

AI in Networks Market
Fiber Optic Boost: Corning and Meta in multiyear $6 billion deal to accelerate U.S data center buildout
Corning Incorporated and Meta Platforms, Inc. (previously known as Facebook) have entered a multiyear agreement valued at up to $6 billion. This strategic collaboration aims to accelerate the deployment of cutting-edge data center infrastructure within the U.S. to bolster Meta’s advanced applications, technologies, and ambitious artificial intelligence initiatives. The agreement specifies that Corning will furnish Meta with its latest advancements in optical fiber, cable, and comprehensive connectivity solutions. As part of this commitment, Corning plans to significantly scale its manufacturing capabilities across its North Carolina facilities.
A key element of this expansion is a substantial capacity increase at its fiber optic cable manufacturing plant in Hickory NC, for which Meta will serve as the foundational anchor customer. The construction and operation of these data centers — critical infrastructure that supports our technologies and moves us toward personalized superintelligence — necessitate robust server and hardware systems designed to facilitate information transfer and connectivity with minimal latency. Fiber optic cabling is a cornerstone component for enabling this high-speed, near real-time connectivity, powering applications from sophisticated wearable technology like the Ray-Ban Meta AI glasses to the global connectivity services utilized by billions of individuals and enterprises.
“This long-term partnership with Meta reflects Corning’s commitment to develop, innovate, and manufacture the critical technologies that power next-generation data centers here in the U.S.,” said Wendell P. Weeks, Chairman and Chief Executive Officer, Corning Incorporated. “The investment will expand our manufacturing footprint in North Carolina, support an increase in Corning’s employment levels in the state by 15 to 20 percent, and help sustain a highly skilled workforce of more than 5,000 — including the scientists, engineers, and production teams at two of the world’s largest optical fiber and cable manufacturing facilities. Together with Meta, we’re strengthening domestic supply chains and helping ensure that advanced data centers are built using U.S. innovation and advanced manufacturing.”
Meta is expanding its commitment to build industry-leading data centers in the U.S. and to source advanced technology made domestically. Here are two quotes from them:
- “Building the most advanced data centers in the U.S. requires world-class partners and American manufacturing,” said Joel Kaplan, Chief Global Affairs Officer at Meta. “We’re proud to partner with Corning – a company with deep expertise in optical connectivity and commitment to domestic manufacturing – for the high-performance fiber optic cables our AI infrastructure needs. This collaboration will help create good-paying, skilled U.S. jobs, strengthen local economies, and help secure the U.S. lead in the global AI race.”
- “As digital tools and generative AI continue to transform our economy — in fields like healthcare, finance, agriculture, and more — the demand for fiber connectivity will continue to grow. By supporting American companies like Corning and building and operating data centers in America, we’re helping ensure that our nation maintains its competitive edge in the digital economy and the global race for AI leadership.”
Key elements of the agreement:
- Multiyear, up to $6 billion commitment.
- Corning to supply latest generation optical fiber, cable and connectivity products designed to meet the density and scale demands of advanced AI data centers.
- New optical cable manufacturing facility in Hickory, North Carolina, in addition to expanded production capacity across Corning’s North Carolina operations.
- Agreement supports Corning’s projected employment growth in North Carolina by 15 to 20 percent, sustaining a skilled workforce of more than 5,000 employees in the state, including thousands of jobs tied to two of the world’s largest optical fiber and cable manufacturing facilities.
…………………………………………………………………………………………………………………………………………………………….
Comment and Analysis:
Corning’s “up to $6 billion” Meta agreement is essentially a long‑term, anchor‑tenant bet that AI‑era data centers will be fundamentally more fiber‑intensive than legacy cloud resident data centers, with Corning positioning itself as the default U.S. optical plant for Meta’s buildout through ~2030. In practice, this deal is a long‑term take‑or‑pay style capacity lock that de‑risks Corning’s capex while giving Meta priority access to scarce, high‑performance data‑center‑grade fiber and cabling.
AI data centers are becoming the new FTTH in the sense that hyperscale AI buildouts are now the primary structural driver of incremental fiber demand, design innovation, and capex prioritization—but with far higher fiber intensity per site and far tighter performance constraints than residential access ever imposed.
Why “AI Data Centers are the new FTTH” for fiber optic vendors:
For fiber‑optic vendors, AI data centers now play the role that FTTH did in the 2005–2015 cycle: the anchor use case that justifies new glass, cable, and connectivity capacity.
-
AI‑optimized data centers need 2–4× more fiber cabling than traditional hyperscalers, and in some designs more than 10×, driven by massively parallel GPU fabrics and east–west traffic.
-
U.S. hyperscale capacity is expected to triple by 2029, forcing roughly a 2× increase in fiber route miles and a 2.3× increase in total fiber miles, a demand shock comparable to or larger than the early FTTH boom but concentrated in fewer, much larger customers.
-
This is already reshaping product roadmaps toward ultra‑high‑fiber‑count (UHFC) cable, bend‑insensitive fiber, and very‑small‑form‑factor connectors to handle hundreds to thousands of fibers per rack and per duct.
In other words, where FTTH once dictated volume and economies of scale, AI data centers now dictate density, performance, and margin mix.
Carrier‑infrastructure: from access to fabric:
From a carrier perspective, the “new FTTH” analogy is about what drives long‑haul and metro planning: instead of last‑mile penetration, it’s AI fabric connectivity and east–west inter‑DC routes.
-
Each new hyperscale/AI data center is modeled to require on the order of 135 new fiber route miles just to reach three core network interconnection points, plus additional miles for new long‑haul routes and capacity upgrades.
-
An FBA‑commissioned study projects U.S. data centers alone will need on the order of 214 million additional fiber miles by 2029, nearly doubling the installed base from ~160M to ~373M fiber miles; that is the new “build everywhere” narrative operators once used for FTTH.
-
Carriers now plan backbone routes, ILAs, and regional rings around dense clusters of AI campuses, treating them as primary traffic gravity wells rather than as just a handful of peering sites at the edge of a consumer broadband network.
The strategic shift: FTTH made the access network fiber‑rich; AI makes the entire cloud and transport fabric fiber‑hungry.
Strategic implications:
-
AI is now the dominant incremental fiber use case: residential fiber adds subscribers; AI adds orders of magnitude more fibers per site and per route.
-
Network economics are moving from passing more homes to feeding more GPUs: route miles, fiber counts, and connector density are being dimensioned to training clusters and inference fabrics, not household penetration curves.
-
Policy and investment narratives should treat AI inter‑DC and campus fiber as “national infrastructure” on par with last‑mile FTTH, given the scale of projected doubling in route miles and more than doubling in fiber miles by 2029.
In summary, the next decade of fiber innovation and capex will be written less in curb‑side PON and more in ultra‑dense, AI‑centric data centers with internal fiber optical fabrics and interconnects.
……………………………………………………………………………………………………………………………………………………………………………………………….
References:
Meta Announces Up to $6 Billion Agreement With Corning to Support US Manufacturing
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
Analysis: Cisco, HPE/Juniper, and Nvidia network equipment for AI data centers
Networking chips and modules for AI data centers: Infiniband, Ultra Ethernet, Optical Connections
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Superclusters of Nvidia GPU/AI chips combined with end-to-end network platforms to create next generation data centers
Lumen Technologies to connect Prometheus Hyperscale’s energy efficient AI data centers
Proposed solutions to high energy consumption of Generative AI LLMs: optimized hardware, new algorithms, green data centers
Hyper Scale Mega Data Centers: Time is NOW for Fiber Optics to the Compute Server
Fierce Network Research report examines telcos role in the AI economy and profiles early AI adopters
The telecommunications industry is at a critical crossroads. As AI reshapes global value chains, communications service providers (CSPs) must determine their strategic position: will they remain infrastructure enablers or evolve into full-scale participants in the AI economy?
A new Fierce Network Research report — “Risk, Reward and Revenue: Defining Telcos’ Role in the AI Economy” — examines this identity challenge — and how network operators are recalibrating for the next generation of network-driven intelligence. Based on a global survey of 500 technology decision-makers across 40 countries, the findings reveal a pronounced industry divide. A majority (57%) of operators see their core opportunity in infrastructure — networks, data centers, and secure connectivity — while 43% advocate for a more integrated position, aspiring to orchestrate AI ecosystems (19%) or participate fully in the AI value chain (24%).
Some of the industry’s early adopters are already showing what that future might look like.
- AT&T reports a twofold increase in cash flow for every dollar it invests in AI, emphasizing measurable outcomes over vague productivity gains. An AT&T executive said that success in the AI era depends on “Goldilocks governance” — a balance not too rigid to stifle innovation, and not too loose to compromise compliance and trust.
- Bell Canada is moving in a similar direction, targeting a doubling of enterprise AI revenue by 2028 and positioning its Ateko subsidiary and AI Fabric platform as the backbone of a “sovereign digital spine” for Canada.
- “We’re using AI to enhance our products and services and make them better,” Ed Fox, MetTel CTO. The company provides a private network to deliver integrated communications and IT services to U.S. businesses and government agencies, including voice, data, network, cloud, mobility, IoT and security solutions. MetTel also provides managed network services such as SD-WAN and secure access service edge (SASE).
- Rick Lievano, Microsoft CTO for the worldwide telecommunications industry, sees operators expanding their use of AI beyond efficiency. “Initially, the first place where telcos began to experiment with AI is around efficiency gains — how can I save money, and how can I do more with fewer people? That’s been the target of the first couple of waves of AI,” Lievano said. “However, their eyes light up when we talk with them about new revenue opportunities,” Lievano said.
The research highlights that telcos possess critical assets few other industries can match: globally distributed data center capacity, secure and resilient networks, and deep, long-standing relationships with enterprise and government customers. But the barriers are equally significant — from proving the business case for AI infrastructure to navigating a shortage of data science and AI talent. Legacy technology debt continues to drag, with one executive lamenting that 145 years of accumulated systems make modern data integration “extraordinarily complex.”

A new Fierce Network Research report reveals how communication service providers are navigating the AI economy amid uncertainty about their role and strategy. (Google Gemini)
The bottom line is clear: to remain relevant in the AI-driven economy, telcos must modernize both infrastructure and business models — transforming from connectivity providers into intelligent digital enablers. However, we’ve heard that cry for telco transformation from dumb pipes to intelligent and autonomous network and IT providers, but it has yet to be realized. Will this time be any different?
References:
https://www.fierce-network.com/cloud/dumb-pipes-or-ai-powerhouses-telcos-face-identity-crisis
Full REPORT: “Risk, Reward and Revenue: Defining telcos’ role in the AI economy.”
Private 5G networks move to include automation, autonomous systems, edge computing & AI operations
Palo Alto Networks and Google Cloud expand partnership with advanced AI infrastructure and cloud security
Generative AI could put telecom jobs in jeopardy; compelling AI in telecom use cases
Generative AI in telecom; ChatGPT as a manager? ChatGPT vs Google Search
Allied Market Research: Global AI in telecom market forecast to reach $38.8 by 2031 with CAGR of 41.4% (from 2022 to 2031)
Markets and Markets: Global AI in Networks market worth $10.9 billion in 2024; projected to reach $46.8 billion by 2029
Ericsson integrates Agentic AI into its NetCloud platform for self healing and autonomous 5G private networks
Ericsson CEO’s strong statements on 5G SA, WRC 27, and AI in networks
New Linux Foundation white paper: How to integrate AI applications with telecom networks using standardized CAMARA APIs and the Model Context Protocol (MCP)
Comparing AI Native mode in 6G (IMT 2030) vs AI Overlay/Add-On status in 5G (IMT 2020)
Executive Summary:
AI integration in 6G specifications (3GPP) and standards (ITU-R IMT 2030) highlights a strategic shift in the telecom industry towards AI-native networks, with telecom industry heavyweights like Huawei, Samsung, Ericsson, and Nokia actively developing foundational technologies. Unlike 5G, where AI and machine learning were limited applications or add-on features over existing architecture, 6G will incorporate AI from the onset with an “AI native” approach where intelligence will allow the network to be smart, agile, and able to learn and adapt according to changing network dynamics.
This transformation is necessary because future 6G networks will be too complex for human operators to manage, requiring AI-empowered and learning-driven networks that can facilitate zero-touch network management through capabilities including learning, reasoning, and decision-making.
- AI-Native Networks: The industry consensus is that 6G will be “AI-native,” meaning artificial intelligence will be built directly into the core functions of network control, resource management, and service orchestration. This moves AI from an optimization layer in 5G to an foundational element in 6G.
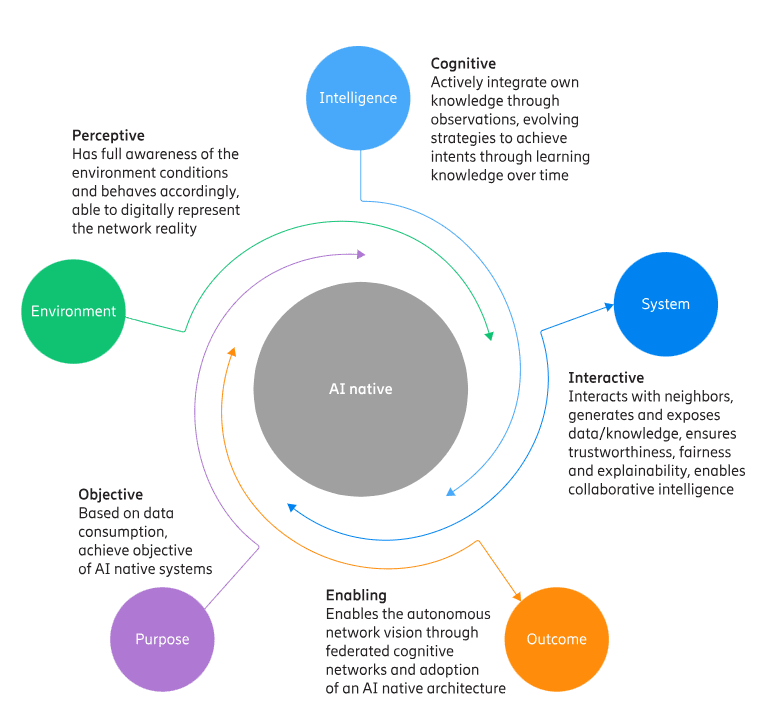
AI Native Image Courtesy of Ericsson
…………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
- Company Initiatives:
- Huawei is focused on making AI a native element of the network architecture (AI-native 6G) rather than an overlay technology, integrating communication, sensing, computing, and intelligence. This vision, called “Connected Intelligence,” involves two aspects: AI for 6G (network automation) and 6G for AI (AI as a Service, AIaaS). More in Huawei Research Areas below.
- Samsung is a major proponent of AI-RAN (Radio Access Network) technology. The company hosted a summit in November 2025 to showcase working AI-RAN technology that autonomously optimizes network performance and is conducting joint research with SK Telecom (SKT) on AI-supported RAN. Samsung sees vRAN (virtualized RAN) as a key enabler for “AI-native, 6G-ready networks”.
- Ericsson emphasizes the necessity of a strong 5G Standalone (5G SA) foundation for an AI future, using AI to manage and automate current networks in preparation for 6G’s demands. Ericsson is also integrating agentic AI into its platforms for more autonomous network management.
- Nokia is deepening its AI push, licensing software to expand AI use in mobile networks and preparing for early field trials in 2026 by porting baseband software to platforms like NVIDIA’s, which opens the door for more advanced AI use cases.
- Industry Analysis and Trends:
- Standardization: 2026 is crucial as formal 6G specification work begins in earnest within 3GPP with Release 21. In WP5D, the IMT 2030 RIT/SRIT standardization work will commence at the February 2027 meeting with the final deadline for submissions at the February 2029 meeting. More in the ITU-R WP5D section below.
- The AI-RAN Alliance is an industry initiative (not a traditional SDO) focused on accelerating real-world AI applications and integration within the RAN. It works alongside SDOs, providing industry insights and pushing for rapid validation and testing of AI-RAN technologies, with a specific focus on leveraging accelerated computing.
- Automation and Efficiency: AI-native algorithms in 6G are expected to deliver extreme spectrum and energy efficiency, significantly reducing operational costs for telcos while improving reliability and performance.
- Monetization Challenges: Despite the technological promise, analysts caution that 6G remains largely theoretical for now. Some operators are stalling on full 5G SA deployment, waiting to move to 6G-ready cores later in the decade, leading to concerns that 5G SA might become an “odd generation.”
- Infrastructure Constraints: The physical demands of AI infrastructure, particularly energy consumption and construction timelines, are becoming operational realities that may bound the pace of AI growth in 2026, regardless of software advancements.
- ITU-R Working Party (WP) 5D is making AI a native and foundational element of the 6G (IMT-2030) system, rather than the “add-on” or “overlay” status it had in 5G (IMT 2020). This shift is being achieved through the definition of specific AI capabilities and requirements that future 6G technologies must inherently support. In particular:
- Defining AI as a Core Capability: The Recommendation ITU-R M.2160 (“Framework and overall objectives of the future development of IMT for 2030 and Beyond”) officially defines “Artificial Intelligence and Communication” as one of the six major usage scenarios and an overarching design principle for IMT-2030.
- Integrating AI into the Radio Interface: WP 5D is actively developing technical performance requirements (TPRs) and evaluation criteria for proposed 6G radio interface technologies (RITs) that inherently incorporate AI/Machine Learning (ML). This includes work on:
- AI-enabled air interface design: This involves the physical layer, potentially moving towards AI-native physical (PHY) layers that can dynamically adapt waveforms and network parameters in real-time, rather than relying on predefined, static configurations.
- AI-driven resource management: AI/ML algorithms will be crucial for real-time optimization of spectral and energy efficiency, managing complex traffic, and ensuring Quality of Service (QoS).
- Enabling AI-Driven Services: The framework for IMT-2030 is designed to support the full lifecycle of AI components, from data collection and model training to deployment and performance monitoring, enabling new AI-driven services and applications directly within the network infrastructure.
- Establishing a Formal Timeline: WP 5D has established a clear timeline for 6G standardization, with specific stages for vision, requirements, evaluation methodology, and specifications. This structured approach ensures that all proposed RITs/SRITs are evaluated against the new AI-native requirements, promoting global alignment and preventing AI from becoming a fragmented, proprietary solution.
- Stage 1 (Vision): Completed in June 2023.
- Stage 2 (Requirements & Evaluation): Targeted for completion in 2026.
- Stage 3 (Specifications): Expected by the end of 2030.
- Purpose: AI is integral to the entire network lifecycle, from initial design and deployment to autonomous operation and service creation.
- Integration Level: Intelligence is embedded across all layers of the network stack, including the physical layer (air interface), control plane, and data plane.
- Scope: AI enables core functionalities such as real-time self-optimization, self- healing capabilities, and dynamic resource allocation, rather than static, predefined configurations.
- Outcome: The creation of a fully cognitive, self-managing, and highly adaptable “intelligence fabric” capable of supporting advanced use cases like real-time holographic communication, digital twins, and autonomous systems with ultra-low latency.
| Feature | 5G (IMT-2020) | 6G (IMT-2030) |
|---|---|---|
| AI Role | Optimization tool (overlay) | Foundational and native element |
| Network Operation | Manual configuration with AI assistance | Autonomous and self-managing |
| Air Interface | Human-designed with some ML optimization | AI/ML-designed and managed |
| Complexity Management | Relies on standard protocols | Manages complexity through embedded AI/ML |
| Services Supported | Enhanced mobile broadband, basic IoT | Integrated AI & Communication, sensing, holographic comms |
–>By embedding AI into the fundamental design principles and technical requirements of IMT-2030, ITU-R WP 5D is ensuring that 6G is an AI-native network capable of self-management, self-optimization, and supporting a vast ecosystem of AI applications, a significant shift from the supplementary role AI played in 5G.
- Agentic-AI Core (A-Core): Huawei unveiled a blueprint for a 6G core network (which will be specified by 3GPP and NOT ITU) where services are managed by specialized AI agents using a large-scale network AI model called “NetGPT”. This allows the network to program, update, and execute its own control procedures automatically without human intervention, based on natural language instructions.
- Network Architecture Redesign: Huawei proposes the NET4AI system architecture, a service-oriented design that moves beyond the 5G service-based architecture. It introduces a dedicated data plane (DP) to handle the massive volume of data generated by AI and sensing services, enabling flexible and efficient many-to-many data flow for distributed learning and inference.
- Integrated Sensing and Communication (ISAC): A core pillar of Huawei’s 6G work is the native integration of sensing with communication. This allows the network to use radio waves for high-resolution sensing, localization, and imaging, creating a “digital twin” of the physical world. The large volume of data collected from sensing then serves as a source for AI model training and real-time environmental monitoring.
- Distributed Machine Learning: Huawei researches deep-edge architecture to enable massive, distributed, and collaborative machine learning (ML). This includes the development of frameworks like a two-level learning architecture that combines federated learning (FL) and split learning (SL) to optimize computing resources and ensure data privacy by keeping raw data local to devices.
- AI as a Service (AIaaS): The 6G network is designed to provide AI capabilities as a service, allowing the training and inference of large AI models to be distributed across the network (edge and cloud). This offers low-latency performance and access to rich data for AI-driven applications like collaborative robotics and autonomous driving.
- Energy Efficiency and Sustainability: The company is researching how native AI capabilities can improve overall energy efficiency by up to 100 times compared to 5G. This involves smart energy control, dynamic resource scaling, and optimizing communication paths for lower power consumption.
- Standardization and White Papers: Huawei is actively contributing to global 6G discussions and standardization bodies like the ITU-R, sharing its vision through publications such as the book 6G: The Next Horizon – From Connected People and Things to Connected Intelligence and various technical white papers. The goal is to define the technical specifications and use cases for 6G that will drive industry-wide innovation by around 2030.
References:
https://www.ericsson.com/en/reports-and-papers/white-papers/ai-native
Roles of 3GPP and ITU-R WP 5D in the IMT 2030/6G standards process
AI wireless and fiber optic network technologies; IMT 2030 “native AI” concept
ITU-R WP5D IMT 2030 Submission & Evaluation Guidelines vs 6G specs in 3GPP Release 20 & 21
ITU-R WP 5D Timeline for submission, evaluation process & consensus building for IMT-2030 (6G) RITs/SRITs
ITU-R WP 5D reports on: IMT-2030 (“6G”) Minimum Technology Performance Requirements; Evaluation Criteria & Methodology
AI wireless and fiber optic network technologies; IMT 2030 “native AI” concept
Highlights of 3GPP Stage 1 Workshop on IMT 2030 (6G) Use Cases
Should Peak Data Rates be specified for 5G (IMT 2020) and 6G (IMT 2030) networks?
GSMA Vision 2040 study identifies spectrum needs during the peak 6G era of 2035–2040
Highlights and Summary of the 2025 Brooklyn 6G Summit
NGMN: 6G Key Messages from a network operator point of view
Nokia and Rohde & Schwarz collaborate on AI-powered 6G receiver years before IMT 2030 RIT submissions to ITU-R WP5D
Verizon’s 6G Innovation Forum joins a crowded list of 6G efforts that may conflict with 3GPP and ITU-R IMT-2030 work
Nokia Bell Labs and KDDI Research partner for 6G energy efficiency and network resiliency
Deutsche Telekom: successful completion of the 6G-TakeOff project with “3D networks”
Market research firms Omdia and Dell’Oro: impact of 6G and AI investments on telcos
Qualcomm CEO: expect “pre-commercial” 6G devices by 2028
Ericsson and e& (UAE) sign MoU for 6G collaboration vs ITU-R IMT-2030 framework
KT and LG Electronics to cooperate on 6G technologies and standards, especially full-duplex communications
Highlights of Nokia’s Smart Factory in Oulu, Finland for 5G and 6G innovation
Nokia sees new types of 6G connected devices facilitated by a “3 layer technology stack”
Rakuten Symphony exec: “5G is a failure; breaking the bank; to the extent 6G may not be affordable”
India’s TRAI releases Recommendations on use of Tera Hertz Spectrum for 6G
New ITU report in progress: Technical feasibility of IMT in bands above 100 GHz (92 GHz and 400 GHz)
Telecom operators investing in Agentic AI while Self Organizing Network AI market set for rapid growth
Telecom companies are planning to use Agentic AI [1.] for customer experience and network automation. A recent RADCOM survey shows 71% of network operators plan to deploy agentic AI in 2026, while 14% have already begun, prioritizing areas that directly influence trust and customer satisfaction: security and fraud prevention (57%) and customer service and support (56%). The top use cases are automated customer complaint resolution and autonomous fault resolution.
Operators are betting on agentic AI to remove friction before customers feel it, with the highest-value use cases reflecting this shift, including:
- 57% – automated customer complaint resolution
- 54% – autonomous fault resolution before it impacts service
- 52% – predicting experience to prevent churn
This technology is shifting networks from simply detecting issues to preventing them before customers notice. In contact centers, 2026 is expected to see a rise in human and AI agent collaboration to improve efficiency and customer service.
Note 1. Agentic AI refers to autonomous artificial intelligence systems that can perceive, reason, plan, and act independently to achieve complex goals with minimal human intervention, going beyond simple command-response to manage multi-step tasks, use various tools, and adapt to new information for proactive automation in dynamic environments. These intelligent agents function like digital coworkers, coordinating internally and with other systems to execute sophisticated workflows.
……………………………………………………………………………………………………………………………………………………………………………………………
ResearchAndMarkets.com has just published a “Self-Organizing Network Artificial Intelligence (AI) Global Market Report 2025.” The market research firm says that the self-organizing network AI [2.] is forecast to expand from $5.19 billion in 2024 to $6.18 billion in 2025, at a CAGR of 19.2%. This surge is driven by the integration of machine learning and AI in telecom networks, smart network management investment, and the growing demand for features like self-healing and self-optimization, as well as predictive maintenance technologies.driven by the expansion of 5G, increasing automation demands, and AI integration for network optimization. Opportunities include AI-driven RRM and predictive maintenance. Asia-Pacific emerges as the fast-growing region, boosting telecom innovations amid global trade shifts.
Note 2. Self-organizing network AI leverages software, hardware, and services to dynamically optimize and manage telecom networks, applicable across various network types and deployment modes. The market encompasses a broad range of solutions, from network optimization software to AI-driven planning products, underscoring its expansive potential.

Looking further ahead, the market is expected to reach $12.32 billion by 2029, with a CAGR of 18.8%. Key drivers during this period include heightened demand for automation, increased 5G deployments, and growing network densification, accompanied by rising data traffic and subscriber numbers. Trends such as AI-driven network automation advancements, machine learning integration for real-time optimization, and the rise of generative AI for analytics are reshaping the landscape.
The expansion of 5G networks plays a pivotal role in propelling this growth. These networks, characterized by high-speed data and ultra-low latency, significantly enhance the capabilities of self-organizing network AI. The integration facilitates real-time data processing, supporting automation, optimization, and predictive maintenance, thereby improving service quality and user experience. A notable development in 2023 saw UK outdoor 5G coverage rise to 85-93%, reflecting growing demand and technological advancement.
Huawei Technologies and other major tech companies, are pioneering innovative solutions like AI-driven radio resource management (RRM), which optimizes network performance and enhances user experience. These solutions rely on AI and machine learning for dynamic spectrum and network resource management. For instance, Huawei’s AI Core Network, introduced at MWC 2025, marks a substantial leap in intelligent telecommunications, integrating AI into core systems for seamless connectivity and real-time decision-making.
Strategic acquisitions are also shaping the market, exemplified by Amdocs Limited acquiring TEOCO Corporation in 2023 to bolster its network optimization and analytics capabilities. This acquisition aims to enhance end-to-end network intelligence and operational efficiency.
Leading players in the market include Huawei, Cisco Systems Inc., Qualcomm Incorporated, and many others, driving innovation and competition. Europe held the largest market share in 2024, with Asia-Pacific poised to be the fastest-growing region through the forecast period.
References:
Operator Priorities for 2026 and Beyond: Data, Automation, Customer Experience
https://uk.finance.yahoo.com/news/self-organizing-network-artificial-intelligence-105400706.html
Ericsson integrates agentic AI into its NetCloud platform for self healing and autonomous 5G private network
Agentic AI and the Future of Communications for Autonomous Vehicles (V2X)
IDC Report: Telecom Operators Turn to AI to Boost EBITDA Margins
Omdia: How telcos will evolve in the AI era
Palo Alto Networks and Google Cloud expand partnership with advanced AI infrastructure and cloud security
Sovereign AI infrastructure for telecom companies: implementation and challenges
Sovereign AI infrastructure refers to the domestic capability of a nation or an organization to own and control the entire technology stack for artificial intelligence (AI) systems within its own borders, subject to local laws and governance. This includes the physical data centers, specialized hardware (like GPUs), software, data, and skilled workforce. Sovereign AI infrastructure involves a full “stack” designed to ensure national control and reduce reliance on foreign providers. A few key features:
- Policies and technical controls (e.g., data localization, encryption) to ensure that sensitive data used for training and inference remains within the jurisdiction.
- Development and hosting of proprietary or locally tailored AI models and software frameworks that align with national values, languages, and ethical standards.
- Workforce Development: Investing in domestic talent, including data scientists, engineers, and legal experts, to build and maintain the local AI ecosystem.
- Regulatory Framework: A comprehensive legal and ethical framework for AI development and deployment that ensures compliance with national laws and standards.
Why It’s Important – The pursuit of sovereign AI infrastructure is driven by several strategic considerations for both governments and private enterprises:
- National Security: To ensure that critical systems in defense, intelligence, and public infrastructure are not dependent on potentially adversarial foreign technologies or subject to extraterritorial access laws (like the U.S. CLOUD Act).
- Economic Competitiveness: To foster a domestic tech industry, create high-skilled jobs, protect intellectual property, and capture the significant economic benefits of AI-driven growth.
- Data Privacy and Compliance: To comply with stringent local data protection regulations (e.g., GDPR in the EU) and build public trust by ensuring citizen data is handled securely and according to local laws. Cultural Preservation: To train AI models on local datasets and languages, preserving cultural nuances and avoiding bias found in generalized, globally trained models.

Image Credit: Nvidia
………………………………………………………………………………………………………………………………………………………………………………………………………..
Governments around the world are starting to build sovereign AI infrastructure, and according to a new report from Morningstar DBRS, which opines that major telecommunications companies are uniquely positioned to benefit from that shift. Here are a few take-aways from the report:
- Sovereign AI funding opens a new growth path for telcos – Governments investing in domestic AI infrastructure are increasingly turning to operators, whose network and regulatory strengths position them to capture a large share of this emerging market.
- Telcos’ capabilities align with sovereignty needs – Their expertise in large-scale networks, local presence, and established government relationships give them an edge over hyperscalers for sensitive, sovereignty-focused AI projects.
- Early adopters gain advantage – Operators in Canada and Europe are already moving into sovereign AI, positioning themselves to secure higher-margin enterprise and government workloads as national AI buildouts accelerate.
- Infrastructure Demands: Building robust domestic AI ecosystems requires specialized expertise spanning hardware, software, data governance, and policy.
- Resource Constraints: Dr. Matt Hasan, CEO at aiRESULTS and a former AT&T executive, highlights specific bottlenecks:
- Compute Density at Scale.
- Spectrum Allocation amidst political pressures.
- Energy Demand exceeding existing grid capacity.
- Intensified Reliability Requirements: Sovereign AI implementation places heightened demands on telecom providers for system uptime, reliability, quality, and data privacy. This necessitates a focus on efficient power consumption, resilient routing and backups, robust encryption, and comprehensive cybersecurity measures.
- Supply Chain Vulnerabilities: Geopolitical tensions introduce risks to the supply of critical components such as GPUs and specialized chips, underscoring the interconnected nature of global hardware supply chains.
- The rapid evolution of AI technology mandates continuous investment and technical agility to ensure sovereign deployments remain current.
- The interplay between global hyperscalers and regional telecom operators is expected to shift.
- Hasan predicts a collaborative model, with regional telcos leveraging their position as sovereign partners through joint ventures, rather than an outright displacement of hyperscalers.
References:
Telcos Across Five Continents Are Building NVIDIA-Powered Sovereign AI Infrastructure
https://www.rcrwireless.com/20251202/ai/sovereign-ai-telcos
Subsea cable systems: the new high-capacity, high-resilience backbone of the AI-driven global network
Analysis: OpenAI and Deutsche Telekom launch multi-year AI collaboration
AI infrastructure spending boom: a path towards AGI or speculative bubble?
Market research firms Omdia and Dell’Oro: impact of 6G and AI investments on telcos
Omdia: How telcos will evolve in the AI era
OpenAI announces new open weight, open source GPT models which Orange will deploy
Expose: AI is more than a bubble; it’s a data center debt bomb
Can the debt fueling the new wave of AI infrastructure buildouts ever be repaid?
Custom AI Chips: Powering the next wave of Intelligent Computing
AI spending boom accelerates: Big tech to invest an aggregate of $400 billion in 2025; much more in 2026!
IBM and Groq Partner to Accelerate Enterprise AI Inference Capabilities
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
AI wireless and fiber optic network technologies; IMT 2030 “native AI” concept
To date, the main benefit of AI for telecom has been to reduce headcount/layoff employees. Light Reading’s Iain Morris wrote, “Telecom operators and vendors, nevertheless, are already using AI as the excuse for thousands of job cuts made and promised. So far, those cuts have not brought any improvement in the sector’s fortunes. Meanwhile, ceding basic but essential skills to systems that hardly anyone understands seems incredibly risky.” Some say that will change with 6G/ IMT 2030, but that’s a long way off. Others point to AI RAN, but that has not gotten any real market traction with wireless telcos.
As Gen AI development accelerates, robust wireless and fiber optic network infrastructure will be essential to accommodate the substantial data and communication volume generated by AI systems. Initially, the existing network ecosystem—encompassing wireless, wireline, broadband, and satellite services—will absorb this traffic load. However, the expanding requirements of AI are anticipated to drive the future emergence of entirely new network architectures and communication paradigms.
For sure, AI needs massive, fast, reliable connectivity to function, driving demand for low latency optical networks and 6G/ IMT 2030, which AI itself will optimize, leading to better efficiency, security, resource management, and new services like real-time AR/VR, ultimately boosting telecom revenue and innovation across the entire digital ecosystem.
![]()
Source: Pitinan Piyavatin/Alamy Stock Photo
……………………………………………………………………………………………………………………………………………………………………..
- AI Backend Scale-Out and Scale-Up Networks: These are specialized, private networks within and across data centers designed to connect numerous GPUs and enable them to function as one massive compute resource. They utilize technologies like:
- InfiniBand: A long-standing high-bandwidth, low-latency technology that has become a top choice for connecting GPU clusters in AI training environments.
- Optimized Ethernet: Ethernet is gaining ground for AI workloads through the development of enhanced, open standards via the Ultra Ethernet Consortium (UEC). These enhancements aim to provide lossless, low-latency fabrics that can match or exceed InfiniBand’s performance at scale.
- High-Speed Optics: The use of 400 Gbps and 800 Gbps (and soon 1.6 Tbps) optical interconnects is critical for meeting the massive bandwidth and power requirements within and between AI data centers.
- Edge AI Networking: As AI inferencing (generating responses from AI models) moves closer to the end-user or device (e.g., in autonomous vehicles, smart hospitals, or factories), specialized edge networks are needed. These networks must ensure low latency and localized processing to enable real-time responses.
- AI-Native 6G Networks: The upcoming sixth-generation (6G) wireless networks are being designed with AI integration as a core principle, rather than an add-on.
- These networks are expected to be fully automated and self-evolving, using AI to optimize resource allocation, predict issues, and enhance security autonomously.
- They will support extremely high data rates (up to 1 Tbps), ultra-low latency (around 1 ms), and new technologies like AI-RAN (Radio Access Network) that integrate AI capabilities directly into the network infrastructure.
- More in next section below.
- Self-Evolving Networks: The ultimate goal is the development of “self-evolving networks” where AI agents manage and optimize the network infrastructure autonomously, adapting to new demands and challenges without human intervention.
……………………………………………………………………………………………………………………………………………………………………..
In IMT 2030/6G networks, AI will shift from being an “add-on” optimization tool (as in 5G) to a native, foundational component of the entire network architecture. This deep integration will enable the network to be self-organizing, highly efficient, and capable of supporting advanced AI applications as a service. Native AI for IMT-2030 (6G) means building AI directly into the network’s core architecture, making it AI-first and pervasive, rather than adding AI as an overlay; this enables self-optimizing, intelligent networks that can autonomously manage resources, provide ubiquitous AI services, and offer seamless, context-aware experiences with minimal human intervention, fundamentally transforming both network operations and user applications by 2030.
- Ubiquitous Intelligence: Embedding AI everywhere, enabling distributed intelligence for AI model training, inference, and deployment directly within the network infrastructure, extending to the network edge.
- Autonomous Operations: AI handles complex tasks like network optimization, resource allocation, and automated maintenance (O&M) in real-time, reducing reliance on manual intervention.
- AI-as-a-Service (AIaaS): The network transforms into a unified platform providing both communication and AI capabilities, making AI accessible for various applications.
- Intelligent Processing: AI drives functions across the air interface, resource management, and control planes for highly efficient operations.
- Data-Driven Automation: Leverages big data and real-time analytics to predict issues, optimize performance, and automate complex decision-making.
- Seamless User Experience: Moves beyond touchscreens to AI-driven interactions, offering more natural and contextual computing.
- Autonomous Operations: AI will enable self-monitoring, self-optimization, and self-healing networks, drastically reducing the need for human intervention in operation and maintenance (O&M).
- Dynamic Resource Management: ML algorithms will analyze massive amounts of network data in real-time to predict traffic patterns and user demands, dynamically allocating bandwidth, power, and computing resources to ensure optimal performance and energy efficiency.
- AI-Native Air Interface: AI/ML models will replace traditional, manually engineered signal processing blocks in the physical layer (e.g., channel estimation, beam management) to adapt dynamically to complex and time-varying wireless environments, improving spectral efficiency.
- Enhanced Security: AI will be critical for real-time threat detection and automated incident response across the hyper-connected 6G ecosystem, identifying anomalies and mitigating security risks that are not well understood by current systems.
- Digital Twins: AI will power the creation and management of real-time digital twins (virtual replicas) of the physical network, allowing for sophisticated simulations and testing of network changes before real-world deployment.
- Pervasive Edge AI: AI model training and inference will be distributed throughout the network, from the cloud to the edge (devices, base stations), reducing latency and enabling real-time, localized decision-making for applications like autonomous driving and industrial automation.
- Support for Advanced Use Cases: The massive data rates (up to 1 Tbps), ultra-low latency, and high reliability enabled by AI in 6G will facilitate new applications such as holographic communication, remote robotic surgery with haptic feedback, and collaborative robotics that were not feasible with 5G.
- Federated Learning: The network will support distributed machine learning techniques, such as federated learning, which allow AI models to be trained on local data across various devices without the need to centralize sensitive user data, thus ensuring data privacy and security.
- Integrated Sensing and Communication (ISAC): AI will process the rich environmental data gathered through 6G’s new sensing capabilities (e.g., precise positioning, motion detection, environmental monitoring), allowing the network to interact with and understand the physical world in a holistic manner for applications like smart city management or augmented reality.
……………………………………………………………………………………………………………………………………………………………………..
AI‑native air interface and RAN:
IMT‑2030 explicitly expects a new AI‑native air interface that uses AI/ML models for core PHY/MAC functions such as channel estimation, symbol detection/decoding, beam management, interference handling, and CSI feedback. This enables adaptive waveforms and link control that react in real time to channel and traffic conditions, going beyond deterministic algorithms in 5G‑Advanced.
At the RAN level, IMT‑2030 envisions “native‑AI enabled” architectures that are simpler but more intelligent, with data‑driven operation and distributed learning across gNBs, edge nodes, and devices. AI/ML will be applied end‑to‑end for resource allocation, mobility, energy optimization, and fault management, effectively turning the RAN into a self‑optimizing, self‑healing system.
Integrated AI and communication services:
The framework defines “Artificial Intelligence and Communication” (often phrased as Integrated AI and Communication) as a specific usage scenario where the network provides AI compute, model hosting, and inference as a service. Example use cases include IMT‑2030‑assisted automated driving, cooperative medical robotics, digital twins, and offloading heavy computation from devices to edge/cloud via the 6G network.
To support this, IMT‑2030 includes “applicable AI‑related capabilities” such as distributed data processing, distributed learning, AI model execution and inference, and AI‑aware scheduling as native capabilities of the system. Computing and data services (not just connectivity) are treated as integral IMT‑2030 components, especially at the edge for low‑latency, energy‑efficient AI workloads.
System intelligence and new use cases:
AI is central to several new IMT‑2030 usage scenarios beyond classic eMBB/mMTC/URLLC, including Immersive Communication, Integrated Sensing and Communication, and Integrated AI and Communication. In integrated sensing, AI fuses multi‑dimensional radio sensing data (position, motion, environment, even human behavior) to provide contextual awareness for applications like smart cities, industrial control, and XR.
Embedding intelligence across air interface, edge, and cloud is seen as necessary to manage 6G complexity and enable “Intelligence of Everything,” including real‑time digital twins and AIGC‑driven services. The vision is for the 6G/IMT‑2030 network to act as a distributed neural system that tightly couples communication, sensing, and computing.
IMT 2030 Goals:
- To create self-healing, self-optimizing networks that can adapt to diverse demands.
- To enable new AI-driven applications, from intelligent digital twins to advanced immersive experiences.
- To build a truly intelligent communication fabric that supports a hyper-connected, AI-enhanced world.
Summary table: AI’s roles in IMT‑2030:
| Dimension | AI role in IMT‑2030 |
|---|---|
| Air interface | AI‑native PHY/MAC for channel estimation, decoding, beamforming, interference control. |
| RAN/core architecture | Native‑AI enabled, data‑driven, self‑optimizing/self‑healing network functions. |
| Compute and data services | Built‑in edge/cloud compute for AI training, inference, and data processing. |
| Usage scenarios | Dedicated “Integrated AI and Communication” plus AI‑rich sensing and immersive use cases. |
| Applications and ecosystems | Support for digital twins, automated driving, robotics, AIGC, and industrial automation. |
In summary, AI in IMT‑2030 is both an internal engine for network intelligence and an exported capability the network offers to verticals, making 6G effectively AI‑native end‑to‑end.
………………………………………………………………………………………………………………………………………………
References:
https://www.lightreading.com/ai-machine-learning/the-lessons-of-pluribus-for-telecom-s-genai-fans
https://www.ericsson.com/en/reports-and-papers/white-papers/ai-native
https://www.5gamericas.org/wp-content/uploads/2024/08/ITUs-IMT-2030-Vision_Id.pdf
ITU-R WP 5D Timeline for submission, evaluation process & consensus building for IMT-2030 (6G) RITs/SRITs
ITU-R WP 5D reports on: IMT-2030 (“6G”) Minimum Technology Performance Requirements; Evaluation Criteria & Methodology
Ericsson and e& (UAE) sign MoU for 6G collaboration vs ITU-R IMT-2030 framework
Nokia and Rohde & Schwarz collaborate on AI-powered 6G receiver years before IMT 2030 RIT submissions to ITU-R WP5D
NTT DOCOMO successful outdoor trial of AI-driven wireless interface with 3 partners
Verizon’s 6G Innovation Forum joins a crowded list of 6G efforts that may conflict with 3GPP and ITU-R IMT-2030 work
ITU-R WP5D IMT 2030 Submission & Evaluation Guidelines vs 6G specs in 3GPP Release 20 & 21
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
Highlights of 3GPP Stage 1 Workshop on IMT 2030 (6G) Use Cases
Draft new ITU-R recommendation (not yet approved): M.[IMT.FRAMEWORK FOR 2030 AND BEYOND]
Analysis: OpenAI and Deutsche Telekom launch multi-year AI collaboration
Deutsche Telekom (DT) has formalized a strategic, multi-year collaboration with OpenAI to integrate advanced artificial intelligence (AI) solutions across its internal operations and customer engagement platforms. The partnership aims to co-develop “simple, personal, and multi-lingual AI experiences” focused on enhancing communication and productivity. Initial pilot programs are slated for deployment in Q1 2026. AI will also play a larger role in customer care, internal copilots, and network operations as the Group advances toward more autonomous, self-healing networks.DT plans a company-wide rollout of ChatGPT Enterprise, leveraging AI to streamline core functions including:
- Customer Care: Deploying sophisticated virtual assistants to manage billing inquiries, service outages, plan modifications, roaming support, and device troubleshooting [1].
- Internal Operations: Utilizing AI copilots to increase internal efficiency.
- Network Management: Optimizing core network provisioning and operations.
- Sovereign Cloud (2021): DT’s T-Systems division partnered with Google Cloud to offer sovereign cloud services.
- T Cloud Suite (Early 2025): The launch of a comprehensive suite providing sovereign public, private, and AI cloud options leveraging hybrid infrastructure.
- Industrial AI Cloud (Early 2025): A collaboration with Nvidia to build a dedicated industrial AI data center in Munich, scheduled for Q1 2026 operations.

- Edge AI compute services for enterprises.
- Vertical AI solutions tailored for healthcare, retail, and manufacturing sectors.
- Integrated private 5G and AI bundles for industrial logistical hubs.
“Telcos – if they execute – will have a big play in the edge inferencing space as well as providing hosting and colo services that can host domain specific SLMs that need to be run closer to the user data,” he said. “Furthermore, telcos will play a role in connectivity services across Neocloud providers such as CoreWeave, Lambda Labs, Digital Ocean, Vast.AI etc. OpenAI does not want to lose the opportunity to partner with telcos so they are striking early,” Nag added.
Other Voices:
- Roger Entner notes the model is highly applicable to European incumbents (e.g., Orange, Telefonica) due to the relative scarcity of existing AI data centers in the region, allowing operators to fill a critical infrastructure gap. Conversely, the model is less viable for U.S. operators, where hyperscalers already dominate the extensive data center market.
- AvidThink Founder and colleague Roy Chua cautions that while DT presents a robust “reference blueprint,” replicating this strategy requires significant scale, substantial financial investment, and regulatory alignment—factors not easily accessible to all network operators.
- Futurum Group VP and Practice Lead Nick Patience told Fierce Network, “This deal elevates DT from being a user of AI to being a co-developer, which is pretty significant. DT is one of the few operators building a full-stack AI story. This is an example of OpenAI treating telcos as high-scale distribution and data channels – customer care, billing, network telemetry, national reach and government relationships. This suggests OpenAI is deliberately building an operator channel in key regions (U.S., Korea, EU) but still in partnership with existing cloud and infra providers rather than displacing them.”
OpenAI has established significant partnerships with several telecom network providers and related technology companies to integrate AI into network operations, enhance customer experience, and develop new AI-native platforms. Those deals and collaborations include:
- T-Mobile: T-Mobile has a multi-year agreement with OpenAI and is actively testing the integration of AI (specifically IntentCX) into its business operations for customer service improvements. T-Mobile is also collaborating with Nokia and Nvidia on AI-RAN (Radio Access Network) technologies for 6G innovation.
- SK Telecom (SKT): SK Telecom has an in-house AI company and collaborates with OpenAI and other AI leaders like Anthropic to enhance its AI capabilities, build sovereign AI infrastructure, and explore new services for its customers in South Korea and globally. They are also reportedly integrating Perplexity into their offerings.
- Deutsche Telekom (DT): DT is partnering with OpenAI to offer ChatGPT Enterprise across its business to help teams work more effectively, improve customer service, and automate network operations.
- Circles: This global telco technology company and OpenAI announced a strategic global collaboration to build a fully AI-native telco SaaS platform, which will first launch in Singapore. The platform aims to revolutionize the consumer experience and drive operational efficiencies for telcos worldwide.
- Rakuten: Rakuten and OpenAI launched a strategic partnership to develop AI tools and a platform aimed at leveraging Rakuten’s Open RAN expertise to revolutionize the use of AI in telecommunications.
- Orange: Orange is working with OpenAI to drive new use cases for enterprise needs, manage networks, and enable innovative customer care solutions, including those that support African regional languages.
- Indian Telecoms (Reliance Jio, Airtel): Telecom providers in India are integrating AI tools from companies like Google and Perplexity into their mobile subscriptions, providing millions of users access to advanced intelligence resources.
- Nokia & Nvidia: In a broader industry collaboration, Nvidia invested $1 billion in Nokia to add Nvidia-powered AI-RAN products to Nokia’s portfolio, enabling telecom service providers to launch AI-native 5G-Advanced and 6G networks. This partnership also includes T-Mobile US for testing.
Conclusions:
With more than 261 million mobile customers globally, Deutsche Telekom provides a strong foundation to bring AI into everyday use at scale. The new collaboration marks the next step in Deutsche Telekom’s AI journey – moving from early pilots to large-scale products that make AI useful for everyone
References:
https://www.telekom.com/en/media/media-information/archive/openai-and-telekom-collaborate-1100164
https://www.telekom.com/en/company/companyprofile/company-profile-625808
Deutsche Telekom: successful completion of the 6G-TakeOff project with “3D networks”
Deutsche Telekom and Google Cloud partner on “RAN Guardian” AI agent
Deutsche Telekom offers 5G mmWave for industrial customers in Germany on 5G SA network
Deutsche Telekom migrates IP-based voice telephony platform to the cloud
Open AI raises $8.3B and is valued at $300B; AI speculative mania rivals Dot-com bubble
OpenAI and Broadcom in $10B deal to make custom AI chips
Custom AI Chips: Powering the next wave of Intelligent Computing
OpenAI orders HBM chips from SK Hynix & Samsung for Stargate UAE project
OpenAI announces new open weight, open source GPT models which Orange will deploy
OpenAI partners with G42 to build giant data center for Stargate UAE project
Reuters & Bloomberg: OpenAI to design “inference AI” chip with Broadcom and TSMC
AI infrastructure spending boom: a path towards AGI or speculative bubble?
by Rahul Sharma, Indxx with Alan J Weissberger, IEEE Techblog
Introduction:
The ongoing wave of artificial intelligence (AI) infrastructure investment by U.S. mega-cap tech firms marks one of the largest corporate spending cycles in history. Aggregate annual AI investments, mostly for cloud resident mega-data centers, are expected to exceed $400 billion in 2025, potentially surpassing $500 billion by 2026 — the scale of this buildout rivals that of past industrial revolutions — from railroads to the internet era.[1]
At its core, this spending surge represents a strategic arms race for computational dominance. Meta, Alphabet, Amazon and Microsoft are racing to secure leadership in artificial intelligence capabilities — a contest where access to data, energy, and compute capacity are the new determinants of market power.
AI Spending & Debt Financing:
Leading technology firms are racing to secure dominance in compute capacity — the new cornerstone of digital power:
- Meta plans to spend $72 billion on AI infrastructure in 2025.
- Alphabet (Google) has expanded its capex guidance to $91–93 billion.[3]
- Microsoft and Amazon are doubling data center capacity, while AWS will drive most of Amazon’s $125 billion 2026 investment.[4]
- Even Apple, typically conservative in R&D, has accelerated AI infrastructure spending.
Their capex is shown in the chart below:
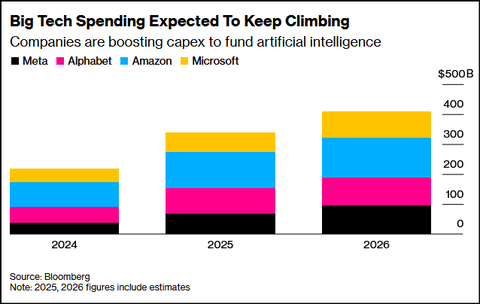
Analysts estimate that AI could add up to 0.5% to U.S. GDP annually over the next several years. Reflecting this optimism, Morgan Stanley forecasts $2.9 trillion in AI-related investments between 2025 and 2028. The scale of commitment from Big Tech is reshaping expectations across financial markets, enterprise strategies, and public policy, marking one of the most intense capital spending cycles in corporate history.[2]
Meanwhile, OpenAI’s trillion-dollar partnerships with Nvidia, Oracle, and Broadcom have redefined the scale of ambition, turning compute infrastructure into a strategic asset comparable to energy independence or semiconductor sovereignty.[5]
Growth Engine or Speculative Bubble?
As Big Tech pours hundreds of billions of dollars into AI infrastructure, analysts and investors remain divided — some view it as a rational, long-term investment cycle, while others warn of a potential speculative bubble. Yet uncertainty remains — especially around Meta’s long-term monetization of AGI-related efforts.[8]
Some analysts view this huge AI spending as a necessary step towards achieving Artificial General Intelligence (AGI) – an unrealized type of AI that possesses human-level cognitive abilities, allowing it to understand, learn, and adapt to any intellectual task a human can. Unlike narrow AI, which is designed for specific functions like playing chess or image recognition, AGI could apply its knowledge to a wide range of different situations and problems without needing to be explicitly programmed for each one.
Other analysts believe this is a speculative bubble, fueled by debt that can never be repaid. Tech sector valuations have soared to dot-com era levels – and, based on price-to-sales ratios, are well beyond them. Some of AI’s biggest proponents acknowledge the fact that valuations are overinflated, including OpenAI chairman Bret Taylor: “AI will transform the economy… and create huge amounts of economic value in the future,” Taylor told The Verge. “I think we’re also in a bubble, and a lot of people will lose a lot of money,” he added.
Here are a few AI bubble points and charts:
- AI-related capex is projected to consume up to 94% of operating cash flows by 2026, according to Bank of America.[6]
- Over $75 billion in AI-linked corporate bonds have been issued in just two months — a signal of mounting leverage. Still, strong revenue growth from AI services (particularly cloud and enterprise AI) keeps optimism alive.[7]
- Meta, Google, Microsoft, Amazon and xAI (Elon Musk’s company) are all using off-balance-sheet debt vehicles, including special-purpose vehicles (SPVs) to fund part of their AI investments. A slowdown in AI demand could render the debt tied to these SPVs worthless, potentially triggering another financial crisis.
- Alphabet’s (Google’s parent company) CEO Sundar Pichai sees “elements of irrationality” in the current scale of AI investing which is much more than excessive investments during the dot-com/fiber optic built-out boom of the late 1990s. If the AI bubble bursts, Pichai said that no company will be immune, including Alphabet, despite its breakthrough technology, Gemini, fueling gains in the company’s stock price.

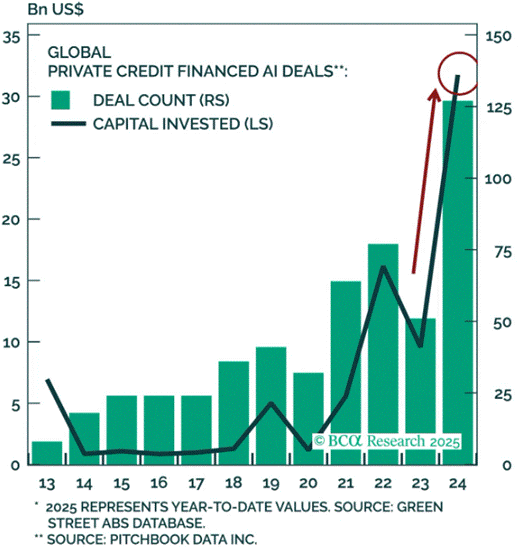
…………………………………………………………………………………………………………………..
From Infrastructure to Intelligence:
Executives justify the massive spend by citing acute compute shortages and exponential demand growth:
- Microsoft’s CFO Amy Hood admitted, “We’ve been short on capacity for many quarters” and confirmed that the company will increase its spending on GPUs and CPUs in 2026 to meet surging demand.
- Amazon’s Andy Jassy noted that “every new tranche of capacity is immediately monetized”, underscoring strong and sustained demand for AI and cloud services.
- Google reported billions in quarterly AI revenue, offering early evidence of commercial payoff.
Macro Ripple Effects – Industrializing Intelligence:
AI data centers have become the factories of the digital age, fueling demand for:
- Semiconductors, especially GPUs (Nvidia, AMD, Broadcom)
- Cloud and networking infrastructure (Oracle, Cisco)
- Energy and advanced cooling systems for AI data centers (Vertiv, Schneider Electric, Johnson Controls, and other specialists such as Liquid Stack and Green Revolution Cooling).
| Company Name | Core Expertise | Key Solutions for AI Data Centers |
|---|---|---|
| Vertiv | Critical infrastructure (power & cooling) | Offers full-stack solutions with air and liquid cooling, power distribution units (PDUs), and monitoring systems, including the AI-ready Vertiv 360AI portfolio. |
| Schneider Electric | Energy management & automation | Provides integrated power and thermal management via its EcoStruxure platform, specializing in modular and liquid cooling solutions for HPC and AI applications. |
| Johnson Controls | HVAC & building solutions | Offers integrated, energy-efficient solutions from design to maintenance, including Silent-Aire cooling and YORK chillers, with a focus on large-scale operations. |
| Eaton | Power management | Specializes in electrical distribution systems, uninterruptible power supplies (UPS), and switchgear, which are crucial for reliable energy delivery to high-density AI racks. |
- LiquidStack: A leader in two-phase and modular immersion cooling and direct-to-chip systems, trusted by large cloud and hardware providers.
- Green Revolution Cooling (GRC): Pioneers in single-phase immersion cooling solutions that help simplify thermal management and improve energy efficiency.
- Iceotope: Focuses on chassis-level precision liquid cooling, delivering dielectric fluid directly to components for maximum efficiency and reduced operational costs.
- Asetek: Specializes in direct-to-chip (D2C) liquid cooling solutions and rack-level Coolant Distribution Units (CDUs) for high-performance computing.
- CoolIT Systems: Known for its custom direct liquid cooling technologies, working closely with server OEMs (Original Equipment Manufacturers) to integrate cold plates and CDUs for AI and HPC workloads.
–>This new AI ecosystem is reshaping global supply chains — but also straining local energy and water resources. For example, Meta’s massive data center in Georgia has already triggered environmental concerns over energy and water usage.
Global Spending Outlook:
- According to UBS, global AI capex will reach $423 billion in 2025, $571 billion by 2026 and $1.3 trillion by 2030, growing at a 25% CAGR during the period 2025-2030.
Compute demand is outpacing expectations, with Google’s Gemini saw 130 times rise in AI token usage over the past 18 months, highlighting soaring compute and Meta’s infrastructure needs expanding sharply.[9]
Conclusions:
The AI infrastructure boom reflects a bold, forward-looking strategy by Big Tech, built on the belief that compute capacity will define the next decade’s leaders. If Artificial General Intelligence (AGI) or large-scale AI monetization unfolds as expected, today’s investments will be seen as visionary and transformative. Either way, the AI era is well underway — and the race for computational excellence is reshaping the future of global markets and innovation.
…………………………………………………………………………………………………………………………………………………………………………………………………………………………….
Footnotes:
[1] https://www.investing.com/news/stock-market-news/ai-capex-to-exceed-half-a-trillion-in-2026-ubs-4343520?utm_medium=feed&utm_source=yahoo&utm_campaign=yahoo-www
[2] https://www.venturepulsemag.com/2025/08/01/big-techs-400-billion-ai-bet-the-race-thats-reshaping-global-technology/#:~:text=Big%20Tech’s%20$400%20Billion%20AI%20Bet:%20The%20Race%20That’s%20Reshaping%20Global%20Technology,-3%20months%20ago&text=The%20world’s%20largest%20technology%20companies,enterprise%20strategy%2C%20and%20public%20policy.
[3] https://www.businessinsider.com/big-tech-capex-spending-ai-earnings-2025-10?
[4] https://www.investing.com/analysis/meta-plunged-12-amazon-jumped-11–same-ai-race-different-economics-200669410
[5] https://www.cnbc.com/2025/10/15/a-guide-to-1-trillion-worth-of-ai-deals-between-openai-nvidia.html
[6] https://finance.yahoo.com/news/bank-america-just-issued-stark-152422714.html
[7] https://news.futunn.com/en/post/64706046/from-cash-rich-to-collective-debt-how-does-wall-street?level=1&data_ticket=1763038546393561
[8] https://www.businessinsider.com/big-tech-capex-spending-ai-earnings-2025-10?
[9] https://finance.yahoo.com/news/ai-capex-exceed-half-trillion-093015889.html
……………………………………………………………………………………………………………………………………………………………………………………………………………………………
About the Author:
Rahul Sharma is President & Co-Chief Executive Officer at Indxx – a provider of end-to-end indexing services, data and technology products. He has been instrumental in leading the firm’s growth since 2011. Raul manages Indxx’s Sales, Client Engagement, Marketing and Branding teams while also helping to set the firm’s overall strategic objectives and vision.
Rahul holds a BS from Boston College and an MBA with Beta Gamma Sigma honors from Georgetown University’s McDonough School of Business.

……………………………………………………………………………………………………………………………………………………………………………………………………………………………
References:
Curmudgeon/Sperandeo: New AI Era Thinking and Circular Financing Deals
Expose: AI is more than a bubble; it’s a data center debt bomb
Can the debt fueling the new wave of AI infrastructure buildouts ever be repaid?
AI spending boom accelerates: Big tech to invest an aggregate of $400 billion in 2025; much more in 2026!
Big tech spending on AI data centers and infrastructure vs the fiber optic buildout during the dot-com boom (& bust)
FT: Scale of AI private company valuations dwarfs dot-com boom
Amazon’s Jeff Bezos at Italian Tech Week: “AI is a kind of industrial bubble”
AI Data Center Boom Carries Huge Default and Demand Risks
Will billions of dollars big tech is spending on Gen AI data centers produce a decent ROI?
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Nokia in major pivot from traditional telecom to AI, cloud infrastructure, data center networking and 6G
Reuters: US Department of Energy forms $1 billion AI supercomputer partnership with AMD
………………………………………………………………………………………………………………………………………………………………………….
Dell’Oro: Analysis of the Nokia-NVIDIA-partnership on AI RAN
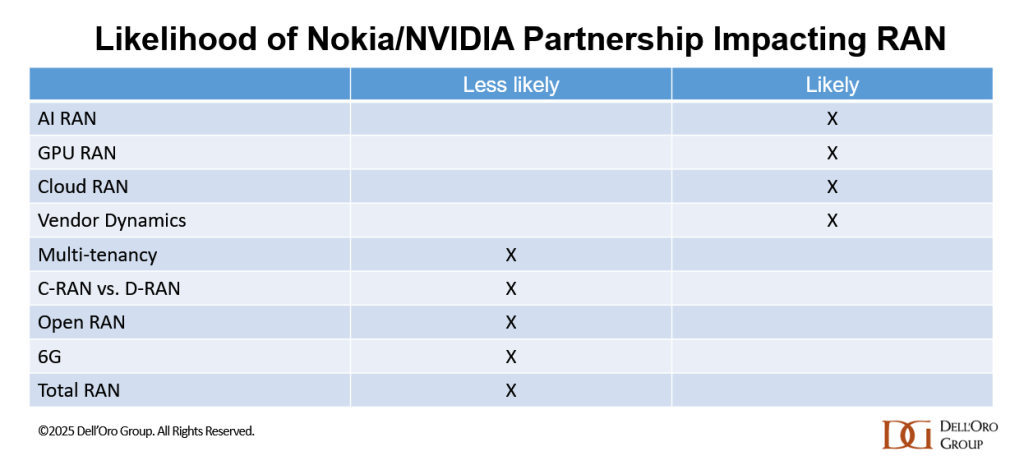
According to Dell’Oro VP Stefan Pongratz, Nokia has outlined a clear plan to arrest its declining RAN revenue share (see chart below), with NVIDIA now a central pillar of that strategy. The partnership is designed to deliver AI RAN [1.] while meeting wireless network operators’ near-term constraints and concerns on performance, power, and TCO (Total Cost of Ownership). IEEE Techblog has noted in many past blog posts that telcos have huge doubts about AI RAN which implies they won’t buy into that new RAN architecture.
This is especially relevant considering the monumental failure of multi-vendor Open RAN which was promoted as a game changer, but has dismally failed to attain that vision.
Note 1. AI RAN is a mobile RAN architecture where AI and machine learning are embedded into the RAN software and underlying compute platform to optimize how the network is planned, configured, and operated. It is being pushed by NVIDIA to get its GPUs into 5G, 5G Advanced and 6G base stations and other wireless network equipment in the RAN.
……………………………………………………………………………………………………………………………………………………..
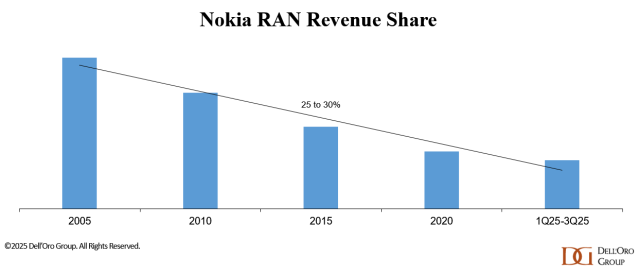
Nokia aims to use collaboration with NVIDIA (which invested $1B in the Finland based company) to stabilize its RAN market share in the near term and create a platform for long-term growth in AI-native 5G-Advanced and 6G networks. The timing—following a dense cadence of disclosures at NVIDIA’s GPU Technology Conference and Nokia’s Capital Markets Day—makes this an ideal time to reassess the scope of the joint announcements, the RAN implications, and Nokia’s broader competitive posture in an increasingly concentrated market.
Both companies share a belief that telecom networks will evolve from best-effort connectivity into a distributed compute fabric underpinning autonomous machines, self-driving vehicles, humanoids, and industrial digital twins. From that perspective, the RAN becomes an “AI grid” that executes and orchestrates AI workloads at the edge, enabling massive numbers of latency-sensitive, bandwidth-intensive AI use cases.
Unlike prior attempts to penetrate the RAN market with its GPUs, NVIDIA is now taking a more pragmatic approach, explicitly targeting parity with incumbent, purpose-built RAN equipment based on performance, power, and TCO rather than leading with speculative multi-tenant or new-revenue narratives. Nokia, acutely aware of wireless telco risk tolerance, is positioning the solution so that the ROI must be justifiable on a pure RAN basis, with additional AI and edge-compute upside treated as optional rather than foundational.
A quick recap of NVIDIA’s entry into RAN: Based on the announcement and subsequent discussions, our understanding is that NVIDIA will invest $1 B in Nokia and that NVIDIA-powered AI-RAN products will be incorporated into Nokia’s RAN portfolio starting in 2027 (with trials beginning in 2026). While RAN compute—which represents less than half of the $30B+ RAN market—is immaterial relative to NVIDIA’s $4+ T market cap, the potential upside becomes more meaningful when viewed in the context of NVIDIA’s broader telecom ambitions and its $165 B in trailing-twelve-month revenue.

With a deployed base of more than 1 million BTS, Nokia is prioritizing three migration vectors to GPU/AI-RAN, in order of expected impact:
-
Purpose-built D-RAN [2.], by inserting a new card into existing AirScale slots.
-
D-RAN vRAN [3.], using COTS servers at the cell site.
-
Cloud RAN [4.] or vRAN, using centralized COTS infrastructure.
This approach aligns with wireless network operators’ desire to sweat existing AirScale assets while minimizing operational disruption.
Note 2. Purpose-built D-RAN is a distributed RAN architecture where the baseband processing runs on dedicated, vendor-specific hardware at or very close to the cell site, rather than on generic COTS servers. It is “purpose-built” because the silicon, boards, and software stack are tightly integrated and optimized for RAN performance, power efficiency, and footprint, not general-purpose compute.
Note 3. vRAN or virtual RAN is a technology that virtualizes the functions of a cellular network’s radio access network, moving them from dedicated hardware to software running on general-purpose servers. This approach makes mobile networks more flexible, scalable, and cost-efficient by replacing proprietary hardware with software on common-off-the-shelf (COTS) hardware.
Note 4. Cloud RAN (C-RAN) is a centralized cellular network architecture that uses cloud computing to virtualize and process radio access network (RAN) functions. This architecture centralizes baseband units in a “BBU hotel,” allowing for more flexible and scalable network management, efficient resource allocation, and improved network performance. It allows operators to pool resources, adjust capacity based on demand, and support new services, which is a key enabler for 5G networks.
………………………………………………………………………………………………………………………………………………
In this model, the Distributed Unit, and often the higher-layer functions, are physically collocated with the radio unit at the site, making each site a largely self-contained RAN node. This contrasts with Cloud RAN or vRAN, where baseband functions are centralized or virtualized on shared cloud infrastructure, and with cloud/AI-RAN approaches that rely on GPUs or other general-purpose accelerators instead of custom RAN hardware.
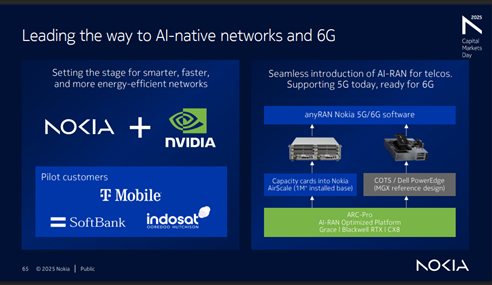
The macro-RAN market (baseband plus radio) is roughly a $30 billion annual opportunity, with on the order of 1–2 million macro sites shipped per year. In that context, operators have limited appetite to pay more than $10,000 for a GPU per sector, even if software-led benefits accumulate over time, which is why NVIDIA is signaling GPU pricing in line with ARC-Compact, but at roughly double the capacity and Nokia is targeting 48–50% gross margins in Mobile Infrastructure by 2028, slightly above the current run-rate.
If the TCO and performance-per-watt gap versus custom silicon continues to narrow, the partnership could materially influence AI-RAN and Cloud-RAN trajectories while also supporting Nokia’s margin expansion goals. AI-RAN was already expected to scale to roughly one-third of the RAN market by 2029; Nokia’s decision to lean harder into GPUs amplifies this structural shift without fundamentally changing the long-term 6G direction.
In the near term, GPU-enabled D-RAN using empty AirScale slots is expected to dominate deployments, reflecting operators’ preference for incremental, site-level upgrades. At the same time, the Nokia-NVIDIA partnership is not expected to meaningfully alter the overall Cloud RAN vs. D-RAN mix, Open RAN adoption (slow or non-existent) , or the trajectory of multi-tenant RAN, which remain more dependent on network operator architecture and commercial decisions than on a single vendor–silicon alignment.
Nokia plans to remain disciplined and focus on areas where it can differentiate and unlock value—particularly through software/faster innovation cycles via its recently announced partnership with NVIDIA. The company sees meaningful opportunities to capture incremental share in North America, Europe, India, and select APAC markets. And it is already off to a solid start— we estimate that Nokia’s 1Q25–3Q25 RAN revenue share outside North America improved slightly relative to 2024. Following this stabilization phase, Nokia is betting that its investments will pay off and that it will be well-positioned to lead with AI-native networks and 6G.
Nokia’s objective is clear: stabilize RAN in the short term, then grow by leading in AI-native networks and 6G over the longer horizon. Success now hinges on Nokia’s ability to operationalize the GPU-based RAN roadmap at scale and on NVIDIA’s ability to deliver carrier-grade economics and performance—turning the AI-RAN narrative into production-grade, repeatable deployments.
Nokia sees meaningful opportunities to capture incremental RAN market share in North America, Europe, India, and select APAC markets. And it is already off to a solid start— we estimate that Nokia’s 1Q25–3Q25 RAN revenue share outside North America improved slightly relative to 2024. Following this stabilization phase, Nokia is betting that its investments will pay off and that it will be well-positioned to lead with AI-native networks and 6G.
References:
Nokia in major pivot from traditional telecom to AI, cloud infrastructure, data center networking and 6G
Indosat Ooredoo Hutchison, Nokia and Nvidia AI-RAN research center in Indonesia amongst telco skepticism
Nvidia pays $1 billion for a stake in Nokia to collaborate on AI networking solutions
RAN silicon rethink – from purpose built products & ASICs to general purpose processors or GPUs for vRAN & AI RAN
Dell’Oro: AI RAN to account for 1/3 of RAN market by 2029; AI RAN Alliance membership increases but few telcos have joined
Dell’Oro: RAN revenue growth in 1Q2025; AI RAN is a conundrum
AI RAN Alliance selects Alex Choi as Chairman
Expose: AI is more than a bubble; it’s a data center debt bomb
GSMA, ETSI, IEEE, ITU & TM Forum: AI Telco Troubleshooting Challenge + TelecomGPT: a dedicated LLM for telecom applications
The GSMA — along with ETSI, IEEE GenAINet, the ITU, and TM Forum — today opened an innovation challenge calling on telco operators, AI researchers, and startups to build large-language models (LLMs) capable of root-cause analysis (RCA) for telecom network faults. The AI Telco Troubleshooting Challenge is supported by Huawei, InterDigital, NextGCloud, RelationalAI, xFlowResearch and technical advisors from AT&T.
The new competition invites teams to submit AI models in three categories: Generalization to New Faults will assess the best performing LLMs for RCA; Small Models at the Edge will evaluate lightweight edge-deployable models; and Explainability/Reasoning will focus on the AI systems that clearly explain their reasoning. Additional categories will include securing edge-cloud deployments and enabling AI services for application developers.
The goal is to deliver AI tools that help operators automatically identify, diagnose, and (eventually) remediate network problems — potentially reducing both downtime and operational costs. This marks a concrete step toward turning “telco-AI” from pilot projects into operational infrastructure.
As telecom networks scale (5G, 5G-Advanced, edge, IoT), faults and failures become costlier. Automating fault detection and troubleshooting with AI could significantly boost network resilience, reduce manual labor, and enable faster recovery from outages.

“Large Language Models have become instrumental in the pursuit of autonomous, resilient and adaptive networks,” said Prof. Merouane Debbah, General Chair of IEEE GenAINet ETI. “Through this challenge, we are tackling core research and engineering challenges, such as generalisation to unseen network faults, interpretability and edge-efficient AI, that are vital for making AI-native telecom infrastructures a reality. IEEE GenAINet ETI is proud to support this initiative, which serves as a testbed for future-ready innovations across the global telco ecosystem.”
“ITU’s global AI challenges connect innovators with computing resources, datasets, and expert mentors to nurture AI innovation ecosystems worldwide,” said Seizo Onoe, Director of the ITU Telecommunication Standardization Bureau. “Crowdsourcing new solutions and creating conditions for them to scale, our challenges boost business by helping innovations achieve meaningful impact.”
“The future of telecoms depends on the autonomation of network resiliency – shifting from static infrastructure to AI-driven, context-aware, self-optimising networks. TM Forum’s AI-Native Blueprint provides the architectural foundation to make this reality, and the AI Telco Troubleshooting Challenge aligns perfectly to support the industry in moving beyond isolated pilots to production-grade resilient autonomation,” said Guy Lupo, AI and Data Mission lead at TM Forum.
The initiative builds on recent breakthroughs in applying AI to network operations, leveraging curated datasets such as TeleLogs and benchmarking frameworks developed by GSMA and its partners under the GSMA Open-Telco LLM Benchmarks community, which includes a leaderboard that highlights how various LLMs perform on telco-specific use cases.
“Network faults cost operators millions annually and root cause analysis is a critical pain point for operators,” said Louis Powell, Director of AI Technologies at GSMA. “By harnessing AI models capable of reasoning and diagnosing unseen faults, the industry can dramatically improve reliability and reduce operational costs. Through this challenge, we aim to accelerate the development of LLMs that combine reasoning, efficiency and scalability.”
“We are encouraged by the upside of this challenge after our team at AT&T fine-tuned a 4-billion-parameter small language model that topped all other evaluated models on the GSMA Open-Telco LLM Benchmarks (TeleLogs RCA task), including frontier models such as GPT-5, Claude Sonnet 4.5 and Grok-4,” said Andy Markus, Chief Data Officer at AT&T. “This challenge has the right mix of an important business problem and a technical opportunity, and we welcome the industry’s collaboration to take it to the next level.”
The AI Telco Troubleshooting Challenge is open for submissions on the 28th November and it closes on 1st February 2026, with the winners announced at a dedicated prize-giving session at MWC26 Barcelona.
…………………………………………………………………………………………………………………………………………………………………………
Separately, the GSMA Foundry and Khalifa University announced a strategic collaboration to develop “TelecomGPT,” a dedicated LLM for telecom applications, plus an Open-Telco Knowledge Graph based on 3GPP specifications.
-
These assets are intended to help the industry overcome limitations of general-purpose LLMs, which often struggle with telecom-specific technical contexts. PR Newswire+2Mobile World Live+2
-
The plan: make TelecomGPT and related knowledge tools available for operators, vendors and researchers to accelerate AI-driven telco innovations. PR Newswire+1
Why it matters: A specialized “telco-native” LLM could improve automation, operations, R&D and standardization efforts — for example, helping operators configure networks, analyze logs, or build AI-powered services. It represents a shift toward embedding AI more deeply into core telecom infrastructure and operations.
…………………………………………………………………………………………………………………………………………………………………………………..
About GSMA
The GSMA is a global organization unifying the mobile ecosystem to discover, develop and deliver innovation foundational to positive business environments and societal change. Our vision is to unlock the full power of connectivity so that people, industry, and society thrive. Representing mobile operators and organizations across the mobile ecosystem and adjacent industries, the GSMA delivers for its members across three broad pillars: Connectivity for Good, Industry Services and Solutions, and Outreach. This activity includes advancing policy, tackling today’s biggest societal challenges, underpinning the technology and interoperability that make mobile work, and providing the world’s largest platform to convene the mobile ecosystem at the MWC and M360 series of events.
We invite you to find out more at gsma.com
About ETSI
ETSI is one of only three bodies officially recognized by the European Union as a European Standards Organization (ESO). It is an independent, not-for-profit body dedicated to ICT standardisation. With over 900 member organizations from more than 60 countries across five continents, ETSI offers an open and inclusive environment for members representing large and small private companies, research institutions, academia, governments, and public organizations. ETSI supports the timely development, ratification, and testing of globally applicable standards for ICT‑enabled systems, applications, and services across all sectors of industry and society. More on: etsi.org
About IEEE GenAINet
The aim of the IEEE Large Generative AI Models in Telecom Emerging Technology Initiative (GenAINet ETI) is to create a dynamic platform of research and innovation for academics, researchers, and industry leaders to advance the research on large generative AI in Telecom, through collaborative efforts across various disciplines, including mathematics, information theory, wireless communications, signal processing, networking, artificial intelligence, and more. More on: https://genainet.committees.comsoc.org
About ITU
The International Telecommunication Union (ITU) is the United Nations agency for digital technologies, driving innovation for people and the planet with 194 Member States and a membership of over 1,000 companies, universities, civil society, and international and regional organizations. Established in 1865, ITU coordinates the global use of the radio spectrum and satellite orbits, establishes international technology standards, drives universal connectivity and digital services, and is helping to make sure everyone benefits from sustainable digital transformation, including the most remote communities. From artificial intelligence (AI) to quantum, from satellites and submarine cables to advanced mobile and wireless broadband networks, ITU is committed to connecting the world and beyond. Learn more: www.itu.int
About TM Forum
TM Forum is an alliance of over 800 organizations spanning the global connectivity ecosystem, including the world’s top ten Communication Service Providers (CSPs), top three hyperscalers and Network Equipment Providers (NEPs), vendors, consultancies and system integrators, large and small. We provide a place for our Members to collaborate, innovate, and deliver lasting change. Together, we are building a sustainable future for the industry in connectivity and beyond. To find out more, visit: www.tmforum.org
References:
The AI Telco Troubleshooting Challenge Launches to Transform Network Reliability
AI Telco Troubleshooting Challenge global launch webinar
GSMA Vision 2040 study identifies spectrum needs during the peak 6G era of 2035–2040
Gartner: Gen AI nearing trough of disillusionment; GSMA survey of network operator use of AI
