

Agentic AI
TM Forum’s DTW Ignite 2026: Open Digital Architecture (ODA); Nokia, Ericsson, IBM and Mavenir AI announcements/cloud partnerships
-
- Shift to Action: TM Forum Vice President Aaron Boasman-Patel and CEO Nik Willetts opened the summit emphasizing that the industry must move past abstract C-suite visions.
- The AI Economy: The flagship keynote officially launched the “Race to 2030,” a direct directive tasking operators to secure their market relevance by deploying high-velocity, production-grade architectures.
-
- On-Stage AI Co-Hosts: In an industry event first, agentic AI systems took the stage alongside human moderators to act as live panel co-hosts, digital analysts, and experts.
- Summit Intelligence Layer: Advanced AI systems recorded and indexed every keynote, panel, and breakout session, functioning as a real-time intelligence layer to deliver daily trend summaries to attendees.
-
- Autonomous Networks (AN): Featuring the largest showcase of live autonomous operating systems to date. Major case studies from carriers like China Mobile, China Telecom, TDC NET, and Telefónica showcased functional solutions for self-optimizing networks, RAN energy efficiency, and fast fault resolution.
- Trustworthy AI and Data: Discussions zeroed in on scaling responsible AI, exploring Models-as-a-Service (MODaaS) frameworks, managing tokenomics, and reinforcing cyber resilience.
- Composable IT and Ecosystems: Demonstrations focused on scaling Open Digital Architecture (ODA) from boardroom design into functional, interoperable engineering realities.

Practical Engineering & Showcases:
- Catalyst Showcases: The exhibition floor hosted over 60 collaborative proof-of-concept Catalyst projects and Innovation Engine live demonstrations.
- New Interactive Hubs: The event debuted dedicated “Mission Garages” for hands-on engineering collaboration, along with a specialized Future Skills program to help tech teams adapt to AI-native workflows. [1]
- Major Tech Partnerships: Industry titans—including IBM, Ericsson, Cisco, and Nokia—used the floor to debut subsea infrastructures, physical AI, and cloud-native automation frameworks.
Note 1. DTW Ignite 2026 is TM Forum’s flagship global connectivity event focused on accelerating AI-native telcos, autonomous networks, and composable IT. The event is from June 23 to June 25 at the Bella Center in Copenhagen, Denmark.
……………………………………………………………………………………………………………………………………………………………….
At the show, the TM Forum and its member alliance of over 850 companies across 180 countries, announced a major structural evolution for the Open Digital Architecture (ODA), shifting it from a cloud-native IT modernization blueprint into an AI-native execution environment. The core focus of these updates is to establish standardized, executable reference frameworks that allow operators to move beyond fragmented AI pilots and build an autonomous enterprise. The primary ODA updates and structural expansions announced at the summit include:
-
- Governed Execution Layer: TM Forum members launched AI-native extensions to the ODA specification, adding a governed execution layer. This allows autonomous AI agents and large language models to run natively within the existing ODA component architecture and Open APIs.
- Project Foundation & AI Canvas: Through the Demo ONE Catalyst project, tech leaders debuted an updated AI-Native ODA Canvas. This cloud-native runtime environment orchestrates data, AI models, and autonomous agents across fragmented BSS, OSS, and network domains to replace rigid legacy systems.
- Model-as-a-Service (MODaaS): To solve the challenge of rising token costs and fragmented model selection, an ODA-aligned MODaaS framework was introduced. It establishes a unified control plane to govern, secure, and manage AI model usage across the carrier architecture.
-
- Space-Telco Interoperability: In a major scope expansion, TM Forum officially launched the ODA for Satellite project. Supported by 16 foundational partners—including Airbus, Terrestar, and Vodacom—the initiative targets multi-billion dollar direct-to-device and space-connectivity markets.
- Unified Non-Terrestrial Frameworks: The project extends standard ODA components to satellite technology providers, standardizing how terrestrial mobile networks and non-terrestrial networks (NTNs) handle cross-industry billing, service delivery, and zero-touch roaming integrations.
- Plug-and-Play Validation: TM Forum rolled out its newly expanded ODA Component Certification. This toolkit gives vendors a programmatic way to verify that their commercial software components are truly plug-and-play ready, lowering custom integration costs for telecom buyers.
- “Running on ODA” Milestones: The alliance celebrated that 18 global Communication Service Providers (CSPs), representing over two billion subscribers globally, have officially achieved “Running on ODA” accreditation—confirming that modular, componentized architecture has reached full scale in production environments.
……………………………………………………………………………………………….
Vendor Announcements:
- Amazon Web Services (AWS) Expansion: Nokia and AWS expanded their partnership to run Nokia’s Autonomous Networks Fabric natively on AWS. The integration brings operators closer to Level 4 network autonomy, enabling networks to orchestrate, analyze, and heal themselves at machine speed.
- Google Cloud Integration: Nokia deepened its alliance with Google Cloud to integrate Gemini models into the Nokia Assurance Center. They unveiled six specialized generative AI agents (including a Router Agent and Event Triage Agent) to automatically process data and isolate the root causes of service faults. It launches as a SaaS offering in September 2026.
- Databricks Proof of Concept: Nokia and Databricks announced the completion of a joint project showing a unified, cloud-agnostic data platform. This resolves a legacy pain point by unifying hundreds of fragmented operational silo data architectures so multi-agent AI can run seamlessly across networks.
- GenAI-Native Operations: Instead of relying on traditional rules-based code, Nokia’s new interfaces allow field engineers to query complex multi-vendor topologies, generate diagnostic code, and run natural-language root-cause analyses on real-time traffic faults.
- Autonomous Network Scaling: Nokia presented multi-party Catalyst project solutions targeting network optimization, zero-touch slicing, and automated enterprise edge deployments tailored for the 5G-Advanced landscape.
……………………………………………………………………………………………………………………………………………………….
- EIAP Core Expansion: The headline announcement from the Ericsson Cloud Software and Services division was the expansion of the Ericsson Intelligent Automation Platform (EIAP). Formerly restricted to RAN operations, the platform now fully integrates and unifies Radio Access Network (RAN) and core network automation systems.
- Introduction of cApps: Ericsson claimed a major industry first by rolling out core-specific automation applications (cApps). These decentralized apps allow operators to run automated routines directly on core architectures, streamlining cross-domain workflows to cut operations costs.
- Business Value Pathways: Ericsson debuted a structured strategic blueprint designed to guide Communication Service Providers (CSPs) through the financial steps of scaling from Level 3 to Level 4 autonomous networks.
…………………………………………………………………………………………………………………………………………………….
- Addressing the “AI Trust Gap”: Responding to a TM Forum study revealing that only 14% of operators can prove their AI systems are fully reliable, IBM presented framework tools at DTW Ignite to address security and model bias.
- B2B2X Monetization: IBM focused its platform showcase on orchestrating automated workflows for multi-enterprise B2B2X networks, enabling secure data federation across third-party hyperscalers and edge servers.
……………………………………………………………………………………………………………………………………………………
- Telco-First Cloud Architecture: Stationed at Booth 334, Mavenir debuted its updated AI-by-design, cloud-native software portfolios built natively around TM Forum’s Open Digital Architecture (ODA) frameworks.
- Closed-Loop Automation: Mavenir demonstrated actionable frameworks that handle real-time resource adjustments, shifting power and processing capacity across base stations based on AI-predicted user demand cycles.
……………………………………………………………………………………………………………………………………………………
References:
https://www.tmforum.org/events/dtw/experience-dtw/new-for-2026
Inside TM Forum’s Catalyst project “Living Networks – Phase III”
Deloitte and TM Forum : How AI could revitalize the ailing telecom industry?
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
GSMA, ETSI, IEEE, ITU & TM Forum: AI Telco Troubleshooting Challenge + TelecomGPT: a dedicated LLM for telecom applications
SHIELD-6G with AI-native cyber threat intelligence platform to enhance cybersecurity for Europe’s future 6G networks
Verizon’s 6G Innovation Forum joins a crowded list of 6G efforts that may conflict with 3GPP and ITU-R IMT-2030 work
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
AI-RAN and Agentic AI get real: Ericsson, Nokia, Verizon & other operators enter into a new network automation era
Disclaimer: Perplexity.ai was used for research in this article.
Executive Summary:
A cluster of announcements in early-to-mid June 2026 signals a real shift from AI research to commercial AI-driven network automation. Telcos are transitioning from isolated AI pilots to production-grade AI operations deployed across live networks.
-
Ericsson launched its AI in RAN commercial software subscription on June 11th, claiming up to 20% higher downlink throughput and up to 10% better spectral efficiency across more than 15 live deployments using existing baseband silicon.
-
Nokia and Indosat Ooredoo Hutchison (Indonesia) announced a GPU-accelerated AI-RAN partnership in Indonesia on June 8, expanding the Nokia–NVIDIA architecture already adopted by T-Mobile US, SoftBank, and Vodafone.
-
Verizon disclosed that its 60,000-site vRAN is now applying agentic AI to planned configuration changes, service assurance, and network optimization, while publicly calling for industry-wide interoperability standards for agentic systems.
-
Nokia launched an agentic AI framework for IP network operations within its Network Services Platform (NSP), marking its third agentic product announcement in a four-week period.
A growing number of network operators are transitioning from traditional connectivity providers into AI infrastructure operators. SK Telecom (South Korea) announced a gigawatt-scale AI Cloud built on NVIDIA DGX SuperPOD architecture; Deutsche Telekom (Germany) secured the German federal government’s sovereign AI cloud contract; and MTN Group (South Africa) detailed a plan to convert 18,000 African tower locations into a distributed AI inference grid.
Over a six-week window, six major network operators—SK Telecom, Deutsche Telekom, MTN Group, Verizon, SoftBank, and Indosat Ooredoo Hutchison—have converged on a single strategic premise: existing telecommunications infrastructure, including connectivity, physical real estate, and data center capacity, constitutes the foundational footprint for a commercial AI compute business.

………………………………………………………………………………………………………………………………………………………………………………………………
Government’s Buys Into AI Compute:
Government involvement in AI compute is intensifying, with direct implications for telecom strategy. China’s $295 billion program defines the upper bound of state-backed AI compute investment. Beijing announced plans to invest 2 trillion yuan ($295 billion) over five years in AI datacenter infrastructure. China Mobile and China Telecom are designated as the primary operators of a national AI compute network, while Huawei will supply the majority of AI chips—explicitly bypassing NVIDIA. The plan accelerates China’s original 2030 national computing network target to 2028, funded through sovereign debt.
- China’s National Data Administration reported 140 trillion daily AI token flows by March 2026—up 1,400-fold from the start of 2024. China Mobile, China Telecom, and China Unicom launched commercial AI token packages in May, with per-token costs that centralized operations can reduce by approximately 30 percent. China Mobile separately unveiled AI-eSIM, which embeds an autonomous decision layer directly into the SIM.
- Chinese network operators are advancing through the full AI lifecycle—token economy, infrastructure mandate, and sovereign chip supply—at a pace and scale unmatched by any other single market.
Technical Implications for Network Architecture:
The convergence of AI-RAN, agentic AI, and AI infrastructure provision demands architectural evolution across several dimensions:
Standards and Interoperability Gap:
Verizon’s public call for industry-wide interoperability standards for agentic systems highlights a critical bottleneck. Agentic AI frameworks from Ericsson, Nokia, and other vendors must interoperate across multi-vendor networks, yet no standardized protocol exists for agentic command, control, and assurance. This gap mirrors the early RAN interoperability challenges that Open RAN later addressed.
The TM Forum’s Autonomous Networks L4/5 roadmap and the 3GPP 6G standardization process will need to incorporate agentic AI interoperability as a core requirement. Without standards, telcos risk vendor lock-in for AI automation capabilities, undermining the multi-vendor flexibility that has been a telco industry priority for decades.
What This Means for 5G and 6G Roadmaps:
AI-driven automation is becoming a prerequisite for 6G L4/5 autonomous networks. The June 2026 announcements suggest that:
-
5G Advanced deployments will increasingly incorporate AI-RAN as a standard feature, not an optional enhancement.
-
6G specifications (expected by end-2028 per Ericsson) will likely embed agentic AI and autonomous decision layers as core architectural elements.
-
Network economics will shift from bandwidth-centric to compute-centric revenue models, with AI token services and inference grids becoming significant revenue streams.
For network architects, the implication is clear: AI infrastructure must be designed as a first-order network capability, not a second-order application layer. GPU acceleration, agentic orchestration, and token-economy support need to be part of the baseline network architecture from the outset.
Conclusions — The Automation Tipping Point:
June 2026 marks a tipping point where AI-driven network automation transitions from pilot to production. The combination of commercial AI-RAN subscriptions, agentic AI deployments at tens-of-thousands-of-site scale, and telco-led AI infrastructure provision signals that AI is no longer an experimental capability but a core network function.
The critical question for telcos is not whether to adopt AI automation, but how to avoid vendor lock-in while achieving the interoperability required for multi-vendor, multi-domain autonomous networks. Standards bodies, operator consortia, and vendor alliances must address this gap before agentic AI becomes a strategic constraint rather than a competitive advantage.
………………………………………………………………………………………………………………………………………………………………………………………………
References:
https://mtnconsulting.substack.com/p/the-unmanned-network-17-june-2026
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
Cisco Execs: New “Network Supercycle” as Agentic AI Workloads Reshape Telecom Infrastructure
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
Ericsson’s June 2026 Mobility Report Highlights + AI impact on network traffic
Ericsson launches AI in RAN as commercial software subscription:
Ericsson goes with custom silicon (rather than Nvidia GPUs) for AI RAN
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
RAN Silicon Rethink- Part II; vRAN and General-Purpose Compute
Analysis: Nvidia’s rumored new 6G AI-RAN – likely features/functions and industry impact
Analysis: Nvidia’s $2 billion investment in Marvell; NVLink Fusion ecosystem & RAN vendor silicon strategy
Dell’Oro: AI RAN to account for 1/3 of RAN market by 2029; AI RAN Alliance membership increases but few telcos have joined
Cisco report: Agentic AI to reshape WAN traffic, AI inference will be ~25% of total traffic by 2035
Executive Summary:
Consumer-driven AI traffic [1.] currently represents a marginal share of aggregate Internet traffic. However, accelerating adoption of agentic AI is expected to materially reshape traffic composition over the next decade. In its “AI Impact on Wide Area Networks” report, Cisco projects that AI will emerge as the dominant driver of network traffic growth. As consumer AI adoption approaches “near-universal usage,” AI and agentic AI are forecast to increase consumer-driven network traffic by approximately 6.6× by the mid-2030s (see chart below).
Cisco estimates that this AI expansion will account for roughly 63% of incremental traffic growth relative to non-AI scenarios. The study focuses specifically on WAN implications, rather than data center or GPU infrastructure, and provides guidance on network design and capacity planning. Methodologically, the report integrates real-world traffic observations (via Cisco Crosswork Assurance User Experience), third-party industry datasets, and controlled laboratory evaluations of AI agents to characterize how AI-generated traffic diverges from conventional web traffic patterns.
Token-consumption data shows nearly 10x year-over-year growth, while in some service provider measurements Cisco is seeing ~4x growth in just eight months. Sustained growth at these rates means AI traffic will become a meaningful component of overall network traffic by 2035.
Note 1. Consumer AI traffic has a few defining technical traits: it is still dominated by short text-based exchanges, but it is becoming more stateful, more upstream-heavy, and more latency-sensitive as users move from simple prompts to agentic workflows and multimodal interactions. Today’s consumer AI traffic is still overwhelmingly text-oriented, which is one reason the aggregate bandwidth impact remains modest despite rapid adoption. Comcast’s network observation is a useful real-world proxy: 97.1% of AI traffic was text-based, while images accounted for 2.6% and video only 0.3%. The key technical implication is that current traffic volumes are often limited more by conversation frequency and session behavior than by very large payloads, though that changes quickly as users adopt image, audio, and video generation.
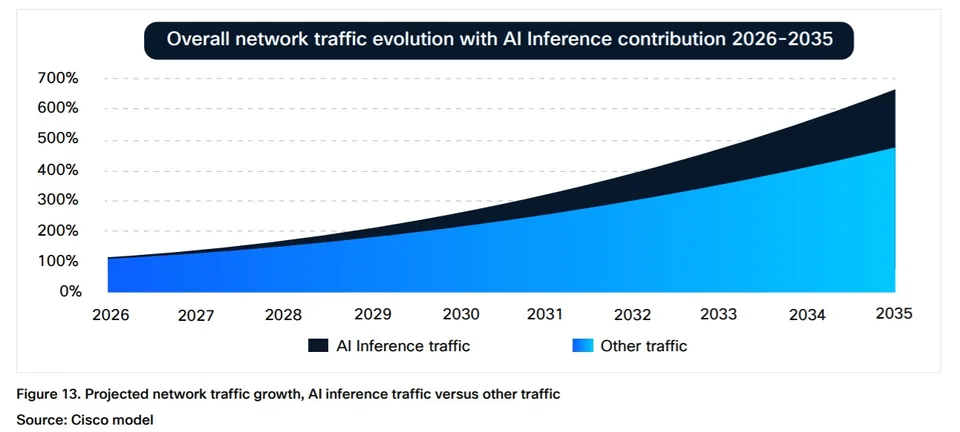
Although AI inference traffic is currently “negligible” relative to dominant categories such as video streaming, Cisco projects it will comprise approximately 25% of total network traffic by 2035 (see chart below). At that point, AI traffic is expected to represent a “meaningful component” of overall network load. Importantly, AI-generated traffic exhibits distinct characteristics: inference flows are approximately twice the duration of typical web transactions, demonstrate higher upstream bandwidth demand, and operate at “software speed” rather than human interaction rates.
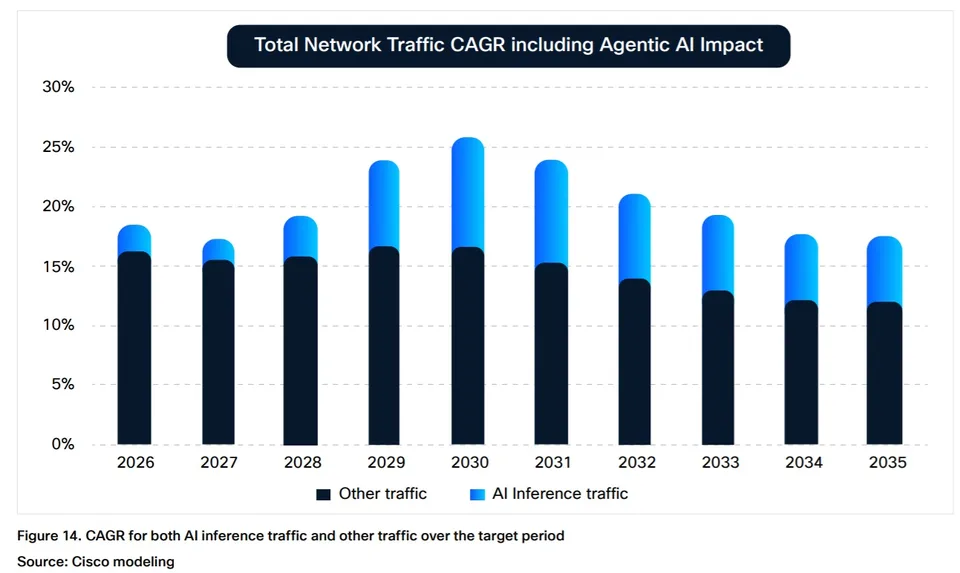
The emergence of AI agents as “power users” further amplifies these dynamics. Cisco notes that agent-executed tasks can generate up to 450% more traffic per task compared to human-driven interactions. This shift is expected to drive operator adoption of “flow-aware network and security systems” as traffic patterns become increasingly machine-driven and less predictable.
Cisco’s broader framing is that AI traffic “isn’t just adding traffic,” but is changing the shape of traffic, with inference flows running about twice as long as typical web transactions and, in some cases, generating up to 450% more traffic per task when an agent executes the workload. AI inference sessions tend to hold resources longer, create more sustained flows, and push operators to think in terms of flow-aware behavior rather than only peak-throughput sizing. Cisco also notes that about 9% of AI inference flows carry more upstream than downstream traffic, versus about 0.5% for typical web traffic, which is a meaningful shift for access and broadband networks. Cisco reports that approximately 9% of AI inference flows are upstream-dominant, compared to roughly 0.5% for traditional web traffic, with this divergence expected to widen alongside increased agentic AI utilization. In parallel, latency sensitivity is anticipated to become a more critical performance parameter for AI-driven applications.
Latency and symmetry:
AI traffic is also more sensitive to latency than many ordinary consumer web transactions because the user experience is often conversational and interactive, with the expectation of near-immediate turn-taking. Cisco describes AI inference as operating at “software speed” rather than human speed, which means small delays can be more noticeable and operationally important. At the same time, upstream demand becomes more significant because prompts, context, attachments, and agent-generated actions can increase return-path traffic, especially as multimodal inputs and agentic tool use expand.
Multimodal growth:
The biggest step-up in technical impact comes when consumer AI shifts from text-only prompting to multimodal generation and agent-driven workflows. In those cases, each task can involve multiple model calls, retrieval steps, tool invocations, and richer media payloads, which expands both flow count and bytes per session. Cisco’s study suggests that this is why AI traffic will increasingly require “flow-aware network and security systems,” because the traffic profile is not just larger, but structurally different from conventional browsing.

Infrastructure Implications:
Telecom infrastructure is becoming “increasingly intertwined with hyperscale infrastructure, not because operators are leading AI investment, but because they are becoming part of the ecosystem that supports it,” analyst firm MTN Consulting said in an April 27th research note. “Demand for optical transport, data-center interconnect, and edge infrastructure is rising as telecom networks carry growing volumes of cloud and AI-driven traffic,” the firm said.
“AI network traffic is already reshaping infrastructure needs. What we are seeing is clear: AI isn’t just adding traffic. It’s changing the shape of traffic,” Javier Antich, principal product management engineer in the CTO office of Cisco’s provider connectivity group, and Gurudatt Shenoy, SVP, product management, provider connectivity, explained in this blog post.
These shifts are beginning to influence access network evolution. Fiber networks already provide relatively symmetric throughput and low latency, while cable operators are advancing similar capabilities through DOCSIS upgrades. Mid-split and high-split architectures increase upstream spectrum allocation, enabling more balanced capacity profiles. Concurrently, Tier 1 operators such as Comcast and Charter Communications are introducing low-latency enhancements within DOCSIS networks.
Operational data reflects early-stage impacts. Comcast Chief Network Officer Elad Nafshi noted at the Cable Next-Gen event in March that approximately 97.1% of AI traffic on Comcast’s network remains text-based, with images accounting for 2.6% and video just 0.3%, indicating that bandwidth-intensive multimodal AI traffic has yet to scale materially.
Network design impact:
For broadband and access networks, the immediate engineering issues are upstream traffic capacity, queue behavior, and latency consistency rather than raw total throughput alone. Symmetry upgrades (such as DOCSIS mid-split and high-split for MSOs), along with low-latency capabilities, are relevant because consumer AI creates more return-path pressure and more time-sensitive sessions. In other words, the challenge is not simply to carry more bytes; it is to carry more interactive sessions with predictable performance, especially as multimodal and agentic usage scales.
………………………………………………………………………………………………………………………………………………………………………………………………………….
References:
Will the wave of AI generated user-to/from-network traffic increase spectacularly as Cisco and Nokia predict?
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Cisco CEO sees great potential in AI data center connectivity, silicon, optics, and optical systems
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
Telecom data centers must be redesigned for the AI era with rack scale architectures, enhanced power & cooling requirements
Is the “far edge” a bridge to far to cross for AI inferencing? What about “Distributed AI Grids”?
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Intel and AI chip startup SambaNova partner; SN50 AI inferencing chip max speed said to be 5X faster than competitive AI chips
CES 2025: Intel announces edge compute processors with AI inferencing capabilities
Inside Nokia’s new AI Networking Innovation Lab
- Silicon & Compute: Collaborating with AMD to optimize enterprise AI workloads alongside Nokia data center switches.
- Testing & Infrastructure: Partnering with Keysight Technologies to emulate workloads across Ultra Ethernet Consortium (UEC) and RoCEv2 transports.
- Hardware & Servers: Integrating high-performance platforms from Lenovo and Supermicro.
- Data Storage & Cloud: Working with Weka and cloud builders like Nscale to eliminate storage bottlenecks during heavy computational training.

Nokia’s AI Networking Innovation Lab is built upon three fundamental pillars: Technology Innovation, Ecosystem Collaboration, and Validation. Image credit: Nokia
………………………………………………………………………………………………………………….
Technology Innovation: The lab provides a dedicated space for AI partners to experiment with next-gen solutions across the entire networking stack – driving emerging standards forward with pioneering approaches to new protocols, switching silicon, congestion control, real-time telemetry, and automation.
“Partnering with Nokia in the AI Networking Innovation Lab has enabled us to benchmark and optimize AI networks under real-world conditions…Together, we are helping accelerate AI network adoption by giving operators and hyperscalers the validated insights needed for confident, large-scale deployment.”
Ecosystem Collaboration: True progress depends on a strong ecosystem of technology providers – silicon manufacturers, GPU developers, system, storage and test vendors, and cloud platforms – that work together to create highly-compatible AI-ready solutions. This facilitates joint testing for interoperability, improves integration, and ensures roadmaps are aligned across different hardware, software, and orchestration layers.
Travis Karr, Corporate Vice President, HPC and Sovereign AI at AMD believes customer collaboration and an open ecosystem are fundamental to accelerating AI innovation:
“By co-developing solutions with partners, such as Nokia in their AI networking innovation lab, we ensure our AMD enterprise AI solutions are tested with Nokia data center switches on real-world workloads and network demands. An open, standards-driven approach empowers customers to integrate seamlessly across heterogeneous environments, avoiding lock-in and fostering industry-wide advancement in AI.”
Validation: This positions the lab as the testing ground for Nokia Validated Designs, where customers and partners rigorously validate multi-vendor data center architectures under authentic AI training and inference workloads. By testing failure scenarios, congestion behavior, and operational automation, the lab turns NVDs into proven, deployable solutions — enabling predictable performance, faster deployment, and reduced operational complexity and risk for organizations navigating the AI era.
Arno van Huyssteen, Vice President of Global Telecommunications for Nscale:
“Nokia is a strategic networking partner for Nscale as we build towards AI Grid, and the engineering rigour behind their Validated Designs reflects the kind of innovation needed to enable next-generation AI infrastructure. The depth of hardware, software and failure testing behind those blueprints is what will give operators the confidence to deploy complex AI environments faster, with fewer integration risks and less operational disruption. We’re excited to collaborate in the AI Networking Innovation Lab to help push the boundaries of AI-native networking and validate the next generation of solutions before they reach production.”
A primary focal point inside the lab is managing data center congestion. Unlike traditional cloud traffic, back-end AI networks feature high-density data synchronization across massive GPU clusters. The lab uses advanced automation, AIOps, and lossless Ethernet solutions—such as the Nokia 7220 IXR-H6 switches—to handle these intense uplink and synchronization demands safely.
The AI Networking Innovation Lab supports Nokia’s broader strategy to accelerate the next era of AI-driven connectivity. As demand for AI infrastructure continues to grow, data center networking has become one of the most critical foundations of the global AI ecosystem. Through this investment, Nokia is strengthening its capabilities in AI and cloud infrastructure while advancing its vision of AI-native networking.
Rudy Hoebeke, Vice President of Software Product Management at Nokia:
“The launch of Nokia’s AI Networking Innovation Lab marks a major milestone in our commitment to drive the next era of AI-native connectivity. As the industry continues to evolve with solutions like scale-across and AI-Grid, this lab is poised to accelerate AI networking technology that will not only support but optimize these emerging industry offerings. This center gives our customers and partners early access to new technologies, deeper collaboration with the world’s leading AI ecosystem players, and the confidence that their networks are validated under more realistic AI conditions. By accelerating innovation and reducing deployment risks, we’re enabling the industry to deliver faster, more reliable, and more sustainable AI experiences to people and businesses everywhere.”
………………………………………………………………………………………………………………………
References:
Analysis: Nokia’s strong growth in Optical Networks and AI network infrastructure
Orange, Nokia, Nvidia, and Intel debate: ASICs vs. GPUs vs. General-Purpose CPUs for RAN Baseband Processing
Nokia’s AI Applications Study: “Physical AI” may require RAN redesign to support high‑volume, low‑latency uplink traffic
Australia’s NBN and Nokia demonstrate multi-generation optical technologies concurrently over existing FTTP infrastructure
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
Tampnet to expand 5G offshore connectivity in the Gulf of Mexico using Nokia AirScale 5G radios
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
By Shazia Hasnie, Ph.D, editorial review by IEEE Techblog team member Sridhar Talari Rajagopal
Abstract:
The adoption of AI agents in network operations has exposed a critical architectural gap. Most enterprise data pipelines were designed for dashboards and reporting, not autonomous decision-making. When AI agents consume data from batch-oriented pipelines, five distinct failure modes emerge: stale data, memory gaps, delete blindness, schema fragility, and coordination failure. This article examines each failure mode, explains the underlying mechanism, and proposes architectural remedies grounded in streaming-first design principles. It also connects each technical failure to measurable business outcomes—extended downtime, recurring incidents, compliance exposure, silent decision degradation, and cascading impact. The result is both a diagnostic framework for I&O leaders and a financial argument for treating streaming data infrastructure as the prerequisite for autonomous operations.
Introduction: The Data Foundation Gap
Artificial intelligence is reshaping network operations. AI agents promise to detect anomalies, diagnose root causes, and execute remediation faster than human engineers. The industry has focused attention on models, GPUs, and orchestration frameworks. The data layer remains largely unexamined.
This is a critical oversight. Most enterprise data pipelines were built for human consumers. They serve dashboards, weekly reports, and historical analysis. Humans tolerate latency. Humans bring context. Humans notice when something looks wrong.
AI agents require something fundamentally different. They need real-time context. They need historical state. They need accurate representations of current reality. When these requirements are not met, agents do not complain. They act—on incomplete information, with incorrect assumptions, producing wrong outcomes.
The gap between what batch pipelines deliver and what agents require creates failure modes that most teams do not see until an agent makes the wrong decision. Recent analysis has identified the economic dimensions of this gap [1], while industry resources have begun documenting the specific failure patterns that arise when batch processing meets autonomous agents [6]. This article extends that work by identifying five distinct failure modes and proposing a streaming-first architectural response.
FIVE FAILURE MODES: ANATOMY OF BATCH-TO-AGENT MISMATCH
The following five failure modes represent the specific ways batch data pipelines undermine autonomous network operations. Each is examined through its mechanism—how the batch pipeline architecture produces the failure—its operational consequence, and the streaming-first architectural remedy that eliminates it. Together, they form a diagnostic taxonomy for any I&O team evaluating whether their data foundation is ready for Agentic AI.
Failure Mode 1: Stale Data
Mechanism: Batch telemetry pipelines poll, collect, and process data in cycles. Data is extracted on a schedule, transformed in bulk, and loaded into a destination—a warehouse, data lake, time-series database, or feature store that holds a static, point-in-time snapshot of the source. Between cycles, the pipeline holds no current state. An AI agent that spins up between cycles receives a snapshot of the past.
Consequence: The agent diagnoses an outage using telemetry from five minutes ago. The network state has changed during that interval. Routes have shifted. Traffic has been redirected. Thus, the agent’s diagnosis is based on a reality that no longer exists. Remediation actions applied to a past state can worsen the current incident. The agent becomes a liability rather than an asset. Industry documentation confirms that AI agents require continuous data freshness to function correctly [5].
Architectural Remedy: Streaming telemetry replaces cyclical polling with continuous event push. Data flows from source to consumer in real time, ingested directly into the streaming platform’s durable event log [2]. The agent consumes from a live stream, not a stale snapshot. Context acquisition takes milliseconds. The cognitive loop remains intact. This is not an add-on to the batch pipeline. It is a structural replacement of the ingestion layer.
Failure Mode 2: Memory Gap
Mechanism: Batch pipelines deliver windows of data—the last hour, the last day, the last processing cycle. They do not preserve the sequence of events that led to the current moment. Historical context is stripped away with each new extract. The pipeline knows what happened. It does not know what happened before.
Consequence: An agent responding to an interface flap cannot answer the most basic diagnostic question: has this happened before? It cannot correlate the current event with the three similar events that occurred in the preceding 24 hours. It cannot detect the pattern that would reveal a degrading optical module. Every incident appears isolated. Pattern recognition—the core value proposition of AI-driven operations—is structurally impossible. The distinction between streaming and batch architectures for these use cases has been well-documented [4].
Architectural Remedy: A durable event log with configurable retention serves as the agent’s memory [2]. Unlike a batch window, which discards history with each new extract, the event log preserves the ordered sequence of all events within the retention period. The agent seeks backward in the log on startup and replays the preceding window of telemetry. Pattern detection across time becomes native to the architecture. This is not a separate cache layered on top. It is the storage layer itself—immutable, ordered, and built for event replay from any offset.
Failure Mode 3: Delete Blindness
Mechanism: Batch pipeline’s Extract, Transform, Load (ETL) processes compare snapshots of source data. They do not watch the database transaction log. They identify what exists at two points in time and process the difference. When a record is deleted from the source system, the pipeline has no way of distinguishing between a row that was deleted and a row that was simply omitted due to extraction error, filtering logic, or schema mismatch. The absence of a row is not an event. It is a gap. Batch pipelines are not designed to interpret gaps as meaningful signals. The record simply vanishes from the next extract. The downstream consumer—an AI agent or any other system—has no way of knowing the record ever existed.
Consequence: The agent queries the downstream data store and finds no record for a deactivated account, a revoked certificate, or a cancelled change order. It cannot distinguish between “never existed” and “was deleted,” so it treats the absence as neutral.
The agent makes decisions on ghosts—data that no longer exists in source systems. In access control scenarios, this is not an operational error. It is a security incident. This specific failure mode has been identified in analyses of batch processing limitations for AI agents [6].
Architectural Remedy: Change data capture (CDC), implemented through Kafka Connect with Debezium connectors, reads the database transaction log directly [2], [8]. Debezium provides CDC source connectors for MySQL, PostgreSQL, MongoDB, SQL Server, and other databases — capturing inserts, updates, and deletes as discrete events with explicit operation types by tailing the database’s native transaction log. Nothing is invisible to the pipeline. The streaming architecture knows not only what exists but what ceased to exist. This is not an ETL workaround with soft-delete flags. It is a structural capability of the integration layer, converting database changes into first-class events the moment they occur.
Failure Mode 4: Schema Fragility
Mechanism: Source database schemas change over time. Columns are renamed, added, deprecated, or re-typed. Batch pipelines are configured for a specific schema at extraction time. When the source schema changes, the pipeline responds in one of two ways. It fails silently and drops the affected field from every subsequent extract. Or it fails loudly and stops processing entirely.
Silent failure is the more dangerous outcome. The pipeline continues delivering data. The consumer has no indication that a critical field is missing.
Consequence: The agent continues operating without a critical data input. It makes decisions with incomplete information. It has no awareness that its reasoning is compromised. The wrong decisions accumulate. By the time the missing field is discovered—often through an operational failure rather than a monitoring alert—the cost of remediation includes auditing and correcting every decision made during the degradation window.
Architectural Remedy: A schema registry with compatibility enforcement validates schema changes before they propagate to downstream consumers [2]. Streaming platforms can enforce backward and forward compatibility rules at the producer level. A breaking schema change is rejected before any data is published. The pipeline fails loudly and immediately. This is not a documentation standard or a code review checklist. It is a structural governance layer embedded in the streaming architecture itself, preventing silent field loss at the point of ingestion.
Failure Mode 5: Coordination Failure
Mechanism: When multiple AI agents operate on batch-derived data, each agent consumes a separate, potentially inconsistent snapshot. Agent A receives data from the 10:00 AM extract. Agent B receives data from the 10:15 AM extract. The extracts differ. Each agent holds a different version of reality. There is no shared, ordered log of events that all agents consume.
Consequence: Two agents respond to the same cascading failure. Agent A identifies a BGP routing issue and begins rerouting traffic. Agent B identifies a DNS resolution failure and begins modifying name server configurations. Neither agent knows the other acted. The redundant changes compete. The conflicting configurations create new instability. The original incident expands rather than resolves. What began as a single point of failure becomes a cascade that erodes trust in autonomous operations.
Architectural Remedy: A shared, ordered event log serves as a single source of truth for all agents in the system. Every agent consumes from the same log. Actions taken by one agent are published back to the log as events, immediately visible to all others [7]. Coordination becomes native to the architecture.
Visibility alone, however, does not prevent conflicting actions. Two agents may observe the same anomaly and both initiate remediation before either’s action becomes visible on the log. In practice, this is addressed through complementary mechanisms layered on the same event-driven model: action intent events that signal an agent is about to act, giving others a window to defer; idempotency keys that prevent duplicate remediation from causing harm; and lightweight leases for resources that should only be modified by one agent at a time. These mechanisms do not require a central coordinator. They are published to the same log, consumed by the same agents, and enforced through the same ordered stream.
This is not a separate orchestration layer or message bus bolted onto the side. It is the core of the streaming platform—a unified, ordered, multi-consumer event stream that provides both the shared state and the coordination primitives that eliminate the inconsistent snapshots batch architectures produce by default.
Batch-to-Streaming Reference Architecture — Five Failure Modes and Their Architectural Remedies
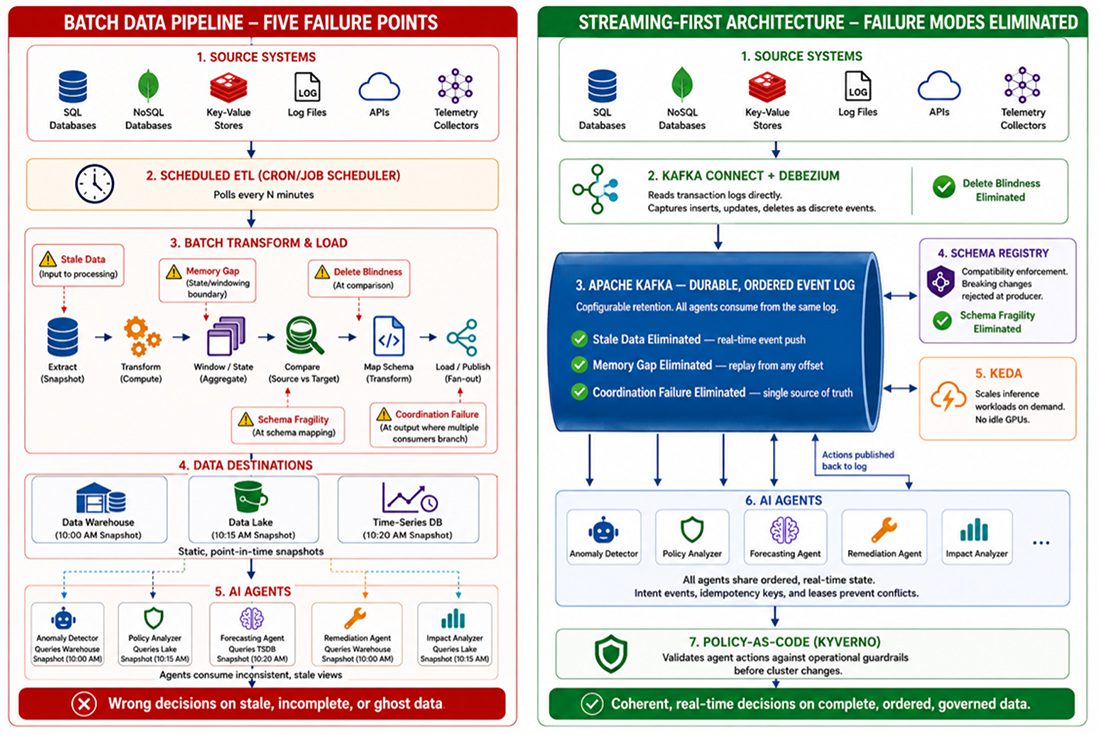
THE UNIFIED DIAGNOSTIC FRAMEWORK
The five failure modes translate into a practical audit that I&O leaders can apply to their own infrastructure. Each question corresponds to a specific architectural requirement.
The Five-Question Audit
- Can the data pipeline deliver real-time context to an agent the moment it wakes up? If not, the system is vulnerable to stale data failures.
- Can the agent access the preceding window of telemetry to detect patterns across events? If not, the system is vulnerable to memory gap failures.
- Does the pipeline capture deletes as explicit events with operation types? If not, the system is vulnerable to delete blindness.
- Does the pipeline detect schema changes before they propagate to downstream consumers? If not, the system is vulnerable to schema fragility.
- Do all agents share a single, ordered view of events with visibility into each other’s actions? If not, the system is vulnerable to coordination failure.
A negative answer to any one of these questions signals a data foundation that is not ready for autonomous operations. The model is not the bottleneck. The GPUs are not the bottleneck. The telemetry pipeline is.
THE MIGRATION PATH: FROM BATCH TO STREAMING-FIRST
Adopting a streaming-first architecture does not require abandoning existing batch investments overnight. For most organizations, the transition follows a coexistence model: streaming pipelines are introduced alongside batch pipelines, not as an immediate replacement.
The practical starting point is to identify the highest-value agent—the one whose decisions carry the greatest operational or financial consequence—and convert its data pipeline first. This agent is typically the one where stale data, memory gaps, or coordination failures have produced measurable incidents. Converting this single pipeline to streaming telemetry with a durable event log delivers a targeted operational improvement while the rest of the batch estate continues to function.
From there, adoption expands incrementally. Each additional agent is migrated as operational experience with the streaming platform grows. Teams develop competence in offset management, schema governance through the registry, and backpressure handling while batch pipelines continue to serve lower-priority consumers. The streaming and batch estates coexist for a transition period measured in months, not days.
This incremental approach also reveals where streaming delivers the greatest marginal benefit. Not every data flow requires real-time treatment. Dashboards fed by hourly batch extracts may serve their purpose indefinitely. The streaming investment should be directed at the pipelines that feed autonomous agents—the flows where the five failure modes carry real operational consequence. The goal is not to stream everything. It is to stream the right things first.
THE BUSINESS IMPACT: FROM TECHNICAL FAILURE TO FINANCIAL CONSEQUENCE
Technical failures in the data pipeline do not remain technical. They cascade into business outcomes that appear on budget reviews, SLA reports, and board presentations. Each failure mode carries a distinct financial consequence.
Stale Data → Extended Downtime
An agent diagnosing from stale telemetry makes incorrect decisions. Remediation applied to a past state can worsen the current incident. Mean Time to Resolution increases. For revenue-generating services, every minute of extended downtime translates to lost revenue and SLA penalty accrual.
Consider an illustrative model: a Tier-1 service provider processing $50M in customer transactions per hour, 5-minute stale-data induced misdiagnosis that extends an outage by 15 minutes represents $12.5M in direct revenue loss—not counting SLA penalties, regulatory scrutiny, or reputational harm. The cost of a single such incident can exceed the annual investment in the streaming infrastructure that would have prevented it. If even a portion of such incidents are eliminated by replacing the batch pipeline feeding the diagnostic agent with a streaming backbone, the infrastructure investment is recovered in a single avoided outage.
Memory Gap → Recurring Incidents
An agent without historical context cannot recognize chronic conditions. A flapping interface, a memory leak, or a degrading optical module triggers the same alert repeatedly. Each occurrence consumes GPU inference cycles. Each occurrence generates a ticket. Each occurrence may require human escalation. The cumulative cost of a single undiagnosed chronic issue, multiplied across an enterprise network over a year, represents operational expenditure that a stateful agent could eliminate.
Delete Blindness → Compliance and Security Exposure
An agent acting on deleted records makes authorization decisions based on invalid state. A deactivated account granted access. A revoked certificate treated as valid. In regulated industries, these errors are compliance violations with defined financial penalties and reporting obligations. The cost of a single access control error caused by ghost data can exceed the annual cost of the streaming infrastructure that would have prevented it.
Schema Fragility → Silent Decision Degradation
When a batch pipeline drops a critical field, the agent does not fail loudly. It continues operating with incomplete inputs. Decisions degrade silently. The cost includes not only the direct operational impact but the effort of auditing and correcting every decision made during the degradation window. Silent failure multiplies eventual remediation cost.
Coordination Failure → Cascading Impact
When multiple agents act on inconsistent views of reality, they create new problems. Redundant changes compete. Conflicting configurations destabilize the environment. The original incident expands. The cost includes extended resolution time, additional engineering effort, and eroded trust in autonomous operations. Organizational credibility is a balance sheet item that coordination failure depletes.
The Aggregated View
Taken together, the five failure modes represent a predictable drain on AI investment returns. An organization that deploys expensive GPU infrastructure, fine-tunes capable models, and implements event-driven orchestration [3]—but feeds all of it with a batch data pipeline—has built an autonomous operations capability on a foundation that guarantees suboptimal outcomes. The streaming backbone is not an incremental cost. It is the insurance policy that protects the returns on every other AI infrastructure investment.
CONCLUSION: STREAMING-FIRST AS THE ARCHITECTURAL PREREQUISITE
The five failure modes share a common root cause. Batch data pipelines were designed for human consumers who tolerate latency, bring context, and notice anomalies. AI agents tolerate nothing. They act on what they receive.
Each failure mode is addressable within a unified streaming data architecture. Streaming telemetry solves stale data by replacing cyclical polling with continuous event push. Durable event logs solve memory gaps by preserving the sequence of events with configurable retention, allowing agents to replay history and detect patterns across time. Change data capture—a structural component of the streaming architecture implemented through Kafka Connect and Debezium—solves delete blindness by reading database transaction logs directly, capturing inserts, updates, and deletes as discrete events with explicit operation types. A schema registry with compatibility enforcement solves schema fragility by validating schema changes before they propagate downstream, catching breaking changes at the source rather than discovering them after agent failure. A shared, ordered event log solves coordination failure by serving as a single source of truth that all agents consume, ensuring every agent operates on the same reality with visibility into every other agent’s actions—complemented by intent events, idempotency keys, and lightweight leases that prevent conflicting actions without a central coordinator.
These are not disparate tools. They are structural elements of a single streaming data architecture. Apache Kafka provides the durable, shared event log at the core. Kafka Connect provides the integration framework for change data capture, ingesting database changes as first-class events. Schema Registry provides the compatibility governance layer. Together, they form a complete data foundation where stale data, memory gaps, delete blindness, schema fragility, and coordination failure are eliminated by design—not patched after the fact.
These architectural components eliminate the data-layer failure modes. But real-time data also enables real-time action—and that speed demands an execution-layer governance framework. Policy-as-code engines ensure that agent decisions, even when based on perfect context and full state, are validated against operational guardrails before they become cluster changes. The streaming backbone delivers the context. The policy layer ensures that context is acted upon safely.
This streaming architecture is not an end in itself. It is the data foundation upon which event-driven network operations can be built. While the streaming backbone eliminates the data-layer failure modes, organizations that pair it with event-driven compute unlock an additional dimension of efficiency. When a telemetry event flows through the event log and an anomaly is detected, that same stream can trigger the Kubernetes Event-driven Autoscaling (KEDA) of inference workloads [3]—spinning up the right-sized model at the right moment, on the right context. The streaming backbone delivers the context. Event-driven orchestration delivers the compute. Together, they close the loop from detection to inference, ensuring the agent has both the data and the compute it needs without the waste of always-on infrastructure.
The barrier is not technology. Each of these architectural components is proven, open-source, and deployed in production environments today. The barrier is architectural awareness. Organizations that invest in a streaming-first data architecture will deploy AI agents that deliver on their promise. Organizations that do not will discover these failure modes in production—after the wrong decision is already made.
The streaming data architecture is not a performance upgrade for Agentic AI. It is the architectural prerequisite.
REFERENCES
[1] P. Madduri and A. L. Thakur, “The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core,” IEEE ComSoc Technology Blog, April 2026. [Online]. Available: https://techblog.comsoc.org/2026/03/30/the-financial-trap-of-autonomous-networks-scaling-agentic-ai-in-the-telecom-core/
[2] Apache Software Foundation, “Apache Kafka Documentation.” [Online].
Available: https://kafka.apache.org/42/getting-started/introduction/
[3] Cloud Native Computing Foundation, “KEDA: Kubernetes Event-driven Autoscaling.” [Online]. Available: https://keda.sh/
[4] Streamkap, “Streaming ETL vs. Batch ETL: A Decision Framework.” [Online].
Available: https://streamkap.com/resources-and-guides/streaming-etl-vs-batch-etl
[5] Streamkap, “Real-Time vs Batch Data for AI Agents: Why Freshness Matters.” [Online]. Available: https://streamkap.com/resources-and-guides/real-time-vs-batch-data-for-agents
[6] Streamkap, “Why AI Agents Can’t Use Batch Data.” [Online]. Available: https://streamkap.com/resources-and-guides/why-agents-cant-use-batch-data
[7] Redpanda, “Building safe, multi-agent AI systems in Redpanda Agentic Data Plane.” [Online]. Available: https://www.redpanda.com/blog/adp-governed-multi-agent-ai-cloud
[8] Debezium Community, “Debezium: Open-Source Change Data Capture,” Debezium Documentation. [Online]. Available: https://debezium.io/
ABOUT THE AUTHOR

Shazia Hasnie, Ph.D., is VP, Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations, AI-driven automation, and streaming data architectures. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale.
STL Partners webinar: Agentic AI needed for RAN autonomy & efficiency
Yesterday, a STL Partners webinar titled “Turning autonomy into margin: Agentic AI and the autonomous RAN,” suggested agentic AI is the missing layer that can turn RAN autonomy from a technical goal into a direct profit margin booster. It argues that operators should prioritize autonomy use cases by business impact, not just by how much automation coverage they add, and that the right roadmap can move autonomy from an engineering KPI to a commercial advantage.
The central message was that autonomy only matters if it improves economics (see poll results below). The webinar revealed that network operators need a dual-axis framework that combines the usual autonomous-network maturity view with a value-creation lens, so they can focus on the capabilities that scale into measurable business outcomes.
Agentic AI is presented as the practical enabler for moving beyond human-in-the-loop operations. In this framing, agents help orchestrate tasks, make decisions, and coordinate network actions in ways that support more closed-loop automation than traditional workflows can deliver.
The results of an “actuality” poll relating to RAN autonomy revealed that controlling costs and reliability were most important, with the enablement of new revenue growth through APIs and sensing only scoring 10.87% of respondents. Similarly, results for an “aspirations” poll for RAN autonomy were also fairly evenly spread between reducing costs and optimizing the customer experience, with just 13.21% citing new revenue growth.
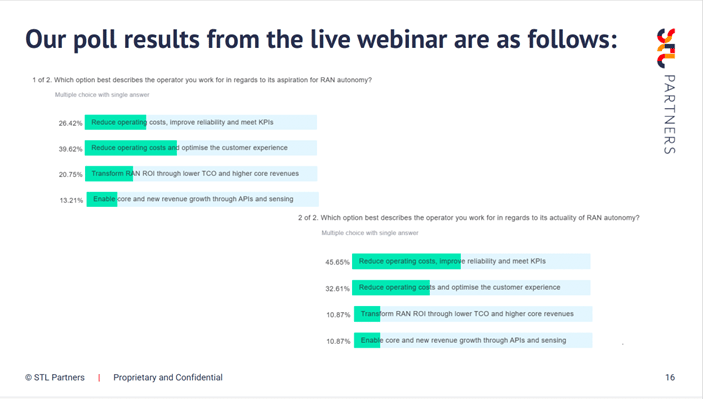
Source: STL Partners
Terje Jensen, SVP, global business security officer and head of network and cloud technology strategy at Telenor, said that he had expected to see network operators’ aspirations shift more clearly towards improving customer experience and even revenue generation, not just efficiency.
Darwin Janz, strategic technology planner at SaskTel, also thought network operators’ ambitions would be higher, but he noted that they still struggle to identify concrete, monetizable use cases. Without that, there’s a real risk of building technical solutions in search of a problem, rather than starting from clear enterprise needs and value, Darwin noted. “We really need to see those use cases and enterprise customer needs,” he added.
……………………………………………………………………………………………………………………….
The webinar was built around four practical questions:
- Which use cases create real commercial impact?
- How to shift from autonomy as an engineering metric to a margin driver?
- Where agentic does AI add value today?
- What data, orchestration, and organizational foundations are needed to scale beyond pilots.
For network operators, the implication is that autonomous RAN strategy should be tied to P&L outcomes such as lower operating cost, better resource utilization, and faster optimization cycles. The webinar’s message is that autonomy becomes strategically important only when it is deployed in a way that compounds across the network and business.
…………………………………………………………………………………………………………………..
References:
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
Nokia to showcase agentic AI network slicing; Ericsson partners with Ookla to measure 5G network slicing performance
T-Mobile US announces new broadband wireless and fiber targets, 5G-A with agentic AI and live voice call translation
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
IDC Survey of Networking Leaders: Enterprise AI progress stalls despite ambitious goals
New IDC research released in April 2026 highlights a growing disconnect between ambitious enterprise AI goals and the reality of their technical execution. The 2026 IDC AI in Networking Special Report (LinkedIn Video hyperlink) [1.] found that organizations expecting to move from early and selective AI use for business and IT initiatives to more advanced deployments largely haven’t. The result is a widening gap between intent and execution that is becoming harder to ignore. This widening gap in AI execution is driven by a mismatch between ambitious goals and the realities of legacy infrastructure, which cannot handle the data demands for production-grade models.
Despite high expectations, many organizations have seen their AI progress stall over the last 18 months, with “select use” adopters failing to advance to more “substantial” deployments. A critical shortage of specialized AI experienced personnel, combined with lagging security and governance controls, has caused widespread “pilot paralysis” across most enterprises. To overcome this, organizations are shifting toward “AI factories” to create a repeatable, governed pipeline for deploying AI.
Note 1. IDC’s 2026 AI in Networking Special Report is a report driven by a worldwide survey of 500+ enterprise network executives and experts. The report covers both the impact and plans for supporting AI workloads across the network and using AI-powered networking solutions. The focus of this research is comprehensive, covering datacenters, cloud services, multi-cloud environments, network core and edge, and network management.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
Mark Leary, IDC research director, Network Observability and Automation:
“Many solution suppliers are prioritizing a platform approach to the challenges associated with moving AI workloads into production. This survey of networking leaders highlights the shift in preference from platforms to best-in-class solutions when supporting AI workloads across their networks. As certain functional requirements intensify, as IT staff experience and expertise build, and as platforms fall short in delivering expected advantages, IT organizations are more willing to take on the added responsibilities associated with assembling their own mix of best-in-class solutions. For the supplier, the challenge is to avoid developing and delivering a platform that is classified as a jack-of-all-trades and master of none.”
“Agentic AI is to have a profound effect on the network infrastructure and on networking staff. Two years ago, AI assistants were labeled leading edge when they offered natural language processing for operator interactions and network management guidance driven by technical manual content. How things have changed! Agentic AI is no longer just a passive informer and instructor but an active intelligent virtual network engineer. Agents gather and process comprehensive network data, develop deep and precise insights, and determine and, increasingly, execute needed network management actions. Whether fixing a network problem, activating a network service, optimizing a network configuration, or responding to a developing network condition, agentic AI solutions are proving more and more useful across the entire network and the entire set of tasks required to engineer and operate the network.”
While this IDC Survey Spotlight offers only an overview of responses relating to agentic AI, detailed results are available by geographic region, select country, company size, major vertical industries, respondent role, and the AI maturity level of the respondent’s organization.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
Organizations are pursuing AI in networking across two categories:
1.] Supporting AI workloads across network infrastructure and
2.] Applying AI to network operations.
But in both cases, progress is constrained by persistent challenges. “2026 is when organizations find out if AI in networking delivers real operational impact—or remains stuck in pilot mode,” Leary said in the referenced LinkedIn Video.

Source: IDC
……………………………………………………………………………………………………………………………
Security remains the top concern among enterprises, both as a barrier to deployment and a primary use case for AI itself. “You have to fight AI with AI from a network security perspective,” said Brandon Butler, senior research manager at IDC. “There’s a realization that nefarious actors are leveraging AI themselves. The pressure is already on the network. The question now is whether organizations can keep up with what AI is demanding of their infrastructure,” he added.
Integration with existing systems and a shortage of skilled talent follow close behind. “Most folks don’t feel their staff can fully evaluate and select the right solutions,” Leary said. As a result, many organizations are turning outward for help:
- 81% say they are increasing spending on managed service providers (MSP) to support AI initiatives.
- 89% of data centers expect to increase bandwidth by at least 11% within the next year, driven by AI workloads.
- That demand extends beyond individual facilities, with 91% expecting similar growth in inter-data center connectivity, highlighting the strain on distributed architectures.
- Nearly half of respondents (46%) prefer AI systems that can both determine and execute network actions autonomously.
- Another 41% favor a guided approach, while 13% prefer no AI involvement.
Cloud environments are seeing sharper increases in AI use. Organizations anticipate an average 49% rise in bandwidth for cloud connectivity over the next year. “The cloud is almost always involved,” Leary says. “The biggest group mixes one cloud platform with one or more data centers.”
Beyond the data center and cloud, the network edge is emerging as the next major growth area. Today, 27% of organizations have deployed AI workloads at the edge, and 54% plan to do so within two years. Butler said: “Folks who are leveraging AI more extensively are already pushing workloads to the edge. We see this as a leading indicator of where the market is going.”
“Two years in a row, the largest group said they want AI to both determine and execute actions. It was honestly surprising,” he added.
Enterprise edge bandwidth is projected to grow by an average of 51% in the next year. As AI becomes more distributed, network teams will need to manage greater complexity across environments while maintaining performance and security.
…………………………………………………………………………………………………………………………………………………………………………….
When assessing expected ROI from AI in networking, IDC survey respondents focused on elevating IT capabilities, with 31% prioritizing superior service levels and 30% focusing on operational efficiency. These outcomes ranked above worker productivity and revenue, suggesting that leaders are strategically utilizing AI to enhance foundational operational workflows. Notably, reducing operating costs ranked seventh, suggesting a focus on strategic value rather than immediate expense reduction.

Source: IDC
……………………………………………………………………………………………………
IDC Research identified specific applications—from automated configuration validation to AI-enhanced threat response—as catalysts for measurable performance gains and the organizational trust essential for broader implementation. For network executives, this phased approach represents the most strategic methodology for achieving long-term operational objectives.
“It doesn’t have to be handing the keys of your kingdom to AI to really get some benefits from these AI tools,” Butler concluded.
……………………………………………………………………………………………………………………………………………………………………………………….
References:
https://www.networkworld.com/article/4152655/ai-for-it-stalls-as-network-complexity-rises.html
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
By Pavan Madduri with Ajay Lotan Thakur
The telecom industry wants autonomous, self-healing networks, but nobody is looking at the GPU bill. Running Agentic AI 24/7 “just in case” will bankrupt your IT department and ruin your ESG goals. The only way to survive the autonomous era is ruthless, event-driven orchestration that scales cognitive compute to absolute zero.
Introduction – The Compute Crisis:
The Compute Crisis Nobody is Talking About
Everyone in telecom right now is obsessed with “self-healing” autonomous networks. The vendor pitch sounds amazing. Just drop in some Agentic AI, let it watch your data plane, and watch it fix anomalies without a human ever touching a keyboard. But there’s a massive trap hiding underneath all that hype, and enterprise architects are completely ignoring it. It comes down to the raw physics of AI compute.
Unlike your standard microservices, which just run deterministic, compiled code on cheap CPU cycles, Agentic AI needs massive foundation models. To actually reason through a network failure, these models have to load gigabytes of weights into Video RAM and generate tokens. You need dedicated GPUs for this. We aren’t talking about cheap, stateless API calls here. These are the most expensive, power-hungry workloads in your entire datacenter.
If a telco tries to run an autonomous core the old-fashioned way by keeping high-end GPU nodes spinning 24/7 just in case a BGP route flaps, their cloud bill is going to wipe out any operational savings the AI was supposed to deliver.
The reality is that autonomy is no longer just a software problem. It’s a financial one. The telcos that actually win will not be the ones with the smartest AI. They will be the ones who figure out how to build a strict “scale-to-zero” environment. They need to spin up that expensive cognitive compute exactly when it is needed, and kill it the exact second the job is done.
Why Traditional Auto-scaling is Broken for AI:
When platform engineers first see the compute costs of running these AI agents, their first instinct is usually just to slap standard Kubernetes Horizontal Pod Autoscaling (HPA) on the cluster and call it a day. But standard HPA was built for stateless web servers, not massive cognitive engines. If you try to use it for Agentic AI in a telecom core, you’re going to fail for two big reasons.
The Cold-Start Penalty: Traditional autoscaling is entirely reactive. It sits around waiting for a CPU to hit 80% before it decides to scale up. In telecom, SLAs are measured in sub-milliseconds. If you wait for an anomaly to spike your CPU, then provision a new GPU node, pull a massive AI container image, and load the model weights into VRAM, you are talking about minutes of delay. By the time your AI agent actually wakes up to fix the problem, you have already breached your SLA.
CPU Utilization is a Liar: For AI workloads, standard hardware metrics are completely misleading. A GPU could be pegged at 90% utilization just thinking through a minor log warning, while a massive, critical network failure is stuck waiting in the queue. If your scaling logic is tied to hardware metrics instead of the actual severity of the event queue, you are just going to burn budget scaling blindly.
We have to abandon reactive resource metrics entirely and move to event-driven orchestration.
The Fix – Event-Driven Orchestration:
If standard HPA is broken for this, what is the fix? You have to completely decouple the infrastructure from the workload using strict, event-driven orchestration.
Instead of keeping baseline infrastructure running just to maintain a state, you treat cognitive compute as 100% ephemeral. You don’t scale based on how hard the CPU is working. You scale based on the exact depth and severity of the anomaly queue.
To actually build this, architects need purpose-built event-driven scalers like KEDA (Kubernetes Event-driven Autoscaling). KEDA lets your cluster completely bypass those reactive hardware metrics and listen directly to the network’s data plane.
But how do you avoid the cold-start latency of booting a fresh GPU pod? KEDA solves this by reacting to the event queue length itself rather than waiting for an existing pod’s CPU to max out. By the time a traditional HPA notices a CPU spike, the system is already overwhelmed. (To solve this exact issue in production, I open-sourced a custom KEDA scaler specifically designed to scrape and react to native GPU metrics, allowing the orchestrator to scale cognitive workloads preemptively. You can view the architecture on [GitHub])
KEDA intercepts the telemetry trigger at the source. When paired with a warm pool of paused GPU nodes and pre-pulled container images, KEDA can scale a pod from zero to active in milliseconds. The infrastructure is anticipating the load based on the queue, not reacting to the stress of it.
Here is what the workflow actually looks like when you do it right:
- The Trigger: Telemetry picks up a severe anomaly ,like a sudden 5G slice degradation, and pushes an event straight to a message broker like Kafka.
- The Scale-Up: KEDA intercepts that exact metric and instantly provisions a dedicated, GPU-backed AI pod from a warm standby pool.
- The Execution: The Agentic AI loads into VRAM, figures out the blast radius of the anomaly, and executes a fix. This is usually by reconciling the state through a GitOps controller.
- The Kill Switch: The absolute millisecond that the event queue clears and the network is stable, the orchestrator aggressively terminates the pod and gives the GPU back to the node pool.
You only pay the premium GPU tax during moments of active reasoning. The 24/7 idle tax is gone.
Architecting the Scale-to-Zero Core:
To make this scale-to-zero dream a reality, you have to fundamentally change how you handle network observability. The biggest mistake I see architects make is tightly coupling their monitoring tools with their AI execution layer. If your observability stack is running on the same hardware as your AI engine, you are literally wasting premium GPU compute just to watch logs.
You need a strict, physical separation of concerns:
The Watchers (The Lightweight Control Plane):
Your network data plane needs to be monitored by lightweight, CPU-efficient edge collectors like Prometheus or OpenTelemetry. These sit right at the edge, continuously eating millions of telemetry data points and BGP state changes. Because they don’t do any complex reasoning, they run incredibly cheap on standard CPU nodes.
The Thinkers (The Heavyweight Execution Plane):
Your expensive AI models are completely isolated in a separate, GPU-backed node pool that literally defaults to zero instances.
When the Watchers spot an anomaly, they don’t try to fix it. They just fire an alert to KEDA. KEDA then wakes up the Thinkers, spinning up the exact number of GPU pods needed to handle that specific blast radius. By decoupling the watchers from the thinkers, you guarantee that not a single cycle of GPU compute is wasted on baseline monitoring.
The Bottom Line:
Autonomous telecom networks are going to happen. But trying to brute-force the infrastructure provisioning is a fast track to bankrupting your IT department. The smartest Agentic AI in the world is useless if you can’t afford the cloud bill to run it.
Furthermore, this isn’t just about protecting the IT budget. Running idle GPUs 24/7 creates a massive, unnecessary carbon footprint. By enforcing a scale-to-zero architecture, telcos can drastically reduce the energy consumption of their autonomous networks, turning a massive ESG liability into a sustainable operational model.
Autonomy is no longer just a software engineering problem. It is an infrastructure balancing act. If Agentic AI is going to survive in the telecom core, we have to ditch legacy threshold scaling and embrace strict, event-driven orchestration.
Tools like KEDA give us the ability to build networks that are both cognitively brilliant and financially ruthless. We can spin up massive intelligence at the exact millisecond of failure and scale right back to zero the moment the network is healed.
References and Further Reading:
- Unlocking Energy Saving in Telecom Networks: A Path to a Sustainable Future – A deep dive into the operational and ESG mandates driving energy efficiency in modern telecom infrastructure.
- KEDA Documentation: Kubernetes Event-driven Autoscaling – Technical specifications for decoupling workload scaling from standard CPU/Memory metrics.
- keda-gpu-scaler – An open-source custom KEDA scaler I developed to enable event-driven autoscaling specifically tied to native GPU telemetry and queue depth.
Building and Operating a Cloud Native 5G SA Core Network
How Network Repository Function Plays a Critical Role in Cloud Native 5G SA Network
HPE Aruba Launches “Cloud Native” Private 5G Network with 4G/5G Small Cell Radios
…………………………………………………………………………………………….
About the Author:

Pavan Madduri is a Cloud-Native Architect, CNCF Golden Kubestronaut, and active IEEE researcher specializing in enterprise infrastructure automation, Agentic SREs, and Kubernetes networking. He designs scalable, zero-trust cloud environments and frequently writes about the intersection of AI governance and cloud-native infrastructure.
Connect with Pavan Madduri on [LinkedIn] .
Disclaimer: The author acknowledges the use of AI-assisted tools for structural formatting, language refinement, and copyediting during the drafting of this article. The core architectural concepts, technical opinions, and engineering strategies remain entirely original.
Huawei unveils AI Centric Network roadmap, U6 GHz products, 5G Advanced strategy and SuperPoD cluster computing platforms
Missing from all the MWC 2026 6G AI alliance announcements, Huawei released a series of all-scenario U6 GHz products to help carriers unlock the full potential of 5G Advanced (5G-A) and set the stage for a seamless transition to 6G. Huawei also showcased its SuperPoD cluster for the first time outside China, which they have created to offer “a new option for the intelligent world.”
- The all-scenario U6 GHz products and solutions Huawei released today use innovative technologies to create a high-capacity, low-latency, optimal-experience backbone designed for mobile AI applications.
- There are already 70 million 5G-A users globally, and 5G-A is increasingly being adopted by carriers at scale. In China, Huawei has helped carriers deliver contiguous 5G-A coverage across 270 cities and launch 5G-A packages that monetize experience in over 30 provinces.
The company also launched enhanced AI-Centric Network solutions [1.] that will help carriers prepare for the agentic era by enabling intelligent services, networks, and network elements (NEs). The company’s plans to build more AI-centric networks and computing backbones that will help carriers and industry customers seize opportunities from the AI era.
Note 1. Huawei’s AI-Centric Network roadmap is designed to integrate intelligence directly into 5G-Advanced (5G-A) infrastructure and accelerate the transition toward Level-4 Autonomous Networks. The company plans to work with global carriers (where its not blacklisted) on the large-scale 5G-A deployment, use high uplink to address surging consumer and industry demand for mobile AI applications, and use the U6 GHz band to unlock the full value of spectrum and pave the way for smooth evolution to 6G.

Photo Credit: Huawei
………………………………………………………………………………………………………………
Three-Layer Intelligence in AI-Centric Networks: Accelerating the Agentic Era:
As mobile network operators transition toward AI-native 5G-Advanced and early 6G architectures, Huawei is positioning its AI-Centric Network portfolio as the blueprint for next-generation intelligent networks. By embedding intelligence across service, network, and network element (NE) layers, Huawei aims to establish the foundation for fully agentic, autonomously managed infrastructures.
- Service Layer: Focuses on multi-agent collaboration platforms to transform core carrier services—such as voice and home broadband—into intelligent service platforms.
- Network Layer: Aims to evolve from single-scenario automation to end-to-end single-domain network autonomy. Huawei officially launched AUTINOps, an AI-native intelligent operations solution designed to replace traditional manual O&M with predictive, preventive “digital employees”.
- Network Element (NE) Layer: Utilizes AI to optimize algorithms for RANs (Radio Access Networks) and core networks, improving spectral efficiency and service awareness.
At the Service layer, Huawei is enabling carriers to operationalize multi-agent collaboration frameworks that embed domain-specific intelligence into key service categories: voice, broadband, and digital experience monetization. These AI agents dynamically manage customer experience and lifecycle value, supporting the transformation of core connectivity services into intelligent, context-aware digital offerings.
At the Network layer, the company’s Autonomous Driving Network Level 4 (ADN L4) initiative focuses on single-scenario automation, delivering measurable improvements in O&M efficiency, service quality, and monetization agility. By the close of 2025, ADN single-scenario deployments were active across more than 130 commercial telecom networks. The next phase targets end-to-end, single-domain autonomy across transport, access, and core networks—an essential step toward zero-touch O&M and intent-driven orchestration in 5G-A and 6G environments.
At the Network Element layer, Huawei is jointly advancing AI-driven innovation across RAN, WAN, and core domains. This includes algorithmic optimization for intelligent RAN scheduling, service-aware traffic identification in WANs, and unified intent modeling across B2C and B2H use cases. Such capabilities enhance spectral and energy efficiency, enable predictive resilience, and provide fine-grained service awareness—all foundational for AI-native air interface and network control in 6G.
Computing Backbone with SuperPoD Clusters:
Supporting this vision, Huawei is introducing its next-generation SuperPoD and cluster computing platforms, designed as high-performance compute backbones for distributed AI model training and inference within telecom and enterprise domains. Featuring the proprietary UnifiedBus interconnect and system-level architecture innovations, the Atlas 950, TaiShan 950, and Atlas 850E SuperPoDs, along with the TaiShan 200–500 servers, deliver ultra-low latency and high throughput optimized for trillion-parameter AI models and real-time agentic operations.
Aligned with its open innovation strategy, Huawei continues to expand an open, collaborative computing ecosystem, supporting open-source frameworks and open-access platforms to accelerate the deployment of intelligent, AI-driven digital infrastructure worldwide.
Intelligent Transformation Across Industry Domains:
At MWC Barcelona 2026, Huawei is highlighting 115 end-to-end industrial intelligence showcases across verticals, underscoring its role in helping enterprises adopt AI-centric operational models. Through the SHAPE 2.0 Partner Framework, 22 co-developed AI and digital infrastructure solutions will demonstrate how vertical industries—from manufacturing and energy to transportation and healthcare—can harness 5G-A and AI integration to deliver measurable business outcomes.
Toward 5G-A Commercialization and 6G Evolution:
With large-scale 5G-Advanced rollouts accelerating, Huawei is collaborating with global carriers and ecosystem partners to realize level-4 autonomous networks and establish the architectural bridge to 6G. Central to this evolution is the convergence of AI, connectivity, and computing—enabling networks that can self-learn, self-optimize, and autonomously orchestrate service intent. These AI-Centric Network initiatives and SuperPoD-based computing backbones form the foundation for value-driven, intelligent networks built for the agentic era.
5G-Advanced and Infrastructure Innovations:
Huawei’s 5G-A strategy, branded as GigaUplink, focuses on delivering the high-uplink capacity and low latency required for mobile AI applications:
- U6 GHz Spectrum: Launched a comprehensive portfolio of all-scenario U6 GHz products to unlock 5G-A’s full potential and provide a smooth evolution path to 6G.
- Agentic Core: Introduced the Agentic Core solution, which integrates intelligence natively into the core network to support ubiquitous AI agent access across devices.
- All-Optical Target Network: Proposed an AI-centric optical roadmap featuring dual strategies: “AI for networks” (optimizing operations) and “networks for AI” (supporting AI workloads with ultra-low latency benchmarks of 1-5ms).
………………………………………………………………………………………………………………………………………………………..
References:
https://www.huawei.com/en/news/2026/3/mwc-ai-centric-network
https://carrier.huawei.com/en/minisite/events/mwc2026/
Huawei FY2025: 2.2% YoY revenue increase; strategic pivot to AI & Automotive
NVIDIA and global telecom leaders to build 6G on open and secure AI-native platforms + Linux Foundation launches OCUDU
Omdia on resurgence of Huawei: #1 RAN vendor in 3 out of 5 regions; RAN market has bottomed
Huawei, Qualcomm, Samsung, and Ericsson Leading Patent Race in $15 Billion 5G Licensing Market
Huawei Cloud Review and Global Sales Partner Policies for 2026
Huawei’s Electric Vehicle Charging Technology & Top 10 Charging Trends
Huawei to Double Output of Ascend AI chips in 2026; OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
Huawei launches CloudMatrix 384 AI System to rival Nvidia’s most advanced AI system
U.S. export controls on Nvidia H20 AI chips enables Huawei’s 910C GPU to be favored by AI tech giants in China
AT&T and Ericsson boost Cloud RAN performance with AI-native software running on Intel Xeon 6 SoC
Ericsson and Intel collaborate to accelerate AI-Native 6G; other AI-Native 6G advancements at MWC 2026
Ericsson and Intel at MWC 2026:
Building on milestones in Cloud RAN, 5G Core, and open network innovation, Ericsson and Intel are showcasing joint technology advancements at the Mobile World Congress (MWC) 2026 in Barcelona this week. Demonstrations can be experienced at the Ericsson Pavilion (Hall 2), Intel Booth (Hall 3, Stand 3E31), and across partner event spaces, highlighting the companies’ shared progress in enabling the next era of AI-driven networks.
The two companies are strengthening their long-standing technology partnership to accelerate ecosystem readiness for AI-native 6G networks and use cases. The expanded collaboration spans next-generation mobile connectivity, cloud infrastructure, and compute acceleration — with a focus on AI-driven RAN and packet core evolution, platform-level security, and scalable cloud-native architectures designed to shorten time-to-market for advanced network solutions.
“6G is not merely an iteration of mobile technology; it will serve as the foundational infrastructure distributing AI across devices, the edge, and the cloud,” said Börje Ekholm, President and CEO of Ericsson. “With our deep history in network innovation and global-scale operator deployments, Ericsson is uniquely positioned to drive practical 6G integration from research to commercialization.”
Lip-Bu Tan, CEO of Intel, added: “Intel’s vision is to lead the industry in unifying RAN, Core, and edge AI to enable seamless deployment of AI-native 6G environments. Together with Ericsson, we are proving that next-generation connectivity can be open, energy-efficient, secure, and intelligent. With future Ericsson Silicon built on Intel’s most advanced process technologies, coupled with Intel Xeon-powered AI-RAN ready Cloud RAN and collaborative multi-year research efforts, we are delivering the performance, efficiency, and supply assurance demanded by leading operators worldwide.”
As 6G transitions from research to commercialization, the industry must align around a mature, standards-based ecosystem. The Ericsson–Intel collaboration aims to accelerate development of high-performance, energy-efficient compute architectures optimized for both AI for Networks and Networks for AI.
AI-native 6G will fuse intelligent, programmable network functions with distributed compute and real-time sensing, bringing processing power closer to the network edge and enabling ultra-responsive, adaptive services. This convergence will enhance network efficiency, agility, and service intelligence across future deployments.
About Ericsson:
Ericsson‘s high-performing networks provide connectivity for billions of people every day. For 150 years, we’ve been pioneers in creating technology for communication. We offer mobile communication and connectivity solutions for service providers and enterprises. Together with our customers and partners, we make the digital world of tomorrow a reality.
About Intel:
Intel is an industry leader, creating world-changing technology that enables global progress and enriches lives. Inspired by Moore’s Law, we continuously work to advance the design and manufacturing of semiconductors to help address our customers’ greatest challenges. By embedding intelligence in the cloud, network, edge and every kind of computing device, we unleash the potential of data to transform business and society for the better.
…………………………………………………………………………………………………………………………………………………………
Related AI-Native 6G Announcements at MWC 2026:

In addition to the Ericsson-Intel collaboration, several vendors and operators announced AI-native 6G advancements or related demos at MWC Barcelona 2026. These initiatives emphasize AI-RAN integration, software-defined architectures, and ecosystem partnerships to bridge 5G-A to 6G.
NVIDIA Multi-Partner Commitment: NVIDIA rallied operators and vendors including Booz Allen, BT Group, Cisco, Deutsche Telekom, Ericsson, Nokia, SK Telecom, SoftBank, and T-Mobile to build open, secure AI-native 6G platforms. The focus is on software-defined wireless with AI embedded in RAN, edge, and core for integrated sensing, communications, and interoperability.
Nokia AI-RAN: Nokia highlighted new partnerships with Dell, Quanta, Red Hat, SuperMicro, NVIDIA, and operators like T-Mobile, Indosat Ooredoo Hutchison, BT, Elisa, NTT DOCOMO, and Vodafone for AI-RAN trials paving the way to cognitive 6G networks. Live demos at Nokia’s Hall 3 Booth 3B20 included Southeast Asia’s first AI-RAN Layer 3 5G call on shared GPU infrastructure and vision AI for immersive services.
T-Mobile & Deutsche Telekom Hub: T-Mobile US and (major shareholder) Deutsche Telekom launched a joint 6G Innovation Hub targeting AI-native autonomous networks, secure sensing/positioning, and connectivity-compute convergence for Physical AI. It builds on agentic AI proofs like network-integrated translation, emphasizing “kinetic tokens” for real-time physical world control.
ZTE GigaMIMO 6G Prototype: ZTE unveiled the world’s first 6G prototype with 2000+ U6G-band antenna elements (GigaMIMO), powered by AI algorithms for 10x capacity over 5G-A, 30% spectral efficiency gains, and AI-driven immersive services. Booth 3F30 demos integrate AI across connectivity, computing, and devices for “AI serves AI” networks.
Qualcomm Agentic AI RAN: Qualcomm announced AI-native RAN management services in its Dragonwing suite for autonomous 6G-grade networks, plus new Open RAN AI features for performance optimization. CEO Cristiano Amon’s keynote focused on “Architecting 6G for the AI Era,” with device-to-data-center transformations.
Huawei U6GHz for 6G Path:
Huawei released all-scenario U6GHz products (macro/micro sites, microwave) with AI-centric solutions for 5G-A capacity (100 Gbps downlink) and low-latency AI apps, enabling smooth 6G evolution. Emphasizes hyper-resolution MU-MIMO and multi-band coordination for indoor/outdoor AI experiences.
Summary Chart:
| Vendor/Operator | Key Focus | Partners/Demos | Booth/Location |
|---|---|---|---|
| NVIDIA | Open AI-native platforms | Multiple operators/vendors | MWC general |
| Nokia | AI-RAN trials & cognitive networks | NVIDIA, T-Mobile, IOH et al. | Hall 3, 3B20 |
| T-Mobile/DT | Physical AI hub | Joint R&D | Announced pre-MWC |
| ZTE | GigaMIMO 6G prototype | China Mobile, Qualcomm | Hall 3, 3F30 |
| Qualcomm | Agentic RAN automation | Open RAN ecosystem | Keynote & demos |
| Huawei | U6GHz AI-centric evolution | Carrier-focused | MWC showcase |
…………………………………………………………………………………………………………………………………………………………………………………….
References:
NVIDIA and global telecom leaders to build 6G on open and secure AI-native platforms + Linux Foundation launches OCUDU
Comparing AI Native mode in 6G (IMT 2030) vs AI Overlay/Add-On status in 5G (IMT 2020)
SKT 6G ATHENA White Paper: a mid-to-long term network evolution strategy for the AI era
Dell’Oro: RAN Market Stabilized in 2025 with 1% CAG forecast over next 5 years; Opinion on AI RAN, 5G Advanced, 6G RAN/Core risks
Nokia and Rohde & Schwarz collaborate on AI-powered 6G receiver years before IMT 2030 RIT submissions to ITU-R WP5D
SK Telecom, DOCOMO, NTT and Nokia develop 6G AI-native air interface
Market research firms Omdia and Dell’Oro: impact of 6G and AI investments on telcos
Ericsson goes with custom silicon (rather than Nvidia GPUs) for AI RAN
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
