag in building new capacity, whereas China has traditionally built power infrastructure in anticipation of high demand. Morgan Stanley has forecast that U.S. data centers could face a 44-gigawatt electricity shortfall in the next three years.
Despite China’s advantage in energy, U.S. export controls on high-end AI chips (such as Nvidia’s GPUs) have acted as a significant constraint on China’s actual AI compute power. This has led to a situation where the U.S. has the best “brains” (chips) but limited power to run them, while China has the “muscle” (energy) but limited access to top-tier AI brains.
However, the rapid improvements in Chinese AI models (such as DeepSeek), which are more energy-efficient and optimized for lower-tier hardware, may help mitigate this constraint.
References:
https://www.iea.org/reports/electricity-2026
https://x.com/KobeissiLetter/status/2023437717888250284
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Analysis: Ethernet gains on InfiniBand in data center connectivity market; White Box/ODM vendors top choice for AI hyperscalers
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
How will fiber and equipment vendors meet the increased demand for fiber optics in 2026 due to AI data center buildouts?
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Nvidia CEO Huang: AI is the largest infrastructure buildout in human history; AI Data Center CAPEX will generate new revenue streams for operators
