

AI data centers
SK Group and AWS to build Korea’s largest AI data center in Ulsan
Amazon Web Services (AWS) is partnering with the SK Group to build South Korea’s largest AI data center. The two companies are expected to launch the project later this month and will hold a groundbreaking ceremony for the 100MW facility in August, according to state news service Yonhap.
Scheduled to begin operations in 2027, the AI Zone will empower organizations in Korea to develop innovative AI applications locally while leveraging world-class AWS services like Amazon SageMaker, Bedrock, and Q. SK Group expects to bolster Korea’s AI competitiveness and establish the region as a key hub for hyperscale infrastructure in Asia-Pacific through AI initiatives.
AWS provides on-demand cloud computing platforms and application programming interfaces (APIs) to individuals, businesses and governments on a pay-per-use basis.The data center will be built on a 36,000-square-meter site in an industrial park in Ulsan, 305 km southeast of Seoul. It will be powered by 60,000 GPUs, making it the country’s first large-scale AI data center.
The facility will be located in the Mipo industrial complex in Ulsan, 305 kilometers southeast of Seoul. It will house 60,000 graphics processing units (GPUs) and have a power capacity of 100 megawatts, making it the country’s first AI infrastructure of such scale, the sources said.
Ryu Young-sang, chief executive officer (CEO) of SK Telecom Co., had announced the company’s plan to build a hyperscale AI data center equipped with 60,000 GPUs in collaboration with a global tech partner, during the Mobile World Congress (MWC) 2025 held in Spain in March.
SK Telecom plans to invest 3.4 trillion won (US$2.49 billion) in AI infrastructure by 2028, with a significant portion expected to be allocated to the data center project. SK Telecom- South Korea’s biggest mobile operator and 31% owned by the SK Group – will manage the project. “They have been working on the project, but the exact timeline and other details have yet to be finalized,” an SK Group spokesperson said.
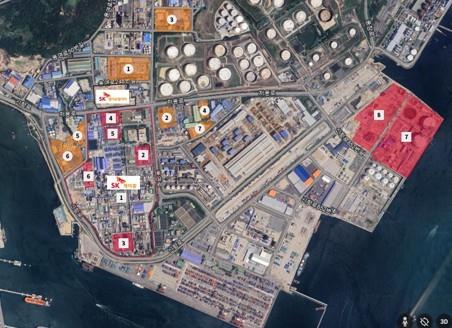
The AI data center will be developed in two phases, with the initial 40MW phase to be completed by November 2027 and the full 100MW capacity to be operational by February 2029, the Korea Herald reported Monday. Once completed, the facility, powered by 60,000 graphics processing units, will have a power capacity of 103 megawatts, making it the country’s largest AI infrastructure, sources said.
SK Group appears to have chosen Ulsan as the site, considering its proximity to SK Gas’ liquefied natural gas combined heat and power plant, ensuring a stable supply of large-scale electricity essential for data center operations. The facility is also capable of utilizing LNG cold energy for data center cooling.
SKT last month released its revised AI pyramid strategy, targeting AI infrastructure including data centers, GPUaaS and customized data centers. It is also developing personal agents A. and Aster for consumers and AIX services for enterprise customers.
Globally, it has found partners through the Global Telecom Alliance, which it co-founded, and is collaborating with US firms Anthropic and Lambda.
SKT’s AI business unit is still small, however, recording just KRW156 billion ($115 million) in revenue in Q1, two-thirds of it from data center infrastructure. Its parent SK Group, which also includes memory chip giant SK Hynix and energy firm SK Innovation, reported $88 billion in revenue last year.
AWS, the world’s largest cloud services provider, has been expanding its footprint in Korea. It currently runs a data center in Seoul and began constructing its second facility in Incheon’s Seo District in late 2023. The company has pledged to invest 7.85 trillion won in Korea’s cloud computing infrastructure by 2027.
“When SK Group’s exceptional technical capabilities combine with AWS’s comprehensive AI cloud services, we’ll empower customers of all sizes, and across all industries here in Korea to build and innovate with safe, secure AI technologies,” said Prasad Kalyanaraman, VP of Infrastructure Services at AWS. “This partnership represents our commitment to Korea’s AI future, and I couldn’t be more excited about what we’ll achieve together.”
Earlier this month AWS launched its Taiwan cloud region – its 15th in Asia-Pacific – with plans to invest $5 billion on local cloud and AI infrastructure.
References:
https://en.yna.co.kr/view/AEN20250616004500320?section=k-biz/corporate
https://www.koreaherald.com/article/10510141
https://www.lightreading.com/data-centers/aws-sk-group-to-build-korea-s-largest-ai-data-center
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
A growing portion of the billions of dollars being spent on AI data centers will go to the suppliers of networking chips, lasers, and switches that integrate thousands of GPUs and conventional micro-processors into a single AI computer cluster. AI can’t advance without advanced networks, says Nvidia’s networking chief Gilad Shainer. “The network is the most important element because it determines the way the data center will behave.”
Networking chips now account for just 5% to 10% of all AI chip spending, said Broadcom CEO Hock Tan. As the size of AI server clusters hits 500,000 or a million processors, Tan expects that networking will become 15% to 20% of a data center’s chip budget. A data center with a million or more processors will cost $100 billion to build.
The firms building the biggest AI clusters are the hyperscalers, led by Alphabet’s Google, Amazon.com, Facebook parent Meta Platforms, and Microsoft. Not far behind are Oracle, xAI, Alibaba Group Holding, and ByteDance. Earlier this month, Bloomberg reported that capex for those four hyperscalers would exceed $200 billion this year, making the year-over-year increase as much as 50%. Goldman Sachs estimates that AI data center spending will rise another 35% to 40% in 2025. Morgan Stanley expects Amazon and Microsoft to lead the pack with $96.4bn and $89.9bn of capex respectively, while Google and Meta will follow at $62.6bn and $52.3bn.
AI compute server architectures began scaling in recent years for two reasons.
1.] High end processor chips from Intel neared the end of speed gains made possible by shrinking a chip’s transistors.
2.] Computer scientists at companies such as Google and OpenAI built AI models that performed amazing feats by finding connections within large volumes of training material.
As the components of these “Large Language Models” (LLMs) grew to millions, billions, and then trillions, they began translating languages, doing college homework, handling customer support, and designing cancer drugs. But training an AI LLM is a huge task, as it calculates across billions of data points, rolls those results into new calculations, then repeats. Even with Nvidia accelerator chips to speed up those calculations, the workload has to be distributed across thousands of Nvidia processors and run for weeks.
To keep up with the distributed computing challenge, AI data centers all have two networks:
- The “front end” network which sends and receives data to/from external users —like the networks of every enterprise data center or cloud-computing center. It’s placed on the network’s outward-facing front end or boundary and typically includes equipment like high end routers, web servers, DNS servers, application servers, load balancers, firewalls, and other devices which connect to the public internet, IP-MPLS VPNs and private lines.
- A “back end” network that connects every AI processor (GPUs and conventional MPUs) and memory chip with every other processor within the AI data center. “It’s just a supercomputer made of many small processors,” says Ram Velaga, Broadcom’s chief of core switching silicon. “All of these processors have to talk to each other as if they are directly connected.” AI’s back-end networks need high bandwidth switches and network connections. Delays and congestion are expensive when each Nvidia compute node costs as much as $400,000. Idle processors waste money. Back-end networks carry huge volumes of data. When thousands of processors are exchanging results, the data crossing one of these networks in a second can equal all of the internet traffic in America.
Nvidia became one of today’s largest vendors of network gear via its acquisition of Israel based Mellanox in 2020 for $6.9 billion. CEO Jensen Huang and his colleagues realized early on that AI workloads would exceed a single box. They started using InfiniBand—a network designed for scientific supercomputers—supplied by Mellanox. InfiniBand became the standard for AI back-end networks.
While most AI dollars still go to Nvidia GPU accelerator chips, back-end networks are important enough that Nvidia has large networking sales. In the September quarter, those network sales grew 20%, to $3.1 billion. However, Ethernet is now challenging InfiniBand’s lock on AI networks. Fortunately for Nvidia, its Mellanox subsidiary also makes high speed Ethernet hardware modules. For example, xAI uses Nvidia Ethernet products in its record-size Colossus system.
While current versions of Ethernet lack InfiniBand’s tools for memory and traffic management, those are now being added in a version called Ultra Ethernet [1.]. Many hyperscalers think Ethernet will outperform InfiniBand, as clusters scale to hundreds of thousands of processors. Another attraction is that Ethernet has many competing suppliers. “All the largest guys—with an exception of Microsoft—have moved over to Ethernet,” says an anonymous network industry executive. “And even Microsoft has said that by summer of next year, they’ll move over to Ethernet, too.”
Note 1. Primary goals and mission of Ultra Ethernet Consortium (UEC): Deliver a complete architecture that optimizes Ethernet for high performance AI and HPC networking, exceeding the performance of today’s specialized technologies. UEC specifically focuses on functionality, performance, TCO, and developer and end-user friendliness, while minimizing changes to only those required and maintaining Ethernet interoperability. Additional goals: Improved bandwidth, latency, tail latency, and scale, matching tomorrow’s workloads and compute architectures. Backwards compatibility to widely-deployed APIs and definition of new APIs that are better optimized to future workloads and compute architectures.

……………………………………………………………………………………………………………………………………………………………………………………………………………………………….
Ethernet back-end networks offer a big opportunity for Arista Networks, which builds switches using Broadcom chips. In the past two years, AI data centers became an important business for Arista. AI provides sales to Arista switch rivals Cisco and Juniper Networks (soon to be a part of Hewlett Packard Enterprise), but those companies aren’t as established among hyperscalers. Analysts expect Arista to get more than $1 billion from AI sales next year and predict that the total market for back-end switches could reach $15 billion in a few years. Three of the five big hyperscale operators are using Arista Ethernet switches in back-end networks, and the other two are testing them. Arista CEO Jayshree Ullal (a former SCU EECS grad student of this author/x-adjunct Professor) says that back-end network sales seem to pull along more orders for front-end gear, too.
The network chips used for AI switching are feats of engineering that rival AI processor chips. Cisco makes its own custom Ethernet switching chips, but some 80% of the chips used in other Ethernet switches comes from Broadcom, with the rest supplied mainly by Marvell. These switch chips now move 51 terabits of data a second; it’s the same amount of data that a person would consume by watching videos for 200 days straight. Next year, switching speeds will double.
The other important parts of a network are connections between computing nodes and cables. As the processor count rises, connections increase at a faster rate. A 25,000-processor cluster needs 75,000 interconnects. A million processors will need 10 million interconnects. More of those connections will be fiber optic, instead of copper or coax. As networks speed up, copper’s reach shrinks. So, expanding clusters have to “scale-out” by linking their racks with optics. “Once you move beyond a few tens of thousand, or 100,000, processors, you cannot connect anything with copper—you have to connect them with optics,” Velaga says.
AI processing chips (GPUs) exchange data at about 10 times the rate of a general-purpose processor chip. Copper has been the preferred conduit because it’s reliable and requires no extra power. At current network speeds, copper works well at lengths of up to five meters. So, hyperscalers have tried to “scale-up” within copper’s reach by packing as many processors as they can within each shelf, and rack of shelves.
Back-end connections now run at 400 gigabits per second, which is equal to a day and half of video viewing. Broadcom’s Velaga says network speeds will rise to 800 gigabits in 2025, and 1.6 terabits in 2026.
Nvidia, Broadcom, and Marvell sell optical interface products, with Marvell enjoying a strong lead in 800-gigabit interconnects. A number of companies supply lasers for optical interconnects, including Coherent, Lumentum Holdings, Applied Optoelectronics, and Chinese vendors Innolight and Eoptolink. They will all battle for the AI data center over the next few years.
A 500,000-processor cluster needs at least 750 megawatts, enough to power 500,000 homes. When AI models scale to a million or more processors, they will require gigawatts of power and have to span more than one physical data center, says Velaga.
The opportunity for optical connections reaches beyond the AI data center. That’s because there isn’t enough power. In September, Marvell, Lumentum, and Coherent demonstrated optical links for data centers as far apart as 300 miles. Nvidia’s next-generation networks will be ready to run a single AI workload across remote locations.
Some worry that AI performance will stop improving as processor counts scale. Nvidia’s Jensen Huang dismissed those concerns on his last conference call, saying that clusters of 100,000 processors or more will just be table stakes with Nvidia’s next generation of chips. Broadcom’s Velaga says he is grateful: “Jensen (Nvidia CEO) has created this massive opportunity for all of us.”
References:
https://www.datacenterdynamics.com/en/news/morgan-stanley-hyperscaler-capex-to-reach-300bn-in-2025/
https://ultraethernet.org/ultra-ethernet-specification-update/
Will AI clusters be interconnected via Infiniband or Ethernet: NVIDIA doesn’t care, but Broadcom sure does!
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Canalys & Gartner: AI investments drive growth in cloud infrastructure spending
AI Echo Chamber: “Upstream AI” companies huge spending fuels profit growth for “Downstream AI” firms
AI wave stimulates big tech spending and strong profits, but for how long?
Markets and Markets: Global AI in Networks market worth $10.9 billion in 2024; projected to reach $46.8 billion by 2029
Using a distributed synchronized fabric for parallel computing workloads- Part I
Using a distributed synchronized fabric for parallel computing workloads- Part II
Lumen Technologies to connect Prometheus Hyperscale’s energy efficient AI data centers
The need for more cloud computing capacity and AI applications has been driving huge investments in data centers. Those investments have led to a steady demand for fiber capacity between data centers and more optical networking innovation inside data centers. Here’s the latest example of that:
Prometheus Hyperscale has chosen Lumen Technologies to connect its energy-efficient data centers to meet growing AI data demands. Lumen network services will help Prometheus with the rapid growth in AI, big data, and cloud computing as they address the critical environmental challenges faced by the AI industry.
Rendering of Prometheus Hyperscale flagship Data Center in Evanston, Wyoming:

……………………………………………………………………………….
Prometheus Hyperscale, known for pioneering sustainability in the hyperscale data center industry, is deploying a Lumen Private Connectivity Fabric℠ solution, including new network routes built with Lumen next generation wavelength services and Dedicated Internet Access (DIA) [1.] services with Distributed Denial of Service (DDoS) protection layered on top.
Note 1. Dedicated Internet Access (DIA) is a premium internet service that provides a business with a private, high-speed connection to the internet.
This expanded network will enable high-density compute in Prometheus facilities to deliver scalable and efficient data center solutions while maintaining their commitment to renewable energy and carbon neutrality. Lumen networking technology will provide the low-latency, high-performance infrastructure critical to meet the demands of AI workloads, from training to inference, across Prometheus’ flagship facility in Wyoming and four future data centers in the western U.S.
“What Prometheus Hyperscale is doing in the data center industry is unique and innovative, and we want to innovate alongside of them,” said Ashley Haynes-Gaspar, Lumen EVP and chief revenue officer. “We’re proud to partner with Prometheus Hyperscale in supporting the next generation of sustainable AI infrastructure. Our Private Connectivity Fabric solution was designed with scalability and security to drive AI innovation while aligning with Prometheus’ ambitious sustainability goals.”
Prometheus, founded as Wyoming Hyperscale in 2020, turned to Lumen networking solutions prior to the launch of its first development site in Aspen, WY. This facility integrates renewable energy sources, sustainable cooling systems, and AI-driven energy optimization, allowing for minimal environmental impact while delivering the computational power AI-driven enterprises demand. The partnership with Lumen reinforces Prometheus’ dedication to both technological innovation and environmental responsibility.
“AI is reshaping industries, but it must be done responsibly,” said Trevor Neilson, president of Prometheus Hyperscale. “By joining forces with Lumen, we’re able to offer our customers best-in-class connectivity to AI workloads while staying true to our mission of building the most sustainable data centers on the planet. Lumen’s network expertise is the perfect complement to our vision.”
Prometheus’ data center campus in Evanston, Wyoming will be one of the biggest data centers in the world with facilities expected to come online in late 2026. Future data centers in Pueblo, Colorado; Fort Morgan, Colorado; Phoenix, Arizona; and Tucson, Arizona, will follow and be strategically designed to leverage clean energy resources and innovative technology.
About Prometheus Hyperscale:
Prometheus Hyperscale, founded by Trenton Thornock, is revolutionizing data center infrastructure by developing sustainable, energy-efficient hyperscale data centers. Leveraging unique, cutting-edge technology and working alongside strategic partners, Prometheus is building next-generation, liquid-cooled hyperscale data centers powered by cleaner energy. With a focus on innovation, scalability, and environmental stewardship, Prometheus Hyperscale is redefining the data center industry for a sustainable future. This announcement follows recent news of Bernard Looney, former CEO of bp, being appointed Chairman of the Board.
To learn more visit: www.prometheushyperscale.com
About Lumen Technologies:
Lumen uses the scale of their network to help companies realize AI’s full potential. From metro connectivity to long-haul data transport to edge cloud, security, managed service, and digital platform capabilities, Lumenn meets its customers’ needs today and is ready for tomorrow’s requirements.
In October, Lumen CTO Dave Ward told Light Reading that a “fundamentally different order of magnitude” of compute power, graphics processing units (GPUs) and bandwidth is required to support AI workloads. “It is the largest expansion of the Internet in our lifetime,” Ward said.
Lumen is constructing 130,000 fiber route miles to support Meta and other customers seeking to interconnect AI-enabled data centers. According to a story by Kelsey Ziser, the fiber conduits in this buildout would contain anywhere from 144 to more than 500 fibers to connect multi-gigawatt data centers.
REFERENCES:
https://www.lightreading.com/data-centers/2024-in-review-data-center-shifts
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
Initiatives and Analysis: Nokia focuses on data centers as its top growth market
Proposed solutions to high energy consumption of Generative AI LLMs: optimized hardware, new algorithms, green data centers
Deutsche Telekom with AWS and VMware demonstrate a global enterprise network for seamless connectivity across geographically distributed data centers
