

Cloud networking
AI-Era Cloud Network Transformation: A Reference Architecture and Implementation Roadmap
By Shazia Hasnie, PhD
Introduction:
The physical network infrastructure that underpins cloud computing was designed for an era that no longer exists. Distributed training across hundreds of thousands of GPUs, real-time inference at the edge, and autonomous agent coordination impose requirements that traditional cloud network designs were never intended to meet. The networks that served the cloud era were architected for north-south traffic, best-effort delivery, and human-scale applications. None of these assumptions hold for AI.
This article presents a framework for transforming cloud network infrastructure for the AI era. It is organized around two components: a four-pillar reference architecture that defines what must be built, and a five-phase implementation roadmap that defines how to execute the transformation. Together, they provide infrastructure transformation leaders with a complete program for preparing their organizations’ physical network infrastructure for the age of AI.
The Four-Pillar Reference Architecture:
The physical network infrastructure for AI-era cloud computing is organized around four interdependent pillars. Each pillar groups related layers of the infrastructure stack. Each depends on the pillars that precede it and enables the pillars that follow.
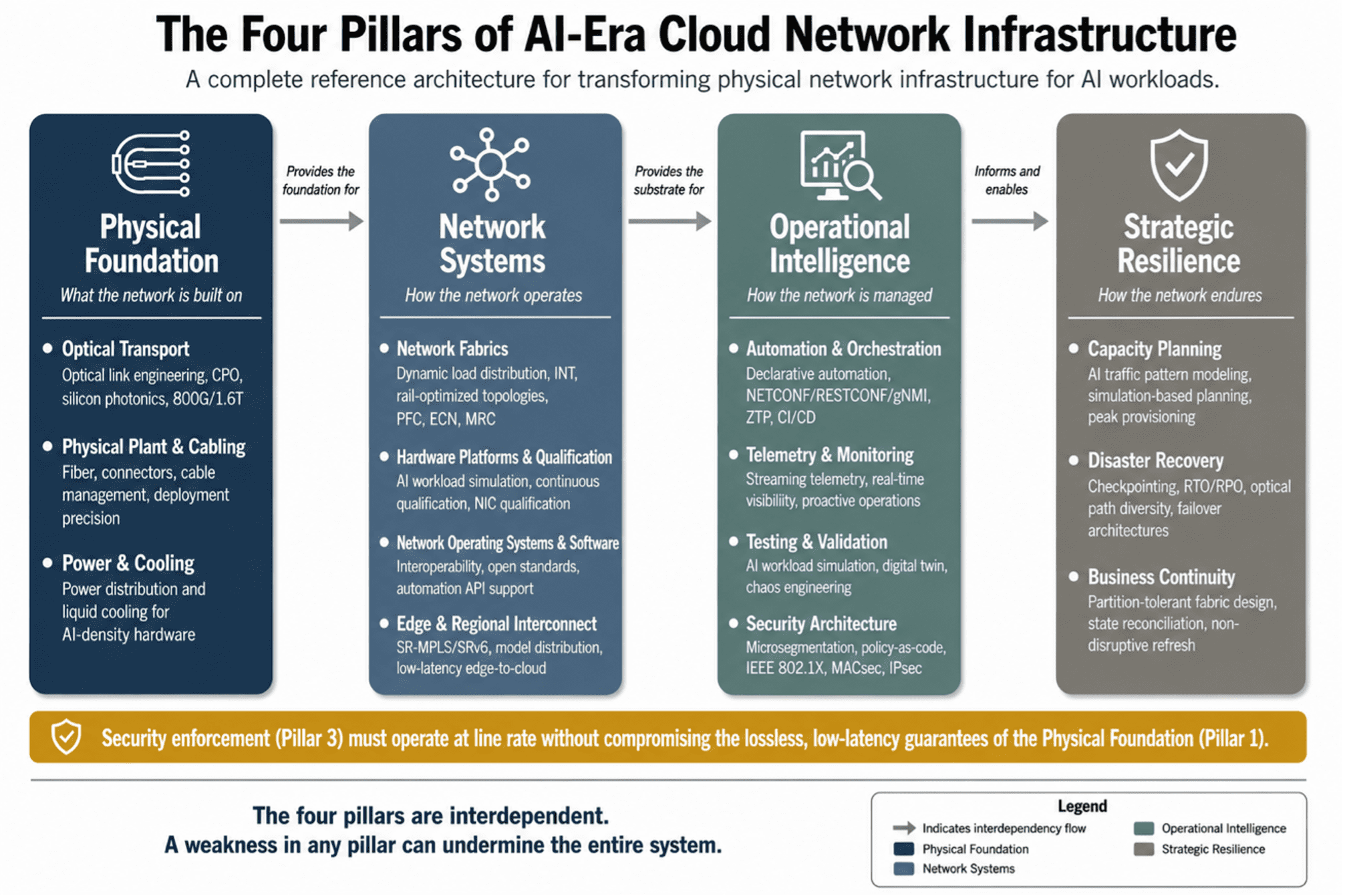
Figure 1: The Four Pillars of AI-Era Cloud Network Infrastructure — a complete reference architecture for physical network transformation.
PILLAR 1: PHYSICAL FOUNDATION
The physical foundation is the literal infrastructure on which all higher-layer network services depend. Optical transport determines the bandwidth, latency, and reliability of every interconnection between data centers, regions, and compute clusters. Physical plant and cabling provide the fiber, connectors, and cable management that make connectivity possible. Power and cooling provide the electrical and thermal infrastructure that keeps everything running.
Optical Transport. Optical link engineering for AI workloads requires a fundamental shift from traditional practice. Traditional optical link engineering treats traffic surges as anomalies and provisions for average utilization. AI workloads generate synchronized, high-bandwidth bursts—checkpointing incast can saturate multiple optical links for minutes at a time—that demand link budgets engineered for peak synchronized demand. The cost of insufficient capacity is not degraded optical performance; it is stalled training runs.
The optical technology roadmap is being reshaped by AI requirements. Co-packaged optics (CPO) integrate the optical engine directly with the switch ASIC, reducing power consumption by 30-50% while increasing port density. Silicon photonics leverage semiconductor manufacturing to produce optical components at scale. 800G and 1.6T per wavelength will be required as GPU bandwidth scales. Linear drive optics remove the digital signal processing from the optical transceiver, reducing power and latency. Breakout optics enable multi-planar topologies where each GPU connects to multiple parallel fabrics. Organizations must ensure that today’s optical investments are forward-compatible with these technologies.
Physical Plant and Cabling. Deployment precision at the physical layer determines whether the architectures designed at higher layers function as intended. Rail-optimized topologies depend on perfect physical cabling—a single miscabled port breaks the single-hop guarantee. Automated cabling verification, where the management interface validates each connection against the reference design, has reduced deployment time by up to 90% for early adopters. Continuous monitoring must detect cabling degradation before it causes performance issues.
Power and Cooling. AI network hardware consumes significantly more power than traditional cloud hardware. A rack of switches populated with 800G pluggable optics can consume over 10 kilowatts. CPO engines may require direct-to-chip liquid cooling. The transition to liquid cooling has implications that extend beyond the network—chilled water systems, heat rejection, building structural load—and retrofitting liquid cooling into a data center designed for air cooling is significantly more expensive than incorporating it into new construction.
PILLAR 2: NETWORK SYSTEMS
Network systems translate the physical foundation into functional network services. Modern data centers operate multiple physical networks—front-end, back-end, storage—each optimized for a specific traffic class. AI training demands a dedicated high-bandwidth, low-latency fabric for GPU-to-GPU communication that must interoperate with existing networks through well-defined interconnection points.
Network Fabrics. AI workloads generate east-west traffic that behaves differently from anything traditional cloud networks were designed to handle. It is dominated by a small number of high-bandwidth elephant flows—sustained, predictable data streams between GPU pairs—that produce synchronized bursts at predictable intervals. Worst-case path latency determines the completion time for collective communication operations, making the performance of the slowest path more important than average performance.
The industry has developed two distinct architectural paths to meet these requirements. For scale-up networks within a single rack or GPU pod, where distances are measured in meters and the cost of a stall is immediate, lossless transport via Priority-Based Flow Control (PFC) and Explicit Congestion Notification (ECN) remains the dominant approach. For scale-out networks connecting GPU clusters across data center halls or buildings, the industry is moving toward efficient utilization with low tail latency through fast recovery rather than absolute loss prevention. The Ultra Ethernet Consortium’s Ultra Ethernet Transport (UET) specification leads this effort, treating packet loss as a recoverable event rather than a failure.
The choice between paths is governed by three criteria: scale of deployment (≤256 GPUs favors lossless; ≥512 GPUs favors low-loss), workload characteristics (tightly coupled training benefits from lossless; loosely coupled inference tolerates low-loss), and organizational maturity (deep PFC expertise extends lossless viability to larger scales).
Four fabric capabilities support both paths. Dynamic load distribution—flowlet switching and packet spray—replaces static Equal Cost Multi-Path (ECMP) with congestion-aware path selection. In-band network telemetry (INT) provides the microsecond-granularity congestion visibility that makes intelligent load distribution possible. Rail-optimized topologies provide single-hop GPU-to-GPU connectivity for the most latency-sensitive collective operations. Advanced transport protocols, add selective retransmission via SACK and NACK that serves both scale-up and scale-out deployments.
Hardware Platforms and Qualification. Hardware must be qualified under AI workload conditions, not standard benchmarks. A switch that performs well under steady-state testing may exhibit unacceptable packet loss under synchronized burst patterns. The qualification process must answer a specific question: will this hardware maintain performance under the traffic patterns that AI workloads generate? Qualification is continuous—a firmware update, a new optics module, or a configuration change can alter behavior and must be validated before reaching production. The endpoint NIC plays a critical role, handling RDMA at line rate, packet-spray reordering, and selective retransmission. NIC qualification must be part of the same AI workload simulation process as switches and optics.
Network Operating Systems. The NOS must support PFC, INT, dynamic load distribution, and automation APIs. Interoperability is an architectural requirement in inherently multi-vendor AI infrastructure. Organizations should prioritize platforms that adhere to open standards—UET specifications, IETF YANG data models, OpenConfig—over proprietary extensions that create long-term supply chain constraints.
Edge and Regional Interconnect. AI inference increasingly occurs at the edge, requiring low-latency connectivity to cloud reasoning agents. Traffic engineering via Segment Routing over MPLS (SR-MPLS) and SR over IPv6 (SRv6) enables explicit path specification for latency-sensitive flows. Model distribution to edge endpoints requires versioned, efficient distribution protocols. Regional interconnect must be treated as a production input, not a shared utility—it is part of the AI supercomputer’s backplane.
PILLAR 3: OPERATIONAL INTELLIGENCE
Operational intelligence provides the control systems that make the network operable at scale. The AI-ready network cannot be managed through manual processes—a single AI cluster may contain thousands of switches requiring consistent configuration, where a single misconfigured buffer can stall thousands of GPUs.
Automation and Orchestration. The architectural response is declarative intent-based automation. The operator declares the desired network state using IETF YANG data models, and the automation framework translates this into device-level configuration via NETCONF, RESTCONF, and gNMI. Zero-touch provisioning enables switches to self-configure from the moment of installation. Configuration-as-code ensures every device conforms to architectural standards, with drift detected and corrected automatically. Network changes move through CI/CD pipelines that validate against policy and test under AI workload conditions before production deployment.
Telemetry and Monitoring. INT captures per-packet, per-path metrics at microsecond granularity. Streaming telemetry replaces polled monitoring with continuous, event-driven data push. The telemetry platform must ingest, store, and analyze millions of data points per second, enabling cross-layer correlation—tracing a GPU-level stall back through the fabric to the specific optical port and wavelength where the loss occurred. Predictive models detect performance degradation before it causes packet loss, shifting operations from reactive to proactive.
Testing and Validation. A dedicated testing environment must replicate production AI workload patterns—synchronized bursts, collective communication operations, checkpointing incast. Fault injection and chaos engineering validate network behavior under failure conditions. A digital twin of the production network, continuously synchronized, within a bounded delay, with real-time telemetry, enables what-if analysis for topology changes, capacity additions, and configuration updates before production deployment.
Security Architecture. Distributed AI dissolves the traditional network perimeter. The architectural response is in-fabric security: microsegmentation at the switch level validates every flow at the point of ingress, policy is bound to workload identity rather than network location, and the enforcement architecture relies on IEEE 802.1X, MACsec, and IPsec. Policy-as-code manages security rules through the same CI/CD pipelines as network configuration. The immutable audit trail serves double duty as both the security record and the compliance record.
PILLAR 4: STRATEGIC RESILIENCE
Strategic resilience ensures the network survives disruptions, scales with demand, and sustains itself over the long term.
Capacity Planning. Traditional capacity planning, based on historical averages and steady-state utilization, systematically underprovisions for AI. AI traffic is bursty, synchronized, and high-volume by design. Capacity must be provisioned for peak synchronized demand. Simulation-based planning models proposed network designs under projected AI workloads, identifying bottlenecks in the design phase before hardware is committed.
Disaster Recovery. AI training runs lasting weeks or months cannot be restarted from scratch. The network must support checkpointing at AI scale, with Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) defined per workload. The optical backbone must provide physically diverse paths with automatic protection switching. Failover architectures—active-active or active-passive—must be designed at the network level for inference workloads requiring high availability.
Business Continuity. The network fabric must tolerate WAN partitions without cascading failures, with local control planes capable of independent operation at each site. State reconciliation architecture—based on the shared event log pattern—must preserve causal ordering across partition boundaries. The network must support non-disruptive infrastructure refresh, with redundant paths and hitless failover enabling component replacement without interrupting workloads that run continuously for weeks or months.
The Five-Phase Implementation Roadmap
The migration from legacy to AI-ready network infrastructure is a multi-phase program that must deliver value at each stage while building toward the target architecture. Each phase has defined activities, deliverables, and success criteria. Each phase delivers measurable value before the next begins. Phase durations are calibrated for a Tier-1 cloud services provider; individual organizational timelines may vary based on scale, complexity, and resource availability. The success criteria stated for each phase are drawn from industry benchmarks and practitioner experience with large-scale network transformation programs. They represent targets that are ambitious but achievable for a Tier-1 cloud services provider with dedicated transformation resources and executive sponsorship.
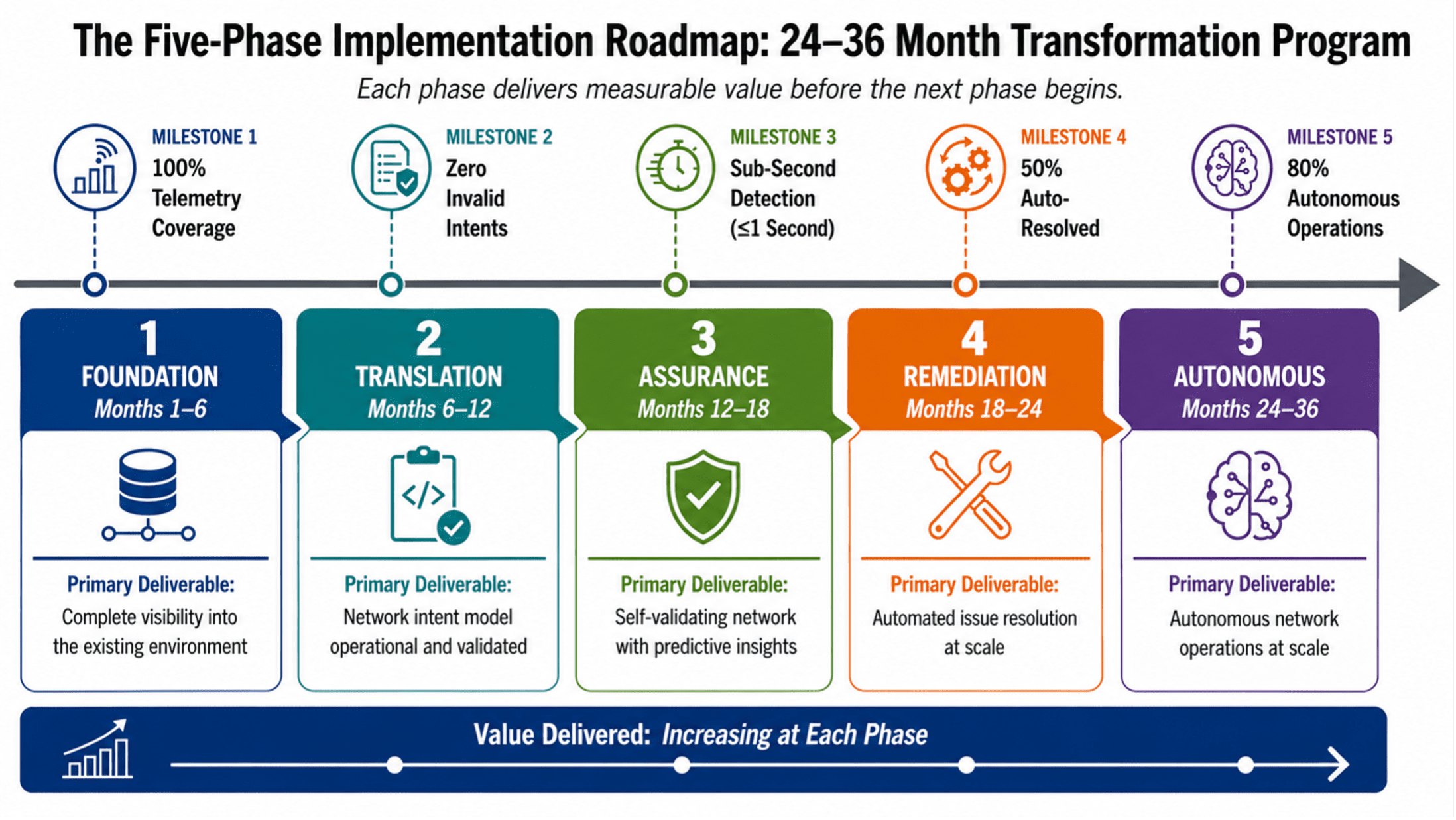
Figure 2: The Five-Phase Implementation Roadmap — A 24–36 Month Transformation Program.
PHASE 1: FOUNDATION (MONTHS 1–6)
The first phase establishes the essential building blocks. Nothing can be automated, optimized, or secured until the network is instrumented and its state is understood.
The starting point is telemetry. Streaming telemetry must be enabled across all network devices in the AI infrastructure path—switches, optics, fabric elements—using gRPC-based protocols and OpenConfig YANG data models. The deliverable is a centralized telemetry platform receiving continuous data streams from every device. The success criterion is 100% telemetry coverage. Without complete visibility, every subsequent phase operates on incomplete information.
With telemetry flowing, a topology knowledge graph must be built—a dynamic map of all devices, links, and interconnections, continuously updated from telemetry data and discovery protocols. The graph must reflect topology changes within seconds, not minutes. Accurate neighbor discovery across all fabric layers is the foundation on which intent-based automation will reason about the network.
Configuration management must be brought under version control. Every device configuration—PFC thresholds, QoS policies, dynamic load distribution parameters—must be stored in version-controlled repositories. Every change must be tracked and attributed. The success criterion is 100% configuration version control with no out-of-band changes permitted. An automation framework that deploys configuration changes cannot operate reliably if changes are also being made through manual processes that bypass the automation pipeline.
Finally, the foundational intent model must be established. This is a structured format for expressing network intent—topology, capacity, QoS policies—in machine-readable YANG-based models. The deliverable is five foundational intents, defined and validated against the existing network state:
- Lossless Transport Intent: “All Remote Direct Memory Access over Converged Ethernet (RoCE) traffic on the AI fabric shall receive PFC priority treatment with zero packet loss under sustained load.”
- Fabric Capacity Intent: “The AI fabric shall maintain a minimum of 30% headroom on all east-west links during peak utilization.”
- Optical Link Diversity Intent: “Every GPU cluster shall have at least two physically diverse optical paths to its checkpoint storage.”
- Configuration Compliance Intent: “All device configurations shall match version-controlled templates. Any deviation shall be detected and flagged within 60 seconds.”
- Telemetry Coverage Intent: “Every device in the AI network path shall stream telemetry data. Any device that stops streaming shall be flagged within 30 seconds.”
These five intents are scoped to be achievable within Phase 1 while covering the most critical dimensions of AI network operations: lossless transport, capacity, resilience, configuration compliance, and observability.
PHASE 2: TRANSLATION (MONTHS 6–12)
The second phase builds the machinery that translates intent into device-level configuration. This is where declarative automation becomes operational.
The centerpiece is the intent compiler—a translation engine that converts YAML or JSON intent specifications into device-level configuration via NETCONF, RESTCONF, and gNMI. The intent compiler is not merely a template engine. It must understand the capabilities and constraints of each target device, select the appropriate protocol for each configuration operation, and handle the transactional semantics that make configuration changes safe. The success criterion is that the five foundational intents from Phase 1 are compiled and deployed without manual intervention.
Before any compiled configuration reaches production, it must be validated in a digital twin—a virtual replica of the AI network, continuously synchronized with production telemetry. The digital twin enables what-if analysis: if this configuration is applied, what happens to fabric utilization, PFC pause events, and flow completion times? The success criterion is 100% of configuration changes validated in the digital twin before production deployment.
Validation checks must be automated. Every intent must pass feasibility validation (can the network support this intent given current capacity?), capability validation (do the target devices support the required features?), and policy validation (does this intent comply with security and operational policies?). The success criterion is zero invalid intents deployed to production.
Multi-domain support must be enabled. The intent compiler must support both data center fabric and optical backbone domains, translating a single intent into coordinated configurations across domains.
PHASE 3: ASSURANCE (MONTHS 12–18)
The third phase closes the loop between intent and reality. The network may be configured correctly at a point in time, but AI workloads cause continuous change—congestion patterns shift, optical performance degrades, buffer utilization fluctuates. Assurance ensures the network remains in its intended state.
Real-time telemetry monitoring must track SLA compliance for all AI network services, updated continuously from streaming telemetry rather than periodically from polled data. Sub-second detection latency for SLA deviations is the success criterion. A RoCE stall that lasts 500 milliseconds must be detected while it is happening, not after the training run has been disrupted.
Drift detection must compare the intended network state against the actual state continuously. Drift can take many forms: a configuration change applied outside the automation pipeline, a performance degradation that violates the intent without changing the configuration, a topology change due to a link failure. The success criterion is 99% detection accuracy for both configuration and performance drift.
The assurance dashboard must provide all stakeholders—network operations, compute operations, capacity planning—with real-time visibility into network state versus intent. Alerting must be integrated with the incident management system so that 100% of SLA breaches generate alerts within one second of detection.
PHASE 4: REMEDIATION (MONTHS 18–24)
The fourth phase enables the network to respond to drift and failures. Detection without response is observation without action. Remediation closes the loop.
Root cause analysis (RCA) must be automated. When drift is detected, the system must correlate telemetry data across layers—optical, fabric, device—to identify the source. A packet loss event at the GPU layer may originate from a congested optical link three hops away. The RCA engine must trace the event across layers. The success criterion is greater than 80% accuracy for common incident types.
At least three remediation types must be implemented and validated in the digital twin before production enablement: rollback to the last known good configuration, traffic rerouting around congested or failed links, and dynamic QoS adjustment.
A policy engine must govern which remediation actions are fully automated, which require human approval, and which are prohibited. The policy framework must be machine-readable, version-controlled, and enforced at the automation layer. The success criterion is 100% of automated remediation actions comply with defined policies.
Supervised remediation must enable a human-in-the-loop approval workflow for actions that exceed the automated threshold. The goal is that 50% of detected issues are resolved automatically without human intervention, with the remainder escalated for approval.
PHASE 5: AUTONOMOUS (MONTHS 24–36)
The final phase extends over 12 months—longer than the preceding phases—because full autonomy is not a single deployment event. It requires progressive expansion of automation scope, validation of continuous optimization across diverse workload patterns, and accumulation of sufficient operational data for the learning system to deliver meaningful accuracy improvements. Each increment of autonomy must be earned through demonstrated reliability.
The automation scope must be expanded to cover all common incident types identified and validated in Phase 4. The success criterion is that 80% of all incidents are resolved automatically. The remaining 20% represent novel failures, complex multi-domain incidents, or situations where policy requires human judgment.
Continuous optimization must become a background process. The network self-tunes PFC thresholds based on observed congestion patterns, adjusts dynamic load distribution policies as workload distributions shift, and reallocates buffer resources as traffic characteristics evolve. The success criterion is a 20% reduction in SLA violations compared to the Phase 3 baseline.
Cross-domain coordination must achieve full automation for standard intents. When a new GPU cluster is provisioned, the orchestration layer coordinates optical link provisioning, fabric configuration, and security policy establishment across domains without manual intervention. Human involvement is reserved for novel or high-risk changes.
The learning system must improve from experience. Machine learning models trained on historical incident and remediation data must increase root cause analysis accuracy over time. The success criterion is a 10% quarterly improvement in RCA accuracy.
COEXISTENCE: RUNNING LEGACY AND AI-READY NETWORKS IN PARALLEL
The transformation cannot be accomplished through a flag-day cutover. The existing cloud network must continue to operate and generate revenue throughout the transition. The AI-ready network is deployed as a separate physical infrastructure—dedicated optical links, dedicated fabric, dedicated switches—wherever possible. Physical separation eliminates the risk that AI workload traffic patterns will disrupt legacy services. Where physical separation is impractical, logical isolation with strict QoS enforcement provides the necessary workload separation. Interconnection points between the two networks must be engineered with the same packet loss, latency and throughput requirements as the AI-ready network. Operational processes must govern both environments simultaneously during a transition measured in years.
ORGANIZATIONAL TRANSFORMATION
The AI-ready network cannot be operated by a team trained only on legacy network operations. Three new skill domains become critical: AI workload literacy (understanding the traffic patterns and failure modes of distributed training and inference), telemetry and data engineering (building and operating streaming telemetry platforms and correlation engines), and automation engineering (designing and operating intent-based automation and CI/CD pipelines). The talent strategy must balance retraining existing engineers—many of the required skills are extensions of existing knowledge—with external hiring for skills that cannot be developed internally in the required timeframe. Retention of critical talent during the transformation is essential: the engineers who understand the legacy infrastructure are essential to the coexistence strategy.
FINANCIAL MODELING
Network investment for AI must be justified on value generation—the network cost per training run completed, per inference served, per GPU-hour utilized—not traditional cost efficiency metrics. This shift from cost-per-bit to value-per-outcome transforms the investment conversation. A network that costs more per gigabit but enables higher GPU utilization generates a return that far exceeds its cost premium. The five-phase roadmap enables investment to be spread over 24 to 36 months, with each phase delivering measurable value before the next begins. The cost of inaction must be quantified and presented alongside the cost of transformation.
CONCLUSIONS:
The physical network is no longer a utility layer that can be taken for granted. It is the foundation on which AI performance depends. The optical backbone determines whether GPU clusters operate at full utilization or sit idle. The network fabric determines whether distributed training completes in days or weeks. The automation and telemetry infrastructure determines whether issues are detected proactively or discovered after customer impact.
The four-pillar reference architecture defines what must be built. The five-phase implementation roadmap defines how to execute the transformation. Together, they form a complete program for infrastructure transformation leaders.
The technologies described here are deployed and operational in production AI networks today. The challenge for infrastructure leaders is not whether these approaches work, but how to adapt them to their organization’s specific constraints, scale, and timeline.
REFERENCES:
[1] TM Forum, “Autonomous Networks: Business Requirements and Framework,” TM Forum IG1251, 2025. [Online].
[2] AMD, “Next Gen Networking Transport for Large Scale AI Training,” May 2026. [Online].
htt
[3] Tolly Group, “Dell Networking Data Center AI Switch Fabric Congestion Mitigation Evaluation,” April 2026. [Online].
[4] Tech Field Day, “Cisco AI Networking Cluster Operations Deep Dive,” November 2025. [Online].
htt
[5] Akamai / WWT, “East-West Is the New North-South: Rethink Security for the AI-Driven Data Center,” February 2026. [Online]. htt
[6] NIST, “Zero Trust Architecture,” NIST Special Publication 800-207, Aug. 2020. [Online].
[7] IETF, “Network Configuration Protocol (NETCONF),” RFC 6241, June 2011. [Online].
[8] IETF, “RESTCONF Protocol,” RFC 8040, January 2017. [Online]. htt
[9] IEEE, “Priority-based Flow Control,” IEEE Standard 802.1Qbb, 2011.
[10] IEEE, “Congestion Notification,” IEEE Standard 802.1Qau, 2010.
[11] OpenConfig, “OpenConfig: Vendor-Neutral Network Configuration and Telemetry,” [Online]. https://www.
[12] Cloud Native Computing Foundation, “gRPC: A High-Performance, Open Source Universal RPC Framework,” [Online]. https://grpc.io/
[13] Ultra Ethernet Consortium, “Ultra Ethernet Specification,” [Online]. https://
………………………………………………………………………………………………………………………………………………………….
References from IEEE Techblog:
Why Batch Pipelines Break AI Agents: The Case For Streaming-First Network Operations
The enterprise network stack is collapsing; AI’s impact; comparison with “Batch Pipelines Break AI Agents”
ABOUT THE AUTHOR:

Shazia Hasnie, Ph.D., is VP Product Strategy and Innovation at Cuber AI, focused on Agentic Network Operations. Her work explores the intersection of autonomous systems, cloud-native infrastructure, and the economic models that make AI operations sustainable at scale. She brings over 20 years of global experience in communications networks and holds a Ph.D. in Communications Engineering from the Australian National University.
The Financial Trap of Autonomous Networks: Scaling Agentic AI in the Telecom Core
By Pavan Madduri with Ajay Lotan Thakur
The telecom industry wants autonomous, self-healing networks, but nobody is looking at the GPU bill. Running Agentic AI 24/7 “just in case” will bankrupt your IT department and ruin your ESG goals. The only way to survive the autonomous era is ruthless, event-driven orchestration that scales cognitive compute to absolute zero.
Introduction – The Compute Crisis:
The Compute Crisis Nobody is Talking About
Everyone in telecom right now is obsessed with “self-healing” autonomous networks. The vendor pitch sounds amazing. Just drop in some Agentic AI, let it watch your data plane, and watch it fix anomalies without a human ever touching a keyboard. But there’s a massive trap hiding underneath all that hype, and enterprise architects are completely ignoring it. It comes down to the raw physics of AI compute.
Unlike your standard microservices, which just run deterministic, compiled code on cheap CPU cycles, Agentic AI needs massive foundation models. To actually reason through a network failure, these models have to load gigabytes of weights into Video RAM and generate tokens. You need dedicated GPUs for this. We aren’t talking about cheap, stateless API calls here. These are the most expensive, power-hungry workloads in your entire datacenter.
If a telco tries to run an autonomous core the old-fashioned way by keeping high-end GPU nodes spinning 24/7 just in case a BGP route flaps, their cloud bill is going to wipe out any operational savings the AI was supposed to deliver.
The reality is that autonomy is no longer just a software problem. It’s a financial one. The telcos that actually win will not be the ones with the smartest AI. They will be the ones who figure out how to build a strict “scale-to-zero” environment. They need to spin up that expensive cognitive compute exactly when it is needed, and kill it the exact second the job is done.
Why Traditional Auto-scaling is Broken for AI:
When platform engineers first see the compute costs of running these AI agents, their first instinct is usually just to slap standard Kubernetes Horizontal Pod Autoscaling (HPA) on the cluster and call it a day. But standard HPA was built for stateless web servers, not massive cognitive engines. If you try to use it for Agentic AI in a telecom core, you’re going to fail for two big reasons.
The Cold-Start Penalty: Traditional autoscaling is entirely reactive. It sits around waiting for a CPU to hit 80% before it decides to scale up. In telecom, SLAs are measured in sub-milliseconds. If you wait for an anomaly to spike your CPU, then provision a new GPU node, pull a massive AI container image, and load the model weights into VRAM, you are talking about minutes of delay. By the time your AI agent actually wakes up to fix the problem, you have already breached your SLA.
CPU Utilization is a Liar: For AI workloads, standard hardware metrics are completely misleading. A GPU could be pegged at 90% utilization just thinking through a minor log warning, while a massive, critical network failure is stuck waiting in the queue. If your scaling logic is tied to hardware metrics instead of the actual severity of the event queue, you are just going to burn budget scaling blindly.
We have to abandon reactive resource metrics entirely and move to event-driven orchestration.
The Fix – Event-Driven Orchestration:
If standard HPA is broken for this, what is the fix? You have to completely decouple the infrastructure from the workload using strict, event-driven orchestration.
Instead of keeping baseline infrastructure running just to maintain a state, you treat cognitive compute as 100% ephemeral. You don’t scale based on how hard the CPU is working. You scale based on the exact depth and severity of the anomaly queue.
To actually build this, architects need purpose-built event-driven scalers like KEDA (Kubernetes Event-driven Autoscaling). KEDA lets your cluster completely bypass those reactive hardware metrics and listen directly to the network’s data plane.
But how do you avoid the cold-start latency of booting a fresh GPU pod? KEDA solves this by reacting to the event queue length itself rather than waiting for an existing pod’s CPU to max out. By the time a traditional HPA notices a CPU spike, the system is already overwhelmed. (To solve this exact issue in production, I open-sourced a custom KEDA scaler specifically designed to scrape and react to native GPU metrics, allowing the orchestrator to scale cognitive workloads preemptively. You can view the architecture on [GitHub])
KEDA intercepts the telemetry trigger at the source. When paired with a warm pool of paused GPU nodes and pre-pulled container images, KEDA can scale a pod from zero to active in milliseconds. The infrastructure is anticipating the load based on the queue, not reacting to the stress of it.
Here is what the workflow actually looks like when you do it right:
- The Trigger: Telemetry picks up a severe anomaly ,like a sudden 5G slice degradation, and pushes an event straight to a message broker like Kafka.
- The Scale-Up: KEDA intercepts that exact metric and instantly provisions a dedicated, GPU-backed AI pod from a warm standby pool.
- The Execution: The Agentic AI loads into VRAM, figures out the blast radius of the anomaly, and executes a fix. This is usually by reconciling the state through a GitOps controller.
- The Kill Switch: The absolute millisecond that the event queue clears and the network is stable, the orchestrator aggressively terminates the pod and gives the GPU back to the node pool.
You only pay the premium GPU tax during moments of active reasoning. The 24/7 idle tax is gone.
Architecting the Scale-to-Zero Core:
To make this scale-to-zero dream a reality, you have to fundamentally change how you handle network observability. The biggest mistake I see architects make is tightly coupling their monitoring tools with their AI execution layer. If your observability stack is running on the same hardware as your AI engine, you are literally wasting premium GPU compute just to watch logs.
You need a strict, physical separation of concerns:
The Watchers (The Lightweight Control Plane):
Your network data plane needs to be monitored by lightweight, CPU-efficient edge collectors like Prometheus or OpenTelemetry. These sit right at the edge, continuously eating millions of telemetry data points and BGP state changes. Because they don’t do any complex reasoning, they run incredibly cheap on standard CPU nodes.
The Thinkers (The Heavyweight Execution Plane):
Your expensive AI models are completely isolated in a separate, GPU-backed node pool that literally defaults to zero instances.
When the Watchers spot an anomaly, they don’t try to fix it. They just fire an alert to KEDA. KEDA then wakes up the Thinkers, spinning up the exact number of GPU pods needed to handle that specific blast radius. By decoupling the watchers from the thinkers, you guarantee that not a single cycle of GPU compute is wasted on baseline monitoring.
The Bottom Line:
Autonomous telecom networks are going to happen. But trying to brute-force the infrastructure provisioning is a fast track to bankrupting your IT department. The smartest Agentic AI in the world is useless if you can’t afford the cloud bill to run it.
Furthermore, this isn’t just about protecting the IT budget. Running idle GPUs 24/7 creates a massive, unnecessary carbon footprint. By enforcing a scale-to-zero architecture, telcos can drastically reduce the energy consumption of their autonomous networks, turning a massive ESG liability into a sustainable operational model.
Autonomy is no longer just a software engineering problem. It is an infrastructure balancing act. If Agentic AI is going to survive in the telecom core, we have to ditch legacy threshold scaling and embrace strict, event-driven orchestration.
Tools like KEDA give us the ability to build networks that are both cognitively brilliant and financially ruthless. We can spin up massive intelligence at the exact millisecond of failure and scale right back to zero the moment the network is healed.
References and Further Reading:
- Unlocking Energy Saving in Telecom Networks: A Path to a Sustainable Future – A deep dive into the operational and ESG mandates driving energy efficiency in modern telecom infrastructure.
- KEDA Documentation: Kubernetes Event-driven Autoscaling – Technical specifications for decoupling workload scaling from standard CPU/Memory metrics.
- keda-gpu-scaler – An open-source custom KEDA scaler I developed to enable event-driven autoscaling specifically tied to native GPU telemetry and queue depth.
Building and Operating a Cloud Native 5G SA Core Network
How Network Repository Function Plays a Critical Role in Cloud Native 5G SA Network
HPE Aruba Launches “Cloud Native” Private 5G Network with 4G/5G Small Cell Radios
…………………………………………………………………………………………….
About the Author:

Pavan Madduri is a Cloud-Native Architect, CNCF Golden Kubestronaut, and active IEEE researcher specializing in enterprise infrastructure automation, Agentic SREs, and Kubernetes networking. He designs scalable, zero-trust cloud environments and frequently writes about the intersection of AI governance and cloud-native infrastructure.
Connect with Pavan Madduri on [LinkedIn] .
Disclaimer: The author acknowledges the use of AI-assisted tools for structural formatting, language refinement, and copyediting during the drafting of this article. The core architectural concepts, technical opinions, and engineering strategies remain entirely original.
Does AI change the business case for cloud networking?
For several years now, the big cloud service providers – Amazon Web Services (AWS), Microsoft Azure, and Google Cloud – have tried to get wireless network operators to run their 5G SA core network, edge computing and various distributed applications on their cloud platforms. For example, Amazon’s AWS public cloud, Microsoft’s Azure for Operators, and Google’s Anthos for Telecom were intended to get network operators to run their core network functions into a hyperscaler cloud.
AWS had early success with Dish Network’s 5G SA core network which has all its functions running in Amazon’s cloud with fully automated network deployment and operations.
Conversely, AT&T has yet to commercially deploy its 5G SA Core network on the Microsoft Azure public cloud. Also, users on AT&T’s network have experienced difficulties accessing Microsoft 365 and Azure services. Those incidents were often traced to changes within the network’s managed environment. As a result, Microsoft has drastically reduced its early telecom ambitions.
Several pundits now say that AI will significantly strengthen the business case for cloud networking by enabling more efficient resource management, advanced predictive analytics, improved security, and automation, ultimately leading to cost savings, better performance, and faster innovation for businesses utilizing cloud infrastructure.
“AI is already a significant traffic driver, and AI traffic growth is accelerating,” wrote analyst Brian Washburn in a market research report for Omdia (owned by Informa). “As AI traffic adds to and substitutes conventional applications, conventional traffic year-over-year growth slows. Omdia forecasts that in 2026–30, global conventional (non-AI) traffic will be about 18% CAGR [compound annual growth rate].”
Omdia forecasts 2031 as “the crossover point where global AI network traffic exceeds conventional traffic.”
Markets & Markets forecasts the global cloud AI market (which includes cloud AI networking) will grow at a CAGR of 32.4% from 2024 to 2029.
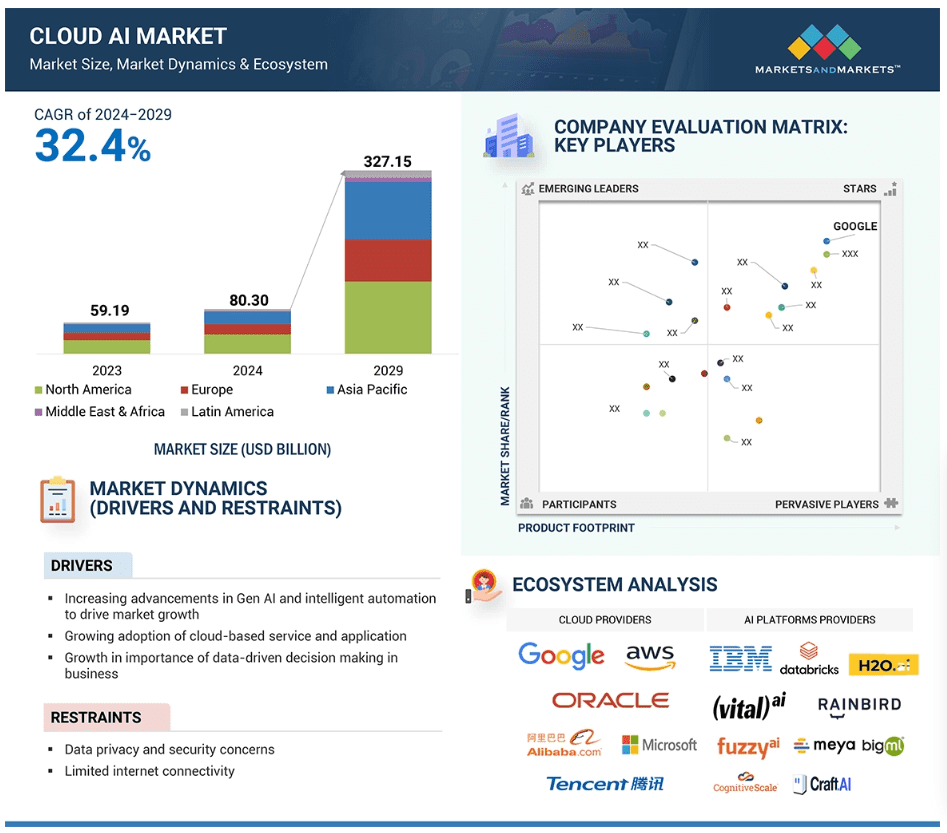
AI is said to enhance cloud networking in these ways:
- Optimized resource allocation:
AI algorithms can analyze real-time data to dynamically adjust cloud resources like compute power and storage based on demand, minimizing unnecessary costs. - Predictive maintenance:
By analyzing network patterns, AI can identify potential issues before they occur, allowing for proactive maintenance and preventing downtime. - Enhanced security:
AI can detect and respond to cyber threats in real-time through anomaly detection and behavioral analysis, improving overall network security. - Intelligent routing:
AI can optimize network traffic flow by dynamically routing data packets to the most efficient paths, improving network performance. - Automated network management:
AI can automate routine network management tasks, freeing up IT staff to focus on more strategic initiatives.
The pitch is that AI will enable businesses to leverage the full potential of cloud networking by providing a more intelligent, adaptable, and cost-effective solution. Well, that remains to be seen. Google’s new global industry lead for telecom, Angelo Libertucci, told Light Reading:
“Now enter AI,” he continued. “With AI … I really have a power to do some amazing things, like enrich customer experiences, automate my network, feed the network data into my customer experience virtual agents. There’s a lot I can do with AI. It changes the business case that we’ve been running.”
“Before AI, the business case was maybe based on certain criteria. With AI, it changes the criteria. And it helps accelerate that move [to the cloud and to the edge],” he explained. “So, I think that work is ongoing, and with AI it’ll actually be accelerated. But we still have work to do with both the carriers and, especially, the network equipment manufacturers.”
Google Cloud last week announced several new AI-focused agreements with companies such as Amdocs, Bell Canada, Deutsche Telekom, Telus and Vodafone Italy.
As IEEE Techblog reported here last week, Deutsche Telekom is using Google Cloud’s Gemini 2.0 in Vertex AI to develop a network AI agent called RAN Guardian. That AI agent can “analyze network behavior, detect performance issues, and implement corrective actions to improve network reliability and customer experience,” according to the companies.
And, of course, there’s all the buzz over AI RAN and we plan to cover expected MWC 2025 announcements in that space next week.
https://www.lightreading.com/cloud/google-cloud-doubles-down-on-mwc
Nvidia AI-RAN survey results; AI inferencing as a reinvention of edge computing?
The case for and against AI-RAN technology using Nvidia or AMD GPUs
Generative AI in telecom; ChatGPT as a manager? ChatGPT vs Google Search
Cisco to lay off more than 4,000 as it shifts focus to AI and Cybersecurity
Reuters reports that Cisco Systems will cut thousands of jobs in its second round of layoffs this year. The number of people affected could be similar to or slightly higher than the 4,000 employees Cisco laid off in February, and will likely be announced as early as Wednesday with the company’s fourth-quarter results.
The San Jose, CA headquartered networking company plans to shift its product focus to higher-growth areas, such as AI and cybersecurity. It’s current set of products and services are listed here.
Cisco has been contending with weakening demand and persistent supply chain issues in its core business – routers and switches – that are used by ISPs and enterprise private networks. Two reasons for that are: 1.] the major cloud service providers design their own switch/routers or use bare metal switches (made by ODMs in Taiwan and China), and 2.] enterprise private/virtual private networks are being replaced by cloud network solutions.
- Global enterprise network sales have been declining. Dell’Oro Group reported sales contractions in Branch Routing and Campus Switching in 4Q-2023 and that is expected to continue throughout most of 2024. On premises data centers (which use Cisco Ethernet switches) are not growing. In its place……
- Enterprise spending on cloud infrastructure services is growing by leaps and bounds. It’s now nearing $80 billion per quarter. Cloud customers increased their spending on cloud services by $14.1 billion to $79.1 billion in the 2Q-2024, an increase of 22% year-over-year. It’s the third consecutive quarter in which the year-over-year growth rate was 20% or more, with generative AI being one of the factors behind the market acceleration.
……………………………………………………………………………………………………………………………………………
As a result of stagnant sales of its core networking products, Cisco has been pursuing a strategy aimed at diversifying its revenue streams. One of the most significant moves in this direction was the $28 billion acquisition of Splunk, a cybersecurity firm, which was finalized in March. This purchase is expected to boost Cisco’s subscription-based services, reducing its dependence on one-time hardware sales, which have been increasingly susceptible to market volatility.
Cisco’s major shift towards AI is a key part of its long-term strategy. In May, the company reiterated its ambitious goal of achieving $1 billion in AI-related product orders by 2025. This target is supported by a $1 billion fund launched in June, aimed at investing in AI startups such as Cohere, Mistral AI, and Scale AI. Over the past few years, Cisco has made over 20 AI-focused acquisitions and investments, highlighting its commitment to integrating AI into its product offerings.
……………………………………………………………………………………………………………………………………………..
Over 126,000 employees have been laid off across 393 tech companies since the start of the year, according to data from tracking website Layoffs.fyi. That surely reflects their need to cut costs to balance huge investments in AI, analytics and related technologies.
……………………………………………………………………………………………………………………………………………..
References:
https://www.cisco.com/c/en/us/products/index.html#~products-by-technology
Cisco to Implement Second Round of Layoffs Amidst Strategic Shift to AI and Cybersecurity
Worldwide Enterprise Network Spending Follows Roller Coaster Trajectory
Cisco restructuring plan will result in ~4100 layoffs; focus on security and cloud based products
Forbes: Cloud is a huge challenge for enterprise networks; AI adds complexity
Survey data and discussions with enterprise networking professionals reveal they are still grappling with many networking issues spawned by the expansion of the cloud – the most common of which include securing connections for remote work, implementing zero-trust security strategies, and integrating myriad cloud and wide-area networks (WANs).
For example, in Futuriom’s latest survey of 196 enterprise IT and networking professionals, more than 80% said the complexity of connecting the wide variety of networks was a large challenge. At nearly 70% of responses, expertise and knowledge was the second-largest challenge (multiple responses were allowed), and cost was cited by 60%. Please refer to survey highlights below.
Contributing to that complexity is the ephemeral nature of both cloud connectivity and hybrid work. Workers are now moving around more than ever, and cloud services can change and scale nearly every day (or minute).

Survey Highlights:
- Survey respondents indicate strong demand for SD-WAN and SASE managed services. Our survey data and discussions with end users indicate that SD-WAN/SASE technology helps professionals with network and security challenges, including the growing complexity created by distributed applications, cloud connectivity, and sprawling security risks.
- Managing network complexity is the largest challenge driving managed services demand. When asked about the largest challenges in managing WANs, 85% of respondents identified complexity, followed by expertise and knowledge (68%). Rounding out the responses were cost (60%) and time (47%). (Multiple responses were allowed.)
- Hybrid work and the need for zero-trust network access (ZTNA) are key drivers of SD-WAN/SASE technology. In the survey, 98% of respondents said that hybrid work has increased demand for SASE and ZTNA. When we asked respondents if ZTNA is a crucial component of SASE and SD-WAN offerings, 92% said yes.
- Hybrid (cloud/edge deployment) and single-pass architectures will be important components of SASE/SD-WAN services going forward. When respondents were asked if they wanted a hybrid solution that can accommodate networking and security both on premises and using cloud points of presence (PoPs), 98% said yes. In addition, 94% of respondents said they prefer a single-pass architecture.
- There will continue to be a diversity of SD-WAN/SASE deployment models. The two most popular models for deployment are best-of-breed combination (34%) and single-vendor (23%), but survey results show a wide diversity of deployment models.
AI increases complexity as enterprises need to figure out how to store, connect, and move their data in hybrid clouds that will leverage AI.
This complexity, along with the rapid shift to hybrid work spurred by COVID, has triggered a wave of innovation in networking – perhaps more innovation than we have seen in decades. Startups are drawing large funding rounds. Best-of-breed established networking players such as Arista Networks, Extreme Networks, Juniper Networks, and HPE are building new networking and security products and chipping away at the market share of market leader Cisco. Cisco is responding in kind. Sources tell me they think Cisco’s acquisition of Valtix may be the most interesting in years.
All of this sets the stage for the most dynamic networking environment I’ve seen in decades. And it’s only going to get more interesting, as the AI and hybrid work wave makes networking more crucial.
The melding of security and networking remains hot. In the software-defined networking (SD-WAN) and Secure Access Service Edge market, potential Initial Public Offering (IPO) companies such as Aryaka Networks, Cato Networks, and Versa Networks are building our product suites to help secure remote workers and cloud connectivity. These companies will also help enterprises connect to cloud on-ramps and consolidate security functions with a SASE approach. Versa last October tanked up with $120 in funding in what it called a “pre-IPO round.”
Many of the cloud networking startups that are included in the Futuriom 50 list of promising cloud innovators are using this chaotic moment to shore up strategies, raise money — or both.
For example, just this week, cloud-native networking start-up Arrcus announced that Hitachi Ventures would invest additional capital, raising its Series D to $65 million before it closes. Arrcus says its Arrcus Connected Edge (ACE) platform will be more economical for cloud providers and service providers deploying services such as 5G and AI. It claims it is growing revenue 100% year-over-year.
Other cloud networking startups are also going after AI. DriveNets recently announced that its Network Cloud-AI solution, which uses cloud-based Ethernet-based networking to boost the performance of AI clouds, is in trials with major hyperscalers.
Cost optimization, one of the strongest themes of the year in cloud technology, is another focus for cloud networking players. Cloud networking pioneer Aviatrix has beefed up security and cost-optimization features and launched a distributed firewall to help enterprises reduce the costs of cloud networking infrastructure. Prosimo last week made an interesting play to get its application-layer cloud networking suite in the hands of more users by launching a free, introductory-level version of its product called MCN Foundation.
Yes, there is a trend to all these announcements. They are focused on return on investment (ROI) and cost savings. This is the right message for the era we are in. Enterprise tech planners not only want to shift to more flexible cloud-based services, they need to do so to save money.
For example, in its new product release, Prosimo said customers can achieve a 30%-50% reduction in total cost of ownership (TCO) by optimizing cloud network connectivity. With its distributed firewall, Aviatrix says network pros will save money by reducing the expense of additional firewall instances, which many enterprises must buy to support additional cloud connectivity and scaling. (But they may not want to stack firewall upon firewall into the cloud, which after all can function as a firewall itself.) DriveNets says its trials have reduced the idle time of AI clouds by as much as 30%.
Integrating all of this stuff isn’t easy either. That’s the value proposition of Itential, a plucky Georgia-based startup with a set of low-code automation tools that streamline networking for integrations in hybrid networking and cloud environments.
It’s no coincidence that the marketing messages have all shifted toward ROI, which is the mother’s milk of technology. It’s the reason we all use cloud-based software-as-a-service and iPhones instead of minicomputers and rotary dial phones. Innovation is about efficiency.
This makes me very optimistic about cloud networking – and the networking market in general. After decades of stagnation, the cloud has woken up the industry. In addition to innovation, there is also a surge in competition — which will put more efficient and affordable technology into the hands of the users.
References:
Networking Startups Jump On Cloud Costs And AI (forbes.com)
https://www.futuriom.com/articles/news/results-from-our-sd-wan-sase-managed-services-survey/2023/06
Generative AI in telecom; ChatGPT as a manager? ChatGPT vs Google Search
Generative AI could put telecom jobs in jeopardy; compelling AI in telecom use cases
Allied Market Research: Global AI in telecom market forecast to reach $38.8 by 2031 with CAGR of 41.4% (from 2022 to 2031)
Telecom TV Poll: How to maximize cloud-native opportunities?
The adoption of cloud-native methodologies, processes and tools has been a challenge for communications service providers (CSPs), aka telcos or network operators.
- Telcos are embracing cloud-native processes and tools
- It’s part of their evolution towards being digital service providers
- But the cloud-native journey is still in its early stages
- Real cultural change is needed if telcos are to capitalise fully on the cloud-native opportunities
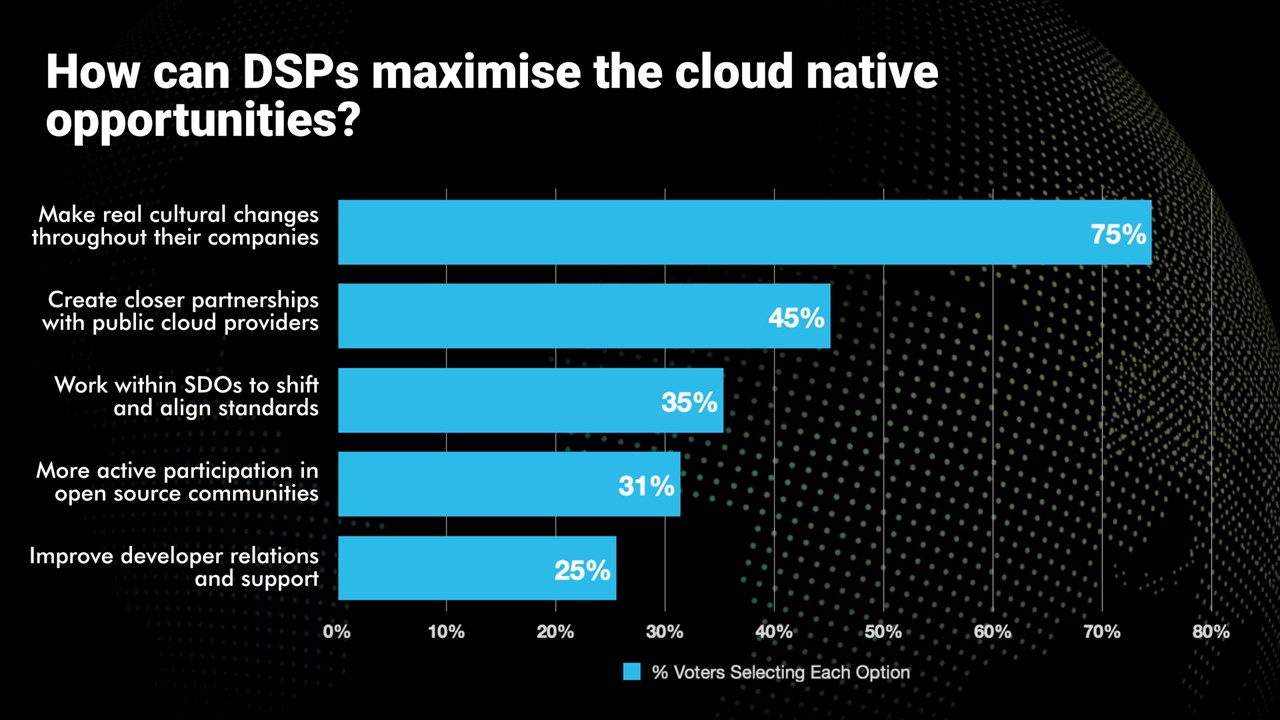
Alongside a a session, Why cloud native is essential to delivering the automation, agility and innovation needed to support new services, at Telco TV’s DSP Leaders World Forum event in Windsor, UK, a poll was taken. The following question was asked, “How can Digital Service Providers maximize the cloud-native opportunities?” Respondents were able to select all the options they deemed relevant. Here are the results:
Please check out the upcoming Cloud Native Telco Summit session on cloud-native application development to see what the industry experts have to say.
Omdia and Ericsson on telco transitioning to cloud native network functions (CNFs) and 5G SA core networks
Huawei Connect 2022: It’s Cloud Native everything!
Banned in the U.S., China Telecom Americas launches eSurfing Cloud services in Brazil
China Telecom do Brasil (“CTB”) today announced the launch of eSurfing Cloud services in Brazil. Through on-demand purchases that aim to simplify the process for more targeted service, the new offering provides businesses with the flexibility of accessing public and private cloud services, combined with the security and control of private cloud.
CTB’s eSurfing Cloud services enable enterprises in Brazil to take advantage of the latest cloud technologies, with the added benefit of local support and expertise. With this new offering, businesses in Brazil can optimize their cloud environments, reduce costs, and improve efficiency, all while maintaining high levels of security and compliance. The eSurfing Cloud services in São Paulo will allow customers to connect on a global multi-cloud network of more than nine public cloud nodes, 30 proprietary edge cloud nodes, and more than 200 CDN nodes.
“We are excited to bring our world-class cloud solutions to businesses in Brazil,” said Luis Fiallo, the officer of China Telecom do Brasil. “Our eSurfing Cloud services deliver flexible and scalable solutions that can meet the unique evolving needs of businesses in the region. The launch of this new offering is our continued commitment to helping our customers achieve their business goals and succeed in today’s digital landscape.”
Brazil is one of the most active cloud markets in Latin America, with high demand for the critical services that connect LATAM to the global market. Cloud adoption in Brazil has increased nearly 40% since 2019 and is expected to grow nearly 19% by 2033. While eSurfing Cloud provides customers with access to public cloud, private cloud, hybrid cloud, and edge cloud, its advantages in cloud-network integration, security, and extensive customization make it the choice digital transformation accelerator for businesses of any size.
About China Telecom do Brasil:
China Telecom do Brasil is the largest subsidiary of China Telecom Americas in Latin America and a leading provider of Internet and cloud computing services in Brazil. With a focus on customer satisfaction, the company delivers reliable, scalable, and secure solutions that enable businesses to connect their networks within Brazil and internationally, while thriving in today’s digital landscape. The company is the largest Chinese Internet provider in Brazil with network POPs and backbone connecting the state of Sao Paulo, State of Rio De Janeiro, State of Parana and State of Rio Grande do Sul to the China Telecom global network.
SOURCE: China Telecom Americas
………………………………………………………………………………………………………………………………………
China Telecom still banned in U.S.:
The Federal Communications Commission (FCC) has raised mounting concerns about Chinese telecom companies in recent years which had won permission to operate in the United States decades ago. On October 26, 2021 the FCC revoked and terminated China Telecom America’s authority to provide Telecom Services in America. The FCC said that China Telecom (Americas) “is subject to exploitation, influence and control by the Chinese government.”
On December 20, 2022, a U.S. federal appeals court rejected China Telecom Corp’s challenge to the order withdrawing the company’s authority to provide services in the United States.
…………………………………………………………………………………………………………………………………………
References:
https://www.fcc.gov/document/fcc-revokes-china-telecom-americas-telecom-services-authority
Analysis and Implications: China’s 3 Major Telecom Operators to be delisted by NYSE
Swisscom, Ericsson and AWS collaborate on 5G SA Core for hybrid clouds
Swiss network operator Swisscom have announced a proof-of-concept (PoC) collaboration with Ericsson 5G SA Core running on AWS. The objective is to explore hybrid cloud use cases with AWS, beginning with 5G core applications. The plan is for more applications to then gradually be added as the trial continues. With each cloud strategy (private, public, hybrid, multi) bringing its own drivers and challenges the idea here seems to be enabling the operator to take advantage of the specific characteristics of both hybrid and public cloud.
The PoC reconfirms Swisscom and Ericsson’s view of the potential hybrid cloud has as a complement to existing private cloud infrastructure. Both Swisscom and Ericsson are on a common journey with AWS to explore how use cases can benefit telecom operators.
The PoC will examine use cases that take advantage of the particular characteristics of hybrid and public cloud. In particular, the flexibility and elasticity it can offer to customers which can mean deployment efficiencies for use cases where capacity is not constantly needed. An example of this could be when maintenance activities are undertaken in Swisscom’s private cloud, or when there are traffic peaks, AWS can be used to offload and complement the private cloud.
Swisscom had already been collaborating with AWS on migrating its 5G infrastructure towards standalone 5G. In addition, it has also used the hyperscaler’s public cloud platform for its IT environments. Telco concerns linger [1.] around the use of public cloud in telecoms infrastructure (especially the core networks) for some operators, hybrid cloud is seemingly gaining momentum as a transitional approach.
Note 1. Telco concerns over public cloud:
- In a recent survey by Telecoms.com more than four in five industry respondents feared security concerns over running telco applications in the public cloud, including 37% who find it hard to make the business case for public cloud as private cloud remains vital in addressing security issues. This also means that any efficiency gains are offset by the IT environment and the network running over two cloud types.
- Many in the industry also fear vendor lock-in and lack of orchestration from public cloud providers. Around a third of industry experts from the same survey find it a compelling reason not to embrace and move workloads to the public cloud unless applications can run on all versions of public cloud and are portable among cloud vendors.
- There’s also a lack of interoperability and interconnectedness with public clouds. The services of different public cloud vendors are indeed not interconnected nor interoperable for the same types of workloads. This concern is one of the drivers to avoid public cloud, according to some network operators.
–>PLEASE SEE THE COMMENT ON THIS TOPIC IN THE BOX BELOW THE ARTICLE.
Quotes:
Mark Düsener, Executive Vice President Mobile Network & Services at Swisscom, says: “By bringing the Ericsson 5G Core onto AWS we will substantially change the way our networks will be built and operated. The elasticity of the cloud in combination with a new magnitude in automatization will support us in delivering even better quality more efficiently over time. In order to shape this new concept, we as Swisscom believe strategic and deep partnerships like the ones we have with Ericsson and AWS are the key for success.”
Monica Zethzon, Head of Solution Area Core Networks, Ericsson says: “5G innovation requires deep collaboration to create the foundations necessary for new and evolving use cases. This Proof-of-Concept project with Swisscom and AWS is about opening up the routes to innovation by using hybrid cloud’s flexible combination of private and public cloud resources. It demonstrates that through partnership, we can deliver a hybrid cloud solution which meets strict telecoms industry requirements and security while making best use of HCP agility and cloud economy of scale.”
Fabio Cerone, General Manager AWS Telco EMEA at AWS, says: “With this move, Swisscom is opening the door to cloud native networks, delivering full automation and elasticity at scale, with the ability to innovate faster and make 5G impactful to their customers. We are committed to working closely with partners, such as Ericsson, to explore new use cases and strategies that best support the needs of customers like Swisscom.”
“How to deploy software in different cloud environments – at a high level, it is hard making that work in practice,” said Per Narvinger, the head of Ericsson’s cloud software and services unit. “You have hyperscalers with their offering and groups trying to standardize and people trying to do it their own way. There needs to be harmonization of what is wanted.”
https://telecoms.com/520337/swisscom-ericson-and-aws-collaborate-on-hybrid-cloud-poc-on-5g-core/
https://telecoms.com/520055/telcos-and-the-public-cloud-drivers-and-challenges/
AWS Telco Network Builder: managed network automation service to deploy, run, and scale telco networks on AWS
Omdia and Ericsson on telco transitioning to cloud native network functions (CNFs) and 5G SA core networks
Info-Tech: Cloud Network Design Must Evolve to Meet Both Current and Future Organizational Needs
Cloud adoption among organizations has increased dramatically over the past few years, both in the range of services used and the extent to which they are employed. However, network builders tend to overlook the vulnerabilities of network topologies, which leads to complications down the road, especially since the structures of cloud network topologies are not all of the same quality. To help organizations build a network design that suits their current needs and future state, global IT research and advisory firm Info-Tech Research Group has published its latest advisory deck, Considerations for a Hub and Spoke Model When Deploying Infrastructure in the Cloud.
The new research deck states that for organizations considering migrating their resources to the cloud, careful planning and decision making is required. This includes selecting the right topology, designing the cloud infrastructure for efficient management, and providing access to shared services. The advisory deck further highlights that one of the main challenges of cloud infrastructure planning is finding the right balance between governance and flexibility, which is often overlooked.

“Evaluating and selecting the right cloud network topology is crucial for optimizing performance. It also enables easier management and resource provisioning,” says Nitin Mukesh, senior research analyst at Info-Tech Research Group. “An ‘as the need arises’ strategy will not work efficiently since network design changes can significantly impact data flows and application architectures, which becomes more complicated as the number of cloud-hosted services grows. Designing a network strategy early on will give more control over networks and prevent the need for significant infrastructure changes later.”
Info-Tech’s research indicates that when organizations move to the cloud, many often retain the mesh networking topology from their on-prem design, or they choose to implement the mesh design using peering technologies in the cloud without considering the potential changes in business needs. Although there are various network topologies for on-prem infrastructure, the network design team may not be aware of the best approach in cloud platforms for their requirements, or a cloud networking strategy may even go overlooked during the migration.
The new resource explores a hub and spoke model for organizations deciding between governance and flexibility in network design. A hub and spoke network design involves connecting multiple networks to a central network, or a hub, that facilitates intercommunication between them. The hub can be used by multiple workloads for hosting services and managing external connectivity.
Other networks connected to the hub through network peering are called spokes and host workloads. Communications between workloads, servers, or services on the spokes pass through the hub, where they are inspected and routed. The spokes can be centrally managed from the hub using IT rules and processes. This design allows for a larger number of virtual networks to be interconnected, with only one peered connection needed to communicate with any other network in the system.
Organizations that choose to deploy the hub and spoke model face a dilemma in choosing between governance and flexibility for their networks. Info-Tech recommends that organizations consider the following design options when developing a cloud network strategy:
- PEERING: Peering Virtual Private Clouds (VPCs) into a mesh design can be an easy way to get onto the cloud, but it shouldn’t be the networking strategy for the long run.
- HUB AND SPOKE: Hub and spoke network design offers more benefits than any other network strategy to be adopted only when the need arises. Organizations should plan for the design and strategize to deploy it as early as possible.
- HYBRID: A mesh and hub and spoke hybrid can be instrumental in connecting multiple large networks, especially when they need to access the same resources without having to route the traffic over the internet.
- GOVERNANCE VS. FLEXIBILITY: Governance vs. flexibility should be a key consideration when designing for hub and spoke to leverage the best out of the infrastructure.
- DOMAINS: Distribute domains across the hub or spokes to leverage costs, security, data collection, and economies of scale and foster secure interactions between networks.
The firm advises that the advantages of using a hub and spoke model far exceed those of using a mesh topology in the cloud. However, organizations, especially large ones, are complex entities, and choosing only one model may not serve all business needs. In such cases, a hybrid approach may be the best strategy.
To learn more, download the complete Considerations for a Hub and Spoke Model When Deploying Infrastructure in the Cloud advisory deck.
Info-Tech Research Group is one of the world’s leading information technology research and advisory firms, proudly serving over 30,000 IT professionals. The company produces unbiased and highly relevant research to help CIOs and IT leaders make strategic, timely, and well-informed decisions. For 25 years, Info-Tech has partnered closely with IT teams to provide them with everything they need, from actionable tools to analyst guidance, ensuring they deliver measurable results for their organizations.
Media professionals can register for unrestricted access to research across IT, HR, and software and over 200 IT and Industry analysts through the ITRG Media Insiders Program. To gain access, contact [email protected].
SOURCE Info-Tech Research Group
……………………………………………………………………………………………………………………
References:
For more information about Info-Tech Research Group or to access the latest research, visit infotech.com and connect via LinkedIn and Twitter.
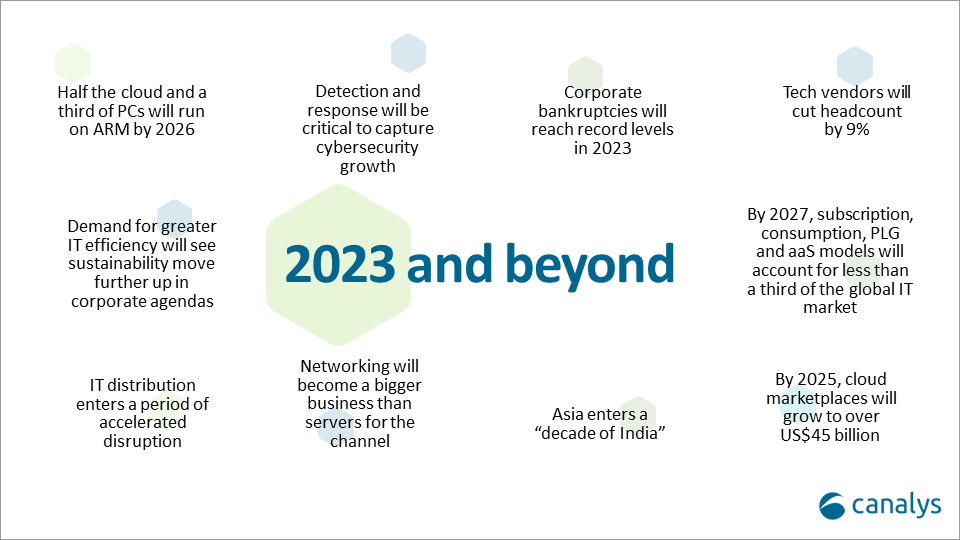
Canalys: Cloud marketplace sales to be > $45 billion by 2025
Canalys now expects that by 2025, cloud marketplaces will grow to more than $45 billion, representing an 84% CAGR. That was one of the market research firm’s predictions for 2023 and beyond (see chart below).
Cloud marketplaces [1.] are accelerating as a route to market for technology, led by hyperscale cloud vendors such as Alibaba, Amazon Web Services, Microsoft, Google and Salesforce, which are pouring billions of development dollars into the sector.
Note 1. A cloud marketplace is an online storefront operated by a cloud service provider. A cloud marketplace provides customers with access to software applications and services that are built on, integrate with or complement the cloud service provider’s offerings. A marketplace typically provides customers with native cloud applications and approved apps created by third-party developers. Applications from third-party developers not only help the cloud provider fill niche gaps in its portfolio and meet the needs of more customers, but they also provide the customer with peace of mind by knowing that all purchases from the vendor’s marketplace will integrate with each other smoothly.
…………………………………………………………………………………………………………………………………………………………………….
“The marketplace route to market is on fire and cannot be ignored by any channel leader,” said Canalys Chief Analyst, Jay McBain. “Marketplaces grew more in the first three months of the pandemic than in the previous decade and have just kept growing,” he added.
“We under-called it,” explained Steven Kiernan, vice president at Canalys. “Cloud marketplaces are accelerating at such a dizzying speed that we’ve doubled our pre-pandemic forecast.
Some software vendors that are active on marketplaces, in particular cybersecurity vendors, are publicly reporting as much as 600% year-on-year growth via this channel, according to McBain.
In addition, the hyperscalers are now reporting growing numbers of billion-dollar customer commitments through enterprise cloud consumption credits, which cover more than just software.
The large cloud marketplaces have lowered fees from upwards of 20% down to 3%, enabling vendors to fund multi-partner offers inside the transaction.
Private equity is funding billions more into marketplace development firms such as AppDirect, Mirakl, Vendasta and CloudBlue to enable hundreds of niche marketplaces across different buyers, industries, geographies, customer segments, product areas and business models.

Canalys Chief Analyst, Alastair Edwards:
“The rise of this route to market represents a threat to both resellers and two-tier distribution. But as more complex technologies are consumed via marketplaces, end customers are also turning to trusted partners to help them discover, procure and manage marketplace purchases. The hyperscalers are increasingly recognizing the value of channel partners, allowing them to create customized vendor offers for end-customers, and supporting the flow of channel margins through their marketplaces. Hyperscalers’ cloud marketplaces are becoming a growing force in global IT distribution as a result.”
By 2025, Canalys conservatively forecasts that almost a third of marketplace procurement will be done via channel partners on behalf of their end customers.
Canalys key predictions for 2023 and beyond:
About Canalys:
Canalys is an independent analyst company that strives to guide clients on the future of the technology industry and to think beyond the business models of the past. We deliver smart market insights to IT, channel and service provider professionals around the world. We stake our reputation on the quality of our data, our innovative use of technology and our high level of customer service.
References:
https://canalys.com/newsroom/cloud-marketplace-forecast-2023
https://www.canalys.com/resources/Canalys-outlook-2023-predictions-for-the-technology-industry
https://www.techtarget.com/searchitchannel/definition/cloud-marketplace
Canalys: Global cloud services spending +33% in Q2 2022 to $62.3B
AWS, Microsoft Azure, Google Cloud account for 62% – 66% of cloud spending in 1Q-2022
IDC: Cloud Infrastructure Spending +13.5% YoY in 4Q-2021 to $21.1 billion; Forecast CAGR of 12.6% from 2021-2026
