

Nvidia
Analysis: Ethernet gains on InfiniBand in data center connectivity market; White Box/ODM vendors top choice for AI hyperscalers
Disclaimer: The author used Perplexity.ai for the research in this article.
……………………………………………………………………………………………………………..
Introduction:
Ethernet is now the leader in “scale-out” AI networking. In 2023, InfiniBand held an ~80% share of the data center switch market. A little over two years later, Ethernet has overtaken it in data center switch and server port counts. Indeed, the demand for Ethernet-based interconnect technologies continues to strengthen, reflecting the market’s broader shift toward scalable, open, and cost-efficient data center fabrics. According to Dell’Oro Group research published in July 2025, Ethernet was on track to overtake InfiniBand and establish itself as the primary fabric technology for large-scale data centers. The report projects cumulative data center switch revenue approaching $80 billion over the next five years, driven largely by AI infrastructure investments. Other analysts say Ethernet now represents a majority of AI‑back‑end switch ports, likely well above 50% and trending toward 70–80% as Ultra Ethernet / RoCE‑based fabrics (Remote Direct Memory Access/RDMA over Converged Ethernet) scale.
With Nvidia’s expanding influence across the data center ecosystem (via its Mellanox acquisition), Ethernet-based switching platforms are expected to maintain strong growth momentum through 2026 and the next investment cycle.
The past, present, and future of Ethernet speeds depicted in the Ethernet Alliance’s 2026 Ethernet Roadmap:
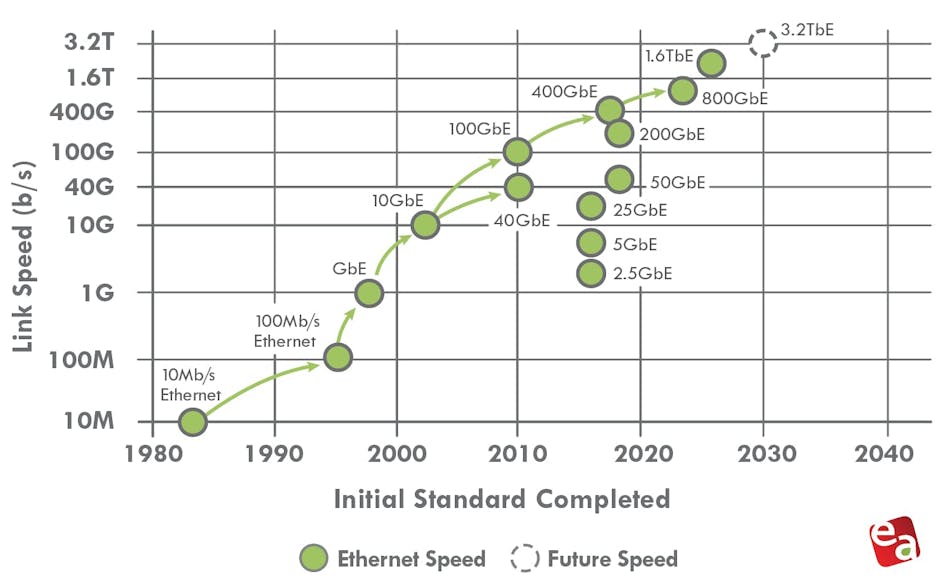
- IEEE 802.3 expects to complete IEEE 802.3dj, which supports 200 Gb/s, 400 Gb/s, 800 Gb/s, and 1.6 Tb/s, by late 2026.
- A 400-Gb/s/lane Signaling Call For Interest (CFI) is already scheduled for March.
- PAM-6 is an emerging, high-order modulation format for short-reach, high-speed optical fiber links (e.g., 100G/400G+ data center interconnects). It encodes 2.585 bits per symbol using 6 distinct amplitude levels, offering a 25% higher bitrate than PAM-4 within the same bandwidth.
………………………………………………………………………………………………………………………………………………………………………………………………………..
Dominant Ethernet speeds and PHY/PMD trends:
In 2026, the Ethernet portfolio spans multiple tiers of performance, with 100G, 200G, 400G, and 800G serving as the dominant server‑ and fabric‑facing speeds, while 1.6T begins to appear in early AI‑scale spine and inter‑cluster links.
-
Server‑to‑leaf topology:
-
100G and 200G remain prevalent for general‑purpose and mid‑tier AI inference workloads, often implemented over 100GBASE‑CR4 / 100GBASE‑FR / 100GBASE‑LR and their 200G counterparts (e.g., 200GBASE‑CR4 / 200GBASE‑FR4 / 200GBASE‑LR4) using 4‑lane PAM4 modulation.
-
Many AI‑optimized racks are migrating to 400G server interfaces, typically using 400GBASE‑CR8 / 400GBASE‑FR8 / 400GBASE‑LR8 with 8‑lane 50 Gb/s PAM4 lanes, often via QSFP‑DD or OSFP form‑factors.
-
-
Leaf‑to‑spine and spine‑to‑spine topology:
-
400G continues as the workhorse for many brownfield and cost‑sensitive fabrics, while 800G is increasingly targeted for new AI and high‑growth pods, typically deployed as 800GBASE‑DR8 / 800GBASE‑FR8 / 800GBASE‑LR8 over 8‑lane 100 Gb/s PAM4 links.
-
IEEE 802.3dj is progressing toward completion in 2026, standardizing 200 Gb/s per lane operation a
-
For cloud‑resident (hyperscale) data centers, the Ethernet‑switch leadership is concentrated among a handful of vendors that supply high‑speed, high‑density leaf‑spine fabrics and AI‑optimized fabrics.
Core Ethernet‑switch leaders:
-
NVIDIA (Spectrum‑X / Spectrum‑4)
NVIDIA has become a dominant force in cloud‑resident Ethernet, largely by bundling its Spectrum‑4 and Spectrum‑X Ethernet switches with H100/H200/Blackwell‑class GPU clusters. Spectrum‑X is specifically tuned for AI workloads, integrating with BlueField DPUs and offering congestion‑aware transport and in‑network collectives, which has helped NVIDIA surpass both Cisco and Arista in data‑center Ethernet revenue in 2025. -
Arista Networks
Arista remains a leading supplier of cloud‑native, high‑speed Ethernet to hyperscalers, with strong positions in 100G–800G leaf‑spine fabrics and its EOS‑based software stack. Arista has overtaken Cisco in high‑speed data‑center‑switch market share and continues to grow via AI‑cluster‑oriented features such as cluster‑load‑balancing and observability suites. -
Cisco Systems
Cisco maintains broad presence in cloud‑scale environments via Nexus 9000 / 7000 platforms and Silicon One‑based designs, particularly where customers want deep integration with routing, security, and multi‑cloud tooling. While its share in pure high‑speed data‑center switching has eroded versus Arista and NVIDIA, Cisco remains a major supplier to many large cloud providers and hybrid‑cloud operators.
Other notable players:
-
HPE (including Aruba and Juniper post‑acquisition)
HPE and its Aruba‑branded switches are widely deployed in cloud‑adjacent and hybrid‑cloud environments, while the HPE‑Juniper combination (via the 2025 acquisition) strengthens its cloud‑native switching and security‑fabric portfolio. -
Huawei
Huawei supplies CloudEngine Ethernet switches into large‑scale cloud and telecom‑owned data centers, especially in regions where its end‑to‑end ecosystem (switching, optics, and management) is preferred. -
White‑box / ODM‑based vendors
Most hyperscalers also source Ethernet switches from ODMs (e.g., Quanta, Celestica, Inspur) running open‑source or custom NOS’ (SONiC, Cumulus‑style stacks), which can collectively represent a large share of cloud‑resident ports even if they are not branded like Cisco or Arista. White‑box / ODM‑based Ethernet switches hold a meaningful and growing share of the data‑center Ethernet market, though they still trail branded vendors in overall revenue. Estimates vary by source and definition. - ODM / white‑box share of the global data‑center Ethernet switch market is commonly estimated in the low‑ to mid‑20% range by revenue in 2024–2025, with some market trackers putting it around 20–25% of the data‑center Ethernet segment. Within hyperscale cloud‑provider data centers specifically, the share of white‑box / ODM‑sourced Ethernet switches is higher, often cited in the 30–40% range by port volume or deployment count, because large cloud operators heavily disaggregate hardware and run open‑source NOSes (e.g., SONiC‑style stacks).
-
ODM‑direct sales into data centers grew over 150% year‑on‑year in 3Q25, according to IDC, signaling that white‑box share is expanding faster than the overall data‑center Ethernet switch market.
-
Separate white‑box‑switch market studies project the global data‑center white‑box Ethernet switch market to reach roughly $3.2–3.5 billion in 2025, growing at a ~12–13% CAGR through 2030, which implies an increasing percentage of the broader Ethernet‑switch pie over time.
Ethernet vendor positioning table:
| Vendor | Key Ethernet positioning in cloud‑resident DCs | Typical speed range (cloud‑scale) |
|---|---|---|
| NVIDIA | AI‑optimized Spectrum‑X fabrics tightly coupled to GPU clusters | 200G/400G/800G, moving toward 1.6T |
| Arista | Cloud‑native, high‑density leaf‑spine with EOS | 100G–800G, strong 400G/800G share |
| Cisco | Broad Nexus/Silicon One portfolio, multi‑cloud integration | 100G–400G, some 800G |
| HPE / Juniper | Cloud‑native switching and security fabrics | 100G–400G, growing 800G |
| Huawei | Cost‑effective high‑throughput CloudEngine switches | 100G–400G, some 800G |
| White‑box ODMs | Disaggregated switches running SONiC‑style NOSes | 100G–400G, increasingly 800G |
Supercomputers and modern HPC clusters increasingly use high‑speed, low‑latency Ethernet as the primary interconnect, often replacing or coexisting with InfiniBand. The “type” of Ethernet used is defined by three layers: speed/lane rate, PHY/PMD/optics, and protocol enhancements tuned for HPC and AI. Slingshot, the proprietary Ethernet-based solution from HPE, commanded 48.1% of performance for the Top500 list in June 2025 and 46.3% in November 2025. On both of the lists, it provided interconnectivity for six of the top 10 – including the top three: El Capitan, Frontier, and Aurora.
HPC Speed and lane‑rate tiers:
-
Mid‑tier HPC / legacy supercomputers:
-
100G Ethernet (e.g., 100GBASE‑CR4/FR4/LR4) remains common for mid‑tier clusters and some scientific workloads, especially where cost and power are constrained.
-
-
AI‑scale and next‑gen HPC:
-
400G and 800G Ethernet (400GBASE‑DR4/FR4/LR4, 800GBASE‑DR8/FR8/LR8) are now the workhorses for GPU‑based supercomputers and large‑scale HPC fabrics.
-
1.6T Ethernet (IEEE 802.3dj, 200 Gb/s per lane) is entering early deployment for spine‑to‑spine and inter‑cluster links in the largest AI‑scale “super‑factories.”
-
In summary, NVIDIA and Arista are the most prominent Ethernet‑switch leaders specifically for AI‑driven, cloud‑resident data centers, with Cisco, HPE/Juniper, Huawei, and white‑box ODMs rounding out the ecosystem depending on region, workload, and procurement model. In hyperscale cloud‑provider data centers, ODMs hold a 30%-to-40% market share.
References:
Will AI clusters be interconnected via Infiniband or Ethernet: NVIDIA doesn’t care, but Broadcom sure does!
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
AI Data Center Boom Carries Huge Default and Demand Risks
Markets and Markets: Global AI in Networks market worth $10.9 billion in 2024; projected to reach $46.8 billion by 2029
Using a distributed synchronized fabric for parallel computing workloads- Part I
Using a distributed synchronized fabric for parallel computing workloads- Part II
China’s open source AI models to capture a larger share of 2026 global AI market
Overview of AI Models – China vs U.S. :
Chinese AI language models (LMs) have advanced rapidly and are now contesting with the U.S. for global market leadership. Alibaba’s Qwen-Image-2512 is emerging as a top-performing, free, open-source model capable of high-fidelity human, landscape, and text rendering. Other key, competitive models include Zhipu AI’s GLM-Image (trained on domestic chips), ByteDance’s Seedream 4.0, and UNIMO-G.
Today, Alibaba-backed Moonshot AI released an upgrade of its flagship AI model, heating up a domestic arms race ahead of an expected rollout by Chinese AI hotshot DeepSeek. The latest iteration of Moonshot’s Kimi can process text, images, and videos simultaneously from a single prompt, the company said in a statement, aligning with a trend toward so-called omni models pioneered by industry leaders like OpenAI and Alphabet Inc.’s Google.
Moonshot AI Kimi website. Photographer: Raul Ariano/Bloomberg
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Chinese AI models are rapidly narrowing the gap with Western counterparts in quality and accessibility. That shift is forcing U.S. AI leaders like Alphabet’s Google, Microsoft’s Copilot, OpenAI, and Anthropic to fight harder to maintain their technological lead in AI. That’s despite their humongous spending on AI data centers, related AI models and infrastructure.
In early 2025, investors seized on DeepSeek’s purportedly lean $5.6 million LM training bill as a sign that Nvidia’s high-end GPUs were already a relic and that U.S. hyperscalers had overspent on AI infrastructure. Instead, the opposite dynamic played out: as models became more capable and more efficient, usage exploded, proving out a classic Jevons’ Paradox and validating the massive data-center build-outs by Microsoft, Amazon, and Google.
The real competitive threat from DeepSeek and its peers is now coming from a different direction. Many Chinese foundation models are released as “open source” or “open weight” AI models which makes them effectively free to download, easy to modify, and cheap to run at scale. By contrast, most leading U.S. players keep tight control over their systems, restricting access to paid APIs and higher-priced subscriptions that protect margins but limit diffusion.
That strategic divergence is visible in how these systems are actually used. U.S. models such as Google’s Gemini, Anthropic’s Claude, and OpenAI’s GPT series still dominate frontier benchmarks [1′] and high‑stakes reasoning tasks. According to a recently published report by OpenRouter, a third-party AI model aggregator, and venture capital firm Andreessen Horowitz. Chinese open-source models have captured roughly 30% of the “working” AI market. They are especially strong in coding support and roleplay-style assistants—where developers and enterprises optimize for cost efficiency, local customization, and deployment freedom rather than raw leaderboard scores.
Note 1. A frontier benchmark for AI models is a high-difficulty evaluation designed to test the absolute limits of artificial intelligence in complex,, often unsolved, reasoning tasks. FrontierMath, for example, is a prominent benchmark focusing on expert-level mathematics, requiring AI to solve hundreds of unpublished problems that challenge, rather than merely measure, current capabilities.
China’s open playbook:
China’s more permissive stance on model weights is not just a pricing strategy — it’s an acceleration strategy. Opening weights turns the broader developer community into an extension of the R&D pipeline, allowing users to inspect internals, pressure‑test safety, and push incremental improvements upstream.
As Kyle Miller at Georgetown’s Center for Security and Emerging Technology argues, China is effectively trading away some proprietary control to gain speed and breadth: by letting capability diffuse across the ecosystem, it can partially offset the difficulty of going head‑to‑head with tightly controlled U.S. champions like OpenAI and Anthropic. That diffusion logic is particularly potent in a system where state planners, big tech platforms, and startups are all incentivized to show visible progress in AI.
Even so, the performance gap has not vanished. Estimates compiled by Epoch AI suggest that Chinese models, on average, trail leading U.S. releases by about seven months. The window briefly narrowed during DeepSeek’s R1 launch in early 2025, when it looked like Chinese labs might have structurally compressed the lag; since then, the gap has widened again as U.S. firms have pushed ahead at the frontier.
Capital, chips, and the power problem:
The reason the U.S. lead has held is massive AI infrastructure spending. Consensus forecasts put capital expenditure by largely American hyperscalers at roughly $400 billion in 2025 and more than $520 billion in 2026, according to Goldman Sachs Research. By comparison, UBS analysts estimate that China’s major internet platforms collectively spent only about $57 billion last year—a fraction of U.S. outlays, even if headline Chinese policy rhetoric around AI is more aggressive.
But sustaining that level of investment runs into a physical constraint that can’t be hand‑waved away: electricity. The newest data-center designs draw more than a gigawatt of power each—about the output of a nuclear reactor—turning grid capacity into a strategic bottleneck. China now generates more than twice as much power as the U.S., and its centralized planning system can more readily steer incremental capacity toward AI clusters than America’s fragmented, heavily regulated electricity market.
That asymmetry is already shaping how some on Wall Street frame the race. Christopher Woods, global head of equity strategy at Jefferies, recently reiterated that China’s combination of open‑source models and abundant cheap power makes it a structurally formidable AI competitor. In his view, the “DeepSeek moment” of early last year remains a warning that markets have largely chosen to ignore as they rotate back into U.S. AI mega‑caps.
A fragile U.S. AI advantage:
For now, U.S. companies still control the most important chokepoint in the stack: advanced AI accelerators. Access to Nvidia’s cutting‑edge GPUs remains a decisive advantage. Yesterday, Microsoft announced the Maia 200 chip – their first silicon and system platform optimized specifically for AI inference. The chip was was designed for efficiency, both in terms of its ability to deliver tokens per dollar and performance per watt of power used.
“Maia 200 can deliver 30% better performance per dollar than the latest generation hardware in our fleet today,” Microsoft EVP for Cloud and AI Scott Guthrie wrote in a blog post.

Image Credit: Microsoft
……………………………………………………………………………………………………………………………………………………………………………………………………………………………….
Leading Chinese AI research labs have struggled to match training results using only domestic designed silicon. DeepSeek, which is developing the successor to its flagship model and is widely expected to release it around Lunar New Year, reportedly experimented with chips from Huawei and other local vendors before concluding that performance was inadequate and turning to Nvidia GPUs for at least part of the training run.
That reliance underscores the limits of China’s current self‑reliance push—but it also shouldn’t be comforting to U.S. strategists. Chinese firms are actively working around the hardware gap, not waiting for it to close. DeepSeek’s latest research focuses on training larger models with fewer chips through more efficient memory design, an incremental but important reminder that architectural innovation can partially offset disadvantages in raw compute.
From a technology‑editorial perspective, the underlying story is not simply “China versus the U.S.” at the model frontier. It is a clash between two AI industrial strategies: an American approach that concentrates capital, compute, and control in a handful of tightly integrated platforms, and a Chinese approach that leans on open weights, diffusion, and state‑backed infrastructure to pull the broader ecosystem forward.
The question for 2026 is whether U.S. AI firms’ lead in capability and chips can keep outrunning China’s advantages in openness and power—or whether the market will again wait for a shock like DeepSeek to re‑price that risk.
Deepseek and Other Chinese AI Models:
DeepSeek published research this month outlining a method of training larger models using fewer chips through a more efficient memory design. “We view DeepSeek’s architecture as a new, promising engineering solution that could enable continued model scaling without a proportional increase in GPU capacity,” wrote UBS analyst Timothy Arcuri.
Export controls haven’t prevented Chinese companies from training advanced models, but challenges emerge when the models are deployed at scale. Zhipu AI, which released its open-weight GLM 4.7 model in December, said this month it was rationing sales of its coding product to 20% of previous capacity after demand from users overwhelmed its servers.
Moonshot, Zhipu AI and MiniMax Group Inc are among a handful of AI LM front-runners in a hotly contested battle among Chinese large language model makers, which at one point was dubbed the “War of One Hundred Models.”
“I don’t see compute constraints limiting [Chinese companies’] ability to make models that are better and compete near the U.S. frontier,” Georgetown’s Miller says. “I would say compute constraints hit on the wider ecosystem level when it comes to deployment.”
Gaining access to Nvidia AI chips:
U.S. President Donald Trump’s plan to allow Nvidia to sell its H200 chips to China could be pivotal. Alibaba Group and ByteDance, TikTok’s parent company, have privately indicated interest in ordering more than 200,000 units each, Bloomberg reported. The H200 outperforms any Chinese-produced AI chip, with a roughly 32% processing-power advantage over Huawei’s Ascend 910C.
With access to Nvidia AI chips, Chinese labs could build AI-training supercomputers as capable as American ones at 50% extra cost compared with U.S.-made ones, according to the Institute for Progress. Subsidies by the Chinese government could cover that differential, leveling the playing field, the institute says.
Conclusions:
A combination of open-source innovation and loosened chip controls could create a cheaper, more capable Chinese AI ecosystem. The possibility is emerging just as OpenAI and Anthropic consider public stock listings (IPOs) and U.S. hyperscalers such as Microsoft and Meta Platforms face pressure to justify heavy spending.
The risk for U.S. AI leaders is no longer theoretical; China’s open‑weight, low‑cost model ecosystem is already eroding the moat that Google, OpenAI, and Anthropic thought they were building. By prioritizing diffusion over tight control, Chinese firms are seeding a broad developer base, compressing iteration cycles, and normalizing expectations that powerful models should be cheap—or effectively free—to adapt and deploy.
U.S. AI leaders could face pressure on pricing and profit margins from China AI competitors while having to deal with AI infrastructure costs and power constraints. Their AI advantage remains real, but fragile—highly exposed to regulatory shifts, export controls, and any breakthrough in China’s workarounds on hardware and training efficiency. The uncomfortable prospect for U.S. AI incumbents is that they could win the race for the best models and still lose ground in the market if China’s diffusion‑driven strategy defines how AI is actually consumed at scale.
…………………………………………………………………………………………………………………………………………………………………………………………………………………..
References:
https://www.barrons.com/articles/deepseek-ai-gemini-chatgpt-stocks-ccde892c
https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/
China gaining on U.S. in AI technology arms race- silicon, models and research
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Goldman Sachs: Big 3 China telecom operators are the biggest beneficiaries of China’s AI boom via DeepSeek models; China Mobile’s ‘AI+NETWORK’ strategy
Bloomberg: China Lures Billionaires Into Race to Catch U.S. in AI
Comparing AI Native mode in 6G (IMT 2030) vs AI Overlay/Add-On status in 5G (IMT 2020)
Custom AI Chips: Powering the next wave of Intelligent Computing
by the Indxx team of market researchers with Alan J Weissberger
The Market for AI Related Semiconductors:
Several market research firms and banks forecast that revenue from AI-related semiconductors will grow at about 18% annually over the next few years—five times faster than non-AI semiconductor market segments.
- IDC forecasts that global AI hardware spending, including chip demand, will grow at an annual rate of 18%.
- Morgan Stanley analysts predict that AI-related semiconductors will grow at an 18% annual rate for a specific company, Taiwan Semiconductor (TSMC).
- Infosys notes that data center semiconductor sales are projected to grow at an 18% CAGR.
- MarketResearch.biz and the IEEE IRDS predict an 18% annual growth rate for AI accelerator chips.
- Citi also forecasts aggregate chip sales for potential AI workloads to grow at a CAGR of 18% through 2030.
AI-focused chips are expected to represent nearly 20% of global semiconductor demand in 2025, contributing approximately $67 billion in revenue [1]. The global AI chip market is projected to reach $40.79 billion in 2025 [2.] and continue expanding rapidly toward $165 billion by 2030.

…………………………………………………………………………………………………………………………………………………
Types of AI Custom Chips:
Artificial intelligence is advancing at a speed that traditional computing hardware can no longer keep pace with. To meet the demands of massive AI models, lower latency, and higher computing efficiency, companies are increasingly turning to custom AI chips which are purpose-built processors optimized for neural networks, training, and inference workloads.
Those AI chips include Application Specific Integrated Circuits (ASICs) and Field- Programmable Gate Arrays (FPGAs) to Neural Processing Units (NPUs) and Google’s Tensor Processing Units (TPUs). They are optimized for core AI tasks like matrix multiplications and convolutions, delivering far higher performance-per-watt than CPUs or GPUs. This efficiency is key as AI workloads grow exponentially with the rise of Large Language Models (LLMs) and generative AI.
OpenAI – Broadcom Deal:
Perhaps the biggest custom AI chip design is being done by an OpenAI partnership with Broadcom in a multi-year, multi-billion dollar deal announced in October 2025. In this arrangement, OpenAI will design the hardware and Broadcom will develop custom chips to integrate AI model knowledge directly into the silicon for efficiency.
Here’s a summary of the partnership:
- OpenAI designs its own AI processors (GPUs) and systems, embedding its AI insights directly into the hardware. Broadcom develops and deploys these custom chips and the surrounding infrastructure, using its Ethernet networking solutions to scale the systems.
- Massive Scale: The agreement covers 10 gigawatts (GW) of AI compute, with deployments expected over four years, potentially extending to 2029.
- Cost Savings: This custom silicon strategy aims to significantly reduce costs compared to off-the-shelf Nvidia or AMD chips, potentially saving 30-40% on large-scale deployments.
- Strategic Goal: The collaboration allows OpenAI to build tailored hardware to meet the intense demands of developing frontier AI models and products, reducing reliance on other chip vendors.
AI Silicon Market Share of Key Players:
- Nvidia, with its extremely popular AI GPUs and CUDA software ecosystem., is expected to maintain its market leadership. It currently holds an estimated 86% share of the AI GPU market segment according to one source [2.]. Others put NVIDIA’s market AI chip market share between 80% and 92%.
- AMD holds a smaller, but growing, AI chip market share, with estimates placing its discrete GPU market share around 4% to 7% in early to mid-2025. AMD is projected to grow its AI chip division significantly, aiming for a double-digit share with products like the MI300X. In response to the extraordinary demand for advanced AI processors, AMD’s Chief Executive Officer, Dr. Lisa Su, presented a strategic initiative to the Board of Directors: to pivot the company’s core operational focus towards artificial intelligence. Ms. Su articulated the view that the “insatiable demand for compute” represented a sustained market trend. AMD’s strategic reorientation has yielded significant financial returns; AMD’s market capitalization has nearly quadrupled, surpassing $350 billion [1]. Furthermore, the company has successfully executed high-profile agreements, securing major contracts to provide cutting-edge silicon solutions to key industry players, including OpenAI and Oracle.
- Intel accounts for approximately 1% of the discrete GPU market share, but is focused on expanding its presence in the AI training accelerator market with its Gaudi 3 platform, where it aims for an 8.7% share by the end of 2025. The former microprocessor king has recently invested heavily in both its design and manufacturing businesses and is courting customers for its advanced data-center processors.
- Qualcomm, which is best known for designing chips for mobile devices and cars, announced in October that it would launch two new AI accelerator chips. The company said the new AI200 and AI250 are distinguished by their very high memory capabilities and energy efficiency.
Big Tech Custom AI chips vs Nvidia AI GPUs:
Big tech companies, including Google, Meta, Amazon, and Apple—are designing their own custom AI silicon to reduce costs, accelerate performance, and scale AI across industries. Yet nearly all rely on TSMC for manufacturing, thanks to its leadership in advanced chip fabrication technology [3.]
- Google recently announced Ironwood, its 7th-generation Tensor Processing Unit (TPU), a major AI chip for LLM training and inference, offering 4x the performance of its predecessor (Trillium) and massive scalability for demanding AI workloads like Gemini, challenging Nvidia’s dominance by efficiently powering complex AI at scale for Google Cloud and major partners like Meta. Ironwood is significantly faster, with claims of over 4x improvement in training and inference compared to the previous Trillium (6th gen) TPU. It allows for super-pods of up to 9,216 interconnected chips, enabling huge computational power for cutting-edge models. It’s optimized for high-volume, low-latency AI inference, handling complex thinking models and real-time chatbots efficiently.
- Meta is in advanced talks to purchase and rent large quantities of Google’s custom AI chips (TPUs), starting with cloud rentals in 2026 and moving to direct purchases for data centers in 2027, a significant move to diversify beyond Nvidia and challenge the AI hardware market. This multi-billion dollar deal could reshape AI infrastructure by giving Meta access to Google’s specialized silicon for workloads like AI model inference, signaling a major shift in big tech’s chip strategy, notes this TechRadar article.
- According to a Wall Street Journal report published on December 2, 2025, Amazon’s new Trainium3 custom AI chip presents a challenge to Nvidia’s market position by providing a more affordable option for AI development. Four times as fast as its previous generation of AI chips, Amazon said Trainium3 (produced by AWS’s Annapurna Labs custom-chip design business) can reduce the cost of training and operating AI models by up to 50% compared with systems that use equivalent graphics processing units, or GPUs. AWS acquired Israeli startup Annapurna Labs in 2015 and began designing chips to power AWS’s data-center servers, including network security chips, central processing units, and later its AI processor series, known as Inferentia and Trainium. “The main advantage at the end of the day is price performance,” said Ron Diamant, an AWS vice president and the chief architect of the Trainium chips. He added that his main goal is giving customers more options for different computing workloads. “I don’t see us trying to replace Nvidia,” Diamant said.
- Interestingly, many of the biggest buyers of Amazon’s chips are also Nvidia customers. Chief among them is Anthropic, which AWS said in late October is using more than one million Trainium2 chips to build and deploy its Claude AI model. Nvidia announced a month later that it was investing $10 billion in Anthropic as part of a massive deal to sell the AI firm computing power generated by its chips.

Image Credit: Emil Lendof/WSJ, iStock
Other AI Silicon Facts and Figures:
- Edge AI chips are forecast to reach $13.5 billion in 2025, driven by IoT and smartphone integration.
- AI accelerators based on ASIC designs are expected to grow by 34% year-over-year in 2025.
- Automotive AI chips are set to surpass $6.3 billion in 2025, thanks to advancements in autonomous driving.
- Google’s TPU v5p reached 30% faster matrix math throughput in benchmark tests.
- U.S.-based AI chip startups raised over $5.1 billion in venture capital in the first half of 2025 alone.
Conclusions:
Custom silicon is now essential for deploying AI in real-world applications such as automation, robotics, healthcare, finance, and mobility. As AI expands across every sector, these purpose-built chips are becoming the true backbone of modern computing—driving a hardware race that is just as important as advances in software. More and more AI firms are seeking to diversify their suppliers by buying chips and other hardware from companies other than Nvidia. Advantages like cost-effectiveness, specialization, lower power consumption and strategic independence that cloud providers gain from developing their own in-house AI silicon. By developing their own chips, hyperscalers can create a vertically integrated AI stack (hardware, software, and cloud services) optimized for their specific internal workloads and cloud platforms. This allows them to tailor performance precisely to their needs, potentially achieving better total cost of ownership (TCO) than general-purpose Nvidia GPUs
However, Nvidia is convinced it will retain a huge lead in selling AI silicon. In a post on X, Nvida wrote that it was “delighted by Google’s success with its TPUs,” before adding that Nvidia “is a generation ahead of the industry—it’s the only platform that runs every AI model and does it everywhere computing is done.” The company said its chips offer “greater performance, versatility, and fungibility” than more narrowly tailored custom chips made by Google and AWS.
The race is far from over, but we can expect to surely see more competition in the AI silicon arena.
………………………………………………………………………………………………………………………………………………………………………………….
Links for Notes:
2. https://sqmagazine.co.uk/ai-chip-statistics/
3. https://www.ibm.com/think/news/custom-chips-ai-future
References:
https://www.wsj.com/tech/ai/amazons-custom-chips-pose-another-threat-to-nvidia-8aa19f5b
https://www.wsj.com/tech/ai/nvidia-ai-chips-competitors-amd-broadcom-google-amazon-6729c65a
AI infrastructure spending boom: a path towards AGI or speculative bubble?
OpenAI and Broadcom in $10B deal to make custom AI chips
Reuters & Bloomberg: OpenAI to design “inference AI” chip with Broadcom and TSMC
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
Expose: AI is more than a bubble; it’s a data center debt bomb
China gaining on U.S. in AI technology arms race- silicon, models and research
Nvidia pays $1 billion for a stake in Nokia to collaborate on AI networking solutions
This is not only astonishing but unheard of: the world’s largest and most popular fabless semiconductor company –Nvidia– taking a $1 billion stake in a telco/reinvented data center connectivity company-Nokia.
Indeed, GPU king Nvidia will pay $1 billion for a stake of 2.9% in Nokia as part of a deal focused on AI and data centers, the Finnish telecom equipment maker said on Tuesday as its shares hit their highest level in nearly a decade on hope for AI to lift their business revenue and profits. The nonexclusive partnership and the investment will make Nvidia the second-largest shareholder in Nokia. Nokia said it will issue 166,389,351 new shares for Nvidia, which the U.S. company will subscribe to at $6.01 per share.
Nokia said the companies will collaborate on artificial intelligence networking solutions and explore opportunities to include its data center communications products in Nvidia’s future AI infrastructure plans. Nokia and its Swedish rival Ericsson both make networking equipment for connectivity inside (intra-) data centers and between (inter-) data centers and have been benefiting from increased AI use.

Summary:
- NVIDIA and Nokia to establish a strategic partnership to enable accelerated development and deployment of next generation AI native mobile networks and AI networking infrastructure.
- NVIDIA introduces NVIDIA Arc Aerial RAN Computer, a 6G-ready telecommunications computing platform.
- Nokia to expand its global access portfolio with new AI-RAN product based on NVIDIA platform.
- T-Mobile U.S. is working with Nokia and NVIDIA to integrate AI-RAN technologies into its 6G development process.
- Collaboration enables new AI services and improved consumer experiences to support explosive growth in mobile AI traffic.
- Dell Technologies provides PowerEdge servers to power new AI-RAN solution.
- Partnership marks turning point for the industry, paving the way to AI-native 6G by taking AI-RAN to innovation and commercialization at a global scale.
In some respects, this new partnership competes with Nvidia’s own data center connectivity solutions from its Mellanox Technologies division, which it acquired for $6.9 billion in 2019. Meanwhile, Nokia now claims to have worked on a redesign to ensure its RAN software is compatible with Nvidia’s compute unified device architecture (CUDA) platform, meaning it can run on Nvidia’s GPUs. Nvidia has also modified its hardware offer, creating capacity cards that will slot directly into Nokia’s existing AirScale baseband units at mobile sites.
Having dethroned Intel several years ago, Nvidia now has a near-monopoly in supplying GPU chips for data centers and has partnered with companies ranging from OpenAI to Microsoft. AMD is a distant second but is gaining ground in the data center GPU space as is ARM Ltd with its RISC CPU cores. Capital expenditure on data center infrastructure is expected to exceed $1.7 trillion by 2030, consulting firm McKinsey, largely because of the expansion of AI.
Nvidia CEO Jensen Huang said the deal would help make the U.S. the center of the next revolution in 6G. “Thank you for helping the United States bring telecommunication technology back to America,” Huang said in a speech in Washington, addressing Nokia CEO Justin Hotard (x-Intel). “The key thing here is it’s American technology delivering the base capability, which is the accelerated computing stack from Nvidia, now purpose-built for mobile,” Hotard told Reuters in an interview. “Jensen and I have been talking for a little bit and I love the pace at which Nvidia moves,” Hotard said. “It’s a pace that I aspire for us to move at Nokia.” He expects the new equipment to start contributing to revenue from 2027 as it goes into commercial deployment, first with 5G, followed by 6G after 2030.
Nvidia has been on a spending spree in recent weeks. The company in September pledged to invest $5 billion in beleaguered chip maker Intel. The investment pairs the world’s most valuable company, which has been a darling of the AI boom, with a chip maker that has almost completely fallen out of the AI conversation.
Later that month, Nvidia said it planned to invest up to $100 billion in OpenAI over an unspecified period that will likely span at least a few years. The partnership includes plans for an enormous data-center build-out and will allow OpenAI to build and deploy at least 10 gigawatts of Nvidia systems.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………
Tech Details:
Nokia uses Marvell Physical Layer (1) baseband chips for many of its products. Among other things, this ensured Nokia had a single software stack for all its virtual and purpose-built RAN products. Pallavi Mahajan, Nokia’s recently joined chief technology and AI officer recently told Light Reading that their software could easily adapt to run on Nvidia’s GPUs: “We built a hardware abstraction layer so that whether you are on Marvell, whether you are on any of the x86 servers or whether you are on GPUs, the abstraction takes away from that complexity, and the software is still the same.”
Fully independent software has been something of a Holy Grail for the entire industry. It would have ramifications for the whole market and its economics. Yet Nokia has conceivably been able to minimize the effort required to put its Layer 1 and specific higher-layer functions on a GPU. “There are going to be pieces of the software that are going to leverage on the accelerated compute,” said Mahajan. “That’s where we will bring in the CUDA integration pieces. But it’s not the entire software,” she added. The appeal of Nvidia as an alternative was largely to be found in “the programmability pieces that you don’t have on any other general merchant silicon,” said Mahajan. “There’s also this entire ecosystem, the CUDA ecosystem, that comes in.” One of Nvidia’s most eye-catching recent moves is the decision to “open source” Aerial, its own CUDA-based RAN software framework, so that other developers can tinker, she says. “What it now enables is the entire ecosystem to go out and contribute.”
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………
Quotes:
“Telecommunications is a critical national infrastructure — the digital nervous system of our economy and security,” said Jensen Huang, founder and CEO of NVIDIA. “Built on NVIDIA CUDA and AI, AI-RAN will revolutionize telecommunications — a generational platform shift that empowers the United States to regain global leadership in this vital infrastructure technology. Together with Nokia and America’s telecom ecosystem, we’re igniting this revolution, equipping operators to build intelligent, adaptive networks that will define the next generation of global connectivity.”
“The next leap in telecom isn’t just from 5G to 6G — it’s a fundamental redesign of the network to deliver AI-powered connectivity, capable of processing intelligence from the data center all the way to the edge. Our partnership with NVIDIA, and their investment in Nokia, will accelerate AI-RAN innovation to put an AI data center into everyone’s pocket,” said Justin Hotard, President and CEO of Nokia. “We’re proud to drive this industry transformation with NVIDIA, Dell Technologies, and T-Mobile U.S., our first AI-RAN deployments in T-Mobile’s network will ensure America leads in the advanced connectivity that AI needs.”
……………………………………………………………………………………………………………………………………………………………………………………
Editor’s Notes:
1. In more advanced 5G networks, Physical Layer functions have demanded the support of custom silicon, or “accelerators.” A technique known as “lookaside,” favored by Ericsson and Samsung, uses an accelerator for only a single problematic Layer 1 task – forward error correction – and keeps everything else on the CPU. Nokia prefers the “inline” approach, which puts the whole of Layer 1 on the accelerator.
2. The huge AI-RAN push that Nvidia started with the formation of the AI-RAN Alliance in early 2024 has not met with an enthusiastic telco response so far. Results from Nokia as well as Ericsson show wireless network operators are spending less on 5G rollouts than they were in the early 2020s. Telco numbers indicate the appetite for smartphone and other mobile data services has not produced any sales growth. As companies prioritize efficiency above all else, baseband units that include Marvell and Nvidia cards may seem too expensive.
……………………………………………………………………………………………………………………………………………………………………………………….
Other Opinions and Quotes:
Nvidia chips are likely to be more expensive, said Mads Rosendal, analyst at Danske Bank Credit Research, but the proposed partnership would be mutually beneficial, given Nvidia’s large share in the U.S. data center market.
“This is a strong endorsement of Nokia’s capabilities,” said PP Foresight analyst Paolo Pescatore. “Next-generation networks, such as 6G, will play a significant role in enabling new AI-powered experiences,” he added.
Iain Morris, International Editor, Light Reading: “Layer 1 control software runs on ARM RISC CPU cores in both Marvell and Nvidia technologies. The bigger differences tend to be in the hardware acceleration “kernels,” or central components, which have some unique demands. Yet Nokia has been working to put as much as it possibly can into a bucket of common software. Regardless, if Nvidia is effectively paying for all this with its $1 billion investment, the risks for Nokia may be small………….Nokia’s customers will in future have an AI-RAN choice that limits or even shrinks the floorspace for Marvell. The development also points to more subtle changes in Nokia’s thinking. The message earlier this year was that Nokia did not require a GPU to implement AI for RAN, whereby machine-generated algorithms help to improve network performance and efficiency. Marvell had that covered because it had incorporated AI and machine-learning technologies into the baseband chips used by Nokia.”
“If you start doing inline, you typically get much more locked into the hardware,” said Per Narvinger, the president of Ericsson’s mobile networks business group, on a recent analyst call. During its own trials with Nvidia, Ericsson said it was effectively able to redeploy virtual RAN software written for Intel’s x86 CPUs on the Grace CPU with minimal changes, leaving the GPU only as a possible option for the FEC accelerator. Putting the entire Layer 1 on a GPU would mean “you probably also get more tightly into that specific implementation,” said Narvinger. “Where does it really benefit from having that kind of parallel compute system?”
………………………………………………………………………………………………………………………………………………….
Separately, Nokia and Nvidia will partner with T-Mobile U.S. to develop and test AI RAN technologies for developing 6G, Nokia said in its press release. Trials are expected to begin in 2026, focused on field validation of performance and efficiency gains for customers.
References:
https://nvidianews.nvidia.com/news/nvidia-nokia-ai-telecommunications
https://www.reuters.com/world/europe/nvidia-make-1-billion-investment-finlands-nokia-2025-10-28/
https://www.lightreading.com/5g/nvidia-takes-1b-stake-in-nokia-which-promises-5g-and-6g-overhaul
https://www.wsj.com/business/telecom/nvidia-takes-1-billion-stake-in-nokia-69f75bb6
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Nvidia’s networking solutions give it an edge over competitive AI chip makers
Telecom sessions at Nvidia’s 2025 AI developers GTC: March 17–21 in San Jose, CA
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
FT: Nvidia invested $1bn in AI start-ups in 2024
The case for and against AI-RAN technology using Nvidia or AMD GPUs
Highlights of Nokia’s Smart Factory in Oulu, Finland for 5G and 6G innovation
Nokia & Deutsche Bahn deploy world’s first 1900 MHz 5G radio network meeting FRMCS requirements
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Indosat Ooredoo Hutchison and Nokia use AI to reduce energy demand and emissions
Verizon partners with Nokia to deploy large private 5G network in the UK
Nvidia’s networking solutions give it an edge over competitive AI chip makers
Nvidia’s networking equipment and module sales accounted for $12.9 billion of its $115.1 billion in data center revenue in its prior fiscal year. Composed of its NVLink, InfiniBand, and Ethernet solutions, Nvidia’s networking products (from its Mellanox acquisition) are what allow its GPU chips to communicate with each other, let servers talk to each other inside massive data centers, and ultimately ensure end users can connect to it all to run AI applications.
“The most important part in building a supercomputer is the infrastructure. The most important part is how you connect those computing engines together to form that larger unit of computing,” explained Gilad Shainer, senior vice president of networking at Nvidia.
In Q1-2025, networking made up $4.9 billion of Nvidia’s $39.1 billion in data center revenue. And it’ll continue to grow as customers continue to build out their AI capacity, whether that’s at research universities or massive data centers.
“It is the most underappreciated part of Nvidia’s business, by orders of magnitude,” Deepwater Asset Management managing partner Gene Munster told Yahoo Finance. “Basically, networking doesn’t get the attention because it’s 11% of revenue. But it’s growing like a rocket ship. “[Nvidia is a] very different business without networking,” Munster explained. “The output that the people who are buying all the Nvidia chips [are] desiring wouldn’t happen if it wasn’t for their networking.”
Nvidia senior vice president of networking Kevin Deierling says the company has to work across three different types of networks:
- NVLink technology connects GPUs to each other within a server or multiple servers inside of a tall, cabinet-like server rack, allowing them to communicate and boost overall performance.
- InfiniBand connects multiple server nodes across data centers to form what is essentially a massive AI computer.
- Ethernet connectivity for front-end network for storage and system management.
Note: Industry groups also have their own competing networking technologies including UALink, which is meant to go head-to-head with NVLink, explained Forrester analyst Alvin Nguyen.
“Those three networks are all required to build a giant AI-scale, or even a moderately sized enterprise-scale, AI computer,” Deierling explained. Low latency is key as longer transit times for data going to/from GPUs slows the entire operation, delaying other processes and impacting the overall efficiency of an entire data center.
Nvidia CEO Jensen Huang presents a Grace Blackwell NVLink72 as he delivers a keynote address at the Consumer Electronics Show (CES) in Las Vegas, Nevada on January 6, 2025. Photo by PATRICK T. FALLON/AFP via Getty Images
As companies continue to develop larger AI models and autonomous and semi-autonomous agentic AI capabilities that can perform tasks for users, making sure those GPUs work in lockstep with each other becomes increasingly important.
The AI industry is in the midst of a broad reordering around the idea of inferencing, which requires more powerful data center systems to run AI models. “I think there’s still a misperception that inferencing is trivial and easy,” Deierling said.
“It turns out that it’s starting to look more and more like training as we get to [an] agentic workflow. So all of these networks are important. Having them together, tightly coupled to the CPU, the GPU, and the DPU [data processing unit], all of that is vitally important to make inferencing a good experience.”
Competitor AI chip makers, like AMD are looking to grab more market share from Nvidia, and cloud giants like Amazon, Google, and Microsoft continue to design and develop their own AI chips. However, none of them have the low latency, high speed connectivity solutions provided by Nvidia (again, think Mellanox).
References:
https://www.nvidia.com/en-us/networking/
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Nvidia enters Data Center Ethernet market with its Spectrum-X networking platform
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
Does AI change the business case for cloud networking?
The case for and against AI-RAN technology using Nvidia or AMD GPUs
Telecom sessions at Nvidia’s 2025 AI developers GTC: March 17–21 in San Jose, CA
Huawei launches CloudMatrix 384 AI System to rival Nvidia’s most advanced AI system
On Saturday, Huawei Technologies displayed an advanced AI computing system in China, as the Chinese technology giant seeks to capture market share in the country’s growing artificial intelligence sector. Huawei’s CloudMatrix 384 system made its first public debut at the World Artificial Intelligence Conference (WAIC), a three-day event in Shanghai where companies showcase their latest AI innovations, drawing a large crowd to the company’s booth.
The Huawei CloudMatrix 384 is a high-density AI computing system featuring 384 Huawei Ascend 910C chips, designed to rival Nvidia’s GB200 NVL72 (more below). The AI system employs a “supernode” architecture with high-speed internal chip interconnects. The system is built with optical links for low-latency, high-bandwidth communication. Huawei has also integrated the CloudMatrix 384 into its cloud platform. The system has drawn close attention from the global AI community since Huawei first announced it in April.
The CloudMatrix 384 resides on the super-node Ascend platform and uses high-speed bus interconnection capability, resulting in low latency linkage between 384 Ascend NPUs. Huawei says that “compared to traditional AI clusters that often stack servers, storage, network technology, and other resources, Huawei CloudMatrix has a super-organized setup. As a result, it also reduces the chance of facing failures at times of large-scale training.

Huawei staff at its WAIC booth declined to comment when asked to introduce the CloudMatrix 384 system. A spokesperson for Huawei did not respond to questions. However, Huawei says that “early reports revealed that the CloudMatrix 384 can offer 300 PFLOPs of dense BF16 computing. That’s double of Nvidia GB200 NVL72 AI tech system. It also excels in terms of memory capacity (3.6x) and bandwidth (2.1x).” Indeed, industry analysts view the CloudMatrix 384 as a direct competitor to Nvidia’s GB200 NVL72, the U.S. GPU chipmaker’s most advanced system-level product currently available in the market.
One industry expert has said the CloudMatrix 384 system rivals Nvidia’s most advanced offerings. Dylan Patel, founder of semiconductor research group SemiAnalysis, said in an April article that Huawei now had AI system capabilities that could beat Nvidia’s AI system. The CloudMatrix 384 incorporates 384 of Huawei’s latest 910C chips and outperforms Nvidia’s GB200 NVL72 on some metrics, which uses 72 B200 chips, according to SemiAnalysis. The performance stems from Huawei’s system design capabilities, which compensate for weaker individual chip performance through the use of more chips and system-level innovations, SemiAnalysis said.
Huawei has become widely regarded as China’s most promising domestic supplier of chips essential for AI development, even though the company faces U.S. export restrictions. Nvidia CEO Jensen Huang told Bloomberg in May that Huawei had been “moving quite fast” and named the CloudMatrix as an example.
Huawei says the system uses “supernode” architecture that allows the chips to interconnect at super-high speeds and in June, Huawei Cloud CEO Zhang Pingan said the CloudMatrix 384 system was operational on Huawei’s cloud platform.
According to Huawei, the Ascend AI chip-based CloudMatrix 384 with three important benefits:
- Ultra-large bandwidth
- Ultra-Low Latency
- Ultra-Strong Performance
These three perks can help enterprises achieve better AI training as well as stable reasoning performance for models. They could further retain long-term reliability.
References:
https://www.huaweicentral.com/huawei-launches-cloudmatrix-384-ai-chip-cluster-against-nvidia-nvl72/
https://semianalysis.com/2025/04/16/huawei-ai-cloudmatrix-384-chinas-answer-to-nvidia-gb200-nvl72/
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Huawei’s “FOUR NEW strategy” for carriers to be successful in AI era
FT: Nvidia invested $1bn in AI start-ups in 2024
Big Tech and VCs invest hundreds of billions in AI while salaries of AI experts reach the stratosphere
Introduction:
Two and a half years after OpenAI set off the generative artificial intelligence (AI) race with the release of the ChatGPT, big tech companies are accelerating their A.I. spending, pumping hundreds of billions of dollars into their frantic effort to create systems that can mimic or even exceed the abilities of the human brain. The areas of super huge AI spending are data centers, salaries for experts, and VC investments. Meanwhile, the UAE is building one of the world’s largest AI data centers while Softbank CEO Masayoshi Son believes that Artificial General Intelligence (AGI) will surpass human-level cognitive abilities (Artificial General Intelligence or AGI) within a few years. And that Artificial Super Intelligence (ASI) will surpass human intelligence by a factor of 10,000 within the next 10 years.
AI Data Center Build-out Boom:
Tech industry’s giants are building AI data centers that can cost more than $100 billion and will consume more electricity than a million American homes. Meta, Microsoft, Amazon and Google have told investors that they expect to spend a combined $320 billion on infrastructure costs this year. Much of that will go toward building new data centers — more than twice what they spent two years ago.
As OpenAI and its partners build a roughly $60 billion data center complex for A.I. in Texas and another in the Middle East, Meta is erecting a facility in Louisiana that will be twice as large. Amazon is going even bigger with a new campus in Indiana. Amazon’s partner, the A.I. start-up Anthropic, says it could eventually use all 30 of the data centers on this 1,200-acre campus to train a single A.I system. Even if Anthropic’s progress stops, Amazon says that it will use those 30 data centers to deliver A.I. services to customers.

Amazon is building a data center complex in New Carlisle, Ind., for its work with the A.I. company Anthropic. Photo Credit…AJ Mast for The New York Times
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Stargate UAE:
OpenAI is partnering with United Arab Emirates firm G42 and others to build a huge artificial-intelligence data center in Abu Dhabi, UAE. The project, called Stargate UAE, is part of a broader push by the U.A.E. to become one of the world’s biggest funders of AI companies and infrastructure—and a hub for AI jobs. The Stargate project is led by G42, an AI firm controlled by Sheikh Tahnoon bin Zayed al Nahyan, the U.A.E. national-security adviser and brother of the president. As part of the deal, an enhanced version of ChatGPT would be available for free nationwide, OpenAI said.
The first 200-megawatt chunk of the data center is due to be completed by the end of 2026, while the remainder of the project hasn’t been finalized. The buildings’ construction will be funded by G42, and the data center will be operated by OpenAI and tech company Oracle, G42 said. Other partners include global tech investor, AI/GPU chip maker Nvidia and network-equipment company Cisco.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Softbank and ASI:
Not wanting to be left behind, SoftBank, led by CEO Masayoshi Son, has made massive investments in AI and has a bold vision for the future of AI development. Son has expressed a strong belief that Artificial Super Intelligence (ASI), surpassing human intelligence by a factor of 10,000, will emerge within the next 10 years. For example, Softbank has:
- Significant investments in OpenAI, with planned investments reaching approximately $33.2 billion. Son considers OpenAI a key partner in realizing their ASI vision.
- Acquired Ampere Computing (chip designer) for $6.5 billion to strengthen their AI computing capabilities.
- Invested in the Stargate Project alongside OpenAI, Oracle, and MGX. Stargate aims to build large AI-focused data centers in the U.S., with a planned investment of up to $500 billion.
Son predicts that AI will surpass human-level cognitive abilities (Artificial General Intelligence or AGI) within a few years. He then anticipates a much more advanced form of AI, ASI, to be 10,000 times smarter than humans within a decade. He believes this progress is driven by advancements in models like OpenAI’s o1, which can “think” for longer before responding.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Super High Salaries for AI Researchers:
Salaries for A.I. experts are going through the roof and reaching the stratosphere. OpenAI, Google DeepMind, Anthropic, Meta, and NVIDIA are paying over $300,000 in base salary, plus bonuses and stock options. Other companies like Netflix, Amazon, and Tesla are also heavily invested in AI and offer competitive compensation packages.
Meta has been offering compensation packages worth as much as $100 million per person. The owner of Facebook made more than 45 offers to researchers at OpenAI alone, according to a person familiar with these approaches. Meta’s CTO Andrew Bosworth implied that only a few people for very senior leadership roles may have been offered that kind of money, but clarified “the actual terms of the offer” wasn’t a “sign-on bonus. It’s all these different things.” Tech companies typically offer the biggest chunks of their pay to senior leaders in restricted stock unit (RSU) grants, dependent on either tenure or performance metrics. A four-year total pay package worth about $100 million for a very senior leader is not inconceivable for Meta. Most of Meta’s named officers, including Bosworth, have earned total compensation of between $20 million and nearly $24 million per year for years.
Meta CEO Mark Zuckerberg on Monday announced its new artificial intelligence organization, Meta Superintelligence Labs, to its employees, according to an internal post reviewed by The Information. The organization includes Meta’s existing AI teams, including its Fundamental AI Research lab, as well as “a new lab focused on developing the next generation of our models,” Zuckerberg said in the post. Scale AI CEO Alexandr Wang has joined Meta as its Chief AI Officer and will partner with former GitHub CEO Nat Friedman to lead the organization. Friedman will lead Meta’s work on AI products and applied research.
“I’m excited about the progress we have planned for Llama 4.1 and 4.2,” Zuckerberg said in the post. “In parallel, we’re going to start research on our next generation models to get to the frontier in the next year or so,” he added.
On Thursday, researcher Lucas Beyer confirmed he was leaving OpenAI to join Meta along with the two others who led OpenAI’s Zurich office. He tweeted: “1) yes, we will be joining Meta. 2) no, we did not get 100M sign-on, that’s fake news.” (Beyer politely declined to comment further on his new role to TechCrunch.) Beyer’s expertise is in computer vision AI. That aligns with what Meta is pursuing: entertainment AI, rather than productivity AI, Bosworth reportedly said in that meeting. Meta already has a stake in the ground in that area with its Quest VR headsets and its Ray-Ban and Oakley AI glasses.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
VC investments in AI are off the charts:
Venture capitalists are strongly increasing their AI spending. U.S. investment in A.I. companies rose to $65 billion in the first quarter, up 33% from the previous quarter and up 550% from the quarter before ChatGPT came out in 2022, according to data from PitchBook, which tracks the industry.
This astounding VC spending, critics argue, comes with a huge risk. A.I. is arguably more expensive than anything the tech industry has tried to build, and there is no guarantee it will live up to its potential. But the bigger risk, many executives believe, is not spending enough to keep pace with rivals.
“The thinking from the big C.E.O.s is that they can’t afford to be wrong by doing too little, but they can afford to be wrong by doing too much,” said Jordan Jacobs, a partner with the venture capital firm Radical Ventures. “Everyone is deeply afraid of being left behind,” said Chris V. Nicholson, an investor with the venture capital firm Page One Ventures who focuses on A.I. technologies.
Indeed, a significant driver of investment has been a fear of missing out on the next big thing, leading to VCs pouring billions into AI startups at “nosebleed valuations” without clear business models or immediate paths to profitability.
Conclusions:
Big tech companies and VCs acknowledge that they may be overestimating A.I.’s potential. Developing and implementing AI systems, especially large language models (LLMs), is incredibly expensive due to hardware (GPUs), software, and expertise requirements. One of the chief concerns is that revenue for many AI companies isn’t matching the pace of investment. Even major players like OpenAI reportedly face significant cash burn problems. But even if the technology falls short, many executives and investors believe, the investments they’re making now will be worth it.
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
References:
https://www.nytimes.com/2025/06/27/technology/ai-spending-openai-amazon-meta.html
Meta is offering multimillion-dollar pay for AI researchers, but not $100M ‘signing bonuses’
https://www.theinformation.com/briefings/meta-announces-new-superintelligence-lab
OpenAI partners with G42 to build giant data center for Stargate UAE project
AI adoption to accelerate growth in the $215 billion Data Center market
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
Proposed solutions to high energy consumption of Generative AI LLMs: optimized hardware, new algorithms, green data centers
OpenAI partners with G42 to build giant data center for Stargate UAE project
OpenAI, the maker of ChatGPT, said it was partnering with United Arab Emirates firm G42 and others to build a huge artificial-intelligence data center in Abu Dhabi, UAE. It will be the company’s first large-scale project outside the U.S. OpenAI and G42 said Thursday the data center would have a capacity of 1 gigawatt (1 GW) [1], putting it among the most powerful in the world. OpenAI and G42 didn’t disclose a cost for the huge data center, although similar projects planned in the U.S. run well over $10 billion.
………………………………………………………………………………………………………………………………………………………………………..
Note 1. 1 GW of continuous power is enough to run roughly one million top‑end Nvidia GPUs once cooling and power‑conversion overheads are included. That’s roughly the annual electricity used by a city the size of San Francisco or Washington.
“Think of 1MW as the backbone for a mid‑sized national‑language model serving an entire country,” Mohammed Soliman, director of the strategic technologies and cybersecurity programme at the Washington-based Middle East Institute think tank, told The National.
………………………………………………………………………………………………………………………………………………………………………..
The project, called Stargate UAE, is part of a broader push by the U.A.E. to become one of the world’s biggest funders of AI companies and infrastructure—and a hub for AI jobs. The Stargate project is led by G42, an AI firm controlled by Sheikh Tahnoon bin Zayed al Nahyan, the U.A.E. national-security adviser and brother of the president. As part of the deal, an enhanced version of ChatGPT would be available for free nationwide, OpenAI said.
The first 200-megawatt chunk of the data center is due to be completed by the end of 2026, while the remainder of the project hasn’t been finalized. The buildings’ construction will be funded by G42, and the data center will be operated by OpenAI and tech company Oracle, G42 said. Other partners include global tech investor, AI/GPU chip maker Nvidia and network-equipment company Cisco.
Data centers are grouped into three sizes: small, measuring up to about 1,000 square feet (93 square metres), medium, around 10,000 sqft to 50,000 sqft, and large, which are more than 50,000 sqft, according to Data Centre World. On a monthly basis, they are estimated to consume as much as 36,000kWh, 2,000MW and 10MW, respectively.

UAE has at least 17 data centers, according to data compiled by industry tracker DataCentres.com. AFP
The data-center project is the fruit of months of negotiations between the Gulf petrostate and the Trump administration that culminated in a deal last week to allow the U.A.E. to import up to 500,000 AI chips a year, people familiar with the deal have said.
That accord overturned Biden administration restrictions that limited access to cutting-edge AI chips to only the closest of U.S. allies, given concerns that the technology could fall into the hands of adversaries, particularly China.
To convince the Trump administration it was a reliable partner, the U.A.E. embarked on a multipronged charm offensive. Officials from the country publicly committed to investing more than $1.4 trillion in the U.S., used $2 billion of cryptocurrency from Trump’s World Liberty Financial to invest in a crypto company, and hosted the CEOs of the top U.S. tech companies for chats in a royal palace in Abu Dhabi.
As part of the U.S.-U.A.E agreement, the Gulf state “will fund the build-out of AI infrastructure in the U.S. at least as large and powerful as that in the UAE,” David Sacks, the Trump administration’s AI czar, said earlier this week on social media.
U.A.E. fund MGX is already an investor in Stargate, the planned $100 billion network of U.S. data centers being pushed by OpenAI and SoftBank.
Similar accords with other U.S. tech companies are expected in the future, as U.A.E. leaders seek to find other tenants for their planned 5-gigawatt data-center cluster. The project was revealed last week during Trump’s visit to the region, where local leaders showed the U.S. president a large model of the project.
The U.A.E. is betting U.S. tech giants will want servers running near users in Africa and India, slightly shaving off the time it takes to transmit data there.
Stargate U.A.E. comes amid a busy week for OpenAI. On Wednesday, a developer said it secured $11.6 billion in funding to push ahead with an expansion of a data center planned for OpenAI in Texas. OpenAI also announced it was purchasing former Apple designer Jony Ive’s startup for $6.5 billion.
References:
https://www.wsj.com/tech/open-ai-abu-dhabi-data-center-1c3e384d?mod=ai_lead_pos6
https://www.thenationalnews.com/future/technology/2025/05/24/stargate-uae-ai-g42/
Wedbush: Middle East (Saudi Arabia and UAE) to be next center of AI infrastructure boom
Cisco to join Stargate UAE consortium as a preferred tech partner
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
Damage of U.S. Export Controls and Trade War with China:
The U.S. big tech sector, especially needs to know what the rules of the trade game will be looking ahead instead of the on-again/off-again Trump tariffs and trade war with China which includes 145% tariffs and export controls on AI chips from Nvidia, AMD, and other U.S. semiconductor companies.
The latest export restriction on Nvidia’s H20 AI chips are a case in point. Nvidia said it would record a $5.5 billion charge on its quarterly earnings after it disclosed that the U.S. will now require a license for exporting the company’s H20 processors to China and other countries. The U.S. government told the chip maker on April 14th that the new license requirement would be in place “indefinitely.”
Nvidia designed the H20 chip to comply with existing U.S. export controls that limit sales of advanced AI processors to Chinese customers. That meant the chip’s capabilities were significantly degraded; Morgan Stanley analyst Joe Moore estimates the H20’s performance is about 75% below that of Nvidia’s H100 family. The Commerce Department said it was issuing new export-licensing requirements covering H20 chips and AMD’s MI308 AI processors.
Big Chinese cloud companies like Tencent, ByteDance (TikTok’s parent), Alibaba, Baidu, and iFlytek have been left scrambling for domestic alternatives to the H20, the primary AI chip that Nvidia had until recently been allowed to sell freely into the Chinese market. Some analysts suggest that H20 bulk orders to build a stockpile were a response to concerns about future U.S. export restrictions and a race to secure limited supplies of Nvidia chips. The estimate is that there’s a 90 days supply of H20 chips, but it’s uncertain what China big tech companies will use when that runs out.
The inability to sell even a low-performance chip into the Chinese market shows how the trade war will hurt Nvidia’s business. The AI chip king is now caught between the world’s two superpowers as they jockey to take the lead in AI development.
Nvidia CEO Jensen Huang “flew to China to do damage control and make sure China/Xi knows Nvidia wants/needs China to maintain its global ironclad grip on the AI Revolution,” the analysts note. The markets and tech world are tired of “deal progress” talks from the White House and want deals starting to be inked so they can plan their future strategy. The analysts think this is a critical week ahead to get some trade deals on the board, because Wall Street has stopped caring about words and comments around “deal progress.”

- Baidu is developing its own AI chips called Kunlun. It recently placed an order for 1,600 of Huawei’s Ascend 910B AI chips for 200 servers. This order was made in anticipation of further U.S. export restrictions on AI chips.
- Alibaba (T-Head) has developed AI chips like the Hanguang 800 inference chip, used to accelerate its e-commerce platform and other services.
- Cambricon Technologies: Designs various types of semiconductors, including those for training AI models and running AI applications on devices.
- Biren Technology: Designs general-purpose GPUs and software development platforms for AI training and inference, with products like the BR100 series.
- Moore Threads: Develops GPUs designed for training large AI models, with data center products like the MTT KUAE.
- Horizon Robotics: Focuses on AI chips for smart driving, including the Sunrise and Journey series, collaborating with automotive companies.
- Enflame Technology: Designs chips for data centers, specializing in AI training and inference.
“With Nvidia’s H20 and other advanced GPUs restricted, domestic alternatives like Huawei’s Ascend series are gaining traction,” said Doug O’Laughlin, an industry analyst at independent semiconductor research company SemiAnalysis. “While there are still gaps in software maturity and overall ecosystem readiness, hardware performance is closing in fast,” O’Laughlin added. According to the SemiAnalysis report, Huawei’s Ascend chip shows how China’s export controls have failed to stop firms like Huawei from accessing critical foreign tools and sub-components needed for advanced GPUs. “While Huawei’s Ascend chip can be fabricated at SMIC, this is a global chip that has HBM from Korea, primary wafer production from TSMC, and is fabricated by 10s of billions of wafer fabrication equipment from the US, Netherlands, and Japan,” the report stated.
Huawei’s New AI Chip May Dominate in China:
Huawei Technologies plans to begin mass shipments of its advanced 910C artificial intelligence chip to Chinese customers as early as next month, according to Reuters. Some shipments have already been made, people familiar with the matter said. Huawei’s 910C, a graphics processing unit (GPU), represents an architectural evolution rather than a technological breakthrough, according to one of the two people and a third source familiar with its design. It achieves performance comparable to Nvidia’s H100 chip by combining two 910B processors into a single package through advanced integration techniques, they said. That means it has double the computing power and memory capacity of the 910B and it also has incremental improvements, including enhanced support for diverse AI workload data.
Conclusions:
The U.S. Commerce Department’s latest export curbs on Nvidia’s H20 “will mean that Huawei’s Ascend 910C GPU will now become the hardware of choice for (Chinese) AI model developers and for deploying inference capacity,” said Paul Triolo, a partner at consulting firm Albright Stonebridge Group.
The markets, tech world and the global economy urgently need U.S. – China trade negotiations in some form to start as soon as possible, Wedbush analysts say in a research note today. The analysts expect minimal or no guidance from tech companies during this earnings season as they are “playing darts blindfolded.”
References:
https://qz.com/china-six-tigers-ai-startup-zhipu-moonshot-minimax-01ai-1851768509#
https://www.huaweicloud.com/intl/en-us/
Goldman Sachs: Big 3 China telecom operators are the biggest beneficiaries of China’s AI boom via DeepSeek models; China Mobile’s ‘AI+NETWORK’ strategy
Telecom sessions at Nvidia’s 2025 AI developers GTC: March 17–21 in San Jose, CA
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
FT: Nvidia invested $1bn in AI start-ups in 2024
Omdia: Huawei increases global RAN market share due to China hegemony
Huawei’s “FOUR NEW strategy” for carriers to be successful in AI era
Telecom sessions at Nvidia’s 2025 AI developers GTC: March 17–21 in San Jose, CA
Nvidia’s annual AI developers conference (GTC) used to be a relatively modest affair, drawing about 9,000 people in its last year before the Covid outbreak. But the event now unofficially dubbed “AI Woodstock” is expected to bring more than 25,000 in-person attendees!
Nvidia’s Blackwell AI chips, the main showcase of last year’s GTC (GPU Technology Conference), have only recently started shipping in high volume following delays related to the mass production of their complicated design. Blackwell is expected to be the main anchor of Nvidia’s AI business through next year. Analysts expect Nvidia Chief Executive Jensen Huang to showcase a revved-up version of that family called Blackwell Ultra at his keynote address on Tuesday.
March 18th Update: The next Blackwell Ultra NVL72 chips, which have one-and-a-half times more memory and two times more bandwidth, will be used to accelerate building AI agents, physical AI, and reasoning models, Huang said. Blackwell Ultra will be available in the second half of this year. The Rubin AI chip, is expected to launch in late 2026. Rubin Ultra will take the stage in 2027.
Nvidia watchers are especially eager to hear more about the next generation of AI chips called Rubin, which Nvidia has only teased at in prior events. Ross Seymore of Deutsche Bank expects the Rubin family to show “very impressive performance improvements” over Blackwell. Atif Malik of Citigroup notes that Blackwell provided 30 times faster performance than the company’s previous generation on AI inferencing, which is when trained AI models generate output. “We don’t rule out Rubin seeing similar improvement,” Malik wrote in a note to clients this month.
Rubin products aren’t expected to start shipping until next year. But much is already expected of the lineup; analysts forecast Nvidia’s data-center business will hit about $237 billion in revenue for the fiscal year ending in January of 2027, more than double its current size. The same segment is expected to eclipse $300 billion in annual revenue two years later, according to consensus estimates from Visible Alpha. That would imply an average annual growth rate of 30% over the next four years, for a business that has already exploded more than sevenfold over the last two.
Nvidia has also been haunted by worries about competition with in-house chips designed by its biggest customers like Amazon and Google. Another concern has been the efficiency breakthroughs claimed by Chinese AI startup DeepSeek, which would seemingly lessen the need for the types of AI chip clusters that Nvidia sells for top dollar.
…………………………………………………………………………………………………………………………………………………………………………………………………………………….
Telecom Sessions of Interest:
Wednesday Mar 19 | 2:00 PM – 2:40 PM
Delivering Real Business Outcomes With AI in Telecom [S73438]
In this session, executives from three leading telcos will share their unique journeys of embedding AI into their organizations. They’ll discuss how AI is driving measurable value across critical areas such as network optimization, customer experience, operational efficiency, and revenue growth. Gain insights into the challenges and lessons learned, key strategies for successful AI implementation, and the transformative potential of AI in addressing evolving industry demands.
Thursday Mar 20 | 11:00 AM – 11:40 AM PDT
AI-RAN in Action [S72987]
Thursday Mar 20 | 9:00 AM – 9:40 AM PDTHow Indonesia Delivered a Telco-led Sovereign AI Platform for 270M Users [S73440]
Thursday Mar 20 | 3:00 PM – 3:40 PM PDT
Driving 6G Development With Advanced Simulation Tools [S72994]
Thursday Mar 20 | 2:00 PM – 2:40 PM PDT
Thursday Mar 20 | 4:00 PM – 4:40 PM PDT
Pushing Spectral Efficiency Limits on CUDA-accelerated 5G/6G RAN [S72990]
Thursday Mar 20 | 4:00 PM – 4:40 PM PDT
Enable AI-Native Networking for Telcos with Kubernetes [S72993]
Monday Mar 17 | 3:00 PM – 4:45 PM PDT
Automate 5G Network Configurations With NVIDIA AI LLM Agents and Kinetica Accelerated Database [DLIT72350]
Learn how to create AI agents using LangGraph and NVIDIA NIM to automate 5G network configurations. You’ll deploy LLM agents to monitor real-time network quality of service (QoS) and dynamically respond to congestion by creating new network slices. LLM agents will process logs to detect when QoS falls below a threshold, then automatically trigger a new slice for the affected user equipment. Using graph-based models, the agents understand the network configuration, identifying impacted elements. This ensures efficient, AI-driven adjustments that consider the overall network architecture.
We’ll use the Open Air Interface 5G lab to simulate the 5G network, demonstrating how AI can be integrated into real-world telecom environments. You’ll also gain practical knowledge on using Python with LangGraph and NVIDIA AI endpoints to develop and deploy LLM agents that automate complex network tasks.
Prerequisite: Python programming.
………………………………………………………………………………………………………………………………………………………………………………………………………..
References:
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
The case for and against AI-RAN technology using Nvidia or AMD GPUs
FT: Nvidia invested $1bn in AI start-ups in 2024
