

Author: Alan Weissberger
Highlights and Analysis of July 30th U.S. Senate hearing on AI and telecommunications
Disclaimer: Perplexity.ai was used for research used to generate this article.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Introduction:
Today, U.S. Senator Deb Fischer (R-Neb), Chairman of the Senate Commerce Subcommittee on Telecommunications and Media, convened a hearing examining how artificial intelligence (AI) is transforming telecommunications networks and how the technology can enhance services across America. Titled “Intelligent Networks: Powering Artificial Intelligence and Transforming Communications,” the hearing examined the bidirectional relationship between AI and network infrastructure. In particular, AI demands low-latency, high-bandwidth networks, while also offering tools to make those networks more efficient and secure.
Witnesses:
-
Jonathan Spalter, President and CEO, USTelecom — The Broadband Association
-
Dan Watermeier, Commissioner, Nebraska Public Service Commission
-
Bob Everson, Chief Architect of Provider Mobility, Cisco
-
Asad Ramzanali, Director of AI and Technology, Vanderbilt Policy Accelerator
From Senator Fischer’s opening remarks:
“As AI adoption increases, so will the demand for reliable and resilient communications infrastructure. Networks are the backbone along which the enormous amounts of data associated with AI are transmitted. I look forward to discussing both how networks are adapting to respond to AI and how AI is being used in networks to proactively plan for the future.”
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Permitting Reform Dominates Discussion
The clearest consensus across industry witnesses was that outdated permitting processes are the primary barrier to deploying AI-ready fiber infrastructure. Spalter testified that “the biggest barrier to building the broadband infrastructure our country needs isn’t technology or investment — it’s outdated permitting processes,” and urged Congress to establish consistent permitting timelines while preserving environmental and historic review requirements.
Watermeier emphasized that fiber is the only broadly deployable technology capable of supporting AI-era traffic, noting that “fiber optic networks can greatly exceed” the FCC’s current 100/20 Mbps threshold. Everson echoed the urgency, stating that providers are ready to build if permitting can be accelerated. Sen. Shelley Moore Capito (R-WV) supported establishing permitting “shot clocks.”
Spalter also identified cybersecurity and sustainable broadband funding as essential priorities, though specific proposals on either topic were not detailed in reported testimony.
Digital Divide and BEAD Funding
Sen. Lisa Blunt Rochester (D-DE) pressed witnesses on the impact of the Trump administration’s approximately 74% cut to the Broadband Equity, Access, and Deployment (BEAD) Program. Ramzanali responded that unconnected households are excluded from AI’s economic benefits, telehealth access, and educational tools, stating: “We shouldn’t accept the state of the country where not every American is connected to high-quality networks”
Grid Reliability and Spectrum: Largely Absent
Despite the hearing’s framing, two critical topics received little direct attention. Grid reliability — a pressing concern given that PJM Interconnection reported data-center-driven supply cost increases exceeding 60%, and Bank of America projected ~125 GW of new U.S. electric load from data centers by 2030 (Legis1) — was not substantively addressed by witnesses.
Spectrum policy was similarly underexplored, despite significant adjacent developments: the FCC’s July 22 vote to auction 160 MHz of upper C-band spectrum, NTIA’s $53 million funding announcement for secure AI-enabled Radio Access Networks, and a detailed spectrum reform brief published by the International Center for Law & Economics timed to the hearing. The ICLE brief recommended five reforms: preserving a balanced mix of licensed, unlicensed, and shared spectrum; streamlining the Spectrum Relocation Fund; strengthening FCC-NTIA coordination; replacing worst-case interference analysis with risk-informed probabilistic methods; and coherent U.S. engagement at the ITU World Radiocommunication Conference to counter Chinese influence in standards bodies.
Cybersecurity: Listed but Undefined
Spalter listed cybersecurity among his three essential priorities but did not elaborate on specific threats or mitigation strategies. The absence is notable given that an adjacent House hearing on July 22 featured testimony from Lindsay Gorman warning that AI is “expanding the cyberattack surface” through prompt-injection attacks, data poisoning, and model exploitation. Gorman urged Congress to mandate AI cybersecurity standards and recommended next-generation networks implement AI-automated defenses and post-quantum cryptography.
Industry vs. Regulatory Divergence
The hearing revealed a clear fault line. The three industry witnesses uniformly advocated for reducing regulatory friction and enabling private investment. Ramzanali, whose broader research at Vanderbilt advocates utility-style regulation of digital infrastructure, structural separation of AI hardware and software, and a dedicated digital regulator, provided the only counterweight — though his reported testimony focused on digital divides rather than his full structural reform agenda.
Sen. Fischer’s opening remarks captured the industry-aligned framing: “Opaque regulations and lack of coordination should not get in the way of network development.” Sen. Blunt Rochester’s questioning represented the regulatory perspective, challenging funding cuts and emphasizing equitable access.
Outlook
The hearing underscored that the U.S. telecommunications policy debate around AI is currently dominated by infrastructure deployment concerns — particularly permitting — while cybersecurity, spectrum management, and grid reliability remain underexamined. With the Senate Commerce Committee delaying broader AI legislation markup until after the summer recess (Washington Times), the substantive policy work on these gaps may not advance until fall.
Full written testimony and a hearing transcript are not yet available on the committee website.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………..
Analysis via Perplexity.ai:
Comparison Matrix: Key Recommendations by Topic
1. Grid Reliability and Energy Demand
2. Cybersecurity Vulnerabilities
3. Spectrum Policy
4. Regulatory Reform vs. Government Oversight
5. AI-Enabled Services: Industry Priorities vs. Regulatory Proposals
Key Divergences and Synthesis
Consensus Points
-
Permitting reform is urgent. All three industry witnesses and Republican senators agreed that permitting delays are the single biggest barrier to AI-ready network deployment. Even Sen. Fischer’s opening remarks flagged “opaque regulations.”
-
Fiber is foundational. Spalter, Watermeier, and Everson all positioned fiber as the backbone infrastructure for AI. Fischer encapsulated it: “AI runs on infrastructure, and infrastructure runs on fiber.”
-
AI transforms networks bidirectionally. Fischer’s framing — that AI requires better networks but can also make networks more efficient and secure — was implicitly accepted across witness testimony.
-
Industry self-regulation vs. structural oversight. The three industry witnesses (Spalter, Watermeier, Everson) uniformly advocated for removing regulatory friction and letting private capital deploy infrastructure. Ramzanali’s framework — developed at Vanderbilt and reflected in his testimony on digital divides — argues for utility-style regulation, structural separation, and a dedicated digital regulator. This is the fundamental fault line.
-
BEAD funding. Industry witnesses mentioned “sustainable broadband funding” as a priority but did not challenge the Trump administration’s 74% cut to BEAD. Sen. Blunt Rochester and Ramzanali directly attacked the cuts as harmful to AI equity. Industry silence on BEAD cuts suggests a pragmatic accommodation with the administration’s budget priorities.
-
Cybersecurity specificity. Spalter listed cybersecurity as essential but offered no concrete proposals in reported testimony. This stands in contrast to the adjacent House hearing where witnesses like Lindsay Gorman called for mandated congressional cybersecurity standards. The gap between listing cybersecurity as a priority and proposing actual security mandates represents a significant industry-regulatory divergence.
-
Spectrum was largely absent. Despite ICLE publishing a detailed five-reform spectrum brief timed to the hearing, and despite the FCC’s July 22 C-band auction vote and NTIA’s $53M AI-RAN funding announcement, none of the witnesses’ reported testimony engaged substantively with spectrum policy. This is a notable omission given that Everson’s title (Chief Architect of Provider Mobility) implies wireless expertise. The ICLE brief’s warning that “the United States cannot lead at digital speed while governing the airwaves at bureaucratic speed” went unaddressed in the hearing room.
Implications for Next-Generation AI-Enabled Services
-
The hearing’s overwhelming focus on permitting reform and fiber deployment — while important — left cybersecurity, spectrum, and grid reliability largely underexplored. The most consequential gap is the absence of detailed cybersecurity testimony, given that AI is simultaneously expanding the attack surface and offering new defensive tools.
-
Ramzanali’s presence provided the only counterweight to the industry consensus, but his reported testimony focused narrowly on digital divides rather than his broader structural reform agenda. Whether his Vanderbilt research on AI infrastructure financial risks and digital utility regulation will influence future Senate action remains to be seen.
-
The ICLE spectrum framework — published as context for this hearing — represents the most detailed policy roadmap for AI-enabled wireless services, but it was not directly debated by the witnesses. The FCC’s C-band auction and NTIA’s AI-RAN funding are proceeding on parallel tracks outside the hearing’s scope.
…………………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
NEWS: Senator Blunt Rochester Highlights How AI Will Impact Digital Divides
Dell’Oro: Telecom carriers are on a 5G SA spending spree with more to come
Dell’Oro Group, says that telecom wireless carriers have spent 208% more on 5G Standalone (SA) than they had on 4G Core functions at the same point in the technology’s lifecycle. However, 5G Mobile Core Network revenue growth is expected to slow over the next two years, as carriers put off transformation projects due to elevated server costs.
“The way the 3GPP specifications unfolded created an offset between 5G RAN spending and the implementation of 5G SA,” said Siân Morgan, Senior Director at Dell’Oro Group. “However, the complexity of the 5G SA is driving cumulative vendor revenues much higher than they were at the same stage in the LTE Evolved Packet Core (EPC) lifecycle.
“5G SA revenues have not yet peaked,” Morgan added. “The majority of mobile network operators haven’t made 5G SA services available to a broad base of their customers. Some operators are delaying core transformation projects because memory shortages are driving up server prices, but we expect double-digit 5G Mobile Core Network revenue growth to resume in 2028.”
Additional highlights from Mobile Core Network and Multi-access Edge Computing 5-Year Forecast July 2026 Report include:
- EMEA (Europe, Middle East and Africa) will drive the most Mobile Core Network revenue over the next five years.
- Despite being superseded by 5G, 4G core revenue grew in 2025, and Dell’Oro Group raised the forecast for this market.
- AI will have a variable impact on mobile core networks, with opportunities for efficiency and revenue generation, alongside a risk of escalating costs.

The Dell’Oro Group Mobile Core Network & Multi-Access Edge Computing Quarterly Report offers complete, in-depth coverage of the market with tables covering manufacturers’ revenue, shipments, and average selling prices for Traditional Packet Core, Evolved Packet Core, 5G Packet Core, Policy, Subscriber Data Management, Signaling, Circuit Switched Core, and IMS Core by geographic regions. To purchase this report, please contact us at [email protected].
……………………………………………………………………………………………………………………………………………………….
From Perplexity.ai and Ericsson:
Analysis:
5G SA differs from NSA because it uses a 5G core rather than relying on 4G core (EPC) anchoring, which makes it better suited for advanced capabilities like network slicing and more flexible service control. All 5G features and functions, e.g. 5G security, network slicing, MEC, etc require a 5G SA core network. 5G network operators can package differentiated services instead of treating 5G only as a faster broadband layer.
Adoption is already broadening geographically. Ericsson says more than 60 service providers had deployed or launched public 5G SA networks by the end of September 2024, with early leadership in North America, China, Southeast Asia, and Australia, and with deployments expanding into Latin America, the Gulf Cooperation Council, and South Africa.
Device readiness is also improving quickly. Ericsson notes that the share of announced 5G devices supporting SA was about 70 percent by the end of June 2024, which lowers one of the biggest historical blockers to mass adoption.
From a vendor and operator perspective, the value of SA is shifting from coverage to monetization. Dell’Oro says many operators already use SA for enterprise and fixed wireless access, even if they have not yet opened it broadly to consumers, which suggests the strongest initial revenues may come from business services before mass-market consumer plans.
Market Forecast:
The strongest public forecast in the sources is subscriber growth: Ericsson projects global 5G SA subscriptions will reach about 1.2 billion by the end of 2024 and approximately 3.6 billion by 2030, which would represent nearly 60 percent of all 5G subscriptions by that time.
On the infrastructure side, Dell’Oro expects the 5G mobile core network market to grow at a 6 percent CAGR from 2024 to 2029, largely driven by SA adoption, while MEC is forecast to grow faster at 17 percent CAGR because of network slicing, RedCap, and network APIs tied to Open Gateway.
A reasonable market view is that 2025–2027 will be the period when SA shifts from launch announcements to scale, especially as more operators convert consumer traffic, expand enterprise use cases, and retire older core dependencies. By the late 2020s, growth should be driven less by “first deployment” and more by monetization density: more SA subscribers, more eligible devices, and more services built on top of the SA core.ericsson+1
What to watch:
-
Consumer rollout pace. Operators that keep SA limited to enterprise and FWA will likely monetize more slowly than those that open it to consumers.
-
Device defaults. SA-enabled devices matter less if SA is not the default setting, so default-on support is an important adoption catalyst.
-
Enterprise use cases. Slicing, private wireless integration, and low-latency applications are likely to produce the clearest near-term ROI.
-
Regional timing. China and India are expected to remain major contributors, while Europe and parts of the Americas close the gap later in the decade.
References:
5G Standalone Revenue Triples 4G Core at Same Stage of Tech Cycle, According to Dell’Oro Group
GSA: 5G Non Terrestrial Networks, 5G SA and 5G Advanced gain momentum
Dell’Oro: Mobile Core Networks +15% in 2025; Ookla: Global Reality Check on 5G SA and 5G Advanced in 2026
Dell’Oro: RAN market stable, Mobile Core Network market +14% Y/Y with 72 5G SA core networks deployed
AT&T deploys nationwide 5G SA while Verizon lags and T-Mobile leads
Ericsson CEO’s strong statements on 5G SA, WRC 27, and AI in networks
Amazon Leo plans to deploy 5,105 D2D to interoperate with Apple devices
Executive Summary:
Amazon Leo, the #1 competitor to SpaceX’s Starlink for LEO satellite internet, is proposing a new Direct to Device (D2D) constellation comprising 5,105 low-Earth orbit (LEO) satellites that will work in concert with satellites Amazon is acquiring from Globalstar.
Amazon Leo has disclosed additional technical and regulatory detail on its proposed global direct‑to‑device (D2D) low Earth orbit (LEO) constellation, envisioned to comprise 5,105 satellites and to operate in conjunction with D2D capacity obtained via Amazon’s planned acquisition of Globalstar.
System architecture and spectrum use:
According to an FCC application filed by Kuiper Systems LLC on Saturday, July 25, the Amazon Leo D2D system is designed to leverage Mobile‑Satellite Service (MSS) spectrum as well as selected terrestrial mobile bands to deliver “ubiquitous global coverage.” The constellation will employ D2D‑optimized spacecraft using service links in the 1.6–2.4 GHz range, supported by feeder links and TT&C in Ka‑ and V‑band. Outside the US, Amazon plans to utilize additional available L‑band and S‑band allocations for service links to expand geographic reach and regulatory flexibility.
In a Monday technical blog post, Amazon Leo outlined a five‑shell orbital architecture, with three mid‑latitude shells designed to serve densely populated regions and two high‑latitude shells to extend coverage into remote geographies, including polar areas. Amazon reiterated that the D2D constellation is being engineered to interoperate with Apple devices (including iPhone and Apple Watch) and to complement its Kuiper broadband network, which is expected to enter commercial service later this year.

Integration with Globalstar and optical ISLs:
The Amazon Leo D2D constellation will incorporate optical inter‑satellite links (OISLs) to integrate the new D2D system with existing Amazon Leo satellite infrastructure and to “work in close concert” with the Globalstar MSS constellation in the 1.6–2.4 GHz band, assuming timely closing of the transaction. Amazon states that it will mitigate inter‑system interference between the Amazon Leo D2D system and Globalstar’s HIBLEO‑4, HIBLEO‑X, and planned C‑3 MSS operations via unified global network management and coordinated controls.
The proposed $11.5 billion Amazon–Globalstar deal remains under active regulatory review. Amazon Leo has previously indicated that its own D2D constellation is targeted for launch around 2028, positioning the system as a smartphone‑ and device‑centric coverage layer beyond the reach of terrestrial radio access networks and as a competitor or complement to emerging D2D offerings from SpaceX, AST SpaceMobile, and others. Amazon has highlighted canonical D2D use cases, including emergency messaging, in‑vehicle connectivity, and a broad range of IoT applications.
The potential role of Amazon’s D2D platform within the new US rural‑coverage D2D joint venture formed by AT&T, T‑Mobile, and Verizon remains unspecified.
Satellite lifecycle, deorbiting, and debris mitigation:
Each Amazon Leo D2D satellite is designed with a nominal operational life of six to eight years, contingent on orbital shell parameters. Amazon plans active end‑of‑life management and deorbiting, reserving approximately 40% of each satellite’s propellant for “disposal operations” to support controlled removal from orbit.
The FCC filing also provides additional detail on collision‑risk management and debris‑mitigation strategies. To reduce the probability of fragmentation events, Amazon has engineered propellant tanks to leak rather than burst under most failure modes, including micrometeoroid and orbital‑debris impacts, and has characterized tank behavior under high‑velocity impact conditions. The constellation will be monitored on a 24/7 basis for conjunction and collision risk, and each satellite will be equipped with onboard propulsion and maneuvering capability to perform collision‑avoidance maneuvers with respect to other spacecraft and tracked objects.
References:
https://www.lightreading.com/satellite/amazon-leo-files-plan-to-deploy-5-105-d2d-satellites
Cheap Chinese AI Models: Unappreciated Threat to U.S. Hyperscaler AI Dominance
Introduction:
IEEE Techblog readers are keenly aware of the stupendous AI capex that has eliminated most hyperscaler free cash flow. There’s also the ROI question when there’s no “killer app” or a clear way to monetize AI services. And let’s not forget issues like: the competition for AI benchmark bragging rights. price per token, rack density, and power consumption-per-dollar.
Now the next AI battleground will be competition from Chinese open-weight models, which are pushing AI toward commoditization faster than many U.S. hyperscalers expected. That shift could quietly erode the economics of the entire AI infrastructure stack.
Raffi Krikorian, the chief technology officer at Mozilla, which runs the Firefox browser, switched to Chinese AI startup Moonshot’s Kimi K3 for many of his day-to-day activities within days of the new, powerful model’s launch more than a week ago. “It just seems snappier,” Krikorian said of K3, comparing it with the acclaimed, higher-priced Claude Fable chatbot from Anthropic, the San Francisco private AI company with a $1 trillion assessed market value. Earlier, he had been using another strong Chinese model, Z.ai’s GLM-5.2, for everyday tasks such as managing his calendar, documents, and email.
Krikorian is among a growing number of Americans turning to Chinese AI systems, which are gaining traction worldwide because they are more affordable and increasingly efficient. U.S. companies such as cryptocurrency exchange Coinbase have said they are switching to Chinese AI models to help reduce costs. Their growing popularity has frustrated some U.S. tech giants, but barring an outright ban, these models are likely to keep attracting independent software developers in the U.S. and beyond.
The shift from training to inference:
The AI buildout is moving from model training toward sustained inference, and that changes the economics of the stack. Training demands enormous one-time bursts of compute, but inference creates continuous load on accelerators, interconnect, storage, and power systems, which means utilization and token pricing now matter as much as raw model capability.
That is where Chinese open-weight models matter most. Reports indicate that some are 60% to 90% cheaper than leading U.S. AI offerings, while still being “good enough” for a large share of enterprise and developer workloads.
Why open weight matters technically:
Open-weight models reduce deployment friction by allowing organizations to download, modify, and run models on their own infrastructure rather than through a centralized API. NTIA has noted that this can broaden access and accelerate innovation, but it also shifts responsibility for integration, safety, and lifecycle management onto deployment.
From an infrastructure perspective, that means AI demand becomes more distributed. Instead of concentrating in a small number of hyperscale regions, workloads can move into private clouds, regional facilities, enterprise data centers, and even edge-adjacent environments, changing traffic patterns and backend topology.
Impact on hyperscaler design:
The first-order risk for hyperscalers is not loss of raw demand; it is lower monetization per unit of demand. If users route routine inference to cheaper Chinese models, the same physical infrastructure may carry more tokens but generate less revenue, pressuring the economics of GPU clusters, accelerator networking, and power-hungry cooling systems.
That is a serious issue because modern AI facilities are purpose-built systems. They rely on dense GPU racks, low-latency fabrics, liquid cooling, and carefully engineered power distribution, all of which are justified by high utilization and strong margins. If the average workload shifts to lower-value inference, the return on those assets falls even if the machines stay busy.
Network and power consequences:
The networking impact is equally important. More self-hosted and regionally deployed inference increases east-west traffic inside enterprise environments and raises demand for metro transport, interconnect, and secure private connectivity, rather than only for giant centralized AI campuses.
Power and cooling are the other pressure points. AI infrastructure already consumes substantial electrical power and water, and inference-heavy systems can run continuously, making thermal design and power delivery central to total cost of ownership. If cheaper models fragment the market across more sites, the industry may need more distributed capacity without the same revenue density to support it.
The strategic takeaway:
For U.S. AI companies and hyperscalers, the threat from Chinese open-weight models is best understood as commoditization of inference. The frontier race may continue at the top end, but the commercial center of gravity is shifting toward lower-cost, portable models that reduce lock-in and weaken pricing power across the stack. The infrastructure question is no longer whether AI demand will grow; it is whether the industry can preserve enough margin, utilization discipline, and network economics to make that growth pay.

……………………………………………………………………………………………………………………………………………………………………….
Open-weight AI model landscape
- Chinese open-weight models are strongest on cost and deployability. That makes them especially disruptive for inference-heavy workloads, where price per token and operational control matter most.
- U.S. closed models remain strongest on managed-service depth and frontier capability. Their advantage is less about openness and more about product integration, reliability, and enterprise tooling.
- For infrastructure operators, the key issue is workload migration. Open-weight models can move inference from hyperscale APIs into private clouds, regional facilities, and enterprise data centers, changing network and power demand patterns.
- The strategic tradeoff is control versus simplicity. Open models lower vendor lock-in, but they increase responsibility for GPU capacity, MLOps, safety, observability, and lifecycle management.
…………………………………………………………………………………………………………………………………………………………………….
References:
Hyperscaler AI Race: Soaring Capex Wipes Out Free Cash Flow; AGI and Digital Gods
| Company | 2024 (Actual) | 2025 (Actual) | 2026 (Current Guidance / Est) | 2027 (Projected) |
|---|---|---|---|---|
| 📦 Amazon | $53B | $112B | $195B – $210B | $230B – $260B |
| 🔍 Alphabet (Google) | $51B | $104B | $195B – $205B | $240B – $280B |
| 💻 Microsoft | $56B | $108B | $185B – $195B | $220B – $250B |
| ♾️ Meta | $38B | $85B | $125B – $145B | $150B – $180B |
| 🗄️ Oracle | $13B | $25B | $45B – $50B | $55B – $65B |
| 🧮 Combined Aggregate | $211B | $434B | $745B – $805B | $895B – $1,035B |
The huge increase in hyperscaler capex, wipes out their free cash flow (revenues-expenses is now negative for all but Microsoft). The shift in focus by investors from earnings to free cash flow marks a turning point in market perceptions. The correct way to describe free cash flow is the cash flow a company generates during a period of time that is available to be paid to the company’s shareholders and debtholders.Companies with negative free cash flow are only able to cover the interest and principal on their debt by additional borrowing or by issuing new equity. In other words, cash is flowing from investors to the company, not the other way around. In a financial crisis, investors become unwilling to support companies not able to cover interest and principal, with the result being a cascade of defaults and runs on financial institutions.
A major concern with the massive AI-capex which has occurred during the last two years is that much of it is debt financed. As the real cost of generative AI-tokens is becoming clear, lower priced Chinese competitors are emerging, and AI customers are beginning to economize on their use of AI. As a result, investors are becoming increasingly alarmed about whether U.S. AI firms will be able to cover their debt obligations. AI-capex has been the main, and perhaps only driver of U.S. economic growth. If more companies announce negative free cash flows, that increase in magnitude, the financial system and overall economy will move closer to the tipping point.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
But wait, Google/Alphabet co-founder says it’s more about winning AI market share than skyrocketing capex or ROI. On Patrick O’Shaughnessy’s Invest Like the Best podcast, Gavin Baker, Chief Investment Officer for Atreides Management, shared an anecdote about what’s been going on within Google/Alphabet offices. According to Baker, Google co-founder Larry Page has been telling Google employees, “I am willing to go bankrupt rather than lose this race.” That shows how high the person who led Alphabet through its halcyon days thinks the stakes are in AI.
References:
https://www.fool.com/investing/2024/08/31/thinking-of-selling-nvidia-stock-larry-page-quote/
Curmudgeon: Caveat Emptor: Huge Debt and Circular Financing Deals Dominate AI Build-Outs
Merry-go-round of dog chasing its tail: Relationship between U.S. hyperscalers and private Gen AI companies
Ookla: AI platform reliability decreases as outages surge
Nvidia CEO Huang: AI is the largest infrastructure buildout in human history; AI Data Center CAPEX will generate new revenue streams for operators
Hyperscaler capex > $600 bn in 2026 a 36% increase over 2025 while global spending on cloud infrastructure services skyrockets
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
5G infrastructure moves from coverage and speeds to cloud-native, orchestration, automation and AI-assisted networks
The most meaningful 5G infrastructure theme this week is the continued shift toward 5G standalone (SA), cloud-native, and AI-assisted networks. Recent news coverage shows that network operators and vendors pushing 5G SA expansion, automation, and 5G private-network use cases, alongside funding and buildout activity in fiber and rural transport that support 5G subscriber coverage and network capacity growth.
A few developments stand out from the available coverage:
- Google Cloud and Nokia expanded their AI partnership for autonomous networks.
- Ericsson and LG Uplus (Korea) agreed to deepen their strategic partnership to develop and expand network-based voice AI solutions for global markets, and advance AI-native network transformation.
- KDDI (Japan) launched a RAN digital twin initiative.
- CityFibre (UK) extended its 5G SA partnership with VodafoneThree (UK).
- Microamp (Poland) won EU backing for a 5G mmWave AI-RAN platform.
- There is also continuing momentum around mission-critical and industrial 5G, including Nokia Defense/KNDS tactical communications and Telia’s work on critical IoT and advanced 5G SA services.
It’s now crystal clear that 5G infrastructure investment is moving beyond raw radio deployment and into orchestration, automation, and vertical-specific network design. That is the bigger takeaway for telecom analysts: 5G spend is increasingly being justified by software intelligence, private/enterprise monetization, and operational efficiency rather than network coverage or speeds.

Image Credit: Nvidia
…………………………………………………………………………………………………………………………………………………………………………………………………………
The following table and text was generated by Perplexity.ai:
AI-Driven Network Management: Nokia vs. Ericsson vs. KDDI (2026):
An important structural caveat: Nokia and Ericsson are network equipment vendors whose AI tools are deployed across multiple operator customers, while KDDI is a mobile network operator deploying AI within its own live network. Direct comparisons of “commercial deployment” must account for this important distinction.
Comparison Table
Furthest along at vendor/customer commercial scale: Ericsson. The strongest discriminator is deployed EIAP customer adoption (AT&T, Swisscom, Telstra, Vodafone), the ~90-rApp ecosystem with ~90 ecosystem members, and the scale of Ericsson’s AI network-optimization estate (100M+ daily AI inferences across 13M+ sites serving 2B+ subscribers). The #1 ABI Research ranking for RAN automation (February 2026), the commercially scalable AI in RAN software subscription (June 2026), and rApp aaS available on AWS Marketplace (February 2026) further solidify Ericsson’s position as the most commercially mature vendor. Ericsson also has the broadest pre-existing digital twin ecosystem, though its RAN digital twin assets are more fragmented across research initiatives, rApps, and site-level tools compared to Nokia’s unified product launch.
Furthest along as an operator using AI agents in its own live network: KDDI. KDDI’s Fault Recovery Support Agent has been live in commercial operations since February 2026, and its multi-AI agent area optimization technology is deploying nationwide across base stations in FY2026 with confirmed quantitative gains (25% improvement in congested areas, 95%+ reduction in optimization work). This is stronger “own-network production” evidence than Nokia’s or Ericsson’s vendor-side claims, because KDDI is demonstrating autonomous AI agents operating in a live commercial network rather than selling tools for others to deploy. However, KDDI’s RAN Digital Twin remains an early-stage collaboration (prototype target March 2028), and its Gemini on GDC integration is still in trial.
Furthest along in explicit Gemini integration: Nokia. Nokia has the most direct and productized Gemini integration of the three, with six specialized Gemini-powered agents built on Google Cloud’s ADK and Gemini Enterprise Agent Platform, two of which (Router and Event Triage) are already running in Nokia’s environment. However, these agents are not yet commercially deployed with operator customers — the full SaaS package targets Google Cloud Marketplace in September 2026, with additional agents shipping through 2027. Nokia also launched the clearest single RAN Digital Twin product (February 2026, NVIDIA AODT) and has the most explicit vendor-side Gemini story, but its commercial deployment footprint with operators is narrower than Ericsson’s.
Summary:
Ericsson leads in commercial scale and breadth, KDDI leads in live operator-network AI agent deployment, and Nokia leads in depth of Gemini integration and unified RAN digital twin productization.
………………………………………………………………………………………………………………………………………………………………………………………….
References:
Nokia RAN Digital Twin launch (Feb 2026) — primary source for the NVIDIA AODT-powered product (Nokia RAN Digital Twin, a telecommunications simulation system built on the NVIDIA Aerial Omniverse Digital Twin (AODT) platform. It uses accelerated ray tracing and AI to model 5G and 6G wireless network environments)
5 New Digital Twin Products Developers Can Use to Build 6G Networks
RCR Wireless: Nokia Gemini agents in network ops (Jun 2026) — detailed breakdown of all six agents, tech stack, 50-80% efficiency gains, deployment timeline
Nokia autonomous networks portfolio upgrade (Jun 2026) — Agent Library, 60-80% productivity gains, all network layers covered
Ericsson AI in RAN launch (Jun 2026) — commercially scalable software subscription, agentic AI support, Ericsson Silicon
Ericsson #1 ranked by ABI Research for RAN automation (Feb 2026) — EIAP adoption by AT&T, Swisscom, Telstra, Vodafone; ~90 Apps and ecosystem members
Ericsson blog: Network digital twin for safe autonomy (Apr 2026) — Ericsson’s vision for predictive, interactive NDTs in autonomous networks
KDDI RAN Digital Twin launch (Jun 2026) — primary source; NVIDIA, Keysight, Samsung partners; prototype by March 2028, commercial validation by FY2030
KDDI Fault Recovery Support Agent (Feb 2026) — live since Feb 19, 2026; operational digital twin for fault analysis; Autonomous Maintenance Agent planned FY2026
KDDI multi-AI agent area optimization (Feb 2026) — nationwide deployment FY2026; 25% improvement in congested areas; 95%+ work reduction
KDDI Gemini on Google Distributed Cloud trial (Apr 2026) — Gemini on GDC trial at Osaka Sakai Data Center; multi-agent system for network development automation; commercial target 2027
Verizon’s $1 Billion Google Dark Fiber Deal Highlights Importance of Optical Networks
Executive Summary:
Verizon CEO Dan Schulman said on Friday the company had secured a more-than-$1 billion dark fiber agreement with Google. It underscores how hyperscale AI growth is elevating dark fiber, route diversity, and high-capacity optical engineering into core industry priorities and is evidence that the network layer is becoming a central enabler of AI-scale computing. The deal, disclosed during Verizon’s Q2 2026 earnings call, is intended to connect Google data centers and support the transport demands of AI workloads.
“We have other deals that we expect to announce by year end that taken together are expected to be worth multiple billions of dollars in revenue over the next several years,” Schulman said on Verizon’s post-earnings call.
From a telecom perspective, the significance lies in the shift from best-effort connectivity toward engineered optical infrastructure with explicit performance objectives. As hyperscalers expand distributed AI training and inference, the requirements for capacity, latency, route diversity, and operational control increasingly favor dark fiber over shared transport models.blogs.cisco+2
Why This Matters for Network Architecture:
Dark fiber gives the customer direct control over the optical layer, enabling custom design choices for line rates, protection schemes, and traffic engineering. That flexibility is especially relevant for large data-center interconnect environments, where traffic growth can quickly outpace conventional managed services.blogs.cisco+1
The Verizon-Google transaction also reinforces the role of long-haul and metro fiber as strategic infrastructure rather than commodity bandwidth. In practice, this places greater emphasis on fiber route resilience, diverse path design, and the ability to scale toward higher-capacity optical systems as AI clusters expand.blogs.cisco+1
Standards and Industry Implications:
While the deal itself is commercial, its implications touch several standards-adjacent concerns that are increasingly important to operators and vendors. These include high-capacity optical transport, inter-domain coordination, deterministic latency for distributed workloads, and the operational models needed to support AI-driven traffic growth.blogs.cisco+1
For IEEE ComSoc readers, the broader signal is that future network evolution may be shaped as much by AI infrastructure economics as by traditional access or mobility growth. The value proposition is moving toward fiber-based transport layers that can support hyperscale interconnect, cloud adjacency, and resilient backhaul for distributed computing environments.benton+1
Conclusions:
Verizon’s reported dark fiber deal with Google suggests that optical connectivity is no longer a passive enabler but a competitive differentiator in the data-center supply chain. It highlights a broader shift in network economics: AI growth is elevating fiber infrastructure from a supporting asset to a strategic enabler. For carriers, the message is clear — the winners in the AI era may be those that can pair scale, route control, and transport engineering with the capacity demands of hyperscale cloud buildouts.
Text & Images from Sebastian Barros:
Verizon’s billion dollar agreement with Google shows that the AI infrastructure boom is moving beyond chips, data centers and electricity. The next constraint is connecting everything together. Verizon will use existing fiber where possible and construct new routes where necessary. It can provide either dark fiber or managed, lit capacity, depending on what the customer wants.

Google already operates one of the most advanced private networks in the world. Its infrastructure spans more than two million miles of lit fiber, 33 subsea cable investments, more than 200 network edge locations, and thousands of content delivery sites. Yet Google still needs Verizon to provide additional routes.
The (hyperscaler) companies building the largest AI brains cannot build every nerve themselves, as the pace is too fast. The telco opportunity begins when data needs to leave the campus.

Models must be copied between regions; training datasets must be moved from storage locations to computing clusters; companies need private connections to cloud platforms; AI applications must retrieve enterprise information stored across different data centers. Inference results must reach factories, vehicles, hospitals, stores, offices, and consumers.
AI therefore requires two different networks. The first connects processors inside the brain. The second connects different brains with the outside world, and Telcos have a much stronger position in the second.
References:
https://sebastianbarros.substack.com/p/every-brain-needs-a-nervous-system
Verizon to build new, long-haul, high-capacity fiber pathways to connect AWS data centers
Hyper Scale Mega Data Centers: Time is NOW for Fiber Optics to the Compute Server
S&P Global Market Intelligence Surveys: Fiber Deployments in U.S. and Europe + AI Infrastructure Causes Market Shift
Amazon and Corning in Multi-Billion-Dollar Fiber Infrastructure Deal in North Carolina
2026 Fiber Connect Keynote: “The Future of Fiber Optics: AI and the Quantum”
Big Fiber’s $250M financing deal to buildout dark fiber routes for AI Data Center expansion
Highlights from Ookla’s U.S. Speedtest Connectivity Report-Mobile & Fixed Networks
Executive Summary:
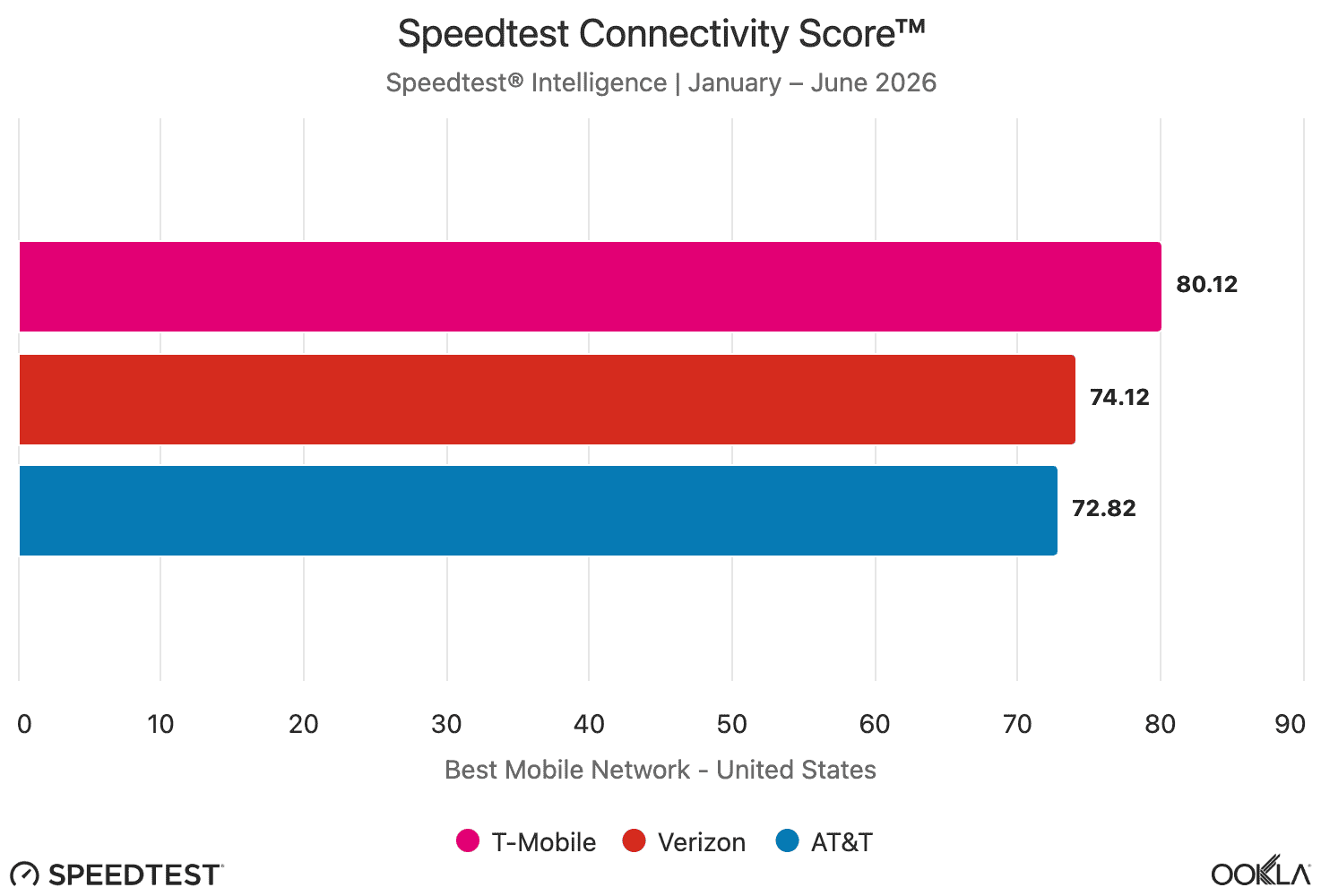
Ookla’s United States Speedtest Connectivity Report H1 2026 provides a detailed snapshot of network performance across the U.S. mobile and fixed broadband markets, based on Speedtest Intelligence data. The findings point to a competitive landscape in which T-Mobile continued to distinguish itself in mobile connectivity, while AT&T Fiber led the fixed broadband segment.
In the mobile network category, T-Mobile was named the Best Mobile Network overall and also claimed the Best 5G Network award for the first half of 2026. The “un-carrier” recorded a median download speed of 275.55 Mbps across all technologies combined, and a median 5G download speed of 314.38 Mbps. These results underscore the strong performance of T-Mobile’s network, particularly in 5G-centric use cases where throughput remains a key differentiator.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
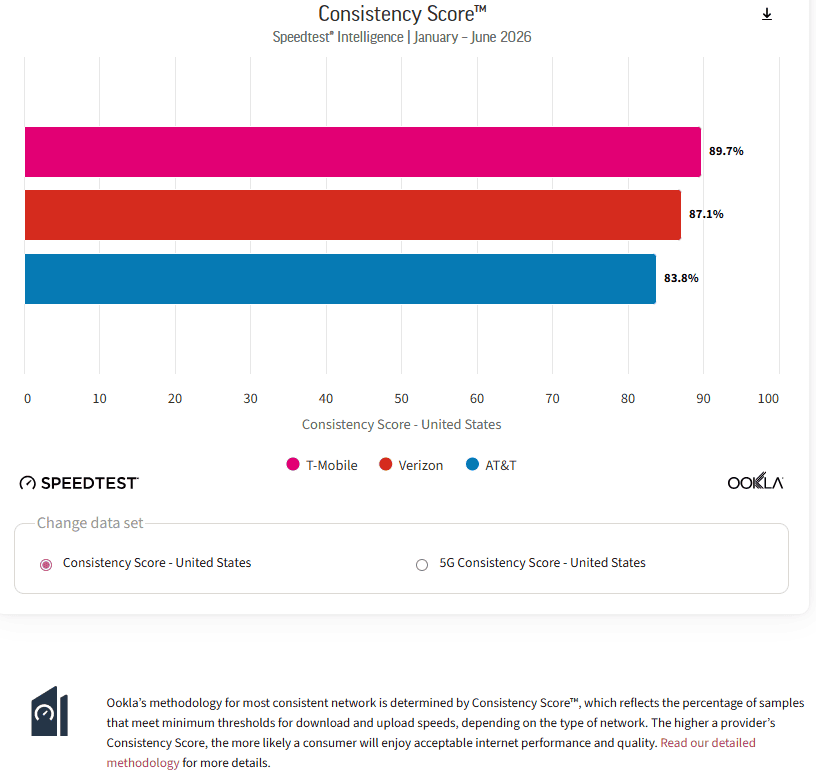
T-Mobile recorded the best mobile network consistency in the United States, for all technologies combined and for 5G. Across all technologies, 89.7% of its samples met or exceeded the threshold of 5 Mbps download and 1 Mbps upload, while 79.3% of its 5G samples met or exceeded the higher threshold of 25 Mbps download and 3 Mbps upload.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
For the fixed line networks, AT&T Fiber was recognized as the Best Internet provider and the Fastest Fixed Network in the United States during the same period. The oldest U.S. network operator posted a median download speed of 374.75 Mbps and a median upload speed of 320.65 Mbps, reflecting the growing importance of high-capacity fiber access in home broadband markets. As fixed and mobile connectivity continue to converge in consumer experience expectations, these metrics highlight the increasingly performance-driven nature of broadband competition.
The report also indicates that T-Mobile delivered the best gaming and video streaming experiences in the United States during 1H 2026, both across all technologies combined and in the 5G-only category. This is notable because it extends the company’s advantage beyond raw speed metrics into application-level quality, where latency sensitivity, jitter, and consistency can be as important as peak throughput.
At the city level, Lincoln, Nebraska recorded the fastest median mobile download speed among the most populous U.S. cities at 395.83 Mbps. In fixed broadband, Durham, NC led the group with a median download speed of 380.47 Mbps. These city-level results reinforce the fact that network performance varies significantly by market, even within a single national assessment, and that local deployment density and backhaul quality can materially influence user experience.
Editorial Analysis & Conclusions:
Taken together, the report suggests that U.S. network leadership in 1H 2026 was shaped by both access technology and service quality. Mobile operators are increasingly being judged not only by coverage and 5G speed, but also by end-user experience across demanding applications, while fiber providers continue to push the upper bounds of fixed-line performance. Ookla’s latest data therefore offers a useful benchmark for understanding where the U.S. connectivity market stands — and where competition is most intense.
- The U.S. mobile market appears to be shifting from a simple coverage contest toward a performance-and-experience contest. T-Mobile’s lead in overall mobile, 5G, gaming, and video-streaming experience suggests that end-user quality is now being shaped by a combination of throughput, consistency, and 5G availability rather than raw coverage alone.
- The results reinforce that 5G leadership is increasingly tied to how well operators can translate spectrum, radio access optimization, and transport capacity into sustained user experience. T-Mobile’s strong median download speeds across both blended and 5G-only measurements indicate that its network engineering is delivering not just peak performance, but performance that is visible in real-world usage patterns.
- The fixed broadband results show that fiber remains the benchmark for high-capacity access in the U.S. AT&T Fiber’s strong download and upload figures illustrate why fiber continues to set the standard for symmetrical, high-throughput residential service, especially as cloud applications, video conferencing, and multi-device home traffic continue to grow.
- Application-centric metrics are becoming more relevant in how networks are evaluated. The fact that T-Mobile led in gaming and video streaming experience suggests that operators are increasingly judged on latency-sensitive and consistency-sensitive workloads, not just speed-test averages. For ComSoc readers, that is a reminder that network KPIs are evolving in step with how people actually use the network.
- At the city level, the report also highlights how uneven performance can be across markets. Lincoln’s leading mobile result and Durham’s leading fixed result suggest that local infrastructure, spectrum conditions, and deployment density still matter significantly even within a mature national market. This is especially relevant for planners and researchers interested in the last mile, metro-area capacity, and regional quality-of-experience gaps.
Overall, the report suggests that U.S. connectivity competition is entering a more mature phase in which operators are differentiated less by whether they can deliver 5G or fiber at all, and more by how well they can optimize those platforms for sustained, application-level performance. For IEEE Techblog readers, that makes the report useful not only for network operator rankings, but as a snapshot of where network engineering priorities are heading.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
https://www.ookla.com/research/reports/united-states-speedtest-connectivity-report-h1-2026
https://www.ookla.com/resources/guides/speedtest-methodology
Ookla: AI workloads will force changes in 5G mobile network infrastructure
Ookla: AI platform reliability decreases as outages surge
Ookla on the Global D2D Market
Ookla: Starlink a viable competitor for hybrid 5G/NTN services due to network performance improvements and larger coverage area
Ookla: D2D satellite connectivity surged 24.5% during last 9 months; Starlink’s footprint expansion leads the way
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Autonomous customer experience required for AI-Native 6G and distributed intelligence at the network edge
Executive Sumary:
Communications service providers (CSPs) have historically competed on network-centric KPIs—coverage, capacity, reliability, and price—anchored in 3GPP performance and management frameworks (e.g., TS 28-series, TS 23.501 QoS models). However, these metrics alone are no longer sufficient to sustain differentiation in increasingly saturated and capital-intensive markets, according to Chantel Cary, Product Marketing Senior Manager at Oracle Communications [1],
“The battleground has shifted,” Cary told Capacity Global. “Today, customer experience is becoming the clearest point of differentiation, and in many cases, the most important driver of growth.”
This shift is unfolding alongside structural constraints: flat ARPU, rising capex associated with 5G standalone, fiber access (FTTx), and edge cloud expansion, and increasing customer acquisition and retention costs. At the same time, customer expectations—benchmarked against hyperscaler-grade digital platforms—are becoming uniformly high across mobile and fixed broadband services.
“They do not compare a telecom provider only to other providers,” she said. “They compare every experience to the best experience they have anywhere.”
…………………………………………………………………………………………………………………………………………………………………………………………………………………..
Note 1. Oracle Communications is a dedicated global business unit and product portfolio fully owned and operated by Oracle. It provides enterprise software and infrastructure designed specifically for telecommunications service providers (like AT&T or Verizon) and large enterprises. Their solutions manage everything from network routing, security, and signaling (including 5G) to back-office billing, revenue management, and customer experience operations,
…………………………………………………………………………………………………………………………………………………………………………………………………………………..
Analysys Mason reports that 97% of operators view AI-powered automation as essential for survival and growth, reinforcing alignment with TM Forum’s Autonomous Networks framework and the broader industry transition toward AI-native system design.
AI-Native Customer Experience Architecture:
Cary’s concept of “autonomous customer experience” maps directly to the emerging paradigm of AI-native networks, where intelligence is embedded across both network and service layers rather than applied as an overlay. “It is not about removing the human element from engagement,” she explained. “It is about using AI to continuously orchestrate the customer lifecycle in ways that humans alone cannot manage at scale.”
In wireless networks, this evolution is reflected in 3GPP-defined enablers such as the Network Data Analytics Function (NWDAF, TS 23.288), which provides real-time analytics to optimize policy control, mobility, and QoS. In parallel, O-RAN Alliance architectures introduce the near-real-time and non-real-time RAN Intelligent Controllers (near-RT RIC, non-RT RIC), enabling AI-driven control loops for radio resource management and service optimization.

Image Credit: Aisera
In wireline and converged networks, similar principles are emerging through SDN-based control planes, broadband network gateways (BNG) with telemetry streaming, and ITU-T frameworks (e.g., Y.3172 for machine learning in future networks), enabling closed-loop optimization across access, aggregation, and core domains.
However, Cary notes that most OSS/BSS environments remain fragmented, limiting the ability to operationalize these capabilities at the customer experience layer. Data silos, batch-oriented processing, and loosely coupled workflows constrain real-time, cross-domain orchestration.
AI Across Commercial and Network Domains:
Cary identifies three primary domains of impact, increasingly converging with network intelligence:
-
Marketing: AI-driven personalization is evolving toward real-time, context-aware engagement informed by both customer behavior and network conditions (e.g., location, QoS state, congestion). This aligns with event-driven architectures and customer data platforms integrated with network analytics (e.g., NWDAF exposure via APIs). “Personalisation shifts from broad audiences to the individual,” she said, adding that relevance is now “a prerequisite for attention.”
-
Sales: AI enables next-best-action and dynamic offer generation, incorporating network-aware insights such as service availability, slice characteristics (in 5G SA), and fiber capacity constraints. Integration with policy control (3GPP TS 23.203) and service orchestration frameworks supports closed-loop order capture and fulfillment. “That combination of higher conversion and lower friction is valuable,” she said.
-
Service: AI-driven assurance is transitioning from reactive fault management to predictive and intent-based service assurance across both wireless and wireline domains. Telemetry from RAN, transport, and fixed access networks feeds AI models that anticipate degradation and trigger remediation before customer impact. “Human agents still play a central role,” Cary said, “but they can be augmented with real-time recommendations, contextual history and autonomous processes that improve both speed and consistency.”
Scaling Challenges in AI-Native Transformation:
Despite progress in AI models and domain-specific analytics, Cary highlights a systemic gap in operationalization.
“What it lacks, in many cases, is the ability to turn fragmented customer data into real-time decisions that can actually be executed across marketing, sales and service,” she said.
Analysys Mason data indicates that only 6% of operators achieve ROI above 25% from AI initiatives, while 60% advance just 20% of proofs of concept into production. This reflects challenges in integrating heterogeneous data sources across OSS, BSS, and network domains, as well as limitations in MLOps and real-time orchestration frameworks.
Fragmentation is compounded in converged networks, where wireless (3GPP-based) and wireline (e.g., Broadband Forum TR-369/USP, TR-383 for disaggregated BNG) ecosystems often evolve independently. Additionally, 93% of operators cite multi-vendor complexity as increasing total cost of ownership, underscoring the need for interoperable, standards-based integration across AI, network, and IT domains.
“That creates an unfortunate pattern across the industry,” she said, “promising AI initiatives that demonstrate value in isolation but fail to scale because they are not connected to the data, systems and processes where real work happens.”
Toward Fully AI-Native Operations:
Cary emphasizes that the target state is not incremental automation but fully AI-native operations, where intelligence is embedded into both network control loops and customer engagement workflows.
“This is why the future of customer experience in communications is not about layering AI onto the edge of the enterprise,” Cary said. “It is about making AI operational at the core of engagement.”
This vision aligns with emerging 6G research directions, where AI is treated as a native design primitive across RAN, core, and service layers, as well as with TM Forum’s Open Digital Architecture (ODA), which promotes composable, API-driven integration between OSS, BSS, and AI components.
Oracle’s approach reflects this convergence by unifying customer data, embedding AI into engagement and orchestration layers, and integrating these capabilities with telecom operational systems across both wireless and wireline domains.
Implementation Suggestions:
Cary said that network providers do not need to transform everything at once. She recommends starting by unifying customer data across touchpoints to establish a trusted, real-time view, before activating high-value AI use cases across marketing, sales and service. From there, providers can embed AI into workflows so insight translates into action rather than sitting in dashboards, eventually connecting those capabilities into end-to-end orchestration.
Indeed, Cary advocates a phased approach consistent with AI-native transformation:
-
Establish a unified, real-time data fabric spanning customer, service, and network domains.
-
Deploy high-value AI use cases (e.g., next-best-action, churn prediction, predictive assurance) leveraging both IT and network telemetry.
-
Embed AI into execution workflows to enable closed-loop, intent-driven orchestration across the customer lifecycle.
This progression reflects the broader industry trajectory toward converged, AI-native networks, where customer experience is no longer an overlay on connectivity, but a direct outcome of tightly coupled intelligence across wireless and wireline infrastructures.
“The communications providers that lead in the years ahead will not be the ones that simply adopt more AI tools. They will be the ones that use AI to rethink how customer engagement works across the enterprise. AI is not just enhancing customer experience,” she added. “It is redefining how customer experience is delivered, and in communications, that shift is likely to separate the providers that keep pace from the ones that set the pace.”
………………………………………………………………………………………………………………………………
Editorial Analysis:
Cary’s vision aligns with IMT 2030/6G’s shift from AI as an overlay to AI as an architectural primitive, spanning the air interface, semantic service handling, and distributed edge intelligence across wireless and wireline domains. The cleanest way to map her suggestions into 6G is to treat “autonomous customer experience” as the service-layer expression of an AI-native network stack: AI decisions would no longer sit only in OSS/BSS, but would be distributed across RAN, transport, core, and edge applications, with closed-loop control spanning wireless and wireline domains. That maps well to current AI-native 6G proposals that emphasize model interdependencies, distributed intelligence, and AI embedded directly in the architecture rather than layered on top.
For the AI native air interface, the link is to AI-assisted radio control, where the network uses learned models to optimize scheduling, mobility, beam management, and QoS-aware policy decisions in real time. In a 6G framing, that extends beyond today’s AI for RAN optimization and toward an AI-native air interface in which the radio stack itself is designed for machine-driven adaptation, including distributed control loops between UE, RAN, and core. For your article, this supports language that customer experience is increasingly shaped by network intelligence at the point of access, not just by back-office engagement systems.ieeexplore.ieee+2
Semantic communications maps to the idea that the network should optimize for meaning or task relevance, not simply bit delivery. In practice, that means a 6G service layer could prioritize the semantic value of an interaction—such as whether a customer is trying to resolve an outage, confirm a move order, or change a plan—and allocate resources accordingly across wireless and wireline paths. The relevance to Cary’s argument is that customer experience becomes more contextual and intent-aware when the network itself can distinguish between low-value traffic and high-importance service interactions.
Distributed intelligence at the network edge is the most direct bridge between CSP operations and 6G design. In a converged wireless-wireline environment, edge AI can fuse RAN telemetry, fixed access metrics, subscriber context, and service history to trigger local decisions such as proactive care, dynamic QoS adjustment, or preemptive fault mitigation. That makes the experience layer more autonomous because the decision point moves closer to where the event occurs, reducing dependence on centralized, slower, batch-oriented processing.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
References:
https://www.nokia.com/6g/unlocking-the-full-potential-of-ai-native-6g-through-standards/
Comparing AI Native mode in 6G (IMT 2030) vs AI Overlay/Add-On status in 5G (IMT 2020)
SHIELD-6G with AI-native cyber threat intelligence platform to enhance cybersecurity for Europe’s future 6G networks
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
Ericsson and Intel collaborate to accelerate AI-Native 6G; other AI-Native 6G advancements at MWC 2026
NVIDIA and global telecom leaders to build 6G on open and secure AI-native platforms + Linux Foundation launches OCUDU
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
Jio’s LEO satellite constellation authorized by IN-SPACe: 5 Tbps over India with 3GPP Rel 17 and 18 NTN Alignment
Executive Summary:
India’s space sector has taken another decisive step toward global competitiveness with the Indian National Space Promotion and Authorization Center (IN-SPACe) granting a key technical authorization to Reliance Jio for a proposed Low Earth Orbit (LEO) satellite constellation of approximately 1,600 satellites. The scale and ambition of the program place it firmly within the same category as leading non-terrestrial network (NTN) initiatives such as SpaceX’s Starlink, Amazon’s Project Kuiper, and Eutelsat OneWeb, while signaling India’s intent to build indigenous capability in space-based broadband infrastructure.
Constellation Scale and Architecture:
At ~1,600 satellites, Jio’s planned constellation is smaller than Starlink’s first-generation deployment (~4,400 satellites, with longer-term plans exceeding 10,000), but comparable to Amazon’s Project Kuiper (~3,236 satellites planned) and significantly larger than OneWeb’s first-generation system (648 satellites). This places Jio in an intermediate design space—large enough to deliver meaningful aggregate capacity and coverage, yet potentially more optimized for regional rather than fully global service.
The announced aggregate capacity of up to 5 Tbps suggests a high-throughput satellite (HTS) architecture leveraging aggressive frequency reuse and multi-spot beam designs. By comparison:
-
Starlink is estimated to already deliver tens of Tbps of global capacity, enabled by dense constellation scaling, advanced phased-array antennas, and increasingly, optical inter-satellite links (ISLs) [2.].
-
Kuiper targets multi-Tbps capacity with a strong emphasis on cloud integration via AWS, though it remains pre-commercial as of mid-2026.
-
OneWeb focuses more on enterprise, maritime, and government backhaul, with comparatively lower aggregate throughput but strong QoS guarantees.
Note 1. ISLs (Inter-Satellite Links) are direct communication connections between spacecraft in orbit, allowing them to route data to one another without first sending it down to an Earth station. This creates a dynamic space mesh network, which dramatically reduces data latency, increases coverage, and bypasses the need for costly ground gateways.
……………………………………………………………………………………………………………………………………………………………………………………………………….
A key technical question for Jio will be whether it incorporates optical ISLs in its initial deployment. Starlink’s Gen2 architecture relies heavily on ISLs for mesh networking and latency optimization, reducing dependence on ground gateway density. In contrast, OneWeb’s first-generation system lacks ISLs, relying instead on a dense ground station network. Jio’s architectural choice here will directly influence both latency performance and ground infrastructure cost.
)
Reliance Jio plans to deploy 1,600 LEO satellites to build a space-based communication network. AI-generated image via Business Standard.
…………………………………………………………………………………………………………………………………………………………..
Spectrum Strategy and Link Budget Considerations:
Although Jio has not publicly disclosed its frequency plan, it is likely to align with Ku- and Ka-band allocations, consistent with global LEO broadband systems. Starlink and Kuiper both rely heavily on Ka-band for feeder links and Ku/Ka for user links, while also exploring V-band (40–75 GHz) for future capacity scaling.
For India-specific deployment, spectrum coordination presents both an opportunity and a constraint. Domestic prioritization could streamline regulatory approvals, but coexistence with incumbent satellite operators and terrestrial 5G services will require careful interference management. This is particularly relevant as 3GPP NTN bands increasingly intersect with traditional satellite allocations.
From a link budget perspective, enabling both fixed broadband and direct-to-device (D2D) services within the same constellation introduces competing design requirements. High-throughput broadband favors higher frequencies and larger user terminals, while D2D requires lower link margins, robust coding, and potentially sub-GHz or S-band spectrum to reach handheld devices.
Direct-to-Device and 3GPP NTN Alignment:
Jio’s emphasis on direct-to-device (D2D) connectivity places it at the forefront of a critical industry transition: the integration of NTN into the 3GPP ecosystem. Releases 17 and 18 define the foundational architecture for NTN support, including adaptations for:
-
Large propagation delays and Doppler shifts in LEO systems
-
Modified random access and timing advance procedures
-
Satellite-aware mobility and handover mechanisms
-
Power-efficient waveform adaptations for handheld devices
Starlink has taken an early lead in this domain through its partnership with T-Mobile, leveraging mid-band PCS spectrum to enable D2D messaging services. AST SpaceMobile, while not a direct LEO broadband competitor, has demonstrated high-throughput D2D links using large phased-array satellites. Apple’s emergency SOS feature (via Globalstar) represents a narrower but commercially successful implementation of NTN for consumer devices.
Jio’s differentiation may lie in tighter vertical integration with its terrestrial network. Unlike Starlink, which operates largely as an overlay network, Jio can embed NTN capabilities directly into its 5G—and eventually 6G—core architecture. This opens the door to unified authentication, billing, and service continuity across terrestrial and satellite domains, consistent with the 3GPP vision of seamless TN–NTN convergence.
Latency, Backhaul, and 5G/6G Integration:
Operating in LEO, Jio’s system can achieve round-trip latencies on the order of 20–40 ms, comparable to Starlink and significantly lower than geostationary systems (>500 ms). With ISLs, latency for long-distance routes can even approach or outperform terrestrial fiber in certain scenarios, depending on routing efficiency.
For India, one of the most compelling use cases is satellite-based backhaul for rural and remote base stations. While fiber deployment remains uneven across the country, a LEO-based backhaul layer could enable rapid expansion of 5G coverage without the need for extensive terrestrial infrastructure. This aligns with ongoing 6G research, where integrated TN–NTN architectures are expected to support ubiquitous coverage and network resilience.
In comparison to Jio:
-
OneWeb has already established a strong position in cellular backhaul, including partnerships in emerging markets.
-
Starlink is increasingly targeting enterprise and mobility segments, including aviation and maritime.
-
Kuiper is expected to leverage AWS edge integration for enterprise and cloud-native applications.
Jio’s advantage lies in its domestic scale and control over both access and core network layers, enabling tighter optimization of end-to-end service delivery.
Manufacturing, Launch, and Economic Viability:
Deploying a 1,600-satellite constellation requires industrial-scale manufacturing and launch capabilities. SpaceX’s vertical integration—spanning satellite production and launch via Falcon 9 and Starship—has been a key enabler of Starlink’s rapid deployment. Amazon is pursuing a mixed launch strategy (ULA, Blue Origin, Arianespace), while OneWeb relied heavily on international launch providers.
Jio’s approach will likely depend on partnerships, potentially leveraging ISRO’s launch capabilities alongside commercial providers. However, achieving cost efficiency comparable to Starlink remains a significant challenge, particularly in satellite mass production and user terminal pricing.
User equipment (UE) economics will be especially critical for D2D services. While fixed terminals can subsidize higher costs, mass-market D2D requires integration into standard smartphones without significant cost premiums. This is an area where chipset ecosystem alignment—Qualcomm, MediaTek, and others—will play a निर्ण role.
Strategic and Geopolitical Implications:
Beyond technical considerations, Jio’s LEO initiative reflects broader geopolitical and industrial policy trends. India is positioning itself to reduce dependence on foreign satellite infrastructure while building domestic capability across the space value chain. This aligns with parallel efforts in semiconductor manufacturing, AI infrastructure, and 6G research.
At the same time, the global LEO market is becoming increasingly competitive and capacity-rich. The risk of oversupply, pricing pressure, and regulatory fragmentation is non-trivial. Jio’s success will depend not only on technical execution but also on its ability to carve out a differentiated market position—potentially focusing on South Asia, enterprise services, and tightly integrated telecom offerings.
…………………………………………………………………………………………………………………………………………………………………………………..
LEO Systems Serving India:
Key parameters of LEO constellations relevant to India’s satellite broadband market.
-
Rel‑15 / Rel‑16 – Baseline 5G NR (Terrestrial)
-
Label text: “TN‑only architecture; NR defined for terrestrial cells and standard mobility.”
-
-
Rel‑17 – Initial NTN Support
-
Label text: “Introduction of NR‑NTN for LEO/GEO satellites and HAPS; adaptations for delay, Doppler, and satellite link budget.”
-
-
Rel‑18 – 5G‑Advanced NTN Enhancements
-
Label text: “Improved NTN mobility, QoS, power efficiency; building blocks for direct‑to‑device scenarios and tighter TN–NTN integration.”
-
-
Beyond Rel‑18 / early 6G – Native TN–NTN Convergence
-
Label text: “Unified terrestrial–satellite architecture, AI‑assisted RAN control, ubiquitous coverage; NTN treated as a first‑class component of 6G systems.”
-
………………………………………………………………………………………………………………
References:
European Consortium 5G NTN transmission paves the way for standards based direct to device (D2D) connectivity
Non-Terrestrial Networks (NTN) Tutorial: Architecture, Spectrum, and Technical Foundations
Non-Terrestrial Networks (NTNs): market, specifications & standards in 3GPP and ITU-R
Ookla: Starlink a viable competitor for hybrid 5G/NTN services due to network performance improvements and larger coverage area
From LPWAN to Hybrid Networks: Satellite and NTN as Enablers of Enterprise IoT – Part 2
Telecoms.com’s survey: 5G NTNs to highlight service reliability and network redundancy
Keysight Technologies Demonstrates 3GPP Rel-19 NR-NTN Connectivity in Band n252
ITU-R recommendation IMT-2020-SAT.SPECS from ITU-R WP 5B to be based on 3GPP 5G NR-NTN and IoT-NTN (from Release 17 & 18)
India approves backhaul satellite connectivity via VSAT for telecom services; BharatNet tender coming soon
